 +
+  +
+ 


 +
+# Usage
+
+```js
+import * as det from '@paddle-js-models/detect';
+
+// Load model
+await det.load();
+
+// Get label index, confidence and coordinates
+const res = await det.detect(img);
+
+res.forEach(item => {
+ // Get label index
+ console.log(item[0]);
+ // Get label confidence
+ console.log(item[1]);
+ // Get label left coordinates
+ console.log(item[2]);
+ // Get label top coordinates
+ console.log(item[3]);
+ // Get label right coordinates
+ console.log(item[4]);
+ // Get label bottom coordinates
+ console.log(item[5]);
+});
+```
+
+# effect
+
+
diff --git a/examples/application/js/package/packages/paddlejs-models/detect/README_cn.md b/examples/application/js/package/packages/paddlejs-models/detect/README_cn.md
new file mode 100644
index 0000000000..0a27988779
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/detect/README_cn.md
@@ -0,0 +1,38 @@
+[English](./README.md)
+
+# detect
+
+detect模型用于检测图像中label框选位置。
+
+
+
+# 使用
+
+```js
+import * as det from '@paddle-js-models/detect';
+
+// 模型加载
+await det.load();
+
+// 获取label对应索引、置信度、检测框选坐标
+const res = await det.detect(img);
+
+res.forEach(item => {
+ // 获取label对应索引
+ console.log(item[0]);
+ // 获取label置信度
+ console.log(item[1]);
+ // 获取检测框选left顶点
+ console.log(item[2]);
+ // 获取检测框选top顶点
+ console.log(item[3]);
+ // 获取检测框选right顶点
+ console.log(item[4]);
+ // 获取检测框选bottom顶点
+ console.log(item[5]);
+});
+```
+
+# 效果
+
+
diff --git a/examples/application/js/package/packages/paddlejs-models/facedetect/README.md b/examples/application/js/package/packages/paddlejs-models/facedetect/README.md
new file mode 100644
index 0000000000..411cb782ae
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/facedetect/README.md
@@ -0,0 +1,38 @@
+[中文版](./README_cn.md)
+
+# Facedetect
+
+Facedetect is used for face detection in image. It provides a simple interface. At the same time, you can use your own model.
+
+
+
+# Usage
+
+```js
+import * as det from '@paddle-js-models/detect';
+
+// Load model
+await det.load();
+
+// Get label index, confidence and coordinates
+const res = await det.detect(img);
+
+res.forEach(item => {
+ // Get label index
+ console.log(item[0]);
+ // Get label confidence
+ console.log(item[1]);
+ // Get label left coordinates
+ console.log(item[2]);
+ // Get label top coordinates
+ console.log(item[3]);
+ // Get label right coordinates
+ console.log(item[4]);
+ // Get label bottom coordinates
+ console.log(item[5]);
+});
+```
+
+# effect
+
+
diff --git a/examples/application/js/package/packages/paddlejs-models/detect/README_cn.md b/examples/application/js/package/packages/paddlejs-models/detect/README_cn.md
new file mode 100644
index 0000000000..0a27988779
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/detect/README_cn.md
@@ -0,0 +1,38 @@
+[English](./README.md)
+
+# detect
+
+detect模型用于检测图像中label框选位置。
+
+
+
+# 使用
+
+```js
+import * as det from '@paddle-js-models/detect';
+
+// 模型加载
+await det.load();
+
+// 获取label对应索引、置信度、检测框选坐标
+const res = await det.detect(img);
+
+res.forEach(item => {
+ // 获取label对应索引
+ console.log(item[0]);
+ // 获取label置信度
+ console.log(item[1]);
+ // 获取检测框选left顶点
+ console.log(item[2]);
+ // 获取检测框选top顶点
+ console.log(item[3]);
+ // 获取检测框选right顶点
+ console.log(item[4]);
+ // 获取检测框选bottom顶点
+ console.log(item[5]);
+});
+```
+
+# 效果
+
+
diff --git a/examples/application/js/package/packages/paddlejs-models/facedetect/README.md b/examples/application/js/package/packages/paddlejs-models/facedetect/README.md
new file mode 100644
index 0000000000..411cb782ae
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/facedetect/README.md
@@ -0,0 +1,38 @@
+[中文版](./README_cn.md)
+
+# Facedetect
+
+Facedetect is used for face detection in image. It provides a simple interface. At the same time, you can use your own model.
