converter = something::startsWith;
+String converted = converter.convert("Java");
+System.out.println(converted); // "J"
+```
+
+接下来看看构造函数是如何使用`::`关键字来引用的,首先我们定义一个包含多个构造函数的简单类:
+
+```java
+class Person {
+ String firstName;
+ String lastName;
+
+ Person() {}
+
+ Person(String firstName, String lastName) {
+ this.firstName = firstName;
+ this.lastName = lastName;
+ }
+}
+```
+接下来我们指定一个用来创建Person对象的对象工厂接口:
+
+```java
+interface PersonFactory {
+ P create(String firstName, String lastName);
+}
+```
+
+这里我们使用构造函数引用来将他们关联起来,而不是手动实现一个完整的工厂:
+
+```java
+PersonFactory personFactory = Person::new;
+Person person = personFactory.create("Peter", "Parker");
+```
+我们只需要使用 `Person::new` 来获取Person类构造函数的引用,Java编译器会自动根据`PersonFactory.create`方法的参数类型来选择合适的构造函数。
+
+### Lamda 表达式作用域(Lambda Scopes)
+
+#### 访问局部变量
+
+我们可以直接在 lambda 表达式中访问外部的局部变量:
+
+```java
+final int num = 1;
+Converter stringConverter =
+ (from) -> String.valueOf(from + num);
+
+stringConverter.convert(2); // 3
+```
+
+但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:
+
+```java
+int num = 1;
+Converter stringConverter =
+ (from) -> String.valueOf(from + num);
+
+stringConverter.convert(2); // 3
+```
+
+不过这里的 num 必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:
+
+```java
+int num = 1;
+Converter stringConverter =
+ (from) -> String.valueOf(from + num);
+num = 3;//在lambda表达式中试图修改num同样是不允许的。
+```
+
+#### 访问字段和静态变量
+
+与局部变量相比,我们对lambda表达式中的实例字段和静态变量都有读写访问权限。 该行为和匿名对象是一致的。
+
+```java
+class Lambda4 {
+ static int outerStaticNum;
+ int outerNum;
+
+ void testScopes() {
+ Converter stringConverter1 = (from) -> {
+ outerNum = 23;
+ return String.valueOf(from);
+ };
+
+ Converter stringConverter2 = (from) -> {
+ outerStaticNum = 72;
+ return String.valueOf(from);
+ };
+ }
+}
+```
+
+#### 访问默认接口方法
+
+还记得第一节中的 formula 示例吗? `Formula` 接口定义了一个默认方法`sqrt`,可以从包含匿名对象的每个 formula 实例访问该方法。 这不适用于lambda表达式。
+
+无法从 lambda 表达式中访问默认方法,故以下代码无法编译:
+
+```java
+Formula formula = (a) -> sqrt(a * 100);
+```
+
+### 内置函数式接口(Built-in Functional Interfaces)
+
+JDK 1.8 API包含许多内置函数式接口。 其中一些借口在老版本的 Java 中是比较常见的比如: `Comparator` 或`Runnable`,这些接口都增加了`@FunctionalInterface`注解以便能用在 lambda 表达式上。
+
+但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 [Google Guava](https://code.google.com/p/guava-libraries/) 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
+
+#### Predicates
+
+Predicate 接口是只有一个参数的返回布尔类型值的 **断言型** 接口。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非):
+
+**译者注:** Predicate 接口源码如下
+
+```java
+package java.util.function;
+import java.util.Objects;
+
+@FunctionalInterface
+public interface Predicate {
+
+ // 该方法是接受一个传入类型,返回一个布尔值.此方法应用于判断.
+ boolean test(T t);
+
+ //and方法与关系型运算符"&&"相似,两边都成立才返回true
+ default Predicate and(Predicate other) {
+ Objects.requireNonNull(other);
+ return (t) -> test(t) && other.test(t);
+ }
+ // 与关系运算符"!"相似,对判断进行取反
+ default Predicate negate() {
+ return (t) -> !test(t);
+ }
+ //or方法与关系型运算符"||"相似,两边只要有一个成立就返回true
+ default Predicate or(Predicate other) {
+ Objects.requireNonNull(other);
+ return (t) -> test(t) || other.test(t);
+ }
+ // 该方法接收一个Object对象,返回一个Predicate类型.此方法用于判断第一个test的方法与第二个test方法相同(equal).
+ static Predicate isEqual(Object targetRef) {
+ return (null == targetRef)
+ ? Objects::isNull
+ : object -> targetRef.equals(object);
+ }
+```
+
+示例:
+
+```java
+Predicate predicate = (s) -> s.length() > 0;
+
+predicate.test("foo"); // true
+predicate.negate().test("foo"); // false
+
+Predicate nonNull = Objects::nonNull;
+Predicate isNull = Objects::isNull;
+
+Predicate isEmpty = String::isEmpty;
+Predicate isNotEmpty = isEmpty.negate();
+```
+
+#### Functions
+
+Function 接口接受一个参数并生成结果。默认方法可用于将多个函数链接在一起(compose, andThen):
+
+**译者注:** Function 接口源码如下
+
+```java
+
+package java.util.function;
+
+import java.util.Objects;
+
+@FunctionalInterface
+public interface Function {
+
+ //将Function对象应用到输入的参数上,然后返回计算结果。
+ R apply(T t);
+ //将两个Function整合,并返回一个能够执行两个Function对象功能的Function对象。
+ default Function compose(Function before) {
+ Objects.requireNonNull(before);
+ return (V v) -> apply(before.apply(v));
+ }
+ //
+ default Function andThen(Function after) {
+ Objects.requireNonNull(after);
+ return (T t) -> after.apply(apply(t));
+ }
+
+ static Function identity() {
+ return t -> t;
+ }
+}
+```
+
+
+
+```java
+Function toInteger = Integer::valueOf;
+Function backToString = toInteger.andThen(String::valueOf);
+backToString.apply("123"); // "123"
+```
+
+#### Suppliers
+
+Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
+
+```java
+Supplier personSupplier = Person::new;
+personSupplier.get(); // new Person
+```
+
+#### Consumers
+
+Consumer 接口表示要对单个输入参数执行的操作。
+
+```java
+Consumer greeter = (p) -> System.out.println("Hello, " + p.firstName);
+greeter.accept(new Person("Luke", "Skywalker"));
+```
+
+#### Comparators
+
+Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
+
+```java
+Comparator comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
+
+Person p1 = new Person("John", "Doe");
+Person p2 = new Person("Alice", "Wonderland");
+
+comparator.compare(p1, p2); // > 0
+comparator.reversed().compare(p1, p2); // < 0
+```
+
+## Optionals
+
+Optionals不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optionals的工作原理。
+
+Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
+
+译者注:示例中每个方法的作用已经添加。
+
+```java
+//of():为非null的值创建一个Optional
+Optional optional = Optional.of("bam");
+// isPresent(): 如果值存在返回true,否则返回false
+optional.isPresent(); // true
+//get():如果Optional有值则将其返回,否则抛出NoSuchElementException
+optional.get(); // "bam"
+//orElse():如果有值则将其返回,否则返回指定的其它值
+optional.orElse("fallback"); // "bam"
+//ifPresent():如果Optional实例有值则为其调用consumer,否则不做处理
+optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
+```
+
+推荐阅读:[[Java8]如何正确使用Optional](https://blog.kaaass.net/archives/764)
+
+## Streams(流)
+
+`java.util.Stream` 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如` java.util.Collection` 的子类,List 或者 Set, Map 不支持。Stream 的操作可以串行执行或者并行执行。
+
+首先看看Stream是怎么用,首先创建实例代码的用到的数据List:
+
+```java
+List stringList = new ArrayList<>();
+stringList.add("ddd2");
+stringList.add("aaa2");
+stringList.add("bbb1");
+stringList.add("aaa1");
+stringList.add("bbb3");
+stringList.add("ccc");
+stringList.add("bbb2");
+stringList.add("ddd1");
+```
+
+Java 8扩展了集合类,可以通过 Collection.stream() 或者 Collection.parallelStream() 来创建一个Stream。下面几节将详细解释常用的Stream操作:
+
+### Filter(过滤)
+
+过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于**中间操作**,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
+
+```java
+ // 测试 Filter(过滤)
+ stringList
+ .stream()
+ .filter((s) -> s.startsWith("a"))
+ .forEach(System.out::println);//aaa2 aaa1
+```
+
+forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。
+
+### Sorted(排序)
+
+排序是一个 **中间操作**,返回的是排序好后的 Stream。**如果你不指定一个自定义的 Comparator 则会使用默认排序。**
+
+```java
+ // 测试 Sort (排序)
+ stringList
+ .stream()
+ .sorted()
+ .filter((s) -> s.startsWith("a"))
+ .forEach(System.out::println);// aaa1 aaa2
+```
+
+需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的:
+
+```java
+ System.out.println(stringList);// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
+```
+
+### Map(映射)
+
+中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
+
+下面的示例展示了将字符串转换为大写字符串。你也可以通过map来讲对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
+
+```java
+ // 测试 Map 操作
+ stringList
+ .stream()
+ .map(String::toUpperCase)
+ .sorted((a, b) -> b.compareTo(a))
+ .forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"
+```
+
+
+
+### Match(匹配)
+
+Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是 **最终操作** ,并返回一个 boolean 类型的值。
+
+```java
+ // 测试 Match (匹配)操作
+ boolean anyStartsWithA =
+ stringList
+ .stream()
+ .anyMatch((s) -> s.startsWith("a"));
+ System.out.println(anyStartsWithA); // true
+
+ boolean allStartsWithA =
+ stringList
+ .stream()
+ .allMatch((s) -> s.startsWith("a"));
+
+ System.out.println(allStartsWithA); // false
+
+ boolean noneStartsWithZ =
+ stringList
+ .stream()
+ .noneMatch((s) -> s.startsWith("z"));
+
+ System.out.println(noneStartsWithZ); // true
+```
+
+
+
+### Count(计数)
+
+计数是一个 **最终操作**,返回Stream中元素的个数,**返回值类型是 long**。
+
+```java
+ //测试 Count (计数)操作
+ long startsWithB =
+ stringList
+ .stream()
+ .filter((s) -> s.startsWith("b"))
+ .count();
+ System.out.println(startsWithB); // 3
+```
+
+### Reduce(规约)
+
+这是一个 **最终操作** ,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规约后的结果是通过Optional 接口表示的:
+
+```java
+ //测试 Reduce (规约)操作
+ Optional reduced =
+ stringList
+ .stream()
+ .sorted()
+ .reduce((s1, s2) -> s1 + "#" + s2);
+
+ reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
+```
+
+
+
+**译者注:** 这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于`Integer sum = integers.reduce(0, (a, b) -> a+b);`也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
+
+```java
+// 字符串连接,concat = "ABCD"
+String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
+// 求最小值,minValue = -3.0
+double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
+// 求和,sumValue = 10, 有起始值
+int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
+// 求和,sumValue = 10, 无起始值
+sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
+// 过滤,字符串连接,concat = "ace"
+concat = Stream.of("a", "B", "c", "D", "e", "F").
+ filter(x -> x.compareTo("Z") > 0).
