
记得一年前分享过一篇《一致性 Hash 算法分析》,当时只是分析了这个算法的实现原理、解决了什么问题等。
但没有实际实现一个这样的算法,毕竟要加深印象还得自己撸一遍,于是本次就当前的一个路由需求来着手实现一次。
看过《为自己搭建一个分布式 IM(即时通讯) 系统》的朋友应该对其中的登录逻辑有所印象。
先给新来的朋友简单介绍下 cim 是干啥的:

其中有一个场景是在客户端登录成功后需要从可用的服务端列表中选择一台服务节点返回给客户端使用。
而这个选择的过程就是一个负载策略的过程;第一版本做的比较简单,默认只支持轮询的方式。
虽然够用,但不够优雅😏。
因此我的规划是内置多种路由策略供使用者根据自己的场景选择,同时提供简单的 API 供用户自定义自己的路由策略。
先来看看一致性 Hash 算法的一些特点:
- 构造一个
0 ~ 2^32-1大小的环。 - 服务节点经过 hash 之后将自身存放到环中的下标中。
- 客户端根据自身的某些数据 hash 之后也定位到这个环中。
- 通过顺时针找到离他最近的一个节点,也就是这次路由的服务节点。
- 考虑到服务节点的个数以及 hash 算法的问题导致环中的数据分布不均匀时引入了虚拟节点。
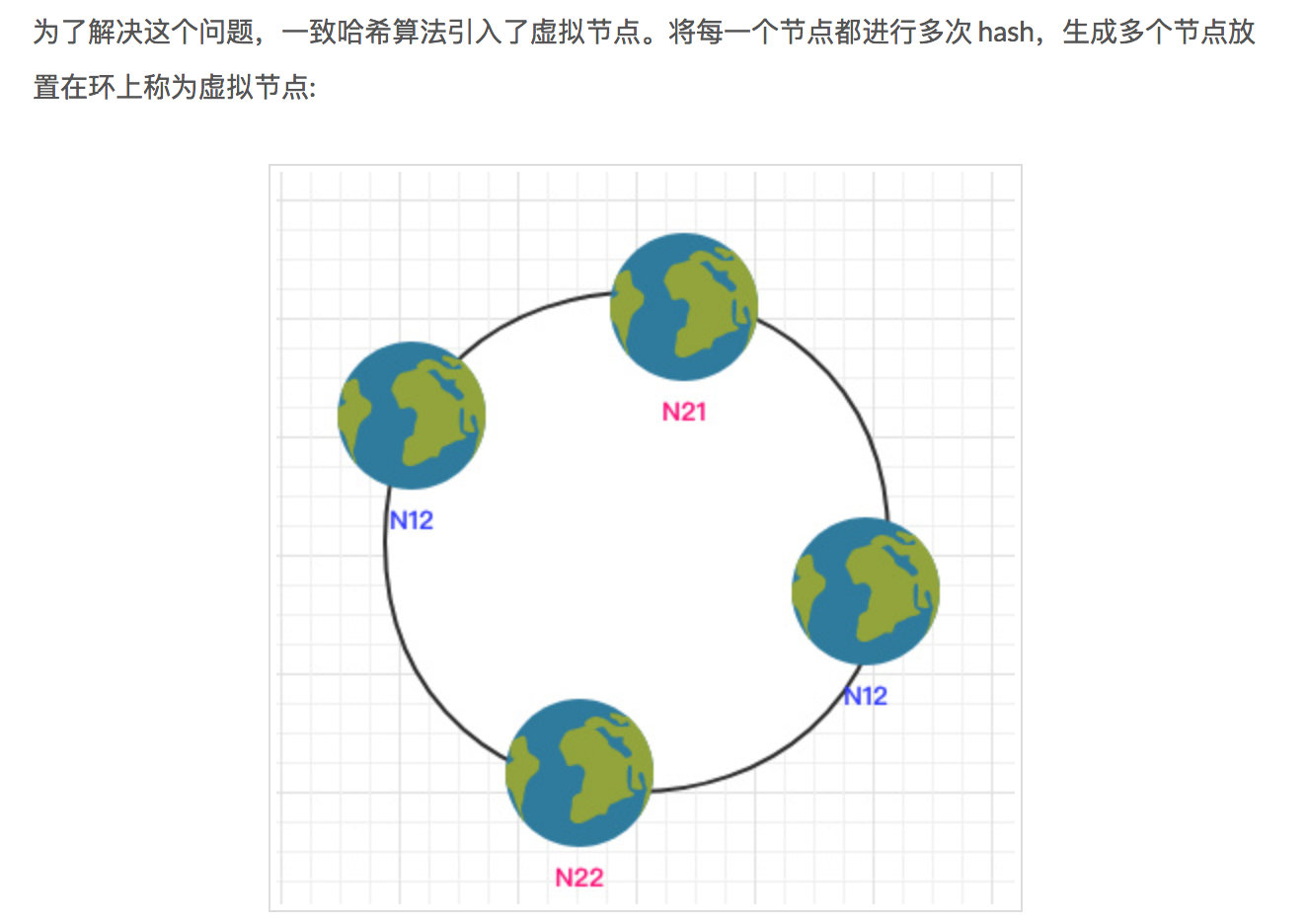
根据这些客观条件我们很容易想到通过自定义一个有序数组来模拟这个环。
这样我们的流程如下:
- 初始化一个长度为 N 的数组。
- 将服务节点通过 hash 算法得到的正整数,同时将节点自身的数据(hashcode、ip、端口等)存放在这里。
