An "oop", or "ordinary object pointer" in HotSpot parlance is a managed pointer to an object. It is normally the same size as a native machine pointer. A managed pointer is carefully tracked by the Java application and GC subsystem, so that storage for unused objects can be reclaimed. This process can also involve relocating (copying) objects which are in use, so that storage can be compacted.
The term "oop" is traditional to certain VMs that derive from Smalltalk and Self, including the following:
- Self (an prototype-based relative of Smalltalk) https://github.com/russellallen/self/blob/master/vm/src/any/objects/oop.hh
- Strongtalk (a Smalltalk implementation) http://code.google.com/p/strongtalk/wiki/VMTypesForSmalltalkObjects
- Hotspot http://hg.openjdk.java.net/hsx/hotspot-main/hotspot/file/0/src/share/vm/oops/oop.hpp
- V8 http://code.google.com/p/v8/source/browse/trunk/src/objects.h (mentions "smi" but not "oop")
(In some of these systems, the term "smi" refers to a special non-oop word, a pseudo-pointer, which encodes a small, 30-bit integer. This term can also be found in the V8 implementation of Smalltalk.)
On an LP64 system, a machine word, and hence an oop, requires 64 bits, while on an ILP32 system, oops are only 32 bits. But on an ILP32 system there is a maximum heap size of somewhat less than 4Gb, which is not enough for many applications. On an LP64 system, though, the heap for any given run may have to be around 1.5 times as large as for the corresponding ILP32 system (assuming the run fits both modes). This is due to the expanded size of managed pointers. Memory is pretty cheap, but these days bandwidth and cache is in short supply, so significantly increasing the size of the heap just to get over the 4Gb limit is painful.
(Additionally, on x86 chips, the ILP32 mode provides half the usable registers that the LP64 mode does. SPARC is not affected this way; RISC chips start out with lots of registers and just widen them for LP64 mode.)
Compressed oops represent managed pointers (in many but not all places in the JVM) as 32-bit values which must be scaled by a factor of 8 and added to a 64-bit base address to find the object they refer to. This allows applications to address up to four billion objects (not bytes), or a heap size of up to about 32Gb. At the same time, data structure compactness is competitive with ILP32 mode.
We use the term decode to express the operation by which a 32-bit compressed oop is converted into a 64-bit native address into the managed heap. The inverse operation is encoding.
In an ILP32-mode JVM, or if the UseCompressedOops flag is turned off in LP64 mode, all oops are the native machine word size.
If UseCompressedOops is true, the following oops in the heap will be compressed:
- the klass field of every object
- every oop instance field
- every element of an oop array (objArray)
The Hotspot VM's data structures to manage Java classes are not compressed. These are generally found in the section of the Java heap known as the Permanent Generation (PermGen).
In the interpreter, oops are never compressed. These include JVM locals and stack elements, outgoing call arguments, and return values. The interpreter eagerly decodes oops loaded from the heap, and encodes them before storing them to the heap.
Likewise, method calling sequences, either interpreted or compiled, do not use compressed oops.
In compiled code, oops are compressed or not according to the outcome of various optimizations. Optimized code may succeed in moving a compressed oop from one location in the managed heap to another without ever decoding it. Likewise, if the chip (i.e., x86) supports addressing modes which can be used for the decode operation, compressed oops might not be decoded even if they are used to address object fields or array elements.
Therefore, the following structures in compiled code can refer to either compressed oops or native heap addresses:
- register or spill slot contents
- oop maps (GC maps)
- debugging information (linked to oop maps)
- oops embedded directly in machine code (on non-RISC chips like x86 which allow this)
- nmethod constant section entries (including those used by relocations affecting machine code)
In the C++ code of the HotSpot JVM, the distinction between compressed and native oops is reflected in the C++ static type system. In general, oops are often uncompressed. In particular C++ member functions operate as usual on receivers (this) represented by native machine words. A few functions in the JVM are overloaded to handle either compressed or native oops.
Important C++ values which are never compressed:
- C++ object pointers (this)
- handles to managed pointers (type Handle, etc.)
- JNI handles (type jobject)
The C++ code has a type called narrowOop to mark places where compressed oops are being manipulated (usually, loaded or stored).
