", " ") - text = text.replace("\t", "") - return text - - -class HYPTextPreprocessor(TextPreprocessor): - def __init__(self): - self.bs4 = try_import("bs4") - - def __call__(self, text): - text = self.bs4.BeautifulSoup(text, "html.parser").get_text() - text = text.strip().replace("\n", "").replace("\t", "") - return text - - -class ClassifierIterator(object): - def __init__( - self, - dataset, - batch_size, - tokenizer, - trainer_num, - trainer_id, - max_seq_length=512, - memory_len=128, - repeat_input=False, - in_tokens=False, - mode="train", - random_seed=None, - preprocess_text_fn=None, - ): - self.batch_size = batch_size - self.tokenizer = tokenizer - self.trainer_num = trainer_num - self.trainer_id = trainer_id - self.max_seq_length = max_seq_length - self.memory_len = memory_len - self.repeat_input = repeat_input - self.in_tokens = in_tokens - self.dataset = [data for data in dataset] - self.num_examples = None - self.mode = mode - self.shuffle = True if mode == "train" else False - if random_seed is None: - random_seed = 12345 - self.random_seed = random_seed - self.preprocess_text_fn = preprocess_text_fn - - def shuffle_sample(self): - if self.shuffle: - self.global_rng = np.random.RandomState(self.random_seed) - self.global_rng.shuffle(self.dataset) - - def _cnt_list(self, inp): - """Cnt_list""" - cnt = 0 - for lit in inp: - if lit: - cnt += 1 - return cnt - - def _convert_to_features(self, example, qid): - """ - Convert example to features fed into model - """ - if "text" in example: # imdb - text = example["text"] - elif "sentence" in example: # iflytek - text = example["sentence"] - - if self.preprocess_text_fn: - text = self.preprocess_text_fn(text) - label = example["label"] - doc_spans = [] - _DocSpan = namedtuple("DocSpan", ["start", "length"]) - start_offset = 0 - max_tokens_for_doc = self.max_seq_length - 2 - tokens_a = self.tokenizer.tokenize(text) - while start_offset < len(tokens_a): - length = len(tokens_a) - start_offset - if length > max_tokens_for_doc: - length = max_tokens_for_doc - doc_spans.append(_DocSpan(start=start_offset, length=length)) - if start_offset + length == len(tokens_a): - break - start_offset += min(length, self.memory_len) - - features = [] - Feature = namedtuple("Feature", ["src_ids", "label_id", "qid", "cal_loss"]) - for (doc_span_index, doc_span) in enumerate(doc_spans): - tokens = tokens_a[doc_span.start : doc_span.start + doc_span.length] + ["[SEP]"] + ["[CLS]"] - token_ids = self.tokenizer.convert_tokens_to_ids(tokens) - features.append(Feature(src_ids=token_ids, label_id=label, qid=qid, cal_loss=1)) - - if self.repeat_input: - features_repeat = features - features = list(map(lambda x: x._replace(cal_loss=0), features)) - features = features + features_repeat - return features - - def _get_samples(self, pre_batch_list, is_last=False): - if is_last: - # Pad batch - len_doc = [len(doc) for doc in pre_batch_list] - max_len_idx = len_doc.index(max(len_doc)) - dirty_sample = pre_batch_list[max_len_idx][-1]._replace(cal_loss=0) - for sample_list in pre_batch_list: - sample_list.extend([dirty_sample] * (max(len_doc) - len(sample_list))) - - samples = [] - min_len = min([len(doc) for doc in pre_batch_list]) - for cnt in range(min_len): - for batch_idx in range(self.batch_size * self.trainer_num): - sample = pre_batch_list[batch_idx][cnt] - samples.append(sample) - - for idx in range(len(pre_batch_list)): - pre_batch_list[idx] = pre_batch_list[idx][min_len:] - return samples - - def _pad_batch_records(self, batch_records, gather_idx=[]): - batch_token_ids = [record.src_ids for record in batch_records] - if batch_records[0].label_id is not None: - batch_labels = [record.label_id for record in batch_records] - batch_labels = np.array(batch_labels).astype("int64").reshape([-1, 1]) - else: - batch_labels = np.array([]).astype("int64").reshape([-1, 1]) - # Qid - if batch_records[-1].qid is not None: - batch_qids = [record.qid for record in batch_records] - batch_qids = np.array(batch_qids).astype("int64").reshape([-1, 1]) - else: - batch_qids = np.array([]).astype("int64").reshape([-1, 1]) - - if gather_idx: - batch_gather_idx = np.array(gather_idx).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([1]).astype("int64") - else: - batch_gather_idx = np.array(list(range(len(batch_records)))).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([0]).astype("int64") - - # Padding - padded_token_ids, input_mask = pad_batch_data( - batch_token_ids, - pad_idx=self.tokenizer.pad_token_id, - pad_max_len=self.max_seq_length, - final_cls=True, - return_input_mask=True, - ) - padded_task_ids = np.zeros_like(padded_token_ids, dtype="int64") - padded_position_ids = get_related_pos(padded_token_ids, self.max_seq_length, self.memory_len) - - return_list = [ - padded_token_ids, - padded_position_ids, - padded_task_ids, - input_mask, - batch_labels, - batch_qids, - batch_gather_idx, - need_cal_loss, - ] - return return_list - - def _prepare_batch_data(self, examples): - batch_records, max_len, gather_idx = [], 0, [] - for index, example in enumerate(examples): - max_len = max(max_len, len(example.src_ids)) - if self.in_tokens: - to_append = (len(batch_records) + 1) * max_len <= self.batch_size - else: - to_append = len(batch_records) < self.batch_size - if to_append: - batch_records.append(example) - if example.cal_loss == 1: - gather_idx.append(index % self.batch_size) - else: - yield self._pad_batch_records(batch_records, gather_idx) - batch_records, max_len = [example], len(example.src_ids) - gather_idx = [index % self.batch_size] if example.cal_loss == 1 else [] - yield self._pad_batch_records(batch_records, gather_idx) - - def _create_instances(self): - examples = self.dataset - pre_batch_list = [] - insert_idx = [] - for qid, example in enumerate(examples): - features = self._convert_to_features(example, qid) - if self._cnt_list(pre_batch_list) < self.batch_size * self.trainer_num: - if insert_idx: - pre_batch_list[insert_idx[0]] = features - insert_idx.pop(0) - else: - pre_batch_list.append(features) - if self._cnt_list(pre_batch_list) == self.batch_size * self.trainer_num: - assert self._cnt_list(pre_batch_list) == len(pre_batch_list), "the two value must be equal" - assert not insert_idx, "the insert_idx must be null" - sample_batch = self._get_samples(pre_batch_list) - - for idx, lit in enumerate(pre_batch_list): - if not lit: - insert_idx.append(idx) - for batch_records in self._prepare_batch_data(sample_batch): - yield batch_records - - if self.mode != "train": - if self._cnt_list(pre_batch_list): - pre_batch_list += [ - [] for _ in range(self.batch_size * self.trainer_num - self._cnt_list(pre_batch_list)) - ] - sample_batch = self._get_samples(pre_batch_list, is_last=True) - for batch_records in self._prepare_batch_data(sample_batch): - yield batch_records - - def __call__(self): - curr_id = 0 - for batch_records in self._create_instances(): - if curr_id == self.trainer_id or self.mode != "train": - yield batch_records - curr_id = (curr_id + 1) % self.trainer_num - - def get_num_examples(self): - if self.num_examples is None: - self.num_examples = 0 - for qid, example in enumerate(self.dataset): - self.num_examples += len(self._convert_to_features(example, qid)) - return self.num_examples - - -class MRCIterator(ClassifierIterator): - """ - Machine Reading Comprehension iterator. Only for answer extraction. - """ - - def __init__( - self, - dataset, - batch_size, - tokenizer, - trainer_num, - trainer_id, - max_seq_length=512, - memory_len=128, - repeat_input=False, - in_tokens=False, - mode="train", - random_seed=None, - doc_stride=128, - max_query_length=64, - ): - super(MRCIterator, self).__init__( - dataset, - batch_size, - tokenizer, - trainer_num, - trainer_id, - max_seq_length, - memory_len, - repeat_input, - in_tokens, - mode, - random_seed, - preprocess_text_fn=None, - ) - self.doc_stride = doc_stride - self.max_query_length = max_query_length - self.examples = [] - self.features = [] - self.features_all = [] - self._preprocess_data() - - def shuffle_sample(self): - if self.shuffle: - self.global_rng = np.random.RandomState(self.random_seed) - self.global_rng.shuffle(self.features_all) - - def _convert_qa_to_examples(self): - Example = namedtuple( - "Example", ["qas_id", "question_text", "doc_tokens", "orig_answer_text", "start_position", "end_position"] - ) - examples = [] - for qa in self.dataset: - qas_id = qa["id"] - question_text = qa["question"] - context = qa["context"] - start_pos = None - end_pos = None - orig_answer_text = None - if self.mode == "train": - if len(qa["answers"]) != 1: - raise ValueError("For training, each question should have exactly 1 answer.") - orig_answer_text = qa["answers"][0] - answer_offset = qa["answer_starts"][0] - answer_length = len(orig_answer_text) - doc_tokens = [ - context[:answer_offset], - context[answer_offset : answer_offset + answer_length], - context[answer_offset + answer_length :], - ] - - start_pos = 1 - end_pos = 1 - - actual_text = " ".join(doc_tokens[start_pos : (end_pos + 1)]) - if orig_answer_text.islower(): - actual_text = actual_text.lower() - if actual_text.find(orig_answer_text) == -1: - logger.info("Could not find answer: '%s' vs. '%s'" % (actual_text, orig_answer_text)) - continue - - else: - doc_tokens = tokenize_chinese_chars(context) - - example = Example( - qas_id=qas_id, - question_text=question_text, - doc_tokens=doc_tokens, - orig_answer_text=orig_answer_text, - start_position=start_pos, - end_position=end_pos, - ) - examples.append(example) - return examples - - def _convert_example_to_feature(self, examples): - Feature = namedtuple( - "Feature", - [ - "qid", - "example_index", - "doc_span_index", - "tokens", - "token_to_orig_map", - "token_is_max_context", - "src_ids", - "start_position", - "end_position", - "cal_loss", - ], - ) - features = [] - self.features_all = [] - unique_id = 1000 - is_training = self.mode == "train" - print("total {} examples".format(len(examples)), flush=True) - for (example_index, example) in enumerate(examples): - query_tokens = self.tokenizer.tokenize(example.question_text) - if len(query_tokens) > self.max_query_length: - query_tokens = query_tokens[0 : self.max_query_length] - tok_to_orig_index = [] - orig_to_tok_index = [] - all_doc_tokens = [] - for (i, token) in enumerate(example.doc_tokens): - orig_to_tok_index.append(len(all_doc_tokens)) - sub_tokens = self.tokenizer.tokenize(token) - for sub_token in sub_tokens: - tok_to_orig_index.append(i) - all_doc_tokens.append(sub_token) - - tok_start_position = None - tok_end_position = None - if is_training: - tok_start_position = orig_to_tok_index[example.start_position] - if example.end_position < len(example.doc_tokens) - 1: - tok_end_position = orig_to_tok_index[example.end_position + 1] - 1 - else: - tok_end_position = len(all_doc_tokens) - 1 - (tok_start_position, tok_end_position) = self._improve_answer_span( - all_doc_tokens, tok_start_position, tok_end_position, example.orig_answer_text - ) - - max_tokens_for_doc = self.max_seq_length - len(query_tokens) - 3 - _DocSpan = namedtuple("DocSpan", ["start", "length"]) - doc_spans = [] - start_offset = 0 - while start_offset < len(all_doc_tokens): - length = len(all_doc_tokens) - start_offset - if length > max_tokens_for_doc: - length = max_tokens_for_doc - doc_spans.append(_DocSpan(start=start_offset, length=length)) - if start_offset + length == len(all_doc_tokens): - break - start_offset += min(length, self.doc_stride) - - features_each = [] - for (doc_span_index, doc_span) in enumerate(doc_spans): - tokens = [] - token_to_orig_map = {} - token_is_max_context = {} - tokens.append("[CLS]") - for i in range(doc_span.length): - split_token_index = doc_span.start + i - token_to_orig_map[i + 1] = tok_to_orig_index[split_token_index] - is_max_context = self._check_is_max_context(doc_spans, doc_span_index, split_token_index) - token_is_max_context[i + 1] = is_max_context - tokens += all_doc_tokens[doc_span.start : doc_span.start + doc_span.length] - tokens.append("[SEP]") - - for token in query_tokens: - tokens.append(token) - tokens.append("[SEP]") - - token_ids = self.tokenizer.convert_tokens_to_ids(tokens) - start_position = None - end_position = None - if is_training: - doc_start = doc_span.start - doc_end = doc_span.start + doc_span.length - 1 - out_of_span = False - if not (tok_start_position >= doc_start and tok_end_position <= doc_end): - out_of_span = True - if out_of_span: - start_position = 0 - end_position = 0 - else: - doc_offset = 1 # len(query_tokens) + 2 - start_position = tok_start_position - doc_start + doc_offset - end_position = tok_end_position - doc_start + doc_offset - - feature = Feature( - qid=unique_id, - example_index=example_index, - doc_span_index=doc_span_index, - tokens=tokens, - token_to_orig_map=token_to_orig_map, - token_is_max_context=token_is_max_context, - src_ids=token_ids, - start_position=start_position, - end_position=end_position, - cal_loss=1, - ) - features.append(feature) - features_each.append(feature) - if example_index % 1000 == 0: - print("processing {} examples".format(example_index), flush=True) - - unique_id += 1 - # Repeat - if self.repeat_input: - features_each_repeat = features_each - features_each = list(map(lambda x: x._replace(cla_loss=0), features_each)) - features_each += features_each_repeat - - self.features_all.append(features_each) - - return features - - def _preprocess_data(self): - # Construct examples - self.examples = self._convert_qa_to_examples() - # Construct features - self.features = self._convert_example_to_feature(self.examples) - - def get_num_examples(self): - if not self.features_all: - self._preprocess_data() - return len(sum(self.features_all, [])) - - def _improve_answer_span(self, doc_tokens, input_start, input_end, orig_answer_text): - """Improve answer span""" - tok_answer_text = " ".join(self.tokenizer.tokenize(orig_answer_text)) - - for new_start in range(input_start, input_end + 1): - for new_end in range(input_end, new_start - 1, -1): - text_span = " ".join(doc_tokens[new_start : (new_end + 1)]) - if text_span == tok_answer_text: - return (new_start, new_end) - - return (input_start, input_end) - - def _check_is_max_context(self, doc_spans, cur_span_index, position): - """Check is max context""" - best_score = None - best_span_index = None - for (span_index, doc_span) in enumerate(doc_spans): - end = doc_span.start + doc_span.length - 1 - if position < doc_span.start: - break - if position > end: - continue - num_left_context = position - doc_span.start - num_right_context = end - position - score = min(num_left_context, num_right_context) + 0.01 * doc_span.length - if best_score is None or score > best_score: - best_score = score - best_span_index = span_index - if best_span_index > cur_span_index: - return False - - return cur_span_index == best_span_index - - def _pad_batch_records(self, batch_records, gather_idx=[]): - """Pad batch data""" - batch_token_ids = [record.src_ids for record in batch_records] - - if self.mode == "train": - batch_start_position = [record.start_position for record in batch_records] - batch_end_position = [record.end_position for record in batch_records] - batch_start_position = np.array(batch_start_position).astype("int64").reshape([-1, 1]) - batch_end_position = np.array(batch_end_position).astype("int64").reshape([-1, 1]) - else: - batch_size = len(batch_token_ids) - batch_start_position = np.zeros(shape=[batch_size, 1], dtype="int64") - batch_end_position = np.zeros(shape=[batch_size, 1], dtype="int64") - - batch_qids = [record.qid for record in batch_records] - batch_qids = np.array(batch_qids).astype("int64").reshape([-1, 1]) - - if gather_idx: - batch_gather_idx = np.array(gather_idx).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([1]).astype("int64") - else: - batch_gather_idx = np.array(list(range(len(batch_records)))).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([0]).astype("int64") - - # padding - padded_token_ids, input_mask = pad_batch_data( - batch_token_ids, - pad_idx=self.tokenizer.pad_token_id, - pad_max_len=self.max_seq_length, - return_input_mask=True, - ) - padded_task_ids = np.zeros_like(padded_token_ids, dtype="int64") - padded_position_ids = get_related_pos(padded_task_ids, self.max_seq_length, self.memory_len) - - return_list = [ - padded_token_ids, - padded_position_ids, - padded_task_ids, - input_mask, - batch_start_position, - batch_end_position, - batch_qids, - batch_gather_idx, - need_cal_loss, - ] - - return return_list - - def _create_instances(self): - """Generate batch records""" - pre_batch_list = [] - insert_idx = [] - for qid, features in enumerate(self.features_all): - if self._cnt_list(pre_batch_list) < self.batch_size * self.trainer_num: - if insert_idx: - pre_batch_list[insert_idx[0]] = features - insert_idx.pop(0) - else: - pre_batch_list.append(features) - if self._cnt_list(pre_batch_list) == self.batch_size * self.trainer_num: - assert self._cnt_list(pre_batch_list) == len(pre_batch_list), "the two value must be equal" - assert not insert_idx, "the insert_idx must be null" - sample_batch = self._get_samples(pre_batch_list) - - for idx, lit in enumerate(pre_batch_list): - if not lit: - insert_idx.append(idx) - for batch_records in self._prepare_batch_data(sample_batch): - yield batch_records - - if self.mode != "train": - if self._cnt_list(pre_batch_list): - pre_batch_list += [ - [] for _ in range(self.batch_size * self.trainer_num - self._cnt_list(pre_batch_list)) - ] - sample_batch = self._get_samples(pre_batch_list, is_last=True) - for batch_records in self._prepare_batch_data(sample_batch): - yield batch_records - - -class MCQIterator(MRCIterator): - """ - Multiple choice question iterator. - """ - - def __init__( - self, - dataset, - batch_size, - tokenizer, - trainer_num, - trainer_id, - max_seq_length=512, - memory_len=128, - repeat_input=False, - in_tokens=False, - mode="train", - random_seed=None, - doc_stride=128, - max_query_length=64, - choice_num=4, - ): - self.choice_num = choice_num - super(MCQIterator, self).__init__( - dataset, - batch_size, - tokenizer, - trainer_num, - trainer_id, - max_seq_length, - memory_len, - repeat_input, - in_tokens, - mode, - random_seed, - ) - - def _truncate_seq_pair(self, tokens_a, tokens_b, max_length): - """Truncates a sequence pair in place to the maximum length.""" - - # This is a simple heuristic which will always truncate the longer sequence - # one token at a time. This makes more sense than truncating an equal percent - # of tokens from each, since if one sequence is very short then each token - # that's truncated likely contains more information than a longer sequence. - tokens_a = list(tokens_a) - tokens_b = list(tokens_b) - while True: - total_length = len(tokens_a) + len(tokens_b) - if total_length <= max_length: - break - if len(tokens_a) > len(tokens_b): - tokens_a.pop() - else: - tokens_b.pop() - return tokens_a, tokens_b - - def _convert_qa_to_examples(self): - Example = namedtuple("Example", ["qas_id", "context", "question", "choice", "label"]) - examples = [] - for qas_id, qa in enumerate(self.dataset): - context = "\n".join(qa["context"]).lower() - question = qa["question"].lower() - choice = [c.lower() for c in qa["choice"]] - # pad empty choice - for k in range(len(choice), self.choice_num): - choice.append("") - label = qa["label"] - - example = Example(qas_id=qas_id, context=context, question=question, choice=choice, label=label) - examples.append(example) - return examples - - def _convert_example_to_feature(self, examples): - Feature = namedtuple("Feature", ["qid", "src_ids", "segment_ids", "label", "cal_loss"]) - features = [] - self.features_all = [] - for (ex_index, example) in enumerate(examples): - context_tokens = self.tokenizer.tokenize(example.context) - question_tokens = self.tokenizer.tokenize(example.question) - choice_tokens_lst = [self.tokenizer.tokenize(choice) for choice in example.choice] - # nums = 4 - question_choice_pairs = [ - self._truncate_seq_pair(question_tokens, choice_tokens, self.max_query_length - 2) - for choice_tokens in choice_tokens_lst - ] - total_qc_num = sum([(len(q) + len(c)) for q, c in question_choice_pairs]) - max_tokens_for_doc = self.max_seq_length - total_qc_num - 4 - _DocSpan = namedtuple("DocSpan", ["start", "length"]) - doc_spans = [] - start_offset = 0 - - while start_offset < len(context_tokens): - length = len(context_tokens) - start_offset - if length > max_tokens_for_doc: - length = max_tokens_for_doc - doc_spans.append(_DocSpan(start=start_offset, length=length)) - if start_offset + length == len(context_tokens): - break - start_offset += min(length, self.doc_stride) - - features_each = [] - for (doc_span_index, doc_span) in enumerate(doc_spans): - qa_features = [] - for q_tokens, c_tokens in question_choice_pairs: - segment_tokens = ["[CLS]"] - token_type_ids = [0] - - segment_tokens += context_tokens[doc_span.start : doc_span.start + doc_span.length] - token_type_ids += [0] * doc_span.length - - segment_tokens += ["[SEP]"] - token_type_ids += [0] - - segment_tokens += q_tokens - token_type_ids += [1] * len(q_tokens) - - segment_tokens += ["[SEP]"] - token_type_ids += [1] - - segment_tokens += c_tokens - token_type_ids += [1] * len(c_tokens) - - segment_tokens += ["[SEP]"] - token_type_ids += [1] - - input_ids = self.tokenizer.convert_tokens_to_ids(segment_tokens) - feature = Feature( - qid=example.qas_id, - label=example.label, - src_ids=input_ids, - segment_ids=token_type_ids, - cal_loss=1, - ) - qa_features.append(feature) - - features.append(qa_features) - features_each.append(qa_features) - - # Repeat - if self.repeat_input: - features_each_repeat = features_each - features_each = list(map(lambda x: x._replace(cla_loss=0), features_each)) - features_each += features_each_repeat - - self.features_all.append(features_each) - - return features - - def _pad_batch_records(self, batch_records, gather_idx=[]): - batch_token_ids = [[record.src_ids for record in records] for records in batch_records] - if batch_records[0][0].label is not None: - batch_labels = [[record.label for record in records] for records in batch_records] - batch_labels = np.array(batch_labels).astype("int64").reshape([-1, 1]) - else: - batch_labels = np.array([]).astype("int64").reshape([-1, 1]) - # Qid - batch_qids = [[record.qid for record in records] for records in batch_records] - batch_qids = np.array(batch_qids).astype("int64").reshape([-1, 1]) - - if gather_idx: - batch_gather_idx = np.array(gather_idx).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([1]).astype("int64") - else: - batch_gather_idx = np.array(list(range(len(batch_records)))).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([0]).astype("int64") - - batch_task_ids = [[record.segment_ids for record in records] for records in batch_records] - - # Padding - batch_padded_token_ids = [] - batch_input_mask = [] - batch_padded_task_ids = [] - batch_padded_position_ids = [] - batch_size = len(batch_token_ids) - for i in range(batch_size): - padded_token_ids, input_mask = pad_batch_data( - batch_token_ids[i], - pad_idx=self.tokenizer.pad_token_id, - pad_max_len=self.max_seq_length, - return_input_mask=True, - ) - padded_task_ids = pad_batch_data( - batch_task_ids[i], pad_idx=self.tokenizer.pad_token_id, pad_max_len=self.max_seq_length - ) - - padded_position_ids = get_related_pos(padded_task_ids, self.max_seq_length, self.memory_len) - - batch_padded_token_ids.append(padded_token_ids) - batch_input_mask.append(input_mask) - batch_padded_task_ids.append(padded_task_ids) - batch_padded_position_ids.append(padded_position_ids) - - batch_padded_token_ids = ( - np.array(batch_padded_token_ids).astype("int64").reshape([batch_size * self.choice_num, -1, 1]) - ) - batch_padded_position_ids = ( - np.array(batch_padded_position_ids).astype("int64").reshape([batch_size * self.choice_num, -1, 1]) - ) - batch_padded_task_ids = ( - np.array(batch_padded_task_ids).astype("int64").reshape([batch_size * self.choice_num, -1, 1]) - ) - batch_input_mask = np.array(batch_input_mask).astype("float32").reshape([batch_size * self.choice_num, -1, 1]) - - return_list = [ - batch_padded_token_ids, - batch_padded_position_ids, - batch_padded_task_ids, - batch_input_mask, - batch_labels, - batch_qids, - batch_gather_idx, - need_cal_loss, - ] - return return_list - - def _prepare_batch_data(self, examples_list): - batch_records, max_len, gather_idx = [], 0, [] - real_batch_size = self.batch_size * self.choice_num - index = 0 - for examples in examples_list: - records = [] - gather_idx_candidate = [] - for example in examples: - if example.cal_loss == 1: - gather_idx_candidate.append(index % real_batch_size) - max_len = max(max_len, len(example.src_ids)) - records.append(example) - index += 1 - - if self.in_tokens: - to_append = (len(batch_records) + 1) * self.choice_num * max_len <= self.batch_size - else: - to_append = len(batch_records) < self.batch_size - if to_append: - batch_records.append(records) - gather_idx += gather_idx_candidate - else: - yield self._pad_batch_records(batch_records, gather_idx) - batch_records, max_len = [records], max(len(record.src_ids) for record in records) - gather_idx = gather_idx_candidate - if len(batch_records) > 0: - yield self._pad_batch_records(batch_records, gather_idx) - - def _get_samples(self, pre_batch_list, is_last=False): - if is_last: - # Pad batch - len_doc = [[len(doc) for doc in doc_list] for doc_list in pre_batch_list] - len_doc = list(itertools.chain(*len_doc)) - max_len_idx = len_doc.index(max(len_doc)) - doc_idx = max_len_idx % self.choice_num - doc_list_idx = max_len_idx // self.choice_num - dirty_sample = pre_batch_list[doc_list_idx][doc_idx][-1]._replace(cal_loss=0) - for sample_list in pre_batch_list: - for samples in sample_list: - samples.extend([dirty_sample] * (max(len_doc) - len(samples))) - samples = [] - min_len = min([len(doc) for doc in pre_batch_list]) - for cnt in range(min_len): - for batch_idx in range(self.batch_size * self.trainer_num): - sample = pre_batch_list[batch_idx][cnt] - samples.append(sample) - - for idx in range(len(pre_batch_list)): - pre_batch_list[idx] = pre_batch_list[idx][min_len:] - return samples - - -class SemanticMatchingIterator(MRCIterator): - def _convert_qa_to_examples(self): - Example = namedtuple("Example", ["qid", "text_a", "text_b", "text_c", "label"]) - examples = [] - for qid, qa in enumerate(self.dataset): - text_a, text_b, text_c = list( - map(lambda x: x.replace("\n", "").strip(), [qa["text_a"], qa["text_b"], qa["text_c"]]) - ) - - example = Example(qid=qid, text_a=text_a, text_b=text_b, text_c=text_c, label=qa["label"]) - examples += [example] - return examples - - def _create_tokens_and_type_id(self, text_a_tokens, text_b_tokens, start, length): - tokens = ( - ["[CLS]"] - + text_a_tokens[start : start + length] - + ["[SEP]"] - + text_b_tokens[start : start + length] - + ["[SEP]"] - ) - token_type_ids = [0] + [0] * (length + 1) + [1] * (length + 1) - return tokens, token_type_ids - - def _convert_example_to_feature(self, examples): - Feature = namedtuple( - "Feature", ["qid", "src_ids", "segment_ids", "pair_src_ids", "pair_segment_ids", "label", "cal_loss"] - ) - features = [] - self.features_all = [] - for (ex_index, example) in enumerate(examples): - text_a_tokens = self.tokenizer.tokenize(example.text_a) - text_b_tokens = self.tokenizer.tokenize(example.text_b) - text_c_tokens = self.tokenizer.tokenize(example.text_c) - a_len, b_len, c_len = list(map(lambda x: len(x), [text_a_tokens, text_b_tokens, text_c_tokens])) - - # Align 3 text - min_text_len = min([a_len, b_len, c_len]) - text_a_tokens = text_a_tokens[:min_text_len] - text_b_tokens = text_b_tokens[:min_text_len] - text_c_tokens = text_c_tokens[:min_text_len] - - _DocSpan = namedtuple("DocSpan", ["start", "length"]) - doc_spans = [] - start_offset = 0 - - max_tokens_for_doc = (self.max_seq_length - 3) // 2 - - while start_offset < len(text_a_tokens): - length = len(text_a_tokens) - start_offset - if length > max_tokens_for_doc: - length = max_tokens_for_doc - doc_spans.append(_DocSpan(start=start_offset, length=length)) - if start_offset + length == len(text_a_tokens): - break - start_offset += min(length, self.doc_stride) - - features_each = [] - for (doc_span_index, doc_span) in enumerate(doc_spans): - tokens1, token_type_ids1 = self._create_tokens_and_type_id( - text_a_tokens, text_b_tokens, doc_span.start, doc_span.length - ) - tokens2, token_type_ids2 = self._create_tokens_and_type_id( - text_a_tokens, text_c_tokens, doc_span.start, doc_span.length - ) - - input_ids1 = self.tokenizer.convert_tokens_to_ids(tokens1) - input_ids2 = self.tokenizer.convert_tokens_to_ids(tokens2) - feature = Feature( - qid=example.qid, - label=example.label, - src_ids=input_ids1, - segment_ids=token_type_ids1, - pair_src_ids=input_ids2, - pair_segment_ids=token_type_ids2, - cal_loss=1, - ) - - features.append(feature) - features_each.append(feature) - - # Repeat - if self.repeat_input: - features_each_repeat = features_each - features_each = list(map(lambda x: x._replace(cla_loss=0), features_each)) - features_each += features_each_repeat - - self.features_all.append(features_each) - - return features - - def _create_pad_ids(self, batch_records, prefix=""): - src_ids = prefix + "src_ids" - segment_ids = prefix + "segment_ids" - batch_token_ids = [getattr(record, src_ids) for record in batch_records] - batch_task_ids = [getattr(record, segment_ids) for record in batch_records] - - # Padding - padded_token_ids, input_mask = pad_batch_data( - batch_token_ids, - pad_idx=self.tokenizer.pad_token_id, - pad_max_len=self.max_seq_length, - return_input_mask=True, - ) - padded_task_ids = pad_batch_data( - batch_task_ids, pad_idx=self.tokenizer.pad_token_id, pad_max_len=self.max_seq_length - ) - - padded_position_ids = get_related_pos(padded_task_ids, self.max_seq_length, self.memory_len) - - return [padded_token_ids, padded_position_ids, padded_task_ids, input_mask] - - def _pad_batch_records(self, batch_records, gather_idx=[]): - if batch_records[0].label is not None: - batch_labels = [record.label for record in batch_records] - batch_labels = np.array(batch_labels).astype("int64").reshape([-1, 1]) - else: - batch_labels = np.array([]).astype("int64").reshape([-1, 1]) - # Qid - batch_qids = [record.qid for record in batch_records] - batch_qids = np.array(batch_qids).astype("int64").reshape([-1, 1]) - - if gather_idx: - batch_gather_idx = np.array(gather_idx).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([1]).astype("int64") - else: - batch_gather_idx = np.array(list(range(len(batch_records)))).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([0]).astype("int64") - - return_list = ( - self._create_pad_ids(batch_records) - + self._create_pad_ids(batch_records, "pair_") - + [batch_labels, batch_qids, batch_gather_idx, need_cal_loss] - ) - return return_list - - -class SequenceLabelingIterator(ClassifierIterator): - def __init__( - self, - dataset, - batch_size, - tokenizer, - trainer_num, - trainer_id, - max_seq_length=512, - memory_len=128, - repeat_input=False, - in_tokens=False, - mode="train", - random_seed=None, - no_entity_id=-1, - ): - super(SequenceLabelingIterator, self).__init__( - dataset, - batch_size, - tokenizer, - trainer_num, - trainer_id, - max_seq_length, - memory_len, - repeat_input, - in_tokens, - mode, - random_seed, - preprocess_text_fn=None, - ) - self.no_entity_id = no_entity_id - - def _convert_to_features(self, example, qid): - """ - Convert example to features fed into model - """ - tokens = example["tokens"] - label = example["labels"] - doc_spans = [] - _DocSpan = namedtuple("DocSpan", ["start", "length"]) - start_offset = 0 - max_tokens_for_doc = self.max_seq_length - 2 - while start_offset < len(tokens): - length = len(tokens) - start_offset - if length > max_tokens_for_doc: - length = max_tokens_for_doc - doc_spans.append(_DocSpan(start=start_offset, length=length)) - if start_offset + length == len(tokens): - break - start_offset += min(length, self.memory_len) - - features = [] - Feature = namedtuple("Feature", ["src_ids", "label_ids", "qid", "cal_loss"]) - for (doc_span_index, doc_span) in enumerate(doc_spans): - curr_tokens = ["[CLS]"] + tokens[doc_span.start : doc_span.start + doc_span.length] + ["[SEP]"] - token_ids = self.tokenizer.convert_tokens_to_ids(curr_tokens) - label = ( - [self.no_entity_id] + label[doc_span.start : doc_span.start + doc_span.length] + [self.no_entity_id] - ) - - features.append(Feature(src_ids=token_ids, label_ids=label, qid=qid, cal_loss=1)) - - if self.repeat_input: - features_repeat = features - features = list(map(lambda x: x._replace(cal_loss=0), features)) - features = features + features_repeat - return features - - def _pad_batch_records(self, batch_records, gather_idx=[]): - batch_token_ids = [record.src_ids for record in batch_records] - batch_length = [len(record.src_ids) for record in batch_records] - batch_length = np.array(batch_length).astype("int64").reshape([-1, 1]) - - if batch_records[0].label_ids is not None: - batch_labels = [record.label_ids for record in batch_records] - else: - batch_labels = np.array([]).astype("int64").reshape([-1, 1]) - # Qid - if batch_records[-1].qid is not None: - batch_qids = [record.qid for record in batch_records] - batch_qids = np.array(batch_qids).astype("int64").reshape([-1, 1]) - else: - batch_qids = np.array([]).astype("int64").reshape([-1, 1]) - - if gather_idx: - batch_gather_idx = np.array(gather_idx).