- 完成节点存放后将整个数组进行排序(排序算法有多种)。
- 客户端获取路由节点时,将自身进行 hash 也得到一个正整数;
- 遍历这个数组直到找到一个数据大于等于当前客户端的 hash 值,就将当前节点作为该客户端所路由的节点。
- 如果没有发现比客户端大的数据就返回第一个节点(满足环的特性)。
先不考虑排序所消耗的时间,单看这个路由的时间复杂度:
- 最好是第一次就找到,时间复杂度为
O(1)。 - 最差为遍历完数组后才找到,时间复杂度为
O(N)。
理论讲完了来看看具体实践。
我自定义了一个类:SortArrayMap
他的使用方法及结果如下:
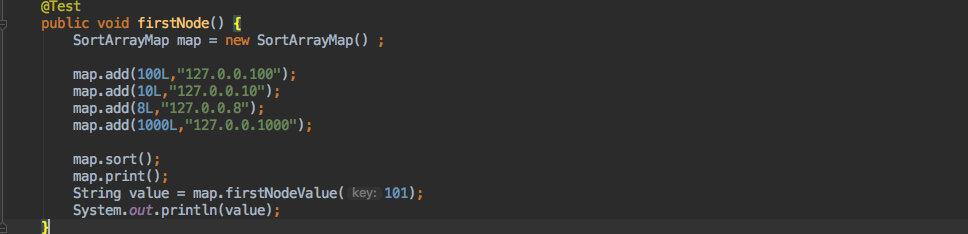
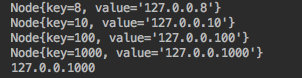
可见最终会按照 key 的大小进行排序,同时传入 hashcode = 101 时会按照顺时针找到 hashcode = 1000 这个节点进行返回。
下面来看看具体的实现。
成员变量和构造函数如下:
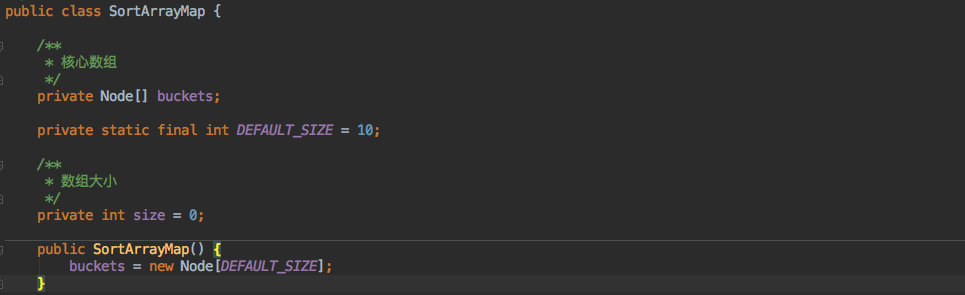
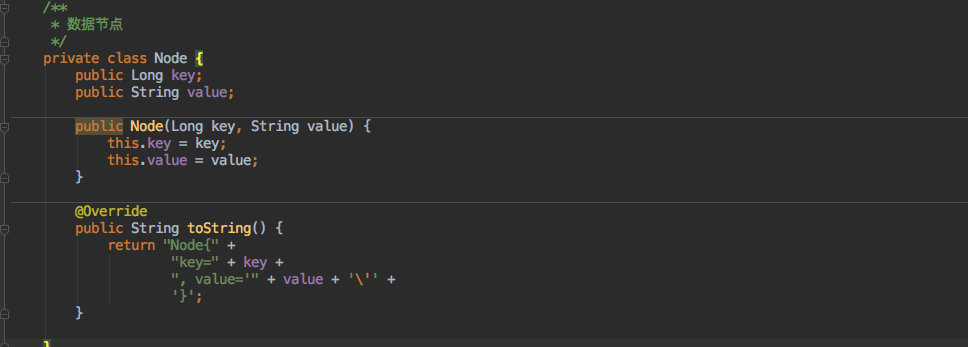
其中最核心的就是一个 Node 数组,用它来存放服务节点的 hashcode 以及 value 值。
其中的内部类 Node 结构如下:
写入数据的方法如下:
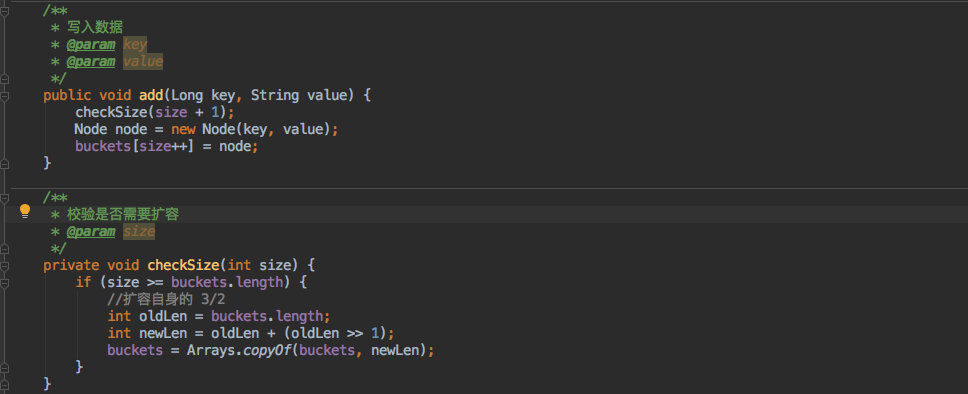
相信看过 ArrayList 的源码应该有印象,这里的写入逻辑和它很像。
