![]()



VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。
VisualDL提供丰富的可视化功能,支持标量、图结构、数据样本(图像、语音、文本)、超参数可视化、直方图、PR曲线、ROC曲线及高维数据降维呈现等诸多功能,同时VisualDL提供可视化结果保存服务,通过VDL.service生成链接,保存并分享可视化结果。具体功能使用方式,请参见 VisualDL使用指南。如欲体验最新特性,欢迎试用我们的在线演示系统。项目正处于高速迭代中,敬请期待新组件的加入。
VisualDL支持浏览器:
- Google Chrome ≥ 79
- Firefox ≥ 67
- Microsoft Edge ≥ 79
- Safari ≥ 11.1
VisualDL原生支持Python的使用, 通过在模型的Python配置中添加几行代码,便可为训练过程提供丰富的可视化支持。
API设计简洁易懂,使用简单。模型结构一键实现可视化。
功能覆盖标量、数据样本、图结构、直方图、PR曲线及数据降维可视化。
全面支持Paddle、ONNX、Caffe等市面主流模型结构可视化,广泛支持各类用户进行可视化分析。
与飞桨服务平台及工具组件全面打通,为您在飞桨生态系统中提供最佳使用体验。
python -m pip install visualdl -i https://mirror.baidu.com/pypi/simplegit clone https://github.com/PaddlePaddle/VisualDL.git
cd VisualDL
python setup.py bdist_wheel
pip install --upgrade dist/visualdl-*.whl
需要注意,官方自2020年1月1日起不再维护Python2,为了保障代码可用性,VisualDL现仅支持Python3
VisualDL将训练过程中的数据、参数等信息储存至日志文件中后,启动面板即可查看可视化结果。
VisualDL的后端提供了Python SDK,可通过LogWriter定制一个日志记录器,接口如下:
class LogWriter(logdir=None,
max_queue=10,
flush_secs=120,
filename_suffix='',
display_name='',
file_name='',
**kwargs)| 参数 | 格式 | 含义 |
|---|---|---|
