-
+

Partnership with 和碩聯合科技, 長庚紀念醫院, 長春集團, 欣興電子, 律果, NVIDIA, 科技報橘
✍️ Online Demo
•
-🤗 Model Collection • 🐦 Twitter • 📃 Paper
+🤗 Model Collection • 🐦 Twitter/X • 📃 Model Paper • 📃 Eval Paper
• 👨️ Yen-Ting Lin
- ![]()
+
![]() -
- ![]() +
+ ![]()
Partnership with 和碩聯合科技, 長庚紀念醫院, 長春集團, 欣興電子, 律果, NVIDIA, 科技報橘
- 🎉🎉🎉Taiwan-LLM v2: We are excited to release Taiwan-LLM v2, including the 7B and 13B models, now available on twllm.com and on our HuggingFace collection🚀 -
+# 🌟 [Demo Site](https://twllm.com/) +Try out Llama-3-Taiwan interactively at [twllm.com](https://twllm.com/) -## Overview -Taiwan-LLM is a full parameter fine-tuned model based on Meta/LLaMa-2 for Traditional Mandarin applications. +# ⚔️ [Chatbot Arena](https://arena.twllm.com/) -**Taiwan-LLM v2.0 13B** pretrained on over 30 billion tokens and instruction-tuned on over 1 million instruction-following conversations both in traditional mandarin. +Participate in the exciting [Chatbot Arena](https://arena.twllm.com/) and compete against other chatbots! -**Taiwan-LLM v2.0 7B** pretrained on over 30 billion tokens and instruction-tuned on over 1 million instruction-following conversations both in traditional mandarin. +# 🚀 Quick Start for Fine-tuning -**Taiwan-LLM v1.0 13B** pretrained on over 5 billion tokens and instruction-tuned on over 490k conversations both in traditional mandarin. +Using [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for fine-tuning: +```bash +# Run the axolotl docker image +docker run --gpus '"all"' --rm -it winglian/axolotl:main-latest -## Demo -A live demonstration of the model can be accessed at [TWLLM.com](https://twllm.com/). +# Preprocess datasets (optional but recommended) +CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess example_training_config_for_finetuning_twllm.yaml -## Key Features +# Fine-tune +accelerate launch -m axolotl.cli.train example_training_config_for_finetuning_twllm.yaml -1. **Traditional Mandarin Support**: The model is fine-tuned to understand and generate text in Traditional Mandarin, making it suitable for Taiwanese culture and related applications. +``` +Check out the example_training_config_for_finetuning_twllm.yaml file for detailed training configuration and parameters. +For more training framework information, visit [Axolotl's GitHub repository](https://github.com/OpenAccess-AI-Collective/axolotl). -2. **Instruction-Tuned**: Further fine-tuned on conversational data to offer context-aware and instruction-following responses. +-------- -3. **Performance on TC-Eval**: Taiwan-LLM v2 13B shows a slight edge over ChatGPT-3 and achieves around 92% of ChatGPT-4's performance in zh-tw benchmarks. -## Work in progress -- [x] **Improved pretraining**: A refined pretraining process (e.g. more data from Taiwan, training strategies) is under development, aiming to enhance model performance for better Taiwanese culture. -- [x] **Extended Length**: Our demo on twllm.com is served in 8k context length. -- [ ] **3B / 1B model**: In the pipeline are scaled-down versions of the Taiwan-LLM with 3 billion and 1 billion parameters, aimed at providing more accessible options for researchers and developers with limited computational resources. -- [ ] **Vision**: We are exploring multi-modal integration into Taiwan-LLM, enabling the model to understand content that combines text and image. -- [ ] **Mixture of Experts**: Planning to incorporate a Mixture of Experts architecture to improve the model's efficiency and capacity. +🚀 We're excited to introduce Llama-3-Taiwan-70B! Llama-3-Taiwan-70B is a 70B parameter model finetuned on a large corpus of Traditional Mandarin and English data using the Llama-3 architecture. It demonstrates state-of-the-art performance on various Traditional Mandarin NLP benchmarks. +The model was trained with [NVIDIA NeMo™ Framework](https://www.nvidia.com/en-us/ai-data-science/generative-ai/nemo-framework/) using the NVIDIA Taipei-1 built with [NVIDIA DGX H100](https://www.nvidia.com/en-us/data-center/dgx-h100/) systems. -## Taiwanese Culture Examples +The compute and data for training Llama-3-Taiwan-70B was generously sponsored by [Chang Gung Memorial Hospital](https://www.cgmh.org.tw/eng), [Chang Chun Group](https://www.ccp.com.tw/ccpweb.nsf/homepage?openagent), [Legalsign.ai](https://legalsign.ai/), [NVIDIA](https://www.nvidia.com/zh-tw/), [Pegatron](https://www.pegatroncorp.com/), [TechOrange](https://buzzorange.com/techorange/), and [Unimicron](https://www.unimicron.com/) (in alphabetical order). -| Question | ChatGPT | **Taiwan LLaMa v1.0** | **Taiwan LLaMa v0.0 (w/o pretraining)** | Llama2_Traditional_Chinese_13b_Chat | -|:-|:-|:-|:-|:-| -| 以惡地景觀著名的是高雄哪一個景點? | 以惡地地景著名的是高雄市的旗津。 | 高雄以擁有惡地景觀著名的景點是田寮月世界。✅ | 以惡地景觀著名的是高雄市的旗津島。