- 写入之前判断是否需要扩容,如果需要则复制原来大小的 1.5 倍数组来存放数据。
- 之后就写入数组,同时数组大小 +1。
但是存放时是按照写入顺序存放的,遍历时自然不会有序;因此提供了一个 Sort 方法,可以把其中的数据按照 key 其实也就是 hashcode 进行排序。
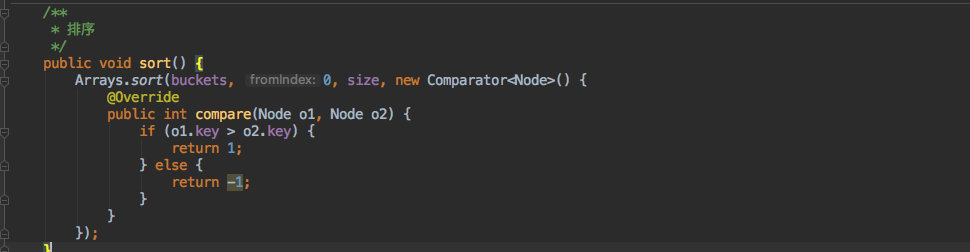
排序也比较简单,使用了 Arrays 这个数组工具进行排序,它其实是使用了一个 TimSort 的排序算法,效率还是比较高的。
最后则需要按照一致性 Hash 的标准顺时针查找对应的节点:
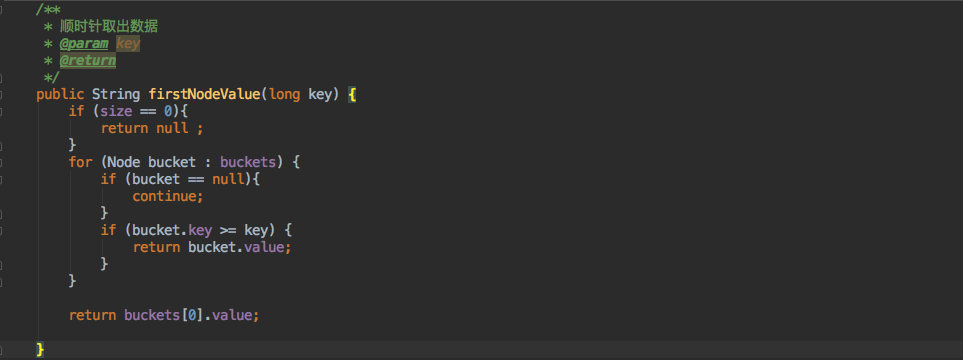
代码还是比较简单清晰的;遍历数组如果找到比当前 key 大的就返回,没有查到就取第一个。
这样就基本实现了一致性 Hash 的要求。
ps:这里并不包含具体的 hash 方法以及虚拟节点等功能(具体实现请看下文),这个可以由使用者来定,SortArrayMap 可作为一个底层的数据结构,提供有序 Map 的能力,使用场景也不局限于一致性 Hash 算法中。
SortArrayMap 虽说是实现了一致性 hash 的功能,但效率还不够高,主要体现在 sort 排序处。
下图是目前主流排序算法的时间复杂度:
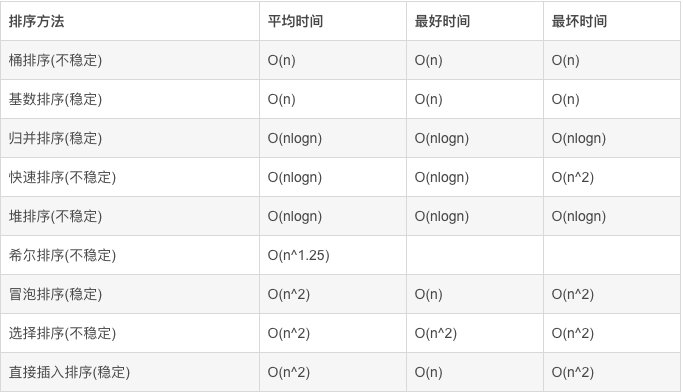
最好的也就是 O(N) 了。
这里完全可以换一个思路,不用对数据进行排序;而是在写入的时候就排好顺序,只是这样会降低写入的效率。