| logdir | string | 日志文件所在的路径,VisualDL将在此路径下建立日志文件并进行记录,如果不填则默认为runs/${CURRENT_TIME} |
| max_queue | int | 日志记录消息队列的最大容量,达到此容量则立即写入到日志文件 |
| flush_secs | int | 日志记录消息队列的最大缓存时间,达到此时间则立即写入到日志文件(日志消息队列到达最大缓存时间或最大容量,都会立即写入日志文件) |
| filename_suffix | string | 为默认的日志文件名添加后缀 |
| display_name | string | 指定面板启动后显示的路径,如不指定此项则显示日志所在的实际路径,当日志所在路径过长或想隐藏日志所在路径时可指定此参数 |
| file_name | string | 指定写入的日志文件名,如果指定的文件名已经存在,则将日志续写在此文件中,因此可通过此参数实现日志续写的功能,文件名必须包括vdlrecords |


设置日志文件并记录标量数据:
from visualdl import LogWriter
# 在`./log/scalar_test/train`路径下建立日志文件
with LogWriter(logdir="./log/scalar_test/train") as writer:
# 使用scalar组件记录一个标量数据,将要记录的所有数据都记录在该writer中
writer.add_scalar(tag="acc", step=1, value=0.5678)
writer.add_scalar(tag="acc", step=2, value=0.6878)
writer.add_scalar(tag="acc", step=3, value=0.9878)
# 如果不想使用上下文管理器`with`,可拆解为以下几步完成:
"""
writer = LogWriter(logdir="./log/scalar_test/train")
writer.add_scalar(tag="acc", step=1, value=0.5678)
writer.add_scalar(tag="acc", step=2, value=0.6878)
writer.add_scalar(tag="acc", step=3, value=0.9878)
writer.close()