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([1]).astype("int64") - else: - batch_gather_idx = np.array(list(range(len(batch_records)))).astype("int64").reshape([-1, 1]) - need_cal_loss = np.array([0]).astype("int64") - # Padding - padded_token_ids, input_mask = pad_batch_data( - batch_token_ids, - pad_idx=self.tokenizer.pad_token_id, - pad_max_len=self.max_seq_length, - return_input_mask=True, - ) - if batch_records[0].label_ids is not None: - padded_batch_labels = pad_batch_data( - batch_labels, pad_idx=self.no_entity_id, pad_max_len=self.max_seq_length - ) - padded_task_ids = np.zeros_like(padded_token_ids, dtype="int64") - padded_position_ids = get_related_pos(padded_token_ids, self.max_seq_length, self.memory_len) - - return_list = [ - padded_token_ids, - padded_position_ids, - padded_task_ids, - input_mask, - padded_batch_labels, - batch_length, - batch_qids, - batch_gather_idx, - need_cal_loss, - ] - return return_list diff --git a/model_zoo/ernie-doc/metrics.py b/model_zoo/ernie-doc/metrics.py deleted file mode 100644 index 41777f1d106c..000000000000 --- a/model_zoo/ernie-doc/metrics.py +++ /dev/null @@ -1,367 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import collections -import sys - -import numpy as np -import paddle -from paddle.utils import try_import - -from paddlenlp.metrics.dureader import ( - _compute_softmax, - _get_best_indexes, - get_final_text, -) - -# Metric for ERNIE-DOCs - - -class F1(object): - def __init__(self, positive_label=1): - self.positive_label = positive_label - self.reset() - - def compute(self, preds, labels): - if isinstance(preds, paddle.Tensor): - preds = preds.numpy() - elif isinstance(preds, list): - preds = np.array(preds, dtype="float32") - if isinstance(labels, list): - labels = np.array(labels, dtype="int64") - elif isinstance(labels, paddle.Tensor): - labels = labels.numpy() - preds = np.argmax(preds, axis=1) - tp = ((preds == labels) & (labels == self.positive_label)).sum() - fn = ((preds != labels) & (labels == self.positive_label)).sum() - fp = ((preds != labels) & (preds == self.positive_label)).sum() - return tp, fp, fn - - def update(self, statistic): - tp, fp, fn = statistic - self.tp += tp - self.fp += fp - self.fn += fn - - def accumulate(self): - recall = self.tp / (self.tp + self.fn) - precision = self.tp / (self.tp + self.fp) - f1 = 2 * recall * precision / (recall + precision) - return f1 - - def reset(self): - self.tp = 0 - self.fp = 0 - self.fn = 0 - - -class EM_AND_F1(object): - def __init__(self): - self.nltk = try_import("nltk") - self.re = try_import("re") - - def _mixed_segmentation(self, in_str, rm_punc=False): - """mixed_segmentation""" - in_str = in_str.lower().strip() - segs_out = [] - temp_str = "" - sp_char = [ - "-", - ":", - "_", - "*", - "^", - "/", - "\\", - "~", - "`", - "+", - "=", - ",", - "。", - ":", - "?", - "!", - "“", - "”", - ";", - "’", - "《", - "》", - "……", - "·", - "、", - "「", - "」", - "(", - ")", - "-", - "~", - "『", - "』", - ] - for char in in_str: - if rm_punc and char in sp_char: - continue - pattern = "[\\u4e00-\\u9fa5]" - if self.re.search(pattern, char) or char in sp_char: - if temp_str != "": - ss = self.nltk.word_tokenize(temp_str) - segs_out.extend(ss) - temp_str = "" - segs_out.append(char) - else: - temp_str += char - - # Handling last part - if temp_str != "": - ss = self.nltk.word_tokenize(temp_str) - segs_out.extend(ss) - - return segs_out - - # Remove punctuation - def _remove_punctuation(self, in_str): - """remove_punctuation""" - in_str = in_str.lower().strip() - sp_char = [ - "-", - ":", - "_", - "*", - "^", - "/", - "\\", - "~", - "`", - "+", - "=", - ",", - "。", - ":", - "?", - "!", - "“", - "”", - ";", - "’", - "《", - "》", - "……", - "·", - "、", - "「", - "」", - "(", - ")", - "-", - "~", - "『", - "』", - ] - out_segs = [] - for char in in_str: - if char in sp_char: - continue - else: - out_segs.append(char) - return "".join(out_segs) - - # Find longest common string - def _find_lcs(self, s1, s2): - m = [[0 for i in range(len(s2) + 1)] for j in range(len(s1) + 1)] - mmax = 0 - p = 0 - for i in range(len(s1)): - for j in range(len(s2)): - if s1[i] == s2[j]: - m[i + 1][j + 1] = m[i][j] + 1 - if m[i + 1][j + 1] > mmax: - mmax = m[i + 1][j + 1] - p = i + 1 - return s1[p - mmax : p], mmax - - def _calc_f1_score(self, answers, prediction): - f1_scores = [] - for ans in answers: - ans_segs = self._mixed_segmentation(ans, rm_punc=True) - prediction_segs = self._mixed_segmentation(prediction, rm_punc=True) - lcs, lcs_len = self._find_lcs(ans_segs, prediction_segs) - if lcs_len == 0: - f1_scores.append(0) - continue - precision = 1.0 * lcs_len / len(prediction_segs) - recall = 1.0 * lcs_len / len(ans_segs) - f1 = (2 * precision * recall) / (precision + recall) - f1_scores.append(f1) - return max(f1_scores) - - def _calc_em_score(self, answers, prediction): - em = 0 - for ans in answers: - ans_ = self._remove_punctuation(ans) - prediction_ = self._remove_punctuation(prediction) - if ans_ == prediction_: - em = 1 - break - return em - - def __call__(self, prediction, ground_truth): - f1 = 0 - em = 0 - total_count = 0 - skip_count = 0 - for instance in ground_truth: - total_count += 1 - query_id = instance["id"] - answers = instance["answers"] - if query_id not in prediction: - sys.stderr.write("Unanswered question: {}\n".format(query_id)) - skip_count += 1 - continue - preds = str(prediction[query_id]) - f1 += self._calc_f1_score(answers, preds) - em += self._calc_em_score(answers, preds) - - f1_score = 100.0 * f1 / total_count - em_score = 100.0 * em / total_count - - avg_score = (f1_score + em_score) * 0.5 - return em_score, f1_score, avg_score, total_count - - -def compute_qa_predictions( - all_examples, all_features, all_results, n_best_size, max_answer_length, do_lower_case, tokenizer, verbose -): - """Write final predictions to the json file and log-odds of null if needed.""" - - example_index_to_features = collections.defaultdict(list) - for feature in all_features: - example_index_to_features[feature.example_index].append(feature) - - unique_id_to_result = {} - for result in all_results: - unique_id_to_result[result.unique_id] = result - - _PrelimPrediction = collections.namedtuple( # pylint: disable=invalid-name - "PrelimPrediction", ["feature_index", "start_index", "end_index", "start_logit", "end_logit"] - ) - - all_predictions = collections.OrderedDict() - all_nbest_json = collections.OrderedDict() - - for (example_index, example) in enumerate(all_examples): - features = example_index_to_features[example_index] - - prelim_predictions = [] - # Keep track of the minimum score of null start+end of position 0 - for (feature_index, feature) in enumerate(features): - result = unique_id_to_result[feature.qid] - start_indexes = _get_best_indexes(result.start_logits, n_best_size) - end_indexes = _get_best_indexes(result.end_logits, n_best_size) - - for start_index in start_indexes: - for end_index in end_indexes: - # We could hypothetically create invalid predictions, e.g., predict - # that the start of the span is in the question. We throw out all - # invalid predictions. - if start_index >= len(feature.tokens): - continue - if end_index >= len(feature.tokens): - continue - if start_index not in feature.token_to_orig_map: - continue - if end_index not in feature.token_to_orig_map: - continue - if not feature.token_is_max_context.get(start_index, False): - continue - if end_index < start_index: - continue - length = end_index - start_index + 1 - if length > max_answer_length: - continue - prelim_predictions.append( - _PrelimPrediction( - feature_index=feature_index, - start_index=start_index, - end_index=end_index, - start_logit=result.start_logits[start_index], - end_logit=result.end_logits[end_index], - ) - ) - - prelim_predictions = sorted(prelim_predictions, key=lambda x: (x.start_logit + x.end_logit), reverse=True) - - _NbestPrediction = collections.namedtuple( # pylint: disable=invalid-name - "NbestPrediction", ["text", "start_logit", "end_logit"] - ) - - seen_predictions = {} - nbest = [] - for pred in prelim_predictions: - if len(nbest) >= n_best_size: - break - feature = features[pred.feature_index] - if pred.start_index > 0: # this is a non-null prediction - tok_tokens = feature.tokens[pred.start_index : (pred.end_index + 1)] - orig_doc_start = feature.token_to_orig_map[pred.start_index] - orig_doc_end = feature.token_to_orig_map[pred.end_index] - orig_tokens = example.doc_tokens[orig_doc_start : (orig_doc_end + 1)] - tok_text = " ".join(tok_tokens) - - # De-tokenize WordPieces that have been split off. - tok_text = tok_text.replace(" ##", "") - tok_text = tok_text.replace("##", "") - - # Clean whitespace - tok_text = tok_text.strip() - tok_text = " ".join(tok_text.split()) - orig_text = "".join(orig_tokens) - - final_text = get_final_text(tok_text, orig_text, tokenizer, verbose) - if final_text in seen_predictions: - continue - - seen_predictions[final_text] = True - else: - final_text = "" - seen_predictions[final_text] = True - - nbest.append(_NbestPrediction(text=final_text, start_logit=pred.start_logit, end_logit=pred.end_logit)) - - # In very rare edge cases we could have no valid predictions. So we - # just create a nonce prediction in this case to avoid failure. - if not nbest: - nbest.append(_NbestPrediction(text="empty", start_logit=0.0, end_logit=0.0)) - - total_scores = [] - for entry in nbest: - total_scores.append(entry.start_logit + entry.end_logit) - - probs = _compute_softmax(total_scores) - - nbest_json = [] - for (i, entry) in enumerate(nbest): - output = collections.OrderedDict() - output["text"] = entry.text - output["probability"] = probs[i] - output["start_logit"] = entry.start_logit - output["end_logit"] = entry.end_logit - nbest_json.append(output) - - assert len(nbest_json) >= 1 - - all_predictions[example.qas_id] = nbest_json[0]["text"] - all_nbest_json[example.qas_id] = nbest_json - return all_predictions, all_nbest_json diff --git a/model_zoo/ernie-doc/model.py b/model_zoo/ernie-doc/model.py deleted file mode 100644 index 5fd3e622596a..000000000000 --- a/model_zoo/ernie-doc/model.py +++ /dev/null @@ -1,50 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import paddle.nn as nn - - -class ErnieDocForTextMatching(nn.Layer): - def __init__(self, ernie_doc, num_classes=2, dropout=None): - super().__init__() - self.ernie_doc = ernie_doc - self.dropout = nn.Dropout(dropout if dropout is not None else 0.1) - self.classifier = nn.Linear(ernie_doc.config["hidden_size"], num_classes) - - def forward( - self, - query_input_ids, - title_input_ids, - query_memories, - title_memories, - query_token_type_ids=None, - query_position_ids=None, - query_attention_mask=None, - title_token_type_ids=None, - title_position_ids=None, - title_attention_mask=None, - ): - - _, query_pooled_output, query_mem, = self.ernie_doc( - query_input_ids, query_memories, query_token_type_ids, query_position_ids, query_attention_mask - ) - - _, title_pooled_output, title_mem = self.ernie_doc( - title_input_ids, title_memories, title_token_type_ids, title_position_ids, title_attention_mask - ) - - diff_pooled_output = query_pooled_output - title_pooled_output - diff_pooled_output = self.dropout(diff_pooled_output) - output = self.classifier(diff_pooled_output) - return output, query_mem, title_mem diff --git a/model_zoo/ernie-doc/run_classifier.py b/model_zoo/ernie-doc/run_classifier.py deleted file mode 100644 index a2985189f416..000000000000 --- a/model_zoo/ernie-doc/run_classifier.py +++ /dev/null @@ -1,323 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os -import random -import time -from collections import defaultdict -from functools import partial - -import numpy as np -import paddle -import paddle.nn as nn -from data import ClassifierIterator, HYPTextPreprocessor, ImdbTextPreprocessor -from metrics import F1 -from paddle.metric import Accuracy -from paddle.optimizer import AdamW - -from paddlenlp.ops.optimizer import layerwise_lr_decay -from paddlenlp.transformers import ( - ErnieDocBPETokenizer, - ErnieDocForSequenceClassification, - ErnieDocTokenizer, - LinearDecayWithWarmup, -) -from paddlenlp.utils.log import logger - -# fmt: off -parser = argparse.ArgumentParser() -parser.add_argument("--batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument("--model_name_or_path", type=str, default="ernie-doc-base-en", help="Pretraining model name or path") -parser.add_argument("--max_seq_length", type=int, default=512, help="The maximum total input sequence length after SentencePiece tokenization.") -parser.add_argument("--learning_rate", type=float, default=7e-5, help="Learning rate used to train.") -parser.add_argument("--save_steps", type=int, default=1000, help="Save checkpoint every X updates steps.") -parser.add_argument("--logging_steps", type=int, default=1, help="Log every X updates steps.") -parser.add_argument("--output_dir", type=str, default='checkpoints/', help="Directory to save model checkpoint") -parser.add_argument("--epochs", type=int, default=3, help="Number of epoches for training.") -parser.add_argument("--device", type=str, default="gpu", choices=["cpu", "gpu"], help="Select cpu, gpu devices to train model.") -parser.add_argument("--seed", type=int, default=1, help="Random seed for initialization.") -parser.add_argument("--memory_length", type=int, default=128, help="Length of the retained previous heads.") -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") -parser.add_argument("--warmup_proportion", default=0.1, type=float, help="Linear warmup proportion over the training process.") -parser.add_argument("--dataset", default="imdb", choices=["imdb", "iflytek", "thucnews", "hyp"], type=str, help="The training dataset") -parser.add_argument("--layerwise_decay", default=1.0, type=float, help="Layerwise decay ratio") -parser.add_argument("--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override num_train_epochs.",) -args = parser.parse_args() -# fmt: on - -# tokenizer, eval_dataset, test_dataset, preprocess_text_fn, metric -# BPETokenizer for English Tasks -# ErnieDocTokenizer for Chinese Tasks - -DATASET_INFO = { - "imdb": (ErnieDocBPETokenizer, "test", "test", ImdbTextPreprocessor(), Accuracy()), - "hyp": (ErnieDocBPETokenizer, "dev", "test", HYPTextPreprocessor(), F1()), - "iflytek": (ErnieDocTokenizer, "validation", "test", None, Accuracy()), - "thucnews": (ErnieDocTokenizer, "dev", "test", None, Accuracy()), -} - - -def set_seed(args): - # Use the same data seed(for data shuffle) for all procs to guarantee data - # consistency after sharding. - random.seed(args.seed) - np.random.seed(args.seed) - # Maybe different op seeds(for dropout) for different procs is better. By: - # `paddle.seed(args.seed + paddle.distributed.get_rank())` - paddle.seed(args.seed) - - -def init_memory(batch_size, memory_length, d_model, n_layers): - return [paddle.zeros([batch_size, memory_length, d_model], dtype="float32") for _ in range(n_layers)] - - -@paddle.no_grad() -def evaluate(model, metric, data_loader, memories0): - model.eval() - losses = [] - # copy the memory - memories = list(memories0) - tic_train = time.time() - eval_logging_step = 500 - - probs_dict = defaultdict(list) - label_dict = dict() - for step, batch in enumerate(data_loader, start=1): - input_ids, position_ids, token_type_ids, attn_mask, labels, qids, gather_idxs, need_cal_loss = batch - logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - logits, labels, qids = list(map(lambda x: paddle.gather(x, gather_idxs), [logits, labels, qids])) - # Need to collect probs for each qid, so use softmax_with_cross_entropy - loss, probs = nn.functional.softmax_with_cross_entropy(logits, labels, return_softmax=True) - losses.append(loss.mean().numpy()) - # Shape: [B, NUM_LABELS] - np_probs = probs.numpy() - # Shape: [B, 1] - np_qids = qids.numpy() - np_labels = labels.numpy().flatten() - for i, qid in enumerate(np_qids.flatten()): - probs_dict[qid].append(np_probs[i]) - label_dict[qid] = np_labels[i] # Same qid share same label. - - if step % eval_logging_step == 0: - logger.info( - "Step %d: loss: %.5f, speed: %.5f steps/s" - % (step, np.mean(losses), eval_logging_step / (time.time() - tic_train)) - ) - tic_train = time.time() - - # Collect predicted labels - preds = [] - labels = [] - for qid, probs in probs_dict.items(): - mean_prob = np.mean(np.array(probs), axis=0) - preds.append(mean_prob) - labels.append(label_dict[qid]) - - preds = paddle.to_tensor(np.array(preds, dtype="float32")) - labels = paddle.to_tensor(np.array(labels, dtype="int64")) - - metric.update(metric.compute(preds, labels)) - acc_or_f1 = metric.accumulate() - logger.info("Eval loss: %.5f, %s: %.5f" % (np.mean(losses), metric.__class__.__name__, acc_or_f1)) - metric.reset() - model.train() - return acc_or_f1 - - -def do_train(args): - set_seed(args) - tokenizer_class, eval_name, test_name, preprocess_text_fn, eval_metric = DATASET_INFO[args.dataset] - tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path) - if args.dataset in ["hyp", "thucnews"]: - from paddlenlp.datasets import load_dataset - - train_ds, eval_ds, test_ds = load_dataset(args.dataset, splits=["train", eval_name, test_name]) - num_classes = len(train_ds.label_list) - - else: - from datasets import load_dataset - - # Get dataset - if args.dataset == "iflytek": - - train_ds, eval_ds, test_ds = load_dataset("clue", name=args.dataset, split=["train", eval_name, test_name]) - else: - train_ds, eval_ds = load_dataset(args.dataset, split=["train", eval_name]) - test_ds = eval_ds - num_classes = train_ds.features["label"].num_classes - - # Initialize model - paddle.set_device(args.device) - trainer_num = paddle.distributed.get_world_size() - if trainer_num > 1: - paddle.distributed.init_parallel_env() - rank = paddle.distributed.get_rank() - if rank == 0: - if os.path.exists(args.model_name_or_path): - logger.info("init checkpoint from %s" % args.model_name_or_path) - model = ErnieDocForSequenceClassification.from_pretrained(args.model_name_or_path, num_classes=num_classes) - model_config = model.ernie_doc.config - if trainer_num > 1: - model = paddle.DataParallel(model) - - train_ds_iter = ClassifierIterator( - train_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - preprocess_text_fn=preprocess_text_fn, - ) - eval_ds_iter = ClassifierIterator( - eval_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - mode="eval", - preprocess_text_fn=preprocess_text_fn, - ) - test_ds_iter = ClassifierIterator( - test_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - mode="test", - preprocess_text_fn=preprocess_text_fn, - ) - - train_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - eval_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - eval_dataloader.set_batch_generator(eval_ds_iter, paddle.get_device()) - test_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - test_dataloader.set_batch_generator(test_ds_iter, paddle.get_device()) - - num_training_examples = train_ds_iter.get_num_examples() - num_training_steps = args.epochs * num_training_examples // args.batch_size // trainer_num - logger.info("Device count: %d, trainer_id: %d" % (trainer_num, rank)) - logger.info("Num train examples: %d" % num_training_examples) - logger.info("Max train steps: %d" % num_training_steps) - logger.info("Num warmup steps: %d" % int(num_training_steps * args.warmup_proportion)) - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - # Construct dict - name_dict = dict() - for n, p in model.named_parameters(): - name_dict[p.name] = n - - simple_lr_setting = partial(layerwise_lr_decay, args.layerwise_decay, name_dict, model_config["num_hidden_layers"]) - - optimizer = AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - lr_ratio=simple_lr_setting, - ) - - criterion = paddle.nn.loss.CrossEntropyLoss() - metric = paddle.metric.Accuracy() - - global_steps = 0 - best_acc = -1 - create_memory = partial( - init_memory, - args.batch_size, - args.memory_length, - model_config["hidden_size"], - model_config["num_hidden_layers"], - ) - # Copy the memory - memories = create_memory() - tic_train = time.time() - stop_training = False - for epoch in range(args.epochs): - train_ds_iter.shuffle_sample() - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - for step, batch in enumerate(train_dataloader, start=1): - global_steps += 1 - input_ids, position_ids, token_type_ids, attn_mask, labels, qids, gather_idx, need_cal_loss = batch - logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - - logits, labels = list(map(lambda x: paddle.gather(x, gather_idx), [logits, labels])) - loss = criterion(logits, labels) * need_cal_loss - mean_loss = loss.mean() - mean_loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - # Rough acc result, not a precise acc - acc = metric.compute(logits, labels) * need_cal_loss - metric.update(acc) - - if global_steps % args.logging_steps == 0: - logger.info( - "train: global step %d, epoch: %d, loss: %f, acc:%f, lr: %f, speed: %.2f step/s" - % ( - global_steps, - epoch, - mean_loss, - metric.accumulate(), - lr_scheduler.get_lr(), - args.logging_steps / (time.time() - tic_train), - ) - ) - tic_train = time.time() - - if global_steps % args.save_steps == 0: - # Evaluate - logger.info("Eval:") - eval_acc = evaluate(model, eval_metric, eval_dataloader, create_memory()) - # Save - if rank == 0: - output_dir = os.path.join(args.output_dir, "model_%d" % (global_steps)) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - model_to_save.save_pretrained(output_dir) - tokenizer.save_pretrained(output_dir) - if eval_acc > best_acc: - logger.info("Save best model......") - best_acc = eval_acc - best_model_dir = os.path.join(args.output_dir, "best_model") - if not os.path.exists(best_model_dir): - os.makedirs(best_model_dir) - model_to_save.save_pretrained(best_model_dir) - tokenizer.save_pretrained(best_model_dir) - - if args.max_steps > 0 and global_steps >= args.max_steps: - stop_training = True - break - if stop_training: - break - logger.info("Final test result:") - eval_acc = evaluate(model, eval_metric, test_dataloader, create_memory()) - - -if __name__ == "__main__": - do_train(args) diff --git a/model_zoo/ernie-doc/run_mcq.py b/model_zoo/ernie-doc/run_mcq.py deleted file mode 100644 index 4050959fa8c7..000000000000 --- a/model_zoo/ernie-doc/run_mcq.py +++ /dev/null @@ -1,306 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os -import random -import time -from collections import defaultdict -from functools import partial - -import numpy as np -import paddle -import paddle.nn as nn -from data import MCQIterator -from paddle.metric import Accuracy -from paddle.optimizer import AdamW - -from paddlenlp.datasets import load_dataset -from paddlenlp.ops.optimizer import layerwise_lr_decay -from paddlenlp.transformers import ( - ErnieDocForSequenceClassification, - ErnieDocTokenizer, - LinearDecayWithWarmup, -) -from paddlenlp.utils.log import logger - -# fmt: off -parser = argparse.ArgumentParser() -parser.add_argument("--model_name_or_path", type=str, default="ernie-doc-base-zh", help="Pretraining model name or path") -parser.add_argument("--max_seq_length", type=int, default=512, help="The maximum total input sequence length after SentencePiece tokenization.") -parser.add_argument("--learning_rate", type=float, default=1e-4, help="Learning rate used to train.") -parser.add_argument("--save_steps", type=int, default=1000, help="Save checkpoint every X updates steps.") -parser.add_argument("--logging_steps", type=int, default=1, help="Log every X updates steps.") -parser.add_argument("--output_dir", type=str, default='checkpoints/', help="Directory to save model checkpoint") -parser.add_argument("--epochs", type=int, default=8, help="Number of epoches for training.") -parser.add_argument("--device", type=str, default="gpu", choices=["cpu", "gpu"], help="Select cpu, gpu devices to train model.") -parser.add_argument("--seed", type=int, default=1, help="Random seed for initialization.") -parser.add_argument("--memory_length", type=int, default=128, help="Length of the retained previous heads.") -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") -parser.add_argument("--warmup_proportion", default=0.1, type=float, help="Linear warmup proportion over the training process.") -parser.add_argument("--dataset", default="c3", choices=["c3"], type=str, help="The training dataset") -parser.add_argument("--layerwise_decay", default=0.8, type=float, help="Layerwise decay ratio") -parser.add_argument("--batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument("--gradient_accumulation_steps", default=4, type=int, help="Number of updates steps to accumualte before performing a backward/update pass.") -parser.add_argument("--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override num_train_epochs.",) -args = parser.parse_args() -# fmt: on - - -DATASET_INFO = { - "c3": (ErnieDocTokenizer, "dev", "test", Accuracy()), -} - - -def set_seed(args): - random.seed(args.seed) - np.random.seed(args.seed) - paddle.seed(args.seed) - - -def init_memory(batch_size, memory_length, d_model, n_layers): - return [paddle.zeros([batch_size, memory_length, d_model], dtype="float32") for _ in range(n_layers)] - - -@paddle.no_grad() -def evaluate(model, metric, data_loader, memories0, choice_num): - model.eval() - losses = [] - # Copy the memory - memories = list(memories0) - tic_train = time.time() - eval_logging_step = 500 - - probs_dict = defaultdict(list) - label_dict = dict() - for step, batch in enumerate(data_loader, start=1): - input_ids, position_ids, token_type_ids, attn_mask, labels, qids, gather_idxs, need_cal_loss = batch - logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - logits, labels, qids = list(map(lambda x: paddle.gather(x, gather_idxs), [logits, labels, qids])) - logits = logits.reshape([-1, choice_num]) - labels = labels.reshape([-1, choice_num, 1])[:, 0] - qids = qids.reshape([-1, choice_num, 1])[:, 0] - loss, probs = nn.functional.softmax_with_cross_entropy(logits, labels, return_softmax=True) - losses.append(loss.mean().numpy()) - # Shape: [B, NUM_LABELS] - np_probs = probs.numpy() - # Shape: [B, 1] - np_qids = qids.numpy().flatten() - np_labels = labels.numpy().flatten() - for i, qid in enumerate(np_qids): - probs_dict[qid].append(np_probs[i]) - label_dict[qid] = np_labels[i] # Same qid share same label. - - if step % eval_logging_step == 0: - logger.info( - "Step %d: loss: %.5f, speed: %.5f steps/s" - % (step, np.mean(losses), eval_logging_step / (time.time() - tic_train)) - ) - tic_train = time.time() - - # Collect predicted labels - preds = [] - labels = [] - logger.info("Total {} qustion".format(len(probs_dict))) - for qid, probs in probs_dict.items(): - mean_prob = np.mean(np.array(probs), axis=0) - preds.append(mean_prob) - labels.append(label_dict[qid]) - - preds = paddle.to_tensor(np.array(preds, dtype="float32")) - labels = paddle.to_tensor(np.array(labels, dtype="int64")) - - metric.update(metric.compute(preds, labels)) - acc_or_f1 = metric.accumulate() - metric.reset() - logger.info("Eval loss: %.5f, %s: %.5f" % (np.mean(losses), metric.__class__.__name__, acc_or_f1)) - model.train() - return acc_or_f1 - - -def do_train(args): - set_seed(args) - tokenizer_class, eval_name, test_name, eval_metric = DATASET_INFO[args.dataset] - tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path) - - # Get dataset - train_ds, eval_ds, test_ds = load_dataset(args.dataset, splits=["train", eval_name, test_name]) - - num_classes = len(train_ds.label_list) - - # Initialize model - paddle.set_device(args.device) - trainer_num = paddle.distributed.get_world_size() - if trainer_num > 1: - paddle.distributed.init_parallel_env() - rank = paddle.distributed.get_rank() - if rank == 0: - if os.path.exists(args.model_name_or_path): - logger.info("init checkpoint from %s" % args.model_name_or_path) - model = ErnieDocForSequenceClassification.from_pretrained(args.model_name_or_path, num_classes=1, cls_token_idx=0) - model_config = model.ernie_doc.config - if trainer_num > 1: - model = paddle.DataParallel(model) - batch_size = int(args.batch_size / args.gradient_accumulation_steps) - train_ds_iter = MCQIterator( - train_ds, - batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - choice_num=num_classes, - ) - - eval_ds_iter = MCQIterator( - eval_ds, - batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - mode="eval", - choice_num=num_classes, - ) - - test_ds_iter = MCQIterator( - test_ds, - batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - mode="test", - choice_num=num_classes, - ) - - train_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - eval_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - eval_dataloader.set_batch_generator(eval_ds_iter, paddle.get_device()) - test_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - test_dataloader.set_batch_generator(test_ds_iter, paddle.get_device()) - - num_training_examples = train_ds_iter.get_num_examples() - num_training_steps = args.epochs * num_training_examples // args.batch_size // trainer_num - logger.info("Device count: %d, trainer_id: %d" % (trainer_num, rank)) - logger.info("Num train examples: %d" % num_training_examples) - logger.info("Max train steps: %d" % num_training_steps) - logger.info("Num warmup steps: %d" % int(num_training_steps * args.warmup_proportion)) - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - # Construct dict - name_dict = dict() - for n, p in model.named_parameters(): - name_dict[p.name] = n - - simple_lr_setting = partial(layerwise_lr_decay, args.layerwise_decay, name_dict, model_config["num_hidden_layers"]) - - optimizer = AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - lr_ratio=simple_lr_setting, - ) - - criterion = paddle.nn.loss.CrossEntropyLoss() - metric = paddle.metric.Accuracy() - - global_steps = 1 - best_acc = -1 - create_memory = partial( - init_memory, - batch_size * num_classes, - args.memory_length, - model_config["hidden_size"], - model_config["num_hidden_layers"], - ) - # Copy the memory - memories = create_memory() - tic_train = time.time() - - for epoch in range(args.epochs): - train_ds_iter.shuffle_sample() - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - for step, batch in enumerate(train_dataloader, start=1): - input_ids, position_ids, token_type_ids, attn_mask, labels, qids, gather_idx, need_cal_loss = batch - logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - logits, labels = list(map(lambda x: paddle.gather(x, gather_idx), [logits, labels])) - logits = logits.reshape([-1, num_classes]) - labels = labels.reshape([-1, num_classes, 1])[:, 0] - - loss = criterion(logits, labels) * need_cal_loss - loss.backward() - if step % args.gradient_accumulation_steps == 0: - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - global_steps += 1 - # Rough acc result, not a precise acc - acc = metric.compute(logits, labels) * need_cal_loss - metric.update(acc) - - if global_steps % args.logging_steps == 0 and step % args.gradient_accumulation_steps == 0: - logger.info( - "train: global step %d, epoch: %d, loss: %f, acc:%f, lr: %f, speed: %.2f step/s" - % ( - global_steps, - epoch, - loss, - metric.accumulate(), - lr_scheduler.get_lr(), - args.logging_steps / (time.time() - tic_train), - ) - ) - tic_train = time.time() - - if global_steps % args.save_steps == 0 and step % args.gradient_accumulation_steps == 0: - logger.info("Eval, total {} qustion.".format(len(eval_ds))) - eval_acc = evaluate(model, eval_metric, eval_dataloader, create_memory(), num_classes) - # Save model - if rank == 0: - output_dir = os.path.join(args.output_dir, "model_%d" % (global_steps)) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - model_to_save.save_pretrained(output_dir) - tokenizer.save_pretrained(output_dir) - if eval_acc > best_acc: - logger.info("Save best model......") - best_acc = eval_acc - best_model_dir = os.path.join(args.output_dir, "best_model") - if not os.path.exists(best_model_dir): - os.makedirs(best_model_dir) - model_to_save.save_pretrained(best_model_dir) - tokenizer.save_pretrained(best_model_dir) - - if args.max_steps > 0 and global_steps >= args.max_steps: - return - logger.info("Final test result:") - eval_acc = evaluate(model, eval_metric, test_dataloader, create_memory(), num_classes) - - -if __name__ == "__main__": - do_train(args) diff --git a/model_zoo/ernie-doc/run_mrc.py b/model_zoo/ernie-doc/run_mrc.py deleted file mode 100644 index 51687dd04dbe..000000000000 --- a/model_zoo/ernie-doc/run_mrc.py +++ /dev/null @@ -1,358 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os -import random -import time -from collections import namedtuple -from functools import partial - -import numpy as np -import paddle -from data import MRCIterator -from metrics import EM_AND_F1, compute_qa_predictions -from paddle.optimizer import AdamW - -from paddlenlp.datasets import load_dataset -from paddlenlp.ops.optimizer import layerwise_lr_decay -from paddlenlp.transformers import ( - ErnieDocForQuestionAnswering, - ErnieDocTokenizer, - LinearDecayWithWarmup, -) -from paddlenlp.utils.log import logger - -# fmt: off -parser = argparse.ArgumentParser() -parser.add_argument("--batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument("--model_name_or_path", type=str, default="ernie-doc-base-zh", help="Pretraining model name or path") -parser.add_argument("--max_seq_length", type=int, default=512, help="The maximum total input sequence length after SentencePiece tokenization.") -parser.add_argument("--learning_rate", type=float, default=2.75e-4, help="Learning rate used to train.") -parser.add_argument("--save_steps", type=int, default=1000, help="Save checkpoint every X updates steps.") -parser.add_argument("--logging_steps", type=int, default=1, help="Log every X updates steps.") -parser.add_argument("--output_dir", type=str, default='checkpoints/', help="Directory to save model checkpoint") -parser.add_argument("--epochs", type=int, default=5, help="Number of epoches for training.") -parser.add_argument("--device", type=str, default="gpu", choices=["cpu", "gpu"], help="Select cpu, gpu devices to train model.") -parser.add_argument("--seed", type=int, default=1, help="Random seed for initialization.") -parser.add_argument("--memory_length", type=int, default=128, help="Length of the retained previous heads.") -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") -parser.add_argument("--warmup_proportion", default=0.1, type=float, help="Linear warmup proportion over the training process.") -parser.add_argument("--layerwise_decay", default=0.8, type=float, help="Layerwise decay ratio") -parser.add_argument("--n_best_size", default=20, type=int, help="The total number of n-best predictions to generate in the nbest_predictions.json output file.") -parser.add_argument("--max_answer_length", default=100, type=int, help="Max answer length.") -parser.add_argument("--do_lower_case", action='store_false', help="Whether to lower case the input text. Should be True for uncased models and False for cased models.") -parser.add_argument("--verbose", action='store_true', help="Whether to output verbose log.") -parser.add_argument("--dropout", default=0.1, type=float, help="Dropout ratio of ernie_doc") -parser.add_argument("--dataset", default="dureader_robust", type=str, choices=["dureader_robust", "cmrc2018", "drcd"], help="The avaliable Q&A dataset") -parser.add_argument("--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override num_train_epochs.",) -args = parser.parse_args() -# fmt: on - -# eval_dataset, test_dataset, -DATASET_INFO = { - "dureader_robust": ["dev", "dev", ErnieDocTokenizer], - "cmrc2018": ["dev", "dev", ErnieDocTokenizer], - "drcd": ["dev", "test", ErnieDocTokenizer], -} - - -def set_seed(args): - random.seed(args.seed) - np.random.seed(args.seed) - paddle.seed(args.seed) - - -def init_memory(batch_size, memory_length, d_model, n_layers): - return [paddle.zeros([batch_size, memory_length, d_model], dtype="float32") for _ in range(n_layers)] - - -class CrossEntropyLossForQA(paddle.nn.Layer): - def __init__(self): - super(CrossEntropyLossForQA, self).