Here is an example of an x86 instruction sequence that uses compressed oops:
! int R8; oop[] R9; // R9 is 64 bits
! oop R10 = R9[R8]; // R10 is 32 bits
! load compressed ptr from wide base ptr:
movl R10, [R9 + R8<<3 + 16]
! klassOop R11 = R10._klass; // R11 is 32 bits
! void* const R12 = GetHeapBase();
! load compressed klass ptr from compressed base ptr:
movl R11, [R12 + R10<<3 + 8]
Here is an example of a sparc instruction sequence which decodes a compressed oop (which might be null):
! java.lang.Thread::getThreadGroup@1 (line 1072)
! L1 = L7.group
ld [ %l7 + 0x44 ], %l1
! L3 = decode(L1)
cmp %l1, 0
sllx %l1, 3, %l3
brnz,a %l3, .+8
add %l3, %g6, %l3 ! %g6 is constant heap base
(Annotated output is from the disassembly plugin.)
A 32-bit zero value decodes into a 64-bit native null value. This requires an awkward special path in the decoding logic, to the point where it is profitable to statically note which compressed oops (like klass fields) are guaranteed never to be null, and use a simpler version of the full decode or encode operation.
Implicit null checks are crucial to JVM performance, in both interpreted and compiled bytecodes. A memory reference which uses a short-enough offset on a base pointer is sure to provoke a trap or signal of some sort if the base pointer is null, because the first page or so of virtual address space is not mapped.
We can sometimes use a similar trick with compressed oops, by unmapping the first page or so of the virtual addresses used by the managed heap. The idea is that, if a compressed null is ever decoded (by shifting and adding to the heap base), it can be used for a load or store operation, and the code still enjoys an implicit null check.
An object header consists of a native-sized mark word, a klass word, a 32-bit length word (if the object is an array), a 32-bit gap (if required by alignment rules), and then zero or more instance fields, array elements, or metadata fields. (Interesting Trivia: Klass metaobjects contain a C++ vtable immediately after the klass word.)
The gap field, if it exists, is often available to store instance fields.
If UseCompressedOops is false (and always on ILP32 systems), the mark and klass are both native machine words. For arrays, the gap is always present on LP64 systems, and only on arrays with 64-bit elements on ILP32 systems.
If UseCompressedOops is true, the klass is 32 bits. Non-arrays have a gap field immediately after the klass, while arrays store the length field immediately after the klass.
Compressed oops use an arbitrary address for the narrow oop base which is calculated as java heap base minus one (protected) page size for implicit NULL checks to work. This means a generic field reference is next:
<narrow-oop-base> + (<narrow-oop> << 3) + <field-offset>.
If the narrow oop base can be made to be zero (the java heap doesn't actually have to start at offset zero), then a generic field reference can be just next:
(<narrow-oop << 3) + <field-offset>
Theoretically it allows to save the heap base add (current Register Allocator does not allow to save register). Also with zero base the null check of compressed oop is not needed. Current code for decoding compressed oops looks like this:
if (<narrow-oop> == NULL)
<wide_oop> = NULL
else
<wide_oop> = <narrow-oop-base> + (<narrow-oop> << 3)
With zero narrow oop base the code is much simpler. It needs only shift to decode/encode a compressed oop:
<wide_oop> = <narrow-oop> << 3
Also if java heap size < 4Gb and it can be moved into low virtual address space (below 4Gb) then compressed oops can be used without encoding/decoding.
Zero based implementation tries to allocated java heap using different strategies based on the heap size and a platform it runs on. First, it tries to allocate java heap below 4Gb to use compressed oops without decoding if heap size < 4Gb. If it fails or heap size > 4Gb it will try to allocate the heap below 32Gb to use zero based compressed oops. If this also fails it will switch to regular compressed oops with narrow oop base.
In this article we are going to introduce you to one of the JVM optimizations known as Compressed oops. The idea of compressed oops is raised from the differences between 32bit and 64bit architecture. So we will have a very short review of 64bit architecture and then go deeper into the topic of compressed oops. At the end we will see it all in action with a simple example.
The example code for this article is rather simple, so we are not going to use any IDE. Compressed oops makes no sense on a 32bit machine. Also it is not activated by default in JDKs prior to 6u23. So we assume you are using a 64bit JDK newer than 6u23. The final tool we need is a memory analyzer tool. For this example we used industry standard Eclipse Memory Analyzer Tool version 1.5.