旗津島是一個小島,... | 高雄市內有多個以惡地景觀著名的景點,其中以下面幾個最為著名: 1. 高雄捷運紅線沿途景點:高雄市政府為了推廣高雄 | -| 唐鳳是誰? | 唐鳳(Audrey Tang)是台灣的政治家、社會活動家和軟體工程師。她於2016年擔任台灣行政院數位政務委員,是台灣政府歷史上首位沒有政黨背景的政務官。唐鳳在軟體工程領域有豐富的經驗。 ✅ | 唐鳳是政治評論家、資訊社會學研究者,也是台灣第一位擔任政府數位政委的人。 ✅ | 唐鳳(Tang Feng)是一位著名的中國演員和歌手。他出生於1974年12月17日,出生地點在中國北京。唐鳳在1995年開始他的演藝生涯,並在同年發行了他的首張專輯《我不孤單》。此後,他發行了許多受歡迎的歌曲,並在多部電視劇和電影中擔任主角。唐鳳因其精湛的演技和迷人的歌聲而被譽為“亞洲魅力男王”。他的音樂獲得了多個獎項,包括“華表最佳新男演唱獎”、“華表最佳歌曲獎”和“華表最佳舞蹈獎”等。 | 唐鳳是唐朝時期的一位著名文學家,他的代表作品包括《陰騭》、《狂凡子》等。他的文學風格具有強烈的個性和創意,被譽為「唐代文學之父」。 | -| NTU 在哪? | NTU位於新加坡,具體地址是50 Nanyang Avenue, Singapore 639798。 | NTU 是國立臺灣大學的縮寫。它是臺灣的一所頂尖研究型大學,位於臺北市。 ✅| NTU 是台灣的一所大學,位於台北市。✅ | NTU 的總部位於台灣新北市板橋區,佔地面積約為1,000公頃。| -| 甚麼是22K? | "22K" 可能指的是金的純度,尤其是在珠寶和金飾方面。 | "22K"是指台灣的大學畢業生的起薪,大約是新台幣22,000元。這個詞被用來形容大學畢業生的起薪偏低,並且在就業市場上對於大學畢業生的需求不足。✅| 22K是指溫度尺度上的22,000K(千度)。1K代表一度,即溫度差距,是攝氏溫標(攝氏度)的一百萬分之一。因此,22K等於-253.15°C(攝氏溫標)或-423.67°F(華氏溫標)。 | 22K是一種簡寫,即22,000。它是一個數字,表示22,000個單位。| -| 肉圓要不要加香菜? | 這是個個人口味的問題,有些人喜歡在肉圓中加入香菜,因為香菜的清香可以增添風味;而有些人則不喜歡香菜的味道,覺得它會蓋過其他食材的味道。所以要不要加香菜,可以根據個人喜好來決定。 | 這是一個個人喜好的問題,有些人喜歡在肉圓裡加香菜,有些人不喜歡。**在台灣**,肉圓加香菜是一種常見的做法,這是一種在肉圓上加香菜的做法。然而,在其他國這是一個文化差異的問題。😊 | 肉圓加香菜可以增添一些芳香和美味的口感,如果你喜歡香菜的味道,可以試試加入肉圓中。香菜通常在製作過程中炒香,可以增添一些芳香和美味的味道。如果你想要加入香菜,可以在製作過程中炒香一些香菜,然後將其混入肉圓中。肉圓加香菜可以增添一些芳香和美味的口感,如果你喜歡香菜的味道,可以試試加入肉圓中。| 加香菜的肉圓味道更好,但是不加香菜的肉圓也很好吃。如果你喜歡香菜的味道,那麼加上香菜就好了。如果你不喜歡香菜,那麼不加也不會影響肉 | +We would like to acknowledge the [contributions](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct#contributions) of our data provider, team members and advisors in the development of this model, including [shasha77](https://www.youtube.com/@shasha77) for high-quality YouTube scripts and study materials, [Taiwan AI Labs](https://ailabs.tw/) for providing local media content, [Ubitus K.K.](https://ubitus.net/zh/) for offering gaming content, Professor Yun-Nung (Vivian) Chen for her guidance and advisement, Wei-Lin Chen for leading our pretraining data pipeline, Tzu-Han Lin for synthetic data generation, Chang-Sheng Kao for enhancing our synthetic data quality, and Kang-Chieh Chen for cleaning instruction-following data. -## Model +# Model Summary -We provide a number of model checkpoints that we trained. Please find them on Hugging Face [here](https://huggingface.co/collections/yentinglin/taiwan-llm-6523f5a2d6ca498dc3810f07). Here are some quick links to the checkpoints that are finetuned from LLaMa 2: +Llama-3-Taiwan-70B is a large language