"""注:调用LogWriter(logdir="./log/scalar_test/train")将会在./log/scalar_test/train目录下生成一个日志文件, 运行一次程序所产生的训练数据应该只记录到一个日志文件中,因此应该只调用一次LogWriter,用返回的LogWriter对象来记录所有数据, 而不是每记录一个数据就创建一次LogWriter。
如下是错误示范:
from visualdl import LogWriter
with LogWriter(logdir="./log/scalar_test/train") as writer: # 将会创建日志文件vdlrecords.xxxx1.log
writer.add_scalar(tag="acc", step=1, value=0.5678) # 数据写入./log/scalar_test/train/vdlrecords.xxxx1.log
with LogWriter(logdir="./log/scalar_test/train") as writer: # 将会创建日志文件vdlrecords.xxxx2.log
writer.add_scalar(tag="acc", step=2, value=0.6878) # 数据将会写入./log/scalar_test/train/vdlrecords.xxxx2.log在上述示例中,日志已记录三组标量数据,现可启动VisualDL面板查看日志的可视化结果,共有两种启动方式:
使用命令行启动VisualDL面板,命令格式如下:
visualdl --logdir <dir_1, dir_2, ... , dir_n> --model <model_file> --host <host> --port <port> --cache-timeout <cache_timeout> --language <language> --public-path <public_path> --api-only --component_tabs <tab_name1, tab_name2, ...>参数详情:
| 参数 | 意义 |
|---|---|
| --logdir | 设定日志所在目录,可以指定多个目录,VisualDL将遍历并且迭代寻找指定目录的子目录,将所有实验结果进行可视化 |
