diff --git a/README.md b/README.md
index 82d115d06cb6..557209513a08 100644
--- a/README.md
+++ b/README.md
@@ -20,30 +20,75 @@
-**PaddleNLP**是一款**简单易用**且**功能强大**的自然语言处理和大语言模型(LLM)开发库。聚合业界**优质预训练模型**并提供**开箱即用**的开发体验,覆盖NLP多场景的模型库搭配**产业实践范例**可满足开发者**灵活定制**的需求。
+**PaddleNLP**是一款基于飞桨深度学习框架的大语言模型(LLM)开发套件,支持在多种硬件上进行高效的大模型训练、无损压缩以及高性能推理。PaddleNLP具备**简单易用**和**性能极致**的特点,致力于助力开发者实现高效的大模型产业级应用。
## News 📢
-* **2024.04.24 [PaddleNLP v2.8](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.8.0)**:自研极致收敛的RsLoRA+算法,大幅提升PEFT训练收敛速度以及训练效果;引入高性能生成加速到RLHF PPO算法,打破 PPO 训练中生成速度瓶颈,PPO训练性能大幅领先。通用化支持 FastFNN、FusedQKV等多个大模型训练性能优化方式,大模型训练更快、更稳定。
+* **2024.06.27 [PaddleNLP v3.0 Beta](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v3.0.0)**:拥抱大模型,体验全升级。统一大模型工具链,实现国产计算芯片全流程接入;全面支持飞桨4D并行配置、高效精调策略、高效对齐算法、高性能推理等大模型产业级应用流程;自研极致收敛的RsLoRA+算法、自动扩缩容存储机制Unified Checkpoint和通用化支持FastFFN、FusedQKV助力大模型训推;主流模型持续支持更新,提供高效解决方案。
+
+* **2024.04.24 [PaddleNLP v2.8](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.8.0)**:自研极致收敛的RsLoRA+算法,大幅提升PEFT训练收敛速度以及训练效果;引入高性能生成加速到RLHF PPO算法,打破 PPO 训练中生成速度瓶颈,PPO训练性能大幅领先。通用化支持 FastFFN、FusedQKV等多个大模型训练性能优化方式,大模型训练更快、更稳定。
+
+* **2024.01.04 [PaddleNLP v2.7](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.7.1)**: 大模型体验全面升级,统一工具链大模型入口。统一预训练、精调、压缩、推理以及部署等环节的实现代码,到 `PaddleNLP/llm`目录。全新[大模型工具链文档](https://paddlenlp.readthedocs.io/zh/latest/llm/finetune.html),一站式指引用户从大模型入门到业务部署上线。自动扩缩容存储机制 Unified Checkpoint,大大提高大模型存储的通用性。高效微调升级,支持了高效微调+LoRA同时使用,支持了QLoRA等算法。
+
+* **2023.08.15 [PaddleNLP v2.6](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.6.0)**: 发布[全流程大模型工具链](./llm),涵盖预训练,精调,压缩,推理以及部署等各个环节,为用户提供端到端的大模型方案和一站式的开发体验;内置[4D并行分布式Trainer](./docs/trainer.md),[高效微调算法LoRA/Prefix Tuning](./llm#33-lora), [自研INT8/INT4量化算法](./llm#6-量化)等等;全面支持[LLaMA 1/2](./llm/llama), [BLOOM](.llm/bloom), [ChatGLM 1/2](./llm/chatglm), [GLM](./llm/glm), [OPT](./llm/opt)等主流大模型
+
+
+## 特性
+
+
+

+
PaddleNLP预训练模型适用任务汇总(点击展开详情)
-
-| Model | Sequence Classification | Token Classification | Question Answering | Text Generation | Multiple Choice |
-|:-------------------|-------------------------|----------------------|--------------------|-----------------|-----------------|
-| ALBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
-| BERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
-| BlenderBot | ❌ | ❌ | ❌ | ✅ | ❌ |
-| ChineseBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ConvBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| CTRL | ✅ | ❌ | ❌ | ❌ | ❌ |
-| DistilBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ELECTRA | ✅ | ✅ | ✅ | ❌ | ✅ |
-| ERNIE | ✅ | ✅ | ✅ | ❌ | ✅ |
-| ERNIE-CTM | ❌ | ✅ | ❌ | ❌ | ❌ |
-| ERNIE-Doc | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ERNIE-GEN | ❌ | ❌ | ❌ | ✅ | ❌ |
-| ERNIE-Gram | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ERNIE-M | ✅ | ✅ | ✅ | ❌ | ❌ |
-| FNet | ✅ | ✅ | ✅ | ❌ | ✅ |
-| Funnel-Transformer | ✅ | ✅ | ✅ | ❌ | ❌ |