__init__() - self.criterion = paddle.nn.CrossEntropyLoss() - - def forward(self, y, label): - start_logits, end_logits = y - start_position, end_position = label - - start_loss = self.criterion(start_logits, start_position) - end_loss = self.criterion(end_logits, end_position) - loss = (start_loss + end_loss) / 2 - return loss - - -@paddle.no_grad() -def evaluate(args, model, criterion, metric, data_loader, memories0, tokenizer): - RawResult = namedtuple("RawResult", ["unique_id", "start_logits", "end_logits"]) - model.eval() - all_results = [] - - tic_start = time.time() - tic_eval = time.time() - memories = list(memories0) - - # Collect result - logger.info("The example number of eval_dataloader: {}".format(len(data_loader._batch_reader.features))) - for step, batch in enumerate(data_loader, start=1): - ( - input_ids, - position_ids, - token_type_ids, - attn_mask, - start_position, - end_position, - qids, - gather_idx, - need_cal_loss, - ) = batch - - start_logits, end_logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - - start_logits, end_logits, qids = list( - map(lambda x: paddle.gather(x, gather_idx), [start_logits, end_logits, qids]) - ) - np_qids = qids.numpy() - np_start_logits = start_logits.numpy() - np_end_logits = end_logits.numpy() - - if int(need_cal_loss.numpy()) == 1: - for idx in range(qids.shape[0]): - if len(all_results) % 1000 == 0 and len(all_results): - logger.info("Processing example: %d" % len(all_results)) - logger.info("time per 1000: {} s".format(time.time() - tic_eval)) - tic_eval = time.time() - - qid_each = int(np_qids[idx]) - start_logits_each = [float(x) for x in np_start_logits[idx].flat] - end_logits_each = [float(x) for x in np_end_logits[idx].flat] - all_results.append( - RawResult(unique_id=qid_each, start_logits=start_logits_each, end_logits=end_logits_each) - ) - - # Compute_predictions - all_predictions_eval, all_nbest_eval = compute_qa_predictions( - data_loader._batch_reader.examples, - data_loader._batch_reader.features, - all_results, - args.n_best_size, - args.max_answer_length, - args.do_lower_case, - tokenizer, - args.verbose, - ) - - EM, F1, AVG, TOTAL = metric(all_predictions_eval, data_loader._batch_reader.dataset) - - logger.info("EM: {}, F1: {}, AVG: {}, TOTAL: {}, TIME: {}".format(EM, F1, AVG, TOTAL, time.time() - tic_start)) - model.train() - return EM, F1, AVG - - -def do_train(args): - set_seed(args) - - DEV, TEST, TOKENIZER_CLASS = DATASET_INFO[args.dataset] - tokenizer = TOKENIZER_CLASS.from_pretrained(args.model_name_or_path) - - train_ds, eval_ds = load_dataset(args.dataset, splits=["train", DEV]) - if DEV == TEST: - test_ds = eval_ds - else: - test_ds = load_dataset(args.dataset, splits=[TEST]) - - paddle.set_device(args.device) - trainer_num = paddle.distributed.get_world_size() - if trainer_num > 1: - paddle.distributed.init_parallel_env() - rank = paddle.distributed.get_rank() - if rank == 0: - if os.path.exists(args.model_name_or_path): - logger.info("init checkpoint from %s" % args.model_name_or_path) - - model = ErnieDocForQuestionAnswering.from_pretrained(args.model_name_or_path, dropout=args.dropout) - model_config = model.ernie_doc.config - if trainer_num > 1: - model = paddle.DataParallel(model) - - train_ds_iter = MRCIterator( - train_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - ) - - eval_ds_iter = MRCIterator( - eval_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - mode="eval", - random_seed=args.seed, - ) - - test_ds_iter = MRCIterator( - test_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - mode="test", - random_seed=args.seed, - ) - - train_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - - eval_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - eval_dataloader.set_batch_generator(eval_ds_iter, paddle.get_device()) - - test_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - test_dataloader.set_batch_generator(test_ds_iter, paddle.get_device()) - - num_training_examples = train_ds_iter.get_num_examples() - num_training_steps = args.epochs * num_training_examples // args.batch_size // trainer_num - logger.info("Device count: %d, trainer_id: %d" % (trainer_num, rank)) - logger.info("Num train examples: %d" % num_training_examples) - logger.info("Max train steps: %d" % num_training_steps) - logger.info("Num warmup steps: %d" % int(num_training_steps * args.warmup_proportion)) - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - # Construct dict - name_dict = dict() - for n, p in model.named_parameters(): - name_dict[p.name] = n - - simple_lr_setting = partial(layerwise_lr_decay, args.layerwise_decay, name_dict, model_config["num_hidden_layers"]) - - optimizer = AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - lr_ratio=simple_lr_setting, - ) - - global_steps = 0 - create_memory = partial( - init_memory, - args.batch_size, - args.memory_length, - model_config["hidden_size"], - model_config["num_hidden_layers"], - ) - - criterion = CrossEntropyLossForQA() - - memories = create_memory() - tic_train = time.time() - best_avg_metric = -1 - stop_training = False - for epoch in range(args.epochs): - train_ds_iter.shuffle_sample() - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - for step, batch in enumerate(train_dataloader, start=1): - global_steps += 1 - ( - input_ids, - position_ids, - token_type_ids, - attn_mask, - start_position, - end_position, - qids, - gather_idx, - need_cal_loss, - ) = batch - start_logits, end_logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - - start_logits, end_logits, qids, start_position, end_position = list( - map( - lambda x: paddle.gather(x, gather_idx), - [start_logits, end_logits, qids, start_position, end_position], - ) - ) - loss = criterion([start_logits, end_logits], [start_position, end_position]) * need_cal_loss - - mean_loss = loss.mean() - mean_loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - - if global_steps % args.logging_steps == 0: - logger.info( - "train: global step %d, epoch: %d, loss: %f, lr: %f, speed: %.2f step/s" - % ( - global_steps, - epoch, - mean_loss, - lr_scheduler.get_lr(), - args.logging_steps / (time.time() - tic_train), - ) - ) - tic_train = time.time() - - if global_steps % args.save_steps == 0: - # Evaluate - logger.info("Eval:") - EM, F1, AVG = evaluate( - args, model, criterion, EM_AND_F1(), eval_dataloader, create_memory(), tokenizer - ) - if rank == 0: - output_dir = os.path.join(args.output_dir, "model_%d" % (global_steps)) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - model_to_save.save_pretrained(output_dir) - tokenizer.save_pretrained(output_dir) - if best_avg_metric < AVG: - output_dir = os.path.join(args.output_dir, "best_model") - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - model_to_save.save_pretrained(output_dir) - tokenizer.save_pretrained(output_dir) - - if args.max_steps > 0 and global_steps >= args.max_steps: - stop_training = True - break - if stop_training: - break - logger.info("Test:") - evaluate(args, model, criterion, EM_AND_F1(), test_dataloader, create_memory(), tokenizer) - if rank == 0: - output_dir = os.path.join(args.output_dir, "model_%d" % (global_steps)) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - model_to_save.save_pretrained(output_dir) - tokenizer.save_pretrained(output_dir) - - -if __name__ == "__main__": - do_train(args) diff --git a/model_zoo/ernie-doc/run_semantic_matching.py b/model_zoo/ernie-doc/run_semantic_matching.py deleted file mode 100644 index 986154f82e15..000000000000 --- a/model_zoo/ernie-doc/run_semantic_matching.py +++ /dev/null @@ -1,357 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os -import random -import time -from collections import defaultdict -from functools import partial - -import numpy as np -import paddle -import paddle.nn as nn -from data import SemanticMatchingIterator -from model import ErnieDocForTextMatching -from paddle.metric import Accuracy -from paddle.optimizer import AdamW - -from paddlenlp.datasets import load_dataset -from paddlenlp.ops.optimizer import layerwise_lr_decay -from paddlenlp.transformers import ( - ErnieDocModel, - ErnieDocTokenizer, - LinearDecayWithWarmup, -) -from paddlenlp.utils.log import logger - -# fmt: off -parser = argparse.ArgumentParser() -parser.add_argument("--batch_size", default=6, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument("--model_name_or_path", type=str, default="ernie-doc-base-zh", help="Pretraining model name or path") -parser.add_argument("--max_seq_length", type=int, default=512, help="The maximum total input sequence length after SentencePiece tokenization.") -parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train.") -parser.add_argument("--save_steps", type=int, default=1000, help="Save checkpoint every X updates steps.") -parser.add_argument("--logging_steps", type=int, default=1, help="Log every X updates steps.") -parser.add_argument("--output_dir", type=str, default='checkpoints/', help="Directory to save model checkpoint") -parser.add_argument("--epochs", type=int, default=15, help="Number of epoches for training.") -parser.add_argument("--device", type=str, default="gpu", choices=["cpu", "gpu"], help="Select cpu, gpu devices to train model.") -parser.add_argument("--seed", type=int, default=1, help="Random seed for initialization.") -parser.add_argument("--memory_length", type=int, default=128, help="Length of the retained previous heads.") -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") -parser.add_argument("--warmup_proportion", default=0.1, type=float, help="Linear warmup proportion over the training process.") -parser.add_argument("--dataset", default="cail2019_scm", choices=["cail2019_scm"], type=str, help="The training dataset") -parser.add_argument("--dropout", default=0.1, type=float, help="Dropout ratio of ernie_doc") -parser.add_argument("--layerwise_decay", default=1.0, type=float, help="Layerwise decay ratio") -parser.add_argument("--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override num_train_epochs.",) -args = parser.parse_args() -# fmt: on - -DATASET_INFO = { - "cail2019_scm": (ErnieDocTokenizer, "dev", "test", Accuracy()), -} - - -def set_seed(args): - random.seed(args.seed) - np.random.seed(args.seed) - paddle.seed(args.seed) - - -def init_memory(batch_size, memory_length, d_model, n_layers): - return [paddle.zeros([batch_size, memory_length, d_model], dtype="float32") for _ in range(n_layers)] - - -@paddle.no_grad() -def evaluate(model, metric, data_loader, memories0, pair_memories0): - model.eval() - losses = [] - # copy the memory - memories = list(memories0) - pair_memories = list(pair_memories0) - tic_train = time.time() - eval_logging_step = 500 - - probs_dict = defaultdict(list) - label_dict = dict() - for step, batch in enumerate(data_loader, start=1): - ( - input_ids, - position_ids, - token_type_ids, - attn_mask, - pair_input_ids, - pair_position_ids, - pair_token_type_ids, - pair_attn_mask, - labels, - qids, - gather_idx, - need_cal_loss, - ) = batch - - logits, memories, pair_memories = model( - input_ids, - pair_input_ids, - memories, - pair_memories, - token_type_ids, - position_ids, - attn_mask, - pair_token_type_ids, - pair_position_ids, - pair_attn_mask, - ) - logits, labels, qids = list(map(lambda x: paddle.gather(x, gather_idx), [logits, labels, qids])) - # Need to collect probs for each qid, so use softmax_with_cross_entropy - loss, probs = nn.functional.softmax_with_cross_entropy(logits, labels, return_softmax=True) - losses.append(loss.mean().numpy()) - # Shape: [B, NUM_LABELS] - np_probs = probs.numpy() - # Shape: [B, 1] - np_qids = qids.numpy() - np_labels = labels.numpy().flatten() - for i, qid in enumerate(np_qids.flatten()): - probs_dict[qid].append(np_probs[i]) - label_dict[qid] = np_labels[i] # Same qid share same label. - - if step % eval_logging_step == 0: - logger.info( - "Step %d: loss: %.5f, speed: %.5f steps/s" - % (step, np.mean(losses), eval_logging_step / (time.time() - tic_train)) - ) - tic_train = time.time() - - # Collect predicted labels - preds = [] - labels = [] - for qid, probs in probs_dict.items(): - mean_prob = np.mean(np.array(probs), axis=0) - preds.append(mean_prob) - labels.append(label_dict[qid]) - - preds = paddle.to_tensor(np.array(preds, dtype="float32")) - labels = paddle.to_tensor(np.array(labels, dtype="int64")) - - metric.update(metric.compute(preds, labels)) - acc_or_f1 = metric.accumulate() - logger.info("Eval loss: %.5f, %s: %.5f" % (np.mean(losses), metric.__class__.__name__, acc_or_f1)) - metric.reset() - model.train() - return acc_or_f1 - - -def do_train(args): - set_seed(args) - tokenizer_class, eval_name, test_name, eval_metric = DATASET_INFO[args.dataset] - tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path) - - # Get dataset - train_ds, eval_ds, test_ds = load_dataset(args.dataset, splits=["train", eval_name, test_name]) - - num_classes = len(train_ds.label_list) - - # Initialize model - paddle.set_device(args.device) - trainer_num = paddle.distributed.get_world_size() - if trainer_num > 1: - paddle.distributed.init_parallel_env() - rank = paddle.distributed.get_rank() - if rank == 0: - if os.path.exists(args.model_name_or_path): - logger.info("init checkpoint from %s" % args.model_name_or_path) - - ernie_doc = ErnieDocModel.from_pretrained(args.model_name_or_path, cls_token_idx=0) - model = ErnieDocForTextMatching(ernie_doc, num_classes, args.dropout) - - model_config = model.ernie_doc.config - if trainer_num > 1: - model = paddle.DataParallel(model) - - train_ds_iter = SemanticMatchingIterator( - train_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - ) - - eval_ds_iter = SemanticMatchingIterator( - eval_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - mode="eval", - ) - - test_ds_iter = SemanticMatchingIterator( - test_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - mode="test", - ) - - train_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - eval_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - eval_dataloader.set_batch_generator(eval_ds_iter, paddle.get_device()) - test_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - test_dataloader.set_batch_generator(test_ds_iter, paddle.get_device()) - - num_training_examples = train_ds_iter.get_num_examples() - num_training_steps = args.epochs * num_training_examples // args.batch_size // trainer_num - logger.info("Device count: %d, trainer_id: %d" % (trainer_num, rank)) - logger.info("Num train examples: %d" % num_training_examples) - logger.info("Max train steps: %d" % num_training_steps) - logger.info("Num warmup steps: %d" % int(num_training_steps * args.warmup_proportion)) - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - # Construct dict - name_dict = dict() - for n, p in model.named_parameters(): - name_dict[p.name] = n - - simple_lr_setting = partial(layerwise_lr_decay, args.layerwise_decay, name_dict, model_config["num_hidden_layers"]) - - optimizer = AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - lr_ratio=simple_lr_setting, - ) - - criterion = paddle.nn.loss.CrossEntropyLoss() - metric = paddle.metric.Accuracy() - - global_steps = 0 - best_acc = -1 - create_memory = partial( - init_memory, - args.batch_size, - args.memory_length, - model_config["hidden_size"], - model_config["num_hidden_layers"], - ) - # Copy the memory - memories = create_memory() - pair_memories = create_memory() - tic_train = time.time() - - for epoch in range(args.epochs): - train_ds_iter.shuffle_sample() - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - for step, batch in enumerate(train_dataloader, start=1): - global_steps += 1 - ( - input_ids, - position_ids, - token_type_ids, - attn_mask, - pair_input_ids, - pair_position_ids, - pair_token_type_ids, - pair_attn_mask, - labels, - qids, - gather_idx, - need_cal_loss, - ) = batch - - logits, memories, pair_memories = model( - input_ids, - pair_input_ids, - memories, - pair_memories, - token_type_ids, - position_ids, - attn_mask, - pair_token_type_ids, - pair_position_ids, - pair_attn_mask, - ) - - logits, labels = list(map(lambda x: paddle.gather(x, gather_idx), [logits, labels])) - loss = criterion(logits, labels) * need_cal_loss - mean_loss = loss.mean() - mean_loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - # Rough acc result, not a precise acc - acc = metric.compute(logits, labels) * need_cal_loss - metric.update(acc) - - if global_steps % args.logging_steps == 0: - logger.info( - "train: global step %d, epoch: %d, loss: %f, acc:%f, lr: %f, speed: %.2f step/s" - % ( - global_steps, - epoch, - mean_loss, - metric.accumulate(), - lr_scheduler.get_lr(), - args.logging_steps / (time.time() - tic_train), - ) - ) - tic_train = time.time() - - if global_steps % args.save_steps == 0: - # Evaluate - logger.info("Eval:") - eval_acc = evaluate(model, eval_metric, eval_dataloader, create_memory(), create_memory()) - # Save - if rank == 0: - output_dir = os.path.join(args.output_dir, "model_%d" % (global_steps)) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - save_param_path = os.path.join(output_dir, "model_state.pdparams") - paddle.save(model_to_save.state_dict(), save_param_path) - tokenizer.save_pretrained(output_dir) - if eval_acc > best_acc: - logger.info("Save best model......") - best_acc = eval_acc - best_model_dir = os.path.join(args.output_dir, "best_model") - if not os.path.exists(best_model_dir): - os.makedirs(best_model_dir) - - save_param_path = os.path.join(best_model_dir, "model_state.pdparams") - paddle.save(model_to_save.state_dict(), save_param_path) - tokenizer.save_pretrained(best_model_dir) - - if args.max_steps > 0 and global_steps >= args.max_steps: - return - logger.info("Final test result:") - eval_acc = evaluate(model, eval_metric, test_dataloader, create_memory(), create_memory()) - - -if __name__ == "__main__": - do_train(args) diff --git a/model_zoo/ernie-doc/run_sequence_labeling.py b/model_zoo/ernie-doc/run_sequence_labeling.py deleted file mode 100644 index 0686f9626ac4..000000000000 --- a/model_zoo/ernie-doc/run_sequence_labeling.py +++ /dev/null @@ -1,300 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os -import random -import time -from collections import defaultdict -from functools import partial - -import numpy as np -import paddle -from data import SequenceLabelingIterator -from paddle.optimizer import AdamW - -from paddlenlp.datasets import load_dataset -from paddlenlp.metrics import ChunkEvaluator -from paddlenlp.ops.optimizer import layerwise_lr_decay -from paddlenlp.transformers import ( - ErnieDocForTokenClassification, - ErnieDocTokenizer, - LinearDecayWithWarmup, -) -from paddlenlp.utils.log import logger - -# fmt: off -parser = argparse.ArgumentParser() -parser.add_argument("--batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument("--model_name_or_path", type=str, default="ernie-doc-base-zh", help="Pretraining model name or path") -parser.add_argument("--max_seq_length", type=int, default=512, help="The maximum total input sequence length after SentencePiece tokenization.") -parser.add_argument("--learning_rate", type=float, default=3e-5, help="Learning rate used to train.") -parser.add_argument("--save_steps", type=int, default=1000, help="Save checkpoint every X updates steps.") -parser.add_argument("--logging_steps", type=int, default=1, help="Log every X updates steps.") -parser.add_argument("--output_dir", type=str, default='checkpoints/', help="Directory to save model checkpoint") -parser.add_argument("--epochs", type=int, default=3, help="Number of epoches for training.") -parser.add_argument("--device", type=str, default="gpu", choices=["cpu", "gpu"], help="Select cpu, gpu devices to train model.") -parser.add_argument("--seed", type=int, default=1, help="Random seed for initialization.") -parser.add_argument("--memory_length", type=int, default=128, help="Length of the retained previous heads.") -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") -parser.add_argument("--warmup_proportion", default=0.1, type=float, help="Linear warmup proportion over the training process.") -parser.add_argument("--dataset", default="msra_ner", choices=["msra_ner"], type=str, help="The training dataset") -parser.add_argument("--layerwise_decay", default=1.0, type=float, help="Layerwise decay ratio") -parser.add_argument("--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override num_train_epochs.",) -args = parser.parse_args() -# fmt: on - - -def set_seed(args): - random.seed(args.seed) - np.random.seed(args.seed) - paddle.seed(args.seed) - - -def init_memory(batch_size, memory_length, d_model, n_layers): - return [paddle.zeros([batch_size, memory_length, d_model], dtype="float32") for _ in range(n_layers)] - - -@paddle.no_grad() -def evaluate(model, metric, data_loader, memories0): - model.eval() - metric.reset() - avg_loss, precision, recall, f1_score = 0, 0, 0, 0 - loss_fct = paddle.nn.loss.CrossEntropyLoss() - losses = [] - # Copy the memory - memories = list(memories0) - tic_train = time.time() - eval_logging_step = 500 - labels_dict = defaultdict(list) - preds_dict = defaultdict(list) - length_dict = defaultdict(list) - - for step, batch in enumerate(data_loader, start=1): - input_ids, position_ids, token_type_ids, attn_mask, labels, lengths, qids, gather_idxs, need_cal_loss = batch - logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - logits, labels, qids, lengths = list( - map(lambda x: paddle.gather(x, gather_idxs), [logits, labels, qids, lengths]) - ) - loss = loss_fct(logits, labels) - avg_loss = loss.mean() - losses.append(avg_loss) - preds = logits.argmax(axis=2) - - np_qids = qids.numpy().flatten() - for i, qid in enumerate(np_qids): - preds_dict[qid].append(preds[i]) - labels_dict[qid].append(labels[i]) - length_dict[qid].append(lengths[i]) - - if step % eval_logging_step == 0: - logger.info( - "Step %d: loss: %.5f, speed: %.5f steps/s" - % (step, np.mean(losses), eval_logging_step / (time.time() - tic_train)) - ) - tic_train = time.time() - - qids = preds_dict.keys() - for qid in qids: - preds = paddle.concat(preds_dict[qid], axis=0).unsqueeze(0) - labels = paddle.concat(labels_dict[qid], axis=0).unsqueeze(0).squeeze(-1) - length = paddle.concat(length_dict[qid], axis=0) - length = length.sum(axis=0, keepdim=True) - num_infer_chunks, num_label_chunks, num_correct_chunks = metric.compute(length, preds, labels) - metric.update(num_infer_chunks.numpy(), num_label_chunks.numpy(), num_correct_chunks.numpy()) - precision, recall, f1_score = metric.accumulate() - metric.reset() - logger.info("Total {} samples.".format(len(qids))) - logger.info("eval loss: %f, precision: %f, recall: %f, f1: %f" % (avg_loss, precision, recall, f1_score)) - model.train() - return precision, recall, f1_score - - -def do_train(args): - set_seed(args) - tokenizer = ErnieDocTokenizer.from_pretrained(args.model_name_or_path) - train_ds, eval_ds = load_dataset(args.dataset, splits=["train", "test"]) - test_ds = eval_ds - - num_classes = len(train_ds.label_list) - no_entity_id = num_classes - 1 - - paddle.set_device(args.device) - trainer_num = paddle.distributed.get_world_size() - if trainer_num > 1: - paddle.distributed.init_parallel_env() - rank = paddle.distributed.get_rank() - if rank == 0: - if os.path.exists(args.model_name_or_path): - logger.info("init checkpoint from %s" % args.model_name_or_path) - model = ErnieDocForTokenClassification.from_pretrained(args.model_name_or_path, num_classes=num_classes) - model_config = model.ernie_doc.config - if trainer_num > 1: - model = paddle.DataParallel(model) - - train_ds_iter = SequenceLabelingIterator( - train_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - random_seed=args.seed, - no_entity_id=no_entity_id, - ) - eval_ds_iter = SequenceLabelingIterator( - eval_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - mode="eval", - no_entity_id=no_entity_id, - ) - test_ds_iter = SequenceLabelingIterator( - test_ds, - args.batch_size, - tokenizer, - trainer_num, - trainer_id=rank, - memory_len=model_config["memory_len"], - max_seq_length=args.max_seq_length, - mode="test", - no_entity_id=no_entity_id, - ) - - train_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - eval_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - eval_dataloader.set_batch_generator(eval_ds_iter, paddle.get_device()) - test_dataloader = paddle.fluid.reader.DataLoader.from_generator(capacity=70, return_list=True) - test_dataloader.set_batch_generator(test_ds_iter, paddle.get_device()) - - num_training_examples = train_ds_iter.get_num_examples() - num_training_steps = args.epochs * num_training_examples // args.batch_size // trainer_num - logger.info("Device count: %d, trainer_id: %d" % (trainer_num, rank)) - logger.info("Num train examples: %d" % num_training_examples) - logger.info("Max train steps: %d" % num_training_steps) - logger.info("Num warmup steps: %d" % int(num_training_steps * args.warmup_proportion)) - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - # Construct dict - name_dict = dict() - for n, p in model.named_parameters(): - name_dict[p.name] = n - - simple_lr_setting = partial(layerwise_lr_decay, args.layerwise_decay, name_dict, model_config["num_hidden_layers"]) - - optimizer = AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - lr_ratio=simple_lr_setting, - ) - - criterion = paddle.nn.loss.CrossEntropyLoss() - metric = ChunkEvaluator(label_list=train_ds.label_list) - - global_steps = 0 - - create_memory = partial( - init_memory, - args.batch_size, - args.memory_length, - model_config["hidden_size"], - model_config["num_hidden_layers"], - ) - # Copy the memory - memories = create_memory() - tic_train = time.time() - best_f1 = 0 - stop_training = False - for epoch in range(args.epochs): - train_ds_iter.shuffle_sample() - train_dataloader.set_batch_generator(train_ds_iter, paddle.get_device()) - for step, batch in enumerate(train_dataloader, start=1): - global_steps += 1 - ( - input_ids, - position_ids, - token_type_ids, - attn_mask, - labels, - lengths, - qids, - gather_idx, - need_cal_loss, - ) = batch - logits, memories = model(input_ids, memories, token_type_ids, position_ids, attn_mask) - logits, labels = list(map(lambda x: paddle.gather(x, gather_idx), [logits, labels])) - - loss = criterion(logits, labels) * need_cal_loss - loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - - if global_steps % args.logging_steps == 0: - logger.info( - "train: global step %d, epoch: %d, loss: %f, lr: %f, speed: %.2f step/s" - % ( - global_steps, - epoch, - loss, - lr_scheduler.get_lr(), - args.logging_steps / (time.time() - tic_train), - ) - ) - tic_train = time.time() - if global_steps % args.save_steps == 0: - # Evaluate - logger.info("Eval:") - precision, recall, f1_score = evaluate(model, metric, eval_dataloader, create_memory()) - # Save - if rank == 0: - output_dir = os.path.join(args.output_dir, "model_%d" % (global_steps)) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - model_to_save.save_pretrained(output_dir) - tokenizer.save_pretrained(output_dir) - if f1_score > best_f1: - logger.info("Save best model......") - best_f1 = f1_score - best_model_dir = os.path.join(args.output_dir, "best_model") - if not os.path.exists(best_model_dir): - os.makedirs(best_model_dir) - model_to_save.save_pretrained(best_model_dir) - tokenizer.save_pretrained(best_model_dir) - - if args.max_steps > 0 and global_steps >= args.max_steps: - stop_training = True - break - if stop_training: - break - - logger.info("Final test result:") - evaluate(model, metric, test_dataloader, create_memory()) - - -if __name__ == "__main__": - do_train(args) diff --git a/model_zoo/ernie-gen/README.md b/model_zoo/ernie-gen/README.md deleted file mode 100644 index 4d236818fd22..000000000000 --- a/model_zoo/ernie-gen/README.md +++ /dev/null @@ -1,148 +0,0 @@ -# ERNIE-Gen: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation - -## 1. 简介 - -ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入**span-by-span 生成任务**,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过**填充式生成机制**和**噪声感知机制**来缓解曝光偏差问题。此外, ERNIE-GEN 采样**多片段-多粒度目标文本采样策略**, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。 - - - -## 快速开始 - -### 环境依赖 - -- tqdm - -安装方式:`pip install tqdm` - -### 数据准备 - -在本例中,我们提供了古诗词数据集,示例数据如下: - -```text -画\002精\002禅\002室\002冷\002,\002方\002暑\002久\002徘\002徊\002。 不\002尽\002林\002端\002雪\002,\002长\002青\002石\002上\002苔\002。\002心\002闲\002对\002岩\002岫\002,\002目\002浄\002失\002尘\002埃\002。\002坐\002久\002清\002风\002至\002,\002疑\002从\002翠\002涧\002来\002。 -``` - -每行数据都是由两列组成,以制表符分隔。第一列是输入的诗句前文,第二列是输出的诗句后文,所有文字都以 `\002` 分隔。 - -完整数据集可以通过以下命令下载并解压: - -```bash -wget --no-check-certificate https://bj.bcebos.com/paddlenlp/datasets/poetry.tar.gz -tar xvf poetry.tar.gz -``` - -### 模型微调 - -#### 单卡训练 - -训练启动方式如下: - -```bash -python -u ./train.py \ - --model_name_or_path ernie-1.0 \ - --max_encode_len 24 \ - --max_decode_len 72 \ - --batch_size 48 \ - --learning_rate 2e-5 \ - --num_epochs 12 \ - --logging_steps 1 \ - --save_steps 1000 \ - --output_dir ./tmp/ \ - --device gpu \ - # --init_checkpoint ./tmp/model_10000/model_state.pdparams -``` - -参数释义如下: -- `model_name_or_path` 指示了某种特定配置的模型,对应有其预训练模型和预训练时使用的 tokenizer,支持[PaddleNLP Transformer类预训练模型](https://paddlenlp.readthedocs.io/zh/latest/model_zoo/index.html#transformer) 中的所有模型,但只有`ernie-gen-base-en, ernie-gen-large-en, ernie-gen-large-en-430g`三种模型会加载最后输出层的参数,其余模型只会加载transformer参数作热启动。若模型相关内容保存在本地,这里也可以提供相应目录地址。 -- `max_encode_len` 表示最大输入句子长度,超过该长度将被截断。 -- `max_decode_len` 表示最大输出句子长度,超过该长度将被截断。 -- `batch_size` 表示每次迭代**每张卡**上的样本数目。 -- `learning_rate` 表示基础学习率大小,将于learning rate scheduler产生的值相乘作为当前学习率。 -- `num_epochs` 表示训练轮数。 -- `logging_steps` 表示日志打印间隔。 -- `save_steps` 表示模型保存及评估间隔。 -- `output_dir` 表示模型保存路径。 -- `device`: 训练使用的设备, 'gpu'表示使用GPU, 'xpu'表示使用百度昆仑卡, 'cpu'表示使用CPU。 -- `init_checkpoint` 表示模型加载路径,通过设置此参数可以开启增量训练。 - -训练会持续很长的时间,为此我们提供了[微调后的模型](https://bj.bcebos.com/paddlenlp/models/transformers/ernie_gen_finetuned/ernie_1.0_poetry.pdparams)。您可以下载该模型并通过`init_checkpoint`加载其参数进行增量训练、评估或预测。 - -#### 多卡训练 - -训练启动方式如下: - -```bash -python -m paddle.distributed.launch --gpus "0,1" ./train.py \ - --model_name_or_path ernie-1.0 \ - --max_encode_len 24 \ - --max_decode_len 72 \ - --batch_size 48 \ - --learning_rate 2e-5 \ - --num_epochs 12 \ - --logging_steps 1 \ - --save_steps 1000 \ - --output_dir ./tmp/ \ - --device gpu \ - # --init_checkpoint ./tmp/model_10000/model_state.pdparams -``` - -### 模型评估 - -通过加载训练保存的模型,可以对验证集数据进行验证,启动方式如下: - -```bash -python -u ./eval.py \ - --model_name_or_path ernie-1.0 \ - --max_encode_len 24 \ - --max_decode_len 72 \ - --batch_size 48 \ - --init_checkpoint ./tmp/model_10000/model_state.pdparams \ - --device gpu -``` - -参数释义如下: -- `model_name_or_path` 指示了某种特定配置的模型,对应有其预训练模型和预训练时使用的 tokenizer,支持[PaddleNLP Transformer类预训练模型](https://paddlenlp.readthedocs.io/zh/latest/model_zoo/index.html#transformer) 中的所有模型,但只有`ernie-gen-base-en, ernie-gen-large-en, ernie-gen-large-en-430g`三种模型会加载最后输出层的参数,其余模型只会加载transformer参数作热启动。若模型相关内容保存在本地,这里也可以提供相应目录地址。 -- `max_encode_len` 表示最大输入句子长度,超过该长度将被截断。 -- `max_decode_len` 表示最大输出句子长度,超过该长度将被截断。 -- `batch_size` 表示每次迭代**每张卡**上的样本数目。 -- `init_checkpoint` 表示模型加载路径。 -- `use_gpu` 表示使用GPU。 - -### 模型预测 - -对无标签数据可以启动模型预测: - -```bash -python -u ./predict.py \ - --model_name_or_path ernie-1.0 \ - --max_encode_len 24 \ - --max_decode_len 72 \ - --batch_size 48 \ - --init_checkpoint ./tmp/model_10000/model_state.pdparams \ - --device gpu -``` - - -## Citation - -您可以按下面的格式引用ERNIE-Gen论文: - -``` -@article{xiao2020ernie-gen, - title={ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation}, - author={Xiao, Dongling and Zhang, Han and Li, Yukun and Sun, Yu and Tian, Hao and Wu, Hua and Wang, Haifeng}, - journal={arXiv preprint arXiv:2001.11314}, - year={2020} -} -``` - -## 线上教程体验 - -我们为诗歌文本生成提供了线上教程,欢迎体验: - -* [使用PaddleNLP预训练模型ERNIE-GEN生成诗歌](https://aistudio.baidu.com/aistudio/projectdetail/1339888) - - -## Acknowledgement - -- 感谢 [chinese-poetry数据集](https://github.com/chinese-poetry/chinese-poetry) 开放的诗歌数据集 diff --git a/model_zoo/ernie-gen/decode.py b/model_zoo/ernie-gen/decode.py deleted file mode 100644 index 0450dd46504f..000000000000 --- a/model_zoo/ernie-gen/decode.py +++ /dev/null @@ -1,292 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -import re -from collections import namedtuple - -import numpy as np -import paddle -import paddle.nn as nn - - -def gen_bias(encoder_inputs, decoder_inputs, step): - decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2] - encoder_bsz, encoder_seqlen = encoder_inputs.shape[:2] - attn_bias = paddle.reshape(paddle.arange(0, decoder_seqlen, 1, dtype="float32") + 1, [1, -1, 1]) - decoder_bias = paddle.cast( - (paddle.matmul(attn_bias, 1.0 / attn_bias, transpose_y=True) >= 1.0), "float32" - ) # [1, decoderlen, decoderlen] - encoder_bias = paddle.unsqueeze( - paddle.cast(paddle.ones_like(encoder_inputs), "float32"), [1] - ) # [bsz, 1, encoderlen] - encoder_bias = paddle.expand( - encoder_bias, [encoder_bsz, decoder_seqlen, encoder_seqlen] - ) # [bsz,decoderlen, encoderlen] - decoder_bias = paddle.expand( - decoder_bias, [decoder_bsz, decoder_seqlen, decoder_seqlen] - ) # [bsz, decoderlen, decoderlen] - if step > 0: - bias = paddle.concat( - [encoder_bias, paddle.ones([decoder_bsz, decoder_seqlen, step], "float32"), decoder_bias], -1 - ) - else: - bias = paddle.concat([encoder_bias, decoder_bias], -1) - return bias - - -@paddle.no_grad() -def greedy_search_infilling( - model, - token_ids, - token_type_ids, - sos_id, - eos_id, - attn_id, - pad_id, - unk_id, - vocab_size, - max_encode_len=640, - max_decode_len=100, - tgt_type_id=3, -): - _, logits, info = model(token_ids, token_type_ids) - d_batch, d_seqlen = token_ids.shape - seqlen = paddle.sum(paddle.cast(token_ids != 0, "int64"), 1, keepdim=True) - has_stopped = np.zeros([d_batch], dtype=np.bool_) - gen_seq_len = np.zeros([d_batch], dtype=np.int64) - output_ids = [] - - past_cache = info["caches"] - - cls_ids = paddle.ones([d_batch], dtype="int64") * sos_id - attn_ids = paddle.ones([d_batch], dtype="int64") * attn_id - ids = paddle.stack([cls_ids, attn_ids], -1) - for step in range(max_decode_len): - bias = gen_bias(token_ids, ids, step) - pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1])) - pos_ids += seqlen - _, logits, info = model( - ids, paddle.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache - ) - - if logits.shape[-1] > vocab_size: - logits[:, :, vocab_size:] = 0 - logits[:, :, pad_id] = 0 - logits[:, :, unk_id] = 0 - logits[:, :, attn_id] = 0 - - gen_ids = paddle.argmax(logits, -1) - - past_cached_k, past_cached_v = past_cache - cached_k, cached_v = info["caches"] - cached_k = [paddle.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached - cached_v = [paddle.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)] - past_cache = (cached_k, cached_v) - - gen_ids = gen_ids[:, 1] - ids = paddle.stack([gen_ids, attn_ids], 1) - - gen_ids = gen_ids.numpy() - has_stopped |= (gen_ids == eos_id).astype(np.bool_) - gen_seq_len += 1 - has_stopped.astype(np.int64) - output_ids.append(gen_ids.tolist()) - if has_stopped.all(): - break - output_ids = np.array(output_ids).transpose([1, 0]) - return output_ids - - -BeamSearchState = namedtuple("BeamSearchState", ["log_probs", "lengths", "finished"]) -BeamSearchOutput = namedtuple("BeamSearchOutput", ["scores", "predicted_ids", "beam_parent_ids"]) - - -def log_softmax(x): - e_x = np.exp(x - np.max(x)) - return np.log(e_x / e_x.sum()) - - -def mask_prob(p, onehot_eos, finished): - is_finished = paddle.cast(paddle.reshape(finished, [-1, 1]) != 0, "float32") - p = is_finished * (1.0 - paddle.cast(onehot_eos, "float32")) * -9999.0 + (1.0 - is_finished) * p - return p - - -def hyp_score(log_probs, length, length_penalty): - lp = paddle.pow((5.0 + paddle.cast(length, "float32")) / 6.0, length_penalty) - return log_probs / lp - - -def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty): - """logits.shape == [B*W, V]""" - _, vocab_size = logits.shape - - bsz, beam_width = state.log_probs.shape - onehot_eos = paddle.cast(nn.functional.one_hot(paddle.ones([1], "int64") * eos_id, vocab_size), "int64") # [1, V] - - probs = paddle.log(nn.functional.softmax(logits)) # [B*W, V] - probs = mask_prob(probs, onehot_eos, state.finished) # [B*W, V] - allprobs = paddle.reshape(state.log_probs, [-1, 1]) + probs # [B*W, V] - - not_finished = 1 - paddle.reshape(state.finished, [-1, 1]) # [B*W,1] - not_eos = 1 - onehot_eos - length_to_add = not_finished * not_eos # [B*W,V] - alllen = paddle.reshape(state.lengths, [-1, 1]) + length_to_add - - allprobs = paddle.reshape(allprobs, [-1, beam_width * vocab_size]) - alllen = paddle.reshape(alllen, [-1, beam_width * vocab_size]) - allscore = hyp_score(allprobs, alllen, length_penalty) - if is_first_step: - allscore = paddle.