添加中文版README, we need a Chinese version of README #361
Comments
|
我先做一版翻译的初稿吧 |
欢迎来到PyPOTS一个致力于部分观测时间序列(POTS)机器学习任务的Python工具箱
⦿ ⦿ 🤗 如果您认为PyPOTS是一个有用的工具箱,请将该项目设为星标🌟,以帮助更多人关注到它。 该说明文档的后续内容如下: ❖ 支持的算法PyPOTS当前支持多变量POTS的填充,分类,聚类,预测以及异常检测任务。下表描述了当前PyPOTS中所集成的算法以及对应支持的任务类型。 🌟 在 v0.2版本更新后, PyPOTS中所有神经网络模型都具备超参数优化功能。此功能基于 Microsoft NNI 框架实现。 🔥 请注意:Transformer, Crossformer, PatchTST, DLinear, ETSformer, FEDformer, Informer, Autoformer 模型在其原始论文中并未提出如何用作填充方法,并且这些模型也不接受POTS作为输入。
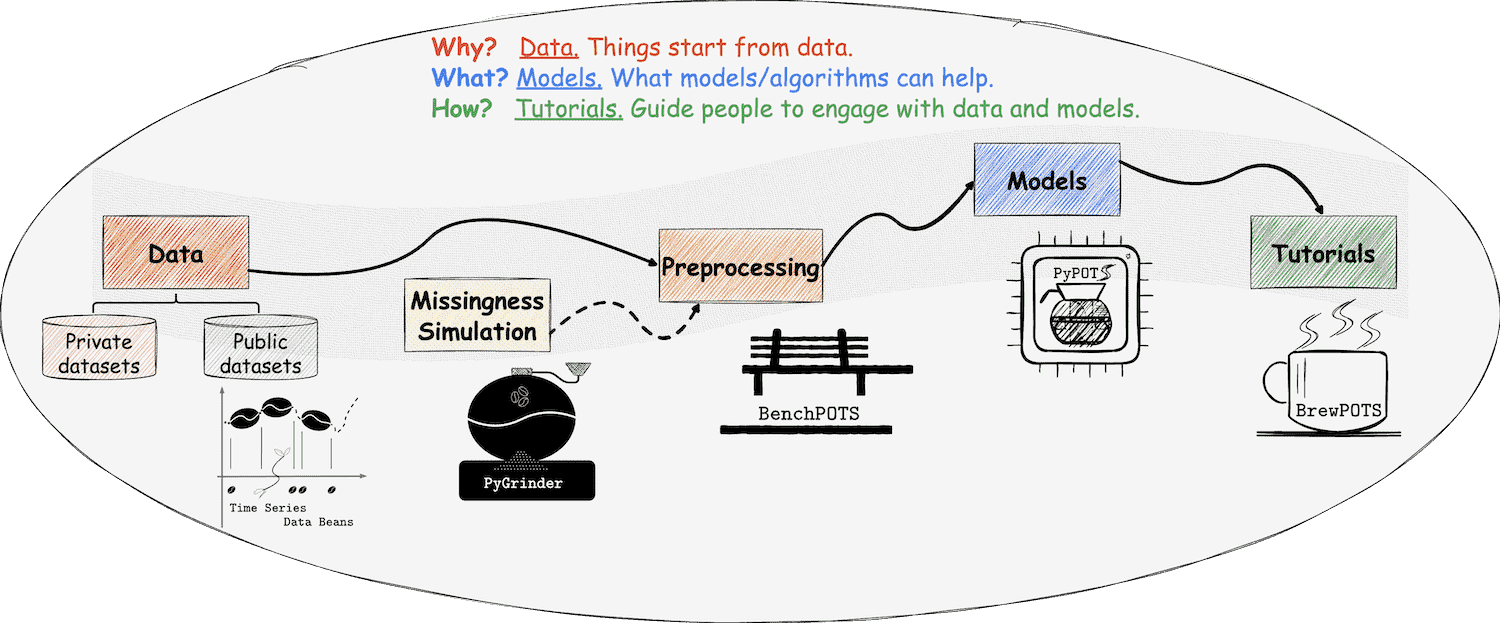
❖ PyPOTS 生态系统在PyPOTS生态系统中,一切都与我们熟悉的咖啡息息相关,甚至可以将其视为一杯咖啡的诞生过程! 👈 在PyPOTS中,时间序列数据集可以被看作咖啡豆,而POTS数据集则是带缺失部分的不完整咖啡豆。 👉 为了在真实数据中模拟缺失进而获得不完整的咖啡豆,我们创建了生态系统中的另一个库:PyGrinder(可以将其视为磨豆机), 👈 现在我们有了咖啡豆、磨豆机和咖啡壶,那么如何给自己冲一杯咖啡呢?冲泡教程是必不可少的!考虑到未来的工作量,
❖ 安装说明您可以参考PyPOTS文档中的 安装说明 以获取更详细的指南。 # 通过 pip
pip install pypots # 首次安装
pip install pypots --upgrade # 更新为最新版本
# 利用最新源代码安装,可能带有尚未正式发布的最新功能
pip install https://github.com/WenjieDu/PyPOTS/archive/main.zip
# 通过 conda
conda install -c conda-forge pypots # 首次安装
conda update -c conda-forge pypots # 更新为最新版本❖ 应用案例除了 BrewPOTS 之外, 您还可以在 Google Colab 点击此处查看 SAITS 模型应用于 PhysioNet2012 数据集填充任务的简单案例:# 数据预处理,可以用PyPOTS处理繁琐过程。
import numpy as np
from sklearn.preprocessing import StandardScaler
from pygrinder import mcar
from pypots.data import load_specific_dataset
data = load_specific_dataset('physionet_2012') # PyPOTS 将自动下载和解压数据
X = data['X']
num_samples = len(X['RecordID'].unique())
X = X.drop(['RecordID', 'Time'], axis = 1)
X = StandardScaler().fit_transform(X.to_numpy())
X = X.reshape(num_samples, 48, -1)
X_ori = X # keep X_ori for validation
X = mcar(X, 0.1) # 随机将观测值的10%掩盖,作为基准数据
dataset = {"X": X} # X 用于模型输入
print(X.shape) # (11988, 48, 37), 11988 samples and each sample has 48 time steps, 37 features
# 模型训练,开始应用PyPOTS.
from pypots.imputation import SAITS
from pypots.utils.metrics import calc_mae
saits = SAITS(n_steps=48, n_features=37, n_layers=2, d_model=256, d_ffn=128, n_heads=4, d_k=64, d_v=64, dropout=0.1, epochs=10)
# 因为基准数据对模型不可知,将整个数据集作为训练集, 也可以把数据集分为训练/验证/测试集
saits.fit(dataset) # 基于数据集训练模型