model finetuned for Traditional Mandarin and English users. It has strong capabilities in language understanding, generation, reasoning, and multi-turn dialogue. Key features include: -| **Model** | **13B** | -|--------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------| -| **Taiwan-LLaMa v2.0 13B** (_better for Taiwanese Culture_) | 🤗 yentinglin/Taiwan-LLM-13B-v2.0-chat | -| **Taiwan-LLaMa v2.0 7B** (_better for Taiwanese Culture_) | 🤗 yentinglin/Taiwan-LLM-7B-v2.0.1-chat | -| Taiwan-LLaMa v1.0 13B | 🤗 yentinglin/Taiwan-LLaMa-v1.0 | +- 70B parameters +- Languages: Traditional Mandarin (zh-tw), English (en) +- Finetuned on High-quality Traditional Mandarin and English corpus covering general knowledge as well as industrial knowledge in legal, manufacturing, medical, and electronics domains +- 8K context length +- Open model released under the Llama-3 license -## Data +# Training Details -| **Dataset** | **Link** | -|---------------------------------|-------------------------------------------------------------------------------------------------------------------------------| -| **Instruction-tuning** | 🤗 yentinglin/traditional_mandarin_instructions | +- Training Framework: [NVIDIA NeMo](https://www.nvidia.com/zh-tw/ai-data-science/products/nemo/), [NVIDIA NeMo Megatron](https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/nlp/megatron.html) +- Inference Framework: [NVIDIA TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM) +- Base model: [Llama-3 70B](https://llama.meta.com/llama3/) +- Hardware: [NVIDIA DGX H100](https://www.nvidia.com/zh-tw/data-center/dgx-h100/) on Taipei-1 +- Context length: 8K tokens ([128k version](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-128k)) +- Batch size: 2M tokens per step -## Architecture -Taiwan-LLaMa is based on LLaMa 2, leveraging transformer architecture, flash attention 2, and bfloat16. +# Evaluation -It includes: +Checkout [Open TW LLM Leaderboard](https://huggingface.co/spaces/yentinglin/open-tw-llm-leaderboard) for full and updated list. -* Pretraining Phase: Pretrained on a vast corpus of over 5 billion tokens, extracted from common crawl in Traditional Mandarin. -* Fine-tuning Phase: Further instruction-tuned on over 490k multi-turn conversational data to enable more instruction-following and context-aware responses. +| Model | [TMLU](https://arxiv.org/pdf/2403.20180) | Taiwan