+ reduce("", String::concat);
+```
+
+上面代码例如第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素,返回的是 Optional,请留意这个区别。更多内容查看: [IBM:Java 8 中的 Streams API 详解](https://www.ibm.com/developerworks/cn/java/j-lo-java8streamapi/index.html)
+
+## Parallel Streams(并行流)
+
+前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
+
+下面的例子展示了是如何通过并行Stream来提升性能:
+
+首先我们创建一个没有重复元素的大表:
+
+```java
+int max = 1000000;
+List values = new ArrayList<>(max);
+for (int i = 0; i < max; i++) {
+ UUID uuid = UUID.randomUUID();
+ values.add(uuid.toString());
+}
+```
+
+我们分别用串行和并行两种方式对其进行排序,最后看看所用时间的对比。
+
+### Sequential Sort(串行排序)
+
+```java
+//串行排序
+long t0 = System.nanoTime();
+long count = values.stream().sorted().count();
+System.out.println(count);
+
+long t1 = System.nanoTime();
+
+long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
+System.out.println(String.format("sequential sort took: %d ms", millis));
+```
+
+```
+1000000
+sequential sort took: 709 ms//串行排序所用的时间
+```
+
+### Parallel Sort(并行排序)
+
+```java
+//并行排序
+long t0 = System.nanoTime();
+
+long count = values.parallelStream().sorted().count();
+System.out.println(count);
+
+long t1 = System.nanoTime();
+
+long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
+System.out.println(String.format("parallel sort took: %d ms", millis));
+
+```
+
+```java
+1000000
+parallel sort took: 475 ms//串行排序所用的时间
+```
+
+上面两个代码几乎是一样的,但是并行版的快了 50% 左右,唯一需要做的改动就是将 `stream()` 改为`parallelStream()`。
+
+## Maps
+
+前面提到过,Map 类型不支持 streams,不过Map提供了一些新的有用的方法来处理一些日常任务。Map接口本身没有可用的 `stream()`方法,但是你可以在键,值上创建专门的流或者通过 `map.keySet().stream()`,`map.values().stream()`和`map.entrySet().stream()`。
+
+此外,Maps 支持各种新的和有用的方法来执行常见任务。
+
+```java
+Map map = new HashMap<>();
+
+for (int i = 0; i < 10; i++) {
+ map.putIfAbsent(i, "val" + i);
+}
+
+map.forEach((id, val) -> System.out.println(val));//val0 val1 val2 val3 val4 val5 val6 val7 val8 val9
+```
+
+`putIfAbsent` 阻止我们在null检查时写入额外的代码;`forEach`接受一个 consumer 来对 map 中的每个元素操作。
+
+此示例显示如何使用函数在 map 上计算代码:
+
+```java
+map.computeIfPresent(3, (num, val) -> val + num);
+map.get(3); // val33
+
+map.computeIfPresent(9, (num, val) -> null);
+map.containsKey(9); // false
+
+map.computeIfAbsent(23, num -> "val" + num);
+map.containsKey(23); // true
+
+map.computeIfAbsent(3, num -> "bam");
+map.get(3); // val33
+```
+
+接下来展示如何在Map里删除一个键值全都匹配的项:
+
+```java
+map.remove(3, "val3");
+map.get(3); // val33
+map.remove(3, "val33");
+map.get(3); // null
+```
+
+另外一个有用的方法:
+
+```java
+map.getOrDefault(42, "not found"); // not found
+```
+
+对Map的元素做合并也变得很容易了:
+
+```java
+map.merge(9, "val9", (value, newValue) -> value.concat(newValue));
+map.get(9); // val9
+map.merge(9, "concat", (value, newValue) -> value.concat(newValue));
+map.get(9); // val9concat
+```
+
+Merge 做的事情是如果键名不存在则插入,否则则对原键对应的值做合并操作并重新插入到map中。
+
+## Date API(日期相关API)
+
+Java 8在 `java.time` 包下包含一个全新的日期和时间API。新的Date API与Joda-Time库相似,但它们不一样。以下示例涵盖了此新 API 的最重要部分。译者对这部分内容参考相关书籍做了大部分修改。
+
+**译者注(总结):**
+
+- Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
+
+- 在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类`ZoneId`(在`java.time`包中)表示一个区域标识符。 它有一个名为`getAvailableZoneIds`的静态方法,它返回所有区域标识符。
+
+- jdk1.8中新增了 LocalDate 与 LocalDateTime等类来解决日期处理方法,同时引入了一个新的类DateTimeFormatter 来解决日期格式化问题。可以使用Instant代替 Date,LocalDateTime代替 Calendar,DateTimeFormatter 代替 SimpleDateFormat。
+
+
+
+### Clock
+
+Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
+
+```java
+Clock clock = Clock.systemDefaultZone();
+long millis = clock.millis();
+System.out.println(millis);//1552379579043
+Instant instant = clock.instant();
+System.out.println(instant);
+Date legacyDate = Date.from(instant); //2019-03-12T08:46:42.588Z
+System.out.println(legacyDate);//Tue Mar 12 16:32:59 CST 2019
+```
+
+### Timezones(时区)
+
+在新API中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法of来获取到。 抽象类`ZoneId`(在`java.time`包中)表示一个区域标识符。 它有一个名为`getAvailableZoneIds`的静态方法,它返回所有区域标识符。
+
+```java
+//输出所有区域标识符
+System.out.println(ZoneId.getAvailableZoneIds());
+
+ZoneId zone1 = ZoneId.of("Europe/Berlin");
+ZoneId zone2 = ZoneId.of("Brazil/East");
+System.out.println(zone1.getRules());// ZoneRules[currentStandardOffset=+01:00]
+System.out.println(zone2.getRules());// ZoneRules[currentStandardOffset=-03:00]
+```
+
+### LocalTime(本地时间)
+
+LocalTime 定义了一个没有时区信息的时间,例如 晚上10点或者 17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差:
+
+```java
+LocalTime now1 = LocalTime.now(zone1);
+LocalTime now2 = LocalTime.now(zone2);
+System.out.println(now1.isBefore(now2)); // false
+
+long hoursBetween = ChronoUnit.HOURS.between(now1, now2);
+long minutesBetween = ChronoUnit.MINUTES.between(now1, now2);
+
+System.out.println(hoursBetween); // -3
+System.out.println(minutesBetween); // -239
+```
+
+LocalTime 提供了多种工厂方法来简化对象的创建,包括解析时间字符串.
+
+```java
+LocalTime late = LocalTime.of(23, 59, 59);
+System.out.println(late); // 23:59:59
+DateTimeFormatter germanFormatter =
+ DateTimeFormatter
+ .ofLocalizedTime(FormatStyle.SHORT)
+ .withLocale(Locale.GERMAN);
+
+LocalTime leetTime = LocalTime.parse("13:37", germanFormatter);
+System.out.println(leetTime); // 13:37
+```
+
+### LocalDate(本地日期)
+
+LocalDate 表示了一个确切的日期,比如 2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。
+
+```java
+LocalDate today = LocalDate.now();//获取现在的日期
+System.out.println("今天的日期: "+today);//2019-03-12
+LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS);
+System.out.println("明天的日期: "+tomorrow);//2019-03-13
+LocalDate yesterday = tomorrow.minusDays(2);
+System.out.println("昨天的日期: "+yesterday);//2019-03-11
+LocalDate independenceDay = LocalDate.of(2019, Month.MARCH, 12);
+DayOfWeek dayOfWeek = independenceDay.getDayOfWeek();
+System.out.println("今天是周几:"+dayOfWeek);//TUESDAY
+```
+
+从字符串解析一个 LocalDate 类型和解析 LocalTime 一样简单,下面是使用 `DateTimeFormatter` 解析字符串的例子:
+
+```java
+ String str1 = "2014==04==12 01时06分09秒";
+ // 根据需要解析的日期、时间字符串定义解析所用的格式器
+ DateTimeFormatter fomatter1 = DateTimeFormatter
+ .ofPattern("yyyy==MM==dd HH时mm分ss秒");
+
+ LocalDateTime dt1 = LocalDateTime.parse(str1, fomatter1);
+ System.out.println(dt1); // 输出 2014-04-12T01:06:09
+
+ String str2 = "2014$$$四月$$$13 20小时";
+ DateTimeFormatter fomatter2 = DateTimeFormatter
+ .ofPattern("yyy$$$MMM$$$dd HH小时");
+ LocalDateTime dt2 = LocalDateTime.parse(str2, fomatter2);
+ System.out.println(dt2); // 输出 2014-04-13T20:00
+
+```
+
+再来看一个使用 `DateTimeFormatter` 格式化日期的示例
+
+```java
+LocalDateTime rightNow=LocalDateTime.now();
+String date=DateTimeFormatter.ISO_LOCAL_DATE_TIME.format(rightNow);
+System.out.println(date);//2019-03-12T16:26:48.29
+DateTimeFormatter formatter=DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss");
+System.out.println(formatter.format(rightNow));//2019-03-12 16:26:48
+```
+
+### LocalDateTime(本地日期时间)
+
+LocalDateTime 同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime 和 LocalTime还有 LocalDate 一样,都是不可变的。LocalDateTime 提供了一些能访问具体字段的方法。
+
+```java
+LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);
+
+DayOfWeek dayOfWeek = sylvester.getDayOfWeek();
+System.out.println(dayOfWeek); // WEDNESDAY
+
+Month month = sylvester.getMonth();
+System.out.println(month); // DECEMBER
+
+long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY);
+System.out.println(minuteOfDay); // 1439
+```
+
+只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的`java.util.Date`。
+
+```java
+Instant instant = sylvester
+ .atZone(ZoneId.systemDefault())
+ .toInstant();
+
+Date legacyDate = Date.from(instant);
+System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014
+```
+
+格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式:
+
+```java
+DateTimeFormatter formatter =
+ DateTimeFormatter
+ .ofPattern("MMM dd, yyyy - HH:mm");
+LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter);
+String string = formatter.format(parsed);
+System.out.println(string); // Nov 03, 2014 - 07:13
+```
+
+和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。
+关于时间日期格式的详细信息在[这里](https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html)。
+
+## Annotations(注解)
+
+在Java 8中支持多重注解了,先看个例子来理解一下是什么意思。
+首先定义一个包装类Hints注解用来放置一组具体的Hint注解:
+
+```java
+@interface Hints {
+ Hint[] value();
+}
+@Repeatable(Hints.class)
+@interface Hint {
+ String value();
+}
+```
+
+Java 8允许我们把同一个类型的注解使用多次,只需要给该注解标注一下`@Repeatable`即可。
+
+例 1: 使用包装类当容器来存多个注解(老方法)
+
+```java
+@Hints({@Hint("hint1"), @Hint("hint2")})
+class Person {}
+```
+
+例 2:使用多重注解(新方法)
+
+```java
+@Hint("hint1")
+@Hint("hint2")
+class Person {}
+```
+
+第二个例子里java编译器会隐性的帮你定义好@Hints注解,了解这一点有助于你用反射来获取这些信息:
+
+```java
+Hint hint = Person.class.getAnnotation(Hint.class);
+System.out.println(hint); // null
+Hints hints1 = Person.class.getAnnotation(Hints.class);
+System.out.println(hints1.value().length); // 2
+
+Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class);
+System.out.println(hints2.length); // 2
+```
+
+即便我们没有在 `Person`类上定义 `@Hints`注解,我们还是可以通过 `getAnnotation(Hints.class) `来获取 `@Hints`注解,更加方便的方法是使用 `getAnnotationsByType` 可以直接获取到所有的`@Hint`注解。
+另外Java 8的注解还增加到两种新的target上了:
+
+```java
+@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE})
+@interface MyAnnotation {}
+```
+
+## Where to go from here?
+
+关于Java 8的新特性就写到这了,肯定还有更多的特性等待发掘。JDK 1.8里还有很多很有用的东西,比如`Arrays.parallelSort`, `StampedLock`和`CompletableFuture`等等。
+
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
\ No newline at end of file
diff --git "a/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md" "b/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
new file mode 100644
index 00000000000..7de58352a5f
--- /dev/null
+++ "b/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
@@ -0,0 +1,18 @@
+### 书籍
+
+- **《Java8 In Action》**
+- **《写给大忙人看的Java SE 8》**
+
+上述书籍的PDF版本见 https://shimo.im/docs/CPB0PK05rP4CFmI2/ 中的 “Java 书籍推荐”。
+
+### 开源文档
+
+- **【译】Java 8 简明教程**:
+- **30 seconds of java8:**
+
+### 视频
+
+- **尚硅谷 Java 8 新特性**
+
+视频资源见: https://shimo.im/docs/CPB0PK05rP4CFmI2/ 。
+
diff --git "a/docs/java/What's New in JDK8/Lambda\350\241\250\350\276\276\345\274\217.md" "b/docs/java/What's New in JDK8/Lambda\350\241\250\350\276\276\345\274\217.md"
new file mode 100644
index 00000000000..359c4714473
--- /dev/null
+++ "b/docs/java/What's New in JDK8/Lambda\350\241\250\350\276\276\345\274\217.md"
@@ -0,0 +1,235 @@
+JDK8--Lambda表达式
+===
+## 1.什么是Lambda表达式
+**Lambda表达式实质上是一个可传递的代码块,Lambda又称为闭包或者匿名函数,是函数式编程语法,让方法可以像普通参数一样传递**
+
+## 2.Lambda表达式语法
+```(参数列表) -> {执行代码块}```
+
参数列表可以为空```()->{}```
+
可以加类型声明比如```(String para1, int para2) -> {return para1 + para2;}```我们可以看到,lambda同样可以有返回值.
+
在编译器可以推断出类型的时候,可以将类型声明省略,比如```(para1, para2) -> {return para1 + para2;}```
+
(lambda有点像动态类型语言语法。lambda在字节码层面是用invokedynamic实现的,而这条指令就是为了让JVM更好的支持运行在其上的动态类型语言)
+
+## 3.函数式接口
+在了解Lambda表达式之前,有必要先了解什么是函数式接口```(@FunctionalInterface)```
+**函数式接口指的是有且只有一个抽象(abstract)方法的接口**
+当需要一个函数式接口的对象时,就可以用Lambda表达式来实现,举个常用的例子:
+
+```java
+ Thread thread = new Thread(() -> {
+ System.out.println("This is JDK8's Lambda!");
+ });
+```
+这段代码和函数式接口有啥关系?我们回忆一下,Thread类的构造函数里是不是有一个以Runnable接口为参数的?