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0 - scores, idx = paddle.topk(allscore, k=beam_width) # [B, W] - next_beam_id = idx // vocab_size # [B, W] - next_word_id = idx % vocab_size - - gather_idx = paddle.concat([paddle.nonzero(idx != -1)[:, :1], paddle.reshape(idx, [-1, 1])], 1) - next_probs = paddle.reshape(paddle.gather_nd(allprobs, gather_idx), idx.shape) - next_len = paddle.reshape(paddle.gather_nd(alllen, gather_idx), idx.shape) - - gather_idx = paddle.concat([paddle.nonzero(next_beam_id != -1)[:, :1], paddle.reshape(next_beam_id, [-1, 1])], 1) - next_finished = paddle.reshape( - paddle.gather_nd(state.finished, gather_idx), state.finished.shape - ) # [gather new beam state according to new beam id] - - next_finished += paddle.cast(next_word_id == eos_id, "int64") - next_finished = paddle.cast(next_finished > 0, "int64") - - next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished) - output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id) - - return output, next_state - - -@paddle.no_grad() -def beam_search_infilling( - model, - token_ids, - token_type_ids, - sos_id, - eos_id, - attn_id, - pad_id, - unk_id, - vocab_size, - max_encode_len=640, - max_decode_len=100, - beam_width=5, - tgt_type_id=3, - length_penalty=1.0, -): - _, __, info = model(token_ids, token_type_ids) - d_batch, d_seqlen = token_ids.shape - - state = BeamSearchState( - log_probs=paddle.zeros([d_batch, beam_width], "float32"), - lengths=paddle.zeros([d_batch, beam_width], "int64"), - finished=paddle.zeros([d_batch, beam_width], "int64"), - ) - outputs = [] - - def reorder_(t, parent_id): - """reorder cache according to parent beam id""" - gather_idx = paddle.nonzero(parent_id != -1)[:, 0] * beam_width + paddle.reshape(parent_id, [-1]) - t = paddle.gather(t, gather_idx) - return t - - def tile_(t, times): - _shapes = list(t.shape[1:]) - new_shape = [t.shape[0], times] + list(t.shape[1:]) - ret = paddle.reshape( - paddle.expand(paddle.unsqueeze(t, [1]), new_shape), - [ - -1, - ] - + _shapes, - ) - return ret - - cached_k, cached_v = info["caches"] - cached_k = [tile_(k, beam_width) for k in cached_k] - cached_v = [tile_(v, beam_width) for v in cached_v] - past_cache = (cached_k, cached_v) - - token_ids = tile_(token_ids, beam_width) - seqlen = paddle.sum(paddle.cast(token_ids != 0, "int64"), 1, keepdim=True) - # log.debug(token_ids.shape) - - cls_ids = paddle.ones([d_batch * beam_width], dtype="int64") * sos_id - attn_ids = paddle.ones([d_batch * beam_width], dtype="int64") * attn_id # SOS - ids = paddle.stack([cls_ids, attn_ids], -1) - for step in range(max_decode_len): - # log.debug('decode step %d' % step) - bias = gen_bias(token_ids, ids, step) - pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1])) - pos_ids += seqlen - _, logits, info = model( - ids, paddle.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache - ) - if logits.shape[-1] > vocab_size: - logits[:, :, vocab_size:] = 0 - logits[:, :, pad_id] = 0 - logits[:, :, unk_id] = 0 - logits[:, :, attn_id] = 0 - - output, state = beam_search_step( - state, - logits[:, 1], - eos_id=eos_id, - beam_width=beam_width, - is_first_step=(step == 0), - length_penalty=length_penalty, - ) - outputs.append(output) - - past_cached_k, past_cached_v = past_cache - cached_k, cached_v = info["caches"] - cached_k = [ - reorder_(paddle.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids) - for pk, k in zip(past_cached_k, cached_k) - ] # concat cached - cached_v = [ - reorder_(paddle.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids) - for pv, v in zip(past_cached_v, cached_v) - ] - past_cache = (cached_k, cached_v) - - pred_ids_flatten = paddle.reshape(output.predicted_ids, [d_batch * beam_width]) - ids = paddle.stack([pred_ids_flatten, attn_ids], 1) - - if state.finished.numpy().all(): - break - - final_ids = paddle.stack([o.predicted_ids for o in outputs], 0) - final_parent_ids = paddle.stack([o.beam_parent_ids for o in outputs], 0) - final_ids = nn.functional.gather_tree(final_ids, final_parent_ids)[:, :, 0] # pick best beam - final_ids = paddle.transpose(paddle.reshape(final_ids, [-1, d_batch * 1]), [1, 0]) - - return final_ids.numpy() - - -en_patten = re.compile(r"^[a-zA-Z0-9]*$") - - -def post_process(token): - if token.startswith("##"): - ret = token[2:] - elif token in ["[CLS]", "[SEP]", "[PAD]"]: - ret = "" - else: - if en_patten.match(token): - ret = " " + token - else: - ret = token - return ret diff --git a/model_zoo/ernie-gen/encode.py b/model_zoo/ernie-gen/encode.py deleted file mode 100644 index a1f47e1f3310..000000000000 --- a/model_zoo/ernie-gen/encode.py +++ /dev/null @@ -1,145 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -from copy import deepcopy - -import numpy as np - - -def convert_example( - tokenizer, - attn_id, - tgt_type_id=3, - max_encode_len=512, - max_decode_len=128, - is_test=False, - noise_prob=0.0, - use_random_noice=False, -): - def warpper(example): - """convert an example into necessary features""" - tokens = example["tokens"] - labels = example["labels"] - encoded_src = tokenizer(tokens, max_seq_len=max_encode_len, pad_to_max_seq_len=False) - src_ids, src_sids = encoded_src["input_ids"], encoded_src["token_type_ids"] - src_pids = np.arange(len(src_ids)) - - if not is_test: - encoded_tgt = tokenizer(labels, max_seq_len=max_decode_len, pad_to_max_seq_len=False) - tgt_ids, tgt_sids = encoded_tgt["input_ids"], encoded_tgt["token_type_ids"] - tgt_ids = np.array(tgt_ids).astype("int64") - tgt_sids = np.array(tgt_sids) + tgt_type_id - tgt_pids = np.arange(len(tgt_ids)) + len(src_ids) - - attn_ids = np.ones_like(tgt_ids) * attn_id - if noise_prob > 0.0: - tgt_labels = deepcopy(tgt_ids) - if use_random_noice: - noice_ids = np.random.randint(1, len(tokenizer.vocab), size=tgt_ids.shape) - else: - noice_ids = np.ones_like(tgt_ids) * tokenizer.vocab["[NOISE]"] - (pos,) = np.where(np.ones_like(tgt_ids)) - np.random.shuffle(pos) - pos = pos[: int(noise_prob * len(pos))] - tgt_ids[pos] = noice_ids[ - pos, - ] - else: - tgt_labels = tgt_ids - - return (src_ids, src_pids, src_sids, tgt_ids, tgt_pids, tgt_sids, attn_ids, tgt_labels) - - return warpper - - -def gen_mask(batch_ids, mask_type="bidi", query_len=None, pad_value=0): - if query_len is None: - query_len = batch_ids.shape[1] - if mask_type != "empty": - mask = (batch_ids != pad_value).astype(np.float32) - mask = np.tile(np.expand_dims(mask, 1), [1, query_len, 1]) - if mask_type == "causal": - assert query_len == batch_ids.shape[1] - mask = np.tril(mask) - elif mask_type == "causal_without_diag": - assert query_len == batch_ids.shape[1] - mask = np.tril(mask, -1) - elif mask_type == "diag": - assert query_len == batch_ids.shape[1] - mask = np.stack([np.diag(np.diag(m)) for m in mask], 0) - - else: - mask_type == "empty" - mask = np.zeros_like(batch_ids).astype(np.float32) - mask = np.tile(np.expand_dims(mask, 1), [1, query_len, 1]) - return mask - - -def after_padding(args): - """ - attention mask: - *** src, tgt, attn - src 00, 01, 11 - tgt 10, 11, 12 - attn 20, 21, 22 - - *** s1, s2 | t1 t2 t3| attn1 attn2 attn3 - s1 1, 1 | 0, 0, 0,| 0, 0, 0, - s2 1, 1 | 0, 0, 0,| 0, 0, 0, - - - t1 1, 1, | 1, 0, 0,| 0, 0, 0, - t2 1, 1, | 1, 1, 0,| 0, 0, 0, - t3 1, 1, | 1, 1, 1,| 0, 0, 0, - - - attn1 1, 1, | 0, 0, 0,| 1, 0, 0, - attn2 1, 1, | 1, 0, 0,| 0, 1, 0, - attn3 1, 1, | 1, 1, 0,| 0, 0, 1, - - for details, see Fig3. https://arxiv.org/abs/2001.11314 - """ - src_ids, src_pids, src_sids, tgt_ids, tgt_pids, tgt_sids, attn_ids, tgt_labels = args - src_len = src_ids.shape[1] - tgt_len = tgt_ids.shape[1] - mask_00 = gen_mask(src_ids, "bidi", query_len=src_len) - # mask_01 = gen_mask(tgt_ids, "empty", query_len=src_len) - # mask_02 = gen_mask(attn_ids, "empty", query_len=src_len) - - mask_10 = gen_mask(src_ids, "bidi", query_len=tgt_len) - mask_11 = gen_mask(tgt_ids, "causal", query_len=tgt_len) - # mask_12 = gen_mask(attn_ids, "empty", query_len=tgt_len) - - mask_20 = gen_mask(src_ids, "bidi", query_len=tgt_len) - mask_21 = gen_mask(tgt_ids, "causal_without_diag", query_len=tgt_len) - mask_22 = gen_mask(attn_ids, "diag", query_len=tgt_len) - - mask_src_2_src = mask_00 - mask_tgt_2_srctgt = np.concatenate([mask_10, mask_11], 2) - mask_attn_2_srctgtattn = np.concatenate([mask_20, mask_21, mask_22], 2) - - raw_tgt_labels = deepcopy(tgt_labels) - tgt_labels = tgt_labels[np.where(tgt_labels != 0)] - return ( - src_ids, - src_sids, - src_pids, - tgt_ids, - tgt_sids, - tgt_pids, - attn_ids, - mask_src_2_src, - mask_tgt_2_srctgt, - mask_attn_2_srctgtattn, - tgt_labels, - raw_tgt_labels, - ) diff --git a/model_zoo/ernie-gen/eval.py b/model_zoo/ernie-gen/eval.py deleted file mode 100644 index 47dd2298ac7b..000000000000 --- a/model_zoo/ernie-gen/eval.py +++ /dev/null @@ -1,147 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse - -import paddle -from decode import beam_search_infilling -from encode import after_padding, convert_example -from paddle.io import DataLoader -from tqdm import tqdm - -from paddlenlp.data import Pad, Tuple -from paddlenlp.datasets import load_dataset -from paddlenlp.metrics import Rouge1, Rouge2 -from paddlenlp.transformers import ( - BertTokenizer, - ElectraTokenizer, - ErnieForGeneration, - ErnieTinyTokenizer, - ErnieTokenizer, - RobertaTokenizer, -) -from paddlenlp.utils.log import logger - -# fmt: off -parser = argparse.ArgumentParser('seq2seq model with ERNIE-GEN') -parser.add_argument("--model_name_or_path", default=None, type=str, required=True, help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(list(ErnieTokenizer.pretrained_init_configuration.keys()))) -parser.add_argument('--max_encode_len', type=int, default=24, help="The max encoding sentence length") -parser.add_argument('--max_decode_len', type=int, default=72, help="The max decoding sentence length") -parser.add_argument("--batch_size", default=50, type=int, help="Batch size per GPU/CPU for training.", ) -parser.add_argument('--beam_width', type=int, default=1, help="Beam search width") -parser.add_argument('--length_penalty', type=float, default=1.0, help="The length penalty during decoding") -parser.add_argument('--init_checkpoint', type=str, default=None, help='Checkpoint to warm start from') -parser.add_argument("--device", default="gpu", type=str, choices=["cpu", "gpu", "xpu"], help="The device to select to train the model, is must be cpu/gpu/xpu.") -args = parser.parse_args() -# fmt: on - - -def evaluate(): - paddle.set_device(args.device) - - model = ErnieForGeneration.from_pretrained(args.model_name_or_path) - if "ernie-tiny" in args.model_name_or_path: - tokenizer = ErnieTinyTokenizer.from_pretrained(args.model_name_or_path) - elif "ernie" in args.model_name_or_path: - tokenizer = ErnieTokenizer.from_pretrained(args.model_name_or_path) - elif "roberta" in args.model_name_or_path or "rbt" in args.model_name_or_path: - tokenizer = RobertaTokenizer.from_pretrained(args.model_name_or_path) - elif "electra" in args.model_name_or_path: - tokenizer = ElectraTokenizer.from_pretrained(args.model_name_or_path) - else: - tokenizer = BertTokenizer.from_pretrained(args.model_name_or_path) - - dev_dataset = load_dataset("poetry", splits=("dev"), lazy=False) - attn_id = tokenizer.vocab["[ATTN]"] if "[ATTN]" in tokenizer.vocab else tokenizer.vocab["[MASK]"] - tgt_type_id = model.sent_emb.weight.shape[0] - 1 - - trans_func = convert_example( - tokenizer=tokenizer, - attn_id=attn_id, - tgt_type_id=tgt_type_id, - max_encode_len=args.max_encode_len, - max_decode_len=args.max_decode_len, - ) - - batchify_fn = lambda samples, fn=Tuple( - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_pids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_sids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_pids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_sids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # attn_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_labels - ): after_padding(fn(samples)) - - dev_dataset = dev_dataset.map(trans_func) - dev_batch_sampler = paddle.io.BatchSampler(dev_dataset, batch_size=args.batch_size, shuffle=False) - data_loader = DataLoader( - dataset=dev_dataset, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn, num_workers=0, return_list=True - ) - - rouge1 = Rouge1() - rouge2 = Rouge2() - - if args.init_checkpoint: - model_state = paddle.load(args.init_checkpoint) - model.set_state_dict(model_state) - - model.eval() - vocab = tokenizer.vocab - eos_id = vocab[tokenizer.sep_token] - sos_id = vocab[tokenizer.cls_token] - pad_id = vocab[tokenizer.pad_token] - unk_id = vocab[tokenizer.unk_token] - vocab_size = len(vocab) - evaluated_sentences_ids = [] - reference_sentences_ids = [] - logger.info("Evaluating...") - for data in tqdm(data_loader): - (src_ids, src_sids, src_pids, _, _, _, _, _, _, _, _, raw_tgt_labels) = data # never use target when infer - # Use greedy_search_infilling or beam_search_infilling to get predictions - output_ids = beam_search_infilling( - model, - src_ids, - src_sids, - eos_id=eos_id, - sos_id=sos_id, - attn_id=attn_id, - pad_id=pad_id, - unk_id=unk_id, - vocab_size=vocab_size, - max_decode_len=args.max_decode_len, - max_encode_len=args.max_encode_len, - beam_width=args.beam_width, - length_penalty=args.length_penalty, - tgt_type_id=tgt_type_id, - ) - - for ids in output_ids.tolist(): - if eos_id in ids: - ids = ids[: ids.index(eos_id)] - evaluated_sentences_ids.append(ids) - - for ids in raw_tgt_labels.numpy().tolist(): - ids = ids[: ids.index(eos_id)] - reference_sentences_ids.append(ids) - - score1 = rouge1.score(evaluated_sentences_ids, reference_sentences_ids) - score2 = rouge2.score(evaluated_sentences_ids, reference_sentences_ids) - - logger.info("Rouge-1: %.5f ,Rouge-2: %.5f" % (score1 * 100, score2 * 100)) - - -if __name__ == "__main__": - evaluate() diff --git a/model_zoo/ernie-gen/model.py b/model_zoo/ernie-gen/model.py deleted file mode 100644 index 31e30c6e9c33..000000000000 --- a/model_zoo/ernie-gen/model.py +++ /dev/null @@ -1,64 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import paddle -import paddle.nn as nn - - -class StackModel(nn.Layer): - def __init__(self, model): - super().__init__() - self.model = model - - def forward( - self, - src_ids, - src_sids, - src_pids, - tgt_ids, - tgt_sids, - tgt_pids, - attn_ids, - mask_src_2_src, - mask_tgt_2_srctgt, - mask_attn_2_srctgtattn, - tgt_labels, - tgt_pos, - ): - _, __, info = self.model( - src_ids, sent_ids=src_sids, pos_ids=src_pids, attn_bias=mask_src_2_src, encode_only=True - ) - cached_k, cached_v = info["caches"] - _, __, info = self.model( - tgt_ids, - sent_ids=tgt_sids, - pos_ids=tgt_pids, - attn_bias=mask_tgt_2_srctgt, - past_cache=(cached_k, cached_v), - encode_only=True, - ) - cached_k2, cached_v2 = info["caches"] - past_cache_k = [paddle.concat([k, k2], 1) for k, k2 in zip(cached_k, cached_k2)] - past_cache_v = [paddle.concat([v, v2], 1) for v, v2 in zip(cached_v, cached_v2)] - loss, _, __ = self.model( - attn_ids, - sent_ids=tgt_sids, - pos_ids=tgt_pids, - attn_bias=mask_attn_2_srctgtattn, - past_cache=(past_cache_k, past_cache_v), - tgt_labels=tgt_labels, - tgt_pos=tgt_pos, - ) - loss = loss.mean() - return loss diff --git a/model_zoo/ernie-gen/predict.py b/model_zoo/ernie-gen/predict.py deleted file mode 100644 index 408ded91231a..000000000000 --- a/model_zoo/ernie-gen/predict.py +++ /dev/null @@ -1,137 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse - -import paddle -from decode import beam_search_infilling, post_process -from encode import after_padding, convert_example -from paddle.io import DataLoader - -from paddlenlp.data import Pad, Tuple -from paddlenlp.datasets import load_dataset -from paddlenlp.transformers import ( - BertTokenizer, - ElectraTokenizer, - ErnieForGeneration, - ErnieTinyTokenizer, - ErnieTokenizer, - RobertaTokenizer, -) -from paddlenlp.utils.log import logger - -# fmt: off -parser = argparse.ArgumentParser('seq2seq model with ERNIE-GEN') -parser.add_argument("--model_name_or_path", default=None, type=str, required=True, help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(list(ErnieTokenizer.pretrained_init_configuration.keys()))) -parser.add_argument('--max_encode_len', type=int, default=24, help="The max encoding sentence length") -parser.add_argument('--max_decode_len', type=int, default=72, help="The max decoding sentence length") -parser.add_argument("--batch_size", default=50, type=int, help="Batch size per GPU/CPU for training.", ) -parser.add_argument('--beam_width', type=int, default=3, help="Beam search width") -parser.add_argument('--length_penalty', type=float, default=1.0, help="The length penalty during decoding") -parser.add_argument('--init_checkpoint', type=str, default=None, help='Checkpoint to warm start from') -parser.add_argument("--device", default="gpu", type=str, choices=["cpu", "gpu", "xpu"], help="The device to select to train the model, is must be cpu/gpu/xpu.") -# fmt: on - -args = parser.parse_args() - - -def predict(): - paddle.set_device(args.device) - - model = ErnieForGeneration.from_pretrained(args.model_name_or_path) - if "ernie-tiny" in args.model_name_or_path: - tokenizer = ErnieTinyTokenizer.from_pretrained(args.model_name_or_path) - elif "ernie" in args.model_name_or_path: - tokenizer = ErnieTokenizer.from_pretrained(args.model_name_or_path) - elif "roberta" in args.model_name_or_path or "rbt" in args.model_name_or_path: - tokenizer = RobertaTokenizer.from_pretrained(args.model_name_or_path) - elif "electra" in args.model_name_or_path: - tokenizer = ElectraTokenizer.from_pretrained(args.model_name_or_path) - else: - tokenizer = BertTokenizer.from_pretrained(args.model_name_or_path) - - dev_dataset = load_dataset("poetry", splits=("dev"), lazy=False) - attn_id = tokenizer.vocab["[ATTN]"] if "[ATTN]" in tokenizer.vocab else tokenizer.vocab["[MASK]"] - tgt_type_id = model.sent_emb.weight.shape[0] - 1 - - trans_func = convert_example( - tokenizer=tokenizer, - attn_id=attn_id, - tgt_type_id=tgt_type_id, - max_encode_len=args.max_encode_len, - max_decode_len=args.max_decode_len, - ) - - batchify_fn = lambda samples, fn=Tuple( - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_pids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_sids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_pids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_sids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # attn_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_labels - ): after_padding(fn(samples)) - - dev_dataset = dev_dataset.map(trans_func) - test_batch_sampler = paddle.io.BatchSampler(dev_dataset, batch_size=args.batch_size, shuffle=False) - data_loader = DataLoader( - dataset=dev_dataset, batch_sampler=test_batch_sampler, collate_fn=batchify_fn, num_workers=0, return_list=True - ) - - if args.init_checkpoint: - model_state = paddle.load(args.init_checkpoint) - model.set_state_dict(model_state) - - model.eval() - vocab = tokenizer.vocab - eos_id = vocab[tokenizer.sep_token] - sos_id = vocab[tokenizer.cls_token] - pad_id = vocab[tokenizer.pad_token] - unk_id = vocab[tokenizer.unk_token] - vocab_size = len(vocab) - logger.info("Predicting...") - for data in data_loader: - (src_ids, src_sids, src_pids, _, _, _, _, _, _, _, _, raw_tgt_labels) = data # never use target when infer - # Use greedy_search_infilling or beam_search_infilling to get predictions - output_ids = beam_search_infilling( - model, - src_ids, - src_sids, - eos_id=eos_id, - sos_id=sos_id, - attn_id=attn_id, - pad_id=pad_id, - unk_id=unk_id, - vocab_size=vocab_size, - max_decode_len=args.max_decode_len, - max_encode_len=args.max_encode_len, - beam_width=args.beam_width, - length_penalty=args.length_penalty, - tgt_type_id=tgt_type_id, - ) - - for source_ids, target_ids, predict_ids in zip( - src_ids.numpy().tolist(), raw_tgt_labels.numpy().tolist(), output_ids.tolist() - ): - if eos_id in predict_ids: - predict_ids = predict_ids[: predict_ids.index(eos_id)] - source_sentence = "".join(map(post_process, vocab.to_tokens(source_ids[1 : source_ids.index(eos_id)]))) - tgt_sentence = "".join(map(post_process, vocab.to_tokens(target_ids[1 : target_ids.index(eos_id)]))) - predict_ids = "".join(map(post_process, vocab.to_tokens(predict_ids))) - print("source :%s\ntarget :%s\npredict:%s\n" % (source_sentence, tgt_sentence, predict_ids)) - - -if __name__ == "__main__": - predict() diff --git a/model_zoo/ernie-gen/train.py b/model_zoo/ernie-gen/train.py deleted file mode 100644 index fa96b5599310..000000000000 --- a/model_zoo/ernie-gen/train.py +++ /dev/null @@ -1,330 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os -import time - -import paddle -import paddle.nn as nn -from decode import beam_search_infilling, post_process -from encode import after_padding, convert_example -from model import StackModel -from paddle.io import DataLoader -from tqdm import tqdm - -from paddlenlp.data import Pad, Tuple -from paddlenlp.datasets import load_dataset -from paddlenlp.metrics import Rouge1, Rouge2 -from paddlenlp.trainer.argparser import strtobool -from paddlenlp.transformers import ( - BertTokenizer, - ElectraTokenizer, - ErnieForGeneration, - ErnieTinyTokenizer, - ErnieTokenizer, - LinearDecayWithWarmup, - RobertaTokenizer, -) -from paddlenlp.utils.log import logger - -parser = argparse.ArgumentParser("seq2seq model with ERNIE-GEN") -parser.add_argument( - "--model_name_or_path", - default=None, - type=str, - required=True, - help="Path to pre-trained model or shortcut name selected in the list: " - + ", ".join(list(ErnieTokenizer.pretrained_init_configuration.keys())), -) -parser.add_argument( - "--output_dir", - default=None, - type=str, - required=True, - help="The output directory where the model predictions and checkpoints will be written.", -) -parser.add_argument("--max_encode_len", type=int, default=5, help="The max encoding sentence length") -parser.add_argument("--max_decode_len", type=int, default=5, help="The max decoding sentence length") -parser.add_argument( - "--batch_size", - default=8, - type=int, - help="Batch size per GPU/CPU for training.", -) -parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.") -parser.add_argument("--weight_decay", default=0.1, type=float, help="Weight decay if we apply some.") -parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.") -parser.add_argument( - "--num_epochs", - default=3, - type=int, - help="Total number of training epochs to perform.", -) -parser.add_argument("--warmup_proportion", default=0.1, type=float, help="Linear warmup proportion.") -parser.add_argument("--logging_steps", type=int, default=1, help="Log every X updates steps.") -parser.add_argument("--save_steps", type=int, default=100, help="Save checkpoint every X updates steps.") -parser.add_argument( - "--device", - default="gpu", - type=str, - choices=["cpu", "gpu", "xpu"], - help="The device to select to train the model, is must be cpu/gpu/xpu.", -) -parser.add_argument("--beam_width", type=int, default=1, help="Beam search width.") -parser.add_argument("--noise_prob", type=float, default=0.0, help="Probability of token be repalced.") -parser.add_argument( - "--use_random_noice", - action="store_true", - help="If set, replace target tokens with random token from vocabulary, else replace with `[NOISE]`.", -) -parser.add_argument("--label_smooth", type=float, default=0.0, help="The soft label smooth rate.") -parser.add_argument("--length_penalty", type=float, default=1.0, help="The length penalty during decoding.") -parser.add_argument("--init_checkpoint", type=str, default=None, help="Checkpoint to warm start from.") -parser.add_argument("--save_dir", type=str, default=None, help="Model output directory.") -parser.add_argument( - "--max_steps", - default=-1, - type=int, - help="If > 0: set total number of training steps to perform. Override num_epochs.", -) -parser.add_argument("--to_static", type=strtobool, default=False, help="Enable training under @to_static.") - -args = parser.parse_args() - - -def evaluate(model, data_loader, tokenizer, rouge1, rouge2, attn_id, tgt_type_id, args): - model.eval() - - vocab = tokenizer.vocab - eos_id = vocab[tokenizer.sep_token] - sos_id = vocab[tokenizer.cls_token] - pad_id = vocab[tokenizer.pad_token] - unk_id = vocab[tokenizer.unk_token] - vocab_size = len(vocab) - evaluated_sentences_ids = [] - reference_sentences_ids = [] - logger.info("Evaluating...") - for data in tqdm(data_loader): - (src_ids, src_tids, src_pids, _, _, _, _, _, _, _, _, raw_tgt_labels) = data # never use target when infer - # Use greedy_search_infilling or beam_search_infilling to get predictions - output_ids = beam_search_infilling( - model, - src_ids, - src_tids, - eos_id=eos_id, - sos_id=sos_id, - attn_id=attn_id, - pad_id=pad_id, - unk_id=unk_id, - vocab_size=vocab_size, - max_decode_len=args.max_decode_len, - max_encode_len=args.max_encode_len, - beam_width=args.beam_width, - length_penalty=args.length_penalty, - tgt_type_id=tgt_type_id, - ) - - for ids in output_ids.tolist(): - if eos_id in ids: - ids = ids[: ids.index(eos_id)] - evaluated_sentences_ids.append(ids) - - for ids in raw_tgt_labels.numpy().tolist(): - ids = ids[: ids.index(eos_id)] - reference_sentences_ids.append(ids) - - score1 = rouge1.score(evaluated_sentences_ids, reference_sentences_ids) - score2 = rouge2.score(evaluated_sentences_ids, reference_sentences_ids) - - logger.info("Rouge-1: %.5f ,Rouge-2: %.5f" % (score1 * 100, score2 * 100)) - - evaluated_sentences = [] - reference_sentences = [] - for ids in reference_sentences_ids[:5]: - reference_sentences.append("".join(map(post_process, vocab.to_tokens(ids)))) - for ids in evaluated_sentences_ids[:5]: - evaluated_sentences.append("".join(map(post_process, vocab.to_tokens(ids)))) - logger.debug(reference_sentences) - logger.debug(evaluated_sentences) - - model.train() - - -def train(): - paddle.set_device(args.device) - if paddle.distributed.get_world_size() > 1: - paddle.distributed.init_parallel_env() - - model = ErnieForGeneration.from_pretrained(args.model_name_or_path) - if "ernie-tiny" in args.model_name_or_path: - tokenizer = ErnieTinyTokenizer.from_pretrained(args.model_name_or_path) - elif "ernie" in args.model_name_or_path: - tokenizer = ErnieTokenizer.from_pretrained(args.model_name_or_path) - elif "roberta" in args.model_name_or_path or "rbt" in args.model_name_or_path: - tokenizer = RobertaTokenizer.from_pretrained(args.model_name_or_path) - elif "electra" in args.model_name_or_path: - tokenizer = ElectraTokenizer.from_pretrained(args.model_name_or_path) - else: - tokenizer = BertTokenizer.from_pretrained(args.model_name_or_path) - if args.init_checkpoint: - model_state = paddle.load(args.init_checkpoint) - model.set_state_dict(model_state) - - train_dataset, dev_dataset = load_dataset("poetry", splits=("train", "dev"), lazy=False) - attn_id = tokenizer.vocab["[ATTN]"] if "[ATTN]" in tokenizer.vocab else tokenizer.vocab["[MASK]"] - tgt_type_id = model.sent_emb.weight.shape[0] - 1 - - trans_func = convert_example( - tokenizer=tokenizer, - attn_id=attn_id, - tgt_type_id=tgt_type_id, - max_encode_len=args.max_encode_len, - max_decode_len=args.max_decode_len, - noise_prob=args.noise_prob, - use_random_noice=args.use_random_noice, - ) - - train_dataset = train_dataset.map(trans_func) - train_batch_sampler = paddle.io.DistributedBatchSampler(train_dataset, batch_size=args.batch_size, shuffle=True) - batchify_fn = lambda samples, fn=Tuple( - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # src_pids - Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # src_tids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_pids - Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # tgt_tids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # attn_ids - Pad(axis=0, pad_val=tokenizer.pad_token_id), # tgt_labels - ): after_padding(fn(samples)) - train_data_loader = DataLoader( - dataset=train_dataset, - batch_sampler=train_batch_sampler, - collate_fn=batchify_fn, - num_workers=0, - return_list=True, - ) - - dev_dataset = dev_dataset.map(trans_func) - dev_data_loader = DataLoader( - dataset=dev_dataset, batch_size=args.batch_size, collate_fn=batchify_fn, num_workers=0, return_list=True - ) - - label_num = model.word_emb.weight.shape[0] - train_model = StackModel(model) - - if args.to_static: - train_model = paddle.jit.to_static(train_model) - logger.info("Successfully to apply @to_static to the whole model.") - - if paddle.distributed.get_world_size() > 1: - # All 'forward' outputs derived from the module parameters using in DataParallel - # must participate in the calculation of losses and subsequent gradient calculations. - # So we use StackModel here to make the model only output loss in its 'forward' function. - train_model = paddle.DataParallel(train_model) - - num_training_steps = args.max_steps if args.max_steps > 0 else len(train_data_loader) * args.num_epochs - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - optimizer = paddle.optimizer.AdamW( - learning_rate=lr_scheduler, - epsilon=args.adam_epsilon, - parameters=model.parameters(), - weight_decay=args.weight_decay, - grad_clip=nn.ClipGradByGlobalNorm(1.0), - apply_decay_param_fun=lambda x: x in decay_params, - ) - - rouge1 = Rouge1() - rouge2 = Rouge2() - - global_step = 0 - tic_train = time.time() - for epoch in range(args.num_epochs): - for step, batch in enumerate(train_data_loader): - global_step += 1 - ( - src_ids, - src_tids, - src_pids, - tgt_ids, - tgt_tids, - tgt_pids, - attn_ids, - mask_src_2_src, - mask_tgt_2_srctgt, - mask_attn_2_srctgtattn, - tgt_labels, - _, - ) = batch - if args.label_smooth > 0.0: - tgt_labels = nn.functional.label_smooth( - nn.functional.one_hot(tgt_labels, label_num), epsilon=args.label_smooth - ) - tgt_pos = paddle.nonzero(attn_ids == attn_id) - loss = train_model( - src_ids, - src_tids, - src_pids, - tgt_ids, - tgt_tids, - tgt_pids, - attn_ids, - mask_src_2_src, - mask_tgt_2_srctgt, - mask_attn_2_srctgtattn, - tgt_labels, - tgt_pos, - ) - if global_step % args.logging_steps == 0: - if paddle.distributed.get_rank() == 0: - logger.info( - "global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s, lr: %.3e" - % ( - global_step, - epoch, - step, - loss, - args.logging_steps / (time.time() - tic_train), - lr_scheduler.get_lr(), - ) - ) - tic_train = time.time() - - loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - if ( - global_step % args.save_steps == 0 - or global_step == num_training_steps - and paddle.distributed.get_rank() == 0 - ): - evaluate(model, dev_data_loader, tokenizer, rouge1, rouge2, attn_id, tgt_type_id, args) - output_dir = os.path.join(args.output_dir, "model_%d" % global_step) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - model_to_save.save_pretrained(output_dir) - tokenizer.save_pretrained(output_dir) - if global_step >= num_training_steps: - return - - -if __name__ == "__main__": - train() diff --git a/model_zoo/ernie-health/README.md b/model_zoo/ernie-health/README.md deleted file mode 100644 index af5924fffec0..000000000000 --- a/model_zoo/ernie-health/README.md +++ /dev/null @@ -1,189 +0,0 @@ -# ERNIE-Health 中文医疗预训练模型 - -医疗领域存在大量的专业知识和医学术语,人类经过长时间的学习才能成为一名优秀的医生。那机器如何才能“读懂”医疗文献呢?尤其是面对电子病历、生物医疗文献中存在的大量非结构化、非标准化文本,计算机是无法直接使用、处理的。这就需要自然语言处理(Natural Language Processing,NLP)技术大展身手了。 - -## 模型介绍 - -本项目针对中文医疗语言理解任务,开源了中文医疗预训练模型 [ERNIE-Health](https://arxiv.org/pdf/2110.07244.pdf)(模型名称`ernie-health-chinese`)。 - -ERNIE-Health 依托百度文心 ERNIE 先进的知识增强预训练语言模型打造, 通过医疗知识增强技术进一步学习海量的医疗数据, 精准地掌握了专业的医学知识。ERNIE-Health 利用医疗实体掩码策略对专业术语等实体级知识学习, 学会了海量的医疗实体知识。同时,通过医疗问答匹配任务学习病患病状描述与医生专业治疗方案的对应关系,获得了医疗实体知识之间的内在联系。ERNIE-Health 共学习了 60 多万的医疗专业术语和 4000 多万的医疗专业问答数据,大幅提升了对医疗专业知识的理解和建模能力。此外,ERNIE-Health 还探索了多级语义判别预训练任务,提升了模型对医疗知识的学习效率。该模型的整体结构与 ELECTRA 相似,包括生成器和判别器两部分。 - - - -更多技术细节可参考论文 -- [Building Chinese Biomedical Language Models via Multi-Level Text Discrimination](https://arxiv.org/pdf/2110.07244.pdf) - -## 模型效果 - -ERNIE-Health模型以超越人类医学专家水平的成绩登顶中文医疗信息处理权威榜单 [CBLUE](https://github.com/CBLUEbenchmark/CBLUE) 冠军, 验证了 ERNIE 在医疗行业应用的重要价值。 - - - -相应的开源模型参数 ``ernie-health-chinese`` 在 CBLUE **验证集** 上的评测指标如下表所示: - -| Task | metric | results | results (fp16) | -| --------- | :------: | :-----: | :------------: | -| CHIP-STS | Macro-F1 | 0.88749 | 0.88555 | -| CHIP-CTC | Macro-F1 | 0.84136 | 0.83514 | -| CHIP-CDN | F1 | 0.76979 | 0.76489 | -| KUAKE-QQR | Accuracy | 0.83865 | 0.84053 | -| KUAKE-QTR | Accuracy | 0.69722 | 0.69722 | -| KUAKE-QIC | Accuracy | 0.81483 | 0.82046 | -| CMeEE | Micro-F1 | 0.66120 | 0.66026 | -| CMeIE | Micro-F1 | 0.61385 | 0.60076 | - -## 环境依赖 - -- paddlepaddle >= 2.2.0 -- paddlenlp >= 2.3.4 - -## 模型预训练 - -PaddleNLP中提供了ERNIE-Health训练好的模型参数。``ernie-health-chinese``版本为160G医疗文本数据上的训练结果,数据包括脱敏医患对话语料、医疗健康科普文章、脱敏医院电子医疗病例档案以及医学和临床病理学教材。本节提供了预训练的整体流程,可用于自定义数据的学习。 - -#### 注意: 预训练资源要求 - -- 推荐使用至少4张16G以上显存的GPU进行预训练。 -- 数据量应尽可能接近ERNIE-Health论文中训练数据的量级,以获得好的预训练模型效果。 -- 若资源有限,可以直接使用开源的ERNIE-Health模型进行微调,具体实现可参考 [CBLUE样例](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-health/cblue)。 - -#### 数据准备 - -- 数据编码:UTF-8 -- 数据格式:预训练文本数据放在同个目录下,每个文件中每行一句中文文本。 - -- 数据预处理:首先对原始文本进行分词,分词结果中非首中文字符替换为``##``前缀的字符(例如,``医疗``处理后得到``[医, ##疗]``)。接着将token转换为对应的id。最后将目录下的全部数据合并存储,token ids拼接后存储至``.npy``文件,每条样本的长度存储在``.npz``文件。 - -```shell -python preprocess.py --input_path ./raw_data/ --output_file ./data/samples --tokenize_tool lac --num_worker 8 -``` -可配置参数包括 -- ``input_path`` 为原始文本数据所在目录,该目录下包含至少一个中文文本文件,UTF-8编码。 -- ``output_file`` 为预处理后数据的存储路径及文件名(不包含后缀)。 -- ``tokenize_tool``表示分词工具,包括``lac``、``seg``和``jieba``,默认为``lac``。 -- ``logging_steps`` 表示日志打印间隔,每处理``logging_steps``个句子打印一次日志。 -- ``num_worker`` 表示使用的进程数,增加进程数可加速预处理。 - - -#### 单机单卡 - -``` -CUDA_VISIBLE_DEVICES=0 python run_pretrain.py \ - --input_dir ./data \ - --output_dir ./output \ - --learning_rate 1e-7 \ - --batch_size 10 \ - --adam_epsilon 1e-8 \ - --weight_decay 1e-2 \ - --warmup_steps 10000 \ - --max_steps 1000000 \ - --save_steps 10000 \ - --logging_steps 1 \ - --seed 1000 \ - --use_amp -``` - -#### 单机多卡 - -``` -unset CUDA_VISIBLE_DEVICES -python -m paddle.distributed.launch --gpus "0,1,2,3" run_pretrain.py \ - --input_dir ./data \ - --output_dir ./output \ - --learning_rate 1e-7 \ - --batch_size 10 \ - --adam_epsilon 1e-8 \ - --weight_decay 1e-2 \ - --warmup_steps 10000 \ - --max_steps 1000000 \ - --save_steps 10000 \ - --logging_steps 1 \ - --seed 1000 \ - --use_amp -``` - -可配置参数包括 -- ``model_name_or_path``表示内置模型参数名(目前支持``ernie-health-chinese``),或者模型参数配置路径(这时需配置 --init_from_ckpt 参数一起使用,一般用于断点恢复训练场景。) -- ``input_dir``表示训练数据所在目录,该目录下要有``.npy``和``.npz``两个文件,格式与```preprocess.py``预处理结果相同。 -- ``output_dir``表示预训练模型参数和训练日志的保存目录。 -- ``batch_size``表示每次迭代每张卡上的样本数量。当batch_size=4时,运行时单卡约需要12G显存。如果实际GPU显存小于12G或大大多于12G,可适当调小/调大此配置。 -- ``learning_rate`` 表示基础学习率大小,将于learning rate scheduler产生的值相乘作为当前学习率。 -- ``max_seq_length`` 表示最大句子长度,超过该长度将被截断。 -- ``weight_decay`` 表示每次迭代中参数缩小的比例,该值乘以学习率为真正缩小的比例。 -- ``adam_epsilon`` 表示adam优化器中的epsilon值。 -- ``warmup_steps`` 表示学习率逐渐升高到基础学习率(即上面配置的learning_rate)所需要的迭代数,最早的使用可以参考[这篇论文](https://arxiv.org/pdf/1706.02677.pdf)。 -- ``num_epochs`` 表示训练轮数。 -- ``logging_steps`` 表示日志打印间隔。 -- ``save_steps`` 表示模型保存间隔。 -- ``max_steps`` 如果配置且大于0,表示预训练最多执行的迭代数量;如果不配置或配置小于0,则根据输入数据量、``batch_size``和``num_epochs``来确定预训练迭代数量。 -- ``device`` 表示使用的设备类型。默认为GPU,可以配置为CPU、GPU、XPU。若希望使用GPU训练,将其设置为GPU,同时环境变量CUDA_VISIBLE_DEVICES配置要使用的GPU id。 -- ``use_amp`` 表示是否开启混合精度(float16)进行训练,默认不开启。如果在命令中加上了--use_amp,则会开启。 -- ``init_from_ckpt`` 表示是否从某个checkpoint继续训练(断点恢复训练),默认不开启。如果在命令中加上了--init_from_ckpt,且 --model_name_or_path 配置的是路径,则会开启从某个checkpoint继续训练。 - -#### Trainer 训练版本 -本样例同时提供了Trainer版本的预训练流程,预训练重启、可视化等流程较为完备。需要从源码安装paddlenlp使用。 - -``` -unset CUDA_VISIBLE_DEVICES -task_name="eheath-pretraining" - -python -u -m paddle.distributed.launch \ - --gpus 0,1,2,3,4,5,6,7 \ - run_pretrain_trainer.py \ - --input_dir "./data" \ - --output_dir "output/$task_name" \ - --max_seq_length 512 \ - --gradient_accumulation_steps 1\ - --per_device_train_batch_size 8 \ - --learning_rate 0.001 \ - --max_steps 1000000 \ - --save_steps 50000 \ - --weight_decay 0.01 \ - --warmup_ratio 0.01 \ - --max_grad_norm 1.0 \ - --logging_steps 20 \ - --dataloader_num_workers 2 \ - --device "gpu"\ - --fp16 \ - --fp16_opt_level "O1" \ - --do_train \ - --disable_tqdm True\ - --save_total_limit 10 -``` -大部分参数含义如上文所述,这里简要介绍一些新参数: - -- ``per_device_train_batch_size`` 同上文batch_size。