-| GPT | ✅ | ✅ | ❌ | ✅ | ❌ |
-| LayoutLM | ✅ | ✅ | ❌ | ❌ | ❌ |
-| LayoutLMv2 | ❌ | ✅ | ❌ | ❌ | ❌ |
-| LayoutXLM | ❌ | ✅ | ❌ | ❌ | ❌ |
-| LUKE | ❌ | ✅ | ✅ | ❌ | ❌ |
-| mBART | ✅ | ❌ | ✅ | ❌ | ✅ |
-| MegatronBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| MobileBERT | ✅ | ❌ | ✅ | ❌ | ❌ |
-| MPNet | ✅ | ✅ | ✅ | ❌ | ✅ |
-| NEZHA | ✅ | ✅ | ✅ | ❌ | ✅ |
-| PP-MiniLM | ✅ | ❌ | ❌ | ❌ | ❌ |
-| ProphetNet | ❌ | ❌ | ❌ | ✅ | ❌ |
-| Reformer | ✅ | ❌ | ✅ | ❌ | ❌ |
-| RemBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| RoBERTa | ✅ | ✅ | ✅ | ❌ | ✅ |
-| RoFormer | ✅ | ✅ | ✅ | ❌ | ❌ |
-| SKEP | ✅ | ✅ | ❌ | ❌ | ❌ |
-| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| T5 | ❌ | ❌ | ❌ | ✅ | ❌ |
-| TinyBERT | ✅ | ❌ | ❌ | ❌ | ❌ |
-| UnifiedTransformer | ❌ | ❌ | ❌ | ✅ | ❌ |
-| XLNet | ✅ | ✅ | ✅ | ❌ | ✅ |
-
-
-
-
-

-
-

-
-

-
-

-
-

-
+
+

+
+
+
------------------------------------------------------------------------------------------
@@ -17,262 +18,131 @@
 -
- Features | Installation | Quick Start | API Reference | Community
-
-**PaddleNLP** is a NLP library that is both **easy to use** and **powerful**. It aggregates high-quality pretrained models in the industry and provides a **plug-and-play** development experience, covering a model library for various NLP scenarios. With practical examples from industry practices, PaddleNLP can meet the needs of developers who require **flexible customization**.
-
-## News 📢
-
-* **2024.01.04 [PaddleNLP v2.7](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.7.0)**: The LLM experience is fully upgraded, and the tool chain LLM entrance is unified. Unify the implementation code of pre-training, fine-tuning, compression, inference and deployment to the `PaddleNLP/llm` directory. The new [LLM Toolchain Documentation](https://paddlenlp.readthedocs.io/zh/latest/llm/finetune.html) provides one-stop guidance for users from getting started with LLM to business deployment and launch. The full breakpoint storage mechanism Unified Checkpoint greatly improves the versatility of LLM storage. Efficient fine-tuning upgrade supports the simultaneous use of efficient fine-tuning + LoRA, and supports QLoRA and other algorithms.
-
-* **2023.08.15 [PaddleNLP v2.6](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.6.0)**: Release [Full-process LLM toolchain](./llm) , covering all aspects of pre-training, fine-tuning, compression, inference and deployment, providing users with end-to-end LLM solutions and one-stop development experience; built-in [4D parallel distributed Trainer](./docs/trainer.md ), [Efficient fine-tuning algorithm LoRA/Prefix Tuning](./llm/README.md#2-%E7%B2%BE%E8%B0%83), [Self-developed INT8/INT4 quantization algorithm](./llm/README.md#4-%E9%87%8F%E5%8C%96), etc.; fully supports [LLaMA 1/2](./llm/config/llama), [BLOOM](./llm/config/bloom), [ChatGLM 1/2](./llm/config/chatglm), [OPT](./llm/config/opt) and other mainstream LLMs.
