Summary: This is a non-exhaustive list of internal and external pretrained models. Internal pretrained models are stored on Zeonodo.
Table of Contents
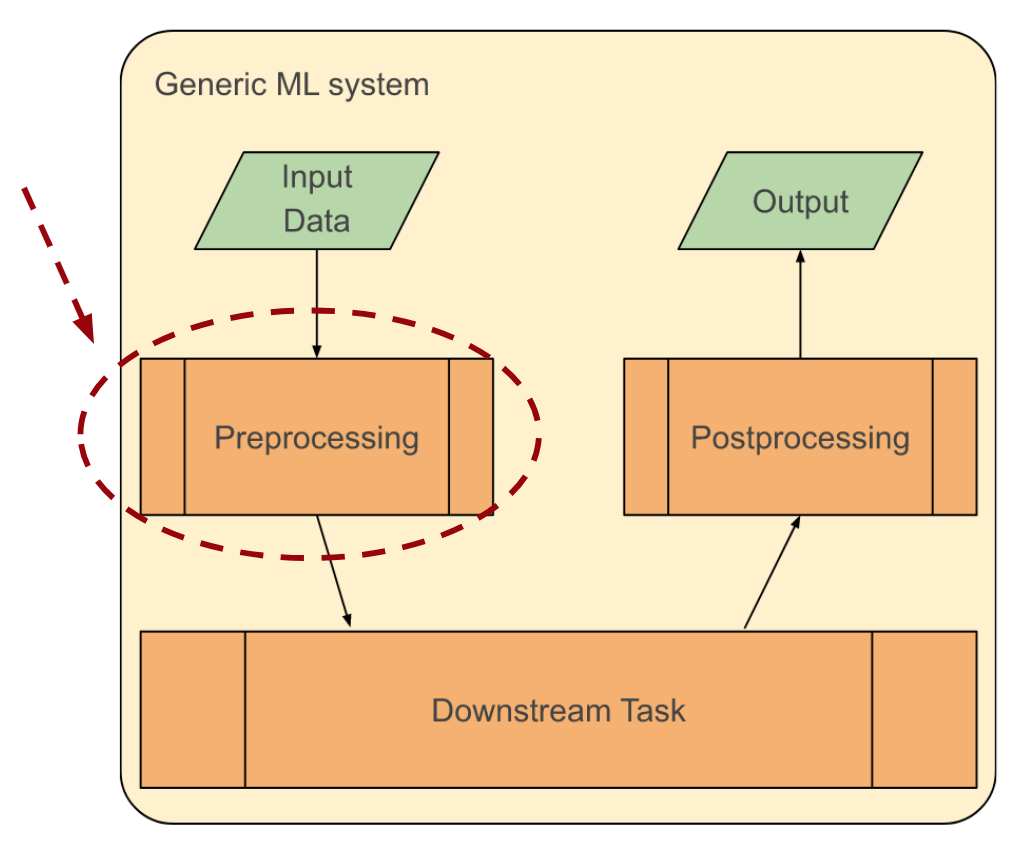
Note: RLMs are typically task-agnostic models which are used at the state of Preprocessing (which is often incorrectly called "pretraining" phase). They are usually trained using Self-Supervised Learning, but Supervised, (narrow-sense) Unsupervised Learning and Reinforcement Learning can also be used. The end goal is to extract dense representations / features / embeddings. This is typically trained at an external dataset (i.e. source dataset) whihch is larger than the one for the Downstream Task (i.e. target dataset).
ViT
- Paper: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Code: https://github.com/google-research/vision_transformer
- Pretrained Model: https://github.com/google-research/vision_transformer
- Released: 2020
- Learning: Supervised
- Architecture: Transformer
BEiT
- Paper: BEiT: BERT Pre-Training of Image Transformers
- Code: https://github.com/microsoft/unilm/tree/master/beit
- Pretrained Model: https://github.com/microsoft/unilm/tree/master/beit
- Released: 2021
- Learning: Self-Supervised
- Architecture: Transformer
DeiT 3
- Paper: DeiT III: Revenge of the ViT
- Code: https://github.com/facebookresearch/deit
- Pretrained Model: https://github.com/facebookresearch/deit
- Released: 2022
- Learning: Self-Supervised
- Architecture: Transformer
BERT
- Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Code: https://github.com/google-research/bert
- Pretrained Model: https://github.com/google-research/bert
- Released: 2018
- Learning: Self-Supervised
- Architecture: Transformer
GPT-J (GPT-3 open-source alternative)
- Paper: Language Models are Few-Shot Learners
- Code: https://github.com/kingoflolz/mesh-transformer-jax
- Pretrained Model: https://github.com/kingoflolz/mesh-transformer-jax
- Released: 2020
- Learning: Self-Supervised
- Architecture: Transformer
HuBERT
- Paper: HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
- Code: https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
- Pretrained model: https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
- Released: 2021
- Learning: Self-Supervised
- Architecture: Transformer
ViLBERT
- Paper: ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
- Code: https://github.com/facebookresearch/vilbert-multi-task
- Pretrained model:
- Released: 2019
- Learning: Self-Supervised
- Architecture: Transformer
- Modalities: images, text
MMFT-BERT
- Paper: MMFT-BERT: Multimodal Fusion Transformer with BERT Encodings for Visual Question Answering
- Code: https://github.com/aurooj/MMFT-BERT
- Pretrained model:
- Released: 2020
- Learning: Self-Supervised
- Architecture: Transformer
- Modalities: images, text
ViLT
- Paper: ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- Code: https://github.com/dandelin/vilt
- Pretrained model: https://github.com/dandelin/vilt
- Released: 2021
- Learning: Self-Supervised
- Architecture: Transformer
- Modalities: images, text
AV-HuBERT
- Paper: Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction
- Code: https://github.com/facebookresearch/av_hubert
- Pretrained model: https://github.com/facebookresearch/av_hubert
- Released: 2022
- Learning: Self-Supervised
- Architecture: Transformer
- Modalities: images, audio
Note: DTMs are typically task-specific models which are used at the Downstream Task. They are usually trained using Supervised Learning, but Self-Supervised, (narrow-sense) Unsupervised Learning and Reinforcement Learning can also be used. The end goal depends on the specific task. The DTMs listed below are only the ones compatible with dense-representation RLMs (e.g. Transformer-based encoders).