+
+


 +
+# Usage
+
+```js
+import { FaceDetector } from '@paddle-js-models/facedetect';
+
+const faceDetector = new FaceDetector();
+await faceDetector.init();
+// Required parameter:imgEle(HTMLImageElement)
+// Optional parameter: shrink, threshold
+// Result is face area information. It includes left, top, width, height, confidence
+const res = await faceDetector.detect(
+ imgEle,
+ { shrink: 0.4, threshold: 0.6 }
+);
+```
+
+# Performance
++ **multi small-sized face**
+
+
+# Usage
+
+```js
+import { FaceDetector } from '@paddle-js-models/facedetect';
+
+const faceDetector = new FaceDetector();
+await faceDetector.init();
+// Required parameter:imgEle(HTMLImageElement)
+// Optional parameter: shrink, threshold
+// Result is face area information. It includes left, top, width, height, confidence
+const res = await faceDetector.detect(
+ imgEle,
+ { shrink: 0.4, threshold: 0.6 }
+);
+```
+
+# Performance
++ **multi small-sized face**
+  +
++ **single big-sized face**
+
+
++ **single big-sized face**
+  +
+# Postprocess
+This model has a better recognition effect for small-sized faces, and the image will be shrink before prediction, so it is necessary to transform the prediction output data.
+
+
+# Postprocess
+This model has a better recognition effect for small-sized faces, and the image will be shrink before prediction, so it is necessary to transform the prediction output data.
+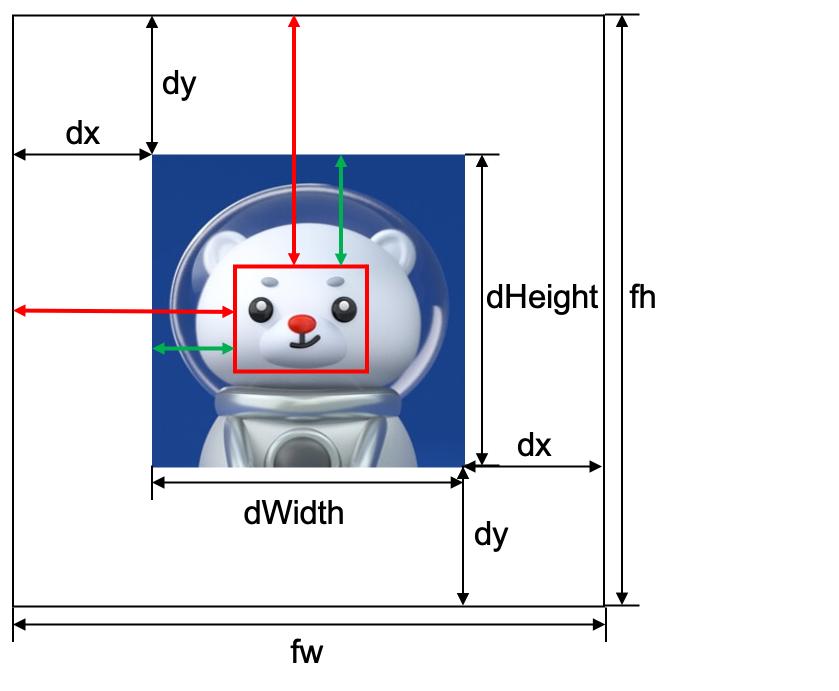 +The red line indicates the predicted output result, and the green line indicates the converted result. dx dy fw fh are known parameters.
+
+# Reference
+[original model link](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.2/modules/image/face_detection/pyramidbox_lite_mobile)
diff --git a/examples/application/js/package/packages/paddlejs-models/facedetect/README_cn.md b/examples/application/js/package/packages/paddlejs-models/facedetect/README_cn.md
new file mode 100644
index 0000000000..6867152f8b
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/facedetect/README_cn.md
@@ -0,0 +1,37 @@
+[English](./README.md)
+
+# Facedetect
+
+Facedetect 实现图像中的人脸检测,提供的接口简单,支持用户传入模型。
+
+
+
+# 使用
+
+```js
+import { FaceDetector } from '@paddle-js-models/facedetect';
+
+const faceDetector = new FaceDetector();
+await faceDetector.init();
+// 使用时必传图像元素(HTMLImageElement),支持指定图片缩小比例(shrink)、置信阈值(threshold)
+// 结果为人脸区域信息,包括:左侧 left,上部 top,区域宽 width,区域高 height,置信度 confidence
+const res = await faceDetector.detect(
+ imgEle,
+ { shrink: 0.4, threshold: 0.6 }
+);
+```
+
+# 效果
++ **多个小尺寸人脸**
+
+
++ **单个大尺寸人脸**
+
+
+# 数据后处理
+此人脸检测模型对小尺寸人脸具有更好的识别效果,图像在预测前会进行缩小,因此需要对预测输出数据进行变换,及为**数据后处理过程**。示意如下:
+
+红线标识的是预测输出结果,绿线标识的是经过转换后的结果,二者变换过程所涉及到的 dx dy fw fh均为已知量。
+
+# 参考
+[源模型链接](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.2/modules/image/face_detection/pyramidbox_lite_mobile)
diff --git a/examples/application/js/package/packages/paddlejs-models/humanseg/README.md b/examples/application/js/package/packages/paddlejs-models/humanseg/README.md
new file mode 100644
index 0000000000..2c8bae8171
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/humanseg/README.md
@@ -0,0 +1,93 @@
+[中文版](./README_cn.md)
+
+# humanseg
+
+A real-time human-segmentation model. You can use it to change background. The output of the model is gray value. Model supplies simple api for users.
+
+Api drawHumanSeg can draw human segmentation with a specified background.
+Api blurBackground can draw human segmentation with a blurred origin background.
+Api drawMask can draw the background without human.
+
+
+
+The red line indicates the predicted output result, and the green line indicates the converted result. dx dy fw fh are known parameters.
+
+# Reference
+[original model link](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.2/modules/image/face_detection/pyramidbox_lite_mobile)
diff --git a/examples/application/js/package/packages/paddlejs-models/facedetect/README_cn.md b/examples/application/js/package/packages/paddlejs-models/facedetect/README_cn.md
new file mode 100644
index 0000000000..6867152f8b
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/facedetect/README_cn.md
@@ -0,0 +1,37 @@
+[English](./README.md)
+
+# Facedetect
+
+Facedetect 实现图像中的人脸检测,提供的接口简单,支持用户传入模型。
+
+
+
+# 使用
+
+```js
+import { FaceDetector } from '@paddle-js-models/facedetect';
+
+const faceDetector = new FaceDetector();
+await faceDetector.init();
+// 使用时必传图像元素(HTMLImageElement),支持指定图片缩小比例(shrink)、置信阈值(threshold)
+// 结果为人脸区域信息,包括:左侧 left,上部 top,区域宽 width,区域高 height,置信度 confidence
+const res = await faceDetector.detect(
+ imgEle,
+ { shrink: 0.4, threshold: 0.6 }
+);
+```
+
+# 效果
++ **多个小尺寸人脸**
+
+
++ **单个大尺寸人脸**
+
+
+# 数据后处理
+此人脸检测模型对小尺寸人脸具有更好的识别效果,图像在预测前会进行缩小,因此需要对预测输出数据进行变换,及为**数据后处理过程**。示意如下:
+
+红线标识的是预测输出结果,绿线标识的是经过转换后的结果,二者变换过程所涉及到的 dx dy fw fh均为已知量。
+
+# 参考
+[源模型链接](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.2/modules/image/face_detection/pyramidbox_lite_mobile)
diff --git a/examples/application/js/package/packages/paddlejs-models/humanseg/README.md b/examples/application/js/package/packages/paddlejs-models/humanseg/README.md
new file mode 100644
index 0000000000..2c8bae8171
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/humanseg/README.md
@@ -0,0 +1,93 @@
+[中文版](./README_cn.md)
+
+# humanseg
+
+A real-time human-segmentation model. You can use it to change background. The output of the model is gray value. Model supplies simple api for users.
+
+Api drawHumanSeg can draw human segmentation with a specified background.
+Api blurBackground can draw human segmentation with a blurred origin background.
+Api drawMask can draw the background without human.
+
+
+


 +
+# Usage
+
+```js
+
+import * as humanseg from '@paddle-js-models/humanseg';
+
+// load humanseg model, use 398x224 shape model, and preheat
+await humanseg.load();
+
+// use 288x160 shape model, preheat and predict faster with a little loss of precision
+// await humanseg.load(true, true);
+
+// get the gray value [2, 398, 224] or [2, 288, 160];
+const { data } = await humanseg.getGrayValue(img);
+
+// background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// draw human segmentation
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+humanseg.drawHumanSeg(data, canvas1, back_canvas) ;
+
+// blur background
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+humanseg.blurBackground(data, canvas2) ;
+
+// draw the mask with background
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+humanseg.drawMask(data, canvas3, back_canvas);
+
+```
+
+## gpu pipeline
+
+```js
+
+// 引入 humanseg sdk
+import * as humanseg from '@paddle-js-models/humanseg/lib/index_gpu';
+
+// load humanseg model, use 398x224 shape model, and preheat
+await humanseg.load();
+
+// use 288x160 shape model, preheat and predict faster with a little loss of precision
+// await humanseg.load(true, true);
+
+
+// background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// draw human segmentation
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+await humanseg.drawHumanSeg(input, canvas1, back_canvas) ;
+
+// blur background
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+await humanseg.blurBackground(input, canvas2) ;
+
+// draw the mask with background
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+await humanseg.drawMask(input, canvas3, back_canvas);
+
+```
+
+# Online experience
+
+image human segmentation:https://paddlejs.baidu.com/humanseg
+
+video-streaming human segmentation:https://paddlejs.baidu.com/humanStream
+
+# Performance
+
+
+