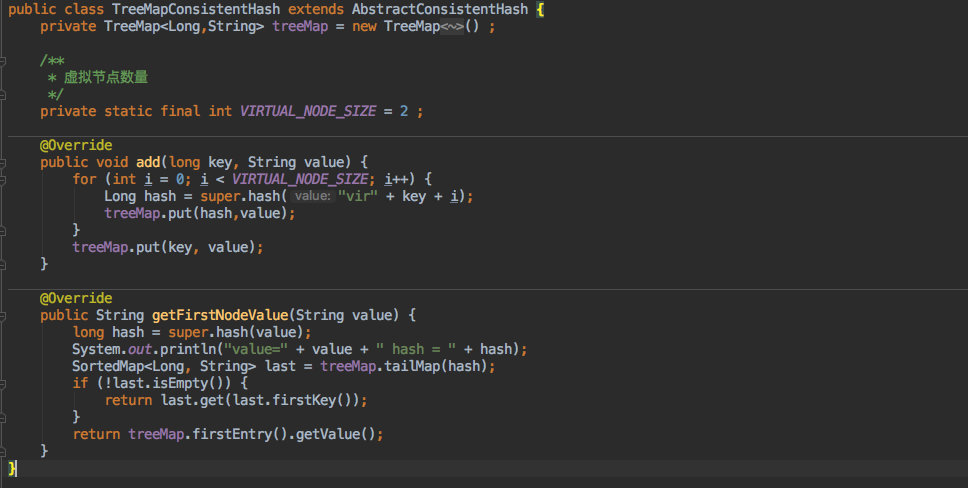
比如二叉查找树,这样的数据结构 jdk 里有现成的实现;比如 TreeMap 就是使用红黑树来实现的,默认情况下它会对 key 进行自然排序。
来看看使用 TreeMap 如何来达到同样的效果。
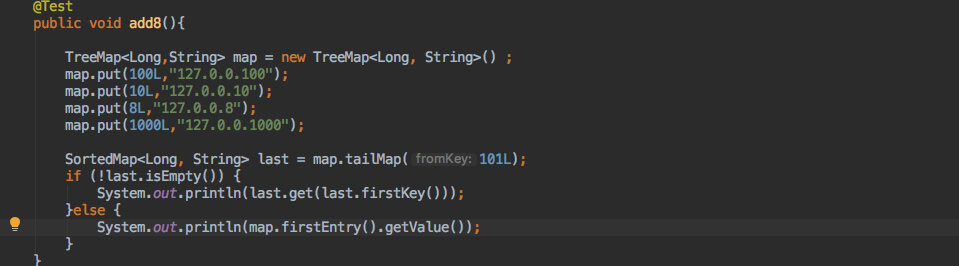
127.0.0.1000
效果和上文使用 SortArrayMap 是一致的。
只使用了 TreeMap 的一些 API:
- 写入数据候,
TreeMap可以保证 key 的自然排序。 tailMap可以获取比当前 key 大的部分数据。- 当这个方法有数据返回时取第一个就是顺时针中的第一个节点了。
- 如果没有返回那就直接取整个
Map的第一个节点,同样也实现了环形结构。
ps:这里同样也没有 hash 方法以及虚拟节点(具体实现请看下文),因为 TreeMap 和 SortArrayMap 一样都是作为基础数据结构来使用的。
为了方便大家选择哪一个数据结构,我用 TreeMap 和 SortArrayMap 分别写入了一百万条数据来对比。
先是 SortArrayMap:
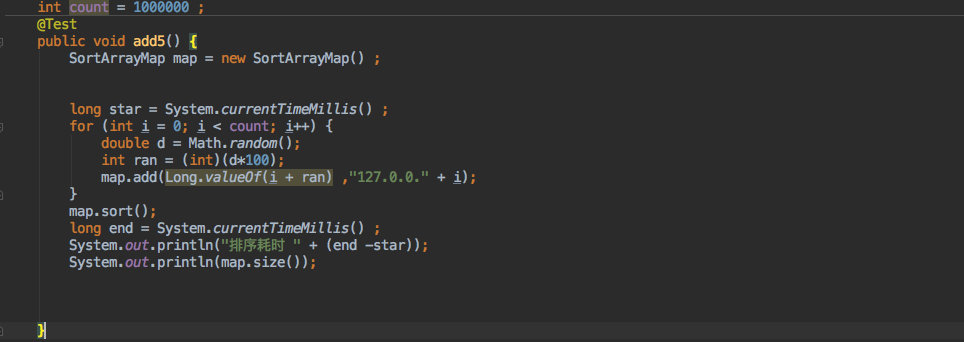
耗时 2237 毫秒。
TreeMap:
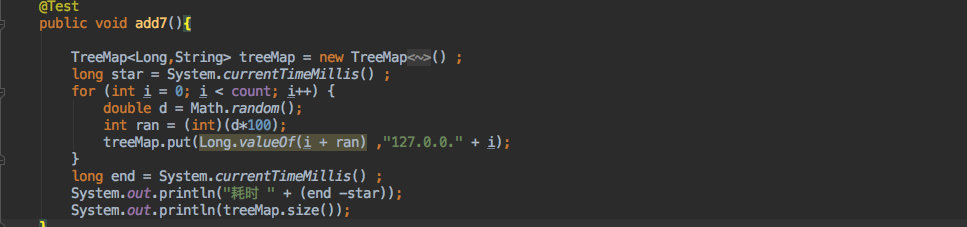
耗时 1316毫秒。
结果是快了将近一倍,所以还是推荐使用 TreeMap 来进行实现,毕竟它不需要额外的排序损耗。
