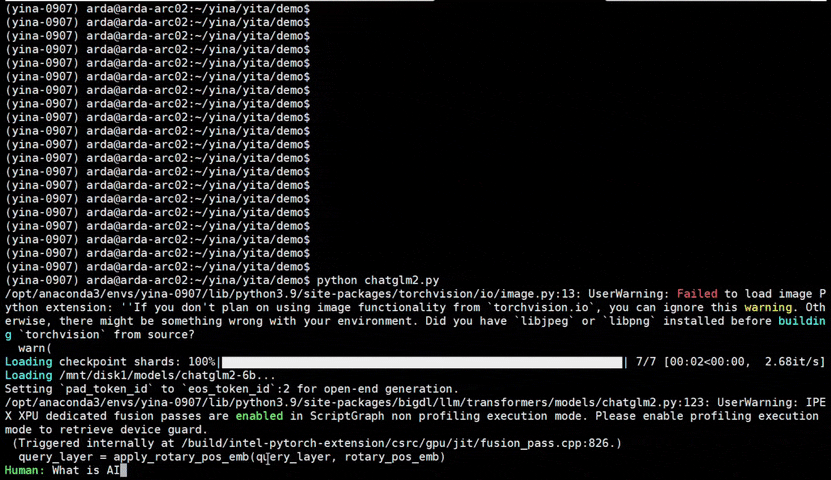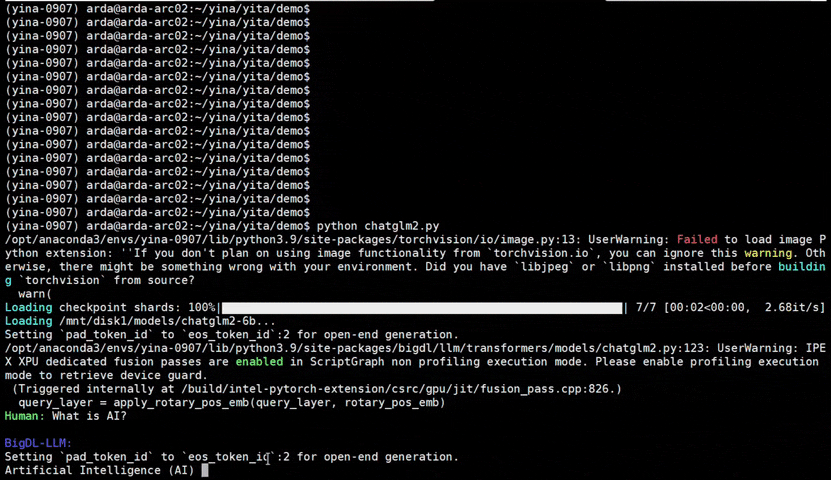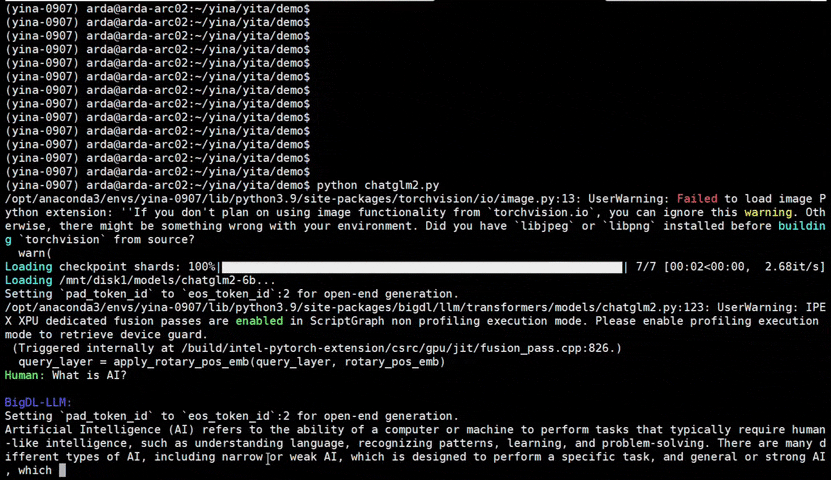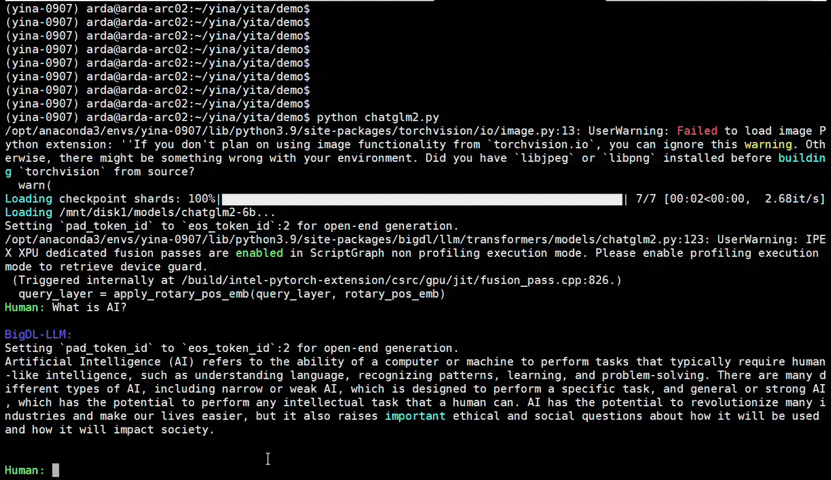
bigdl-llm is a library for running LLM (large language model) on Intel XPU (from Laptop to GPU to Cloud) using INT4 with very low latency1 (for any PyTorch model).
It is built on top of the excellent work of llama.cpp, gptq, ggml, llama-cpp-python, bitsandbytes, qlora, gptq_for_llama, chatglm.cpp, redpajama.cpp, gptneox.cpp, bloomz.cpp, etc.
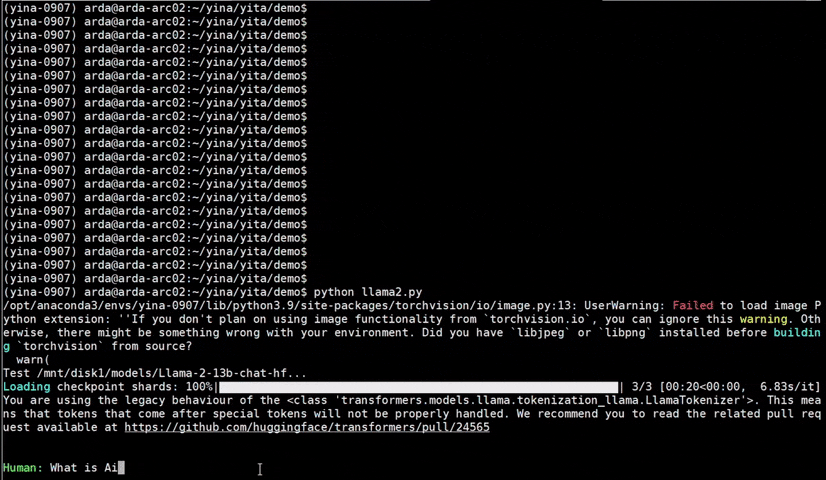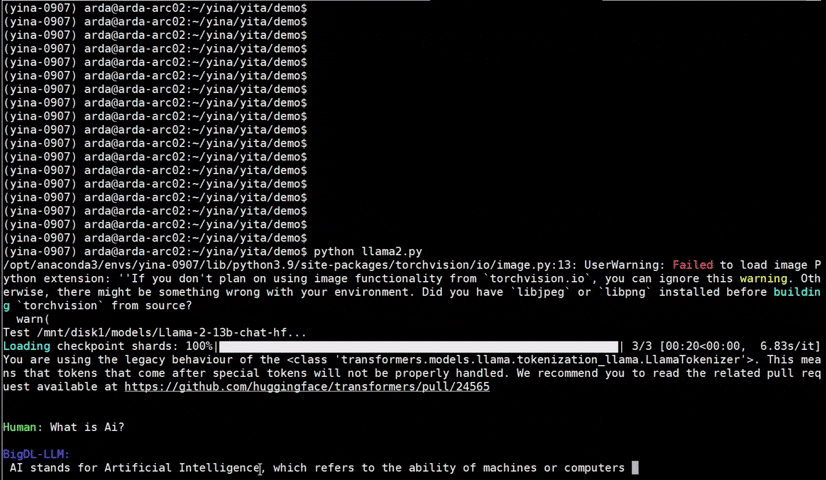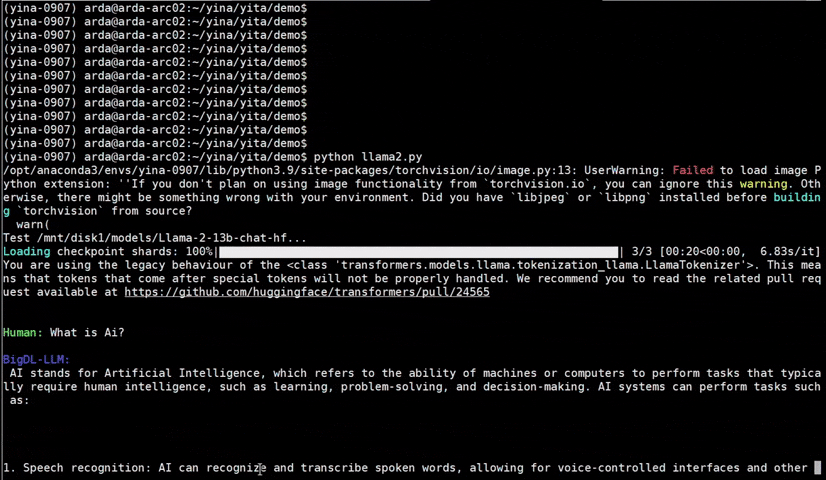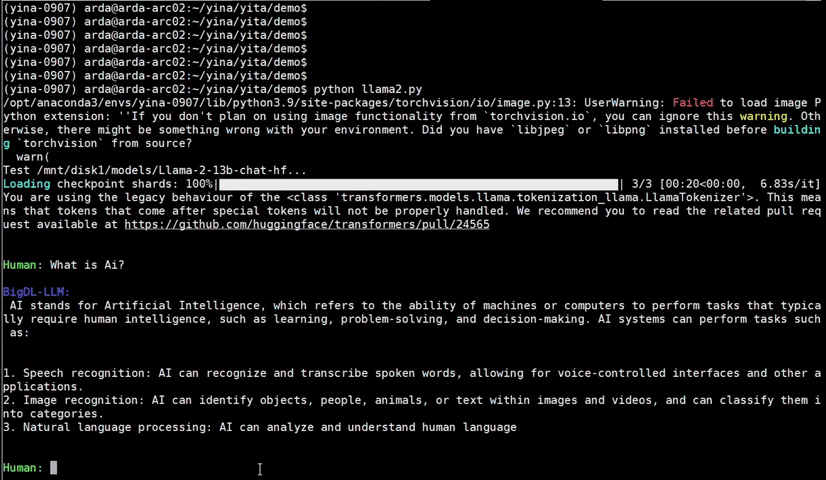
See the optimized performance of chatglm2-6b and llama-2-13b-chat models on 12th Gen Intel Core CPU and Intel Arc GPU below.