| --model | 设定模型文件路径(非文件夹路径),VisualDL将在此路径指定的模型文件进行可视化,目前可支持PaddlePaddle、ONNX、Keras、Core ML、Caffe等多种模型结构,详情可查看graph支持模型种类 |
| --host | 设定IP,默认为127.0.0.1,若想使得本机以外的机器访问启动的VisualDL面板,需指定此项为0.0.0.0或自己的公网IP地址 |
| --port | 设定端口,默认为8040 |
| --cache-timeout | 后端缓存时间,在缓存时间内前端多次请求同一url,返回的数据从缓存中获取,默认为20秒 |
| --language | VisualDL面板语言,可指定为'en'或'zh',默认为浏览器使用语言 |
| --public-path | VisualDL面板URL路径,默认是'/app',即访问地址为'http://<host>:<port>/app' |
| --api-only | 是否只提供API,如果设置此参数,则VisualDL不提供页面展示,只提供API服务,此时API地址为'http://<host>:<port>/<public_path>/api';若没有设置public_path参数,则默认为'http://<host>:<port>/api' |
| --component_tabs | 设定需要显示的组件,当前支持'scalar', 'image', 'text', 'embeddings', 'audio', 'histogram', 'hyper_parameters', 'static_graph', 'dynamic_graph', 'pr_curve', 'roc_curve', 'profiler', 'x2paddle', 'fastdeploy_server', 'fastdeploy_client'共15个组件。如果设置了此参数,将只展示所指定的组件。如果没有设置此参数,当指定了--logdir参数时候,将会根据日志文件中拥有的数据类型来自动显示相应的组件。当没有指定--logdir参数,默认显示'static_graph', 'x2paddle', 'fastdeploy_server', 'fastdeploy_client'这四个名称代表的组件 |
针对上一步生成的日志,启动命令为:
visualdl --logdir ./log
支持在Python脚本中启动VisualDL面板,接口如下:
visualdl.server.app.run(logdir,