下面来看看在 cim 这个应用中是如何具体使用的,其中也包括上文提到的虚拟节点以及 hash 算法。
在应用的时候考虑到就算是一致性 hash 算法都有多种实现,为了方便其使用者扩展自己的一致性 hash 算法因此我定义了一个抽象类;其中定义了一些模板方法,这样大家只需要在子类中进行不同的实现即可完成自己的算法。
AbstractConsistentHash,这个抽象类的主要方法如下:
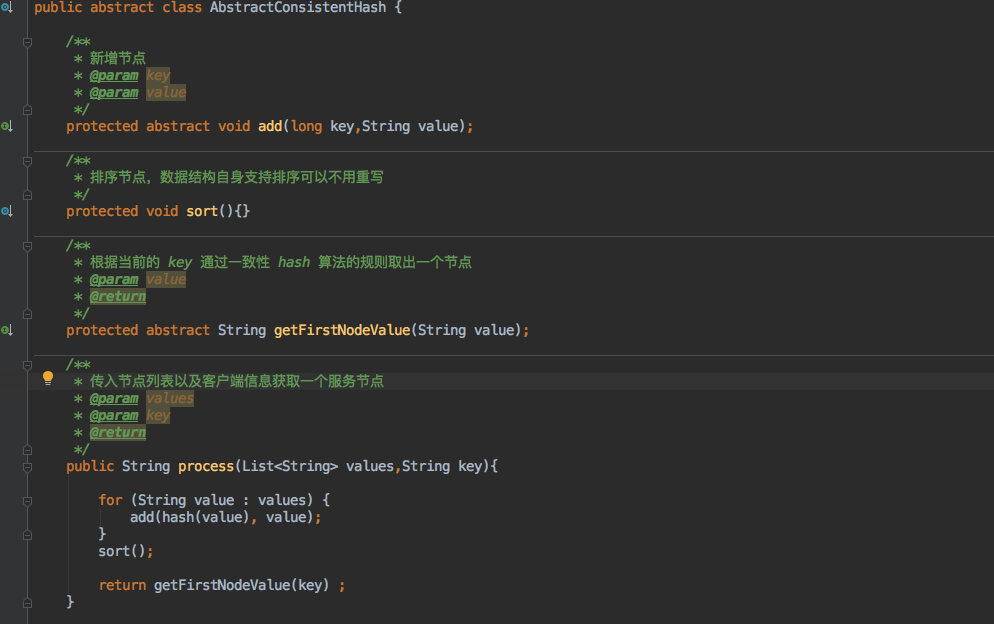
add方法自然是写入数据的。sort方法用于排序,但子类也不一定需要重写,比如TreeMap这样自带排序的容器就不用。getFirstNodeValue获取节点。process则是面向客户端的,最终只需要调用这个方法即可返回一个节点。
下面我们来看看利用 SortArrayMap 以及 AbstractConsistentHash 是如何实现的。
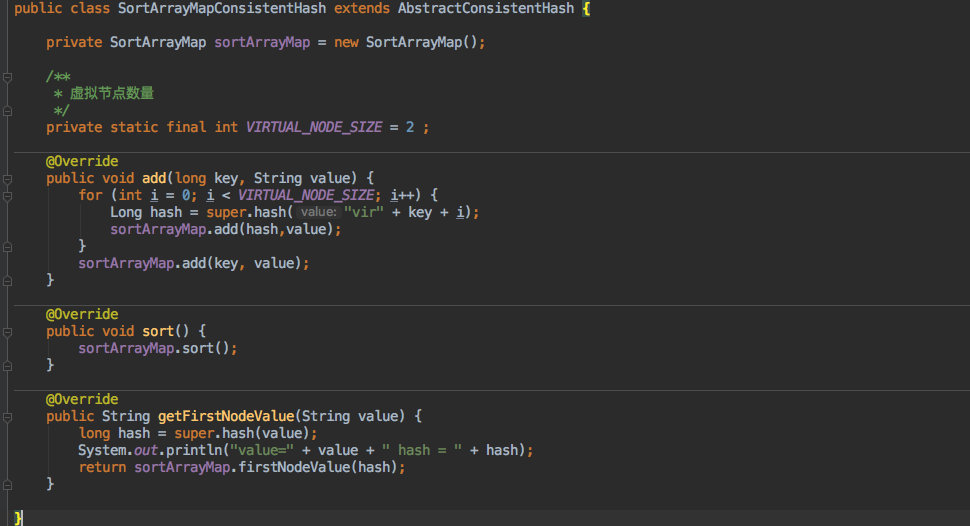
就是实现了几个抽象方法,逻辑和上文是一样的,只是抽取到了不同的方法中。
只是在 add 方法中新增了几个虚拟节点,相信大家也看得明白。
把虚拟节点的控制放到子类而没有放到抽象类中也是为了灵活性考虑,可能不同的实现对虚拟节点的数量要求也不一样,所以不如自定义的好。
但是 hash 方法确是放到了抽象类中,子类不用重写;因为这是一个基本功能,只需要有一个公共算法可以保证他散列地足够均匀即可。
因此在 AbstractConsistentHash 中定义了 hash 方法。