| 12th Gen Intel Core CPU | Intel Arc GPU | ||
|
|
|
|
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
Over 20 models have been optimized/verified on bigdl-llm, including LLaMA/LLaMA2, ChatGLM/ChatGLM2, MPT, Falcon, Dolly-v1/Dolly-v2, StarCoder, Whisper, InternLM, QWen, Baichuan, MOSS, and more; see the complete list below.
Table of verified models
| Model | Example |
|---|---|
| LLaMA (such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.) | link1, link2 |
| LLaMA 2 | link |
| MPT | link |
| Falcon | link |
| ChatGLM | link |
| ChatGLM2 | link |
| Qwen | link |
| MOSS | link |
| Baichuan | link |
| Baichuan2 | link |
| Dolly-v1 | link |
| Dolly-v2 | link |
| RedPajama | link1, link2 |
| Phoenix | link1, link2 |
| StarCoder | link1, link2 |
| InternLM | link |
| Whisper | link |
Table of Contents
You may install bigdl-llm on Intel CPU as follows:
pip install --pre --upgrade bigdl-llm[all]Note:
bigdl-llmhas been tested on Python 3.9
You may install bigdl-llm on Intel GPU as follows:
# below command will install intel_extension_for_pytorch==2.0.110+xpu as default
# you can install specific ipex/torch version for your need
pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpuNote:
bigdl-llmhas been tested on Python 3.9
You may run the models using bigdl-llm through one of the following APIs:
You may run any Hugging Face Transformers model as follows:
You may apply INT4 optimizations to any Hugging Face Transformers model on Intel CPU as follows.