32bit versus 64bit was all the rage in early 2000s. While 64bit CPU was nothing new in the world of supercomputers it was not until recently that personal computers brought it to the mainstream. Transition from 32bit architecture to 64bit is by no means an easy job, everything from hardware to operating system must change. Java embraced this transition with the introduction of 64bit virtual machine.
The main advantage of this transition is memory capacity. In a 32bit system you have memory address width of 32 bits (hence the name) which means the total amount of addressable memory is 2^32 or 4 gigabyte of RAM. This might have been an infinite amount of memory for a personal computer in the past (after all who needs more than 640kB of RAM!) but not in the time that a smartphone with one gigabyte of memory is considered a low end product. 64bit architecture solved this limitation. In such a machine the theoretical amount of addressable memory is 2^64, a ridiculously huge number. Unfortunately it is just a theoretical cap, in the real world there are a lot of hardware and software factors that limit us to the much smaller memory. For example Windows 7 Ultimate supports only up to 192GB. Using the word only for 192 gigabytes seems a bit harsh but it pales in comparison to 2^64. Now that you see why 64bit matters let’s move to the next part and see how compressed oops are going to help us.
“There is no such thing as free lunch”. The excessive amount of memory in 64bit machines comes with a price. Generally an application consumes more memory on a 64bit system, and in a non trivial application this amount is not negligible. Compressed oops help you reserve some memory by using 32bit class pointers in a 64bit environment, provided that your heap size is not going to be larger than 32GB. To see this in more detail lets see how an object is represented in Java.
To see how objects are represented in Java we use a very simple example, an Integer object that holds a primitive int. When you write a simple line of code as below:
Integer i = ``new` `Integer(``23``);
The compiler allocates much more than 32 bits of heap to this object. ints are 32 bits long in java but every object has headers. The size of these headers differs in 32bit and 64bit and in different VMs. In a 32bit virtual machine each of these header fields are one word or 4 bytes. In a 64bit virtual machine the field that holds the int remains 32 bits but the size of the other fields doubles to 8 bytes (one word in 64bit environment). In fact the story doesn’t end here. Objects are word aligned which means in a 64bit machine the amount of memory they take must be divisible by 64. The main point of interest for us is the size of class pointer which is known as Klass in Hotspot VM parlance. As you can see in the image below the klass size is 8 bytes on a 64bit virtual machine but with compressed oops enabled it becomes 4 bytes.
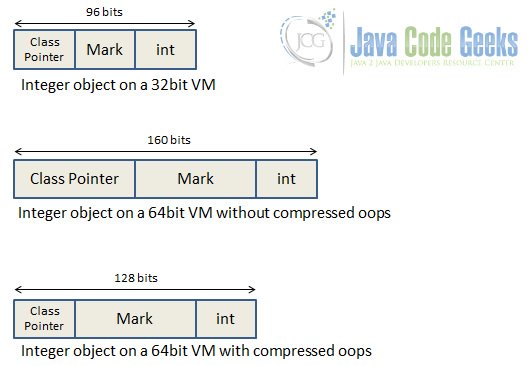
Representation of an Integer object in different VMs
oop in compressed oops stands for ordinary object pointer. These object pointers (as we saw in previous section) are the same size as the native pointers of the machine. So oops size is 32 bits or 64 bits on a 32bit and 64bit machine respectively. With compressed oops we have 32 bits pointers on a 64bit machine.
The trick behind compressed oops is the difference between byte addressing and word addressing of memory. With byte addressing you have access to every byte in memory but need a unique address for each byte as well. In a 32bit environment this limits you to 2^32 bytes of memory. In word addressing you still have the same amount of addressable memory blocks but this memory chunk is one word instead of one byte. In a 64bit machine a word is 8 bytes. This gives JVM three zero bits. Java takes advantage of these bits by shifting them to expand the addressable memory and implement compressed oops.
To see the effect of compressed oops in action we use a simple application. This is a small java object that makes a linked list of 2 million integers.
To be able to see the heap condition we use Eclipse Memory Analyzer Tool. Since we are not using Eclipse IDE we use the stand alone application. You can download it from here.
Since this example uses only one class we don’t use Eclipse or any other IDE. Use a text editor and make a file named IntegerApplication.java. Type the following code inside the file. Remember he name of the file should match the name of the java class. Instead of typing this by hand you can download the class file from the download section of this article.
IntegerApplication.java
import` `java.util.LinkedList;``import` `java.util.List;``import` `java.util.Scanner;` `public` `class` `IntegerApplication {`` ``public` `static` `void` `main(String[] args) {`` ``List<Integer> intList = ``new` `LinkedList<>();`` ``for``(``int` `i=``0``;i<``2000000``;i++){`` ``Integer number = ``new` `Integer(``1``);`` ``intList.add(number);`` ``}`` ``Scanner scanner = ``new` `Scanner(System.in);`` ``System.out.println(``"application is running..."``);`` ``String tmp = scanner.nextLine();`` ``System.exit(``0``);`` ``}``}
Open a command prompt window and navigate to the directory of this file. Use the following command to compile it.
javac IntegerApplication.java
Now you should have a IntegerApplication.class file. We run this file twice, once with compressed oops enabled and second time without compressed oops. Compressed oops is enabled by default in JVMs newer than 6u23 so you only need to run the application by typing this in command prompt:
java IntegerApplication
You may have noticed the Scanner object in source code. It’s used to keep the application alive until you type something and terminate it. If you see the sentence “application is running…” in your command prompt it’s time to start memory analyzer. Depending on your machine it may take a while for it to do the initialization process.
From file menu select Acquire Heap Dump…
Process selection window
you will see the process selection window. Select the process named IntegerApplication and click finish.
After a while you will be in the main screen of the MAT. From the toolbar select the histogram button as shown in the image:
Select Histogram from toolbar
Now you can see a detailed overview of all the objects in your application. This is the histogram of our simple application running with compressed oops enabled.
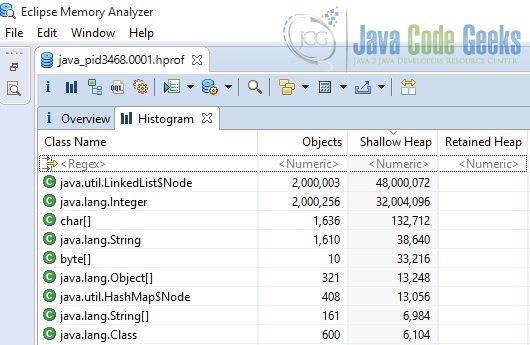
Heap dump of application with compressed oops enabled.
This time we run the application without compressed oops. In order to disable compressed oops we use -XX:-UseCompressedOops flag. You don’t need to recompile your class again just type the following command in your command prompt:
java -XX:-UseCompressedOops IntegerApplication
Again when you see the “Application is running…” text acquire a heap dump same as before. This is the histogram of heap dump when application is running without compressed oops.
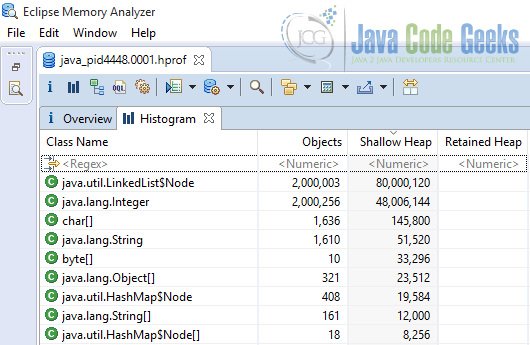
Heap dump of application with compressed oops disabled
As we expected the heap size increased. The majority of heap is occupied by two types of objects, linked list nodes and integers. There are more than 2 million integers that in the compressed oops version required 32 million bytes and in non compressed oops 48 million bytes. With a simple math we can see this exactly matches our predictions.
2000000*(128/8) = 32000000 or 32 megabytes
2000000*(192/8) = 48000000 or 48 megabytes
If you notice in the second equation we have used 192 while in the above section the object size was mentioned as 160 bits. The reason is Java is byte addressed so the address is aligned to closest 8 bytes which is 192 bits in this case.
The example provided here was contrived but this doesn’t mean it doesn’t hold true in real world applications. When tested with H2 database application compressed oops decreased heap size from 3.6 to 3.1 megabytes. This is almost 14% more efficient use of valuable heap space. As we saw there is no harm in using compressed oops and indeed most often than not you are not going to disable this feature. But knowing the details of the compiler tricks can help with writing codes with performance in mind.