model="path/to/model",
host="127.0.0.1",
port=8080,
cache_timeout=20,
language=None,
public_path=None,
api_only=False,
open_browser=False)请注意:除logdir外,其他参数均为不定参数,传递时请指明参数名。
接口参数具体如下:
| 参数 | 格式 | 含义 |
|---|---|---|
| logdir | string或list[string_1, string_2, ... , string_n] | 日志文件所在的路径,VisualDL将在此路径下递归搜索日志文件并进行可视化,可指定单个或多个路径,每个路径中及其子目录中的日志都将视为独立日志展现在前端面板上 |
| model | string | 模型文件路径(非文件夹路径),VisualDL将在此路径指定的模型文件进行可视化,目前可支持PaddlePaddle、ONNX、Keras、Core ML、Caffe等多种模型结构,详情可查看graph支持模型种类 |
| host | string | 设定IP,默认为127.0.0.1,若想使得本机以外的机器访问启动的VisualDL面板,需指定此项为0.0.0.0或自己的公网IP地址 |
| port | int | 启动服务端口,默认为8040 |
| cache_timeout | int | 后端缓存时间,在缓存时间内前端多次请求同一url,返回的数据从缓存中获取,默认为20秒 |
| language | string | VisualDL面板语言,可指定为'en'或'zh',默认为浏览器使用语言 |
| public_path | string | VisualDL面板URL路径,默认是'/app',即访问地址为'http://<host>:<port>/app' |
| api_only | boolean | 是否只提供API,如果设置此参数,则VisualDL不提供页面展示,只提供API服务,此时API地址为'http://<host>:<port>/<public_path>/api';若没有设置public_path参数,则默认为'http://<host>:<port>/api' |
| open_browser | boolean | 是否打开浏览器,设置为True则在启动后自动打开浏览器并访问VisualDL面板,若设置api_only,则忽略此参数 |