Truthful QA | [Legal Eval](https://huggingface.co/datasets/lianghsun/tw-legal-benchmark-v1) | [TW MT-Bench](https://huggingface.co/datasets/MediaTek-Research/TCEval-v2) | Long context | Function Calling | [TMMLU+](https://github.com/iKala/ievals) | +|---------------------------------------------------------------------------------|--------------|---------------|--------------------|--------------|--------------|-----------------|-----------| +| | 學科知識 | 台灣在地化測試 | 台灣法律考題 | 中文多輪對答 | 長文本支援 | 函數呼叫 | | +| [**yentinglin/Llama-3-Taiwan-70B-Instruct**](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct) | **74.76%** | 80.95% | 68.42% | 7.54 | [128k version](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-128k) | ✅ | 67.53% | +| [**yentinglin/Llama-3-Taiwan-70B-Instruct-DPO**](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-DPO) | 74.60% | **81.75%** | **70.33%** | - | - | ✅ | - | +| [**yentinglin/Llama-3-Taiwan-70B-Instruct-128k**](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct) | 73.01% | 80.16% | 63.64% | - | - | ✅ | - | +| [**yentinglin/Llama-3-Taiwan-8B-Instruct**](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct) | 59.50% | 61.11% | 53.11% | 7.21 | [128k version](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct-128k) | ✅ | 52.28% | +| [**yentinglin/Llama-3-Taiwan-8B-Instruct-DPO**](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct-DPO) | 59.88% | 59.52% | 52.63% | - | - | ✅ | - | +| [**yentinglin/Llama-3-Taiwan-8B-Instruct-128k**](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct-128k) | - | - | - | - | - | ✅ | - | +| [Claude-3-Opus](https://www.anthropic.com/api) | [73.59% (5-shot)](https://arxiv.org/pdf/2403.20180) | [69.84%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/opus-Taiwan-Truthful-QA) | [60.29%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/opus) | - | 200k | ✅ | - | +| [GPT4-o](https://platform.openai.com/docs/api-reference/chat/create) | [65.56% (0-shot), 69.88% (5-shot)](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/4o-tmlu) | [76.98%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/4o-Taiwan-Truthful-QA) | [53.59%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/4o) | - | 128k | ✅ | - | +| [GPT4-turbo](https://platform.openai.com/docs/api-reference/chat/create) | [70.42% (5-shot)](https://arxiv.org/pdf/2403.20180) | - | - | - | 