-
-## Installation
-### Prerequisites
+
-* python >= 3.7
-* paddlepaddle >= 2.6.0
+**PaddleNLP** is a Large Language Model (LLM) development suite based on the PaddlePaddle deep learning framework, supporting efficient large model training, lossless compression, and high-performance inference on various hardware devices. With its **simplicity** and **ultimate performance**, PaddleNLP is dedicated to helping developers achieve efficient industrial applications of large models.
-More information about PaddlePaddle installation please refer to [PaddlePaddle's Website](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/conda/linux-conda.html).
-
-### Python pip Installation
+## News 📢
-```
-pip install --upgrade paddlenlp
-```
+* **2024.06.27 [PaddleNLP v3.0 Beta](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v3.0.0)**:Embrace large models and experience a complete upgrade. With a unified large model toolchain, we achieve full-process access to domestically produced computing chips. We fully support industrial-level application processes for large models, such as PaddlePaddle's 4D parallel configuration, efficient fine-tuning strategies, efficient alignment algorithms, and high-performance reasoning. Our developed RsLoRA+ algorithm, full checkpoint storage mechanism Unified Checkpoint, and generalized support for FastFNN and FusedQKV all contribute to the training and inference of large models. We continuously support updates to mainstream models for providing efficient solutions.
-or you can install the latest develop branch code with the following command:
+* **2024.04.24 [PaddleNLP v2.8](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.8.0)**:Our self-developed RsLoRA+ algorithm with extreme convergence significantly improves the convergence speed and training effectiveness of PEFT training. By introducing high-performance generation acceleration into the RLHF PPO algorithm, we have broken through the generation speed bottleneck in PPO training, achieving a significant lead in PPO training performance. We generally support multiple large model training performance optimization methods such as FastFFN and FusedQKV, making large model training faster and more stable.
-```shell
-pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.html
-```
+* **2024.01.04 [PaddleNLP v2.7](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.7.0)**: The LLM experience is fully upgraded, and the tool chain LLM entrance is unified. Unify the implementation code of pre-training, fine-tuning, compression, inference and deployment to the `PaddleNLP/llm` directory. The new [LLM Toolchain Documentation](https://paddlenlp.readthedocs.io/zh/latest/llm/finetune.html) provides one-stop guidance for users from getting started with LLM to business deployment and launch. The full breakpoint storage mechanism Unified Checkpoint greatly improves the versatility of LLM storage. Efficient fine-tuning upgrade supports the simultaneous use of efficient fine-tuning + LoRA, and supports QLoRA and other algorithms.
+* **2023.08.15 [PaddleNLP v2.6](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.6.0)**: Release [Full-process LLM toolchain](./llm) , covering all aspects of pre-training, fine-tuning, compression, inference and deployment, providing users with end-to-end LLM solutions and one-stop development experience; built-in [4D parallel distributed Trainer](./docs/trainer.md ), [Efficient fine-tuning algorithm LoRA/Prefix Tuning](./llm/README.md#2-%E7%B2%BE%E8%B0%83), [Self-developed INT8/INT4 quantization algorithm](./llm/README.md#4-%E9%87%8F%E5%8C%96), etc.; fully supports [LLaMA 1/2](./llm/config/llama), [BLOOM](./llm/config/bloom), [ChatGLM 1/2](./llm/config/chatglm), [OPT](./llm/config/opt) and other mainstream LLMs.