| --component_tabs | string或list[string_1, string_2, ... , string_n] | 设定需要显示的组件,当前支持'scalar', 'image', 'text', 'embeddings', 'audio', 'histogram', 'hyper_parameters', 'static_graph', 'dynamic_graph', 'pr_curve', 'roc_curve', 'profiler', 'x2paddle', 'fastdeploy_server', 'fastdeploy_client'共15个组件。如果设置了此参数,将只展示所指定的组件。如果没有设置此参数,当指定了--logdir参数时候,将会根据日志文件中拥有的数据类型来自动显示相应的组件。当没有指定--logdir参数,默认显示'static_graph', 'x2paddle', 'fastdeploy_server', 'fastdeploy_client'这四个名称代表的组件 |
针对上一步生成的日志,我们的启动脚本为:
from visualdl.server import app
app.run(logdir="./log")在使用任意一种方式启动VisualDL面板后,打开浏览器访问VisualDL面板,即可查看日志的可视化结果,如图:

VisualDL的后端也提供了获取日志数据的组件LogReader,可通过其获取日志中任意数据,接口如下:
class LogReader(file_path='')| 参数 | 格式 | 含义 |
|---|---|---|
| file_path | string | 指定要读的日志文件路径,必填,注意这里与file_name不同,需填写具体路径 |
假定在./log文件夹下有一个日志文件vdlrecords.1605533348.log,则获取LogReader实例如下:
from visualdl import LogReader
reader = LogReader(file_path='./log/vdlrecords.1605533348.log')
data = reader.get_data('scalar', 'loss')
print(data)结果为列表形式,如下
...
id: 5
tag: "Metrics/Training(Step): loss"
timestamp: 1605533356039
