



Attention mechanism for processing sequential data that considers the context for each timestamp.

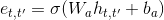


pip install keras-self-attention默认情况下,注意力层使用加性注意力机制,并使用全部上下文进行计算。下面的代码根据页首的公式创建了一个注意力层(attention_activation是注意力权重e_{t, t'}):
import keras
from keras_self_attention import SeqSelfAttention
model = keras.models.Sequential()
model.add(keras.layers.Embedding(input_dim=10000,
output_dim=300,
mask_zero=True))
model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=128,
return_sequences=True)))
model.add(SeqSelfAttention(attention_activation='sigmoid'))
model.add(keras.layers.Dense(units=5))
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['categorical_accuracy'],
)
model.summary()参数attention_width控制着局部注意力的宽度:
from keras_self_attention import SeqSelfAttention
SeqSelfAttention(
attention_width=15,
attention_activation='sigmoid',
name='Attention',
)用attention_type来改变注意力机制的计算方法:

from keras_self_attention import SeqSelfAttention
SeqSelfAttention(
attention_width=15,
attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL,
attention_activation=None,
kernel_regularizer=keras.regularizers.l2(1e-6),
use_attention_bias=False,
name='Attention',
)
通过将attention_regularizer_weight设置为一个正数来使用正则化:
import keras
from keras_self_attention import SeqSelfAttention
inputs = keras.layers.Input(shape=(None,))
embd = keras.layers.Embedding(input_dim=32,
output_dim=16,
mask_zero=True)(inputs)
lstm = keras.layers.Bidirectional(keras.layers.LSTM(units=16,
return_sequences=True))(embd)
att = SeqSelfAttention(attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL,
kernel_regularizer=keras.regularizers.l2(1e-4),
bias_regularizer=keras.regularizers.l1(1e-4),
attention_regularizer_weight=1e-4,
name='Attention')(lstm)
dense = keras.layers.Dense(units=5, name='Dense')(att)
model = keras.models.Model(inputs=inputs, outputs=[dense])
model.compile(
optimizer='adam',
loss={'Dense': 'sparse_categorical_crossentropy'},
metrics={'Dense': 'categorical_accuracy'},
)
model.summary(line_length=100)Make sure to add SeqSelfAttention to custom objects:
import keras
keras.models.load_model(model_path, custom_objects=SeqSelfAttention.get_custom_objects())对于decoder等场景,为了保持输出固定只能使用上文的信息:
SeqSelfAttention(
attention_width=3,
history_only=True,
name='Attention',
)