+# Usage
+
+```js
+
+import * as humanseg from '@paddle-js-models/humanseg';
+
+// load humanseg model, use 398x224 shape model, and preheat
+await humanseg.load();
+
+// use 288x160 shape model, preheat and predict faster with a little loss of precision
+// await humanseg.load(true, true);
+
+// get the gray value [2, 398, 224] or [2, 288, 160];
+const { data } = await humanseg.getGrayValue(img);
+
+// background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// draw human segmentation
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+humanseg.drawHumanSeg(data, canvas1, back_canvas) ;
+
+// blur background
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+humanseg.blurBackground(data, canvas2) ;
+
+// draw the mask with background
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+humanseg.drawMask(data, canvas3, back_canvas);
+
+```
+
+## gpu pipeline
+
+```js
+
+// 引入 humanseg sdk
+import * as humanseg from '@paddle-js-models/humanseg/lib/index_gpu';
+
+// load humanseg model, use 398x224 shape model, and preheat
+await humanseg.load();
+
+// use 288x160 shape model, preheat and predict faster with a little loss of precision
+// await humanseg.load(true, true);
+
+
+// background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// draw human segmentation
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+await humanseg.drawHumanSeg(input, canvas1, back_canvas) ;
+
+// blur background
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+await humanseg.blurBackground(input, canvas2) ;
+
+// draw the mask with background
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+await humanseg.drawMask(input, canvas3, back_canvas);
+
+```
+
+# Online experience
+
+image human segmentation:https://paddlejs.baidu.com/humanseg
+
+video-streaming human segmentation:https://paddlejs.baidu.com/humanStream
+
+# Performance
+
+  +
+  +
+
+# Used in Video Meeting
+
+
+
+# Used in Video Meeting
+
+
+
+
+
+# 使用
+
+```js
+
+// 引入 humanseg sdk
+import * as humanseg from '@paddle-js-models/humanseg';
+
+// 默认下载 398x224 shape 的模型,默认执行预热
+await humanseg.load();
+
+// 指定下载更轻量模型, 该模型 shape 288x160,预测过程会更快,但会有少许精度损失
+// await humanseg.load(true, true);
+
+
+// 获取分割后的像素 alpha 值,大小为 [2, 398, 224] 或者 [2, 288, 160]
+const { data } = await humanseg.getGrayValue(img);
+
+// 获取 background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// 背景替换, 使用 back_canvas 作为新背景实现背景替换
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+humanseg.drawHumanSeg(data, canvas1, back_canvas) ;
+
+// 背景虚化
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+humanseg.blurBackground(data, canvas2) ;
+
+// 绘制人型遮罩,在新背景上隐藏人像
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+humanseg.drawMask(data, canvas3, back_canvas);
+
+```
+
+## gpu pipeline
+
+```js
+
+// 引入 humanseg sdk
+import * as humanseg from '@paddle-js-models/humanseg/lib/index_gpu';
+
+// 默认下载 398x224 shape 的模型,默认执行预热
+await humanseg.load();
+
+// 指定下载更轻量模型, 该模型 shape 288x160,预测过程会更快,但会有少许精度损失
+// await humanseg.load(true, true);
+
+
+// 获取 background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// 背景替换, 使用 back_canvas 作为新背景实现背景替换
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+await humanseg.drawHumanSeg(input, canvas1, back_canvas) ;
+
+// 背景虚化
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+await humanseg.blurBackground(input, canvas2) ;
+
+// 绘制人型遮罩,在新背景上隐藏人像
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+await humanseg.drawMask(input, canvas3, back_canvas);
+
+```
+
+# 在线体验
+
+图片人像分割:https://paddlejs.baidu.com/humanseg
+
+基于视频流人像分割:https://paddlejs.baidu.com/humanStream
+
+# 效果
+
+从左到右:原图、背景虚化、背景替换、人型遮罩
+
+
+
+
+
+# 视频会议
+
+
+
+
+
+# Usage
+
+```js
+
+import * as humanseg from '@paddle-js-models/humanseg';
+
+// load humanseg model, use 398x224 shape model, and preheat
+await humanseg.load();
+
+// use 288x160 shape model, preheat and predict faster with a little loss of precision
+// await humanseg.load(true, true);
+
+// get the gray value [2, 398, 224] or [2, 288, 160];
+const { data } = await humanseg.getGrayValue(img);
+
+// background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// draw human segmentation