训练时,每次迭代每张卡上的样本数目。 -- ``warmup_ratio`` 与warmup_steps类似,warmup步数占总步数的比例。 -- ``fp16`` 与`use_amp`相同,表示使用混合精度 -- ``fp16_opt_level`` 混合精度的策略。注:O2训练eHealth存在部分问题,暂时请勿使用。 -- ``save_total_limit`` 保存的ckpt数量的最大限制 - -## 微调 - -模型预训练结束后,可以对判别器进行微调以完成下游医疗任务。不同任务的模型加载方式如下: - -``` -from paddlenlp.transformers import * - -tokenizer = AutoTokenizer.from_pretrained('ernie-health-chinese') - -# 分类任务 -model = AutoModelForSequenceClassification.from_pretrained('ernie-health-chinese') -# 序列标注任务 -model = AutoModelForTokenClassification.from_pretrained('ernie-health-chinese') -# 阅读理解任务 -model = AutoModelForQuestionAnswering.from_pretrained('ernie-health-chinese') -``` - -本项目提供了在 CBLUE 数据集上的微调脚本,包括分类、实体识别和关系抽取三类任务,详细信息可参考 ``cblue``[目录](./cblue)。 - -## 部署 - -我们为ERNIE-Health微调后的模型提供了Python端部署方案,请根据实际情况进行实现。 - -详细部署流程请参考:[基于ONNXRuntime推理部署指南](./cblue/deploy/predictor/) - - -## Reference - -Wang, Quan, et al. “Building Chinese Biomedical Language Models via Multi-Level Text Discrimination.” arXiv preprint arXiv:2110.07244 (2021). [pdf](https://arxiv.org/abs/2110.07244) diff --git a/model_zoo/ernie-health/cblue/README.md b/model_zoo/ernie-health/cblue/README.md deleted file mode 100644 index ce37227d052c..000000000000 --- a/model_zoo/ernie-health/cblue/README.md +++ /dev/null @@ -1,130 +0,0 @@ -# 使用医疗领域预训练模型Fine-tune完成中文医疗语言理解任务 - -本示例展示了中文医疗预训练模型 ERNIE-Health([Building Chinese Biomedical Language Models via Multi-Level Text Discrimination](https://arxiv.org/abs/2110.07244))如何 Fine-tune 完成中文医疗语言理解任务。 - -## 数据集介绍 - -本项目使用了中文医学语言理解测评([Chinese Biomedical Language Understanding Evaluation,CBLUE](https://github.com/CBLUEbenchmark/CBLUE))1.0 版本数据集,这是国内首个面向中文医疗文本处理的多任务榜单,涵盖了医学文本信息抽取(实体识别、关系抽取)、医学术语归一化、医学文本分类、医学句子关系判定和医学问答共5大类任务8个子任务。其数据来源分布广泛,包括医学教材、电子病历、临床试验公示以及互联网用户真实查询等。该榜单一经推出便受到了学界和业界的广泛关注,已逐渐发展成为检验AI系统中文医疗信息处理能力的“金标准”。 - -* CMeEE:中文医学命名实体识别 -* CMeIE:中文医学文本实体关系抽取 -* CHIP-CDN:临床术语标准化任务 -* CHIP-CTC:临床试验筛选标准短文本分类 -* CHIP-STS:平安医疗科技疾病问答迁移学习 -* KUAKE-QIC:医疗搜索检索词意图分类 -* KUAKE-QTR:医疗搜索查询词-页面标题相关性 -* KUAKE-QQR:医疗搜索查询词-查询词相关性 - -更多信息可参考CBLUE的[github](https://github.com/CBLUEbenchmark/CBLUE/blob/main/README_ZH.md)。其中对于临床术语标准化任务(CHIP-CDN),我们按照 ERNIE-Health 中的方法通过检索将原多分类任务转换为了二分类任务,即给定一诊断原词和一诊断标准词,要求判定后者是否是前者对应的诊断标准词。本项目提供了检索处理后的 CHIP-CDN 数据集(简写`CHIP-CDN-2C`),且构建了基于该数据集的example代码。 - -## 模型介绍 - -ERNIE-Health 模型的整体结构与 ELECTRA 相似,包括生成器和判别器两部分。 而 Fine-tune 过程只用到了判别器模块,由 12 层 Transformer 网络组成。 - -## 快速开始 - -### 代码结构说明 - -以下是本项目主要代码结构及说明: - -```text -cblue/ -├── train_classification.py # 文本分类任务训练评估脚本 -├── train_ner.py # 实体识别任务训练评估脚本 -├── train_spo.py # 关系抽取任务训练评估脚本 -├── export_model.py # 动态图导出静态图参数脚本 -└── README.md -``` - -### 依赖安装 - -```shell -pip install xlrd==1.2.0 -``` - -### 模型训练 - -我们按照任务类别划分,同时提供了8个任务的样例代码。可以运行下边的命令,在训练集上进行训练,并在**验证集**上进行验证。 - -**训练参数设置(Training setup)及结果** - -| Task | epochs | batch_size | learning_rate | max_seq_length | metric | results | results (fp16) | -| --------- | :----: | :--------: | :-----------: | :------------: | :------: | :-----: | :------------: | -| CHIP-STS | 4 | 16 | 3e-5 | 96 | Macro-F1 | 0.88749 | 0.88555 | -| CHIP-CTC | 4 | 32 | 6e-5 | 160 | Macro-F1 | 0.84136 | 0.83514 | -| CHIP-CDN | 16 | 256 | 3e-5 | 32 | F1 | 0.76979 | 0.76489 | -| KUAKE-QQR | 2 | 32 | 6e-5 | 64 | Accuracy | 0.83865 | 0.84053 | -| KUAKE-QTR | 4 | 32 | 6e-5 | 64 | Accuracy | 0.69722 | 0.69722 | -| KUAKE-QIC | 4 | 32 | 6e-5 | 128 | Accuracy | 0.81483 | 0.82046 | -| CMeEE | 2 | 32 | 6e-5 | 128 | Micro-F1 | 0.66120 | 0.66026 | -| CMeIE | 100 | 12 | 6e-5 | 300 | Micro-F1 | 0.61385 | 0.60076 | - -可支持配置的参数: - -* `save_dir`:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。 -* `max_seq_length`:可选,ELECTRA模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。 -* `batch_size`:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。 -* `learning_rate`:可选,Fine-tune的最大学习率;默认为6e-5。 -* `weight_decay`:可选,控制正则项力度的参数,用于防止过拟合,默认为0.01。 -* `epochs`: 训练轮次,默认为3。 -* `max_steps`: 最大训练步数。若训练`epochs`轮包含的训练步数大于该值,则达到`max_steps`后就提前结束。 -* `valid_steps`: evaluate的间隔steps数,默认100。 -* `save_steps`: 保存checkpoints的间隔steps数,默认100。 -* `logging_steps`: 日志打印的间隔steps数,默认10。 -* `warmup_proption`:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.1。 -* `init_from_ckpt`:可选,模型参数路径,恢复模型训练;默认为None。 -* `seed`:可选,随机种子,默认为1000. -* `device`: 选用什么设备进行训练,可选cpu、gpu或npu。如使用gpu训练则参数gpus指定GPU卡号。 -* `use_amp`: 是否使用混合精度训练,默认为False。 - - -#### 医疗文本分类任务 - -```shell -$ unset CUDA_VISIBLE_DEVICES -$ python -m paddle.distributed.launch --gpus '0,1,2,3' train_classification.py --dataset CHIP-CDN-2C --batch_size 256 --max_seq_length 32 --learning_rate 3e-5 --epochs 16 -``` - -其他可支持配置的参数: - -* `dataset`:可选,CHIP-CDN-2C CHIP-CTC CHIP-STS KUAKE-QIC KUAKE-QTR KUAKE-QQR,默认为KUAKE-QIC数据集。 - -#### 医疗命名实体识别任务(CMeEE) - -```shell -$ export CUDA_VISIBLE_DEVICES=0 -$ python train_ner.py --batch_size 32 --max_seq_length 128 --learning_rate 6e-5 --epochs 12 -``` - -#### 医疗关系抽取任务(CMeIE) - -```shell -$ export CUDA_VISIBLE_DEVICES=0 -$ python train_spo.py --batch_size 12 --max_seq_length 300 --learning_rate 6e-5 --epochs 100 -``` - -### 静态图模型导出 - -使用动态图训练结束之后,还可以将动态图参数导出成静态图参数,用于部署推理等,具体代码见export_model.py。静态图参数保存在`output_path`指定路径中。 - -运行方式: -1. 分类任务静态图模型导出 -```shell -python export_model.py --train_dataset CHIP-CDN-2C --params_path=./checkpoint/model_900/ --output_path=./export -``` - -2. SPO任务静态图模型导出 -```shell -python export_model.py --train_dataset CMeIE --params_path=./checkpoint/model_900/ --output_path=./export -``` - -3. NER任务静态图模型导出 -```shell -python export_model.py --train_dataset CMeEE --params_path=./checkpoint/model_1500/ --output_path=./export -``` - -**NOTICE**: train_dataset分类任务选择填上训练数据集名称,params_path选择最好参数的模型的路径。 - -[1] CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark [pdf](https://arxiv.org/abs/2106.08087) [git](https://github.com/CBLUEbenchmark/CBLUE) [web](https://tianchi.aliyun.com/specials/promotion/2021chinesemedicalnlpleaderboardchallenge) - -[2] Wang, Quan, et al. “Building Chinese Biomedical Language Models via Multi-Level Text Discrimination.” arXiv preprint arXiv:2110.07244 (2021). [pdf](https://arxiv.org/abs/2110.07244) diff --git a/model_zoo/ernie-health/cblue/deploy/predictor/README.md b/model_zoo/ernie-health/cblue/deploy/predictor/README.md deleted file mode 100644 index 4741a43385ff..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/predictor/README.md +++ /dev/null @@ -1,191 +0,0 @@ -# 基于ONNXRuntime推理部署指南 - -本示例以[CBLUE数据集微调](../../README.md)得到的ERNIE-Health模型为例,分别提供了文本分类任务、实体识别任务和关系抽取任务的部署代码,自定义数据集可参考实现。 -在推理部署前需将微调后的动态图模型转换导出为静态图,详细步骤见[静态图模型导出](../../README.md)。 - -**目录** - * [环境安装](#环境安装) - * [GPU部署推理样例](#gpu部署推理样例) - * [CPU部署推理样例](#cpu部署推理样例) - * [性能与精度测试](#性能与精度测试) - * [GPU精度与性能](#gpu精度与性能) - * [CPU精度与性能](#cpu精度与性能) - -## 环境安装 - -ONNX模型转换和推理部署依赖于Paddle2ONNX和ONNXRuntime。其中Paddle2ONNX支持将Paddle静态图模型转化为ONNX模型格式,算子目前稳定支持导出ONNX Opset 7~15,更多细节可参考:[Paddle2ONNX](https://github.com/PaddlePaddle/Paddle2ONNX)。 - -#### GPU端 -请先确保机器已正确安装NVIDIA相关驱动和基础软件,确保CUDA >= 11.2,CuDNN >= 8.2,并使用以下命令安装所需依赖: -``` -python -m pip install -r requirements_gpu.tx -``` -\* 如需使用半精度(FP16)部署,请确保GPU设备的CUDA计算能力 (CUDA Compute Capability) 大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。 更多关于CUDA Compute Capability和精度支持情况请参考NVIDIA文档:[GPU硬件与支持精度对照表](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-840-ea/support-matrix/index.html#hardware-precision-matrix) -#### CPU端 -请使用如下命令安装所需依赖: -``` -python -m pip install -r requirements_cpu.txt -``` -## GPU部署推理样例 - -请使用如下命令进行GPU上的部署,可用`use_fp16`开启**半精度部署推理加速**,可用`device_id`**指定GPU卡号**。 - -- 文本分类任务 - -``` -python infer_classification.py --device gpu --device_id 0 --dataset KUAKE-QIC --model_path_prefix ../../export/inference -``` - -- 实体识别任务 - -``` -python infer_ner.py --device gpu --device_id 0 --dataset CMeEE --model_path_prefix ../../export/inference -``` - -- 关系抽取任务 - -``` -python infer_spo.py --device gpu --device_id 0 --dataset CMeIE --model_path_prefix ../../export/inference -``` - -可支持配置的参数: - -* `model_path_prefix`:必须,待推理模型路径前缀。 -* `model_name_or_path`:选择预训练模型;默认为"ernie-health-chinese"。 -* `dataset`:CBLUE中的训练数据集。 - * `文本分类任务`:包括KUAKE-QIC, KUAKE-QQR, KUAKE-QTR, CHIP-CTC, CHIP-STS, CHIP-CDN-2C;默认为KUAKE-QIC。 - * `实体抽取任务`:默认为CMeEE。 - * `关系抽取任务`:默认为CMeIE。 -* `max_seq_length`:模型使用的最大序列长度,最大不能超过512;`关系抽取任务`默认为300,其余默认为128。 -* `use_fp16`:选择是否开启FP16进行加速,仅在`devive=gpu`时生效;默认关闭。 -* `batch_size`:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为200。 -* `device`: 选用什么设备进行训练,可选cpu、gpu;默认为gpu。 -* `device_id`: 选择GPU卡号;默认为0。 -* `data_file`:本地待预测数据文件;默认为None。 - -#### 本地数据集加载 -如需使用本地数据集,请指定本地待预测数据文件 `data_file`,每行一条样例,单文本输入每句一行,双文本输入以`\t`分隔符隔开。例如 - -**ctc-data.txt** -``` -在过去的6个月曾服用偏头痛预防性药物或长期服用镇痛药物者,以及有酒精依赖或药物滥用习惯者; -患有严重的冠心病、脑卒中,以及传染性疾病、精神疾病者; -活动性乙肝(包括大三阳或小三阳)或血清学指标(HBsAg或/和HBeAg或/和HBcAb)阳性者,丙肝、肺结核、巨细胞病毒、严重真菌感染或HIV感染; -... -``` - -**sts-data.txt** -``` -糖尿病能吃减肥药吗?能治愈吗?\t糖尿病为什么不能吃减肥药? -为什么慢性乙肝会急性发作\t引起隐匿性慢性乙肝的原因是什么 -标准血压是多少高血压指?低血压又指?\t半月前检查血压100/130,正常吗? -... -``` - -## CPU部署推理样例 - -请使用如下命令进行CPU上的部署,可用`num_threads`**调整预测线程数量**。 - -- 文本分类任务 - -``` -python infer_classification.py --device cpu --dataset KUAKE-QIC --model_path_prefix ../../export/inference -``` - -- 实体识别任务 - -``` -python infer_ner.py --device cpu --dataset CMeEE --model_path_prefix ../../export/inference -``` - -- 关系抽取任务 - -``` -python infer_spo.py --device cpu --dataset CMeIE --model_path_prefix ../../export/inference -``` - -可支持配置的参数: - -* `model_path_prefix`:必须,待推理模型路径前缀。 -* `model_name_or_path`:选择预训练模型;默认为"ernie-health-chinese"。 -* `dataset`:CBLUE中的训练数据集。 - * `文本分类任务`:包括KUAKE-QIC, KUAKE-QQR, KUAKE-QTR, CHIP-CTC, CHIP-STS, CHIP-CDN-2C;默认为KUAKE-QIC。 - * `实体抽取任务`:默认为CMeEE。 - * `关系抽取任务`:默认为CMeIE。 -* `max_seq_length`:模型使用的最大序列长度,最大不能超过512;`关系抽取任务`默认为300,其余默认为128。 -* `batch_size`:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为200。 -* `device`: 选用什么设备进行训练,可选cpu、gpu;默认为gpu。 -* `num_threads`:cpu线程数,在`device=gpu`时影响较小;默认为cpu的物理核心数量。 -* `data_file`:本地待预测数据文件,格式见[GPU部署推理样例](#本地数据集加载)中的介绍;默认为None。 - -## 性能与精度测试 - -本节提供了在CBLUE数据集上预测的性能和精度数据,以供参考。 - -测试配置如下: - -1. 数据集 - - 使用CBLUE数据集中的开发集用于ERNIE-Health微调模型部署推理的性能与精度测试,包括 - - - 医疗搜索检索词意图分类(KUAKE-QIC)任务 - - 医疗搜索查询词-页面标题相关性(KUAKE-QTR)任务 - - 医疗搜索查询词-查询词相关性(KUAKE-QQR)任务 - - 临床试验筛选标准短文本分类(CHIP-CTC)任务 - - 平安医疗科技疾病问答迁移学习(CHIP-STS)任务 - - 临床术语标准化匹配(CHIP-CDN-2C)任务 - - 中文医学命名实体识别(CMeEE)任务 - - 中文医学文本实体关系抽取(CMeIE)任务 - -2. 物理机环境 - - 系统: CentOS Linux release 7.7.1908 (Core) - - GPU: Tesla V100-SXM2-32GB - - CPU: Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz - - CUDA: 11.2 - - cuDNN: 8.1.0 - - Driver Version: 460.27.04 - - 内存: 630 GB - -3. PaddlePaddle 版本:2.3.0 - -4. PaddleNLP 版本:2.3.4 - -5. 性能数据指标:latency。latency 测试方法:固定 batch size 为 200(CHIP-CDN-2C 和 CMeIE 数据集为 20),部署运行时间 total_time,计算 latency = total_time / total_samples - - -### GPU精度与性能 - -| 数据集 | 最大文本长度 | 精度评估指标 | FP32 指标值 | FP16 指标值 | FP32 latency(ms) | FP16 latency(ms) | -| ---------- | ---------- | ---------- | ---------- | ---------- | ---------------- | ---------------- | -| KUAKE-QIC | 128 | Accuracy | 0.8046 | 0.8046 | 1.92 | 0.46 | -| KUAKE-QTR | 64 | Accuracy | 0.6886 | 0.6876 (-) | 0.92 | 0.23 | -| KUAKE-QQR | 64 | Accuracy | 0.7755 | 0.7755 | 0.61 | 0.16 | -| CHIP-CTC | 160 | Macro F1 | 0.8445 | 0.8446 (+) | 2.34 | 0.60 | -| CHIP-STS | 96 | Macro F1 | 0.8892 | 0.8892 | 1.39 | 0.35 | -| CHIP-CDN-2C | 256 | Macro F1 | 0.8921 | 0.8920 (-) | 1.58 | 0.48 | -| CMeEE | 128 | Micro F1 | 0.6469 | 0.6468 (-) | 1.90 | 0.48 | -| CMeIE | 300 | Micro F1 | 0.5903 | 0.5902 (-) | 50.32 | 41.50 | - -经过FP16转化加速比达到 1.2 ~ 4 倍左右,精度变化在 1e-4 ~ 1e-3 内。 - -### CPU精度与性能 - -测试环境及说明如上,测试 CPU 性能时,线程数设置为40。 - -| 数据集 | 最大文本长度 | 精度评估指标 | FP32 指标值 | FP32 latency(ms) | -| ---------- | ------------ | ------------ | ---------- | ---------------- | -| KUAKE-QIC | 128 | Accuracy | 0.8046 | 37.72 | -| KUAKE-QTR | 64 | Accuracy | 0.6886 | 18.40 | -| KUAKE-QQR | 64 | Accuracy | 0.7755 | 10.34 | -| CHIP-CTC | 160 | Macro F1 | 0.8445 | 47.43 | -| CHIP-STS | 96 | Macro F1 | 0.8892 | 27.67 | -| CHIP-CDN-2C | 256 | Micro F1 | 0.8921 | 26.86 | -| CMeEE | 128 | Micro F1 | 0.6469 | 37.59 | -| CMeIE | 300 | Micro F1 | 0.5902 | 213.04 | diff --git a/model_zoo/ernie-health/cblue/deploy/predictor/infer_classification.py b/model_zoo/ernie-health/cblue/deploy/predictor/infer_classification.py deleted file mode 100644 index 2c4586fc9bc2..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/predictor/infer_classification.py +++ /dev/null @@ -1,146 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse - -import psutil -from predictor import CLSPredictor - -from paddlenlp.utils.log import logger - - -def parse_args(): - parser = argparse.ArgumentParser() - parser.add_argument( - "--model_path_prefix", type=str, required=True, help="The path prefix of inference model to be used." - ) - parser.add_argument( - "--model_name_or_path", default="ernie-health-chinese", type=str, help="The directory or name of model." - ) - parser.add_argument("--dataset", default="KUAKE-QIC", type=str, help="Dataset for text classfication.") - parser.add_argument("--data_file", default=None, type=str, help="The data to predict with one sample per line.") - parser.add_argument( - "--max_seq_length", default=128, type=int, help="The maximum total input sequence length after tokenization." - ) - parser.add_argument( - "--use_fp16", - action="store_true", - help="Whether to use fp16 inference, only takes effect when deploying on gpu.", - ) - parser.add_argument("--batch_size", default=200, type=int, help="Batch size per GPU/CPU for predicting.") - parser.add_argument( - "--num_threads", default=psutil.cpu_count(logical=False), type=int, help="num_threads for cpu." - ) - parser.add_argument( - "--device", choices=["cpu", "gpu"], default="gpu", help="Select which device to train model, defaults to gpu." - ) - parser.add_argument("--device_id", default=0, help="Select which gpu device to train model.") - args = parser.parse_args() - return args - - -LABEL_LIST = { - "kuake-qic": ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"], - "kuake-qtr": ["完全不匹配", "很少匹配,有一些参考价值", "部分匹配", "完全匹配"], - "kuake-qqr": ["B为A的语义父集,B指代范围大于A; 或者A与B语义毫无关联。", "B为A的语义子集,B指代范围小于A。", "表示A与B等价,表述完全一致。"], - "chip-ctc": [ - "成瘾行为", - "居住情况", - "年龄", - "酒精使用", - "过敏耐受", - "睡眠", - "献血", - "能力", - "依存性", - "知情同意", - "数据可及性", - "设备", - "诊断", - "饮食", - "残疾群体", - "疾病", - "教育情况", - "病例来源", - "参与其它试验", - "伦理审查", - "种族", - "锻炼", - "性别", - "健康群体", - "实验室检查", - "预期寿命", - "读写能力", - "含有多类别的语句", - "肿瘤进展", - "疾病分期", - "护理", - "口腔相关", - "器官组织状态", - "药物", - "怀孕相关", - "受体状态", - "研究者决定", - "风险评估", - "性取向", - "体征(医生检测)", - " 吸烟状况", - "特殊病人特征", - "症状(患者感受)", - "治疗或手术", - ], - "chip-sts": ["语义不同", "语义相同"], - "chip-cdn-2c": ["否", "是"], -} - -TEXT = { - "kuake-qic": ["心肌缺血如何治疗与调养呢?", "什么叫痔核脱出?什么叫外痔?"], - "kuake-qtr": [["儿童远视眼怎么恢复视力", "远视眼该如何保养才能恢复一些视力"], ["抗生素的药有哪些", "抗生素类的药物都有哪些?"]], - "kuake-qqr": [["茴香是发物吗", "茴香怎么吃?"], ["气的胃疼是怎么回事", "气到胃痛是什么原因"]], - "chip-ctc": ["(1)前牙结构发育不良:釉质发育不全、氟斑牙、四环素牙等;", "怀疑或确有酒精或药物滥用史;"], - "chip-sts": [["糖尿病能吃减肥药吗?能治愈吗?", "糖尿病为什么不能吃减肥药"], ["H型高血压的定义", "WHO对高血压的最新分类定义标准数值"]], - "chip-cdn-2c": [["1型糖尿病性植物神经病变", " 1型糖尿病肾病IV期"], ["髂腰肌囊性占位", "髂肌囊肿"]], -} - -METRIC = { - "kuake-qic": "acc", - "kuake-qtr": "acc", - "kuake-qqr": "acc", - "chip-ctc": "macro", - "chip-sts": "macro", - "chip-cdn-2c": "macro", -} - - -def main(): - args = parse_args() - - for arg_name, arg_value in vars(args).items(): - logger.info("{:20}: {}".format(arg_name, arg_value)) - - args.dataset = args.dataset.lower() - label_list = LABEL_LIST[args.dataset] - if args.data_file is not None: - with open(args.data_file, "r") as fp: - input_data = [x.strip().split("\t") for x in fp.readlines()] - input_data = [x[0] if len(x) == 1 else x for x in input_data] - else: - input_data = TEXT[args.dataset] - - predictor = CLSPredictor(args, label_list) - predictor.predict(input_data) - - -if __name__ == "__main__": - main() diff --git a/model_zoo/ernie-health/cblue/deploy/predictor/infer_ner.py b/model_zoo/ernie-health/cblue/deploy/predictor/infer_ner.py deleted file mode 100644 index afc2d2ba99fc..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/predictor/infer_ner.py +++ /dev/null @@ -1,116 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse - -import psutil -from predictor import NERPredictor - -from paddlenlp.utils.log import logger - - -def parse_args(): - parser = argparse.ArgumentParser() - parser.add_argument( - "--model_path_prefix", type=str, required=True, help="The path prefix of inference model to be used." - ) - parser.add_argument( - "--model_name_or_path", default="ernie-health-chinese", type=str, help="The directory or name of model." - ) - parser.add_argument("--dataset", default="CMeEE", type=str, help="Dataset for named entity recognition.") - parser.add_argument("--data_file", default=None, type=str, help="The data to predict with one sample per line.") - parser.add_argument( - "--max_seq_length", default=128, type=int, help="The maximum total input sequence length after tokenization" - ) - parser.add_argument( - "--use_fp16", - action="store_true", - help="Whether to use fp16 inference, only takes effect when deploying on gpu.", - ) - parser.add_argument("--batch_size", default=200, type=int, help="Batch size per GPU/CPU for predicting.") - parser.add_argument( - "--num_threads", default=psutil.cpu_count(logical=False), type=int, help="Number of threads for cpu." - ) - parser.add_argument( - "--device", choices=["cpu", "gpu"], default="gpu", help="Select which device to train model, defaults to gpu." - ) - parser.add_argument("--device_id", default=0, help="Select which gpu device to train model.") - args = parser.parse_args() - return args - - -LABEL_LIST = { - "cmeee": [ - [ - "B-bod", - "I-bod", - "E-bod", - "S-bod", - "B-dis", - "I-dis", - "E-dis", - "S-dis", - "B-pro", - "I-pro", - "E-pro", - "S-pro", - "B-dru", - "I-dru", - "E-dru", - "S-dru", - "B-ite", - "I-ite", - "E-ite", - "S-ite", - "B-mic", - "I-mic", - "E-mic", - "S-mic", - "B-equ", - "I-equ", - "E-equ", - "S-equ", - "B-dep", - "I-dep", - "E-dep", - "S-dep", - "O", - ], - ["B-sym", "I-sym", "E-sym", "S-sym", "O"], - ] -} - -TEXT = {"cmeee": ["研究证实,细胞减少与肺内病变程度及肺内炎性病变吸收程度密切相关。", "可为不规则发热、稽留热或弛张热,但以不规则发热为多,可能与患儿应用退热药物导致热型不规律有关。"]} - - -def main(): - args = parse_args() - - for arg_name, arg_value in vars(args).items(): - logger.info("{:20}: {}".format(arg_name, arg_value)) - - dataset = args.dataset.lower() - label_list = LABEL_LIST[dataset] - if args.data_file is not None: - with open(args.data_file, "r") as fp: - input_data = [x.strip() for x in fp.readlines()] - else: - input_data = TEXT[dataset] - - predictor = NERPredictor(args, label_list) - predictor.predict(input_data) - - -if __name__ == "__main__": - main() diff --git a/model_zoo/ernie-health/cblue/deploy/predictor/infer_spo.py b/model_zoo/ernie-health/cblue/deploy/predictor/infer_spo.py deleted file mode 100644 index 972eade14d75..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/predictor/infer_spo.py +++ /dev/null @@ -1,124 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse - -import psutil -from predictor import SPOPredictor - -from paddlenlp.utils.log import logger - - -def parse_args(): - parser = argparse.ArgumentParser() - parser.add_argument( - "--model_path_prefix", type=str, required=True, help="The path prefix of inference model to be used." - ) - parser.add_argument( - "--model_name_or_path", default="ernie-health-chinese", type=str, help="The directory or name of model." - ) - parser.add_argument("--dataset", default="CMeIE", type=str, help="Dataset for named entity recognition.") - parser.add_argument("--data_file", default=None, type=str, help="The data to predict with one sample per line.") - parser.add_argument( - "--max_seq_length", default=300, type=int, help="The maximum total input sequence length after tokenization." - ) - parser.add_argument( - "--use_fp16", - action="store_true", - help="Whether to use fp16 inference, only takes effect when deploying on gpu.", - ) - parser.add_argument( - "--num_threads", default=psutil.cpu_count(logical=False), type=int, help="num_threads for cpu." - ) - parser.add_argument("--batch_size", default=20, type=int, help="Batch size per GPU/CPU for predicting.") - parser.add_argument( - "--device", choices=["cpu", "gpu"], default="gpu", help="Select which device to train model, defaults to gpu." - ) - parser.add_argument("--device_id", default=0, help="Select which gpu device to train model.") - args = parser.parse_args() - return args - - -LABEL_LIST = { - "cmeie": [ - "预防", - "阶段", - "就诊科室", - "辅助治疗", - "化疗", - "放射治疗", - "手术治疗", - "实验室检查", - "影像学检查", - "辅助检查", - "组织学检查", - "内窥镜检查", - "筛查", - "多发群体", - "发病率", - "发病年龄", - "多发地区", - "发病性别倾向", - "死亡率", - "多发季节", - "传播途径", - "并发症", - "病理分型", - "相关(导致)", - "鉴别诊断", - "相关(转化)", - "相关(症状)", - "临床表现", - "治疗后症状", - "侵及周围组织转移的症状", - "病因", - "高危因素", - "风险评估因素", - "病史", - "遗传因素", - "发病机制", - "病理生理", - "药物治疗", - "发病部位", - "转移部位", - "外侵部位", - "预后状况", - "预后生存率", - "同义词", - ] -} - -TEXT = {"cmeie": ["骶髂关节炎是明确诊断JAS的关键条件。若有肋椎关节病变会使胸部扩张度减小。", "稳定型缺血性心脏疾病@肥胖与缺乏活动也导致高血压增多。"]} - - -def main(): - args = parse_args() - - for arg_name, arg_value in vars(args).items(): - logger.info("{:20}: {}".format(arg_name, arg_value)) - - dataset = args.dataset.lower() - label_list = LABEL_LIST[dataset] - if args.data_file is not None: - with open(args.data_file, "r") as fp: - input_data = [x.strip() for x in fp.readlines()] - else: - input_data = TEXT[dataset] - - predictor = SPOPredictor(args, label_list) - predictor.predict(input_data) - - -if __name__ == "__main__": - main() diff --git a/model_zoo/ernie-health/cblue/deploy/predictor/predictor.py b/model_zoo/ernie-health/cblue/deploy/predictor/predictor.py deleted file mode 100644 index 6e3137301cfd..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/predictor/predictor.py +++ /dev/null @@ -1,361 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import os -import time - -import numpy as np -import onnxruntime as ort -import paddle2onnx -import six - -from paddlenlp.transformers import ( - AutoTokenizer, - normalize_chars, - tokenize_special_chars, -) -from paddlenlp.utils.log import logger - - -class InferBackend(object): - def __init__(self, model_path_prefix, device="cpu", device_id=0, use_fp16=False, num_threads=10): - - if not isinstance(device, six.string_types): - logger.error( - ">>> [InferBackend] The type of device must be string, but the type you set is: ", type(device) - ) - exit(0) - if device not in ["cpu", "gpu"]: - logger.error(">>> [InferBackend] The device must be cpu or gpu, but your device is set to:", type(device)) - exit(0) - - logger.info(">>> [InferBackend] Creating Engine ...") - - onnx_model = paddle2onnx.command.c_paddle_to_onnx( - model_file=model_path_prefix + ".pdmodel", - params_file=model_path_prefix + ".pdiparams", - opset_version=13, - enable_onnx_checker=True, - ) - infer_model_dir = model_path_prefix.rsplit("/", 1)[0] - float_onnx_file = os.path.join(infer_model_dir, "model.onnx") - with open(float_onnx_file, "wb") as f: - f.write(onnx_model) - - if device == "gpu": - logger.info(">>> [InferBackend] Use GPU to inference ...") - providers = ["CUDAExecutionProvider"] - if use_fp16: - logger.info(">>> [InferBackend] Use FP16 to inference ...") - import onnx - from onnxconverter_common import float16 - - fp16_model_file = os.path.join(infer_model_dir, "fp16_model.onnx") - onnx_model = onnx.load_model(float_onnx_file) - trans_model = float16.convert_float_to_float16(onnx_model, keep_io_types=True) - onnx.save_model(trans_model, fp16_model_file) - onnx_model = fp16_model_file - else: - logger.info(">>> [InferBackend] Use CPU to inference ...") - providers = ["CPUExecutionProvider"] - if use_fp16: - logger.warning( - ">>> [InferBackend] Ignore use_fp16 as it only " + "takes effect when deploying on gpu..." - ) - - sess_options = ort.SessionOptions() - sess_options.intra_op_num_threads = num_threads - self.predictor = ort.InferenceSession( - onnx_model, sess_options=sess_options, providers=providers, provider_options=[{"device_id": device_id}] - ) - - self.input_handles = [ - self.predictor.get_inputs()[0].name, - self.predictor.get_inputs()[1].name, - ] - - if device == "gpu": - try: - assert "CUDAExecutionProvider" in self.predictor.get_providers() - except AssertionError: - raise AssertionError( - """The environment for GPU inference is not set properly. \nA possible cause is that you had installed both onnxruntime and onnxruntime-gpu. \nPlease run the following commands to reinstall: \n1) pip uninstall -y onnxruntime onnxruntime-gpu \n2) pip install onnxruntime-gpu""" - ) - logger.info(">>> [InferBackend] Engine Created ...") - - def infer(self, input_dict: dict): - input_dict = {k: v for k, v in input_dict.items() if k in self.input_handles} - result = self.predictor.run(None, input_dict) - return result - - -class EHealthPredictor(object): - def __init__(self, args, label_list): - self.label_list = label_list - self._tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, use_fast=True) - self._max_seq_length = args.max_seq_length - self._batch_size = args.batch_size - self.inference_backend = InferBackend( - args.model_path_prefix, args.device, args.device_id, args.use_fp16, args.num_threads - ) - - def predict(self, input_data: list): - encoded_inputs = self.preprocess(input_data) - infer_result = self.infer_batch(encoded_inputs) - result = self.postprocess(infer_result) - self.printer(result, input_data) - return result - - def _infer(self, input_dict): - infer_data = self.inference_backend.infer(input_dict) - return infer_data - - def infer_batch(self, encoded_inputs): - num_sample = len(encoded_inputs["input_ids"]) - infer_data = None - num_infer_data = None - for idx in range(0, num_sample, self._batch_size): - l, r = idx, idx + self._batch_size - keys = encoded_inputs.keys() - input_dict = {k: encoded_inputs[k][l:r] for k in keys} - results = self._infer(input_dict) - if infer_data is None: - infer_data = [[x] for x in results] - num_infer_data = len(results) - else: - for i in range(num_infer_data): - infer_data[i].append(results[i]) - for i in range(num_infer_data): - infer_data[i] = np.concatenate(infer_data[i], axis=0) - return infer_data - - def performance(self, encoded_inputs): - nums = len(encoded_inputs["input_ids"]) - start_time = time.time() - infer_result = self.infer_batch(preprocess_result) # noqa - total_time = time.time() - start_time - logger.info("sample nums: %d, time: %.2f, latency: %.2f ms" % (nums, total_time, 1000 * total_time / nums)) - - def get_text_and_label(self, dataset): - raise NotImplementedError - - def preprocess(self, input_data: list): - raise NotImplementedError - - def postprocess(self, infer_data): - raise NotImplementedError - - def printer(self, result, input_data): - raise NotImplementedError - - -class CLSPredictor(EHealthPredictor): - def preprocess(self, input_data: list): - norm_text = lambda x: tokenize_special_chars(normalize_chars(x)) - # To deal with a pair of input text. - if isinstance(input_data[0], list): - text = [norm_text(sample[0]) for sample in input_data] - text_pair = [norm_text(sample[1]) for sample in input_data] - else: - text = [norm_text(x) for x in input_data] - text_pair = None - - data = self._tokenizer( - text=text, text_pair=text_pair, max_length=self._max_seq_length, padding=True, truncation=True - ) - - encoded_inputs = { - "input_ids": np.array(data["input_ids"], dtype="int64"), - "token_type_ids": np.array(data["token_type_ids"], dtype="int64"), - } - return encoded_inputs - - def postprocess(self, infer_data): - infer_data = infer_data[0] - max_value = np.max(infer_data, axis=1, keepdims=True) - exp_data = np.exp(infer_data - max_value) - probs = exp_data / np.sum(exp_data, axis=1, keepdims=True) - label = probs.argmax(axis=-1) - confidence = probs.max(axis=-1) - return {"label": label, "confidence": confidence} - - def printer(self, result, input_data): - label, confidence = result["label"], result["confidence"] - for i in range(len(label)): - logger.info("input data: {}".format(input_data[i])) - logger.info("labels: {}, confidence: {}".format(self.label_list[label[i]], confidence[i])) - logger.info("-----------------------------") - - -class NERPredictor(EHealthPredictor): - """The predictor for CMeEE dataset.""" - - en_to_cn = { - "bod": "身体", - "mic": "微生物类", - "dis": "疾病", - "sym": "临床表现", - "pro": "医疗程序", - "equ": "医疗设备", - "dru": "药物", - "dep": "科室", - "ite": "医学检验项目", - } - - def _extract_chunk(self, tokens): - chunks = set() - start_idx, cur_idx = 0, 0 - while cur_idx < len(tokens): - if tokens[cur_idx][0] == "B": - start_idx = cur_idx - cur_idx += 1 - while cur_idx < len(tokens) and tokens[cur_idx][0] == "I": - if tokens[cur_idx][2:] == tokens[start_idx][2:]: - cur_idx += 1 - else: - break - if cur_idx < len(tokens) and tokens[cur_idx][0] == "E": - if tokens[cur_idx][2:] == tokens[start_idx][2:]: - chunks.add((tokens[cur_idx][2:], start_idx - 1, cur_idx)) - cur_idx += 1 - elif tokens[cur_idx][0] == "S": - chunks.add((tokens[cur_idx][2:], cur_idx - 1, cur_idx)) - cur_idx += 1 - else: - cur_idx += 1 - return list(chunks) - - def preprocess(self, infer_data): - infer_data = [[x.lower() for x in text] for text in infer_data] - data = self._tokenizer( - infer_data, max_length=self._max_seq_length, padding=True, is_split_into_words=True, truncation=True - ) - - encoded_inputs = { - "input_ids": np.array(data["input_ids"], dtype="int64"), - "token_type_ids": np.array(data["token_type_ids"], dtype="int64"), - } - return encoded_inputs - - def postprocess(self, infer_data): - tokens_oth = np.argmax(infer_data[0], axis=-1) - tokens_sym = np.argmax(infer_data[1], axis=-1) - entity = [] - for oth_ids, sym_ids in zip(tokens_oth, tokens_sym): - token_oth = [self.label_list[0][x] for x in oth_ids] - token_sym = [self.label_list[1][x] for x in sym_ids] - chunks = self._extract_chunk(token_oth) + self._extract_chunk(token_sym) - sub_entity = [] - for etype, sid, eid in chunks: - sub_entity.append({"type": self.en_to_cn[etype], "start_id": sid, "end_id": eid}) - entity.append(sub_entity) - return {"entity": entity} - - def printer(self, result, input_data): - result = result["entity"] - for i, preds in enumerate(result): - logger.info("input data: {}".format(input_data[i])) - logger.info("detected entities:") - for item in preds: - logger.info( - "* entity: {}, type: {}, position: ({}, {})".format( - input_data[i][item["start_id"] : item["end_id"]], - item["type"], - item["start_id"], - item["end_id"], - ) - ) - logger.info("-----------------------------") - - -class SPOPredictor(EHealthPredictor): - """The predictor for the CMeIE dataset.""" - - def predict(self, input_data: list): - encoded_inputs = self.preprocess(input_data) - lengths = encoded_inputs["attention_mask"].sum(axis=-1) - infer_result = self.infer_batch(encoded_inputs) - result = self.postprocess(infer_result, lengths) - self.printer(result, input_data) - return result - - def preprocess(self, infer_data): - infer_data = [[x.lower() for x in text] for text in infer_data] - data = self._tokenizer( - infer_data, - max_length=self._max_seq_length, - padding=True, - is_split_into_words=True, - truncation=True, - return_attention_mask=True, - ) - encoded_inputs = { - "input_ids": np.array(data["input_ids"], dtype="int64"), - "token_type_ids": np.array(data["token_type_ids"], dtype="int64"), - "attention_mask": np.array(data["attention_mask"], dtype="float32"), - } - return encoded_inputs - - def postprocess(self, infer_data, lengths): - ent_logits = np.array(infer_data[0]) - spo_logits = np.array(infer_data[1]) - ent_pred_list = [] - ent_idxs_list = [] - for idx, ent_pred in enumerate(ent_logits): - seq_len = lengths[idx] - 2 - start = np.where(ent_pred[:, 0] > 0.5)[0] - end = np.where(ent_pred[:, 1] > 0.5)[0] - ent_pred = [] - ent_idxs = {} - for x in start: - y = end[end >= x] - if (x == 0) or (x > seq_len): - continue - if len(y) > 0: - y = y[0] - if y > seq_len: - continue - ent_idxs[x] = (x - 1, y - 1) - ent_pred.append((x - 1, y - 1)) - ent_pred_list.append(ent_pred) - ent_idxs_list.append(ent_idxs) - - spo_preds = spo_logits > 0 - spo_pred_list = [[] for _ in range(len(spo_preds))] - idxs, preds, subs, objs = np.nonzero(spo_preds) - for idx, p_id, s_id, o_id in zip(idxs, preds, subs, objs): - obj = ent_idxs_list[idx].get(o_id, None) - if obj is None: - continue - sub = ent_idxs_list[idx].get(s_id, None) - if sub is None: - continue - spo_pred_list[idx].append((tuple(sub), p_id, tuple(obj))) - - return {"entity": ent_pred_list, "spo": spo_pred_list} - - def printer(self, result, input_data): - ent_pred_list, spo_pred_list = result["entity"], result["spo"] - for i, (ent, rel) in enumerate(zip(ent_pred_list, spo_pred_list)): - logger.info("input data: {}".format(input_data[i])) - logger.info("detected entities and relations:") - for sid, eid in ent: - logger.info("* entity: {}, position: ({}, {})".format(input_data[i][sid : eid + 1], sid, eid)) - for s, p, o in rel: - logger.info( - "+ spo: ({}, {}, {})".format( - input_data[i][s[0] : s[1] + 1], self.label_list[p], input_data[i][o[0] : o[1] + 1] - ) - ) - logger.info("-----------------------------") diff --git a/model_zoo/ernie-health/cblue/deploy/predictor/requirements_cpu.txt b/model_zoo/ernie-health/cblue/deploy/predictor/requirements_cpu.txt deleted file mode 100755 index 645682ec79c6..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/predictor/requirements_cpu.txt +++ /dev/null @@ -1,2 +0,0 @@ -onnxruntime==1.10.0 -psutil diff --git a/model_zoo/ernie-health/cblue/deploy/predictor/requirements_gpu.txt b/model_zoo/ernie-health/cblue/deploy/predictor/requirements_gpu.txt deleted file mode 100755 index 2ca8b172eb79..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/predictor/requirements_gpu.txt +++ /dev/null @@ -1,4 +0,0 @@ -onnxruntime-gpu==1.11.1 -onnx==1.12.0 -onnxconverter-common==1.9.0 -psutil diff --git a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/README.md b/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/README.md deleted file mode 100644 index 50166fe400b5..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/README.md +++ /dev/null @@ -1,60 +0,0 @@ -# 基于PaddleNLP SimpleServing 的服务化部署 - -## 目录 -- [环境准备](#环境准备) -- [Server启动服务](#Server服务启动) -- [其他参数设置](#其他参数设置) - -## 环境准备 -使用有SimpleServing功能的PaddleNLP版本 -```shell -pip install paddlenlp >= 2.3.6 -``` -## Server服务启动 -### 分类任务启动 -#### 启动 分类 Server 服务 -```bash -paddlenlp server server_classification:app --host 0.0.0.0 --port 8189 -``` - -#### 分类任务发送服务 -```bash -python client_classification.py --dataset chip-cdn-2c -``` - -### NER 任务启动 -#### 启动 NER Server 服务 -```bash -paddlenlp server server_ner:app --host 0.0.0.0 --port 8189 -``` - -#### NER Client发送服务 -```bash -python client_ner.py -``` - -### SPO 任务启动 -#### 启动 SPO Server 服务 -```bash -paddlenlp server server_spo:app --host 0.0.0.0 --port 8189 -``` - -#### SPO Client 发送服务 -```bash -python client_spo.py -``` - -## 其他参数设置 -可以在client端设置 `max_seq_len`, `batch_size` 参数 -```python - data = { - 'data': { - 'text': texts, - 'text_pair': text_pairs if len(text_pairs) > 0 else None - }, - 'parameters': { - 'max_seq_len': args.max_seq_len, - 'batch_size': args.batch_size - } - } -``` diff --git a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_classification.py b/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_classification.py deleted file mode 100644 index 1993acb4b0f0..