This is the 3rd place solution code for the Wikipedia - Image/Caption Matching Competition on Kaggle.
This repo consist of two main parts:
-
This folder contains notebooks carrying out
- data preparation,
- filtering, and
- ranking.
Some of the notebooks presented here process only a part of data, but should serve as templates for processing the rest data, and are marked with 🧩.
-
This is a package providing functionality for filtering by searching for possible matches between images and text candidates. The filtering procedure is based on several heuristic rankers estimating matching rates.
This stage is an offline pipeline for precomputing various data used in the sequel for filtering and feature engineering.
Translation is performed by GoogleTranslator from deep-translator.
Sentence Embeddings (SEs) and Image-Text Embeddings (ITEs) are computed by pre-trained models from SentenceTransformers.
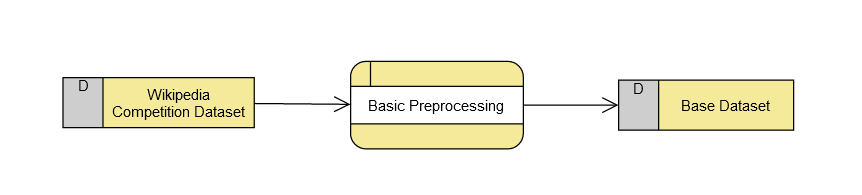
The base training dataset contains 69,480 records for images and 301,664 records for its textual candidates made from page_title and caption_reference_description.

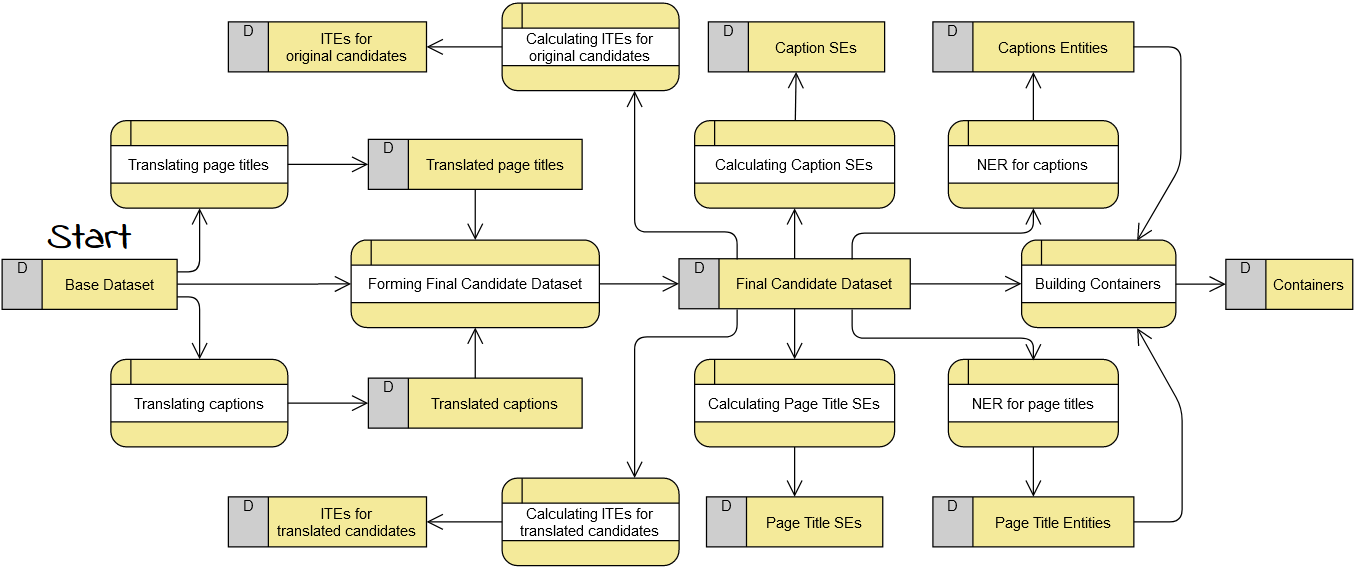
In this stage, for each image, candidate filtering is performed. The filtering procedure uses several heuristic algorithms computing ranks based on string similarity, named entity matching, number matching, and cosine similarity between various embeddings.
To estimate the degree of string similarity, RapidFuzz is exploited.
The ranks computed here are used for candidate selection and feature engineering.
For this filterting procedure, Recall is approximately 0.95 and
some quantiles of the number of candidates for images are shown in the
following table.
| Q25 | Q50 | Q75 | Q90 |
|---|---|---|---|
| 2800 | 3200 | 3600 | 4000 |
After this stage, all the images from the base training dataset and its candidates and features are divided into 72 parts of data.
Now, for each image, the matching problem comes to ranking its candidates with XGBRanker.
After filtering, the data prepared is split into training dataset, validation dataset, and holdout dataset as follows.
| Dataset | Parts |
|---|---|
| Training | 0–58, 60–68 |
| Validation | 70, 71 |
| Holdout | 59, 69 |
According to the table below, the training dataset, in turn, is divided into 7 ranges, each intended for training a certain base model.
| Base Model | Part Range |
|---|---|
model-00 |
0–9 |
model-01 |
10–19 |
model-02 |
20–29 |
model-03 |
30–39 |
model-04 |
40–49 |
model-05 |
50–58 |
model-06 |
60–68 |
In accordance with stacking techniques, the final model is trained on the ranks made by the base models.
The training and inference procedures are depicted visually in the following diagram.

-
This notebook makes final preparations of filtered data forming datasets for base models.
-
These notebooks fit
XGBRankerto a specified training dataset and differ only in hyperparameters and the path to the folder containing tranining data. -
This notebook uses
model-00to produce its ranks for the validation and holdout datasets. For each image, the ranks obtained are used to determine the 50 candidates with the highest rank, while the rest of the ones are rejected. The best candidates and its ranks subsequently form training and validation data for the final model.