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+humanseg.drawHumanSeg(data, canvas1, back_canvas) ;
+
+// blur background
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+humanseg.blurBackground(data, canvas2) ;
+
+// draw the mask with background
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+humanseg.drawMask(data, canvas3, back_canvas);
+
+```
+
+## gpu pipeline
+
+```js
+
+// 引入 humanseg sdk
+import * as humanseg from '@paddle-js-models/humanseg/lib/index_gpu';
+
+// load humanseg model, use 398x224 shape model, and preheat
+await humanseg.load();
+
+// use 288x160 shape model, preheat and predict faster with a little loss of precision
+// await humanseg.load(true, true);
+
+
+// background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// draw human segmentation
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+await humanseg.drawHumanSeg(input, canvas1, back_canvas) ;
+
+// blur background
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+await humanseg.blurBackground(input, canvas2) ;
+
+// draw the mask with background
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+await humanseg.drawMask(input, canvas3, back_canvas);
+
+```
+
+# Online experience
+
+image human segmentation:https://paddlejs.baidu.com/humanseg
+
+video-streaming human segmentation:https://paddlejs.baidu.com/humanStream
+
+# Performance
+
+
+
+
+
+# Used in Video Meeting
+
+
+
+
+
+# 使用
+
+```js
+
+// 引入 humanseg sdk
+import * as humanseg from '@paddle-js-models/humanseg';
+
+// 默认下载 398x224 shape 的模型,默认执行预热
+await humanseg.load();
+
+// 指定下载更轻量模型, 该模型 shape 288x160,预测过程会更快,但会有少许精度损失
+// await humanseg.load(true, true);
+
+
+// 获取分割后的像素 alpha 值,大小为 [2, 398, 224] 或者 [2, 288, 160]
+const { data } = await humanseg.getGrayValue(img);
+
+// 获取 background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// 背景替换, 使用 back_canvas 作为新背景实现背景替换
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+humanseg.drawHumanSeg(data, canvas1, back_canvas) ;
+
+// 背景虚化
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+humanseg.blurBackground(data, canvas2) ;
+
+// 绘制人型遮罩,在新背景上隐藏人像
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+humanseg.drawMask(data, canvas3, back_canvas);
+
+```
+
+## gpu pipeline
+
+```js
+
+// 引入 humanseg sdk
+import * as humanseg from '@paddle-js-models/humanseg/lib/index_gpu';
+
+// 默认下载 398x224 shape 的模型,默认执行预热
+await humanseg.load();
+
+// 指定下载更轻量模型, 该模型 shape 288x160,预测过程会更快,但会有少许精度损失
+// await humanseg.load(true, true);
+
+
+// 获取 background canvas
+const back_canvas = document.getElementById('background') as HTMLCanvasElement;
+
+// 背景替换, 使用 back_canvas 作为新背景实现背景替换
+const canvas1 = document.getElementById('back') as HTMLCanvasElement;
+await humanseg.drawHumanSeg(input, canvas1, back_canvas) ;
+
+// 背景虚化
+const canvas2 = document.getElementById('blur') as HTMLCanvasElement;
+await humanseg.blurBackground(input, canvas2) ;
+
+// 绘制人型遮罩,在新背景上隐藏人像
+const canvas3 = document.getElementById('mask') as HTMLCanvasElement;
+await humanseg.drawMask(input, canvas3, back_canvas);
+
+```
+
+# 在线体验
+
+图片人像分割:https://paddlejs.baidu.com/humanseg
+
+基于视频流人像分割:https://paddlejs.baidu.com/humanStream
+
+# 效果
+
+从左到右:原图、背景虚化、背景替换、人型遮罩
+
+
+
+
+
+# 视频会议
+
+
+
+



 +
+# Usage
+
+```js
+import * as mobilenet from '@paddle-js-models/mobilenet';
+// You need to specify your model path and the binary file count
+// If your has mean and std params, you need to specify them.
+// map is the results your model can classify.
+await mobilenet.load({
+ path,
+ mean: [0.485, 0.456, 0.406],
+ std: [0.229, 0.224, 0.225]
+}, map);
+// get the result the mobilenet model classified.
+const res = await mobilenet.classify(img);
+```
+
+# Online experience
+
+mobileNet:https://paddlejs.baidu.com/mobilenet
+
+wine:https://paddlejs.baidu.com/wine
+
+# Performance
+
+
+# Usage
+
+```js
+import * as mobilenet from '@paddle-js-models/mobilenet';
+// You need to specify your model path and the binary file count
+// If your has mean and std params, you need to specify them.
+// map is the results your model can classify.
+await mobilenet.load({
+ path,
+ mean: [0.485, 0.456, 0.406],
+ std: [0.229, 0.224, 0.225]
+}, map);
+// get the result the mobilenet model classified.