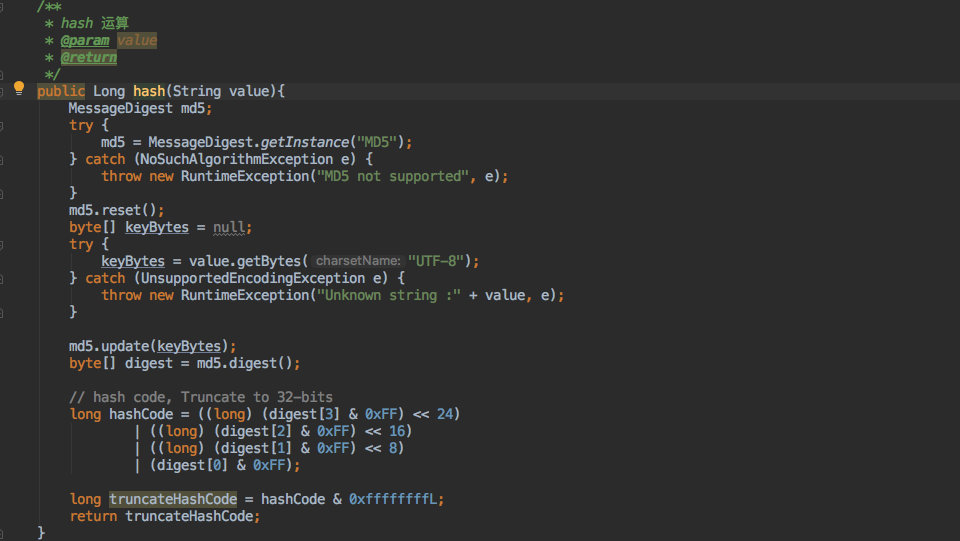
这里的算法摘抄自 xxl_job,网上也有其他不同的实现,比如
FNV1_32_HASH等;实现不同但是目的都一样。
这样对于使用者来说就非常简单了:
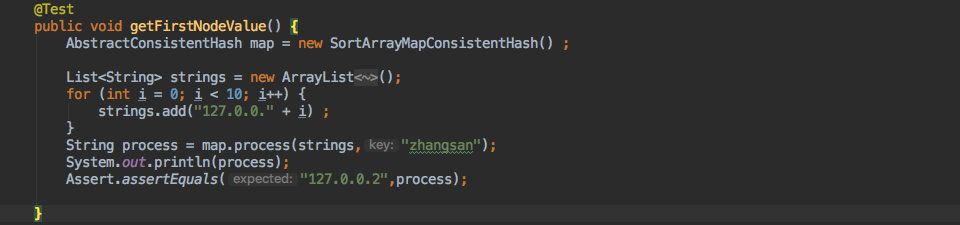
他只需要构建一个服务列表,然后把当前的客户端信息传入 process 方法中即可获得一个一致性 hash 算法的返回。
同样的对于想通过 TreeMap 来实现也是一样的套路:
他这里不需要重写 sort 方法,因为自身写入时已经排好序了。
而在使用时对于客户端来说只需求修改一个实现类,其他的啥都不用改就可以了。
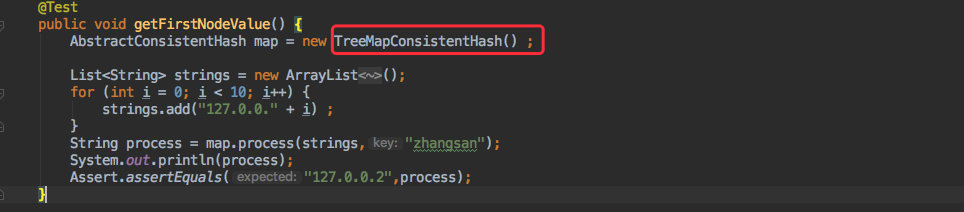
运行的效果也是一样的。
这样大家想自定义自己的算法时只需要继承 AbstractConsistentHash 重写相关方法即可,客户端代码无须改动。
但其实对于 cim 来说真正的扩展性是对路由算法来说的,比如它需要支持轮询、hash、一致性hash、随机、LRU等。
只是一致性 hash 也有多种实现,他们的关系就如下图:
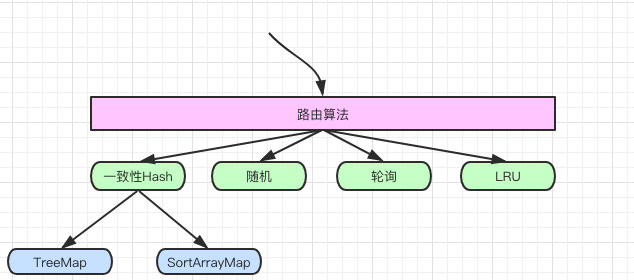
应用还需要满足对这一类路由策略的灵活支持,比如我也想自定义一个随机的策略。
因此定义了一个接口:RouteHandle
public interface RouteHandle {
/**
* 再一批服务器里进行路由
* @param values
* @param key