## Features
-#### 📦 Out-of-Box NLP Toolset
-
-#### 🤗 Awesome Chinese Model Zoo
-
-#### 🎛️ Industrial End-to-end System
-
-#### 🚀 High Performance Distributed Training and Inference
-
-
-### Out-of-Box NLP Toolset
-
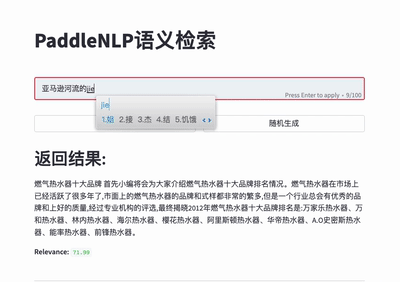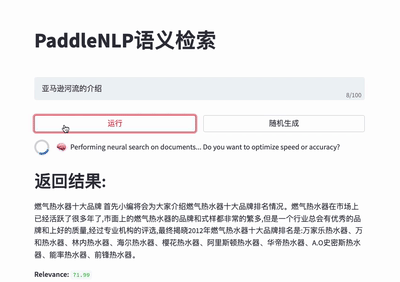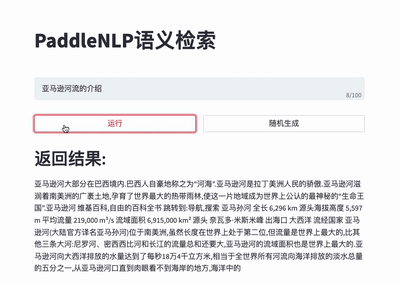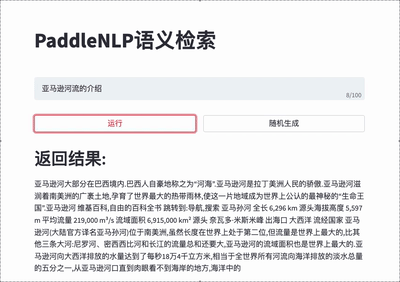
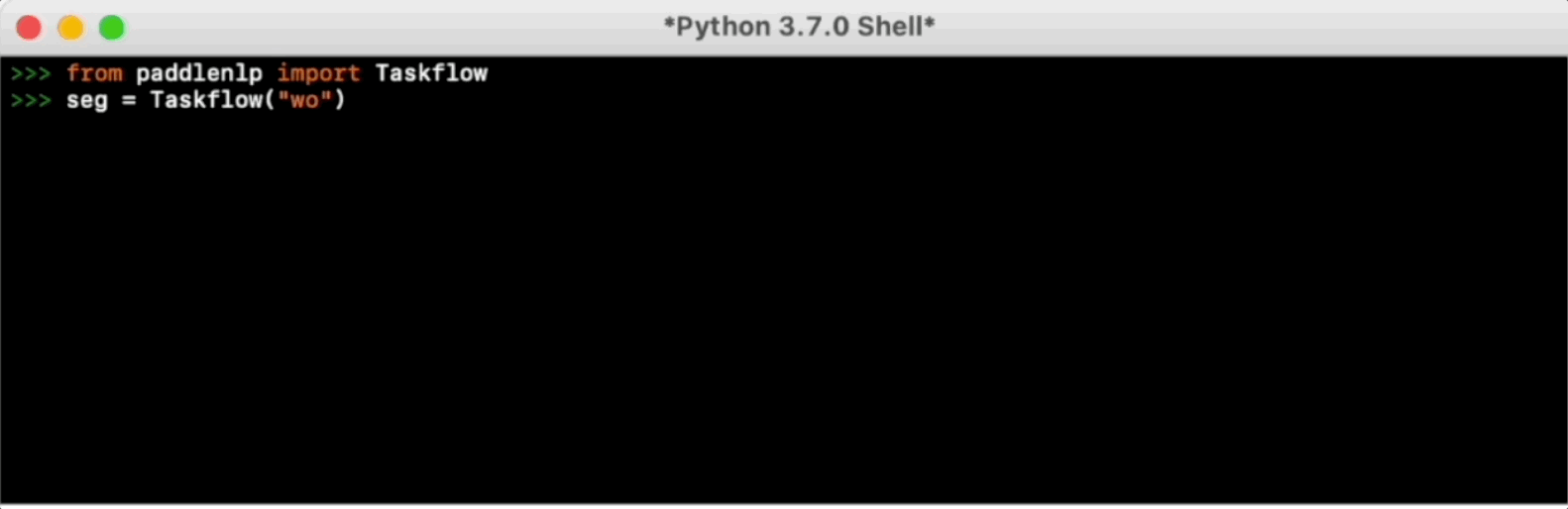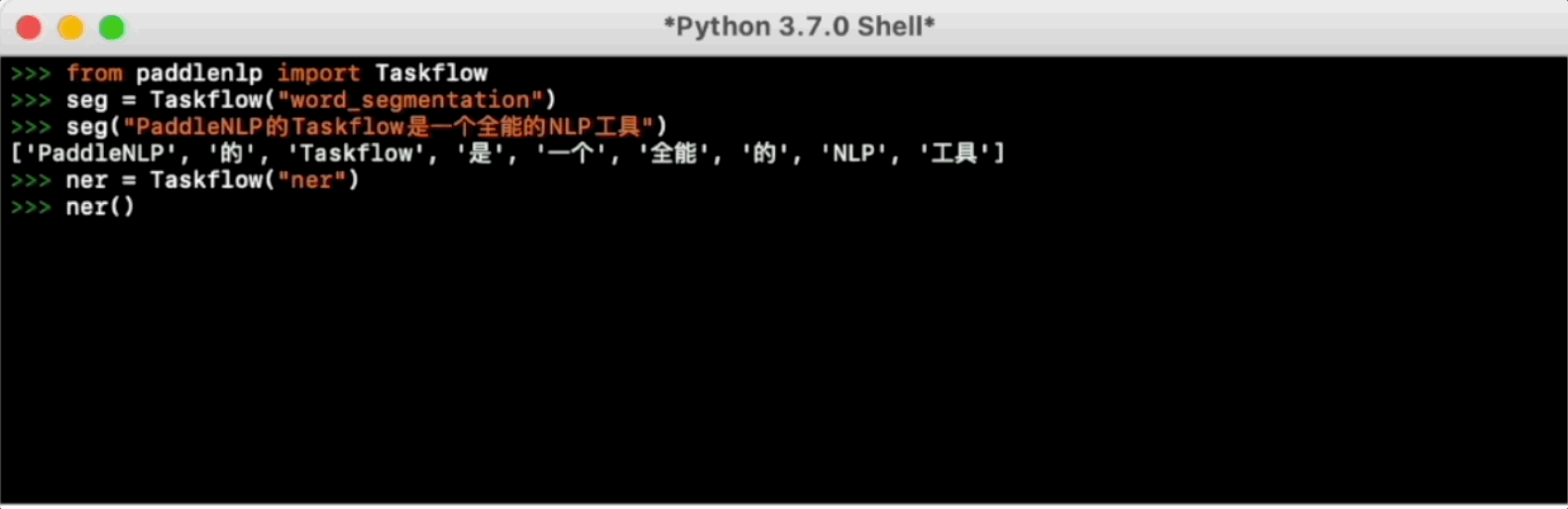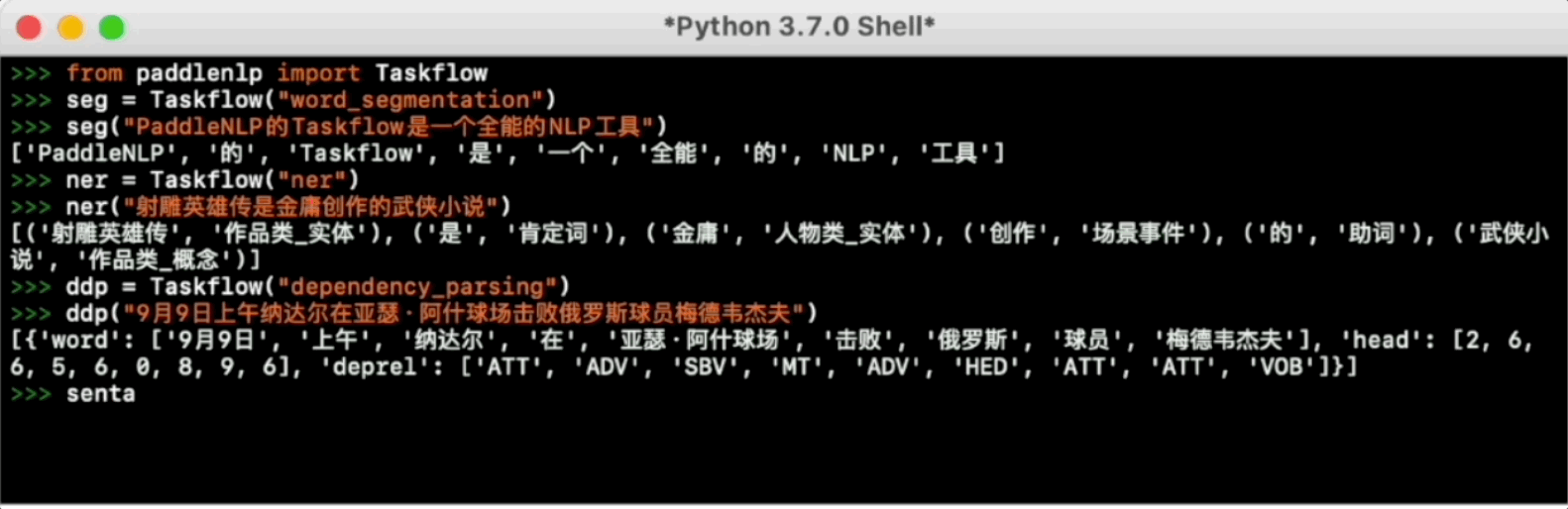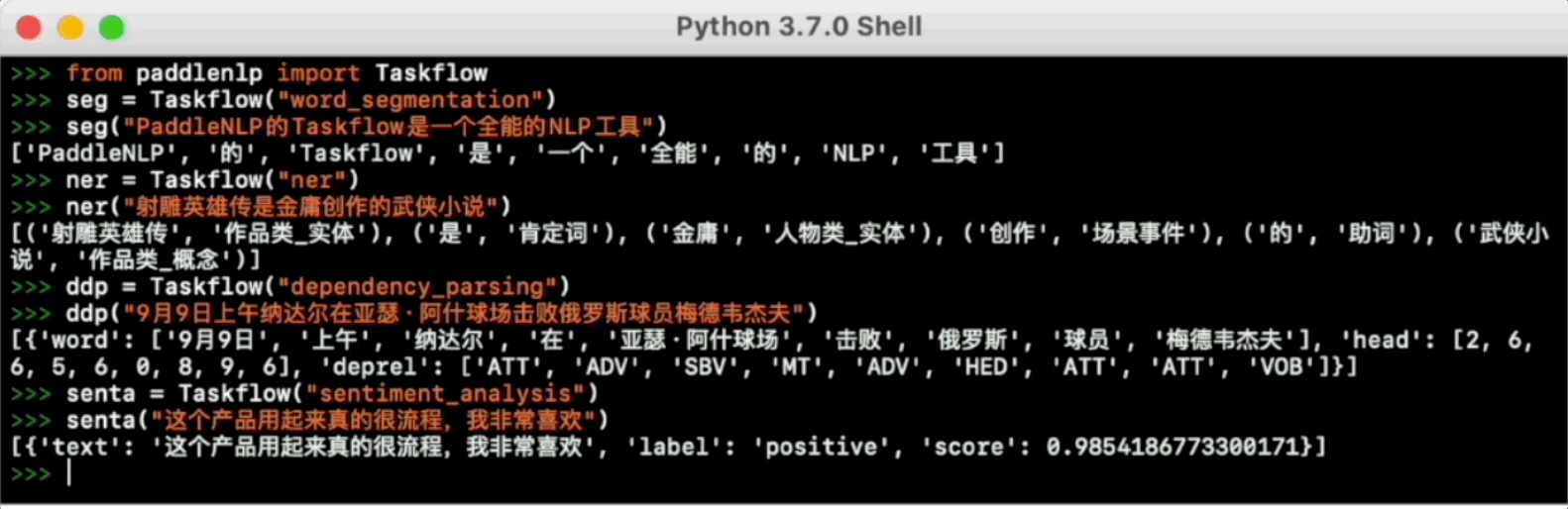
-Taskflow aims to provide off-the-shelf NLP pre-built task covering NLU and NLG technique, in the meanwhile with extremely fast inference satisfying industrial scenario.
-
-
-
-For more usage please refer to [Taskflow Docs](./docs/model_zoo/taskflow.md).
-
-### Awesome Chinese Model Zoo
-
-#### 🀄 Comprehensive Chinese Transformer Models
-
-We provide **45+** network architectures and over **500+** pretrained models. Not only includes all the SOTA model like ERNIE, PLATO and SKEP released by Baidu, but also integrates most of the high-quality Chinese pretrained model developed by other organizations. Use `AutoModel` API to **⚡SUPER FAST⚡** download pretrained models of different architecture. We welcome all developers to contribute your Transformer models to PaddleNLP!
-
-```python
-from paddlenlp.transformers import *
-
-ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
-bert = AutoModel.from_pretrained('bert-wwm-chinese')
-albert = AutoModel.from_pretrained('albert-chinese-tiny')
-roberta = AutoModel.from_pretrained('roberta-wwm-ext')
-electra = AutoModel.from_pretrained('chinese-electra-small')
-gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')
-```
-
-Due to the computation limitation, you can use the ERNIE-Tiny light models to accelerate the deployment of pretrained models.