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_classification.py +++ /dev/null @@ -1,54 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import json - -import requests - -parser = argparse.ArgumentParser() -parser.add_argument("--dataset", required=True, type=str, help="The dataset name for the simple seving") -parser.add_argument( - "--max_seq_len", default=128, type=int, help="The maximum total input sequence length after tokenization." -) -parser.add_argument("--batch_size", default=1, type=int, help="Batch size per GPU/CPU for predicting.") -args = parser.parse_args() - -url = "http://0.0.0.0:8189/models/cblue_cls" -headers = {"Content-Type": "application/json"} - -TEXT = { - "kuake-qic": ["心肌缺血如何治疗与调养呢?", "什么叫痔核脱出?什么叫外痔?"], - "kuake-qtr": [["儿童远视眼怎么恢复视力", "远视眼该如何保养才能恢复一些视力"], ["抗生素的药有哪些", "抗生素类的药物都有哪些?"]], - "kuake-qqr": [["茴香是发物吗", "茴香怎么吃?"], ["气的胃疼是怎么回事", "气到胃痛是什么原因"]], - "chip-ctc": ["(1)前牙结构发育不良:釉质发育不全、氟斑牙、四环素牙等;", "怀疑或确有酒精或药物滥用史;"], - "chip-sts": [["糖尿病能吃减肥药吗?能治愈吗?", "糖尿病为什么不能吃减肥药"], ["H型高血压的定义", "WHO对高血压的最新分类定义标准数值"]], - "chip-cdn-2c": [["1型糖尿病性植物神经病变", " 1型糖尿病肾病IV期"], ["髂腰肌囊性占位", "髂肌囊肿"]], -} - -if __name__ == "__main__": - args.dataset = args.dataset.lower() - input_data = TEXT[args.dataset] - texts = [] - text_pairs = [] - for data in input_data: - if len(data) == 2: - text_pairs.append(data[1]) - texts.append(data[0]) - data = { - "data": {"text": texts, "text_pair": text_pairs if len(text_pairs) > 0 else None}, - "parameters": {"max_seq_len": args.max_seq_len, "batch_size": args.batch_size}, - } - r = requests.post(url=url, headers=headers, data=json.dumps(data)) - print(r.text) diff --git a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_ner.py b/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_ner.py deleted file mode 100644 index d3c64479ec20..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_ner.py +++ /dev/null @@ -1,40 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import json - -import requests - -parser = argparse.ArgumentParser() -parser.add_argument( - "--max_seq_len", default=128, type=int, help="The maximum total input sequence length after tokenization." -) -parser.add_argument("--batch_size", default=2, type=int, help="Batch size per GPU/CPU for predicting.") -args = parser.parse_args() - -url = "http://0.0.0.0:8189/models/cblue_ner" -headers = {"Content-Type": "application/json"} - -if __name__ == "__main__": - texts = ["研究证实,细胞减少与肺内病变程度及肺内炎性病变吸收程度密切相关。", "可为不规则发热、稽留热或弛张热,但以不规则发热为多,可能与患儿应用退热药物导致热型不规律有关。"] - texts = [[x.lower() for x in text] for text in texts] - data = { - "data": { - "text": texts, - }, - "parameters": {"max_seq_len": args.max_seq_len, "batch_size": args.batch_size, "is_split_into_words": True}, - } - r = requests.post(url=url, headers=headers, data=json.dumps(data)) - print(r.text) diff --git a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_spo.py b/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_spo.py deleted file mode 100644 index 38c34459d054..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/client_spo.py +++ /dev/null @@ -1,45 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import json - -import requests - -parser = argparse.ArgumentParser() -parser.add_argument( - "--max_seq_len", default=128, type=int, help="The maximum total input sequence length after tokenization." -) -parser.add_argument("--batch_size", default=2, type=int, help="Batch size per GPU/CPU for predicting.") -args = parser.parse_args() - -url = "http://0.0.0.0:8189/models/cblue_spo" -headers = {"Content-Type": "application/json"} - -if __name__ == "__main__": - texts = ["骶髂关节炎是明确诊断JAS的关键条件。若有肋椎关节病变会使胸部扩张度减小。", "稳定型缺血性心脏疾病@肥胖与缺乏活动也导致高血压增多。"] - texts = [[x.lower() for x in text] for text in texts] - data = { - "data": { - "text": texts, - }, - "parameters": { - "max_seq_len": args.max_seq_len, - "batch_size": args.batch_size, - "return_attention_mask": True, - "is_split_into_words": True, - }, - } - r = requests.post(url=url, headers=headers, data=json.dumps(data)) - print(r.text) diff --git a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_classification.py b/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_classification.py deleted file mode 100644 index 1c024501dd15..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_classification.py +++ /dev/null @@ -1,25 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -from paddlenlp import SimpleServer -from paddlenlp.server import CustomModelHandler, MultiClassificationPostHandler - -app = SimpleServer() -app.register( - "models/cblue_cls", - model_path="../../../export", - tokenizer_name="ernie-health-chinese", - model_handler=CustomModelHandler, - post_handler=MultiClassificationPostHandler, -) diff --git a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_ner.py b/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_ner.py deleted file mode 100644 index 2b20efd1df81..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_ner.py +++ /dev/null @@ -1,129 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -import numpy as np - -from paddlenlp import SimpleServer -from paddlenlp.server import BasePostHandler, TokenClsModelHandler - -en_to_cn = { - "bod": "身体", - "mic": "微生物类", - "dis": "疾病", - "sym": "临床表现", - "pro": "医疗程序", - "equ": "医疗设备", - "dru": "药物", - "dep": "科室", - "ite": "医学检验项目", -} - -label_list = [ - [ - "B-bod", - "I-bod", - "E-bod", - "S-bod", - "B-dis", - "I-dis", - "E-dis", - "S-dis", - "B-pro", - "I-pro", - "E-pro", - "S-pro", - "B-dru", - "I-dru", - "E-dru", - "S-dru", - "B-ite", - "I-ite", - "E-ite", - "S-ite", - "B-mic", - "I-mic", - "E-mic", - "S-mic", - "B-equ", - "I-equ", - "E-equ", - "S-equ", - "B-dep", - "I-dep", - "E-dep", - "S-dep", - "O", - ], - ["B-sym", "I-sym", "E-sym", "S-sym", "O"], -] - - -def _extract_chunk(tokens): - chunks = set() - start_idx, cur_idx = 0, 0 - while cur_idx < len(tokens): - if tokens[cur_idx][0] == "B": - start_idx = cur_idx - cur_idx += 1 - while cur_idx < len(tokens) and tokens[cur_idx][0] == "I": - if tokens[cur_idx][2:] == tokens[start_idx][2:]: - cur_idx += 1 - else: - break - if cur_idx < len(tokens) and tokens[cur_idx][0] == "E": - if tokens[cur_idx][2:] == tokens[start_idx][2:]: - chunks.add((tokens[cur_idx][2:], start_idx - 1, cur_idx)) - cur_idx += 1 - elif tokens[cur_idx][0] == "S": - chunks.add((tokens[cur_idx][2:], cur_idx - 1, cur_idx)) - cur_idx += 1 - else: - cur_idx += 1 - return list(chunks) - - -class NERPostHandler(BasePostHandler): - def __init__(self): - super().__init__() - - @classmethod - def process(cls, data, parameters): - if "logits" not in data or "logits_1" not in data: - raise ValueError( - "The output of model handler do not include the 'logits', " - " please check the model handler output. The model handler output:\n{}".format(data) - ) - tokens_oth = np.array(data["logits"]) - tokens_sym = np.array(data["logits_1"]) - tokens_oth = np.argmax(tokens_oth, axis=-1) - tokens_sym = np.argmax(tokens_sym, axis=-1) - entity = [] - for oth_ids, sym_ids in zip(tokens_oth, tokens_sym): - token_oth = [label_list[0][x] for x in oth_ids] - token_sym = [label_list[1][x] for x in sym_ids] - chunks = _extract_chunk(token_oth) + _extract_chunk(token_sym) - sub_entity = [] - for etype, sid, eid in chunks: - sub_entity.append({"type": en_to_cn[etype], "start_id": sid, "end_id": eid}) - entity.append(sub_entity) - return {"entity": entity} - - -app = SimpleServer() -app.register( - "models/cblue_ner", - model_path="../../../export_ner", - tokenizer_name="ernie-health-chinese", - model_handler=TokenClsModelHandler, - post_handler=NERPostHandler, -) diff --git a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_spo.py b/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_spo.py deleted file mode 100644 index 1a64cdbe66aa..000000000000 --- a/model_zoo/ernie-health/cblue/deploy/serving/simple_serving/server_spo.py +++ /dev/null @@ -1,142 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -import numpy as np - -from paddlenlp import SimpleServer -from paddlenlp.server import BasePostHandler, TokenClsModelHandler - -label_list = [ - "预防", - "阶段", - "就诊科室", - "辅助治疗", - "化疗", - "放射治疗", - "手术治疗", - "实验室检查", - "影像学检查", - "辅助检查", - "组织学检查", - "内窥镜检查", - "筛查", - "多发群体", - "发病率", - "发病年龄", - "多发地区", - "发病性别倾向", - "死亡率", - "多发季节", - "传播途径", - "并发症", - "病理分型", - "相关(导致)", - "鉴别诊断", - "相关(转化)", - "相关(症状)", - "临床表现", - "治疗后症状", - "侵及周围组织转移的症状", - "病因", - "高危因素", - "风险评估因素", - "病史", - "遗传因素", - "发病机制", - "病理生理", - "药物治疗", - "发病部位", - "转移部位", - "外侵部位", - "预后状况", - "预后生存率", - "同义词", -] - - -class SPOPostHandler(BasePostHandler): - def __init__(self): - super().__init__() - - @classmethod - def process(cls, data, parameters): - if "logits" not in data or "logits_1" not in data: - raise ValueError( - "The output of model handler do not include the 'logits', " - " please check the model handler output. The model handler output:\n{}".format(data) - ) - lengths = np.array(data["attention_mask"], dtype="float32").sum(axis=-1) - ent_logits = np.array(data["logits"]) - spo_logits = np.array(data["logits_1"]) - ent_pred_list = [] - ent_idxs_list = [] - for idx, ent_pred in enumerate(ent_logits): - seq_len = lengths[idx] - 2 - start = np.where(ent_pred[:, 0] > 0.5)[0] - end = np.where(ent_pred[:, 1] > 0.5)[0] - ent_pred = [] - ent_idxs = {} - for x in start: - y = end[end >= x] - if (x == 0) or (x > seq_len): - continue - if len(y) > 0: - y = y[0] - if y > seq_len: - continue - ent_idxs[x] = (x - 1, y - 1) - ent_pred.append((x - 1, y - 1)) - ent_pred_list.append(ent_pred) - ent_idxs_list.append(ent_idxs) - - spo_preds = spo_logits > 0 - spo_pred_list = [[] for _ in range(len(spo_preds))] - idxs, preds, subs, objs = np.nonzero(spo_preds) - for idx, p_id, s_id, o_id in zip(idxs, preds, subs, objs): - obj = ent_idxs_list[idx].get(o_id, None) - if obj is None: - continue - sub = ent_idxs_list[idx].get(s_id, None) - if sub is None: - continue - spo_pred_list[idx].append((tuple(sub), p_id, tuple(obj))) - input_data = data["data"]["text"] - ent_list = [] - spo_list = [] - for i, (ent, rel) in enumerate(zip(ent_pred_list, spo_pred_list)): - cur_ent_list = [] - cur_spo_list = [] - for sid, eid in ent: - cur_ent_list.append("".join([str(d) for d in input_data[i][sid : eid + 1]])) - for s, p, o in rel: - cur_spo_list.append( - ( - "".join([str(d) for d in input_data[i][s[0] : s[1] + 1]]), - label_list[p], - "".join([str(d) for d in input_data[i][o[0] : o[1] + 1]]), - ) - ) - ent_list.append(cur_ent_list) - spo_list.append(cur_spo_list) - - return {"entity": ent_list, "spo": spo_list} - - -app = SimpleServer() -app.register( - "models/cblue_spo", - model_path="../../../export", - tokenizer_name="ernie-health-chinese", - model_handler=TokenClsModelHandler, - post_handler=SPOPostHandler, -) diff --git a/model_zoo/ernie-health/cblue/export_model.py b/model_zoo/ernie-health/cblue/export_model.py deleted file mode 100644 index ebc71e376aa4..000000000000 --- a/model_zoo/ernie-health/cblue/export_model.py +++ /dev/null @@ -1,88 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os - -import paddle -from model import ElectraForBinaryTokenClassification, ElectraForSPO - -from paddlenlp.transformers import ElectraForSequenceClassification - -NUM_CLASSES = { - "CHIP-CDN-2C": 2, - "CHIP-STS": 2, - "CHIP-CTC": 44, - "KUAKE-QQR": 3, - "KUAKE-QTR": 4, - "KUAKE-QIC": 11, - "CMeEE": [33, 5], - "CMeIE": 44, -} - - -def parse_args(): - parser = argparse.ArgumentParser() - parser.add_argument("--train_dataset", required=True, type=str, help="The name of dataset used for training.") - parser.add_argument( - "--params_path", - type=str, - required=True, - default="./checkpoint/", - help="The path to model parameters to be loaded.", - ) - parser.add_argument( - "--output_path", type=str, default="./export", help="The path of model parameter in static graph to be saved." - ) - args = parser.parse_args() - return args - - -def main(): - args = parse_args() - - # Load the model parameters. - if args.train_dataset not in NUM_CLASSES: - raise ValueError(f"Please modify the code to fit {args.dataset}") - - if args.train_dataset == "CMeEE": - model = ElectraForBinaryTokenClassification.from_pretrained( - args.params_path, - num_classes_oth=NUM_CLASSES[args.train_dataset][0], - num_classes_sym=NUM_CLASSES[args.train_dataset][1], - ) - elif args.train_dataset == "CMeIE": - model = ElectraForSPO.from_pretrained(args.params_path, num_labels=NUM_CLASSES[args.train_dataset]) - else: - model = ElectraForSequenceClassification.from_pretrained( - args.params_path, num_labels=NUM_CLASSES[args.train_dataset] - ) - - model.eval() - - # Convert to static graph with specific input description: - # input_ids, token_type_ids - input_spec = [ - paddle.static.InputSpec(shape=[None, None], dtype="int64"), - paddle.static.InputSpec(shape=[None, None], dtype="int64"), - ] - model = paddle.jit.to_static(model, input_spec=input_spec) - - # Save in static graph model. - save_path = os.path.join(args.output_path, "inference") - paddle.jit.save(model, save_path) - - -if __name__ == "__main__": - main() diff --git a/model_zoo/ernie-health/cblue/model.py b/model_zoo/ernie-health/cblue/model.py deleted file mode 100644 index 71c9d62e71ff..000000000000 --- a/model_zoo/ernie-health/cblue/model.py +++ /dev/null @@ -1,122 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import paddle -import paddle.nn as nn - -from paddlenlp.transformers import ElectraConfig, ElectraModel, ElectraPretrainedModel - - -class ElectraForBinaryTokenClassification(ElectraPretrainedModel): - """ - Electra Model with two linear layers on top of the hidden-states output layers, - designed for token classification tasks with nesting. - - Args: - electra (:class:`ElectraModel`): - An instance of ElectraModel. - num_classes (list): - The number of classes. - dropout (float, optionl): - The dropout probability for output of Electra. - If None, use the same value as `hidden_dropout_prob' of 'ElectraModel` - instance `electra`. Defaults to None. - """ - - def __init__(self, config: ElectraConfig, num_classes_oth, num_classes_sym): - super(ElectraForBinaryTokenClassification, self).__init__(config) - self.num_classes_oth = num_classes_oth - self.num_classes_sym = num_classes_sym - self.electra = ElectraModel(config) - self.dropout = nn.Dropout(config.hidden_dropout_prob) - self.classifier_oth = nn.Linear(config.hidden_size, self.num_classes_oth) - self.classifier_sym = nn.Linear(config.hidden_size, self.num_classes_sym) - - def forward(self, input_ids=None, token_type_ids=None, position_ids=None, attention_mask=None): - sequence_output = self.electra(input_ids, token_type_ids, position_ids, attention_mask) - sequence_output = self.dropout(sequence_output) - - logits_sym = self.classifier_sym(sequence_output) - logits_oth = self.classifier_oth(sequence_output) - - return logits_oth, logits_sym - - -class MultiHeadAttentionForSPO(nn.Layer): - """ - Multi-head attention layer for SPO task. - """ - - def __init__(self, embed_dim, num_heads, scale_value=768): - super(MultiHeadAttentionForSPO, self).__init__() - self.embed_dim = embed_dim - self.num_heads = num_heads - self.scale_value = scale_value**-0.5 - self.q_proj = nn.Linear(embed_dim, embed_dim * num_heads) - self.k_proj = nn.Linear(embed_dim, embed_dim * num_heads) - - def forward(self, query, key): - q = self.q_proj(query) - k = self.k_proj(key) - q = paddle.reshape(q, shape=[0, 0, self.num_heads, self.embed_dim]) - k = paddle.reshape(k, shape=[0, 0, self.num_heads, self.embed_dim]) - q = paddle.transpose(q, perm=[0, 2, 1, 3]) - k = paddle.transpose(k, perm=[0, 2, 1, 3]) - scores = paddle.matmul(q, k, transpose_y=True) - scores = paddle.scale(scores, scale=self.scale_value) - return scores - - -class ElectraForSPO(ElectraPretrainedModel): - """ - Electra Model with a linear layer on top of the hidden-states output - layers for entity recognition, and a multi-head attention layer for - relation classification. - - Args: - electra (:class:`ElectraModel`): - An instance of ElectraModel. - num_classes (int): - The number of classes. - dropout (float, optionl): - The dropout probability for output of Electra. - If None, use the same value as `hidden_dropout_prob' of 'ElectraModel` - instance `electra`. Defaults to None. - """ - - def __init__(self, config: ElectraConfig): - super(ElectraForSPO, self).__init__(config) - self.num_classes = config.num_labels - self.electra = ElectraModel(config) - self.dropout = nn.Dropout(config.hidden_dropout_prob) - self.classifier = nn.Linear(config.hidden_size, 2) - self.span_attention = MultiHeadAttentionForSPO(config.hidden_size, config.num_labels) - - def forward(self, input_ids=None, token_type_ids=None, position_ids=None, attention_mask=None): - outputs = self.electra( - input_ids, token_type_ids, position_ids, attention_mask, output_hidden_states=True, return_dict=True - ) - sequence_outputs = outputs.last_hidden_state - all_hidden_states = outputs.hidden_states - sequence_outputs = self.dropout(sequence_outputs) - ent_logits = self.classifier(sequence_outputs) - - subject_output = all_hidden_states[-2] - cls_output = paddle.unsqueeze(sequence_outputs[:, 0, :], axis=1) - subject_output = subject_output + cls_output - - output_size = self.num_classes + self.electra.config["hidden_size"] # noqa:F841 - rel_logits = self.span_attention(sequence_outputs, subject_output) - - return ent_logits, rel_logits diff --git a/model_zoo/ernie-health/cblue/train_classification.py b/model_zoo/ernie-health/cblue/train_classification.py deleted file mode 100644 index b7e59b2f80f0..000000000000 --- a/model_zoo/ernie-health/cblue/train_classification.py +++ /dev/null @@ -1,263 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import distutils.util -import os -import random -import time -from functools import partial - -import numpy as np -import paddle -import paddle.nn.functional as F -from paddle.metric import Accuracy -from utils import LinearDecayWithWarmup, convert_example, create_dataloader - -from paddlenlp.data import Pad, Stack, Tuple -from paddlenlp.datasets import load_dataset -from paddlenlp.metrics import AccuracyAndF1, MultiLabelsMetric -from paddlenlp.transformers import ElectraForSequenceClassification, ElectraTokenizer - -METRIC_CLASSES = { - "KUAKE-QIC": Accuracy, - "KUAKE-QQR": Accuracy, - "KUAKE-QTR": Accuracy, - "CHIP-CTC": MultiLabelsMetric, - "CHIP-STS": MultiLabelsMetric, - "CHIP-CDN-2C": AccuracyAndF1, -} - -parser = argparse.ArgumentParser() -parser.add_argument( - "--dataset", - choices=["KUAKE-QIC", "KUAKE-QQR", "KUAKE-QTR", "CHIP-STS", "CHIP-CTC", "CHIP-CDN-2C"], - default="KUAKE-QIC", - type=str, - help="Dataset for sequence classfication tasks.", -) -parser.add_argument("--seed", default=1000, type=int, help="Random seed for initialization.") -parser.add_argument( - "--device", - choices=["cpu", "gpu", "xpu", "npu"], - default="gpu", - help="Select which device to train model, default to gpu.", -) -parser.add_argument("--epochs", default=3, type=int, help="Total number of training epochs.") -parser.add_argument( - "--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override epochs." -) -parser.add_argument("--batch_size", default=32, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument( - "--learning_rate", default=6e-5, type=float, help="Learning rate for fine-tuning sequence classification task." -) -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay of optimizer if we apply some.") -parser.add_argument( - "--warmup_proportion", - default=0.1, - type=float, - help="Linear warmup proportion of learning rate over the training process.", -) -parser.add_argument( - "--max_seq_length", default=128, type=int, help="The maximum total input sequence length after tokenization." -) -parser.add_argument("--init_from_ckpt", default=None, type=str, help="The path of checkpoint to be loaded.") -parser.add_argument("--logging_steps", default=10, type=int, help="The interval steps to logging.") -parser.add_argument( - "--save_dir", - default="./checkpoint", - type=str, - help="The output directory where the model checkpoints will be written.", -) -parser.add_argument("--save_steps", default=100, type=int, help="The interval steps to save checkpoints.") -parser.add_argument("--valid_steps", default=100, type=int, help="The interval steps to evaluate model performance.") -parser.add_argument("--use_amp", default=False, type=distutils.util.strtobool, help="Enable mixed precision training.") -parser.add_argument("--scale_loss", default=128, type=float, help="The value of scale_loss for fp16.") - -args = parser.parse_args() - - -def set_seed(seed): - """set random seed""" - random.seed(seed) - np.random.seed(seed) - paddle.seed(seed) - - -@paddle.no_grad() -def evaluate(model, criterion, metric, data_loader): - """ - Given a dataset, it evals model and compute the metric. - - Args: - model(obj:`paddle.nn.Layer`): A model to classify texts. - dataloader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches. - criterion(obj:`paddle.nn.Layer`): It can compute the loss. - metric(obj:`paddle.metric.Metric`): The evaluation metric. - """ - model.eval() - metric.reset() - losses = [] - for batch in data_loader: - input_ids, token_type_ids, position_ids, labels = batch - logits = model(input_ids, token_type_ids, position_ids) - loss = criterion(logits, labels) - losses.append(loss.numpy()) - correct = metric.compute(logits, labels) - metric.update(correct) - if isinstance(metric, Accuracy): - metric_name = "accuracy" - result = metric.accumulate() - elif isinstance(metric, MultiLabelsMetric): - metric_name = "macro f1" - _, _, result = metric.accumulate("macro") - else: - metric_name = "micro f1" - _, _, _, result, _ = metric.accumulate() - - print("eval loss: %.5f, %s: %.5f" % (np.mean(losses), metric_name, result)) - model.train() - metric.reset() - - -def do_train(): - paddle.set_device(args.device) - rank = paddle.distributed.get_rank() - if paddle.distributed.get_world_size() > 1: - paddle.distributed.init_parallel_env() - - set_seed(args.seed) - - train_ds, dev_ds = load_dataset("cblue", args.dataset, splits=["train", "dev"]) - - model = ElectraForSequenceClassification.from_pretrained( - "ernie-health-chinese", num_labels=len(train_ds.label_list) - ) - tokenizer = ElectraTokenizer.from_pretrained("ernie-health-chinese") - - trans_func = partial(convert_example, tokenizer=tokenizer, max_seq_length=args.max_seq_length) - batchify_fn = lambda samples, fn=Tuple( # noqa: E731 - Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), # input - Pad(axis=0, pad_val=tokenizer.pad_token_type_id, dtype="int64"), # segment - Pad(axis=0, pad_val=args.max_seq_length - 1, dtype="int64"), # position - Stack(dtype="int64"), - ): [data for data in fn(samples)] - train_data_loader = create_dataloader( - train_ds, mode="train", batch_size=args.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func - ) - dev_data_loader = create_dataloader( - dev_ds, mode="dev", batch_size=args.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func - ) - - if args.init_from_ckpt and os.path.isfile(args.init_from_ckpt): - state_dict = paddle.load(args.init_from_ckpt) - state_keys = {x: x.replace("discriminator.", "") for x in state_dict.keys() if "discriminator." in x} - if len(state_keys) > 0: - state_dict = {state_keys[k]: state_dict[k] for k in state_keys.keys()} - model.set_dict(state_dict) - if paddle.distributed.get_world_size() > 1: - model = paddle.DataParallel(model) - - num_training_steps = args.max_steps if args.max_steps > 0 else len(train_data_loader) * args.epochs - args.epochs = (num_training_steps - 1) // len(train_data_loader) + 1 - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - - optimizer = paddle.optimizer.AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - ) - - criterion = paddle.nn.loss.CrossEntropyLoss() - if METRIC_CLASSES[args.dataset] is Accuracy: - metric = METRIC_CLASSES[args.dataset]() - metric_name = "accuracy" - elif METRIC_CLASSES[args.dataset] is MultiLabelsMetric: - metric = METRIC_CLASSES[args.dataset](num_labels=len(train_ds.label_list)) - metric_name = "macro f1" - else: - metric = METRIC_CLASSES[args.dataset]() - metric_name = "micro f1" - if args.use_amp: - scaler = paddle.amp.GradScaler(init_loss_scaling=args.scale_loss) - global_step = 0 - tic_train = time.time() - total_train_time = 0 - for epoch in range(1, args.epochs + 1): - for step, batch in enumerate(train_data_loader, start=1): - input_ids, token_type_ids, position_ids, labels = batch - with paddle.amp.auto_cast( - args.use_amp, - custom_white_list=["layer_norm", "softmax", "gelu", "tanh"], - ): - logits = model(input_ids, token_type_ids, position_ids) - loss = criterion(logits, labels) - probs = F.softmax(logits, axis=1) - correct = metric.compute(probs, labels) - metric.update(correct) - - if isinstance(metric, Accuracy): - result = metric.accumulate() - elif isinstance(metric, MultiLabelsMetric): - _, _, result = metric.accumulate("macro") - else: - _, _, _, result, _ = metric.accumulate() - - if args.use_amp: - scaler.scale(loss).backward() - scaler.minimize(optimizer, loss) - else: - loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - - global_step += 1 - if global_step % args.logging_steps == 0 and rank == 0: - time_diff = time.time() - tic_train - total_train_time += time_diff - print( - "global step %d, epoch: %d, batch: %d, loss: %.5f, %s: %.5f, speed: %.2f step/s" - % (global_step, epoch, step, loss, metric_name, result, args.logging_steps / time_diff) - ) - - if global_step % args.valid_steps == 0 and rank == 0: - evaluate(model, criterion, metric, dev_data_loader) - - if global_step % args.save_steps == 0 and rank == 0: - save_dir = os.path.join(args.save_dir, "model_%d" % global_step) - if not os.path.exists(save_dir): - os.makedirs(save_dir) - if paddle.distributed.get_world_size() > 1: - model._layers.save_pretrained(save_dir) - else: - model.save_pretrained(save_dir) - tokenizer.save_pretrained(save_dir) - - if global_step >= num_training_steps: - return - tic_train = time.time() - - if rank == 0 and total_train_time > 0: - print("Speed: %.2f steps/s" % (global_step / total_train_time)) - - -if __name__ == "__main__": - do_train() diff --git a/model_zoo/ernie-health/cblue/train_ner.py b/model_zoo/ernie-health/cblue/train_ner.py deleted file mode 100644 index de7e50b1f9dd..000000000000 --- a/model_zoo/ernie-health/cblue/train_ner.py +++ /dev/null @@ -1,254 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import os -import random -import time -from functools import partial - -import numpy as np -import paddle -from model import ElectraForBinaryTokenClassification -from utils import ( - LinearDecayWithWarmup, - NERChunkEvaluator, - convert_example_ner, - create_dataloader, -) - -from paddlenlp.data import Dict, Pad -from paddlenlp.datasets import load_dataset -from paddlenlp.transformers import ElectraTokenizer - -parser = argparse.ArgumentParser() -parser.add_argument( - "--device", - choices=["cpu", "gpu", "xpu", "npu"], - default="gpu", - help="Select which device to train model, default to gpu.", -) -parser.add_argument("--init_from_ckpt", default=None, type=str, help="The path of checkpoint to be loaded.") -parser.add_argument("--batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument( - "--learning_rate", default=6e-5, type=float, help="Learning rate for fine-tuning token classification task." -) -parser.add_argument( - "--max_seq_length", default=128, type=int, help="The maximum total input sequence length after tokenization." -) -parser.add_argument("--valid_steps", default=100, type=int, help="The interval steps to evaluate model performance.") -parser.add_argument("--logging_steps", default=10, type=int, help="The interval steps to logging.") -parser.add_argument("--save_steps", default=100, type=int, help="The interval steps to save checkpoints.") -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") -parser.add_argument( - "--warmup_proportion", default=0.1, type=float, help="Linear warmup proportion over the training process." -) -parser.add_argument("--use_amp", default=False, type=bool, help="Enable mixed precision training.") -parser.add_argument("--epochs", default=1, type=int, help="Total number of training epochs.") -parser.add_argument( - "--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override epochs." -) -parser.add_argument("--seed", default=1000, type=int, help="Random seed.") -parser.add_argument( - "--save_dir", - default="./checkpoint", - type=str, - help="The output directory where the model checkpoints will be written.", -) -parser.add_argument("--scale_loss", default=128, type=float, help="The value of scale_loss for fp16.") - -args = parser.parse_args() - - -def set_seed(seed): - """set random seed""" - random.seed(seed) - np.random.seed(seed) - paddle.seed(seed) - - -@paddle.no_grad() -def evaluate(model, criterion, metric, data_loader): - model.eval() - metric.reset() - losses = [] - for batch in data_loader: - input_ids, token_type_ids, position_ids, masks, label_oth, label_sym = batch - logits = model(input_ids, token_type_ids, position_ids) - - loss_mask = masks.unsqueeze(2) - loss = [(criterion(x, y.unsqueeze(2)) * loss_mask).mean() for x, y in zip(logits, [label_oth, label_sym])] - losses.append([x.numpy() for x in loss]) - - lengths = paddle.sum(masks, axis=1) - preds = [paddle.argmax(x, axis=2) for x in logits] - correct = metric.compute(lengths, preds, [label_oth, label_sym]) - metric.update(correct) - _, _, result = metric.accumulate() - loss = np.mean(losses, axis=0) - print("eval loss symptom: %.5f, loss others: %.5f, loss: %.5f, f1: %.5f" % (loss[1], loss[0], loss.sum(), result)) - model.train() - metric.reset() - - -def do_train(): - paddle.set_device(args.device) - rank = paddle.distributed.get_rank() - if paddle.distributed.get_world_size() > 1: - paddle.distributed.init_parallel_env() - - set_seed(args.seed) - - train_ds, dev_ds = load_dataset("cblue", "CMeEE", splits=["train", "dev"]) - - model = ElectraForBinaryTokenClassification.from_pretrained( - "ernie-health-chinese", - num_classes_oth=len(train_ds.label_list[0]), - num_classes_sym=len(train_ds.label_list[1]), - ) - tokenizer = ElectraTokenizer.from_pretrained("ernie-health-chinese") - - label_list = train_ds.label_list - pad_label_id = [len(label_list[0]) - 1, len(label_list[1]) - 1] - - trans_func = partial( - convert_example_ner, tokenizer=tokenizer, max_seq_length=args.max_seq_length, pad_label_id=pad_label_id - ) - - batchify_fn = lambda samples, fn=Dict( # noqa: E731 - { - "input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), - "token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id, dtype="int64"), - "position_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), - "attention_mask": Pad(axis=0, pad_val=0, dtype="float32"), - "label_oth": Pad(axis=0, pad_val=pad_label_id[0], dtype="int64"), - "label_sym": Pad(axis=0, pad_val=pad_label_id[1], dtype="int64"), - } - ): fn(samples) - - train_data_loader = create_dataloader( - train_ds, mode="train", batch_size=args.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func - ) - - dev_data_loader = create_dataloader( - dev_ds, mode="dev", batch_size=args.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func - ) - - if args.init_from_ckpt: - if not os.path.isfile(args.init_from_ckpt): - raise ValueError("init_from_ckpt is not a valid model filename.") - state_dict = paddle.load(args.init_from_ckpt) - state_keys = {x: x.replace("discriminator.", "") for x in state_dict.keys() if "discriminator." in x} - if len(state_keys) > 0: - state_dict = {state_keys[k]: state_dict[k] for k in state_keys.keys()} - model.set_dict(state_dict) - if paddle.distributed.get_world_size() > 1: - model = paddle.DataParallel(model) - - num_training_steps = args.max_steps if args.max_steps > 0 else len(train_data_loader) * args.epochs - args.epochs = (num_training_steps - 1) // len(train_data_loader) + 1 - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - - optimizer = paddle.optimizer.AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - ) - - criterion = paddle.nn.functional.softmax_with_cross_entropy - - metric = NERChunkEvaluator(label_list) - - if args.use_amp: - scaler = paddle.amp.GradScaler(init_loss_scaling=args.scale_loss) - - global_step = 0 - tic_train = time.time() - total_train_time = 0 - for epoch in range(1, args.epochs + 1): - for step, batch in enumerate(train_data_loader, start=1): - input_ids, token_type_ids, position_ids, masks, label_oth, label_sym = batch - with paddle.amp.auto_cast( - args.use_amp, - custom_white_list=["layer_norm", "softmax", "gelu"], - ): - logits = model(input_ids, token_type_ids, position_ids) - - loss_mask = paddle.unsqueeze(masks, 2) - losses = [ - (criterion(x, y.unsqueeze(2)) * loss_mask).mean() for x, y in zip(logits, [label_oth, label_sym]) - ] - loss = losses[0] + losses[1] - - lengths = paddle.sum(masks, axis=1) - preds = [paddle.argmax(x, axis=-1) for x in logits] - correct = metric.compute(lengths, preds, [label_oth, label_sym]) - metric.update(correct) - _, _, f1 = metric.accumulate() - - if args.use_amp: - scaler.scale(loss).backward() - scaler.minimize(optimizer, loss) - else: - loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - - global_step += 1 - if global_step % args.logging_steps == 0 and rank == 0: - time_diff = time.time() - tic_train - total_train_time += time_diff - print( - "global step %d, epoch: %d, batch: %d, loss: %.5f, loss symptom: %.5f, loss others: %.5f, f1: %.5f, speed: %.2f step/s, learning_rate: %f" - % ( - global_step, - epoch, - step, - loss, - losses[1], - losses[0], - f1, - args.logging_steps / time_diff, - lr_scheduler.get_lr(), - ) - ) - - if global_step % args.valid_steps == 0 and rank == 0: - evaluate(model, criterion, metric, dev_data_loader) - - if global_step % args.save_steps == 0 and rank == 0: - save_dir = os.path.join(args.save_dir, "model_%d" % global_step) - if not os.path.exists(save_dir): - os.makedirs(save_dir) - if paddle.distributed.get_world_size() > 1: - model._layers.save_pretrained(save_dir) - else: - model.save_pretrained(save_dir) - tokenizer.save_pretrained(save_dir) - - if global_step >= num_training_steps: - return - tic_train = time.time() - - if rank == 0 and total_train_time > 0: - print("Speed: %.2f steps/s" % (global_step / total_train_time)) - - -if __name__ == "__main__": - do_train() diff --git a/model_zoo/ernie-health/cblue/train_spo.py b/model_zoo/ernie-health/cblue/train_spo.py deleted file mode 100644 index e5d8d5eb6128..000000000000 --- a/model_zoo/ernie-health/cblue/train_spo.py +++ /dev/null @@ -1,300 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import distutils.util -import os -import random -import time -from functools import partial - -import numpy as np -import paddle -import paddle.nn.functional as F -from model import ElectraForSPO -from tqdm import tqdm -from utils import ( - LinearDecayWithWarmup, - SPOChunkEvaluator, - convert_example_spo, - create_dataloader, -) - -from paddlenlp.data import Dict, Pad -from paddlenlp.datasets import load_dataset -from paddlenlp.transformers import ElectraTokenizer - -parser = argparse.ArgumentParser() -parser.add_argument("--seed", default=1000, type=int, help="Random seed for initialization.") -parser.add_argument( - "--device", - choices=["cpu", "gpu", "xpu", "npu"], - default="gpu", - help="Select which device to train model, default to gpu.", -) -parser.add_argument("--epochs", default=100, type=int, help="Total number of training epochs.") -parser.add_argument( - "--max_steps", default=-1, type=int, help="If > 0: set total number of training steps to perform. Override epochs." -) -parser.add_argument("--batch_size", default=12, type=int, help="Batch size per GPU/CPU for training.") -parser.add_argument( - "--learning_rate", default=6e-5, type=float, help="Learning rate for fine-tuning sequence classification task." -) -parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay of optimizer if we apply some.") -parser.add_argument( - "--warmup_proportion", - default=0.1, - type=float, - help="Linear warmup proportion of learning rate over the training process.", -) -parser.add_argument( - "--max_seq_length", default=300, type=int, help="The maximum total input sequence length after tokenization." -) -parser.add_argument("--init_from_ckpt", default=None, type=str, help="The path of checkpoint to be loaded.") -parser.add_argument("--logging_steps", default=10, type=int, help="The interval steps to logging.") -parser.add_argument( - "--save_dir", - default="./checkpoint", - type=str, - help="The output directory where the model checkpoints will be written.", -) -parser.add_argument("--save_steps", default=100, type=int, help="The interval steps to save checkpoints.") -parser.add_argument("--valid_steps", default=100, type=int, help="The interval steps to evaluate model performance.") -parser.add_argument("--use_amp", default=False, type=distutils.util.strtobool, help="Enable mixed precision training.") -parser.add_argument("--scale_loss", default=128, type=float, help="The value of scale_loss for fp16.") - -args = parser.parse_args() - - -def set_seed(seed): - """set random seed""" - random.seed(seed) - np.random.seed(seed) - paddle.seed(seed) - - -@paddle.no_grad() -def evaluate(model, criterion, metric, data_loader): - """ - Given a dataset, it evals model and compute the metric. - Args: - model(obj:`paddle.nn.Layer`): A model to classify texts. - dataloader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches. - criterion(`paddle.nn.functional`): It can compute the loss. - metric(obj:`paddle.metric.Metric`): The evaluation metric. - """ - model.eval() - metric.reset() - losses = [] - for batch in tqdm(data_loader): - input_ids, token_type_ids, position_ids, masks, ent_label, spo_label = batch - ent_mask = paddle.unsqueeze(masks, axis=2) - spo_mask = paddle.matmul(ent_mask, ent_mask, transpose_y=True) - spo_mask = paddle.unsqueeze(spo_mask, axis=1) - - logits = model(input_ids, token_type_ids, position_ids) - - ent_loss = criterion(logits[0], ent_label[0], weight=ent_mask, reduction="sum") - spo_loss = criterion(logits[1], spo_label[0], weight=spo_mask, reduction="sum") - loss = ent_loss + spo_loss - losses.append(loss.numpy()) - lengths = paddle.sum(masks, axis=-1) - correct = metric.compute(lengths, logits[0], logits[1], ent_label[1], spo_label[1]) - metric.update(correct) - results = metric.accumulate() - print( - "eval loss: %.5f, entity f1: %.5f, spo f1: %.5f" % (np.mean(losses), results["entity"][2], results["spo"][2]) - ) - model.train() - metric.reset() - - -def do_train(): - paddle.set_device(args.device) - rank = paddle.distributed.get_rank() - if paddle.distributed.get_world_size() > 1: - paddle.distributed.init_parallel_env() - - set_seed(args.seed) - - train_ds, dev_ds = load_dataset("cblue", "CMeIE", splits=["train", "dev"]) - - model = ElectraForSPO.from_pretrained("ernie-health-chinese", num_classes=len(train_ds.label_list)) - tokenizer = ElectraTokenizer.from_pretrained("ernie-health-chinese") - - trans_func = partial( - convert_example_spo, - tokenizer=tokenizer, - num_classes=len(train_ds.label_list), - max_seq_length=args.max_seq_length, - ) - - def batchify_fn(data): - _batchify_fn = lambda samples, fn=Dict( # noqa: E731 - { - "input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), - "token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), - "position_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype="int64"), - "attention_mask": Pad(axis=0, pad_val=0, dtype="float32"), - } - ): fn(samples) - ent_label = [x["ent_label"] for x in data] - spo_label = [x["spo_label"] for x in data] - input_ids, token_type_ids, position_ids, masks = _batchify_fn(data) - batch_size, batch_len = input_ids.shape - num_classes = len(train_ds.label_list) - # Create one-hot labels. - # - # For example, - # - text: - # [CLS], 局, 部, 皮, 肤, 感, 染, 引, 起, 的, 皮, 疹, 等, [SEP] - # - # - ent_label (obj: `list`): - # [(0, 5), (9, 10)] # ['局部皮肤感染', '皮疹'] - # - # - one_hot_ent_label: # shape (sequence_length, 2) - # [[ 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], # start index - # [ 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0]] # end index - # - # - spo_label (obj: `list`): - # [(0, 23, 9)] # [('局部皮肤感染', '相关(导致)', '皮疹')], where entities - # are encoded by their start indexes. - # - # - one_hot_spo_label: # shape (num_predicate, sequence_length, sequence_length) - # [..., - # [..., [0, ..., 1, ..., 0], ...], # for predicate '相关(导致)' - # ...] # the value at [23, 1, 10] is set as 1 - # - one_hot_ent_label = np.zeros([batch_size, batch_len, 2], dtype=np.float32) - one_hot_spo_label = np.zeros([batch_size, num_classes, batch_len, batch_len], dtype=np.float32) - for idx, ent_idxs in enumerate(ent_label): - # Shift index by 1 because input_ids start with [CLS] here. - for x, y in ent_idxs: - x = x + 1 - y = y + 1 - if x > 0 and x < batch_len and y < batch_len: - one_hot_ent_label[idx, x, 0] = 1 - one_hot_ent_label[idx, y, 1] = 1 - for idx, spo_idxs in enumerate(spo_label): - for s, p, o in spo_idxs: - s_id = s[0] + 1 - o_id = o[0] + 1 - if s_id > 0 and s_id < batch_len and o_id < batch_len: - one_hot_spo_label[idx, p, s_id, o_id] = 1 - # one_hot_xxx_label are used for loss computation. - # xxx_label are used for metric computation. - ent_label = [one_hot_ent_label, ent_label] - spo_label = [one_hot_spo_label, spo_label] - return input_ids, token_type_ids, position_ids, masks, ent_label, spo_label - - train_data_loader = create_dataloader( - train_ds, mode="train", batch_size=args.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func - ) - - dev_data_loader = create_dataloader( - dev_ds, mode="dev", batch_size=args.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func - ) - - if args.init_from_ckpt: - if not os.path.isfile(args.init_from_ckpt): - raise ValueError("init_from_ckpt is not a valid model filename.") - state_dict = paddle.load(args.init_from_ckpt) - state_keys = {x: x.replace("discriminator.", "") for x in state_dict.keys() if "discriminator." in x} - if len(state_keys) > 0: - state_dict = {state_keys[k]: state_dict[k] for k in state_keys.keys()} - model.set_dict(state_dict) - if paddle.distributed.get_world_size() > 1: - model = paddle.DataParallel(model) - - num_training_steps = args.max_steps if args.max_steps > 0 else len(train_data_loader) * args.epochs - args.epochs = (num_training_steps - 1) // len(train_data_loader) + 1 - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_proportion) - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - - optimizer = paddle.optimizer.AdamW( - learning_rate=lr_scheduler, - parameters=model.parameters(), - weight_decay=args.weight_decay, - apply_decay_param_fun=lambda x: x in decay_params, - ) - - criterion = F.binary_cross_entropy_with_logits - - metric = SPOChunkEvaluator(num_classes=len(train_ds.label_list)) - - if args.use_amp: - scaler = paddle.amp.GradScaler(init_loss_scaling=args.scale_loss) - global_step = 0 - tic_train = time.time() - total_train_time = 0 - for epoch in range(1, args.epochs + 1): - for step, batch in enumerate(train_data_loader, start=1): - input_ids, token_type_ids, position_ids, masks, ent_label, spo_label = batch - ent_mask = paddle.unsqueeze(masks, axis=2) - spo_mask = paddle.matmul(ent_mask, ent_mask, transpose_y=True) - spo_mask = paddle.unsqueeze(spo_mask, axis=1) - - with paddle.amp.auto_cast( - args.use_amp, - custom_white_list=["layer_norm", "softmax", "gelu"], - ): - logits = model(input_ids, token_type_ids, position_ids) - ent_loss = criterion(logits[0], ent_label[0], weight=ent_mask, reduction="sum") - spo_loss = criterion(logits[1], spo_label[0], weight=spo_mask, reduction="sum") - - loss = ent_loss + spo_loss - - if args.use_amp: - scaler.scale(loss).backward() - scaler.minimize(optimizer, loss) - else: - loss.backward() - optimizer.step() - lr_scheduler.step() - optimizer.clear_grad() - - global_step += 1 - if global_step % args.logging_steps == 0 and rank == 0: - time_diff = time.time() - tic_train - total_train_time += time_diff - print( - "global step %d, epoch: %d, batch: %d, loss: %.5f, " - "ent_loss: %.5f, spo_loss: %.5f, speed: %.2f steps/s" - % (global_step, epoch, step, loss, ent_loss, spo_loss, args.logging_steps / time_diff) - ) - - if global_step % args.valid_steps == 0 and rank == 0: - evaluate(model, criterion, metric, dev_data_loader) - - if global_step % args.save_steps == 0 and rank == 0: - save_dir = os.path.join(args.save_dir, "model_%d" % global_step) - if not os.path.exists(save_dir): - os.makedirs(save_dir) - if paddle.distributed.get_world_size() > 1: - model._layers.save_pretrained(save_dir) - else: - model.save_pretrained(save_dir) - tokenizer.save_pretrained(save_dir) - - if global_step >= num_training_steps: - return - tic_train = time.time() - - if rank == 0 and total_train_time > 0: - print("Speed: %.2f steps/s" % (global_step / total_train_time)) - - -if __name__ == "__main__": - do_train() diff --git a/model_zoo/ernie-health/cblue/utils.py b/model_zoo/ernie-health/cblue/utils.py deleted file mode 100644 index 4c0bda0c63eb..000000000000 --- a/model_zoo/ernie-health/cblue/utils.py +++ /dev/null @@ -1,503 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import math - -import numpy as np -import paddle -from paddle.optimizer.lr import LambdaDecay - -from paddlenlp.transformers import normalize_chars, tokenize_special_chars - - -def create_dataloader(dataset, mode="train", batch_size=1, batchify_fn=None, trans_fn=None): - if trans_fn: - dataset = dataset.map(trans_fn) - - shuffle = True if mode == "train" else False - if mode == "train": - batch_sampler = paddle.io.DistributedBatchSampler(dataset, batch_size=batch_size, shuffle=shuffle) - else: - batch_sampler = paddle.io.BatchSampler(dataset, batch_size=batch_size, shuffle=shuffle) - - return paddle.io.DataLoader(dataset=dataset, batch_sampler=batch_sampler, collate_fn=batchify_fn, return_list=True) - - -class LinearDecayWithWarmup(LambdaDecay): - def __init__(self, learning_rate, total_steps, warmup, last_epoch=-1, verbose=False): - """ - Creates a learning rate scheduler, which increases learning rate linearly - from 0 to given `learning_rate`, after this warmup period learning rate - would be decreased linearly from the base learning rate to 0. - - Args: - learning_rate (float): - The base learning rate. It is a python float number. - total_steps (int): - The number of training steps. - warmup (int or float): - If int, it means the number of steps for warmup. If float, it means - the proportion of warmup in total training steps. - last_epoch (int, optional): - The index of last epoch. It can be set to restart training. If - None, it means initial learning rate. - Defaults to -1. - verbose (bool, optional): - If True, prints a message to stdout for each update. - Defaults to False. - """ - - warmup_steps = warmup if isinstance(warmup, int) else int(math.floor(warmup * total_steps)) - - def lr_lambda(current_step): - if current_step < warmup_steps: - return float(current_step) / float(max(1, warmup_steps)) - return max(0.0, 1.0 - current_step / total_steps) - - super(LinearDecayWithWarmup, self).__init__(learning_rate, lr_lambda, last_epoch, verbose) - - -def convert_example(example, tokenizer, max_seq_length=512, is_test=False): - """ - Builds model inputs from a sequence or a pair of sequences for sequence - classification tasks by concatenating and adding special tokens. And - creates a mask from the two sequences for sequence-pair classification - tasks. - - The convention in Electra/EHealth is: - - - single sequence: - input_ids: ``[CLS] X [SEP]`` - token_type_ids: `` 0 0 0`` - position_ids: `` 0 1 2`` - - - a senquence pair: - input_ids: ``[CLS] X [SEP] Y [SEP]`` - token_type_ids: `` 0 0 0 1 1`` - position_ids: `` 0 1 2 3 4`` - - Args: - example (obj:`dict`): - A dictionary of input data, containing text and label if it has. - tokenizer (obj:`PretrainedTokenizer`): - A tokenizer inherits from :class:`paddlenlp.transformers.PretrainedTokenizer`. - Users can refer to the superclass for more information. - max_seq_length (obj:`int`): - The maximum total input sequence length after tokenization. - Sequences longer will be truncated, and the shorter will be padded. - is_test (obj:`bool`, default to `False`): - Whether the example contains label or not. - - Returns: - input_ids (obj:`list[int]`): - The list of token ids. - token_type_ids (obj:`list[int]`): - List of sequence pair mask. - position_ids (obj:`list[int]`): - List of position ids. - label(obj:`numpy.array`, data type of int64, optional): - The input label if not is_test. - """ - text_a = example["text_a"] - text_b = example.get("text_b", None) - - text_a = tokenize_special_chars(normalize_chars(text_a)) - if text_b is not None: - text_b = tokenize_special_chars(normalize_chars(text_b)) - - encoded_inputs = tokenizer(text=text_a, text_pair=text_b, max_seq_len=max_seq_length, return_position_ids=True) - input_ids = encoded_inputs["input_ids"] - token_type_ids = encoded_inputs["token_type_ids"] - position_ids = encoded_inputs["position_ids"] - - if is_test: - return input_ids, token_type_ids, position_ids - label = np.array([example["label"]], dtype="int64") - return input_ids, token_type_ids, position_ids, label - - -def convert_example_ner(example, tokenizer, max_seq_length=512, pad_label_id=-100, is_test=False): - """ - Builds model inputs from a sequence and creates labels for named- - entity recognition task CMeEE. - - For example, a sample should be: - - - input_ids: ``[CLS] x1 x2 [SEP] [PAD]`` - - token_type_ids: `` 0 0 0 0 0`` - - position_ids: `` 0 1 2 3 0`` - - attention_mask: `` 1 1 1 1 0`` - - label_oth: `` 32 3 32 32 32`` (optional, label ids of others) - - label_sym: `` 4 4 4 4 4`` (optional, label ids of symptom) - - Args: - example (obj:`dict`): - A dictionary of input data, containing text and label if it has. - tokenizer (obj:`PretrainedTokenizer`): - A tokenizer inherits from :class:`paddlenlp.transformers.PretrainedTokenizer`. - Users can refer to the superclass for more information. - max_seq_length (obj:`int`): - The maximum total input sequence length after tokenization. - Sequences longer will be truncated, and the shorter will be padded. - is_test (obj:`bool`, default to `False`): - Whether the example contains label or not. - - Returns: - encoded_output (obj: `dict[str, list|np.array]`): - The sample dictionary including `input_ids`, `token_type_ids`, - `position_ids`, `attention_mask`, `label_oth` (optional), - `label_sym` (optional) - """ - - encoded_inputs = {} - text = example["text"] - if len(text) > max_seq_length - 2: - text = text[: max_seq_length - 2] - text = ["[CLS]"] + [x.lower() for x in text] + ["[SEP]"] - input_len = len(text) - encoded_inputs["input_ids"] = tokenizer.convert_tokens_to_ids(text) - encoded_inputs["token_type_ids"] = np.zeros(input_len) - encoded_inputs["position_ids"] = list(range(input_len)) - encoded_inputs["attention_mask"] = np.ones(input_len) - - if not is_test: - labels = example["labels"] - if input_len - 2 < len(labels[0]): - labels[0] = labels[0][: input_len - 2] - if input_len - 2 < len(labels[1]): - labels[1] = labels[1][: input_len - 2] - encoded_inputs["label_oth"] = [pad_label_id[0]] + labels[0] + [pad_label_id[0]] - encoded_inputs["label_sym"] = [pad_label_id[1]] + labels[1] + [pad_label_id[1]] - - return encoded_inputs - - -def convert_example_spo(example, tokenizer, num_classes, max_seq_length=512, is_test=False): - """ - Builds model inputs from a sequence and creates labels for SPO prediction - task CMeIE. - - For example, a sample should be: - - - input_ids: ``[CLS] x1 x2 [SEP] [PAD]`` - - token_type_ids: `` 0 0 0 0 0`` - - position_ids: `` 0 1 2 3 0`` - - attention_mask: `` 1 1 1 1 0`` - - ent_label: ``[[0 1 0 0 0], # start ids are set as 1 - [0 0 1 0 0]] # end ids are set as 1 - - spo_label: a tensor of shape [num_classes, max_batch_len, max_batch_len]. - Set [predicate_id, subject_start_id, object_start_id] as 1 - when (subject, predicate, object) exists. - - Args: - example (obj:`dict`): - A dictionary of input data, containing text and label if it has. - tokenizer (obj:`PretrainedTokenizer`): - A tokenizer inherits from :class:`paddlenlp.transformers.PretrainedTokenizer`. - Users can refer to the superclass for more information. - num_classes (obj:`int`): - The number of predicates. - max_seq_length (obj:`int`): - The maximum total input sequence length after tokenization. - Sequences longer will be truncated, and the shorter will be padded. - is_test (obj:`bool`, default to `False`): - Whether the example contains label or not. - - Returns: - encoded_output (obj: `dict[str, list|np.array]`): - The sample dictionary including `input_ids`, `token_type_ids`, - `position_ids`, `attention_mask`, `ent_label` (optional), - `spo_label` (optional) - """ - encoded_inputs = {} - text = example["text"] - if len(text) > max_seq_length - 2: - text = text[: max_seq_length - 2] - text = ["[CLS]"] + [x.lower() for x in text] + ["[SEP]"] - input_len = len(text) - encoded_inputs["input_ids"] = tokenizer.convert_tokens_to_ids(text) - encoded_inputs["token_type_ids"] = np.zeros(input_len) - encoded_inputs["position_ids"] = list(range(input_len)) - encoded_inputs["attention_mask"] = np.ones(input_len) - if not is_test: - encoded_inputs["ent_label"] = example["ent_label"] - encoded_inputs["spo_label"] = example["spo_label"] - return encoded_inputs - - -class NERChunkEvaluator(paddle.metric.Metric): - """ - NERChunkEvaluator computes the precision, recall and F1-score for chunk detection. - It is often used in sequence tagging tasks, such as Named Entity Recognition (NER). - - Args: - label_list (list): - The label list. - - Note: - Difference from `paddlenlp.metric.ChunkEvaluator`: - - - `paddlenlp.metric.ChunkEvaluator` - All sequences with non-'O' labels are taken as chunks when computing num_infer. - - `NERChunkEvaluator` - Only complete sequences are taken as chunks, namely `B- I- E-` or `S-`. - """ - - def __init__(self, label_list): - super(NERChunkEvaluator, self).__init__() - self.id2label = [dict(enumerate(x)) for x in label_list] - self.num_classes = [len(x) for x in label_list] - self.num_infer = 0 - self.num_label = 0 - self.num_correct = 0 - - def compute(self, lengths, predictions, labels): - """ - Computes the prediction, recall and F1-score for chunk detection. - - Args: - lengths (Tensor): - The valid length of every sequence, a tensor with shape `[batch_size]`. - predictions (Tensor): - The predictions index, a tensor with shape `[batch_size, sequence_length]`. - labels (Tensor): - The labels index, a tensor with shape `[batch_size, sequence_length]`. - - Returns: - tuple: Returns tuple (`num_infer_chunks, num_label_chunks, num_correct_chunks`). - - With the fields: - - - `num_infer_chunks` (Tensor): The number of the inference chunks. - - `num_label_chunks` (Tensor): The number of the label chunks. - - `num_correct_chunks` (Tensor): The number of the correct chunks. - """ - assert len(predictions) == len(labels) - assert len(predictions) == len(self.id2label) - preds = [x.numpy() for x in predictions] - labels = [x.numpy() for x in labels] - - preds_chunk = set() - label_chunk = set() - for idx, (pred, label) in enumerate(zip(preds, labels)): - for i, case in enumerate(pred): - case = [self.id2label[idx][x] for x in case[: lengths[i]]] - preds_chunk |= self.extract_chunk(case, i) - for i, case in enumerate(label): - case = [self.id2label[idx][x] for x in case[: lengths[i]]] - label_chunk |= self.extract_chunk(case, i) - - num_infer = len(preds_chunk) - num_label = len(label_chunk) - num_correct = len(preds_chunk & label_chunk) - return num_infer, num_label, num_correct - - def update(self, correct): - num_infer, num_label, num_correct = correct - self.num_infer += num_infer - self.num_label += num_label - self.num_correct += num_correct - - def accumulate(self): - precision = self.num_correct / (self.num_infer + 1e-6) - recall = self.num_correct / (self.num_label + 1e-6) - f1 = 2 * precision * recall / (precision + recall + 1e-6) - return precision, recall, f1 - - def reset(self): - self.num_infer = 0 - self.num_label = 0 - self.num_correct = 0 - - def name(self): - return "precision", "recall", "f1" - - def extract_chunk(self, sequence, cid=0): - chunks = set() - - start_idx, cur_idx = 0, 0 - while cur_idx < len(sequence): - if sequence[cur_idx][0] == "B": - start_idx = cur_idx - cur_idx += 1 - while cur_idx < len(sequence) and sequence[cur_idx][0] == "I": - if sequence[cur_idx][2:] == sequence[start_idx][2:]: - cur_idx += 1 - else: - break - if cur_idx < len(sequence) and sequence[cur_idx][0] == "E": - if sequence[cur_idx][2:] == sequence[start_idx][2:]: - chunks.add((cid, sequence[cur_idx][2:], start_idx, cur_idx)) - cur_idx += 1 - elif sequence[cur_idx][0] == "S": - chunks.add((cid, sequence[cur_idx][2:], cur_idx, cur_idx)) - cur_idx += 1 - else: - cur_idx += 1 - - return chunks - - -class SPOChunkEvaluator(paddle.metric.Metric): - """ - SPOChunkEvaluator computes the precision, recall and F1-score for multiple - chunk detections, including Named Entity Recognition (NER) and SPO Prediction. - - Args: - num_classes (int): - The number of predicates. - """ - - def __init__(self, num_classes=None): - super(SPOChunkEvaluator, self).__init__() - self.num_classes = num_classes - self.num_infer_ent = 0 - self.num_infer_spo = 1e-10 - self.num_label_ent = 0 - self.num_label_spo = 1e-10 - self.num_correct_ent = 0 - self.num_correct_spo = 0 - - def compute(self, lengths, ent_preds, spo_preds, ent_labels, spo_labels): - """ - Computes the prediction, recall and F1-score for NER and SPO prediction. - - Args: - lengths (Tensor): - The valid length of every sequence, a tensor with shape `[batch_size]`. - ent_preds (Tensor): - The predictions of entities. - A tensor with shape `[batch_size, sequence_length, 2]`. - `ent_preds[:, :, 0]` denotes the start indexes of entities. - `ent_preds[:, :, 1]` denotes the end indexes of entities. - spo_preds (Tensor): - The predictions of predicates between all possible entities. - A tensor with shape `[batch_size, num_classes, sequence_length, sequence_length]`. - ent_labels (list[list|tuple]): - The entity labels' indexes. A list of pair `[start_index, end_index]`. - spo_labels (list[list|tuple]): - The SPO labels' indexes. A list of triple `[[subject_start_index, subject_end_index], - predicate_id, [object_start_index, object_end_index]]`. - - Returns: - tuple: - Returns tuple (`num_infer_chunks, num_label_chunks, num_correct_chunks`). - The `ent` denotes results of NER and the `spo` denotes results of SPO prediction. - - With the fields: - - - `num_infer_chunks` (dict): The number of the inference chunks. - - `num_label_chunks` (dict): The number of the label chunks. - - `num_correct_chunks` (dict): The number of the correct chunks. - """ - ent_preds = ent_preds.numpy() - spo_preds = spo_preds.numpy() - - ent_pred_list = [] - ent_idxs_list = [] - for idx, ent_pred in enumerate(ent_preds): - seq_len = lengths[idx] - 2 - start = np.where(ent_pred[:, 0] > 0.5)[0] - end = np.where(ent_pred[:, 1] > 0.5)[0] - ent_pred = [] - ent_idxs = {} - for x in start: - y = end[end >= x] - if (x == 0) or (x > seq_len): - continue - if len(y) > 0: - y = y[0] - if y > seq_len: - continue - ent_idxs[x] = (x - 1, y - 1) - ent_pred.append((x - 1, y - 1)) - ent_pred_list.append(ent_pred) - ent_idxs_list.append(ent_idxs) - - spo_preds = spo_preds > 0 - spo_pred_list = [[] for _ in range(len(spo_preds))] - idxs, preds, subs, objs = np.nonzero(spo_preds) - for idx, p_id, s_id, o_id in zip(idxs, preds, subs, objs): - obj = ent_idxs_list[idx].get(o_id, None) - if obj is None: - continue - sub = ent_idxs_list[idx].get(s_id, None) - if sub is None: - continue - spo_pred_list[idx].append((sub, p_id, obj)) - - correct = {"ent": 0, "spo": 0} - infer = {"ent": 0, "spo": 0} - label = {"ent": 0, "spo": 0} - for ent_pred, ent_true in zip(ent_pred_list, ent_labels): - ent_true = [tuple(x) for x in ent_true] - infer["ent"] += len(set(ent_pred)) - label["ent"] += len(set(ent_true)) - correct["ent"] += len(set(ent_pred) & set(ent_true)) - - for spo_pred, spo_true in zip(spo_pred_list, spo_labels): - spo_true = [(tuple(s), p, tuple(o)) for s, p, o in spo_true] - infer["spo"] += len(set(spo_pred)) - label["spo"] += len(set(spo_true)) - correct["spo"] += len(set(spo_pred) & set(spo_true)) - - return infer, label, correct - - def update(self, corrects): - assert len(corrects) == 3 - for item in corrects: - assert isinstance(item, dict) - for value in item.values(): - if not self._is_number_or_matrix(value): - raise ValueError("The numbers must be a number(int) or a numpy ndarray.") - num_infer, num_label, num_correct = corrects - self.num_infer_ent += num_infer["ent"] - self.num_infer_spo += num_infer["spo"] - self.num_label_ent += num_label["ent"] - self.num_label_spo += num_label["spo"] - self.num_correct_ent += num_correct["ent"] - self.num_correct_spo += num_correct["spo"] - - def accumulate(self): - spo_precision = self.num_correct_spo / self.num_infer_spo - spo_recall = self.num_correct_spo / self.num_label_spo - spo_f1 = 2 * self.num_correct_spo / (self.num_infer_spo + self.num_label_spo) - ent_precision = self.num_correct_ent / self.num_infer_ent if self.num_infer_ent > 0 else 0.0 - ent_recall = self.num_correct_ent / self.num_label_ent if self.num_label_ent > 0 else 0.0 - ent_f1 = ( - 2 * ent_precision * ent_recall / (ent_precision + ent_recall) if (ent_precision + ent_recall) != 0 else 0.0 - ) - return {"entity": (ent_precision, ent_recall, ent_f1), "spo": (spo_precision, spo_recall, spo_f1)} - - def _is_number_or_matrix(self, var): - def _is_number_(var): - return ( - isinstance(var, int) - or isinstance(var, np.int64) - or isinstance(var, float) - or (isinstance(var, np.ndarray) and var.shape == (1,)) - ) - - return _is_number_(var) or isinstance(var, np.ndarray) - - def reset(self): - self.num_infer_ent = 0 - self.num_infer_spo = 1e-10 - self.num_label_ent = 0 - self.num_label_spo = 1e-10 - self.num_correct_ent = 0 - self.num_correct_spo = 0 - - def name(self): - return {"entity": ("precision", "recall", "f1"), "spo": ("precision", "recall", "f1")} diff --git a/model_zoo/ernie-health/dataset.py b/model_zoo/ernie-health/dataset.py deleted file mode 100644 index 252b2e952aee..000000000000 --- a/model_zoo/ernie-health/dataset.py +++ /dev/null @@ -1,204 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import os - -import numpy as np -import paddle - - -class MedicalCorpus(paddle.io.Dataset): - def __init__(self, data_path, tokenizer): - self.data_path = data_path - self.tokenizer = tokenizer - # Add ids for suffixal chinese tokens in tokenized text, e.g. '##度' in '百度'. - # It should coincide with the vocab dictionary in preprocess.py. - orig_len = len(self.tokenizer) # noqa:F841 - suffix_vocab = {} - for idx, token in enumerate(range(0x4E00, 0x9FA6)): - suffix_vocab[len(self.tokenizer) + idx] = "##" + chr(token) - self.tokenizer.added_tokens_decoder.update(suffix_vocab) - self._samples, self._global_index = self._read_data_files(data_path) - - def _get_data_files(self, data_path): - # Get all prefix of .npy/.npz files in the current and next-level directories. - files = [ - os.path.join(data_path, f) - for f in os.listdir(data_path) - if (os.path.isfile(os.path.join(data_path, f)) and "_idx.npz" in str(f)) - ] - files = [x.replace("_idx.npz", "") for x in files] - return files - - def _read_data_files(self, data_path): - data_files = self._get_data_files(data_path) - samples = [] - indexes = [] - for file_id, file_name in enumerate(data_files): - - for suffix in ["_ids.npy", "_idx.npz"]: - if not os.path.isfile(file_name + suffix): - raise ValueError("File Not found, %s" % (file_name + suffix)) - - token_ids = np.load(file_name + "_ids.npy", mmap_mode="r", allow_pickle=True) - samples.append(token_ids) - - split_ids = np.load(file_name + "_idx.npz") - end_ids = np.cumsum(split_ids["lens"], dtype=np.int64) - file_ids = np.full(end_ids.shape, file_id) - split_ids = np.stack([file_ids, end_ids], axis=-1) - indexes.extend(split_ids) - indexes = np.stack(indexes, axis=0) - return samples, indexes - - def __len__(self): - return len(self._global_index) - - def __getitem__(self, index): - file_id, end_id = self._global_index[index] - start_id = 0 - if index > 0: - pre_file_id, pre_end_id = self._global_index[index - 1] - if pre_file_id == file_id: - start_id = pre_end_id - word_token_ids = self._samples[file_id][start_id:end_id] - token_ids = [] - is_suffix = np.zeros(word_token_ids.shape) - for idx, token_id in enumerate(word_token_ids): - token = self.tokenizer.convert_ids_to_tokens(int(token_id)) - if "##" in token: - token_id = self.tokenizer.convert_tokens_to_ids(token[-1]) - is_suffix[idx] = 1 - token_ids.append(token_id) - - return token_ids, is_suffix.astype(np.int64) - - -class DataCollatorForErnieHealth(object): - def __init__(self, tokenizer, mlm_prob, max_seq_length, return_dict=False): - self.tokenizer = tokenizer - self.mlm_prob = mlm_prob - self.max_seq_len = max_seq_length - self.return_dict = return_dict - self._ids = { - "cls": self.tokenizer.convert_tokens_to_ids(self.tokenizer.cls_token), - "sep": self.tokenizer.convert_tokens_to_ids(self.tokenizer.sep_token), - "pad": self.tokenizer.convert_tokens_to_ids(self.tokenizer.pad_token), - "mask": self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token), - } - - def __call__(self, data): - masked_input_ids_a, input_ids_a, labels_a = self.mask_tokens(data) - masked_input_ids_b, input_ids_b, labels_b = self.mask_tokens(data) - masked_input_ids = paddle.concat([masked_input_ids_a, masked_input_ids_b], axis=0).astype("int64") - input_ids = paddle.concat([input_ids_a, input_ids_b], axis=0) - labels = paddle.concat([labels_a, labels_b], axis=0) - if self.return_dict: - return {"input_ids": masked_input_ids, "raw_input_ids": input_ids, "generator_labels": labels} - - else: - return masked_input_ids, input_ids, labels - - def mask_tokens(self, batch_data): - - token_ids = [x[0] for x in batch_data] - is_suffix = [x[1] for x in batch_data] - - # Create probability matrix where the probability of real tokens is - # self.mlm_prob, while that of others is zero. - data = self.add_special_tokens_and_set_maskprob(token_ids, is_suffix) - token_ids, is_suffix, prob_matrix = data - token_ids = paddle.to_tensor(token_ids, dtype="int64", stop_gradient=True) - masked_token_ids = token_ids.clone() - labels = token_ids.clone() - - # Create masks for words, where '百' must be masked if '度' is masked - # for the word '百度'. - prob_matrix = prob_matrix * (1 - is_suffix) - word_mask_index = np.random.binomial(1, prob_matrix).astype("float") - is_suffix_mask = is_suffix == 1 - word_mask_index_tmp = word_mask_index - while word_mask_index_tmp.sum() > 0: - word_mask_index_tmp = np.concatenate( - [np.zeros((word_mask_index.shape[0], 1)), word_mask_index_tmp[:, :-1]], axis=1 - ) - word_mask_index_tmp = word_mask_index_tmp * is_suffix_mask - word_mask_index += word_mask_index_tmp - word_mask_index = word_mask_index.astype("bool") - labels[~word_mask_index] = -100 - - # 80% replaced with [MASK]. - token_mask_index = paddle.bernoulli(paddle.full(labels.shape, 0.8)).astype("bool").numpy() & word_mask_index - masked_token_ids[token_mask_index] = self._ids["mask"] - - # 10% replaced with random token ids. - token_random_index = paddle.to_tensor( - paddle.bernoulli(paddle.full(labels.shape, 0.5)).astype("bool").numpy() - & word_mask_index - & ~token_mask_index - ) - random_tokens = paddle.randint(low=0, high=self.tokenizer.vocab_size, shape=labels.shape, dtype="int64") - masked_token_ids = paddle.where(token_random_index, random_tokens, masked_token_ids) - - return masked_token_ids, token_ids, labels - - def add_special_tokens_and_set_maskprob(self, token_ids, is_suffix): - batch_size = len(token_ids) - batch_token_ids = np.full((batch_size, self.max_seq_len), self._ids["pad"]) - batch_token_ids[:, 0] = self._ids["cls"] - batch_is_suffix = np.full_like(batch_token_ids, -1) - prob_matrix = np.zeros_like(batch_token_ids, dtype="float32") - - for idx in range(batch_size): - if len(token_ids[idx]) > self.max_seq_len - 2: - token_ids[idx] = token_ids[idx][: self.max_seq_len - 2] - is_suffix[idx] = is_suffix[idx][: self.max_seq_len - 2] - seq_len = len(token_ids[idx]) - batch_token_ids[idx, seq_len + 1] = self._ids["sep"] - batch_token_ids[idx, 1 : seq_len + 1] = token_ids[idx] - batch_is_suffix[idx, 1 : seq_len + 1] = is_suffix[idx] - prob_matrix[idx, 1 : seq_len + 1] = self.mlm_prob - - return batch_token_ids, batch_is_suffix, prob_matrix - - -def create_dataloader(dataset, mode="train", batch_size=1, use_gpu=True, data_collator=None): - """ - Creats dataloader. - Args: - dataset(obj:`paddle.io.Dataset`): - Dataset instance. - mode(obj:`str`, optional, defaults to obj:`train`): - If mode is 'train', it will shuffle the dataset randomly. - batch_size(obj:`int`, optional, defaults to 1): - The sample number of a mini-batch. - use_gpu(obj:`bool`, optional, defaults to obj:`True`): - Whether to use gpu to run. - Returns: - dataloader(obj:`paddle.io.DataLoader`): The dataloader which generates batches. - """ - - if mode == "train" and use_gpu: - sampler = paddle.io.DistributedBatchSampler(dataset=dataset, batch_size=batch_size, shuffle=True) - dataloader = paddle.io.DataLoader( - dataset, batch_sampler=sampler, return_list=True, collate_fn=data_collator, num_workers=0 - ) - else: - shuffle = True if mode == "train" else False - sampler = paddle.io.BatchSampler(dataset=dataset, batch_size=batch_size, shuffle=shuffle) - dataloader = paddle.io.DataLoader( - dataset, batch_sampler=sampler, return_list=True, collate_fn=data_collator, num_workers=0 - ) - - return dataloader diff --git a/model_zoo/ernie-health/preprocess.py b/model_zoo/ernie-health/preprocess.py deleted file mode 100644 index c8c6ec2c5629..000000000000 --- a/model_zoo/ernie-health/preprocess.py +++ /dev/null @@ -1,201 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import io -import multiprocessing -import os -import re -import sys -import time - -import numpy as np -from tqdm import tqdm - -from paddlenlp.transformers import ElectraTokenizer - - -def parse_args(): - parser = argparse.ArgumentParser("Preprocessor for ERNIE-Health") - parser.add_argument( - "--input_path", type=str, required=True, help="The path to input text files where a sentence per line." - ) - parser.add_argument("--output_file", type=str, required=True, help="The output file path of preprocessed ids.") - parser.add_argument( - "--tokenize_tool", - type=str, - default="lac", - choices=["lac", "seg", "jieba"], - help="The tokenization tool for chinese words.", - ) - parser.add_argument("--logging_steps", type=int, default=100, help="The interval between progress updates.") - parser.add_argument("--num_worker", type=int, default=1, help="Number of worker processes to launch.") - - args = parser.parse_args() - return args - - -def lac_segmentation(): - from LAC import LAC - - tool = LAC(mode="lac") - - def process(text): - words, _ = tool.run(text) - return words - - return process - - -def seg_segmentation(): - from