#load Hugging Face Transformers model with INT4 optimizations
from bigdl.llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on Intel CPU
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...)
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids)See the complete examples here.
You may apply INT4 optimizations to any Hugging Face Transformers model on Intel GPU as follows.
#load Hugging Face Transformers model with INT4 optimizations
from bigdl.llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on Intel GPU
model = model.to('xpu')
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...).to('xpu')
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids.cpu())See the complete examples here.
-
Save and load
After the model is optimized using
bigdl-llm, you may save and load the model as follows:model.save_low_bit(model_path) new_model = AutoModelForCausalLM.load_low_bit(model_path)
See the complete example here.
-
Additonal data types
In addition to INT4, You may apply other low bit optimizations (such as INT8, INT5, NF4, etc.) as follows:
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_low_bit="sym_int8")
See the complete example here.
You may also convert Hugging Face Transformers models into native INT4 model format for maximum performance as follows.
Notes: Currently only llama/bloom/gptneox/starcoder/chatglm model families are supported; for other models, you may use the Hugging Face
transformersmodel format as described above).
#convert the model
from bigdl.llm import llm_convert
bigdl_llm_path = llm_convert(model='/path/to/model/',
outfile='/path/to/output/', outtype='int4', model_family="llama")
#load the converted model
#switch to ChatGLMForCausalLM/GptneoxForCausalLM/BloomForCausalLM/StarcoderForCausalLM to load other models
from bigdl.llm.transformers import LlamaForCausalLM
llm = LlamaForCausalLM.from_pretrained("/path/to/output/model.bin", native=True, ...)
#run the converted model
input_ids = llm.tokenize(prompt)
output_ids = llm.generate(input_ids, ...)
output = llm.batch_decode(output_ids)See the complete example here.
You may run the models using the LangChain API in bigdl-llm.
-
Using Hugging Face
transformersmodelYou may run any Hugging Face Transformers model (with INT4 optimiztions applied) using the LangChain API as follows:
from bigdl.llm.langchain.llms import TransformersLLM from bigdl.llm.langchain.embeddings import TransformersEmbeddings from langchain.chains.question_answering import load_qa_chain embeddings = TransformersEmbeddings.from_model_id(model_id=model_path) bigdl_llm = TransformersLLM.from_model_id(model_id=model_path, ...) doc_chain = load_qa_chain(bigdl_llm, ...) output = doc_chain.run(...)
See the examples here.
-
Using native INT4 model
You may also convert Hugging Face Transformers models into native INT4 format, and then run the converted models using the LangChain API as follows.
Notes:* Currently only llama/bloom/gptneox/starcoder/chatglm model families are supported; for other models, you may use the Hugging Face
transformersmodel format as described above).from bigdl.llm.langchain.llms import LlamaLLM from bigdl.llm.langchain.embeddings import LlamaEmbeddings from langchain.chains.question_answering import load_qa_chain #switch to ChatGLMEmbeddings/GptneoxEmbeddings/BloomEmbeddings/StarcoderEmbeddings to load other models embeddings = LlamaEmbeddings(model_path='/path/to/converted/model.bin') #switch to ChatGLMLLM/GptneoxLLM/BloomLLM/StarcoderLLM to load other models bigdl_llm = LlamaLLM(model_path='/path/to/converted/model.bin') doc_chain = load_qa_chain(bigdl_llm, ...) doc_chain.run(...)
See the examples here.
Note: Currently
bigdl-llmCLI supports LLaMA (e.g., vicuna), GPT-NeoX (e.g., redpajama), BLOOM (e.g., pheonix) and GPT2 (e.g., starcoder) model architecture; for other models, you may use the Hugging Facetransformersor LangChain APIs.
-
You may convert the downloaded model into native INT4 format using
llm-convert.#convert PyTorch (fp16 or fp32) model; #llama/bloom/gptneox/starcoder model family is currently supported llm-convert "/path/to/model/" --model-format pth --model-family "bloom" --outfile "/path/to/output/" #convert GPTQ-4bit model #only llama model family is currently supported llm-convert "/path/to/model/" --model-format gptq --model-family "llama" --outfile "/path/to/output/"
-
You may run the converted model using
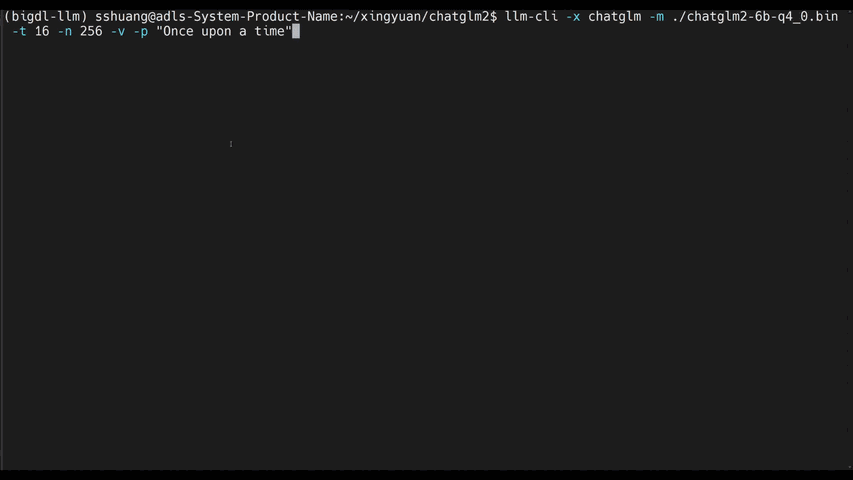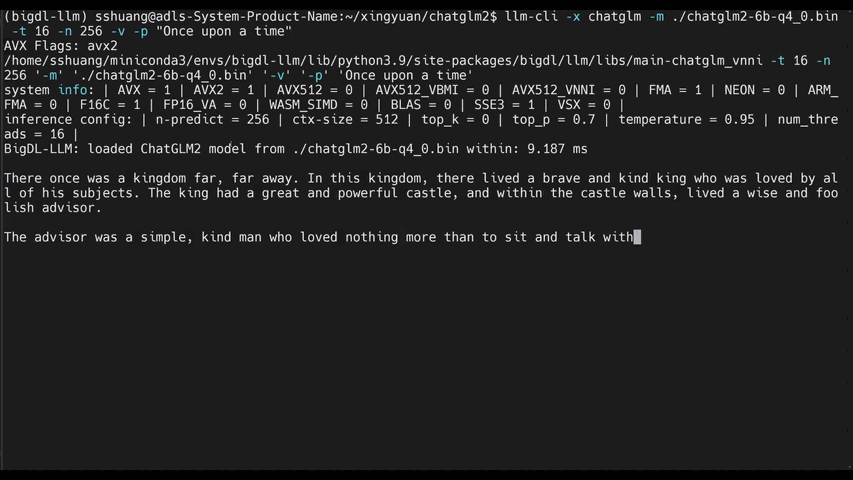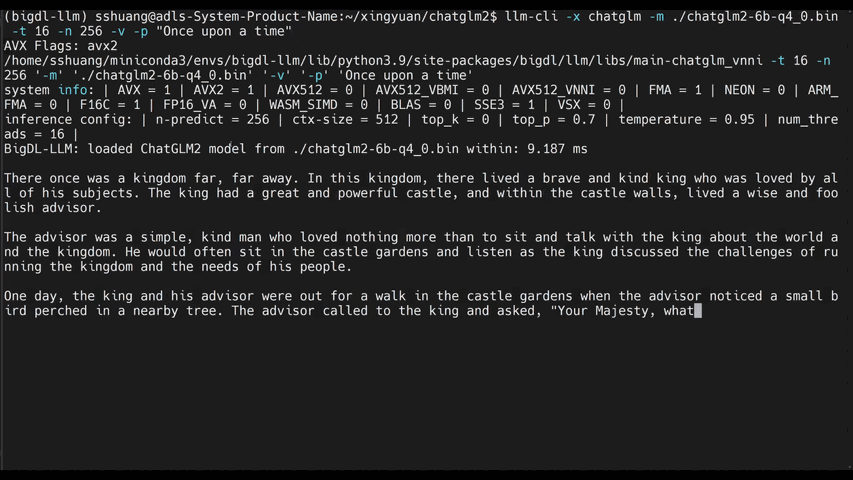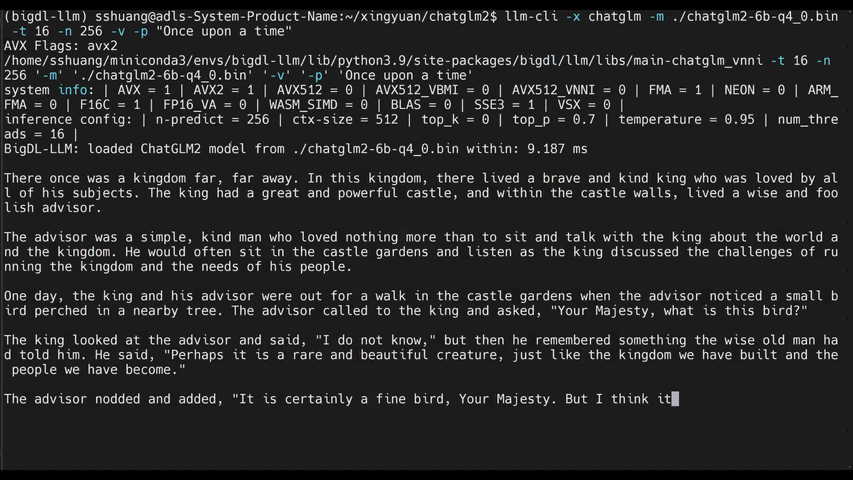
