{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
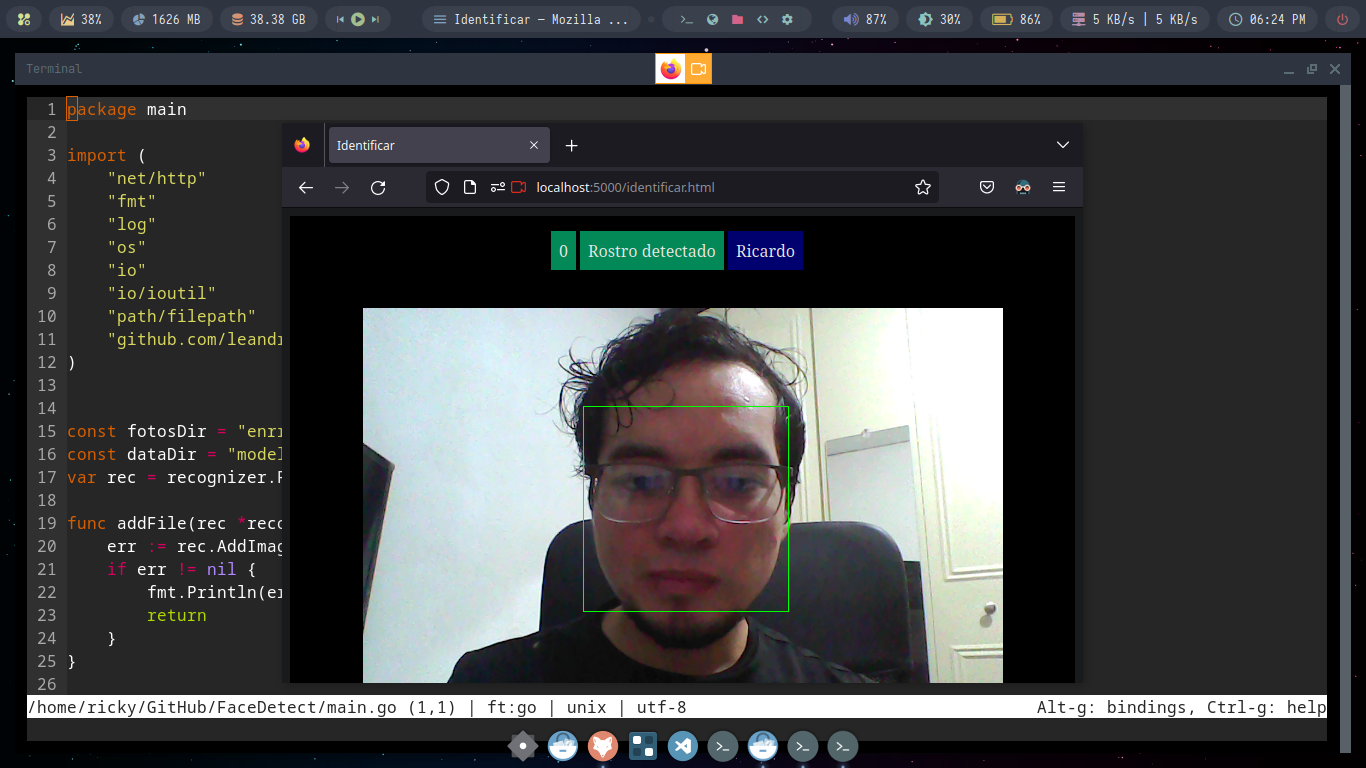
Este proyecto es un servidor web hecho para la detección y reconocimiento de rostros; implementando un conjunto de herramientas escritas en python, javascript y C++. Para poder ejecutar este proyecto de manera mas fácil, evitando el tedioso trabajo de instalar las dependencias para compilar, puedes ejecutar los siguientes comandos, para los cuales solo necesitaras tener instalado docker:
docker-compose up

Librerías usadas:
- OpenCV (https://docs.opencv.org/3.4/d5/d10/tutorial_js_root.html)
- Face Recognition (https://github.com/ageitgey/face_recognition)
- Dlib (http://dlib.net/)
Modelos entrenados para el reconocimiento, detección y predicción de rostros:
- @davisking (https://github.com/davisking/dlib-models)
Notas de: @davisking (https://github.com/davisking/dlib-models)
Este modelo está entrenado con el conjunto de datos: http://dlib.net/files/data/dlib_face_detection_dataset-2016-09-30.tar.gz. Se creó el conjunto de datos encontrando imágenes de rostros en muchos conjuntos de datos de imágenes disponibles públicamente (excluyendo el conjunto de datos FDDB). En particular, hay imágenes de ImageNet, AFLW, Pascal VOC, el conjunto de datos VGG, WIDER y face scrub. Todas las anotaciones en el conjunto de datos fueron creadas usando la herramienta imglab de dlib.

Este es un modelo de referencia de 5 puntos que identifica las esquinas de los ojos y la parte inferior de la nariz. Se entrenó con el conjunto de datos que se encuentra en http://dlib.net/files/data/dlib_faces_5points.tar, que consta de 7198 rostros. Se creó este conjunto de datos descargando imágenes de Internet y anotándolas con la herramienta imglab de dlib. Este modelo está diseñado para funcionar bien con el detector de rostros HOG de dlib y el detector de rostros CNN (mmod_human_face_detector.dat).

Este modelo está entrenado en el conjunto de datos ibug 300-W (https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/). La licencia de este conjunto de datos excluye el uso comercial y Stefanos Zafeiriou, uno de los creadores del conjunto de datos, pidió que incluyera una nota aquí diciendo que el modelo entrenado no se puede usar en un producto comercial. Por lo tanto, debe comunicarse con un abogado o hablar con el Imperial College London para averiguar si está bien que use este modelo en un producto comercial.

La red se entrenó desde cero con un conjunto de datos de aproximadamente 3 millones de rostros. Este conjunto de datos se deriva de dos conjuntos de datos. El conjunto de datos de face scrub (http://vintage.winklerbros.net/facescrub.html) y el conjunto de datos de VGG (http://www.robots.ox.ac.uk/~vgg/data/vgg_face/). Se hizo este modelo entrenando una CNN de reconocimiento facial y luego usando métodos de agrupación de gráficos y mucha revisión manual para limpiar el conjunto de datos. Al final, aproximadamente la mitad de las imágenes son de VGG y face scrub. Además, el número total de identidades individuales en el conjunto de datos es 7485. Se evitaron superposiciones de identidades en LFW.