LAC import LAC - - tool = LAC(mode="seg") - - def process(text): - words = tool.run(text) - return words - - return process - - -def jieba_segmentation(): - import jieba - - def process(text): - words = jieba.cut(text) - return list(words) - - return process - - -SEGMENTATION_FN = {"lac": lac_segmentation(), "seg": seg_segmentation(), "jieba": jieba_segmentation()} - - -class ProcessFn(object): - def __init__(self, args): - self.args = args - - def initializer(self): - ProcessFn.tokenizer = ElectraTokenizer.from_pretrained("ernie-health-chinese") - ProcessFn.segmenter = SEGMENTATION_FN[self.args.tokenize_tool] - # Update vocabulary with '##'-prefixed chinese characters. - # The ids should coincide with those in run_pretrain.py. - suffix_vocab = {} - for idx, token in enumerate(range(0x4E00, 0x9FA6)): - suffix_vocab["##" + chr(token)] = len(ProcessFn.tokenizer) + idx - ProcessFn.tokenizer.added_tokens_encoder.update(suffix_vocab) - - def mark_word_in_tokens(tokens, words, max_word_length=4): - word_set = set(words) - index = 0 - while index < len(tokens): - # Skip non-chinese characters. - if len(re.findall("[\u4E00-\u9FA5]", tokens[index])) == 0: - index += 1 - continue - # Find the word with maximum length and mark it. - find_word = False - for length in range(max_word_length, 0, -1): - if index + length > len(tokens): - continue - if "".join(tokens[index : index + length]) in word_set: - for i in range(1, length): - tokens[index + i] = "##" + tokens[index + i] - index += length - find_word = True - break - - if not find_word: - index += 1 - return tokens - - def process(text): - words = ProcessFn.segmenter(text.strip()) - tokens = ProcessFn.tokenizer.tokenize("".join(words)) - tokens = mark_word_in_tokens(tokens, words) - tokens = ProcessFn.tokenizer.convert_tokens_to_ids(tokens) - return tokens - - ProcessFn.process = process - - def encode(self, text): - token_ids = ProcessFn.process(text) - return token_ids, len(text.encode("utf-8")) - - -def main(): - args = parse_args() - - file_paths = [] - if os.path.isfile(args.input_path): - file_paths.append(args.input_path) - else: - for root, dirs, files in os.walk(args.input_path): - for file_name in files: - file_paths.append(os.path.join(root, file_name)) - file_paths.sort() - - tokenizer = ElectraTokenizer.from_pretrained("ernie-health-chinese") - save_dtype = np.uint16 if tokenizer.vocab_size < 2**16 - 1 else np.int32 - processer = ProcessFn(args) - - pool = multiprocessing.Pool(args.num_worker, initializer=processer.initializer) - - token_id_stream = io.BytesIO() - sent_len_stream = io.BytesIO() - - step = 0 - sent_count = 0 - total_bytes_processed = 0 - start_tic = time.time() - - for path in tqdm(file_paths): - text_fp = open(path, "r") - processed_text = pool.imap(processer.encode, text_fp, 256) - print("Processing %s" % path) - for i, (tokens, bytes_processed) in enumerate(processed_text, start=1): - step += 1 - total_bytes_processed += bytes_processed - - sentence_len = len(tokens) - if sentence_len == 0: - continue - sent_len_stream.write(sentence_len.to_bytes(4, byteorder="little", signed=True)) - sent_count += 1 - token_id_stream.write(np.array(tokens, dtype=save_dtype).tobytes(order="C")) - - if step % args.logging_steps == 0: - time_cost = time.time() - start_tic - mbs = total_bytes_processed / time_cost / 1024 / 1024 - print( - f"Processed {step} sentences", - f"({step/time_cost:.2f} sentences/s, {mbs:.4f} MB/s).", - file=sys.stderr, - ) - - pool.close() - print("Saving tokens to files...") - all_token_ids = np.frombuffer(token_id_stream.getbuffer(), dtype=save_dtype) - all_sent_lens = np.frombuffer(sent_len_stream.getbuffer(), dtype=np.int32) - np.save(args.output_file + "_ids.npy", all_token_ids) - np.savez(args.output_file + "_idx.npz", lens=all_sent_lens) - - print("Total sentences num: %d" % len(all_sent_lens)) - print("Total tokens num: %d" % len(all_token_ids)) - print("Average tokens per sentence: %.2f" % (len(all_token_ids) / len(all_sent_lens))) - - -if __name__ == "__main__": - main() diff --git a/model_zoo/ernie-health/run_pretrain.py b/model_zoo/ernie-health/run_pretrain.py deleted file mode 100644 index 2774a865ed9c..000000000000 --- a/model_zoo/ernie-health/run_pretrain.py +++ /dev/null @@ -1,396 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import json -import os -import random -import time -from collections import defaultdict - -import numpy as np -import paddle -from dataset import DataCollatorForErnieHealth, MedicalCorpus, create_dataloader -from visualdl import LogWriter - -from paddlenlp.transformers import ( - ElectraConfig, - ElectraTokenizer, - ErnieHealthForTotalPretraining, - LinearDecayWithWarmup, -) -from paddlenlp.utils.log import logger - -MODEL_CLASSES = { - "ernie-health": (ElectraConfig, ErnieHealthForTotalPretraining, ElectraTokenizer), -} - - -def parse_args(): - parser = argparse.ArgumentParser() - - parser.add_argument( - "--model_name_or_path", - default="ernie-health-chinese", - type=str, - help="Path to pre-trained model or shortcut name selected in the list: " - + ", ".join( - sum([list(classes[-1].pretrained_init_configuration.keys()) for classes in MODEL_CLASSES.values()], []) - ), - ) - parser.add_argument( - "--input_dir", - default=None, - type=str, - required=True, - help="The input directory where the data will be read from.", - ) - parser.add_argument( - "--output_dir", - default=None, - type=str, - required=True, - help="The output directory where the model predictions and checkpoints will be written.", - ) - parser.add_argument("--max_seq_length", default=512, type=int, help="The max length of each sequence") - parser.add_argument( - "--mlm_prob", default=0.15, type=float, help="The probability of tokens to be sampled as masks." - ) - parser.add_argument( - "--batch_size", - default=256, - type=int, - help="Batch size per GPU/CPU for training.", - ) - parser.add_argument("--learning_rate", default=2e-4, type=float, help="The initial learning rate for Adam.") - parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") - parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.") - parser.add_argument( - "--num_epochs", - default=100, - type=int, - help="Total number of training epochs to perform.", - ) - parser.add_argument( - "--max_steps", - default=-1, - type=int, - help="If > 0: set total number of training steps to perform. Override num_epochs.", - ) - parser.add_argument("--warmup_steps", default=10000, type=int, help="Linear warmup over warmup_steps.") - parser.add_argument("--logging_steps", type=int, default=100, help="Log every X updates steps.") - parser.add_argument("--save_steps", type=int, default=10000, help="Save checkpoint every X updates steps.") - parser.add_argument( - "--init_from_ckpt", - action="store_true", - help="Whether to load model checkpoint. if True, args.model_name_or_path must be dir store ckpt or will train from fresh start", - ) - parser.add_argument( - "--use_amp", action="store_true", help="Whether to use float16(Automatic Mixed Precision) to train." - ) - parser.add_argument("--eager_run", type=bool, default=True, help="Use dygraph mode.") - parser.add_argument( - "--device", - default="gpu", - type=str, - choices=["cpu", "gpu"], - help="The device to select to train the model, is must be cpu/gpu.", - ) - parser.add_argument("--seed", type=int, default=1000, help="random seed for initialization") - args = parser.parse_args() - return args - - -def set_seed(seed): - # Use the same data seed(for data shuffle) for all procs to guarantee data - # consistency after sharding. - random.seed(seed) - np.random.seed(seed) - # Maybe different op seeds(for dropout) for different procs is better. By: - # `paddle.seed(args.seed + paddle.distributed.get_rank())` - paddle.seed(seed) - - -class WorkerInitObj(object): - def __init__(self, seed): - self.seed = seed - - def __call__(self, id): - np.random.seed(seed=self.seed + id) - random.seed(self.seed + id) - - -def do_train(args): - paddle.enable_static() if not args.eager_run else None - paddle.set_device(args.device) - if paddle.distributed.get_world_size() > 1: - paddle.distributed.init_parallel_env() - - set_seed(args.seed) - - config_class, model_class, tokenizer_class = MODEL_CLASSES["ernie-health"] - - # Loads or initialize a model. - pretrained_models = list(tokenizer_class.pretrained_init_configuration.keys()) - - if os.path.isdir(args.model_name_or_path) and args.init_from_ckpt: - # Load checkpoint - tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path) - with open(os.path.join(args.model_name_or_path, "run_states.json"), "r") as f: - config_dict = json.load(f) - model_name = config_dict["model_name"] - if model_name in pretrained_models: - model = model_class.from_pretrained(args.model_name_or_path) - model.set_state_dict(paddle.load(os.path.join(args.model_name_or_path, "model_state.pdparams"))) - else: - raise ValueError( - "initialize a model from ckpt need model_name " - "in model_config_file. The supported model_name " - "are as follows: {}".format(tokenizer_class.pretrained_init_configuration.keys()) - ) - else: - tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path) - model_config = config_class() - model = model_class(model_config) - args.init_from_ckpt = False - - if paddle.distributed.get_world_size() > 1: - model = paddle.DataParallel(model) - - # Loads dataset. - tic_load_data = time.time() - logger.info("start load data : %s" % (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))) - - train_dataset = MedicalCorpus(data_path=args.input_dir, tokenizer=tokenizer) - logger.info("load data done, total : %s s" % (time.time() - tic_load_data)) - - # Reads data and generates mini-batches. - data_collator = DataCollatorForErnieHealth( - tokenizer=tokenizer, max_seq_length=args.max_seq_length, mlm_prob=args.mlm_prob - ) - - train_data_loader = create_dataloader( - train_dataset, - batch_size=args.batch_size, - mode="train", - use_gpu=True if args.device in "gpu" else False, - data_collator=data_collator, - ) - - num_training_steps = args.max_steps if args.max_steps > 0 else (len(train_data_loader) * args.num_epochs) - args.num_epochs = (num_training_steps - 1) // len(train_data_loader) + 1 - - lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps, args.warmup_steps) - - clip = paddle.nn.ClipGradByGlobalNorm(clip_norm=1.0) - - # Generate parameter names needed to perform weight decay. - # All bias and LayerNorm parameters are excluded. - decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])] - optimizer = paddle.optimizer.AdamW( - learning_rate=lr_scheduler, - epsilon=args.adam_epsilon, - parameters=model.parameters(), - weight_decay=args.weight_decay, - grad_clip=clip, - apply_decay_param_fun=lambda x: x in decay_params, - ) - if args.use_amp: - scaler = paddle.amp.GradScaler(init_loss_scaling=1024) - - logger.info("start train : %s" % (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))) - trained_global_step = global_step = 0 - t_loss = defaultdict(lambda: paddle.to_tensor([0.0])) - log_loss = defaultdict(lambda: paddle.to_tensor([0.0])) - loss_list = defaultdict(list) - log_list = [] - tic_train = time.time() - - if os.path.isdir(args.model_name_or_path) and args.init_from_ckpt: - optimizer.set_state_dict(paddle.load(os.path.join(args.model_name_or_path, "model_state.pdopt"))) - trained_global_step = global_step = config_dict["global_step"] - if trained_global_step < num_training_steps: - logger.info( - "[ start train from checkpoint ] we have already trained %s steps, seeking next step : %s" - % (trained_global_step, trained_global_step + 1) - ) - else: - logger.info( - "[ start train from checkpoint ] we have already trained %s steps, but total training steps is %s, please check configuration !" - % (trained_global_step, num_training_steps) - ) - exit(0) - - if paddle.distributed.get_rank() == 0: - writer = LogWriter(os.path.join(args.output_dir, "loss_log")) - - for epoch in range(args.num_epochs): - for step, batch in enumerate(train_data_loader): - if trained_global_step > 0: - trained_global_step -= 1 - continue - global_step += 1 - masked_input_ids, input_ids, gen_labels = batch - - if args.use_amp: - with paddle.amp.auto_cast(): - loss, gen_loss, rtd_loss, mts_loss, csp_loss = model( - input_ids=masked_input_ids, - raw_input_ids=input_ids, - generator_labels=gen_labels, - ) - - scaled = scaler.scale(loss) - scaled.backward() - t_loss["loss"] += loss.detach() - t_loss["gen"] += gen_loss.detach() - t_loss["rtd"] += rtd_loss.detach() - t_loss["mts"] += mts_loss.detach() - t_loss["csp"] += csp_loss.detach() - scaler.minimize(optimizer, scaled) - else: - loss, gen_loss, rtd_loss, mts_loss, csp_loss = model( - input_ids=masked_input_ids, - raw_input_ids=input_ids, - generator_labels=gen_labels, - ) - loss.backward() - t_loss["loss"] += loss.detach() - t_loss["gen"] += gen_loss.detach() - t_loss["rtd"] += rtd_loss.detach() - t_loss["mts"] += mts_loss.detach() - t_loss["csp"] += csp_loss.detach() - optimizer.step() - - lr_scheduler.step() - optimizer.clear_grad() - if global_step % args.logging_steps == 0: - local_loss = dict( - [(k, (t_loss[k] - log_loss[k]) / args.logging_steps) for k in ["loss", "gen", "rtd", "mts", "csp"]] - ) - if paddle.distributed.get_world_size() > 1: - for k in ["loss", "gen", "rtd", "mts", "csp"]: - paddle.distributed.all_gather(loss_list[k], local_loss[k]) - if paddle.distributed.get_rank() == 0: - tmp_loss = dict( - [ - (k, float((paddle.stack(loss_list[k]).sum() / len(loss_list[k])).numpy())) - for k in ["loss", "gen", "rtd", "mts", "csp"] - ] - ) - log_str = ( - "global step {0:d}/{1:d}, epoch: {2:d}, batch: {3:d}, " - "avg_loss: {4:.15f}, generator: {5:.15f}, rtd: {6:.15f}, multi_choice: {7:.15f}, " - "seq_contrastive: {8:.15f}, lr: {9:.10f}, speed: {10:.2f} s/it" - ).format( - global_step, - num_training_steps, - epoch, - step, - tmp_loss["loss"], - tmp_loss["gen"], - tmp_loss["rtd"], - tmp_loss["mts"], - tmp_loss["csp"], - optimizer.get_lr(), - (time.time() - tic_train) / args.logging_steps, - ) - logger.info(log_str) - log_list.append(log_str) - writer.add_scalar("generator_loss", tmp_loss["gen"], global_step) - writer.add_scalar("rtd_loss", tmp_loss["rtd"] * 50, global_step) - writer.add_scalar("mts_loss", tmp_loss["mts"] * 20, global_step) - writer.add_scalar("csp_loss", tmp_loss["csp"], global_step) - writer.add_scalar("total_loss", tmp_loss["loss"], global_step) - writer.add_scalar("lr", optimizer.get_lr(), global_step) - loss_list = defaultdict(list) - else: - local_loss = dict([(k, float(v)) for k, v in local_loss.items()]) - log_str = ( - "global step {0:d}/{1:d}, epoch: {2:d}, batch: {3:d}, " - "avg_loss: {4:.15f}, generator: {5:.15f}, rtd: {6:.15f}, multi_choice: {7:.15f}, " - "seq_contrastive_loss: {8:.15f}, lr: {9:.10f}, speed: {10:.2f} s/it" - ).format( - global_step, - num_training_steps, - epoch, - step, - local_loss["loss"], - local_loss["gen"], - local_loss["rtd"], - local_loss["mts"], - local_loss["csp"], - optimizer.get_lr(), - (time.time() - tic_train) / args.logging_steps, - ) - logger.info(log_str) - log_list.append(log_str) - loss_dict = { - "generator_loss": local_loss["gen"], - "rtd_loss": local_loss["rtd"] * 50, - "mts_loss": local_loss["mts"] * 20, - "csp_loss": local_loss["csp"], - } - for k, v in loss_dict.items(): - writer.add_scalar("loss/%s" % k, v, global_step) - writer.add_scalar("total_loss", local_loss["loss"], global_step) - writer.add_scalar("lr", optimizer.get_lr(), global_step) - log_loss = dict(t_loss) - tic_train = time.time() - - if global_step % args.save_steps == 0: - if paddle.distributed.get_rank() == 0: - output_dir = os.path.join(args.output_dir, "model_%d.pdparams" % global_step) - if not os.path.exists(output_dir): - os.makedirs(output_dir) - model_to_save = model._layers if isinstance(model, paddle.DataParallel) else model - config_to_save = model_to_save.discriminator.electra.config.to_dict() - if "self" in config_to_save: - del config_to_save["self"] - run_states = { - "model_name": model_name if args.init_from_ckpt else args.model_name_or_path, - "global_step": global_step, - "epoch": epoch, - "step": step, - } - with open(os.path.join(output_dir, "model_config.json"), "w") as f: - json.dump(config_to_save, f) - with open(os.path.join(output_dir, "run_states.json"), "w") as f: - json.dump(run_states, f) - paddle.save(model.state_dict(), os.path.join(output_dir, "model_state.pdparams")) - tokenizer.save_pretrained(output_dir) - paddle.save(optimizer.state_dict(), os.path.join(output_dir, "model_state.pdopt")) - if len(log_list) > 0: - with open(os.path.join(output_dir, "train.log"), "w") as f: - for log in log_list: - if len(log.strip()) > 0: - f.write(log.strip() + "\n") - if global_step >= num_training_steps: - if paddle.distributed.get_rank() == 0: - writer.close() - return - - -def print_arguments(args): - """print arguments""" - print("----------- Configuration Arguments -----------") - for arg, value in sorted(vars(args).items()): - print("%s: %s" % (arg, value)) - print("------------------------------------------------") - - -if __name__ == "__main__": - args = parse_args() - print_arguments(args) - do_train(args) diff --git a/model_zoo/ernie-health/run_pretrain_trainer.py b/model_zoo/ernie-health/run_pretrain_trainer.py deleted file mode 100644 index 98505d68958f..000000000000 --- a/model_zoo/ernie-health/run_pretrain_trainer.py +++ /dev/null @@ -1,166 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import os -import time -from dataclasses import dataclass, field -from typing import Optional - -import paddle -from dataset import DataCollatorForErnieHealth, MedicalCorpus - -from paddlenlp.trainer import ( - PdArgumentParser, - Trainer, - TrainingArguments, - get_last_checkpoint, -) -from paddlenlp.transformers import ( - ElectraConfig, - ElectraTokenizer, - ErnieHealthForTotalPretraining, -) -from paddlenlp.utils.log import logger - -MODEL_CLASSES = { - "ernie-health": (ElectraConfig, ErnieHealthForTotalPretraining, ElectraTokenizer), -} - - -@dataclass -class DataArguments: - """ - Arguments pertaining to what data we are going to input our model for training and evaluating. - Using `PdArgumentParser` we can turn this class into argparse arguments to be able to - specify them on the command line. - """ - - input_dir: str = field( - default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."} - ) - max_seq_length: int = field( - default=512, - metadata={ - "help": "The maximum total input sequence length after tokenization. Sequences longer " - "than this will be truncated, sequences shorter will be padded." - }, - ) - masked_lm_prob: float = field( - default=0.15, - metadata={"help": "Mask token prob."}, - ) - - -@dataclass -class ModelArguments: - """ - Arguments pertaining to which model/config/tokenizer we are going to pre-train from. - """ - - model_type: Optional[str] = field( - default="ernie-health", metadata={"help": "Only support for ernie-health pre-training for now."} - ) - model_name_or_path: str = field( - default="ernie-health-chinese", - metadata={ - "help": "Path to pretrained model or model identifier from https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers.html" - }, - ) - - -def main(): - parser = PdArgumentParser((ModelArguments, DataArguments, TrainingArguments)) - model_args, data_args, training_args = parser.parse_args_into_dataclasses() - - training_args.eval_iters = 10 - training_args.test_iters = training_args.eval_iters * 10 - # training_args.recompute = True - - # Log model and data config - training_args.print_config(model_args, "Model") - training_args.print_config(data_args, "Data") - - paddle.set_device(training_args.device) - - # Log on each process the small summary: - logger.warning( - f"Process rank: {training_args.local_rank}, device: {training_args.device}, world_size: {training_args.world_size}, " - + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}" - ) - - # Detecting last checkpoint. - last_checkpoint = None - if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir: - last_checkpoint = get_last_checkpoint(training_args.output_dir) - if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 1: - raise ValueError( - f"Output directory ({training_args.output_dir}) already exists and is not empty. " - "Use --overwrite_output_dir to overcome." - ) - elif last_checkpoint is not None and training_args.resume_from_checkpoint is None: - logger.info( - f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change " - "the `--output_dir` or add `--overwrite_output_dir` to train from scratch." - ) - - config_class, model_class, tokenizer_class = MODEL_CLASSES["ernie-health"] - - # Loads or initialize a model. - tokenizer = tokenizer_class.from_pretrained(model_args.model_name_or_path) - - model_config = config_class() - model = model_class(model_config) - - # Loads dataset. - tic_load_data = time.time() - logger.info("start load data : %s" % (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))) - - train_dataset = MedicalCorpus(data_path=data_args.input_dir, tokenizer=tokenizer) - logger.info("load data done, total : %s s" % (time.time() - tic_load_data)) - - # Reads data and generates mini-batches. - data_collator = DataCollatorForErnieHealth( - tokenizer=tokenizer, - max_seq_length=data_args.max_seq_length, - mlm_prob=data_args.masked_lm_prob, - return_dict=True, - ) - - trainer = Trainer( - model=model, - args=training_args, - data_collator=data_collator, - train_dataset=train_dataset if training_args.do_train else None, - eval_dataset=None, - tokenizer=tokenizer, - ) - - checkpoint = None - if training_args.resume_from_checkpoint is not None: - checkpoint = training_args.resume_from_checkpoint - elif last_checkpoint is not None: - checkpoint = last_checkpoint - - # Training - if training_args.do_train: - train_result = trainer.train(resume_from_checkpoint=checkpoint) - metrics = train_result.metrics - trainer.save_model() - trainer.log_metrics("train", metrics) - trainer.save_metrics("train", metrics) - trainer.save_state() - - -if __name__ == "__main__": - main() diff --git a/model_zoo/ernie-health/run_trainer.sh b/model_zoo/ernie-health/run_trainer.sh deleted file mode 100644 index 94b99e834713..000000000000 --- a/model_zoo/ernie-health/run_trainer.sh +++ /dev/null @@ -1,45 +0,0 @@ -# Copyright (c) 2023 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -#set -x -unset CUDA_VISIBLE_DEVICES - -task_name="eheath-pretraining" -rm -rf output/$task_name/log - -python -u -m paddle.distributed.launch \ - --gpus 0,1,2,3,4,5,6,7 \ - run_pretrain_trainer.py \ - --input_dir "./data" \ - --output_dir "output/$task_name" \ - --max_seq_length 512 \ - --gradient_accumulation_steps 1\ - --per_device_train_batch_size 8 \ - --per_device_eval_batch_size 8 \ - --learning_rate 0.001 \ - --max_steps 1000000 \ - --save_steps 50000 \ - --weight_decay 0.01 \ - --warmup_ratio 0.01 \ - --max_grad_norm 1.0 \ - --logging_steps 20 \ - --dataloader_num_workers 4 \ - --device "gpu"\ - --fp16 \ - --fp16_opt_level "O1" \ - --do_train \ - --disable_tqdm True\ - --save_total_limit 10 - -# WARNING: fp16_opt_level O2 may cause ehealth pretraining fail ! \ No newline at end of file diff --git a/model_zoo/ernie-m/README.md b/model_zoo/ernie-m/README.md deleted file mode 100644 index 634f88c21deb..000000000000 --- a/model_zoo/ernie-m/README.md +++ /dev/null @@ -1,237 +0,0 @@ -# ERNIE-M - -* [模型介绍](#模型介绍) -* [开始运行](#开始运行) - * [环境要求](#环境要求) - * [数据准备](#数据准备) - * [模型训练](#模型训练) - * [参数释义](#参数释义) - * [单卡训练](#单卡训练) - * [单机多卡](#单机多卡) - * [预测评估](#预测评估) - * [部署](#部署) - * [FastDeploy 部署](#FastDeploy部署) - * [Python 部署](#Python部署) - * [服务化部署](#服务化部署) -* [参考论文](#参考论文) - -## 模型介绍 - -[ERNIE-M](https://arxiv.org/abs/2012.15674) 是百度提出的一种多语言语言模型。原文提出了一种新的训练方法,让模型能够将多种语言的表示与单语语料库对齐,以克服平行语料库大小对模型性能的限制。原文的主要想法是将回译机制整合到预训练的流程中,在单语语料库上生成伪平行句对,以便学习不同语言之间的语义对齐,从而增强跨语言模型的语义建模。实验结果表明,ERNIE-M 优于现有的跨语言模型,并在各种跨语言下游任务中提供了最新的 SOTA 结果。 -原文提出两种方法建模各种语言间的对齐关系: - -- **Cross-Attention Masked Language Modeling(CAMLM)**: 该算法在少量双语语料上捕捉语言间的对齐信息。其需要在不利用源句子上下文的情况下,通过目标句子还原被掩盖的词语,使模型初步建模了语言间的对齐关系。 -- **Back-Translation masked language modeling(BTMLM)**: 该方法基于回译机制从单语语料中学习语言间的对齐关系。通过CAMLM 生成伪平行语料,然后让模型学习生成的伪平行句子,使模型可以利用单语语料更好地建模语义对齐关系。 - - -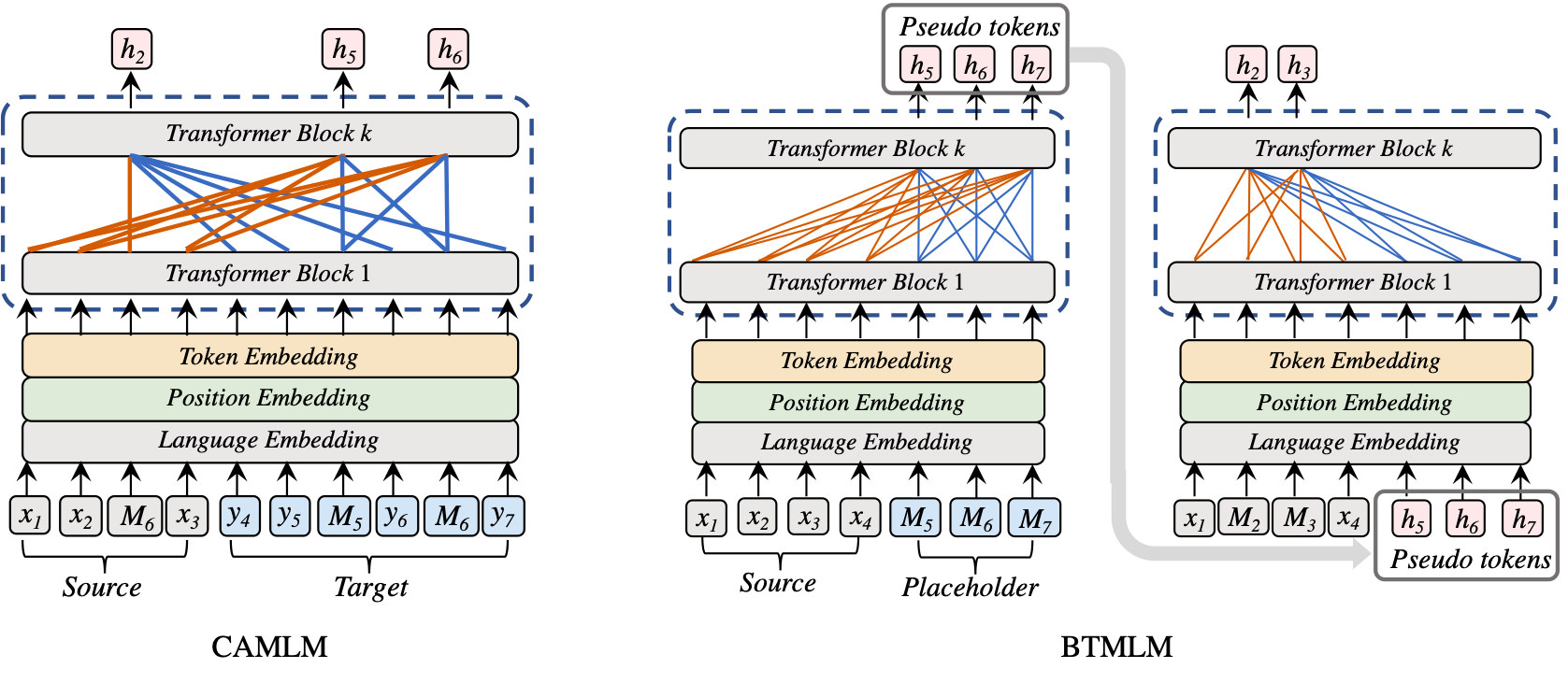 - -本项目是 ERNIE-M 的 PaddlePaddle 动态图实现,包含模型训练,模型验证等内容。以下是本例的简要目录结构及说明: - -```text -. -|-- README.md # 文档 -|-- deploy # 部署目录 -| |-- predictor # onnx离线部署 -| | |-- README.md -| | |-- ernie_m_predictor.py -| | |-- inference.py -| | |-- requirements_cpu.txt -| | `-- requirements_gpu.txt -| `-- simple_serving # 基于PaddleNLP SimpleServing 服务化部署 -| |-- README.md -| |-- client_seq_cls.py -| `-- server_seq_cls.py -`-- run_classifier.py # 分类任务微调脚本 -``` - -## 开始运行 - -下面提供以XNLI数据集进行模型微调相关训练、预测、部署的代码,XNLI数据集是MNLI的子集,并且已被翻译成14种不同的语言(包含一些较低资源语言)。与MNLI一样,目标是预测文本蕴含(句子 A 是否暗示/矛盾/都不是句子 B )。 - -### 环境要求 - -python >= 3.7 -paddlepaddle >= 2.3 -paddlenlp >= 2.4.9 -paddle2onnx >= 1.0.5 - -### 数据准备 - -此次微调数据使用XNLI数据集, 可以通过下面的方式来使用数据集 - -```python -from datasets import load_dataset - -# all_languages = ["ar", "bg", "de", "el", "en", "es", "fr", "hi", "ru", "sw", "th", "tr", "ur", "vi", "zh"] -# load xnli dataset of english -train_ds, eval_ds, test_ds = load_dataset("xnli", "en", split=["train_ds", "validation", "test"]) -``` - -### 模型训练 - -#### 参数释义 - -- `task_type` 表示了自然语言推断任务的类型,目前支持的类型为:"cross-lingual-transfer", "translate-train-all" - ,分别表示在英文数据集上训练并在所有15种语言数据集上测试、在所有15种语言数据集上训练和测试。 -- `model_name_or_path` 指示了 Fine-tuning 使用的具体预训练模型以及预训练时使用的tokenizer,目前支持的预训练模型有:"ernie-m-base", "ernie-m-large" - 。若模型相关内容保存在本地,这里也可以提供相应目录地址,例如:"./finetuned_models"。 -- `do_train` 是否进行训练任务。 -- `do_eval` 是否进行评估任务。 -- `do_predict` 是否进行评测任务。 -- `do_export` 是否导出模型。 -- `output_dir` 表示模型保存路径。 -- `export_model_dir` 模型的导出路径。 -- `per_device_train_batch_size` 表示训练时每次迭代**每张**卡上的样本数目。 -- `per_device_eval_batch_size` 表示验证时每次迭代**每张**卡上的样本数目。 -- `max_seq_length` 表示最大句子长度,超过该长度将被截断,不足该长度的将会进行 padding。 -- `learning_rate` 表示基础学习率大小,将于 learning rate scheduler 产生的值相乘作为当前学习率。 -- `classifier_dropout` 表示模型用于分类的 dropout rate ,默认是0.1。 -- `num_train_epochs` 表示训练轮数。 -- `logging_steps` 表示日志打印间隔步数。 -- `save_steps` 表示模型保存及评估间隔步数。 -- `layerwise_decay` 表示 AdamW with Layerwise decay 的逐层衰减系数。 -- `warmup_rate` 表示学习率warmup系数。 -- `max_steps` 表示最大训练步数。若训练`num_train_epochs`轮包含的训练步数大于该值,则达到`max_steps`后就提前结束。 -- `seed` 表示随机数种子。 -- `device` 表示训练使用的设备, 'gpu'表示使用 GPU, 'xpu'表示使用百度昆仑卡, 'cpu'表示使用 CPU。 -- `fp16` 表示是否启用自动混合精度训练。 -- `scale_loss` 表示自动混合精度训练的参数。 -- `load_best_model_at_end` 训练结束后是否加载最优模型,通常与`metric_for_best_model`配合使用。 -- `metric_for_best_model` 最优模型指标,如`eval_accuarcy`等,用于比较模型好坏。 - -#### 单卡训练 - -`run_classifier.py`是模型微调脚本,可以使用如下命令对预训练模型进行微调训练。 - -```shell -python run_classifier.py \ - --do_train \ - --do_eval \ - --do_export \ - --task_type cross-lingual-transfer \ - --model_name_or_path ernie-m-base \ - --output_dir ./finetuned_models/ \ - --export_model_dir ./finetuned_models/ \ - --per_device_train_batch_size 16 \ - --per_device_eval_batch_size 16 \ - --max_seq_length 256 \ - --learning_rate 5e-5 \ - --classifier_dropout 0.1 \ - --weight_decay 0.0 \ - --layerwise_decay 0.8 \ - --save_steps 12272 \ - --eval_steps 767 \ - --num_train_epochs 5 \ - --warmup_ratio 0.1 \ - --load_best_model_at_end True \ - --metric_for_best_model eval_accuracy \ - --overwrite_output_dir -``` - -#### 单机多卡 - -同样,可以执行如下命令实现多卡训练 - -```shell -python -m paddle.distributed.launch --gpus 0,1 run_classifier.py \ - --do_train \ - --do_eval \ - --do_export \ - --task_type cross-lingual-transfer \ - --model_name_or_path ernie-m-base \ - --output_dir ./finetuned_models/ \ - --export_model_dir ./finetuned_models/ \ - --per_device_train_batch_size 16 \ - --per_device_eval_batch_size 16 \ - --max_seq_length 256 \ - --learning_rate 5e-5 \ - --classifier_dropout 0.1 \ - --weight_decay 0.0 \ - --layerwise_decay 0.8 \ - --save_steps 12272 \ - --eval_steps 767 \ - --num_train_epochs 5 \ - --warmup_ratio 0.1 \ - --load_best_model_at_end True \ - --metric_for_best_model eval_accuracy \ - --overwrite_output_dir \ - --remove_unused_columns False -``` - -这里设置额外的参数`--remove_unused_columns`为`False`是因为数据集中不需要的字段已经被手动去除了。 - -#### 预测评估 - -当训练完成后,可以直接加载训练保存的模型进行评估,此时`--model_name_or_path`传入训练时的`output_dir`即`./finetuned_models`。 - -```shell -python run_classifier.py \ - --do_predict \ - --task_type cross-lingual-transfer \ - --model_name_or_path ./finetuned_models \ - --output_dir ./finetuned_models -``` - -预测结果(label)和预测的置信度(confidence)将写入`./finetuned_models/test_results.json`文件。 - - -在XNLI数据集上微调 cross-lingual-transfer 类型的自然语言推断任务后,在测试集上有如下结果 -| Model | en | fr | es | de | el | bg | ru | tr | ar | vi | th | zh | hi | sw | ur | Avg | -| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | -| Cross-lingual Transfer | | | | | | | | | | | | | | | | | -| XLM | 85.0 | 78.7 | 78.9 | 77.8 | 76.6 | 77.4 | 75.3 | 72.5 | 73.1 | 76.1 | 73.2 | 76.5 | 69.6 | 68.4 | 67.3 | 75.1 | -| Unicoder | 85.1 | 79.0 | 79.4 | 77.8 | 77.2 | 77.2 | 76.3 | 72.8 | 73.5 | 76.4 | 73.6 | 76.2 | 69.4 | 69.7 | 66.7 | 75.4 | -| XLM-R | 85.8 | 79.7 | 80.7 | 78.7 | 77.5 | 79.6 | 78.1 | 74.2 | 73.8 | 76.5 | 74.6 | 76.7 | 72.4 | 66.5 | 68.3 | 76.2 | -| INFOXLM | **86.4** | **80.6** | 80.8 | 78.9 | 77.8 | 78.9 | 77.6 | 75.6 | 74.0 | 77.0 | 73.7 | 76.7 | 72.0 | 66.4 | 67.1 | 76.2 | -| **ERNIE-M** | 85.5 | 80.1 | **81.2** | **79.2** | **79.1** | **80.4** | **78.1** | **76.8** | **76.3** | **78.3** | **75.8** | **77.4** | **72.9** | **69.5** | **68.8** | **77.3** | -| XLM-R Large | 89.1 | 84.1 | 85.1 | 83.9 | 82.9 | 84.0 | 81.2 | 79.6 | 79.8 | 80.8 | 78.1 | 80.2 | 76.9 | 73.9 | 73.8 | 80.9 | -| INFOXLM Large | **89.7** | 84.5 | 85.5 | 84.1 | 83.4 | 84.2 | 81.3 | 80.9 | 80.4 | 80.8 | 78.9 | 80.9 | 77.9 | 74.8 | 73.7 | 81.4 | -| VECO Large | 88.2 | 79.2 | 83.1 | 82.9 | 81.2 | 84.2 | 82.8 | 76.2 | 80.3 | 74.3 | 77.0 | 78.4 | 71.3 | **80.4** | **79.1** | 79.9 | -| **ERNIR-M Large** | 89.3 | **85.1** | **85.7** | **84.4** | **83.7** | **84.5** | 82.0 | **81.2** | **81.2** | **81.9** | **79.2** | **81.0** | **78.6** | 76.2 | 75.4 | **82.0** | -| Translate-Train-All | | | | | | | | | | | | | | | | | -| XLM | 85.0 | 80.8 | 81.3 | 80.3 | 79.1 | 80.9 | 78.3 | 75.6 | 77.6 | 78.5 | 76.0 | 79.5 | 72.9 | 72.8 | 68.5 | 77.8 | -| Unicoder | 85.6 | 81.1 | 82.3 | 80.9 | 79.5 | 81.4 | 79.7 | 76.8 | 78.2 | 77.9 | 77.1 | 80.5 | 73.4 | 73.8 | 69.6 | 78.5 | -| XLM-R | 85.4 | 81.4 | 82.2 | 80.3 | 80.4 | 81.3 | 79.7 | 78.6 | 77.3 | 79.7 | 77.9 | 80.2 | 76.1 | 73.1 | 73.0 | 79.1 | -| INFOXLM | 86.1 | 82.0 | 82.8 | 81.8 | 80.9 | 82.0 | 80.2 | 79.0 | 78.8 | 80.5 | 78.3 | 80.5 | 77.4 | 73.0 | 71.6 | 79.7 | -| **ERNIE-M** | **86.2** | **82.5** | **83.8** | **82.6** | **82.4** | **83.4** | **80.2** | **80.6** | **80.5** | **81.1** | **79.2** | **80.5** | **77.7** | **75.0** | **73.3** | **80.6** | -| XLM-R Large | 89.1 | 85.1 | 86.6 | 85.7 | 85.3 | 85.9 | 83.5 | 83.2 | 83.1 | 83.7 | 81.5 | **83.7** | **81.6** | 78.0 | 78.1 | 83.6 | -| VECO Large | 88.9 | 82.4 | 86.0 | 84.7 | 85.3 | 86.2 | **85.8** | 80.1 | 83.0 | 77.2 | 80.9 | 82.8 | 75.3 | **83.1** | **83.0** | 83.0 | -| **ERNIE-M Large** | **89.5** | **86.5** | **86.9** | **86.1** | **86.0** | **86.8** | 84.1 | **83.8** | **84.1** | **84.5** | **82.1** | 83.5 | 81.1 | 79.4 | 77.9 | **84.2** | - - - -## 部署 - -我们基于 FastDeploy 为 ERNIE-M 提供了多种部署方案,可以满足不同场景下的部署需求,请根据实际情况进行选择。 - - - -### FastDeploy 部署 - -⚡️[FastDeploy](https://github.com/PaddlePaddle/FastDeploy)是一款全场景、易用灵活、极致高效的AI推理部署工具,为开发者提供多硬件、多推理引擎后端的部署能力。开发者只需调用一行代码即可随意切换硬件、推理引擎后端。 - -
-
- -
-
-
-
-
-目前 ERNIE-M 模型已提供基于 FastDeploy 的部署示例,支持在多款硬件(CPU、GPU、昆仑芯、华为昇腾以及 Graphcore IPU)以及推理引擎后端进行部署。
-
-
-
-#### Python 部署
-
-Python 部署请参考:[Python 部署指南](./deploy/python/README.md)
-
-
-
-### 服务化部署
-
-* [PaddleNLP SimpleServing 服务化部署指南](./deploy/simple_serving/README.md)
-
-
-## 参考论文
-
- [Ouyang X , Wang S , Pang C , et al. ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora[J]. 2020.](https://arxiv.org/abs/2012.15674)
diff --git a/model_zoo/ernie-m/deploy/python/README.md b/model_zoo/ernie-m/deploy/python/README.md
deleted file mode 100644
index 167c3e0bd470..000000000000
--- a/model_zoo/ernie-m/deploy/python/README.md
+++ /dev/null
@@ -1,132 +0,0 @@
-# FastDeploy ERNIE-M 模型 Python 部署示例
-
-在部署前,参考 [FastDeploy SDK 安装文档](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/download_prebuilt_libraries.md)安装 FastDeploy Python SDK。
-
-本目录下分别提供 `seq_cls_infer.py` 快速完成在 CPU/GPU 的文本分类任务的 Python 部署示例。
-
-
-## 快速开始
-
-以下示例展示如何基于 FastDeploy 库完成 ERNIE-M 模型在 XNLI 数据集上进行自然语言推断任务的 Python 预测部署,可通过命令行参数`--device`以及`--backend`指定运行在不同的硬件以及推理引擎后端,并使用`--model_dir`参数指定运行的模型,具体参数设置可查看下面[参数说明](#参数说明)。示例中的模型是按照 [ERNIE-M 训练文档](../../README.md)导出得到的部署模型,其模型目录为`model_zoo/ernie-m/finetuned_models/export`(用户可按实际情况设置)。
-
-
-```bash
-
-# CPU 推理
-python seq_cls_infer.py --model_dir ../../finetuned_models/export/ --device cpu --backend paddle
-
-# GPU 推理
-python seq_cls_infer.py --model_dir ../../finetuned_models/export/model --device gpu --backend paddle
-
-```
-
-运行完成后返回的结果如下:
-
-```bash
-
-[INFO] fastdeploy/runtime/runtime.cc(309)::CreatePaddleBackend Runtime initialized with Backend::PDINFER in Device::GPU.
-Batch id:0, example id:0, sentence1:"他们告诉我,呃,我最后会被叫到一个人那里去见面。", sentence2:"我从来没有被告知任何与任何人会面。", label:contradiction, similarity:0.9975
-Batch id:1, example id:0, sentence1:"他们告诉我,呃,我最后会被叫到一个人那里去见面。", sentence2:"我被告知将有一个人被叫进来与我见面。", label:entailment, similarity:0.9866
-Batch id:2, example id:0, sentence1:"他们告诉我,呃,我最后会被叫到一个人那里去见面。", sentence2:"那个人来得有点晚。", label:neutral, similarity:0.9921
-
-```
-
-## 参数说明
-
-| 参数 |参数说明 |
-|----------|--------------|
-|--model_dir | 指定部署模型的目录, |
-|--batch_size |输入的batch size,默认为 1|
-|--max_length |最大序列长度,默认为 128|
-|--device | 运行的设备,可选范围: ['cpu', 'gpu'],默认为'cpu' |
-|--device_id | 运行设备的id。默认为0。 |
-|--cpu_threads | 当使用cpu推理时,指定推理的cpu线程数,默认为1。|
-|--backend | 支持的推理后端,可选范围: ['onnx_runtime', 'paddle', 'openvino', 'tensorrt', 'paddle_tensorrt'],默认为'paddle' |
-|--use_fp16 | 是否使用FP16模式进行推理。使用tensorrt和paddle_tensorrt后端时可开启,默认为False |
-
-## FastDeploy 高阶用法
-
-FastDeploy 在 Python 端上,提供 `fastdeploy.RuntimeOption.use_xxx()` 以及 `fastdeploy.RuntimeOption.use_xxx_backend()` 接口支持开发者选择不同的硬件、不同的推理引擎进行部署。在不同的硬件上部署 ERNIE-M 模型,需要选择硬件所支持的推理引擎进行部署,下表展示如何在不同的硬件上选择可用的推理引擎部署 ERNIE-M 模型。
-
-符号说明: (1) ✅: 已经支持; (2) ❔: 正在进行中; (3) N/A: 暂不支持;
-
-
-
-| 硬件 | -硬件对应的接口 | -可用的推理引擎 | -推理引擎对应的接口 | -是否支持 Paddle 新格式量化模型 | -是否支持 FP16 模式 | -
| CPU | -use_cpu() | -Paddle Inference | -use_paddle_infer_backend() | -✅ | -N/A | -
| ONNX Runtime | -use_ort_backend() | -✅ | -N/A | -||
| OpenVINO | -use_openvino_backend() | -❔ | -N/A | -||
| GPU | -use_gpu() | -Paddle Inference | -use_paddle_infer_backend() | -✅ | -N/A | -
| ONNX Runtime | -use_ort_backend() | -✅ | -❔ | -||
| Paddle TensorRT | -use_paddle_infer_backend() + paddle_infer_option.enable_trt = True | -✅ | -✅ | -||
| TensorRT | -use_trt_backend() | -✅ | -✅ | -||
| 昆仑芯 XPU | -use_kunlunxin() | -Paddle Lite | -use_paddle_lite_backend() | -N/A | -✅ | -
| 华为 昇腾 | -use_ascend() | -Paddle Lite | -use_paddle_lite_backend() | -❔ | -✅ | -
| Graphcore IPU | -use_ipu() | -Paddle Inference | -use_paddle_infer_backend() | -❔ | -N/A | -
| batch size | -K | -FastGeneration1卡FP16 | -FastGeneration4卡FP16 | -多卡并行SpeedUp | -
| 1 | -1 | -706.937 | -348.653 | -2.027 | -
| 1 | -10 | -707.514 | -348.699 | -2.029 | -
| 4 | -1 | -768.597 | -384.730 | -1.997 | -
| 4 | -10 | -770.008 | -385.244 | -1.998 | -
| 8 | -1 | -862.017 | -418.313 | -2.060 | -
| 8 | -10 | -866.490 | -418.965 | -2.068 | -
| 16 | -1 | -1016.362 | -486.974 | -2.087 | -
| 16 | -10 | -1060.472 | -488.156 | -2.172 | -
| 32 | -1 | -1325.700 | -606.770 | -2.184 | -
| 32 | -10 | -1326.222 | -608.479 | -2.179 | -