imputation = saits.impute(dataset) # 填充数据集中原始缺失部分和人为掩盖缺失部分
indicating_mask = np.isnan(X) ^ np.isnan(X_ori) # 用于计算填充误差的掩码矩阵
mae = calc_mae(imputation, np.nan_to_num(X_ori), indicating_mask) #计算人为掩盖部分数据的平均绝对误差
saits.save("save_it_here/saits_physionet2012.pypots") # 保存模型
saits.load("save_it_here/saits_physionet2012.pypots") # 重新加载序列化的模型文件以进行后续的填充或训练❖ 引用PyPOTS
介绍PyPOTS的论文可以通过该 地址 在arXiv上获取,我们正在努力将其发表在更具影响力的学术期刊上, 据不完全统计,该 列表 为当前使用PyPOTS并在其论文中进行引用的科学研究项目 @article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
year={2023},
eprint={2305.18811},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2305.18811},
doi={10.48550/arXiv.2305.18811},
}或者
❖ 贡献声明非常欢迎您为这个优质的项目做出贡献!
您也可以通过为该项目设置星标🌟 ,帮助更多人关注它。
👏 点击这里可以查看PyPOTS当前的星标者和分支者
|










|
hi ,我按照自己的理解修改了几个部分:
|
|
建议专业术语和专有名词给出英语的全称和简称,我的主要修改如下: ❖支持的算法PyPOTS 支持对多变量部分观测时间序列进行插补、分类、聚类、预测和异常检测。下表显示了 PyPOTS 中每个算法在不同任务中的可用性。符号 ✅ 表示该算法可用于相应的任务(请注意,模型将来会不断更新以处理当前不支持的任务。敬请关注❗️) 根据 Robin 的理论,缺失模式分为三类:完全随机缺失(missing completely at random,简称为MCAR)、随机缺失(missing at random,简称为MAR)和非随机缺失(missing not at random,简称为MNAR )。 ❖应用案例示例代码的第一个注释建议修改为:使用PyPOTS帮助完成繁琐的数据预处理 |
|
汇总了一下近期各位伙伴们给出的修改建议,下面是 中文ReadmeV2.0,再一起看看还有没有润色改进的空间! |
欢迎来到PyPOTS一个致力于部分观测时间序列(POTS)机器学习任务的Python工具箱
⦿ 🤗 如果您认为PyPOTS是一个有用的工具箱,请将该项目设为星标🌟,以帮助它被更多人所了解。 该说明文档的后续内容如下: ❖ 支持的算法PyPOTS当前支持多变量POTS数据的插补,预测,分类,聚类以及异常检测五类任务。下表描述了当前PyPOTS中所集成的算法以及对应不同任务的可用性。 🌟 在 v0.2版本更新后, PyPOTS中所有神经网络模型都支持超参数优化。此功能基于 Microsoft NNI 框架实现。 🔥 请注意:Transformer, Crossformer, PatchTST, DLinear, ETSformer, FEDformer, Informer, Autoformer 模型在其原始论文中并未提及用作插补方法,并且这些模型也不接受POTS数据作为输入。
❖ PyPOTS 生态系统在PyPOTS生态系统中,一切都与我们熟悉的咖啡息息相关,甚至可以将其视为一杯咖啡的诞生过程! 👈 在PyPOTS中,时间序列数据可以被看作一连串的咖啡豆,而POTS数据则是带缺失部分的不完整咖啡豆。 👉 为了在真实数据中模拟缺失进而获得不完整的咖啡豆,我们创建了生态系统中的另一个库:PyGrinder(可以将其视为磨豆机), 👈 现在我们有了咖啡豆、磨豆机和咖啡壶,那么如何给自己冲一杯咖啡呢?冲泡教程是必不可少的!考虑到未来的工作量,
❖ 安装教程您可以参考PyPOTS文档中的 安装说明 以获取更详细的指南。 # 通过 pip
pip install pypots # 首次安装
pip install pypots --upgrade # 更新为最新版本
# 利用最新源代码安装最新版本,可能带有尚未正式发布的最新功能
pip install https://github.com/WenjieDu/PyPOTS/archive/main.zip