value: 3.1297709941864014
...关于LogReader的更多具体用法,可参考LogReader。
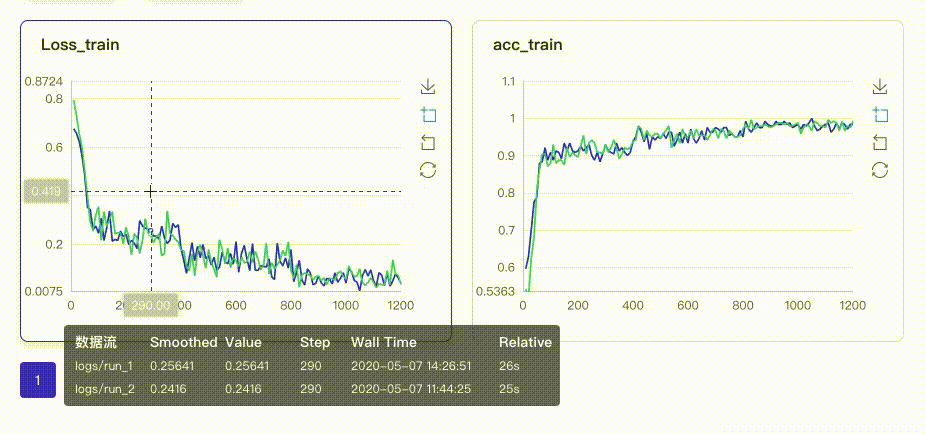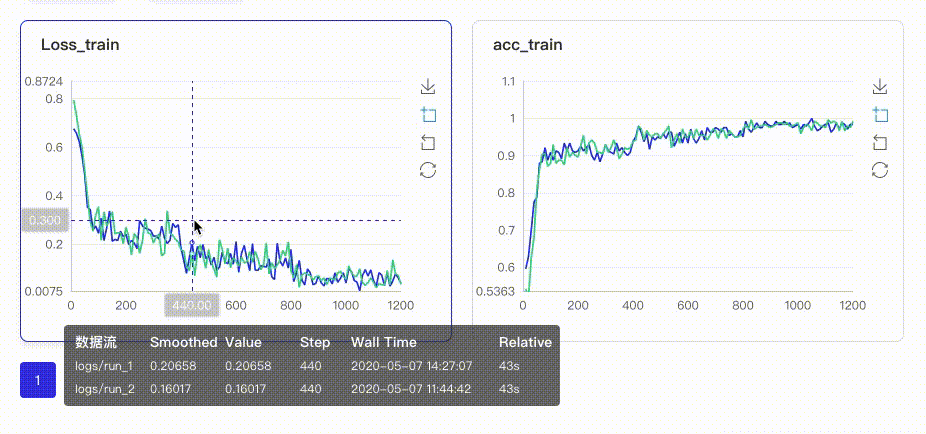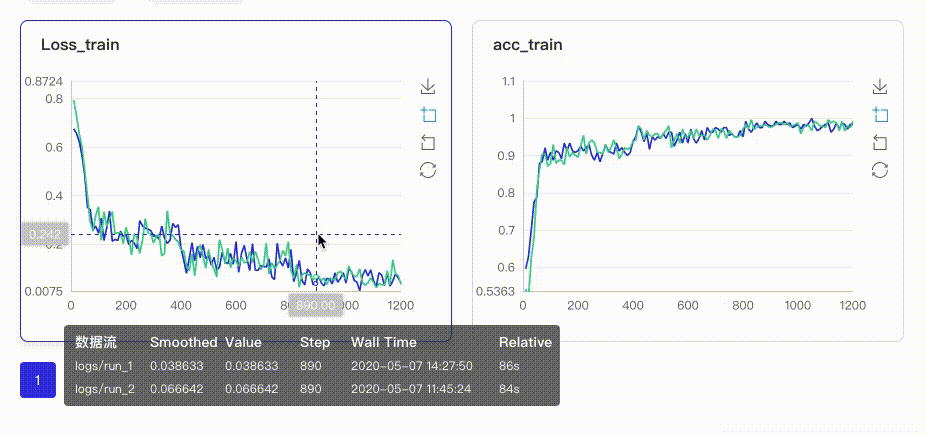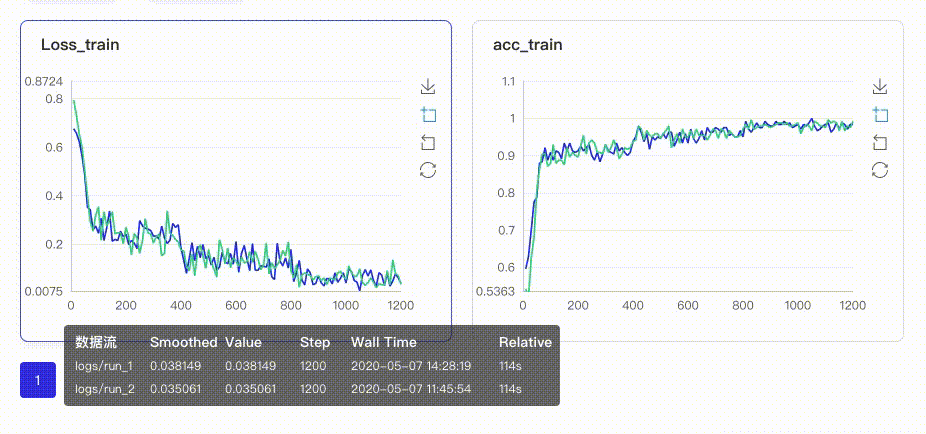
以图表形式实时展示训练过程参数,如loss、accuracy。让用户通过观察单组或多组训练参数变化,了解训练过程,加速模型调优。具有两大特点:
在启动VisualDL Board后,LogReader将不断增量的读取日志中数据并供前端调用展示,因此能够在训练中同步观测指标变化,如下图:
只需在启动VisualDL Board的时将每个实验日志所在路径同时传入即可,每个实验中相同tag的指标将绘制在一张图中同步呈现,如下图:
实时展示训练过程中的图像数据,用于观察不同训练阶段的图像变化,进而深入了解训练过程及效果。

实时查看训练过程中的音频数据,监控语音识别与合成等任务的训练过程。
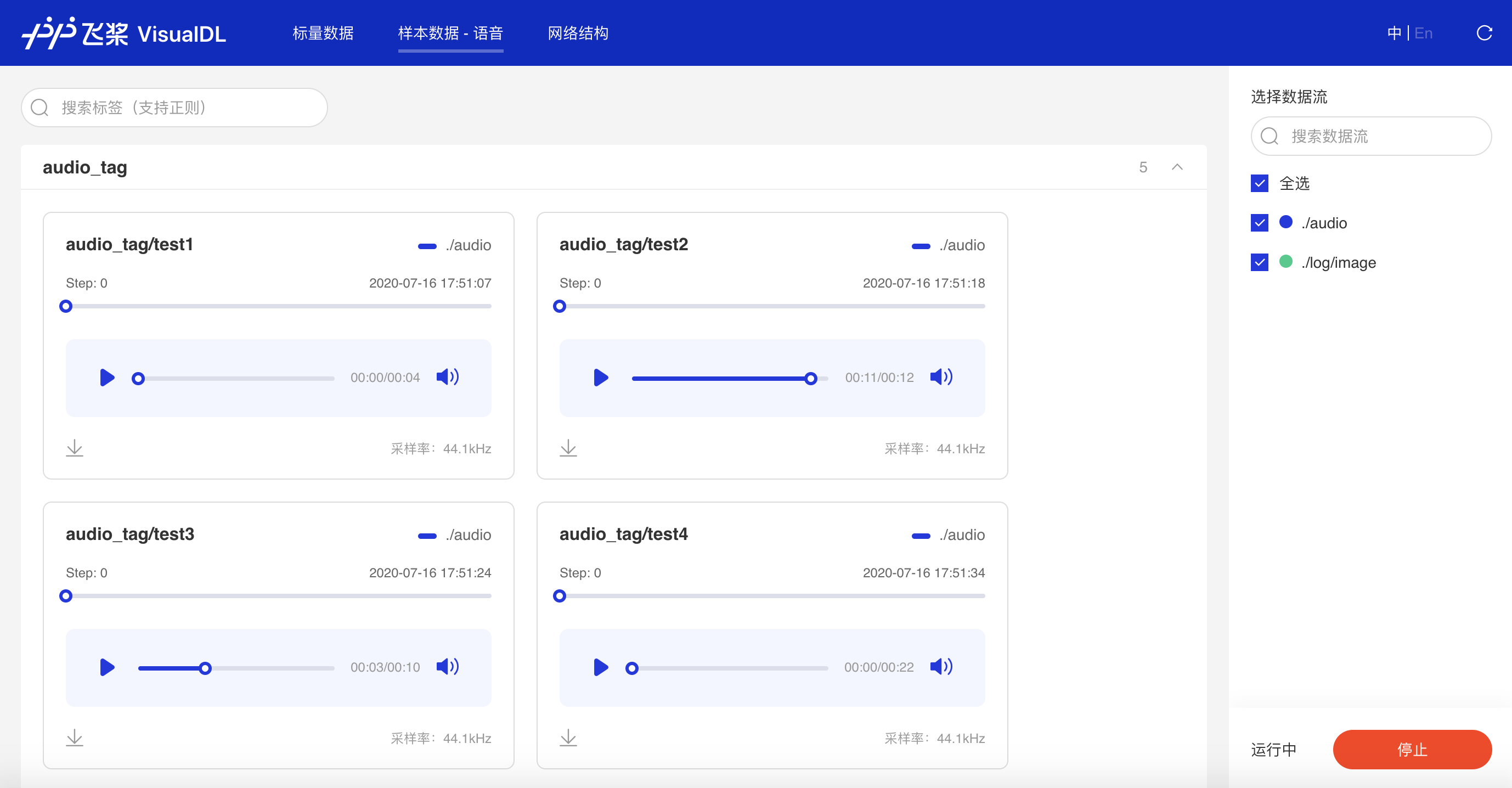
展示文本任务任意阶段的数据输出,对比不同阶段的文本变化,便于深入了解训练过程及效果。

一键可视化模型的网络结构。可查看模型属性、节点信息、节点输入输出等,并支持节点搜索,辅助用户快速分析模型结构与了解数据流向,覆盖动态图与静态图两种格式。
- 动态图

- 静态图

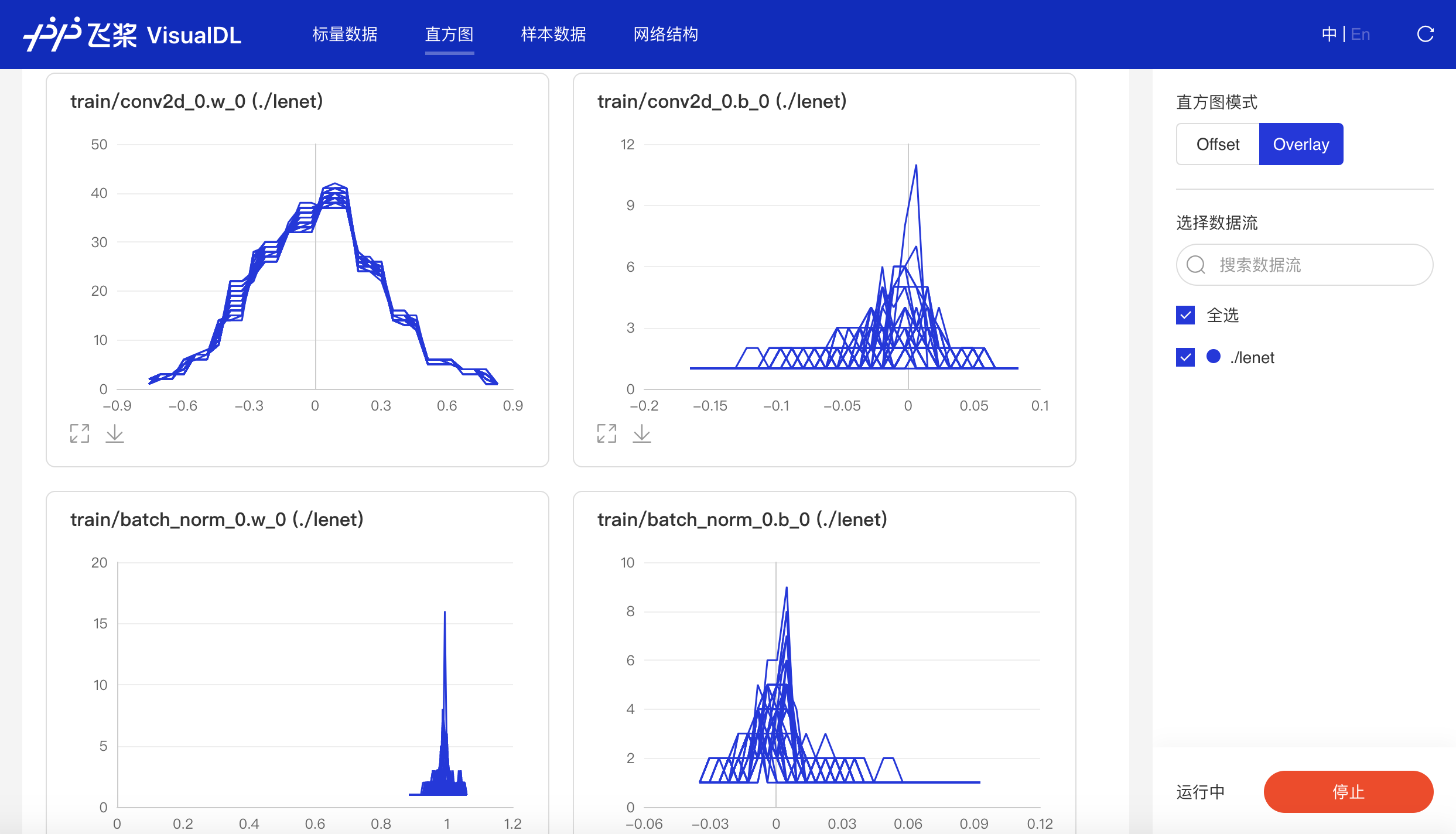
以直方图形式展示Tensor(weight、bias、gradient等)数据在训练过程中的变化趋势。深入了解模型各层效果,帮助开发者精准调整模型结构。
- Offset模式

- Overlay模式
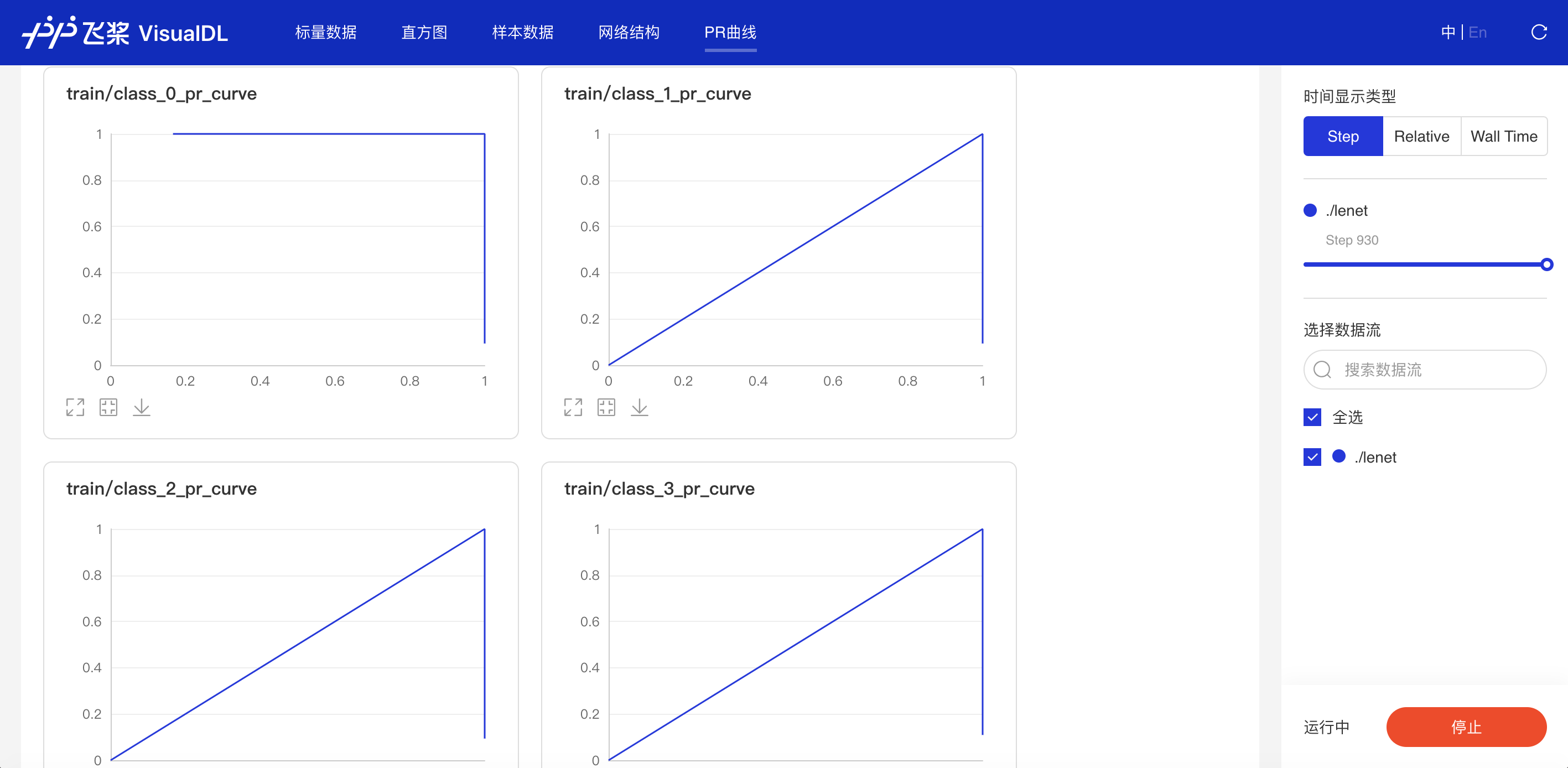
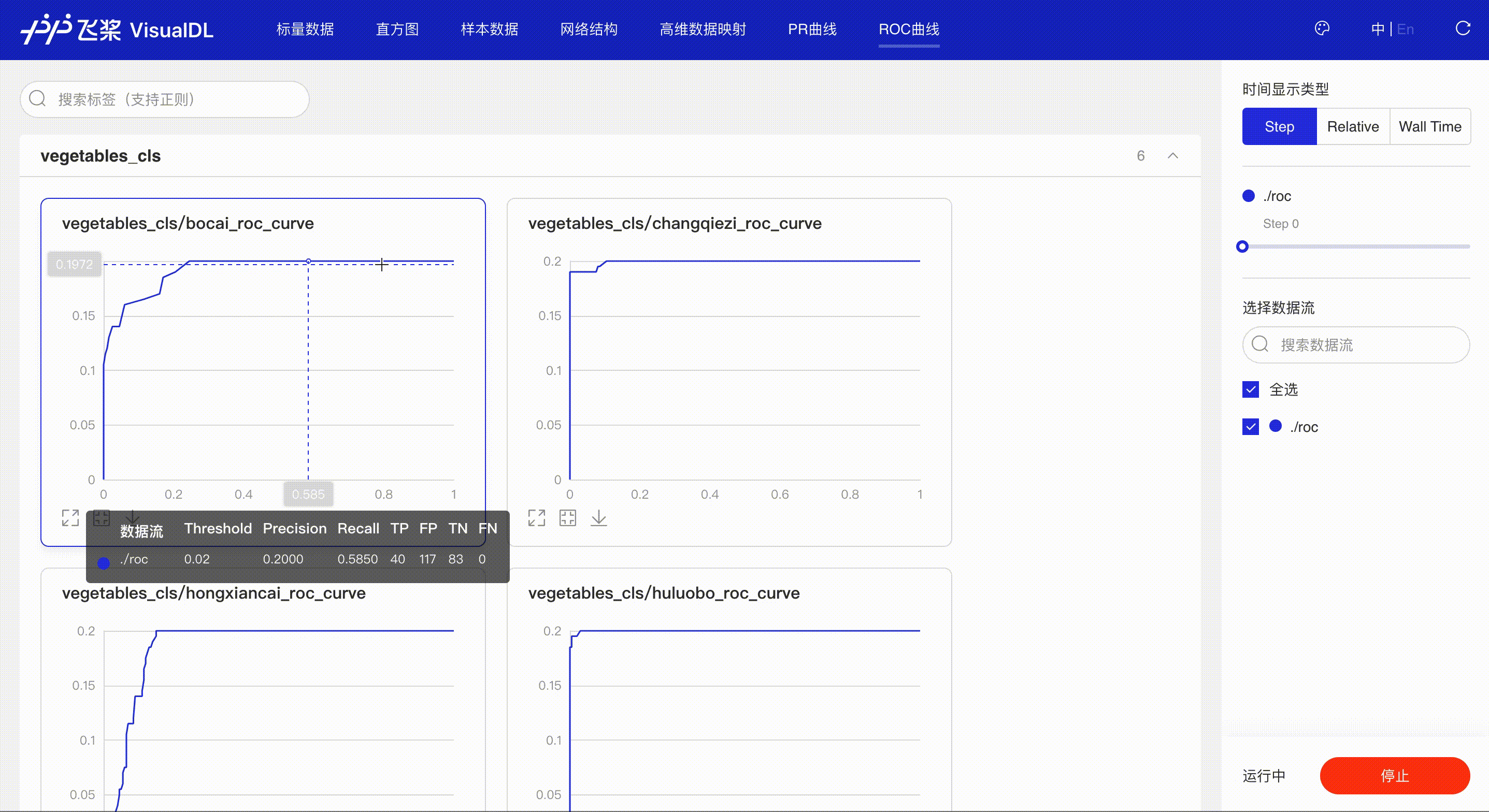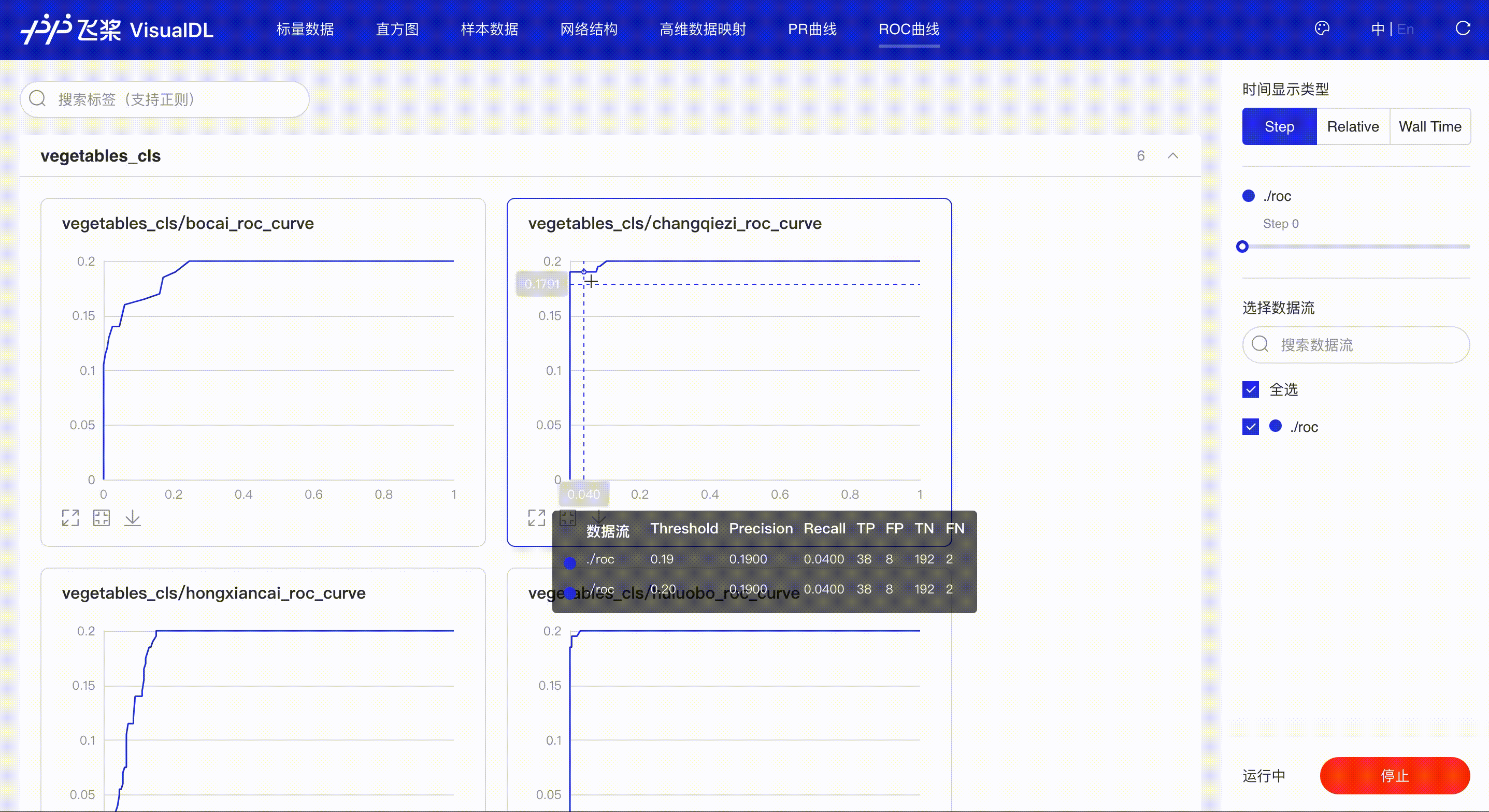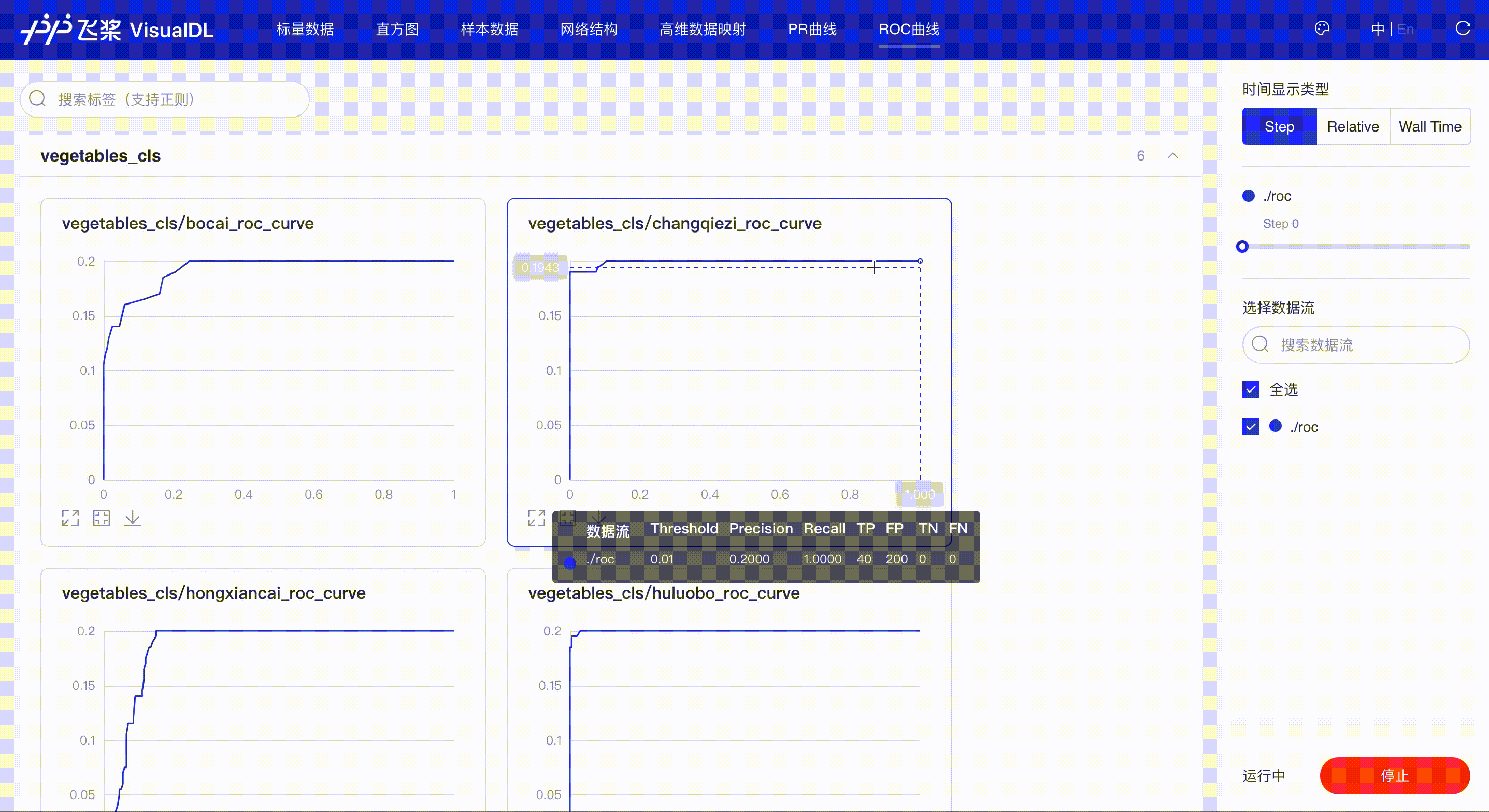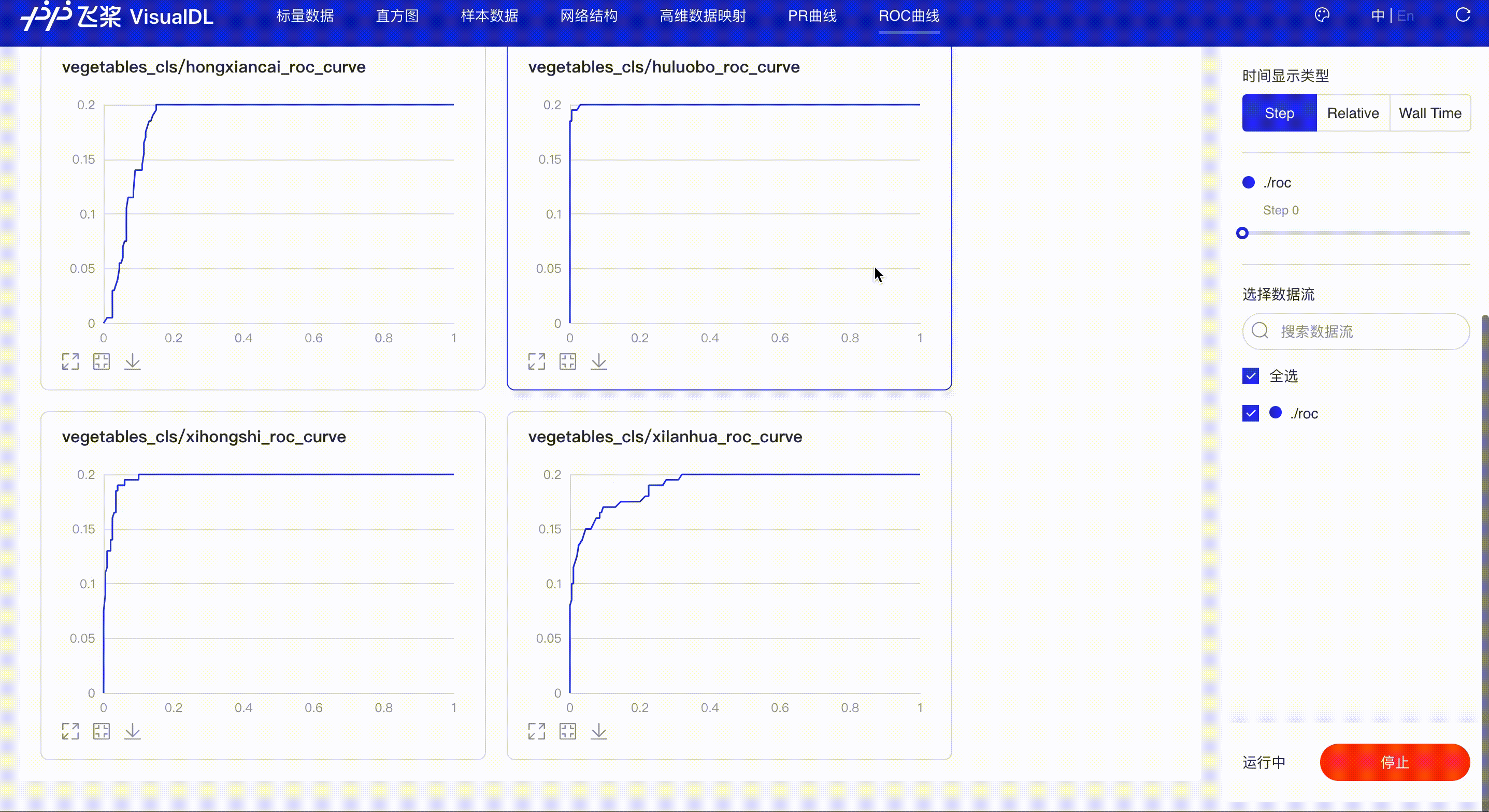
精度-召回率曲线,帮助开发者权衡模型精度和召回率之间的平衡,设定最佳阈值。