+```java
+public Thread(Runnable target) {...}
+
+/**
+ * Runnable Interface
+ */
+@FunctionalInterface
+public interface Runnable {
+ public abstract void run();
+}
+```
+到这里大家可能已经明白了,**Lambda表达式相当于一个匿名类或者说是一个匿名方法**。上面Thread的例子相当于
+```java
+ Thread thread = new Thread(new Runnable() {
+ @Override
+ public void run() {
+ System.out.println("Anonymous class");
+ }
+ });
+```
+也就是说,上面的lambda表达式相当于实现了这个run()方法,然后当做参数传入(个人感觉可以这么理解,lambda表达式就是一个函数,只不过它的返回值、参数列表都
+由编译器帮我们推断,因此可以减少很多代码量)。
+
Lambda也可以这样用 :
+```java
+ Runnable runnable = () -> {...};
+```
+其实这和上面的用法没有什么本质上的区别。
+
至此大家应该明白什么是函数式接口以及函数式接口和lambda表达式之间的关系了。在JDK8中修改了接口的规范,
+目的是为了在给接口添加新的功能时保持向前兼容(个人理解),比如一个已经定义了的函数式接口,某天我们想给它添加新功能,那么就不能保持向前兼容了,
+因为在旧的接口规范下,添加新功能必定会破坏这个函数式接口[(JDK8中接口规范)]()
+
+除了上面说的Runnable接口之外,JDK中已经存在了很多函数式接口
+比如(当然不止这些):
+- ```java.util.concurrent.Callable```
+- ```java.util.Comparator```
+- ```java.io.FileFilter```
+
**关于JDK中的预定义的函数式接口**
+
+- JDK在```java.util.function```下预定义了很多函数式接口
+ - ```Function {R apply(T t);}``` 接受一个T对象,然后返回一个R对象,就像普通的函数。
+ - ```Consumer {void accept(T t);}``` 消费者 接受一个T对象,没有返回值。
+ - ```Predicate {boolean test(T t);}``` 判断,接受一个T对象,返回一个布尔值。
+ - ```Supplier {T get();} 提供者(工厂)``` 返回一个T对象。
+ - 其他的跟上面的相似,大家可以看一下function包下的具体接口。
+## 4.变量作用域
+```java
+public class VaraibleHide {
+ @FunctionalInterface
+ interface IInner {
+ void printInt(int x);
+ }
+ public static void main(String[] args) {
+ int x = 20;
+ IInner inner = new IInner() {
+ int x = 10;
+ @Override
+ public void printInt(int x) {
+ System.out.println(x);
+ }
+ };
+ inner.printInt(30);
+
+ inner = (s) -> {
+ //Variable used in lambda expression should be final or effectively final
+ //!int x = 10;
+ //!x= 50; error
+ System.out.print(x);
+ };
+ inner.printInt(30);
+ }
+}
+输出 :
+30
+20
+```
+对于lambda表达式```java inner = (s) -> {System.out.print(x);};```,变量x并不是在lambda表达式中定义的,像这样并不是在lambda中定义或者通过lambda的参数列表()获取的变量成为自由变量,它是被lambda表达式捕获的。
+
lambda表达式和内部类一样,对外部自由变量捕获时,外部自由变量必须为final或者是最终变量(effectively final)的,也就是说这个变量初始化后就不能为它赋新值,
+同时lambda不像内部类/匿名类,lambda表达式与外围嵌套块有着相同的作用域,因此对变量命名的有关规则对lambda同样适用。大家阅读上面的代码对这些概念应该
+不难理解。
+## 5.方法引用
+**只需要提供方法的名字,具体的调用过程由Lambda和函数式接口来确定,这样的方法调用成为方法引用。**
+
下面的例子会打印list中的每个元素:
+```java
+List list = new ArrayList<>();
+ for (int i = 0; i < 10; ++i) {
+ list.add(i);
+ }
+ list.forEach(System.out::println);
+```
+其中```System.out::println```这个就是一个方法引用,等价于Lambda表达式 ```(para)->{System.out.println(para);}```
+
我们看一下List#forEach方法 ```default void forEach(Consumer action)```可以看到它的参数是一个Consumer接口,该接口是一个函数式接口
+```java
+@FunctionalInterface
+public interface Consumer {
+ void accept(T t);
+```
+大家能发现这个函数接口的方法和```System.out::println```有什么相似的么?没错,它们有着相似的参数列表和返回值。
+
我们自己定义一个方法,看看能不能像标准输出的打印函数一样被调用
+```java
+public class MethodReference {
+ public static void main(String[] args) {
+ List list = new ArrayList<>();
+ for (int i = 0; i < 10; ++i) {
+ list.add(i);
+ }
+ list.forEach(MethodReference::myPrint);
+ }
+
+ static void myPrint(int i) {
+ System.out.print(i + ", ");
+ }
+}
+
+输出: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
+```
+可以看到,我们自己定义的方法也可以当做方法引用。
+
到这里大家多少对方法引用有了一定的了解,我们再来说一下方法引用的形式。
+- 方法引用
+ - 类名::静态方法名
+ - 类名::实例方法名
+ - 类名::new (构造方法引用)
+ - 实例名::实例方法名
+可以看出,方法引用是通过(方法归属名)::(方法名)来调用的。通过上面的例子已经讲解了一个`类名::静态方法名`的使用方法了,下面再依次介绍其余的几种
+方法引用的使用方法。
+**类名::实例方法名**
+先来看一段代码
+```java
+ String[] strings = new String[10];
+ Arrays.sort(strings, String::compareToIgnoreCase);
+```
+**上面的String::compareToIgnoreCase等价于(x, y) -> {return x.compareToIgnoreCase(y);}**
+我们看一下`Arrays#sort`方法`public static void sort(T[] a, Comparator c)`,
+可以看到第二个参数是一个Comparator接口,该接口也是一个函数式接口,其中的抽象方法是`int compare(T o1, T o2);`,再看一下
+`String#compareToIgnoreCase`方法,`public int compareToIgnoreCase(String str)`,这个方法好像和上面讲方法引用中`类名::静态方法名`不大一样啊,它
+的参数列表和函数式接口的参数列表不一样啊,虽然它的返回值一样?
+
是的,确实不一样但是别忘了,String类的这个方法是个实例方法,而不是静态方法,也就是说,这个方法是需要有一个接收者的。所谓接收者就是
+instance.method(x)中的instance,
+它是某个类的实例,有的朋友可能已经明白了。上面函数式接口的`compare(T o1, T o2)`中的第一个参数作为了实例方法的接收者,而第二个参数作为了实例方法的
+参数。我们再举一个自己实现的例子:
+```java
+public class MethodReference {
+ static Random random = new Random(47);
+ public static void main(String[] args) {
+ MethodReference[] methodReferences = new MethodReference[10];
+ Arrays.sort(methodReferences, MethodReference::myCompare);
+ }
+ int myCompare(MethodReference o) {
+ return random.nextInt(2) - 1;
+ }
+}
+```
+上面的例子可以在IDE里通过编译,大家有兴趣的可以模仿上面的例子自己写一个程序,打印出排序后的结果。
+
**构造器引用**
+构造器引用仍然需要与特定的函数式接口配合使用,并不能像下面这样直接使用。IDE会提示String不是一个函数式接口
+```java
+ //compile error : String is not a functional interface
+ String str = String::new;
+```
+下面是一个使用构造器引用的例子,可以看出构造器引用可以和这种工厂型的函数式接口一起使用的。
+```java
+ interface IFunctional {
+ T func();
+}
+
+public class ConstructorReference {
+
+ public ConstructorReference() {
+ }
+
+ public static void main(String[] args) {
+ Supplier supplier0 = () -> new ConstructorReference();
+ Supplier supplier1 = ConstructorReference::new;
+ IFunctional functional = () -> new ConstructorReference();
+ IFunctional functional1 = ConstructorReference::new;
+ }
+}
+```
+下面是一个JDK官方的例子
+```java
+ public static , DEST extends Collection>
+ DEST transferElements(
+ SOURCE sourceCollection,
+ Supplier collectionFactory) {
+
+ DEST result = collectionFactory.get();
+ for (T t : sourceCollection) {
+ result.add(t);
+ }
+ return result;
+ }
+
+ ...
+
+ Set rosterSet = transferElements(
+ roster, HashSet::new);
+```
+
+**实例::实例方法**
+
+其实开始那个例子就是一个实例::实例方法的引用
+```java
+List list = new ArrayList<>();
+ for (int i = 0; i < 10; ++i) {
+ list.add(i);
+ }
+ list.forEach(System.out::println);
+```
+其中System.out就是一个实例,println是一个实例方法。相信不用再给大家做解释了。
+## 总结
+Lambda表达式是JDK8引入Java的函数式编程语法,使用Lambda需要直接或者间接的与函数式接口配合,在开发中使用Lambda可以减少代码量,
+但是并不是说必须要使用Lambda(虽然它是一个很酷的东西)。有些情况下使用Lambda会使代码的可读性急剧下降,并且也节省不了多少代码,
+所以在实际开发中还是需要仔细斟酌是否要使用Lambda。和Lambda相似的还有JDK10中加入的var类型推断,同样对于这个特性需要斟酌使用。
diff --git a/docs/java/What's New in JDK8/README.md b/docs/java/What's New in JDK8/README.md
new file mode 100644
index 00000000000..fa71e907410
--- /dev/null
+++ b/docs/java/What's New in JDK8/README.md
@@ -0,0 +1,556 @@
+JDK8新特性总结
+======
+总结了部分JDK8新特性,另外一些新特性可以通过Oracle的官方文档查看,毕竟是官方文档,各种新特性都会介绍,有兴趣的可以去看。
+[Oracle官方文档:What's New in JDK8](https://www.oracle.com/technetwork/java/javase/8-whats-new-2157071.html)
+-----
+- [Java语言特性](#JavaProgrammingLanguage)
+ - [Lambda表达式是一个新的语言特性,已经在JDK8中加入。它是一个可以传递的代码块,你也可以把它们当做方法参数。
+ Lambda表达式允许您更紧凑地创建单虚方法接口(称为功能接口)的实例。](#LambdaExpressions)
+
+ - [方法引用为已经存在的具名方法提供易于阅读的Lambda表达式](#MethodReferences)
+
+ - [默认方法允许将新功能添加到库的接口,并确保与为这些接口的旧版本编写的代码的二进制兼容性。](#DefaultMethods)
+
+ - [改进的类型推断。](#ImprovedTypeInference)
+
+ - [方法参数反射(通过反射获得方法参数信息)](#MethodParameterReflection)
+
+- [流(stream)](#stream)
+ - [新java.util.stream包中的类提供Stream API以支持对元素流的功能样式操作。流(stream)和I/O里的流不是同一个概念
+ ,使用stream API可以更方便的操作集合。]()
+
+- [国际化]()
+ - 待办
+- 待办
+___
+
+
+
+
+
+
+
+## Lambda表达式
+### 1.什么是Lambda表达式
+**Lambda表达式实质上是一个可传递的代码块,Lambda又称为闭包或者匿名函数,是函数式编程语法,让方法可以像普通参数一样传递**
+
+### 2.Lambda表达式语法
+```(参数列表) -> {执行代码块}```
+
参数列表可以为空```()->{}```
+
可以加类型声明比如```(String para1, int para2) -> {return para1 + para2;}```我们可以看到,lambda同样可以有返回值.
+
在编译器可以推断出类型的时候,可以将类型声明省略,比如```(para1, para2) -> {return para1 + para2;}```
+
(lambda有点像动态类型语言语法。lambda在字节码层面是用invokedynamic实现的,而这条指令就是为了让JVM更好的支持运行在其上的动态类型语言)
+
+### 3.函数式接口
+在了解Lambda表达式之前,有必要先了解什么是函数式接口```(@FunctionalInterface)```
+**函数式接口指的是有且只有一个抽象(abstract)方法的接口**
+当需要一个函数式接口的对象时,就可以用Lambda表达式来实现,举个常用的例子:
+
+```java
+ Thread thread = new Thread(() -> {
+ System.out.println("This is JDK8's Lambda!");
+ });
+```
+这段代码和函数式接口有啥关系?我们回忆一下,Thread类的构造函数里是不是有一个以Runnable接口为参数的?
+```java
+public Thread(Runnable target) {...}
+
+/**
+ * Runnable Interface
+ */
+@FunctionalInterface
+public interface Runnable {
+ public abstract void run();
+}
+```
+到这里大家可能已经明白了,**Lambda表达式相当于一个匿名类或者说是一个匿名方法**。上面Thread的例子相当于
+```java
+ Thread thread = new Thread(new Runnable() {
+ @Override
+ public void run() {
+ System.out.println("Anonymous class");
+ }
+ });
+```
+也就是说,上面的lambda表达式相当于实现了这个run()方法,然后当做参数传入(个人感觉可以这么理解,lambda表达式就是一个函数,只不过它的返回值、参数列表都
+由编译器帮我们推断,因此可以减少很多代码量)。
+
Lambda也可以这样用 :
+```java
+ Runnable runnable = () -> {...};
+```
+其实这和上面的用法没有什么本质上的区别。
+
至此大家应该明白什么是函数式接口以及函数式接口和lambda表达式之间的关系了。在JDK8中修改了接口的规范,
+目的是为了在给接口添加新的功能时保持向前兼容(个人理解),比如一个已经定义了的函数式接口,某天我们想给它添加新功能,那么就不能保持向前兼容了,
+因为在旧的接口规范下,添加新功能必定会破坏这个函数式接口[(JDK8中接口规范)]()
+
+除了上面说的Runnable接口之外,JDK中已经存在了很多函数式接口
+比如(当然不止这些):
+- ```java.util.concurrent.Callable```
+- ```java.util.Comparator```
+- ```java.io.FileFilter```
+
**关于JDK中的预定义的函数式接口**
+
+- JDK在```java.util.function```下预定义了很多函数式接口
+ - ```Function {R apply(T t);}``` 接受一个T对象,然后返回一个R对象,就像普通的函数。
+ - ```Consumer {void accept(T t);}``` 消费者 接受一个T对象,没有返回值。
+ - ```Predicate {boolean test(T t);}``` 判断,接受一个T对象,返回一个布尔值。
+ - ```Supplier {T get();} 提供者(工厂)``` 返回一个T对象。
+ - 其他的跟上面的相似,大家可以看一下function包下的具体接口。
+### 4.变量作用域
+```java
+public class VaraibleHide {
+ @FunctionalInterface
+ interface IInner {
+ void printInt(int x);
+ }
+ public static void main(String[] args) {
+ int x = 20;
+ IInner inner = new IInner() {
+ int x = 10;
+ @Override
+ public void printInt(int x) {
+ System.out.println(x);
+ }
+ };
+ inner.printInt(30);
+
+ inner = (s) -> {
+ //Variable used in lambda expression should be final or effectively final
+ //!int x = 10;
+ //!x= 50; error
+ System.out.print(x);
+ };
+ inner.printInt(30);
+ }
+}
+输出 :
+30
+20
+```
+对于lambda表达式```java inner = (s) -> {System.out.print(x);};```,变量x并不是在lambda表达式中定义的,像这样并不是在lambda中定义或者通过lambda
+的参数列表()获取的变量成为自由变量,它是被lambda表达式捕获的。
+
lambda表达式和内部类一样,对外部自由变量捕获时,外部自由变量必须为final或者是最终变量(effectively final)的,也就是说这个变量初始化后就不能为它赋新值,同时lambda不像内部类/匿名类,lambda表达式与外围嵌套块有着相同的作用域,因此对变量命名的有关规则对lambda同样适用。大家阅读上面的代码对这些概念应该不难理解。
+
+### 5.方法引用
+**只需要提供方法的名字,具体的调用过程由Lambda和函数式接口来确定,这样的方法调用成为方法引用。**
+
下面的例子会打印list中的每个元素:
+```java
+List list = new ArrayList<>();
+ for (int i = 0; i < 10; ++i) {
+ list.add(i);
+ }
+ list.forEach(System.out::println);
+```
+其中```System.out::println```这个就是一个方法引用,等价于Lambda表达式 ```(para)->{System.out.println(para);}```
+
我们看一下List#forEach方法 ```default void forEach(Consumer action)```可以看到它的参数是一个Consumer接口,该接口是一个函数式接口
+```java
+@FunctionalInterface
+public interface Consumer {
+ void accept(T t);
+```
+大家能发现这个函数接口的方法和```System.out::println```有什么相似的么?没错,它们有着相似的参数列表和返回值。
+
我们自己定义一个方法,看看能不能像标准输出的打印函数一样被调用
+```java
+public class MethodReference {
+ public static void main(String[] args) {
+ List list = new ArrayList<>();
+ for (int i = 0; i < 10; ++i) {
+ list.add(i);
+ }
+ list.forEach(MethodReference::myPrint);
+ }
+
+ static void myPrint(int i) {
+ System.out.print(i + ", ");
+ }
+}
+
+输出: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
+```
+可以看到,我们自己定义的方法也可以当做方法引用。
+
到这里大家多少对方法引用有了一定的了解,我们再来说一下方法引用的形式。
+- 方法引用
+ - 类名::静态方法名
+ - 类名::实例方法名
+ - 类名::new (构造方法引用)
+ - 实例名::实例方法名
+可以看出,方法引用是通过(方法归属名)::(方法名)来调用的。通过上面的例子已经讲解了一个`类名::静态方法名`的使用方法了,下面再依次介绍其余的几种
+方法引用的使用方法。
+**类名::实例方法名**
+先来看一段代码
+```java
+ String[] strings = new String[10];
+ Arrays.sort(strings, String::compareToIgnoreCase);
+```
+**上面的String::compareToIgnoreCase等价于(x, y) -> {return x.compareToIgnoreCase(y);}**
+我们看一下`Arrays#sort`方法`public static void sort(T[] a, Comparator c)`,
+可以看到第二个参数是一个Comparator接口,该接口也是一个函数式接口,其中的抽象方法是`int compare(T o1, T o2);`,再看一下
+`String#compareToIgnoreCase`方法,`public int compareToIgnoreCase(String str)`,这个方法好像和上面讲方法引用中`类名::静态方法名`不大一样啊,它
+的参数列表和函数式接口的参数列表不一样啊,虽然它的返回值一样?
+
是的,确实不一样但是别忘了,String类的这个方法是个实例方法,而不是静态方法,也就是说,这个方法是需要有一个接收者的。所谓接收者就是
+instance.method(x)中的instance,
+它是某个类的实例,有的朋友可能已经明白了。上面函数式接口的`compare(T o1, T o2)`中的第一个参数作为了实例方法的接收者,而第二个参数作为了实例方法的
+参数。我们再举一个自己实现的例子:
+```java
+public class MethodReference {
+ static Random random = new Random(47);
+ public static void main(String[] args) {
+ MethodReference[] methodReferences = new MethodReference[10];
+ Arrays.sort(methodReferences, MethodReference::myCompare);
+ }
+ int myCompare(MethodReference o) {
+ return random.nextInt(2) - 1;
+ }
+}
+```
+上面的例子可以在IDE里通过编译,大家有兴趣的可以模仿上面的例子自己写一个程序,打印出排序后的结果。
+
**构造器引用**
+构造器引用仍然需要与特定的函数式接口配合使用,并不能像下面这样直接使用。IDE会提示String不是一个函数式接口
+```java
+ //compile error : String is not a functional interface
+ String str = String::new;
+```
+下面是一个使用构造器引用的例子,可以看出构造器引用可以和这种工厂型的函数式接口一起使用的。
+```java
+ interface IFunctional {
+ T func();
+}
+
+public class ConstructorReference {
+
+ public ConstructorReference() {
+ }
+
+ public static void main(String[] args) {
+ Supplier supplier0 = () -> new ConstructorReference();
+ Supplier supplier1 = ConstructorReference::new;
+ IFunctional functional = () -> new ConstructorReference();
+ IFunctional functional1 = ConstructorReference::new;
+ }
+}
+```
+下面是一个JDK官方的例子
+```java
+ public static , DEST extends Collection>
+ DEST transferElements(
+ SOURCE sourceCollection,
+ Supplier collectionFactory) {
+
+ DEST result = collectionFactory.get();
+ for (T t : sourceCollection) {
+ result.add(t);
+ }
+ return result;
+ }
+
+ ...
+
+ Set rosterSet = transferElements(
+ roster, HashSet::new);
+```
+
+**实例::实例方法**
+
+其实开始那个例子就是一个实例::实例方法的引用
+```java
+List list = new ArrayList<>();
+ for (int i = 0; i < 10; ++i) {
+ list.add(i);
+ }
+ list.forEach(System.out::println);
+```
+其中System.out就是一个实例,println是一个实例方法。相信不用再给大家做解释了。
+### 总结
+Lambda表达式是JDK8引入Java的函数式编程语法,使用Lambda需要直接或者间接的与函数式接口配合,在开发中使用Lambda可以减少代码量,
+但是并不是说必须要使用Lambda(虽然它是一个很酷的东西)。有些情况下使用Lambda会使代码的可读性急剧下降,并且也节省不了多少代码,
+所以在实际开发中还是需要仔细斟酌是否要使用Lambda。和Lambda相似的还有JDK10中加入的var类型推断,同样对于这个特性需要斟酌使用。
+
+
+___
+
+
+## JDK8接口规范
+### 在JDK8中引入了lambda表达式,出现了函数式接口的概念,为了在扩展接口时保持向前兼容性(JDK8之前扩展接口会使得实现了该接口的类必须实现添加的方法,否则会报错。为了保持兼容性而做出妥协的特性还有泛型,泛型也是为了保持兼容性而失去了在一些别的语言泛型拥有的功能),Java接口规范发生了一些改变。
+### 1.JDK8以前的接口规范
+- JDK8以前接口可以定义的变量和方法
+ - 所有变量(Field)不论是否显式 的声明为```public static final```,它实际上都是```public static final```的。
+ - 所有方法(Method)不论是否显示 的声明为```public abstract```,它实际上都是```public abstract```的。
+```java
+public interface AInterfaceBeforeJDK8 {
+ int FIELD = 0;
+ void simpleMethod();
+}
+```
+以上接口信息反编译以后可以看到字节码信息里Filed是public static final的,而方法是public abstract的,即是你没有显示的去声明它。
+```java
+{
+ public static final int FIELD;
+ descriptor: I
+ flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
+ ConstantValue: int 0
+
+ public abstract void simpleMethod();
+ descriptor: ()V
+ flags: (0x0401) ACC_PUBLIC, ACC_ABSTRACT
+}
+```
+### 2.JDK8之后的接口规范
+- JDK8之后接口可以定义的变量和方法
+ - 变量(Field)仍然必须是 ```java public static final```的
+ - 方法(Method)除了可以是public abstract之外,还可以是public static或者是default(相当于仅public修饰的实例方法)的。
+从以上改变不难看出,修改接口的规范主要是为了能在扩展接口时保持向前兼容。
+
下面是一个JDK8之后的接口例子
+```java
+public interface AInterfaceInJDK8 {
+ int simpleFiled = 0;
+ static int staticField = 1;
+
+ public static void main(String[] args) {
+ }
+ static void staticMethod(){}
+
+ default void defaultMethod(){}
+
+ void simpleMethod() throws IOException;
+
+}
+```
+进行反编译(去除了一些没用信息)
+```java
+{
+ public static final int simpleFiled;
+ flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
+
+ public static final int staticField;
+ flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
+
+ public static void main(java.lang.String[]);
+ flags: (0x0009) ACC_PUBLIC, ACC_STATIC
+
+ public static void staticMethod();
+ flags: (0x0009) ACC_PUBLIC, ACC_STATIC
+
+ public void defaultMethod();
+ flags: (0x0001) ACC_PUBLIC
+
+ public abstract void simpleMethod() throws java.io.IOException;
+ flags: (0x0401) ACC_PUBLIC, ACC_ABSTRACT
+ Exceptions:
+ throws java.io.IOException
+}
+```
+可以看到 default关键字修饰的方法是像实例方法(就是普通类中定义的普通方法)一样定义的,所以我们来定义一个只有default方法的接口并且实现一下这个接口试一
+试。
+```java
+interface Default {
+ default int defaultMethod() {
+ return 4396;
+ }
+}
+
+public class DefaultMethod implements Default {
+ public static void main(String[] args) {
+ DefaultMethod defaultMethod = new DefaultMethod();
+ System.out.println(defaultMethod.defaultMethod());
+ //compile error : Non-static method 'defaultMethod()' cannot be referenced from a static context
+ //! DefaultMethod.defaultMethod();
+ }
+}
+```
+可以看到default方法确实像实例方法一样,必须有实例对象才能调用,并且子类在实现接口时,可以不用实现default方法,也可以选择覆盖该方法。
+这有点像子类继承父类实例方法。
+
+接口静态方法就像是类静态方法,唯一的区别是**接口静态方法只能通过接口名调用,而类静态方法既可以通过类名调用也可以通过实例调用**
+```java
+interface Static {
+ static int staticMethod() {
+ return 4396;
+ }
+}
+ ... main(String...args)
+ //!compile error: Static method may be invoked on containing interface class only
+ //!aInstanceOfStatic.staticMethod();
+ ...
+```
+另一个问题是多继承问题,大家知道Java中类是不支持多继承的,但是接口是多继承和多实现(implements后跟多个接口)的,
+那么如果一个接口继承另一个接口,两个接口都有同名的default方法会怎么样呢?答案是会像类继承一样覆写(@Override),以下代码在IDE中可以顺利编译
+```java
+interface Default {
+ default int defaultMethod() {
+ return 4396;
+ }
+}
+interface Default2 extends Default {
+ @Override
+ default int defaultMethod() {
+ return 9527;
+ }
+}
+public class DefaultMethod implements Default,Default2 {
+ public static void main(String[] args) {
+ DefaultMethod defaultMethod = new DefaultMethod();
+ System.out.println(defaultMethod.defaultMethod());
+ }
+}
+
+输出 : 9527
+```
+出现上面的情况时,会优先找继承树上近的方法,类似于“短路优先”。
+
+那么如果一个类实现了两个没有继承关系的接口,且这两个接口有同名方法的话会怎么样呢?IDE会要求你重写这个冲突的方法,让你自己选择去执行哪个方法,因为IDE它还没智能到你不告诉它,它就知道你想执行哪个方法。可以通过```java 接口名.super```指针来访问接口中定义的实例(default)方法。
+```java
+interface Default {
+ default int defaultMethod() {
+ return 4396;
+ }
+}
+
+interface Default2 {
+ default int defaultMethod() {
+ return 9527;
+ }
+}
+//如果不重写
+//compile error : defaults.DefaultMethod inherits unrelated defaults for defaultMethod() from types defaults.Default and defaults.Default2
+public class DefaultMethod implements Default,Default2 {
+@Override
+ public int defaultMethod() {
+ System.out.println(Default.super.defaultMethod());
+ System.out.println(Default2.super.defaultMethod());
+ return 996;
+ }
+ public static void main(String[] args) {
+ DefaultMethod defaultMethod = new DefaultMethod();
+ System.out.println(defaultMethod.defaultMethod());
+ }
+}
+
+运行输出 :
+4396
+9527
+996
+```
+
+
+___
+
+
+## 改进的类型推断
+### 1.什么是类型推断
+类型推断就像它的字面意思一样,编译器根据你显示声明的已知的信息 推断出你没有显示声明的类型,这就是类型推断。
+看过《Java编程思想 第四版》的朋友可能还记得里面讲解泛型一章的时候,里面很多例子是下面这样的:
+```java
+ Map map = new Map();
+```
+而我们平常写的都是这样的:
+```java
+ Map map = new Map<>();
+```
+这就是类型推断,《Java编程思想 第四版》这本书出书的时候最新的JDK只有1.6(JDK7推出的类型推断),在Java编程思想里Bruce Eckel大叔还提到过这个问题
+(可能JDK的官方人员看了Bruce Eckel大叔的Thinking in Java才加的类型推断,☺),在JDK7中推出了上面这样的类型推断,可以减少一些无用的代码。
+(Java编程思想到现在还只有第四版,是不是因为Bruce Eckel大叔觉得Java新推出的语言特性“然并卵”呢?/滑稽)
+
+在JDK7中,类型推断只有上面例子的那样的能力,即只有在使用**赋值语句**时才能自动推断出泛型参数信息(即<>里的信息),下面的官方文档里的例子在JDK7里会编译
+错误
+```java
+ List stringList = new ArrayList<>();
+ stringList.add("A");
+ //error : addAll(java.util.Collection)in List cannot be applied to (java.util.List)
+ stringList.addAll(Arrays.asList());
+```
+但是上面的代码在JDK8里可以通过,也就说,JDK8里,类型推断不仅可以用于赋值语句,而且可以根据代码中上下文里的信息推断出更多的信息,因此我们需要些的代码
+会更少。加强的类型推断还有一个就是用于Lambda表达式了。
+
+大家其实不必细究类型推断,在日常使用中IDE会自动判断,当IDE自己无法推断出足够的信息时,就需要我们额外做一下工作,比如在<>里添加更多的类型信息,
+相信随着Java的进化,这些便利的功能会越来越强大。
+
+
+____
+
+
+## 通过反射获得方法的参数信息
+JDK8之前 .class文件是不会存储方法参数信息的,因此也就无法通过反射获取该信息(想想反射获取类信息的入口是什么?当然就是Class类了)。即是是在JDK11里
+也不会默认生成这些信息,可以通过在javac加上-parameters参数来让javac生成这些信息(javac就是java编译器,可以把java文件编译成.class文件)。生成额外
+的信息(运行时非必须信息)会消耗内存并且有可能公布敏感信息(某些方法参数比如password,JDK文档里这么说的),并且确实很多信息javac并不会为我们生成,比如
+LocalVariableTable,javac就不会默认生成,需要你加上 -g:vars来强制让编译器生成,同样的,方法参数信息也需要加上
+-parameters来让javac为你在.class文件中生成这些信息,否则运行时反射是无法获取到这些信息的。在讲解Java语言层面的方法之前,先看一下javac加上该
+参数和不加生成的信息有什么区别(不感兴趣想直接看运行代码的可以跳过这段)。下面是随便写的一个类。
+```java
+public class ByteCodeParameters {
+ public String simpleMethod(String canUGetMyName, Object yesICan) {
+ return "9527";
+ }
+}
+```
+先来不加参数编译和反编译一下这个类javac ByteCodeParameters.java , javap -v ByteCodeParameters:
+```java
+ //只截取了部分信息
+ public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
+ descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
+ flags: (0x0001) ACC_PUBLIC
+ Code:
+ stack=1, locals=3, args_size=3
+ 0: ldc #2 // String 9527
+ 2: areturn
+ LineNumberTable:
+ line 5: 0
+ //这个方法的描述到这里就结束了
+```
+接下来我们加上参数javac -parameters ByteCodeParameters.java 再来看反编译的信息:
+```java
+ public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
+ descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
+ flags: (0x0001) ACC_PUBLIC
+ Code:
+ stack=1, locals=3, args_size=3
+ 0: ldc #2 // String 9527
+ 2: areturn
+ LineNumberTable:
+ line 8: 0
+ MethodParameters:
+ Name Flags
+ canUGetMyName
+ yesICan
+```
+可以看到.class文件里多了一个MethodParameters信息,这就是参数的名字,可以看到默认是不保存的。
+
下面看一下在Intelj Idea里运行的这个例子,我们试一下通过反射获取方法名 :
+```java
+public class ByteCodeParameters {
+ public String simpleMethod(String canUGetMyName, Object yesICan) {
+ return "9527";
+ }
+
+ public static void main(String[] args) throws NoSuchMethodException {
+ Class clazz = ByteCodeParameters.class;
+ Method simple = clazz.getDeclaredMethod("simpleMethod", String.class, Object.class);
+ Parameter[] parameters = simple.getParameters();
+ for (Parameter p : parameters) {
+ System.out.println(p.getName());
+ }
+ }
+}
+输出 :
+arg0
+arg1
+```
+???说好的方法名呢????别急,哈哈。前面说了,默认是不生成参数名信息的,因此我们需要做一些配置,我们找到IDEA的settings里的Java Compiler选项,在
+Additional command line parameters:一行加上-parameters(Eclipse 也是找到Java Compiler选中Stoer information about method parameters),或者自
+己编译一个.class文件放在IDEA的out下,然后再来运行 :
+```java
+输出 :
+canUGetMyName
+yesICan
+```
+这样我们就通过反射获取到参数信息了。想要了解更多的同学可以自己研究一下 [官方文档]
+(https://docs.oracle.com/javase/tutorial/reflect/member/methodparameterreflection.html)
+
+## 总结与补充
+在JDK8之后,可以通过-parameters参数来让编译器生成参数信息然后在运行时通过反射获取方法参数信息,其实在SpringFramework
+里面也有一个LocalVariableTableParameterNameDiscoverer对象可以获取方法参数名信息,有兴趣的同学可以自行百度(这个类在打印日志时可能会比较有用吧,个人感觉)。
+
+____
+
+
+
+
+___
diff --git a/docs/java/What's New in JDK8/Stream.md b/docs/java/What's New in JDK8/Stream.md
new file mode 100644
index 00000000000..de7c86e3f2e
--- /dev/null
+++ b/docs/java/What's New in JDK8/Stream.md
@@ -0,0 +1,75 @@
+Stream API 旨在让编码更高效率、干净、简洁。
+
+### 从迭代器到Stream操作
+
+当使用 `Stream` 时,我们一般会通过三个阶段建立一个流水线:
+
+1. 创建一个 `Stream`;
+2. 进行一个或多个中间操作;
+3. 使用终止操作产生一个结果,`Stream` 就不会再被使用了。
+
+**案例1:统计 List 中的单词长度大于6的个数**
+
+```java
+/**
+* 案例1:统计 List 中的单词长度大于6的个数
+*/
+ArrayList wordsList = new ArrayList();
+wordsList.add("Charles");
+wordsList.add("Vincent");
+wordsList.add("William");
+wordsList.add("Joseph");
+wordsList.add("Henry");
+wordsList.add("Bill");
+wordsList.add("Joan");
+wordsList.add("Linda");
+int count = 0;
+```
+Java8之前我们通常用迭代方法来完成上面的需求:
+
+```java
+//迭代(Java8之前的常用方法)
+//迭代不好的地方:1. 代码多;2 很难被并行运算。
+for (String word : wordsList) {
+ if (word.length() > 6) {
+ count++;
+ }
+}
+System.out.println(count);//3
+```
+Java8之前我们使用 `Stream` 一行代码就能解决了,而且可以瞬间转换为并行执行的效果:
+
+```java
+//Stream
+//将stream()改为parallelStream()就可以瞬间将代码编程并行执行的效果
+long count2=wordsList.stream()
+ .filter(w->w.length()>6)
+ .count();
+long count3=wordsList.parallelStream()
+ .filter(w->w.length()>6)
+ .count();
+System.out.println(count2);
+System.out.println(count3);
+```
+
+### `distinct()`
+
+去除 List 中重复的 String
+
+```java
+List list = list.stream()
+ .distinct()
+ .collect(Collectors.toList());
+```
+
+### `map`
+
+map 方法用于映射每个元素到对应的结果,以下代码片段使用 map 输出了元素对应的平方数:
+
+```java
+List numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
+// 获取 List 中每个元素对应的平方数并去重
+List squaresList = numbers.stream().map( i -> i*i).distinct().collect(Collectors.toList());
+System.out.println(squaresList.toString());//[9, 4, 49, 25]
+```
+
diff --git "a/docs/java/What's New in JDK8/\346\224\271\350\277\233\347\232\204\347\261\273\345\236\213\346\216\250\346\226\255.md" "b/docs/java/What's New in JDK8/\346\224\271\350\277\233\347\232\204\347\261\273\345\236\213\346\216\250\346\226\255.md"
new file mode 100644
index 00000000000..b5cff7bb0c0
--- /dev/null
+++ "b/docs/java/What's New in JDK8/\346\224\271\350\277\233\347\232\204\347\261\273\345\236\213\346\216\250\346\226\255.md"
@@ -0,0 +1,30 @@
+## 改进的类型推断
+### 1.什么是类型推断
+类型推断就像它的字面意思一样,编译器根据你显示声明的已知的信息 推断出你没有显示声明的类型,这就是类型推断。
+看过《Java编程思想 第四版》的朋友可能还记得里面讲解泛型一章的时候,里面很多例子是下面这样的:
+```java
+ Map map = new Map();
+```
+而我们平常写的都是这样的:
+```java
+ Map map = new Map<>();
+```
+这就是类型推断,《Java编程思想 第四版》这本书出书的时候最新的JDK只有1.6(JDK7推出的类型推断),在Java编程思想里Bruce Eckel大叔还提到过这个问题
+(可能JDK的官方人员看了Bruce Eckel大叔的Thinking in Java才加的类型推断,☺),在JDK7中推出了上面这样的类型推断,可以减少一些无用的代码。
+(Java编程思想到现在还只有第四版,是不是因为Bruce Eckel大叔觉得Java新推出的语言特性“然并卵”呢?/滑稽)
+
+在JDK7中,类型推断只有上面例子的那样的能力,即只有在使用**赋值语句**时才能自动推断出泛型参数信息(即<>里的信息),下面的官方文档里的例子在JDK7里会编译
+错误
+```java
+ List stringList = new ArrayList<>();
+ stringList.add("A");
+ //error : addAll(java.util.Collection)in List cannot be applied to (java.util.List)
+ stringList.addAll(Arrays.asList());
+```
+但是上面的代码在JDK8里可以通过,也就说,JDK8里,类型推断不仅可以用于赋值语句,而且可以根据代码中上下文里的信息推断出更多的信息,因此我们需要些的代码
+会更少。加强的类型推断还有一个就是用于Lambda表达式了。
+
+大家其实不必细究类型推断,在日常使用中IDE会自动判断,当IDE自己无法推断出足够的信息时,就需要我们额外做一下工作,比如在<>里添加更多的类型信息,
+相信随着Java的进化,这些便利的功能会越来越强大。
+
+
diff --git "a/docs/java/What's New in JDK8/\351\200\232\350\277\207\345\217\215\345\260\204\350\216\267\345\276\227\346\226\271\346\263\225\347\232\204\345\217\202\346\225\260\344\277\241\346\201\257.md" "b/docs/java/What's New in JDK8/\351\200\232\350\277\207\345\217\215\345\260\204\350\216\267\345\276\227\346\226\271\346\263\225\347\232\204\345\217\202\346\225\260\344\277\241\346\201\257.md"
new file mode 100644
index 00000000000..a1d91c4b2fe
--- /dev/null
+++ "b/docs/java/What's New in JDK8/\351\200\232\350\277\207\345\217\215\345\260\204\350\216\267\345\276\227\346\226\271\346\263\225\347\232\204\345\217\202\346\225\260\344\277\241\346\201\257.md"
@@ -0,0 +1,79 @@
+## 通过反射获得方法的参数信息
+JDK8之前 .class文件是不会存储方法参数信息的,因此也就无法通过反射获取该信息(想想反射获取类信息的入口是什么?当然就是Class类了)。即是是在JDK11里
+也不会默认生成这些信息,可以通过在javac加上-parameters参数来让javac生成这些信息(javac就是java编译器,可以把java文件编译成.class文件)。生成额外
+的信息(运行时非必须信息)会消耗内存并且有可能公布敏感信息(某些方法参数比如password,JDK文档里这么说的),并且确实很多信息javac并不会为我们生成,比如
+LocalVariableTable,javac就不会默认生成,需要你加上 -g:vars来强制让编译器生成,同样的,方法参数信息也需要加上
+-parameters来让javac为你在.class文件中生成这些信息,否则运行时反射是无法获取到这些信息的。在讲解Java语言层面的方法之前,先看一下javac加上该
+参数和不加生成的信息有什么区别(不感兴趣想直接看运行代码的可以跳过这段)。下面是随便写的一个类。
+```java
+public class ByteCodeParameters {
+ public String simpleMethod(String canUGetMyName, Object yesICan) {
+ return "9527";
+ }
+}
+```
+先来不加参数编译和反编译一下这个类javac ByteCodeParameters.java , javap -v ByteCodeParameters:
+```java
+ //只截取了部分信息
+ public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
+ descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
+ flags: (0x0001) ACC_PUBLIC
+ Code:
+ stack=1, locals=3, args_size=3
+ 0: ldc #2 // String 9527
+ 2: areturn
+ LineNumberTable:
+ line 5: 0
+ //这个方法的描述到这里就结束了
+```
+接下来我们加上参数javac -parameters ByteCodeParameters.java 再来看反编译的信息:
+```java
+ public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
+ descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
+ flags: (0x0001) ACC_PUBLIC
+ Code:
+ stack=1, locals=3, args_size=3
+ 0: ldc #2 // String 9527
+ 2: areturn
+ LineNumberTable:
+ line 8: 0
+ MethodParameters:
+ Name Flags
+ canUGetMyName
+ yesICan
+```
+可以看到.class文件里多了一个MethodParameters信息,这就是参数的名字,可以看到默认是不保存的。
+
下面看一下在Intelj Idea里运行的这个例子,我们试一下通过反射获取方法名 :
+```java
+public class ByteCodeParameters {
+ public String simpleMethod(String canUGetMyName, Object yesICan) {
+ return "9527";
+ }
+
+ public static void main(String[] args) throws NoSuchMethodException {
+ Class clazz = ByteCodeParameters.class;
+ Method simple = clazz.getDeclaredMethod("simpleMethod", String.class, Object.class);
+ Parameter[] parameters = simple.getParameters();
+ for (Parameter p : parameters) {
+ System.out.println(p.getName());
+ }
+ }
+}
+输出 :
+arg0
+arg1
+```
+???说好的方法名呢????别急,哈哈。前面说了,默认是不生成参数名信息的,因此我们需要做一些配置,我们找到IDEA的settings里的Java Compiler选项,在
+Additional command line parameters:一行加上-parameters(Eclipse 也是找到Java Compiler选中Stoer information about method parameters),或者自
+己编译一个.class文件放在IDEA的out下,然后再来运行 :
+```java
+输出 :
+canUGetMyName
+yesICan
+```
+这样我们就通过反射获取到参数信息了。想要了解更多的同学可以自己研究一下 [官方文档]
+(https://docs.oracle.com/javase/tutorial/reflect/member/methodparameterreflection.html)
+
+## 总结与补充
+在JDK8之后,可以通过-parameters参数来让编译器生成参数信息然后在运行时通过反射获取方法参数信息,其实在SpringFramework
+里面也有一个LocalVariableTableParameterNameDiscoverer对象可以获取方法参数名信息,有兴趣的同学可以自行百度(这个类在打印日志时可能会比较有用吧,个人感觉)。
diff --git "a/Java\347\233\270\345\205\263/ArrayList-Grow.md" b/docs/java/collection/ArrayList-Grow.md
similarity index 98%
rename from "Java\347\233\270\345\205\263/ArrayList-Grow.md"
rename to docs/java/collection/ArrayList-Grow.md
index d763cb83492..06fa5388d76 100644
--- "a/Java\347\233\270\345\205\263/ArrayList-Grow.md"
+++ b/docs/java/collection/ArrayList-Grow.md
@@ -145,7 +145,7 @@
}
```
-**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍!** 记清楚了!不是网上很多人说的 1.5 倍+1!
+**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍!(JDK1.6版本以后)** JDk1.6版本时,扩容之后容量为 1.5 倍+1!详情请参考源码
> ">>"(移位运算符):>>1 右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
@@ -270,7 +270,6 @@ public class ArrayscopyOfTest {
10
```
-
### 3.3 两者联系和区别
**联系:**
@@ -281,8 +280,6 @@ public class ArrayscopyOfTest {
`arraycopy()` 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 `copyOf()` 是系统自动在内部新建一个数组,并返回该数组。
-
-
## 四 `ensureCapacity`方法
ArrayList 源码中有一个 `ensureCapacity` 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
@@ -341,7 +338,6 @@ public class EnsureCapacityTest {
```
使用ensureCapacity方法前:4637
使用ensureCapacity方法后:241
-
```
通过运行结果,我们可以很明显的看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量重新分配的次数
diff --git "a/Java\347\233\270\345\205\263/ArrayList.md" b/docs/java/collection/ArrayList.md
similarity index 98%
rename from "Java\347\233\270\345\205\263/ArrayList.md"
rename to docs/java/collection/ArrayList.md
index c3e8dd47896..f6578a7a784 100644
--- "a/Java\347\233\270\345\205\263/ArrayList.md"
+++ b/docs/java/collection/ArrayList.md
@@ -660,7 +660,7 @@ public class ArrayList extends AbstractList
(3)private class SubList extends AbstractList implements RandomAccess
(4)static final class ArrayListSpliterator implements Spliterator
```
- ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**,**next()**,**remove()**等方法;其中的**ListItr**继承**Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**,**nextIndex()**,**previousIndex()**,**previous()**,**set(E e)**,**add(E e)**等方法,所以这也可以看出了 **Iterator和ListIterator的区别:**ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
+ ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**, **next()**, **remove()** 等方法;其中的**ListItr** 继承 **Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**, **nextIndex()**, **previousIndex()**, **previous()**, **set(E e)**, **add(E e)** 等方法,所以这也可以看出了 **Iterator和ListIterator的区别:** ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
### ArrayList经典Demo
```java
diff --git "a/Java\347\233\270\345\205\263/HashMap.md" b/docs/java/collection/HashMap.md
similarity index 99%
rename from "Java\347\233\270\345\205\263/HashMap.md"
rename to docs/java/collection/HashMap.md
index 45fad50cdb3..716bb1f34a5 100644
--- "a/Java\347\233\270\345\205\263/HashMap.md"
+++ b/docs/java/collection/HashMap.md
@@ -235,7 +235,7 @@ HashMap只提供了put用于添加元素,putVal方法只是给put方法调用
**对putVal方法添加元素的分析如下:**
- ①如果定位到的数组位置没有元素 就直接插入。
-- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用`e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入。
+- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用`e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
diff --git "a/docs/java/collection/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md" "b/docs/java/collection/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md"
new file mode 100644
index 00000000000..031f82e80d7
--- /dev/null
+++ "b/docs/java/collection/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md"
@@ -0,0 +1,456 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
+
+
+
+- [剖析面试最常见问题之Java基础知识](#剖析面试最常见问题之java基础知识)
+ - [说说List,Set,Map三者的区别?](#说说listsetmap三者的区别)
+ - [Arraylist 与 LinkedList 区别?](#arraylist-与-linkedlist-区别)
+ - [补充内容:RandomAccess接口](#补充内容randomaccess接口)
+ - [补充内容:双向链表和双向循环链表](#补充内容双向链表和双向循环链表)
+ - [ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢?](#arraylist-与-vector-区别呢为什么要用arraylist取代vector呢)
+ - [说一说 ArrayList 的扩容机制吧](#说一说-arraylist-的扩容机制吧)
+ - [HashMap 和 Hashtable 的区别](#hashmap-和-hashtable-的区别)
+ - [HashMap 和 HashSet区别](#hashmap-和-hashset区别)
+ - [HashSet如何检查重复](#hashset如何检查重复)
+ - [HashMap的底层实现](#hashmap的底层实现)
+ - [JDK1.8之前](#jdk18之前)
+ - [JDK1.8之后](#jdk18之后)
+ - [HashMap 的长度为什么是2的幂次方](#hashmap-的长度为什么是2的幂次方)
+ - [HashMap 多线程操作导致死循环问题](#hashmap-多线程操作导致死循环问题)
+ - [ConcurrentHashMap 和 Hashtable 的区别](#concurrenthashmap-和-hashtable-的区别)
+ - [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](#concurrenthashmap线程安全的具体实现方式底层具体实现)
+ - [JDK1.7(上面有示意图)](#jdk17上面有示意图)
+ - [JDK1.8 (上面有示意图)](#jdk18-上面有示意图)
+ - [comparable 和 Comparator的区别](#comparable-和-comparator的区别)
+ - [Comparator定制排序](#comparator定制排序)
+ - [重写compareTo方法实现按年龄来排序](#重写compareto方法实现按年龄来排序)
+ - [集合框架底层数据结构总结](#集合框架底层数据结构总结)
+ - [Collection](#collection)
+ - [1. List](#1-list)
+ - [2. Set](#2-set)
+ - [Map](#map)
+ - [如何选用集合?](#如何选用集合)
+
+
+
+# 剖析面试最常见问题之Java基础知识
+
+## 说说List,Set,Map三者的区别?
+
+- **List(对付顺序的好帮手):** List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
+- **Set(注重独一无二的性质):** 不允许重复的集合。不会有多个元素引用相同的对象。
+- **Map(用Key来搜索的专家):** 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
+
+## Arraylist 与 LinkedList 区别?
+
+- **1. 是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
+
+- **2. 底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
+
+- **3. 插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
+
+- **4. 是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
+
+- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
+
+### **补充内容:RandomAccess接口**
+
+```java
+public interface RandomAccess {
+}
+```
+
+查看源码我们发现实际上 `RandomAccess` 接口中什么都没有定义。所以,在我看来 `RandomAccess` 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
+
+在 `binarySearch(`)方法中,它要判断传入的list 是否 `RamdomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
+
+```java
+ public static
+ int binarySearch(List> list, T key) {
+ if (list instanceof RandomAccess || list.size() MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+ this.loadFactor = loadFactor;
+ this.threshold = tableSizeFor(initialCapacity);
+ }
+ public HashMap(int initialCapacity) {
+ this(initialCapacity, DEFAULT_LOAD_FACTOR);
+ }
+```
+
+下面这个方法保证了 HashMap 总是使用2的幂作为哈希表的大小。
+
+```java
+ /**
+ * Returns a power of two size for the given target capacity.