+const res = await mobilenet.classify(img);
+```
+
+# Online experience
+
+mobileNet:https://paddlejs.baidu.com/mobilenet
+
+wine:https://paddlejs.baidu.com/wine
+
+# Performance
+ diff --git a/examples/application/js/package/packages/paddlejs-models/mobilenet/README_cn.md b/examples/application/js/package/packages/paddlejs-models/mobilenet/README_cn.md
new file mode 100644
index 0000000000..6745fffd21
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/mobilenet/README_cn.md
@@ -0,0 +1,31 @@
+[English](./README.md)
+
+# mobilenet
+
+mobilenet 模型可以对图片进行分类,提供的接口简单,使用者传入自己的分类模型去分类。
+
+
+
+# 使用
+
+```js
+import * as mobilenet from '@paddle-js-models/mobilenet';
+// 使用者需要提供分类模型的地址和二进制参数文件个数,且二进制参数文件,参考 chunk_1.dat、chunk_2.dat,...
+// 模型参数支持 mean 和 std。如果没有,则不需要传
+// 还需要传递分类映射文件
+await mobilenet.load({
+ path,
+ mean: [0.485, 0.456, 0.406],
+ std: [0.229, 0.224, 0.225]
+}, map);
+// 获取图片分类结果
+const res = await mobilenet.classify(img);
+```
+# 在线体验
+
+1000物品识别:https://paddlejs.baidu.com/mobilenet
+
+酒瓶识别:https://paddlejs.baidu.com/wine
+
+# 效果
+
\ No newline at end of file
diff --git a/examples/application/js/package/packages/paddlejs-models/ocr/README.md b/examples/application/js/package/packages/paddlejs-models/ocr/README.md
new file mode 100644
index 0000000000..14d448c4b6
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocr/README.md
@@ -0,0 +1,36 @@
+[中文版](./README_cn.md)
+
+# OCR
+
+OCR is a text recognition module, which includes two models: ocr_detection and ocr_recognition。 ocr_detection model detects the region of the text in the picture, ocr_recognition model can recognize the characters (Chinese / English / numbers) in each text area.
+
+
diff --git a/examples/application/js/package/packages/paddlejs-models/mobilenet/README_cn.md b/examples/application/js/package/packages/paddlejs-models/mobilenet/README_cn.md
new file mode 100644
index 0000000000..6745fffd21
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/mobilenet/README_cn.md
@@ -0,0 +1,31 @@
+[English](./README.md)
+
+# mobilenet
+
+mobilenet 模型可以对图片进行分类,提供的接口简单,使用者传入自己的分类模型去分类。
+
+
+
+# 使用
+
+```js
+import * as mobilenet from '@paddle-js-models/mobilenet';
+// 使用者需要提供分类模型的地址和二进制参数文件个数,且二进制参数文件,参考 chunk_1.dat、chunk_2.dat,...
+// 模型参数支持 mean 和 std。如果没有,则不需要传
+// 还需要传递分类映射文件
+await mobilenet.load({
+ path,
+ mean: [0.485, 0.456, 0.406],
+ std: [0.229, 0.224, 0.225]
+}, map);
+// 获取图片分类结果
+const res = await mobilenet.classify(img);
+```
+# 在线体验
+
+1000物品识别:https://paddlejs.baidu.com/mobilenet
+
+酒瓶识别:https://paddlejs.baidu.com/wine
+
+# 效果
+
\ No newline at end of file
diff --git a/examples/application/js/package/packages/paddlejs-models/ocr/README.md b/examples/application/js/package/packages/paddlejs-models/ocr/README.md
new file mode 100644
index 0000000000..14d448c4b6
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocr/README.md
@@ -0,0 +1,36 @@
+[中文版](./README_cn.md)
+
+# OCR
+
+OCR is a text recognition module, which includes two models: ocr_detection and ocr_recognition。 ocr_detection model detects the region of the text in the picture, ocr_recognition model can recognize the characters (Chinese / English / numbers) in each text area.
+
+


 +
+The module provides a simple and easy-to-use interface. Users only need to upload pictures to obtain text recognition results.
+
+The ocr_detection and ocr_recognition models are compressed from [PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_en/PP-OCRv3_introduction_en.md) which released by [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), which greatly improves the running speed on js at a small loss of accuracy.
+
+The input shape of the ocr_recognition model is [1, 3, 48, 320], and the selected area of the picture text box will be processed before the model reasoning: the width height ratio of the selected area of the picture text box is < = 10, and the whole selected area will be transferred into the recognition model; If the width height ratio of the frame selected area is > 10, the frame selected area will be cropped according to the width, the cropped area will be introduced into the recognition model, and finally the recognition results of each part of the cropped area will be spliced.
+
+
+# Usage
+
+```js
+import * as ocr from '@paddle-js-models/ocr';
+// Model initialization
+await ocr.init();
+// Get the text recognition result API, img is the user's upload picture, and option is an optional parameter
+// option.canvas as HTMLElementCanvas:if the user needs to draw the selected area of the text box, pass in the canvas element
+// option.style as object:if the user needs to configure the canvas style, pass in the style object
+// option.style.strokeStyle as string:select a color for the text box
+// option.style.lineWidth as number:width of selected line segment in text box
+// option.style.fillStyle as string:select the fill color for the text box
+const res = await ocr.recognize(img, option?);
+// character recognition results
+console.log(res.text);
+// text area points
+console.log(res.points);
+```
+
+# Performance
+
+
+The module provides a simple and easy-to-use interface. Users only need to upload pictures to obtain text recognition results.
+
+The ocr_detection and ocr_recognition models are compressed from [PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_en/PP-OCRv3_introduction_en.md) which released by [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), which greatly improves the running speed on js at a small loss of accuracy.
+
+The input shape of the ocr_recognition model is [1, 3, 48, 320], and the selected area of the picture text box will be processed before the model reasoning: the width height ratio of the selected area of the picture text box is < = 10, and the whole selected area will be transferred into the recognition model; If the width height ratio of the frame selected area is > 10, the frame selected area will be cropped according to the width, the cropped area will be introduced into the recognition model, and finally the recognition results of each part of the cropped area will be spliced.
+
+
+# Usage
+
+```js
+import * as ocr from '@paddle-js-models/ocr';
+// Model initialization
+await ocr.init();
+// Get the text recognition result API, img is the user's upload picture, and option is an optional parameter
+// option.canvas as HTMLElementCanvas:if the user needs to draw the selected area of the text box, pass in the canvas element
+// option.style as object:if the user needs to configure the canvas style, pass in the style object
+// option.style.strokeStyle as string:select a color for the text box
+// option.style.lineWidth as number:width of selected line segment in text box
+// option.style.fillStyle as string:select the fill color for the text box
+const res = await ocr.recognize(img, option?);
+// character recognition results
+console.log(res.text);
+// text area points
+console.log(res.points);
+```
+
+# Performance
+ \ No newline at end of file
diff --git a/examples/application/js/package/packages/paddlejs-models/ocr/README_cn.md b/examples/application/js/package/packages/paddlejs-models/ocr/README_cn.md
new file mode 100644
index 0000000000..30ec9e232a
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocr/README_cn.md
@@ -0,0 +1,39 @@
+[English](./README.md)
+
+# OCR
+
+ocr 为文本识别模块,包括两个模型:ocr_detection 和 ocr_recognition。ocr_detection 模型检测图片中文本所在区域,ocr_recognition 模型可识别每个文本区域内的字符(中文/英文/数字)。
+
+
+
+模块提供简单易用的接口,使用者只需上传图片即可获取文本识别结果。
+
+ocr_detection和ocr_recognition模型是[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)发布[PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/PP-OCRv3_introduction.md)模型的压缩版本,在损失一小部分精度的情况下,大幅提升在js上的运行速度。
+
+ocr_recognition模型输入shape为[1, 3, 48, 320],模型推理前会对图片文本框选区域进行处理:图片文本框选区域宽高比 <= 10,将整个框选区域传入识别模型;框选区域宽高比 > 10,则对框选区域按宽度进行裁剪,将裁剪区域传入识别模型,最终拼接裁剪区域每一部分的识别结果。
+
+
+
+
+# 使用
+
+```js
+import * as ocr from '@paddle-js-models/ocr';
+// 模型初始化
+await ocr.init();
+// 获取文本识别结果API,img为用户上传图片,option为可选参数
+// option.canvas as HTMLElementCanvas:若用户需要绘制文本框选区域,传入canvas元素
+// option.style as object:若用户需要配置canvas 样式,传入style 对象
+// option.style.strokeStyle as string:文本框选颜色
+// option.style.lineWidth as number:文本框选线段宽度
+// option.style.fillStyle as string:文本框选填充颜色
+const res = await ocr.recognize(img, option?);
+// 识别文字结果
+console.log(res.text);
+// 文本区域坐标
+console.log(res.points);
+```
+# 在线体验
+https://paddlejs.baidu.com/ocr
+# 效果
+
\ No newline at end of file
diff --git a/examples/application/js/package/packages/paddlejs-models/ocrdetection/README.md b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README.md
new file mode 100644
index 0000000000..55f49b0dcc
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README.md
@@ -0,0 +1,28 @@
+[中文版](./README_cn.md)
+
+# ocr_detection
+
+ocr_detection model is used to detect the text area in the image.
+
+
\ No newline at end of file
diff --git a/examples/application/js/package/packages/paddlejs-models/ocr/README_cn.md b/examples/application/js/package/packages/paddlejs-models/ocr/README_cn.md
new file mode 100644
index 0000000000..30ec9e232a
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocr/README_cn.md
@@ -0,0 +1,39 @@
+[English](./README.md)
+
+# OCR
+
+ocr 为文本识别模块,包括两个模型:ocr_detection 和 ocr_recognition。ocr_detection 模型检测图片中文本所在区域,ocr_recognition 模型可识别每个文本区域内的字符(中文/英文/数字)。
+
+
+
+模块提供简单易用的接口,使用者只需上传图片即可获取文本识别结果。
+
+ocr_detection和ocr_recognition模型是[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)发布[PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/PP-OCRv3_introduction.md)模型的压缩版本,在损失一小部分精度的情况下,大幅提升在js上的运行速度。
+
+ocr_recognition模型输入shape为[1, 3, 48, 320],模型推理前会对图片文本框选区域进行处理:图片文本框选区域宽高比 <= 10,将整个框选区域传入识别模型;框选区域宽高比 > 10,则对框选区域按宽度进行裁剪,将裁剪区域传入识别模型,最终拼接裁剪区域每一部分的识别结果。
+
+
+
+
+# 使用
+
+```js
+import * as ocr from '@paddle-js-models/ocr';
+// 模型初始化
+await ocr.init();
+// 获取文本识别结果API,img为用户上传图片,option为可选参数
+// option.canvas as HTMLElementCanvas:若用户需要绘制文本框选区域,传入canvas元素
+// option.style as object:若用户需要配置canvas 样式,传入style 对象
+// option.style.strokeStyle as string:文本框选颜色
+// option.style.lineWidth as number:文本框选线段宽度
+// option.style.fillStyle as string:文本框选填充颜色
+const res = await ocr.recognize(img, option?);
+// 识别文字结果
+console.log(res.text);
+// 文本区域坐标
+console.log(res.points);
+```
+# 在线体验
+https://paddlejs.baidu.com/ocr
+# 效果
+
\ No newline at end of file
diff --git a/examples/application/js/package/packages/paddlejs-models/ocrdetection/README.md b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README.md
new file mode 100644
index 0000000000..55f49b0dcc
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README.md
@@ -0,0 +1,28 @@
+[中文版](./README_cn.md)
+
+# ocr_detection
+
+ocr_detection model is used to detect the text area in the image.
+
+


 +
+
+The ocr_detection model is compressed from [PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_en/PP-OCRv3_introduction_en.md) which released by [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), which greatly improves the running speed on js at a small loss of accuracy.
+
+
+# Usage
+
+```js
+import * as ocr from '@paddle-js-models/ocrdet';
+// Load ocr_detect model
+await ocr.load();
+// Get text area points
+const res = await ocr.detect(img);
+```
+
+# Online experience
+
+https://paddlejs.baidu.com/ocrdet
+
+# Performance
+
+
+
+The ocr_detection model is compressed from [PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_en/PP-OCRv3_introduction_en.md) which released by [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), which greatly improves the running speed on js at a small loss of accuracy.
+
+
+# Usage
+
+```js
+import * as ocr from '@paddle-js-models/ocrdet';
+// Load ocr_detect model
+await ocr.load();
+// Get text area points
+const res = await ocr.detect(img);
+```
+
+# Online experience
+
+https://paddlejs.baidu.com/ocrdet
+
+# Performance
+ diff --git a/examples/application/js/package/packages/paddlejs-models/ocrdetection/README_cn.md b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README_cn.md
new file mode 100644
index 0000000000..8be3966037
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README_cn.md
@@ -0,0 +1,24 @@
+[English](./README.md)
+
+# ocr_detection
+
+ocr_detection模型用于检测图像中文字区域。
+
+
+
+
+ocr_detection模型是[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)发布[PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/PP-OCRv3_introduction.md)模型的压缩版本,压缩后的模型仅0.47M,在损失一小部分精度的情况下,大幅提升在js上的运行速度。
+
+# 使用
+
+```js
+import * as ocr from '@paddle-js-models/ocrdet';
+// ocr_detect模型加载
+await ocr.load();
+// 获取文字区域坐标
+const res = await ocr.detect(img);
+```
+
+# 效果
+
+
diff --git a/examples/application/js/package/packages/paddlejs-models/ocrdetection/README_cn.md b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README_cn.md
new file mode 100644
index 0000000000..8be3966037
--- /dev/null
+++ b/examples/application/js/package/packages/paddlejs-models/ocrdetection/README_cn.md
@@ -0,0 +1,24 @@
+[English](./README.md)
+
+# ocr_detection
+
+ocr_detection模型用于检测图像中文字区域。
+
+
+
+
+ocr_detection模型是[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)发布[PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/PP-OCRv3_introduction.md)模型的压缩版本,压缩后的模型仅0.47M,在损失一小部分精度的情况下,大幅提升在js上的运行速度。
+
+# 使用
+
+```js
+import * as ocr from '@paddle-js-models/ocrdet';
+// ocr_detect模型加载
+await ocr.load();
+// 获取文字区域坐标
+const res = await ocr.detect(img);
+```
+
+# 效果
+
+