{kind=link}
This software implements the Convolutional Recurrent Neural Network (CRNN), a combination of CNN, RNN and CTC loss for image-based sequence recognition tasks, such as scene text recognition and OCR.
https://arxiv.org/abs/1507.05717
More details for CRNN and CTC loss (in chinese): https://zhuanlan.zhihu.com/p/43534801
The crnn+seq2seq+attention ocr code can be found here bai-shang/crnn_seq2seq_ocr_pytorch
All dependencies should be installed are as follow:
- Python3
- tensorflow==1.15.0
- opencv-python
- numpy
Required packages can be installed with
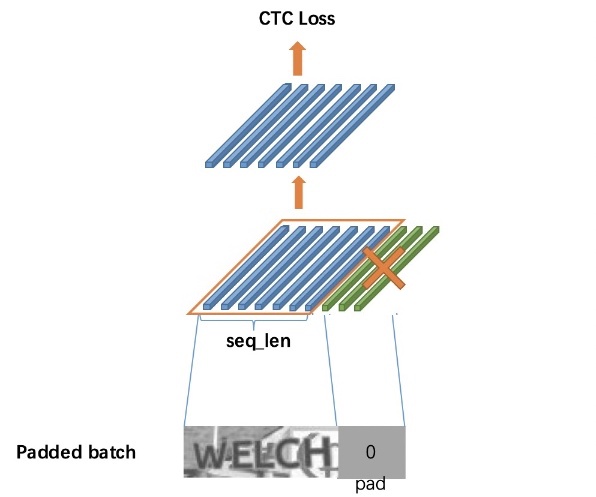
pip3 install -r requirements.txtNote: This code cannot run on the tensorflow2.0 since it's modified the 'tf.nn.ctc_loss' API.
Asume your current work directory is "crnn_ctc_ocr_tf":
cd path/to/your/crnn_ctc_ocr_tf/Dowload pretrained model and extract it to your disc: GoogleDrive .
Export current work directory path into PYTHONPATH:
export PYTHONPATH=$PYTHONPATH:./Run inference demo:
python3 tools/inference_crnn_ctc.py \
--image_dir ./test_data/images/ --image_list ./test_data/image_list.txt \
--model_dir /path/to/your/bs_synth90k_model/ 2>/dev/nullResult is:
Predict 1_AFTERSHAVE_1509.jpg image as: aftershave

Predict 2_LARIAT_43420.jpg image as: lariat

-
Firstly you need download Synth90k datasets and extract it into a folder.
-
Secondly supply a txt file to specify the relative path to the image data dir and it's corresponding text label.
For example: image_list.txt
90kDICT32px/1/2/373_coley_14845.jpg coley
90kDICT32px/17/5/176_Nevadans_51437.jpg nevadans- Then you suppose to convert your dataset to tfrecord format can be done by
python3 tools/create_crnn_ctc_tfrecord.py \
--image_dir path/to/90kDICT32px/ --anno_file path/to/image_list.txt --data_dir ./tfrecords/ \
--validation_split_fraction 0.1Note: make sure that images can be read from the path you specificed. For example:
path/to/90kDICT32px/1/2/373_coley_14845.jpg
path/to/90kDICT32px/17/5/176_Nevadans_51437.jpg
.......All training images will be scaled into height 32pix and write to tfrecord file.
The dataset will be divided into train and validation set and you can change the parameter to control the ratio of them.
Otherwise you can use the dowload_synth90k_and_create_tfrecord.sh script automatically create tfrecord:
cd ./data
sh dowload_synth90k_and_create_tfrecord.sh
python3 tools/train_crnn_ctc.py --data_dir ./tfrecords/ --model_dir ./model/ --batch_size 32After several times of iteration you can check the output in terminal as follow:

During my experiment the loss drops as follow:

python3 tools/eval_crnn_ctc.py --data_dir ./tfrecords/ --model_dir ./model/ 2>/dev/null