+ */
+ static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+```
+
+## HashMap 和 HashSet区别
+
+如果你看过 `HashSet` 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 `clone() `、`writeObject()`、`readObject()`是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
+
+| HashMap | HashSet |
+| :------------------------------: | :----------------------------------------------------------: |
+| 实现了Map接口 | 实现Set接口 |
+| 存储键值对 | 仅存储对象 |
+| 调用 `put()`向map中添加元素 | 调用 `add()`方法向Set中添加元素 |
+| HashMap使用键(Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性, |
+
+## HashSet如何检查重复
+
+当你把对象加入`HashSet`时,HashSet会先计算对象的`hashcode`值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用`equals()`方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。(摘自我的Java启蒙书《Head fist java》第二版)
+
+**hashCode()与equals()的相关规定:**
+
+1. 如果两个对象相等,则hashcode一定也是相同的
+2. 两个对象相等,对两个equals方法返回true
+3. 两个对象有相同的hashcode值,它们也不一定是相等的
+4. 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
+5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
+
+**==与equals的区别**
+
+1. ==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
+2. ==是指对内存地址进行比较 equals()是对字符串的内容进行比较
+3. ==指引用是否相同 equals()指的是值是否相同
+
+## HashMap的底层实现
+
+### JDK1.8之前
+
+JDK1.8 之前 `HashMap` 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
+
+**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
+
+**JDK 1.8 HashMap 的 hash 方法源码:**
+
+JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
+
+```java
+ static final int hash(Object key) {
+ int h;
+ // key.hashCode():返回散列值也就是hashcode
+ // ^ :按位异或
+ // >>>:无符号右移,忽略符号位,空位都以0补齐
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+ }
+```
+
+对比一下 JDK1.7的 HashMap 的 hash 方法源码.
+
+```java
+static int hash(int h) {
+ // This function ensures that hashCodes that differ only by
+ // constant multiples at each bit position have a bounded
+ // number of collisions (approximately 8 at default load factor).
+
+ h ^= (h >>> 20) ^ (h >>> 12);
+ return h ^ (h >>> 7) ^ (h >>> 4);
+}
+```
+
+相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
+
+所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
+
+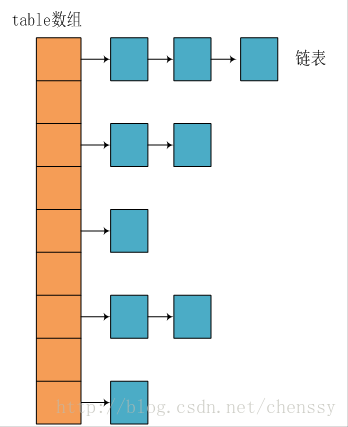
+
+### JDK1.8之后
+
+相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
+
+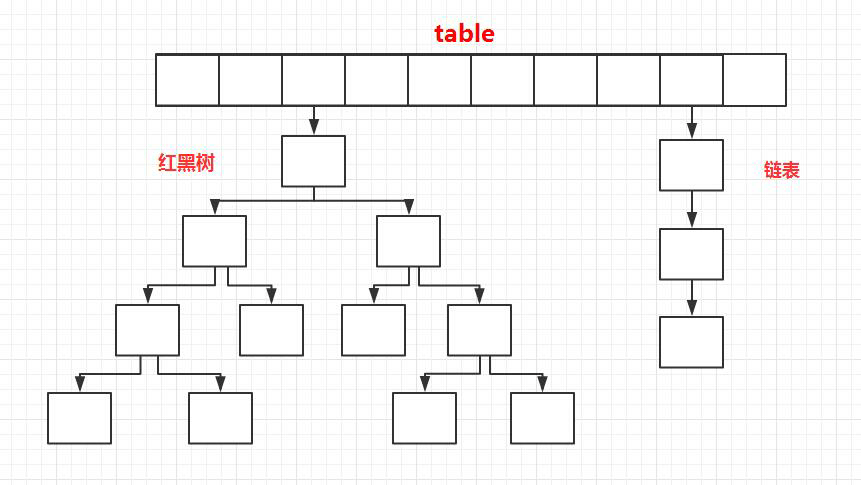
+
+> TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
+
+**推荐阅读:**
+
+- 《Java 8系列之重新认识HashMap》 :
+
+## HashMap 的长度为什么是2的幂次方
+
+为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
+
+**这个算法应该如何设计呢?**
+
+我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。**
+
+## HashMap 多线程操作导致死循环问题
+
+主要原因在于 并发下的Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
+
+详情请查看:
+
+## ConcurrentHashMap 和 Hashtable 的区别
+
+ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
+
+- **底层数据结构:** JDK1.7的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
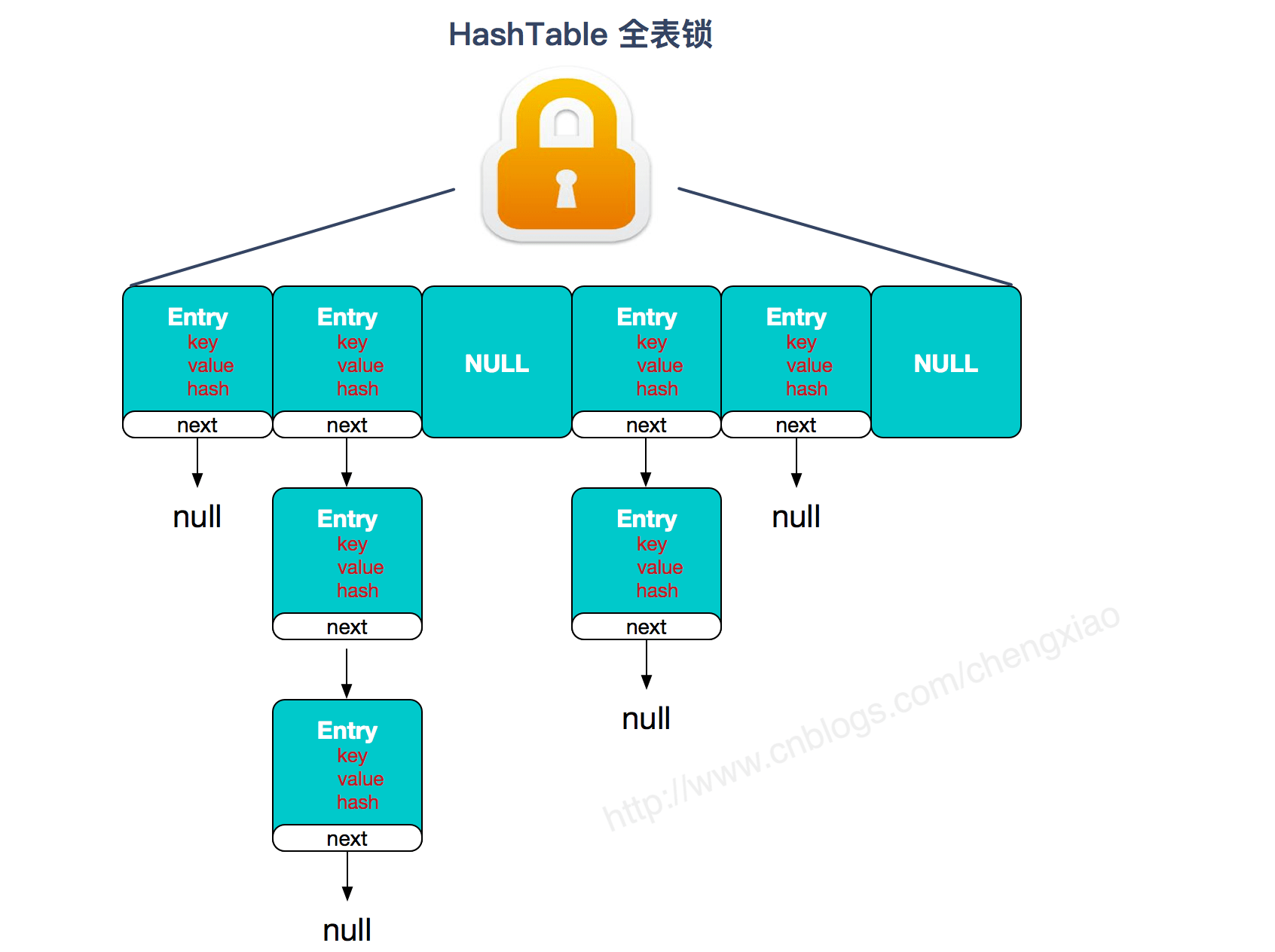
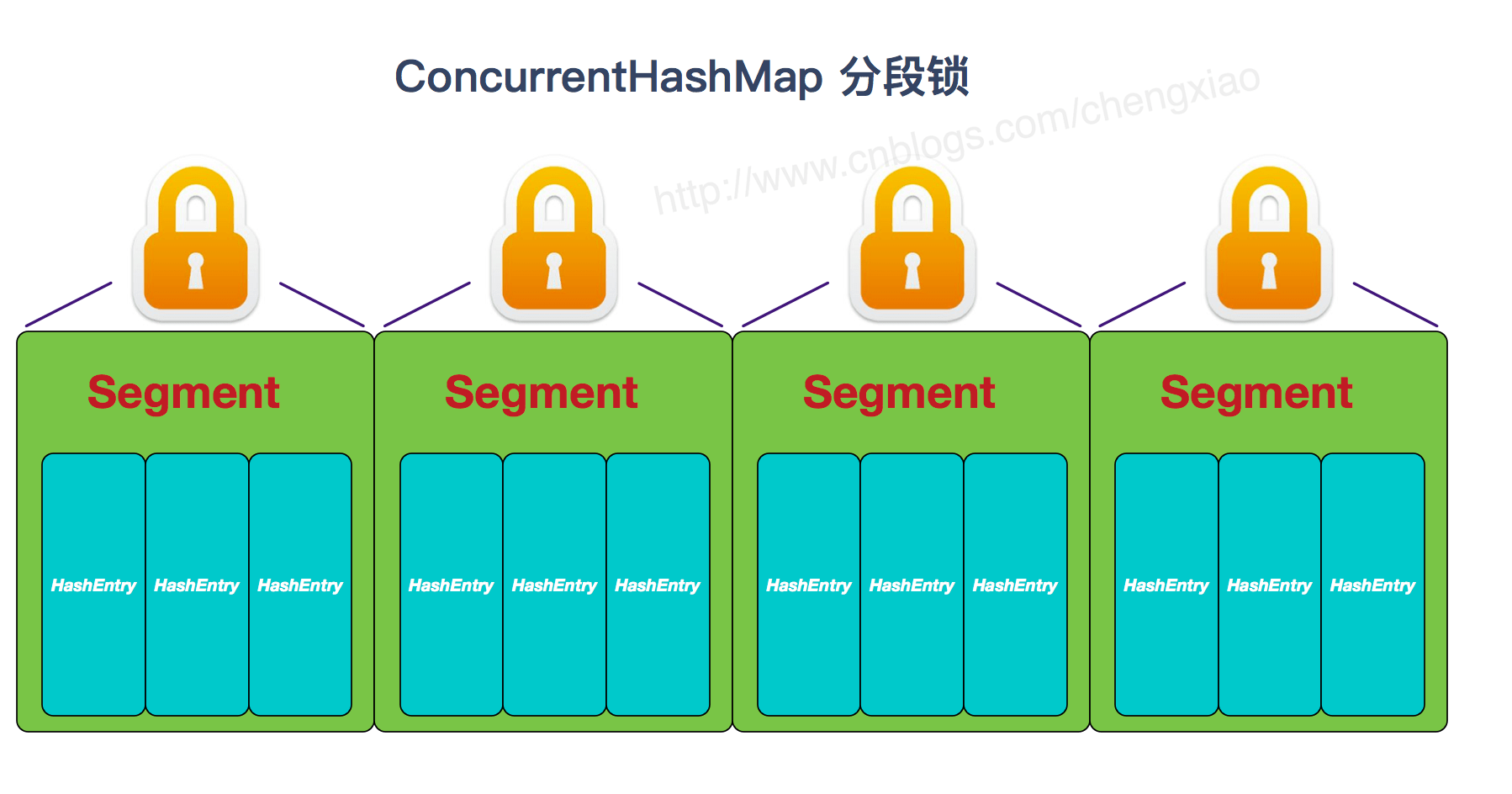
+- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
+
+**两者的对比图:**
+
+图片来源:
+
+**HashTable:**
+
+
+
+**JDK1.7的ConcurrentHashMap:**
+
+
+
+**JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点):**
+
+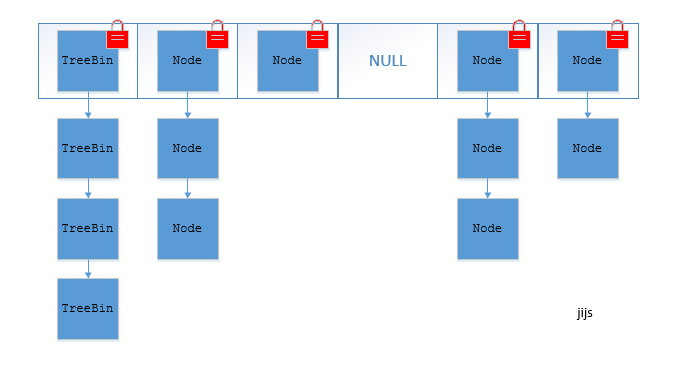
+
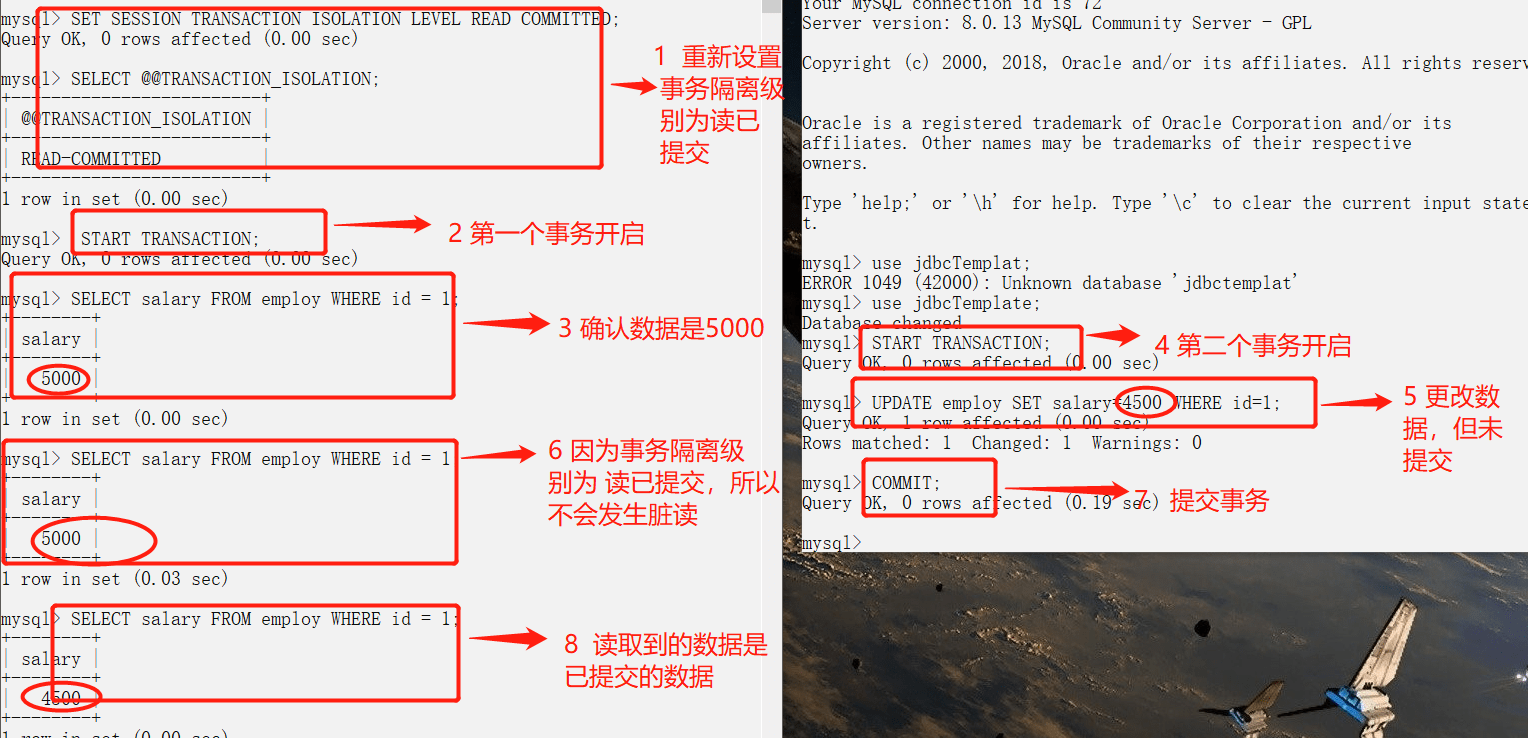
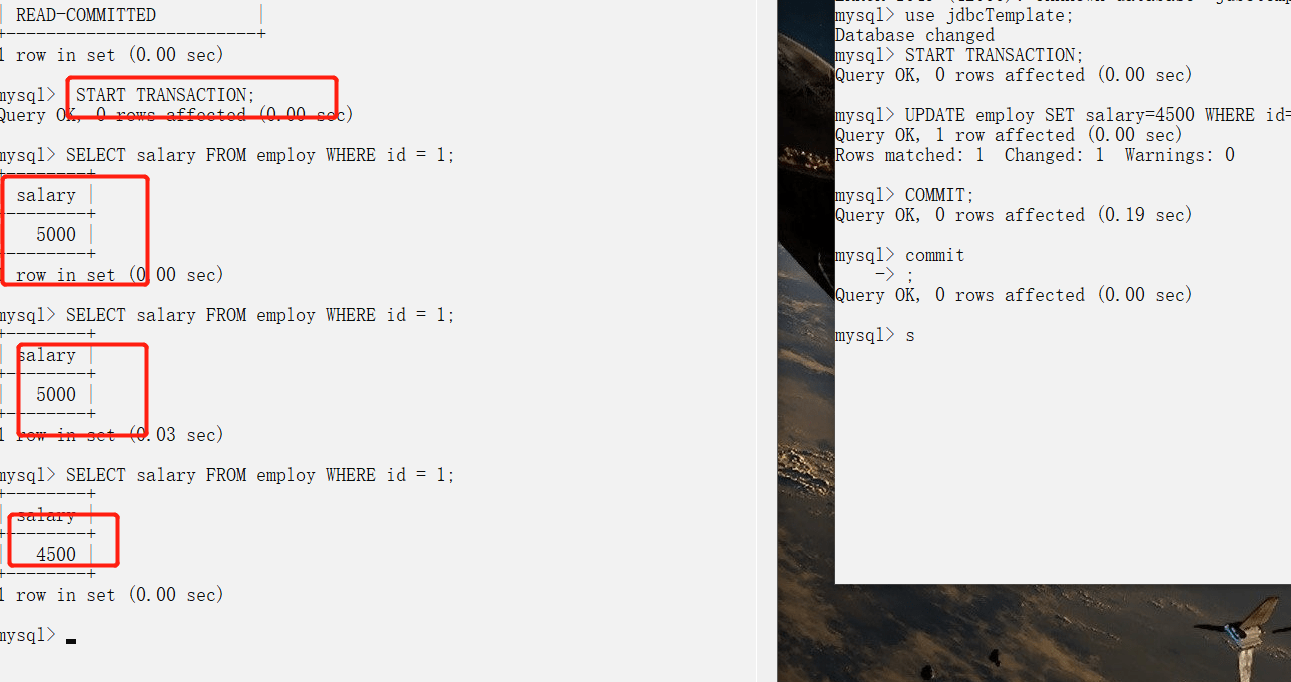
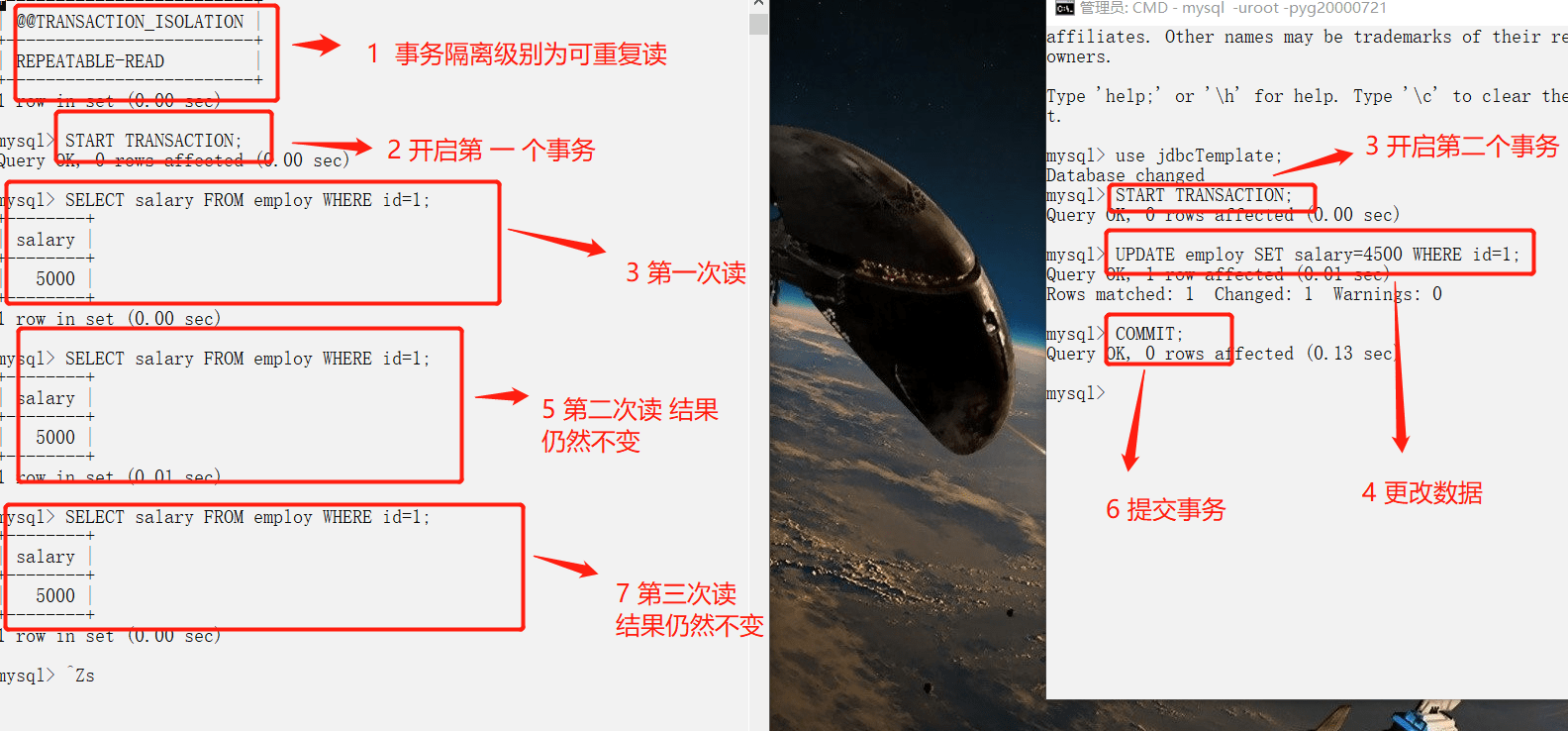
+## ConcurrentHashMap线程安全的具体实现方式/底层具体实现
+
+### JDK1.7(上面有示意图)
+
+首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
+
+**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
+
+Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
+
+```java
+static class Segment
 -
-
-
- +
+
+
+ +
+
+
+ +
+
+
+ 
 +
+
+
+ 
 @@ -260,9 +318,25 @@
@@ -260,9 +318,25 @@
 +
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
### 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
\ No newline at end of file
diff --git a/docs/.nojekyll b/docs/.nojekyll
new file mode 100644
index 00000000000..e69de29bb2d
diff --git a/docs/HomePage.md b/docs/HomePage.md
new file mode 100644
index 00000000000..55000c08dee
--- /dev/null
+++ b/docs/HomePage.md
@@ -0,0 +1,242 @@
+点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/./9BJjNsNg7S4dCnz3/)
+
+
+
### 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
\ No newline at end of file
diff --git a/docs/.nojekyll b/docs/.nojekyll
new file mode 100644
index 00000000000..e69de29bb2d
diff --git a/docs/HomePage.md b/docs/HomePage.md
new file mode 100644
index 00000000000..55000c08dee
--- /dev/null
+++ b/docs/HomePage.md
@@ -0,0 +1,242 @@
+点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/./9BJjNsNg7S4dCnz3/)
+
+ +
+实例.jpg) +
+ +
+ +
+ +
+.jpg) +
+