# 通过 conda
conda install -c conda-forge pypots # 首次安装
conda update -c conda-forge pypots # 更新为最新版本❖ 使用案例除了 BrewPOTS 之外, 您还可以在 Google Colab 点击此处查看 SAITS 模型应用于 PhysioNet2012 数据集插补任务的简单案例:# 数据预处理,使用PyPOTS生态帮助完成繁琐的数据预处理。
import numpy as np
from sklearn.preprocessing import StandardScaler
from pygrinder import mcar
from pypots.data import load_specific_dataset
data = load_specific_dataset('physionet_2012') # PyPOTS 将自动下载和解压数据
X = data['X']
num_samples = len(X['RecordID'].unique())
X = X.drop(['RecordID', 'Time'], axis = 1)
X = StandardScaler().fit_transform(X.to_numpy())
X = X.reshape(num_samples, 48, -1)
X_ori = X # keep X_ori for validation
X = mcar(X, 0.1) # 随机掩盖观测值的10%,作为基准数据
dataset = {"X": X} # X 用于模型输入
print(X.shape) # (11988, 48, 37), 11988 samples and each sample has 48 time steps, 37 features
# 模型训练,开始应用PyPOTS.
from pypots.imputation import SAITS
from pypots.utils.metrics import calc_mae
saits = SAITS(n_steps=48, n_features=37, n_layers=2, d_model=256, d_ffn=128, n_heads=4, d_k=64, d_v=64, dropout=0.1, epochs=10)
# 因为基准数据对模型不可知,将整个数据集作为训练集, 也可以把数据集分为训练/验证/测试集
saits.fit(dataset) # 基于数据集训练模型
imputation = saits.impute(dataset) # 插补数据集中原始缺失部分和人为掩盖缺失部分
indicating_mask = np.isnan(X) ^ np.isnan(X_ori) # 用于计算插补误差的掩码矩阵
mae = calc_mae(imputation, np.nan_to_num(X_ori), indicating_mask) #计算人为掩盖部分数据的平均绝对误差
saits.save("save_it_here/saits_physionet2012.pypots") # 保存模型
saits.load("save_it_here/saits_physionet2012.pypots") # 重新加载序列化的模型文件以进行后续的插补或训练❖ 引用PyPOTS
介绍PyPOTS的论文可以通过该 地址 在arXiv上获取,我们正在努力将其发表在更具影响力的学术期刊上, 据不完全统计,该 列表 为当前使用PyPOTS并在其论文中引用PyPOTS的科学研究项目 @article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
year={2023},
eprint={2305.18811},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2305.18811},
doi={10.48550/arXiv.2305.18811},
}或者
❖ 贡献声明非常欢迎您为这个有趣的项目做出贡献!
您也可以通过为该项目设置星标🌟 ,帮助更多人关注它。
👏 点击这里可以查看PyPOTS当前的星标者和分支者
|
|
谢谢佳欣 @Justin0388,也谢谢思佳和海涛的建议! 佳欣请新建一个PR把最新版本提交,新建文件名为 再次感谢大家的贡献!🤗 |
Issue description
为了方便国内中文用户的使用以及中文的检索,我们需要一个中文版本的README
The text was updated successfully, but these errors were encountered: