公众号:数据挖掘与机器学习笔记
import os
import jieba
import random
import numpy as np
from collections import Counter
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
# 参数设置
word_size = 64 # 词向量维度
window = 5 # 窗口大小
nb_negative = 25 # 随机负采样的样本数
min_count = 10 # 频数少于min_count的词会将被抛弃,低频词类似于噪声,可以抛弃掉
file_num = 10000 #只取file_num个文件进行训练
# 数据预处理
def get_all_apths(dirname):
paths = [] # 将所有的txt文件路径存放在这个list中
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename) # 合并成一个完整路径
paths.append(apath)
return paths
def get_corpus(file_path):
words = []
corpus = []
i = 0
for file in file_path:
if ".txt" in file:
i += 1
try:
with open(file, encoding="utf-8") as fr:
for line in fr:
words += jieba.lcut(line)
corpus.append(jieba.lcut(line))
except Exception as e:
print(e)
if i == file_num:
break
words = dict(Counter(words))
total = sum(words.values())
words = {i: j for i, j in words.items() if j >= min_count} # 去掉低频词
id2word = {i + 2: j for i, j in enumerate(words)}
id2word[0] = "PAD"
id2word[1] = "UNK"
word2id = {j: i for i, j in id2word.items()}
return words, corpus, id2word, word2id
def get_negative_sample(x, word_range, neg_num):
"""
负采样
:param x:
:param word_range:
:param neg_num:
:return:
"""
negs = []
while True:
rand = random.randrange(0, word_range)
if rand not in negs and rand != x:
negs.append(rand)
if len(negs) == neg_num:
return negs
def data_generator(corpus, word2id, id2word):
"""
生成训练数据
:return:
"""
x, y = [], []
for sentence in corpus:
sentence = [0] * window + [word2id[w] for w in sentence if w in word2id] + [0] * window
# 上面这句代码的意思是,因为我们是通过滑窗的方式来获取训练数据的,那么每一句语料的第一个词和最后一个词
# 如何出现在中心位置呢?答案就是给它padding一下,例如“我/喜欢/足球”,两边分别补窗口大小个pad,得到“pad pad 我 喜欢 足球 pad pad”
# 那么第一条训练数据的背景词就是['pad', 'pad','喜欢', '足球'],中心词就是'我'
for i in range(window, len(sentence) - window):
x.append(sentence[i - window:i] + sentence[i + 1:window + i + 1])
y.append([sentence[i]] + get_negative_sample(sentence[i], len(id2word), nb_negative))
x, y = np.array(x), np.array(y)
z = np.zeros((len(x), nb_negative + 1))
z[:, 0] = 1
return x, y, z
def get_train_test_data(x, y, z):
X_train, X_test, y_train, y_test, z_train, z_test = train_test_split([x, y, z], test_size=0.2, random_state=42, shuffle=True)
return X_train, X_test, y_train, y_test, z_train, z_test
#准备成pytorch的DataLoader格式,方便训练
class DatasetTorch(Dataset):
def __init__(self, x, y, z):
self.x = x
self.y = y
self.z = z[:, 1] # torch使用交叉熵损失时,target不需要使用onehot
def __len__(self):
return self.x.shape[0]
def __getitem__(self, index):
return self.x[index], self.y[index], self.z[index]
#划分训练和测试数据
def get_train_test_dataloader(x, y, z, batch_size):
"""
生成训练和测试数据的DataLoader
:param x:
:param y:
:param z:
:param batch_size:
:return:
"""