128k | ✅ | 60.34%^ | +| [Gemini-Pro](https://ai.google.dev/gemini-api/docs) | [61.40% (5-shot)](https://arxiv.org/pdf/2403.20180) | - | - | - | 1000k | ✅ | 49.92%^ | +| [GPT-3.5-turbo-1106](https://platform.openai.com/docs/api-reference/chat/create) | [49.37% (5-shot)](https://arxiv.org/pdf/2403.20180) | - | - | 7.1 | 128k | ✅ | 41.76%^ | +| [Qwen1.5-110B-Chat](https://huggingface.co/Qwen/Qwen1.5-110B-Chat) | **75.69%** | 66.67% | 49.28% | - | 32k | ✅ | 65.81% | +| [Yi-34B-Chat](https://huggingface.co/01-ai/Yi-34B-Chat) | 73.59% | 71.43% | 55.02% | 6.9 | 200k | ✅ | 64.10% | +| [Meta-Llama-3-70B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct) | 70.95% | 65.08% | 52.63% | - | 8k | ✅ | 62.75% | +| [Mixtral-8x22B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1) | 55.57% | 52.38% | 44.98% | - | 64k | ✅ | 52.16% | +| [Breexe-8x7B-Instruct-v0_1](https://huggingface.co/MediaTek-Research/Breexe-8x7B-Instruct-v0_1) | - | - | - | 7.2 | 8k | ❓ | 48.92% | +| [c4ai-command-r-plus](https://huggingface.co/CohereForAI/c4ai-command-r-plus) | 62.87% | 64.29% | 34.45% | - | 128k | ✅ | 49.75% | +| [Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) | 55.81% | 46.83% | 35.89% | - | 8k | ✅ | 43.38% | +| [Breeze-7B-Instruct-v1_0](https://huggingface.co/MediaTek-Research/Breeze-7B-Instruct-v1_0) | 55.57% | 52.38% | 39.23% | 6.0 | 32k | ❓ | 41.77% | +| [Llama3-TAIDE-LX-8B-Chat-Alpha1](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1) | 47.30% | 50.79% | 37.80% | - | 8k | ❓ | 39.03% | +| [Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) | 40.97% | 37.30% | 27.27% | - | 4k | ❓ | 33.02% | -## Evaluating "Taiwan LLM" on TC-Eval -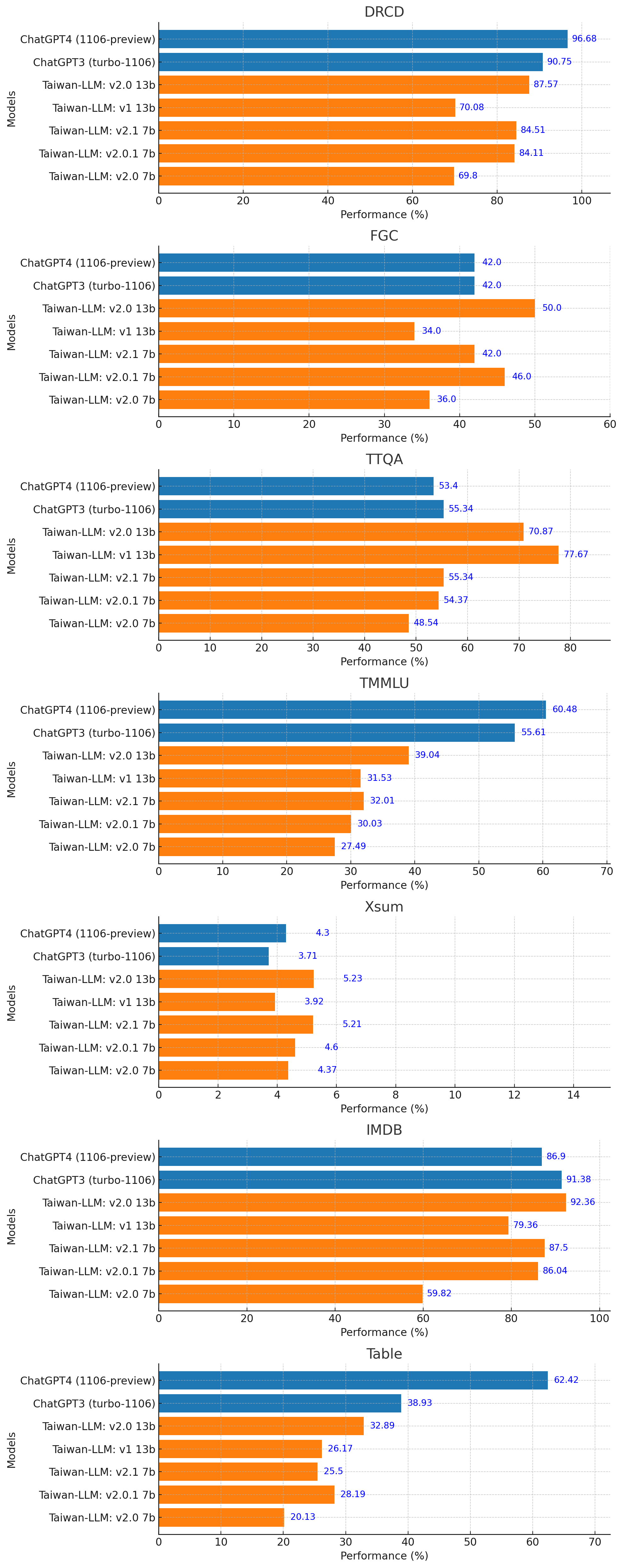 +Numbers are 0-shot by default. +[Eval implementation](https://github.com/adamlin120/lm-evaluation-harness) -## How to deploy the model on my own machine? +^ taken the closet matching numbers from original dataset. -### Text Generation Inference -We recommend hosting models with [🤗 Text Generation Inference](https://github.com/huggingface/text-generation-inference). Please see their [license](https://github.com/huggingface/text-generation-inference/blob/main/LICENSE) for details on usage and limitations. -```bash -bash run_text_generation_inference.sh "yentinglin/Taiwan-LLaMa-v1.0" NUM_GPUS DIR_TO_SAVE_MODEL PORT MAX_INPUT_LEN MODEL_MAX_LEN -``` +## Needle in a Haystack Evaluation -Taiwan LLm Prompt Template: +The "Needle in a 出師表" evaluation tests the model's ability to locate and recall important information embedded within a large body of text, using the classic Chinese text 《出師表》 by 諸葛亮. -**How to properly format my prompt?