* @return
*/
String routeServer(List<String> values,String key) ;
}其中只有一个方法,也就是路由方法;入参分别是服务列表以及客户端信息即可。
而对于一致性 hash 算法来说也是只需要实现这个接口,同时在这个接口中选择使用 SortArrayMapConsistentHash 还是 TreeMapConsistentHash 即可。
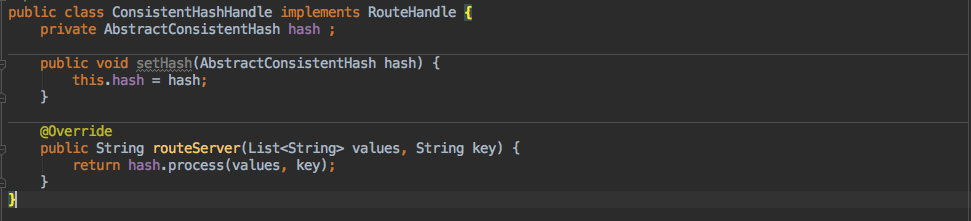
这里还有一个 setHash 的方法,入参是 AbstractConsistentHash;这就是用于客户端指定需要使用具体的那种数据结构。
而对于之前就存在的轮询策略来说也是同样的实现 RouteHandle 接口。
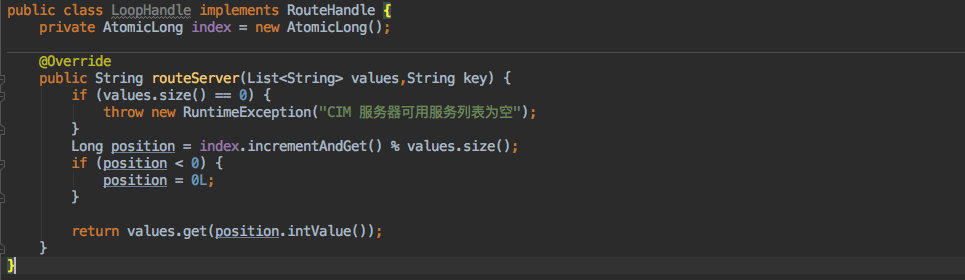
这里我只是把之前的代码搬过来了而已。
接下来看看客户端到底是如何使用以及如何选择使用哪种算法。
为了使客户端代码几乎不动,我将这个选择的过程放入了配置文件。
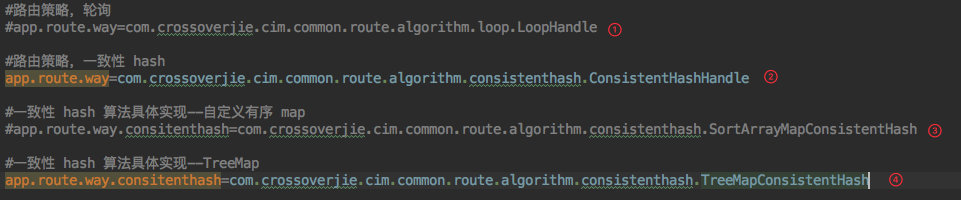
- 如果想使用原有的轮询策略,就配置实现了
RouteHandle接口的轮询策略的全限定名。 - 如果想使用一致性 hash 的策略,也只需要配置实现了
RouteHandle接口的一致性 hash 算法的全限定名。 - 当然目前的一致性 hash 也有多种实现,所以一旦配置为一致性 hash 后就需要再加一个配置用于决定使用