展示不同阈值下模型指标的变化,同时曲线下的面积(AUC)直观的反应模型表现,辅助开发者掌握模型训练情况并高效进行阈值选择。
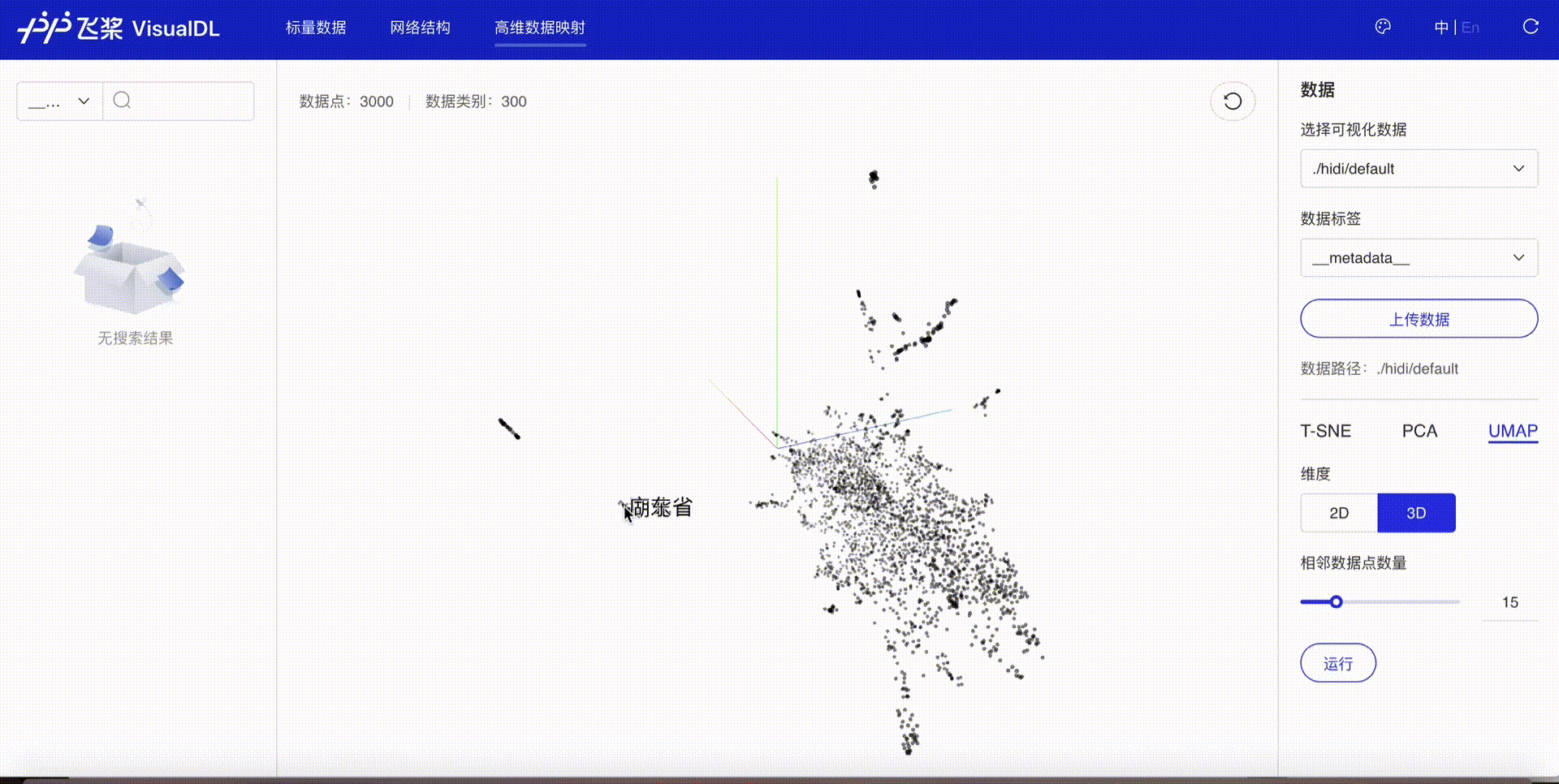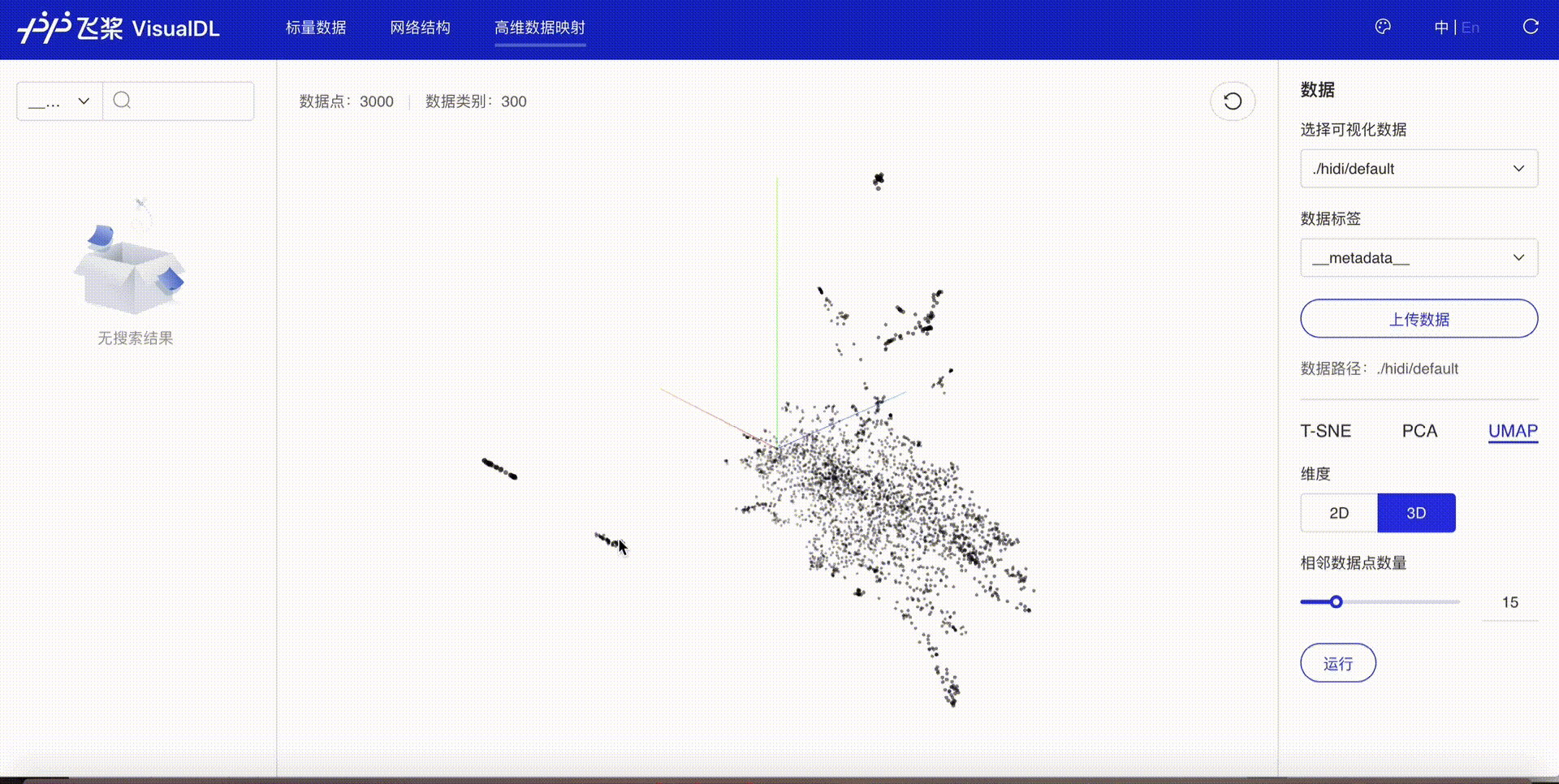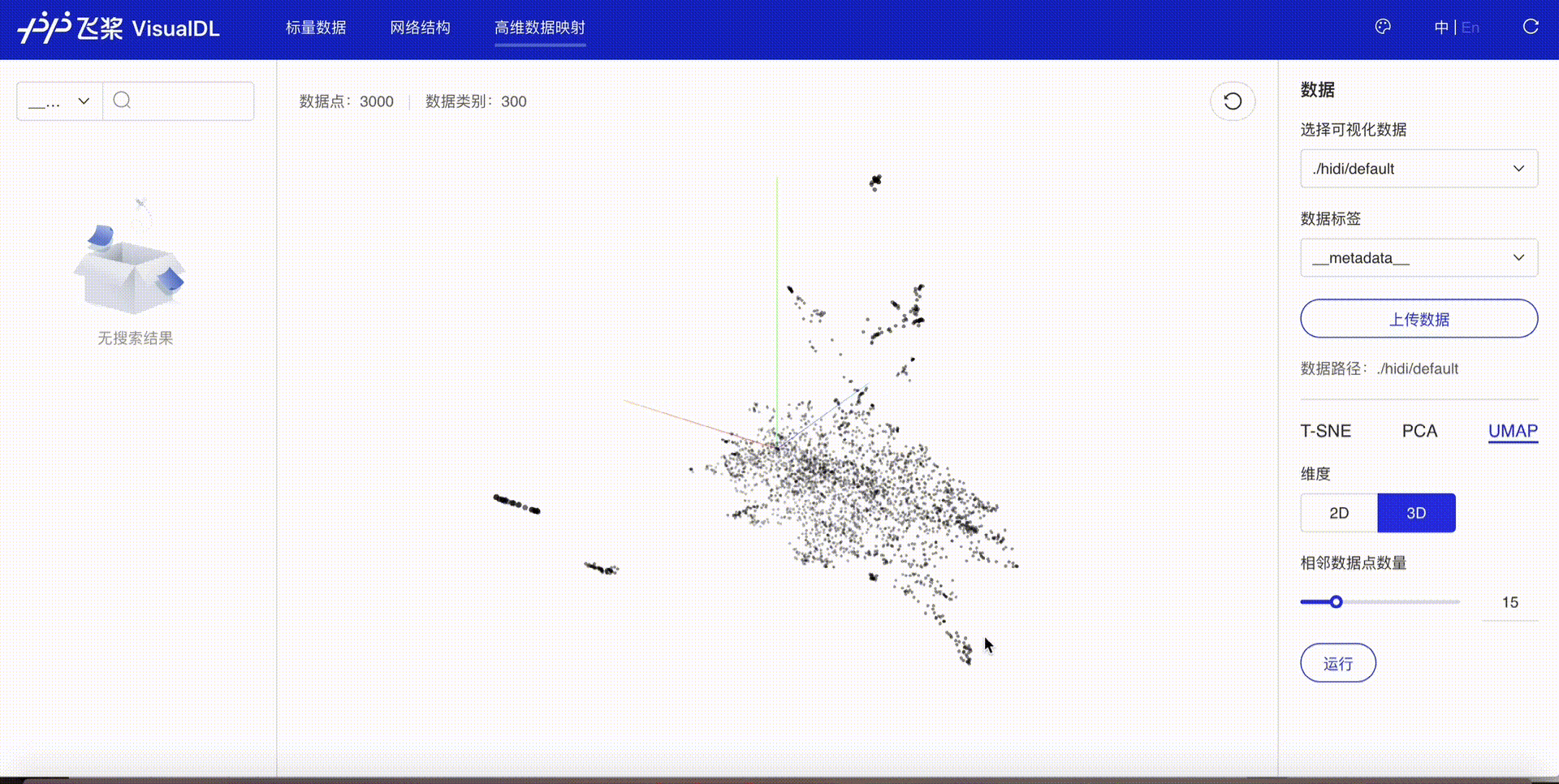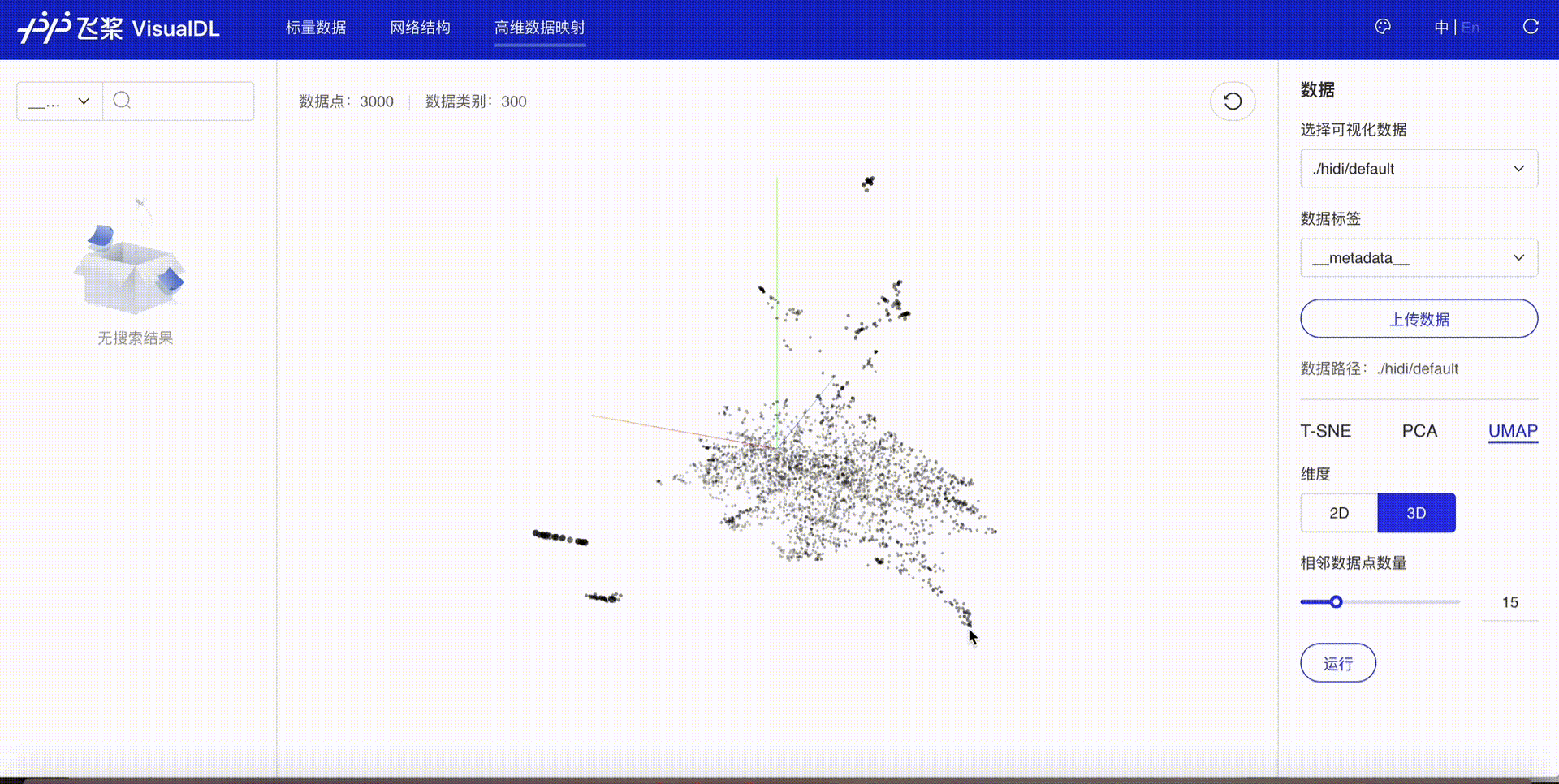
将高维数据进行降维展示,目前支持T-SNE、PCA、UMAP三种降维方式,用于深入分析高维数据间的关系,方便用户根据数据特征进行算法优化。
以丰富的视图多角度地可视化超参数与模型关键指标间的关系,便于快速确定最佳超参组合,实现高效调参。

通过多个视图可视化性能分析的数据,辅助用户定位性能瓶颈并进行优化。可参考使用VisualDL做性能分析。

提供onnx模型转paddle模型的可视化操作界面,帮助用户可视化onnx模型结构并且获取转换后的paddle模型结构和参数文件。

基于FastDeploy的Serving可视化部署,提供配置模型库、管理监控服务以及测试服务等功能。详细内容可参考使用VisualDL进行Serving可视化部署。

提供给用户访问fastdeployserver服务的客户端界面,进行一键预测和可视化结果。详细内容可参考使用VisualDL作为fastdeployserver服务的客户端。

VisualDL可视化结果保存服务,以链接形式将可视化结果保存下来,方便用户快速、便捷的进行托管与分享。

在使用VisualDL的过程中可能遇到的一些问题,可参考常见问题帮助解决
-
2020.12.22
《手拆朋友圈斗图利器—『圣诞写真生成器』》b站直播中奖用户名单请点击圣诞直播中奖名单查看~
VisualDL 是由 PaddlePaddle 和 ECharts 合作推出的开源项目。 Graph 相关功能由 Netron 提供技术支持。 欢迎所有人使用,提意见以及贡献代码。
想了解更多关于VisualDL可视化功能的使用详情介绍,请查看VisualDL使用指南,使用VisualDL做性能分析,使用VisualDL进行Serving可视化部署,使用VisualDL作为fastdeployserver服务的客户端。
欢迎您加入VisualDL官方QQ群:1045783368 与飞桨团队以及其他用户共同针对VisualDL进行讨论与交流。