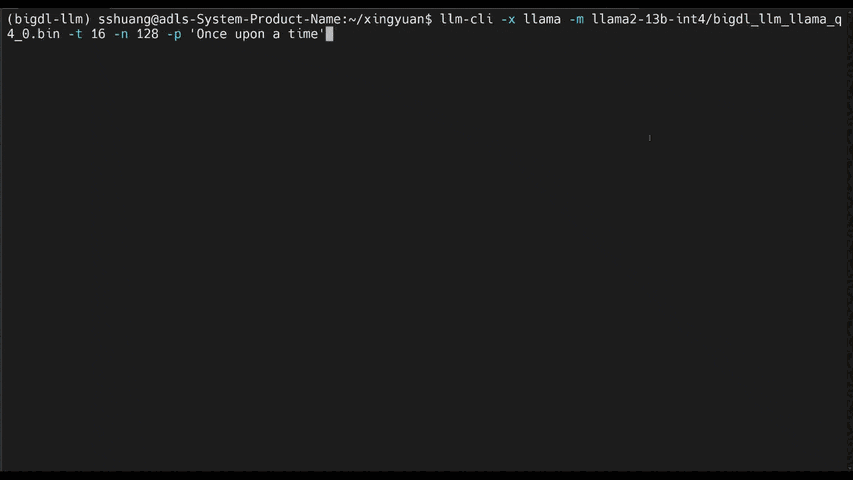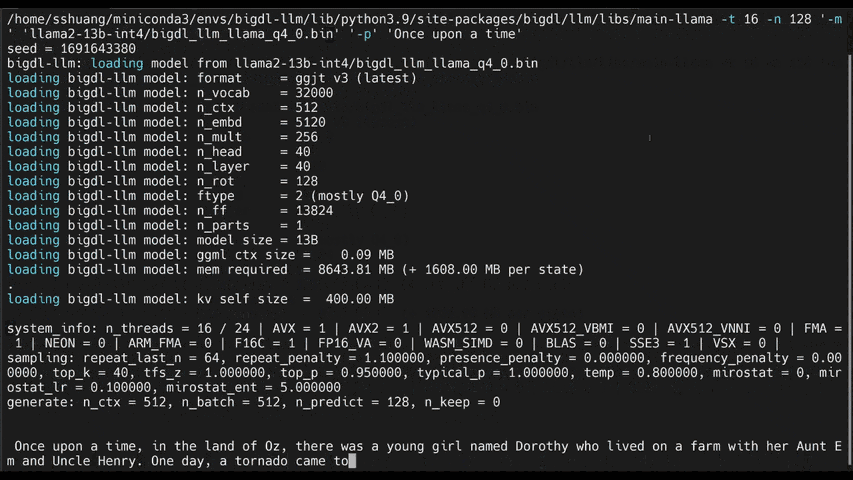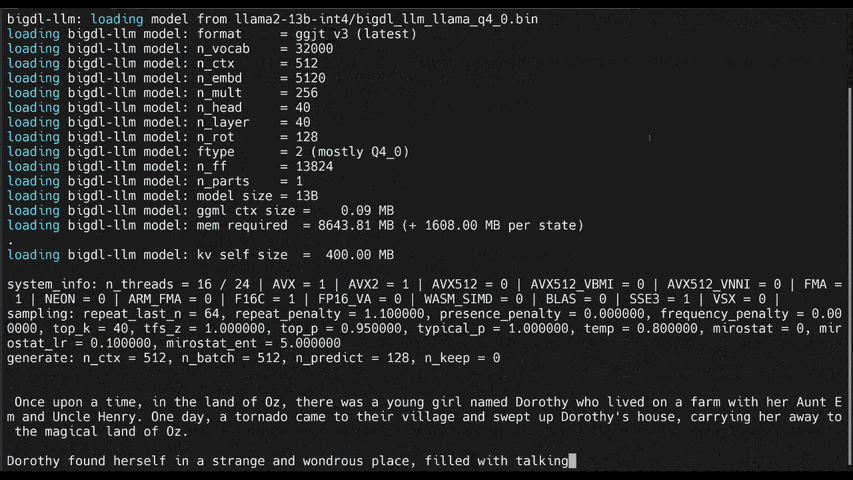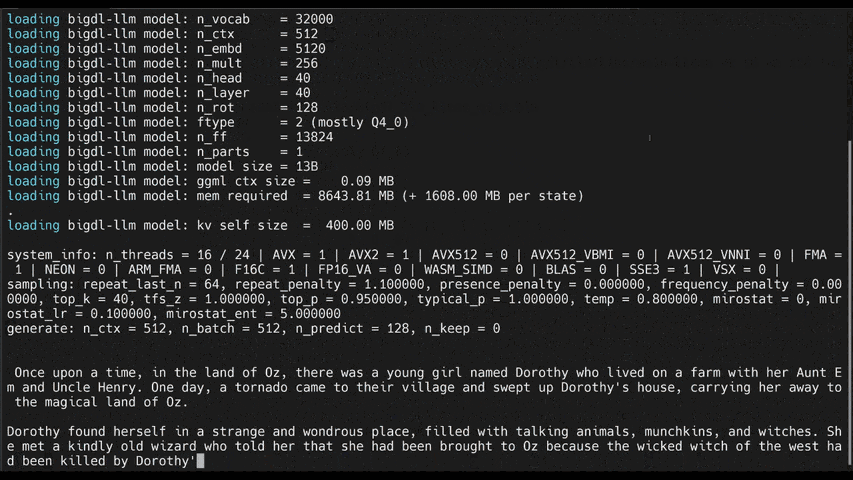
llm-cliorllm-chat(built on top ofmain.cppin llama.cpp)#help #llama/bloom/gptneox/starcoder model family is currently supported llm-cli -x gptneox -h #text completion #llama/bloom/gptneox/starcoder model family is currently supported llm-cli -t 16 -x gptneox -m "/path/to/output/model.bin" -p 'Once upon a time,' #chat mode #llama/gptneox model family is currently supported llm-chat -m "/path/to/output/model.bin" -x llama
See the inital bigdl-llm API Doc here.
The native code/lib in bigdl-llm has been built using the following tools.
Note that lower LIBC version on your Linux system may be incompatible with bigdl-llm.
| Model family | Platform | Compiler | GLIBC |
|---|---|---|---|
| llama | Linux | GCC 11.2.1 | 2.17 |
| llama | Windows | MSVC 19.36.32532.0 | |
| llama | Windows | GCC 13.1.0 | |
| gptneox | Linux | GCC 11.2.1 | 2.17 |
| gptneox | Windows | MSVC 19.36.32532.0 | |
| gptneox | Windows | GCC 13.1.0 | |
| bloom | Linux | GCC 11.2.1 | 2.29 |
| bloom | Windows | MSVC 19.36.32532.0 | |
| bloom | Windows | GCC 13.1.0 | |
| starcoder | Linux | GCC 11.2.1 | 2.29 |
| starcoder | Windows | MSVC 19.36.32532.0 | |
| starcoder | Windows | GCC 13.1.0 |
Footnotes
-
Performance varies by use, configuration and other factors.
bigdl-llmmay not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. ↩