-```python
-# 6L768H
-ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
-# 6L384H
-ernie = AutoModel.from_pretrained('ernie-3.0-mini-zh')
-# 4L384H
-ernie = AutoModel.from_pretrained('ernie-3.0-micro-zh')
-# 4L312H
-ernie = AutoModel.from_pretrained('ernie-3.0-nano-zh')
-```
-Unified API experience for NLP task like semantic representation, text classification, sentence matching, sequence labeling, question answering, etc.
-
-```python
-import paddle
-from paddlenlp.transformers import *
-
-tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
-text = tokenizer('natural language processing')
-
-# Semantic Representation
-model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
-sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
-# Text Classificaiton and Matching
-model = AutoModelForSequenceClassification.from_pretrained('ernie-3.0-medium-zh')
-# Sequence Labeling
-model = AutoModelForTokenClassification.from_pretrained('ernie-3.0-medium-zh')
-# Question Answering
-model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')
-```
-
-#### Wide-range NLP Task Support
-
-PaddleNLP provides rich examples covering mainstream NLP task to help developers accelerate problem solving. You can find our powerful transformer [Model Zoo](./legacy/model_zoo), and wide-range NLP application [examples](./legacy/examples) with detailed instructions.
-
-Also you can run our interactive [Notebook tutorial](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995) on AI Studio, a powerful platform with **FREE** computing resource.
-
- PaddleNLP Transformer model summary (click to show details)
-
-| Model | Sequence Classification | Token Classification | Question Answering | Text Generation | Multiple Choice |
-| :----------------- | ----------------------- | -------------------- | ------------------ | --------------- | --------------- |
-| ALBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
-| BERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
-| BlenderBot | ❌ | ❌ | ❌ | ✅ | ❌ |
-| ChineseBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ConvBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| CTRL | ✅ | ❌ | ❌ | ❌ | ❌ |
-| DistilBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ELECTRA | ✅ | ✅ | ✅ | ❌ | ✅ |
-| ERNIE | ✅ | ✅ | ✅ | ❌ | ✅ |
-| ERNIE-CTM | ❌ | ✅ | ❌ | ❌ | ❌ |
-| ERNIE-Doc | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ERNIE-GEN | ❌ | ❌ | ❌ | ✅ | ❌ |
-| ERNIE-Gram | ✅ | ✅ | ✅ | ❌ | ❌ |
-| ERNIE-M | ✅ | ✅ | ✅ | ❌ | ❌ |
-| FNet | ✅ | ✅ | ✅ | ❌ | ✅ |
-| Funnel-Transformer | ✅ | ✅ | ✅ | ❌ | ❌ |
-| GPT | ✅ | ✅ | ❌ | ✅ | ❌ |
-| LayoutLM | ✅ | ✅ | ❌ | ❌ | ❌ |
-| LayoutLMv2 | ❌ | ✅ | ❌ | ❌ | ❌ |
-| LayoutXLM | ❌ | ✅ | ❌ | ❌ | ❌ |
-| LUKE | ❌ | ✅ | ✅ | ❌ | ❌ |
-| mBART | ✅ | ❌ | ✅ | ❌ | ✅ |
-| MegatronBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| MobileBERT | ✅ | ❌ | ✅ | ❌ | ❌ |
-| MPNet | ✅ | ✅ | ✅ | ❌ | ✅ |
-| NEZHA | ✅ | ✅ | ✅ | ❌ | ✅ |
-| PP-MiniLM | ✅ | ❌ | ❌ | ❌ | ❌ |
-| ProphetNet | ❌ | ❌ | ❌ | ✅ | ❌ |
-| Reformer | ✅ | ❌ | ✅ | ❌ | ❌ |
-| RemBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
-| RoBERTa | ✅ | ✅ | ✅ | ❌ | ✅ |
-| RoFormer | ✅ | ✅ | ✅ | ❌ | ❌ |
-| SKEP | ✅ | ✅ | ❌ | ❌ | ❌ |
-| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| T5 | ❌ | ❌ | ❌ | ✅ | ❌ |
-| TinyBERT | ✅ | ❌ | ❌ | ❌ | ❌ |
-| UnifiedTransformer | ❌ | ❌ | ❌ | ✅ | ❌ |
-| XLNet | ✅ | ✅ | ✅ | ❌ | ✅ |
-
-
-
+

-
-
-
-
-

-
-
-
-
+