** -```python -from transformers import AutoTokenizer -# system message is optional -chat = [ - # {"role": "system", "content": "你講中文"}, - {"role": "user", "content": "Hello, how are you?"}, - {"role": "assistant", "content": "I'm doing great. How can I help you today?"}, - {"role": "user", "content": "I'd like to show off how chat templating works!"}, -] -# This applies to all Taiwan-LLM series. -tokenizer = AutoTokenizer.from_pretrained("yentinglin/Taiwan-LLM-7B-v2.0.1-chat") -prompt_for_generation = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True) -print(prompt_for_generation) -``` +To run the evaluation, use the [script](https://github.com/adamlin120/needle-haystack/tree/main). -Version 2 is more robust to different system prompt or none. -``` -你是人工智慧助理,以下是用戶和人工智能助理之間的對話。你要對用戶的問題提供有用、安全、詳細和禮貌的回答。USER: {user} ASSISTANT: -``` +# TW MT-Bench Score -Taiwan LLm v1 Prompt Template: -``` -A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {user} ASSISTANT: -``` +- Average Score: 7.5375 +- Maximum Score: 10 +- Minimum Score: 1 +- Median Score: 9.0 +- Standard Deviation: 3.0349783771882133 +- Total Number of Scores: 160 +- [Model resopnse](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc1/blob/main/Llama-3-Taiwan.jsonl) +- [GPT-4 Eval](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc1/blob/main/gpt-4_single.jsonl) +- [Code fork from `mtkresearch/TCEval` with bug fixing](https://github.com/adamlin120/TCEval) -### Ollama -[Ollama](https://github.com/ollama/ollama) is a local inference framework client for deploying large language models such as Llama 2, Mistral, Llava, etc. with one click. Now we support you to run [Taiwan-LLM-13B-v2.0-chat](https://ollama.com/wangrongsheng/taiwanllm-13b-v2.0-chat) (**INT4 quantization**) and [Taiwan-LLM-7B-v2.1-chat](https://ollama.com/wangrongsheng/taiwanllm-7b-v2.1-chat) (**INT4 quantization**) on Ollama. You can run Taiwan-LLM in a simple way on your local computer. +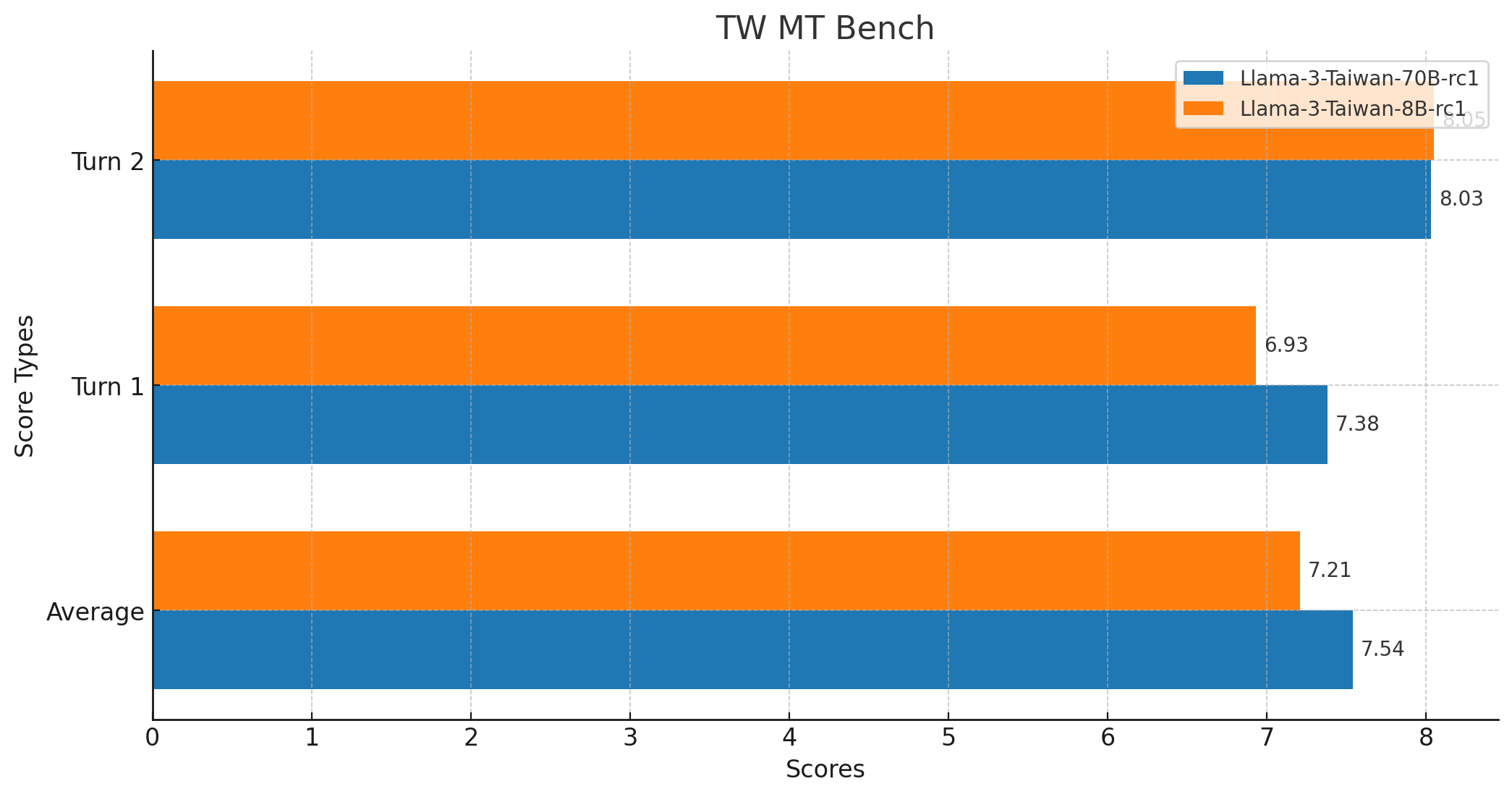 -1. Install Ollama. - 1. If you use `macOS`, you can download [it](https://ollama.com/download/Ollama-darwin.zip). - 2. If you use `Windows10`, you can download [it](https://ollama.com/download/OllamaSetup.exe). - 3. If you use `Linux`, you can use the following command to install. -```sh -curl -fsSL https://ollama.com/install.sh | sh -``` -2. Download and Run Taiwan-LLM -```sh -# Download Taiwan-LLM-7B-v2.1-chat -ollama run wangrongsheng/taiwanllm-7b-v2.1-chat - -# or -# Download Taiwan-LLM-13B-v2.0-chat -ollama run wangrongsheng/taiwanllm-13b-v2.0-chat -``` - +# Use Cases -## Setup development environment -```bash -conda create -n taiwan-llama python=3.10 -y -conda activate taiwan-llama -pip install -r requirements.txt -``` +Llama-3-Taiwan-70B can be applied to a wide variety of NLP tasks in Traditional Chinese and English, including: -## 常見問題 ++System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project. -可以參考這個 [#19 (comment)](https://github.com/MiuLab/Taiwan-LLaMa/issues/19#issuecomment-1687281286)。 +User: 嗨,你好! -### 能否商用化? +Assistant: 你好!我今天可以如何協助你? -關於模型能不能商用,我建議您自行尋求法律意見。 +User: 就想聊天而已.... -模型作者 (Meta 與我) 都願意開放商用,但是『可以商用的模型”訓練在“有著作權法保護的資料上”,是否可以商用』需要您的判斷。 +Assistant: 當然,我很樂意和你聊天!有什麼特別想談論的嗎? +-台灣沒有相關法案保護模型訓練在有著作權的資料上,但就我的理解,我們模型雖訓練在著作權資料上,但並沒有抄襲著作權人的意思表示,所以模型是可以商用的。 +
+System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project. -For questions on commercial use, consult legal advice. +User: 明天台大天氣如何? -Both the model authors (Meta and I) are open to commercial use. However, whether a "commercially usable model" trained on "copyrighted data" can be used commercially is for you to decide. +Assistant: 根據天氣預報,明天台大天氣為陣雨。低溫 24°C。10 到 15 公里/小時 的 東 風 。降雨機率為 40%。 +-To my understanding, although the model is trained on copyrighted data, it does not plagiarize. Therefore, it can be commercialized. +
+System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project. + +User: 您是電影評論分析師,負責情緒分析。 +分析每個被評論的句子,評估句子中每個字和標點符號的重要性, +並且將結果使用 tuple 的結構列出。 +tuple 值的範圍介於 -1 (負向) 到 1 (正向) 之間, +然後,將評論分類為正向 (1) 或負向 (-1)。 +這些需要被評論的句子,包含在+標籤中間。 + +輸出範例: +[(<單字或標點符號>, ), ...] + + 根據外媒報導,宏都拉斯在去年3月與台灣斷交,並轉往與中國建交之後,卻遲遲等不到中國的金援,談好要進口宏都拉斯的白蝦也拖延許久,甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。 + + +Assistant: [('根據', 0.2), ('外媒', 0.1), ('報導', -0.1), (',', 0.05), ('宏都拉斯', -0.3), ('在去年3月與台灣斷交, ', -0.5), ('並轉往與中國建交之後, ', -0.4), ('卻遲遲等不到中國的金援, ', -1), +('談好要進口宏都拉斯的白蝦也拖延許久, ', -1), +(',甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。 ',-1)] +-1 + +