SortArrayMapConsistentHash还是TreeMapConsistentHash或是自定义的其他方案。 - 同样的也是需要配置继承了
AbstractConsistentHash的全限定名。
不管这里的策略如何改变,在使用处依然保持不变。
只需要注入 RouteHandle,调用它的 routeServer 方法。
@Autowired
private RouteHandle routeHandle ;
String server = routeHandle.routeServer(serverCache.getAll(),String.valueOf(loginReqVO.getUserId()));既然使用了注入,那其实这个策略切换的过程就在创建 RouteHandle bean 的时候完成的。
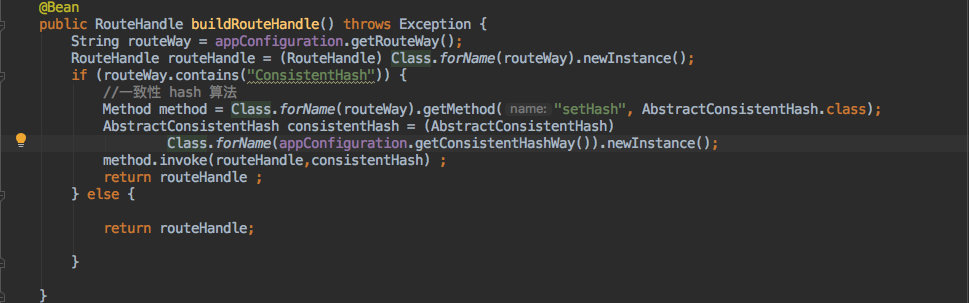
也比较简单,需要读取之前的配置文件来动态生成具体的实现类,主要是利用反射完成的。
这样处理之后就比较灵活了,比如想新建一个随机的路由策略也是同样的套路;到时候只需要修改配置即可。
感兴趣的朋友也可提交 PR 来新增更多的路由策略。
希望看到这里的朋友能对这个算法有所理解,同时对一些设计模式在实际的使用也能有所帮助。
相信在金三银四的面试过程中还是能让面试官眼前一亮的,毕竟根据我这段时间的面试过程来看听过这个名词的都在少数😂(可能也是和候选人都在 1~3 年这个层级有关)。
以上所有源码:
https://github.com/crossoverJie/cim
如果本文对你有所帮助还请不吝转发。