x_train, x_test, y_train, y_test, z_train, z_test = train_test_split(x, y, z, test_size=0.2, random_state=42, shuffle=True)
train_dataset = DatasetTorch(x_train, y_train, z_train)
test_dataset = DatasetTorch(x_test, y_test, z_test)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size)
return train_dataloader, test_dataloaderimport tensorflow as tf
from data_helper import get_all_apths, get_corpus, data_generator
from data_helper import window, word_size, nb_negative
nb_epoch = 10 # 迭代次数
from tensorflow import keras
def build_model():
"""
模型网络构建
:return:
"""
input_words = keras.layers.Input(shape=(window * 2,), dtype="int32") # shape=(,window*2)
input_vecs = keras.layers.Embedding(len(id2word), word_size, name="word2vec")(input_words) # shape=(,window*2,word_size)
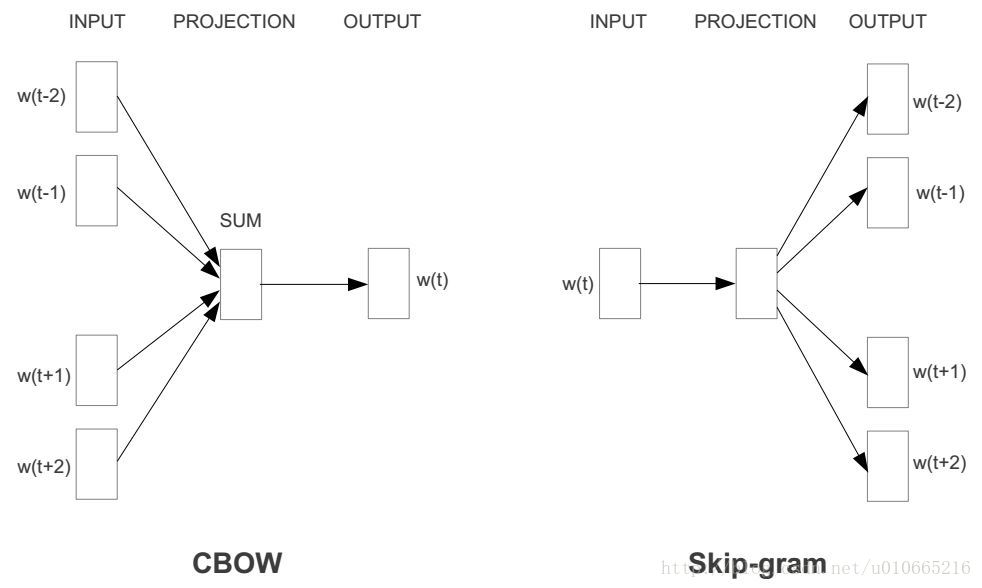
input_vecs_sum = keras.layers.Lambda(lambda x: tf.reduce_sum(x, axis=1))(input_vecs) # CBOW模型直接将上下文词向量求和 shape=(,word_size)
# 第二个输入,中心词和负样本词
samples = keras.layers.Input(shape=(nb_negative + 1,), dtype="int32") # shape=(,nb_negative + 1)
softmax_weights = keras.layers.Embedding(len(id2word), word_size, name="W")(samples) # shape=(,nb_negative + 1,word_size)
softmax_biases = keras.layers.Embedding(len(id2word), 1, name="b")(samples) # shape=(,nb_negative + 1,1)
# 将加和得到的词向量与中心词和负样本的词向量分别进行点乘
input_vecs_sum_dot = keras.layers.Lambda(lambda x: tf.matmul(x[0], tf.expand_dims(x[1], 2)))([softmax_weights, input_vecs_sum]) # shape=(,nb_negative + 1,1)
add_biases = keras.layers.Lambda(lambda x: tf.reshape(x[0] + x[1], shape=(-1, nb_negative + 1)))([input_vecs_sum_dot, softmax_biases])
softmax = keras.layers.Lambda(lambda x: tf.nn.softmax(x))(add_biases)
# 模型编译
model = keras.layers.Model(inputs=[input_words, samples], outputs=softmax)
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
print(model.summary())
return model
if __name__ == '__main__':
file_dir = "F:\\data\\machine_learning\\THUCNews\\THUCNews"
paths = get_all_apths(file_dir)
print(len(paths), paths[0:10])
words, corpus, id2word, word2id = get_corpus(paths)
# print(words)
# print(id2word)
x, y, z = data_generator(corpus, word2id, id2word)
print(x.shape, y.shape, z.shape)
model = build_model()
model.fit([x, y], z, epochs=nb_epoch, batch_size=512)
import torch
from torch import nn
from torch.nn import Module, CrossEntropyLoss
from torch.optim import SGD
from data_helper import get_all_apths, get_corpus, data_generator, get_train_test_dataloader
from data_helper import window, word_size, nb_negative
nb_epoch = 10 # 迭代次数
class Word2VecCBOW(Module):
def __init__(self, window, id2word, nb_negative, embedding_dim):
"""
CBOW模型
:param window:窗口大小
:param id2word:
:param nb_negative:负采样数量
:param embedding_dim:词向量维度
"""
super(Word2VecCBOW, self).__init__()
self.embedding = nn.Embedding(num_embeddings=len(id2word), embedding_dim=embedding_dim)
self.window = window
self.id2word = id2word
self.nb_negative = nb_negative
self.embedding_dim = embedding_dim
def forward(self, input_words, negative_samples):
"""
:param input_words: 上下文单词
:param negative_samples:中心词和负采样单词
:return:
"""
input_vecs = self.embedding(input_words) # shape=(,window*2,word_size)
input_vecs_sum = torch.sum(input_vecs, dim=1) # CBOW模型直接对上下文单词的嵌入进行求和操作 shape=(,word_size)
negative_sample_vecs = self.embedding(negative_samples) # shape=(,nb_negative + 1,word_size)
out = torch.matmul(negative_sample_vecs, torch.unsqueeze(input_vecs_sum, dim=2))
out = torch.squeeze(out)
out = torch.softmax(out, dim=-1)
return out
def train(model, train_dataloader, device, optimizer, crossEntropyLoss):
model.train()
train_loss = 0.0
for i, data in enumerate(train_dataloader):
x_train, y_train, z_train = data
x_train, y_train, z_train = x_train.to(torch.long).to(device), y_train.to(torch.long).to(device), z_train.to(torch.long).to(device)
optimizer.zero_grad() # 梯度清零
z_predict = model(x_train, y_train) # (batch_size,51)
loss = crossEntropyLoss(z_predict, z_train)
loss.backward() # 梯度反向传播
optimizer.step() # 梯度更新
train_loss += loss.item()
# if i % 10 == 0:
# print(loss.item())
return train_loss / i
def test(model, test_dataloader, device, crossEntropyLoss):
model.eval()
test_loss = 0.0
for i, data in enumerate(test_dataloader):
x_test, y_test, z_test = data
x_test, y_test, z_test = x_test.to(torch.long).to(device), y_test.to(torch.long).to(device), z_test.to(torch.long).to(device)
z_predict = model(x_test, y_test) # (batch_size,51)
loss = crossEntropyLoss(z_predict, z_test)
test_loss += loss.item()
return test_loss / i
def train_test(epochs, batch_size):
file_dir = "F:\\data\\machine_learning\\THUCNews\\THUCNews"
paths = get_all_apths(file_dir)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
words, corpus, id2word, word2id = get_corpus(paths)
x, y, z = data_generator(corpus, word2id, id2word)
print(x.shape, y.shape, z.shape)
train_dataloader, test_dataloader = get_train_test_dataloader(x, y, z, batch_size=batch_size)
loss_fun = CrossEntropyLoss()
cbow = Word2VecCBOW(window, id2word, nb_negative, word_size)
cbow.to(device)
optimizer = SGD(cbow.parameters(), lr=0.01)
print("------开始训练------:", device)
for epoch in range(1, epochs + 1):
train_loss = train(cbow, train_dataloader, device, optimizer, loss_fun)
test_loss = test(cbow, test_dataloader, device, loss_fun)
print("epoch %d, train loss: %.2f, test loss:%.2f" % (epoch, train_loss, test_loss))
torch.save(cbow, "../models/cbow_w2v.pkl")
if __name__ == '__main__':
# train_test(nb_epoch, 32) #训练、测试
cbow = torch.load("../models/cbow_w2v.pkl") # 加载模型
print(cbow.embedding.weight.shape) # 提取训练好的Embedding