You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
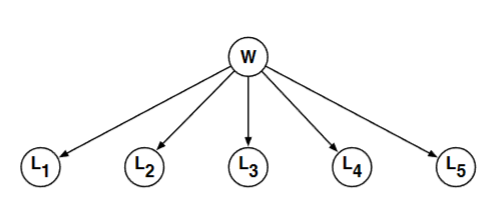
Consider the belief network shown below, where the random variable $W$ stores a five-letter word and the random variable $L_i \in \{\mathrm{A}, \mathrm{B}, \ldots, \mathrm{Z}\}$ reveals only the word's $i$ th letter. Also, suppose that these five-letter words are chosen at random from a large corpus of text according to their frequency:
where $\text{COUNT}(w)$ denotes the number of times that $w$ appears in the corpus and where the denominator is a sum over all five-letter words. Note that in this model the conditional probability tables for the random variables $L_i$ are particularly simple:
$$
P\left(L_i=\ell \mid W=w\right)= \begin{cases}1 & \text { if } \ell \text { is the } i \text { th letter of } w, \ 0 & \text { otherwise. }\end{cases}
$$
Now imagine a game in which you are asked to guess the word $w$ one letter at a time. The rules of this game are as follows: after each letter (A through Z) that you guess, you'll be told whether the letter appears in the word and also where it appears. Given the evidence that you have at any stage in this game, the critical question is what letter to guess next.
Let's work an example. Suppose that after three guesses - the letters D, I, M - you've learned that the letter I does not appear and that the letters D and M appear as follows:
In other words, pick the letter $\ell$ that is most likely to appear in the blank (unguessed) spaces of the word. For any letter $\ell$ we can compute this probability as follows:
where in the third line we have exploited the conditional independence (CI) of the letters $L_i$ given the word $W$. Inside this sum there are two terms, and they are both easy to compute. In particular, the second term is more or less trivial:
$$
P\left(L_2=\ell \text { or } L_4=\ell \mid W=w\right)= \begin{cases}1 & \text { if } \ell \text { is the second or fourth letter of } w \ 0 & \text { otherwise. }\end{cases}
$$
In the numerator of Bayes rule are two terms; the left term is equal to zero or one (depending on whether the evidence is compatible with the word $w)$, and the right term is the prior probability $P(W=w)$, as determined by the empirical word frequencies. The denominator of Bayes rule is given by:
where again all the right terms inside the sum are equal to zero or one. Note that the denominator merely sums the empirical frequencies of words that are compatible with the observed evidence.
Now let's consider the general problem. Let $E$ denote the evidence at some intermediate round of the game: in general, some letters will have been guessed correctly and their places revealed in the word, while other letters will have been guessed incorrectly and thus revealed to be absent. There are two essential computations. The first is the posterior probability, obtained from the Bayes rule:
The second key computation is the predictive probability, based on the evidence, that the letter $\ell$ appears somewhere in the word:
$$
P\left(L_i=\ell \text { for some } i \in\{1,2,3,4,5\} \mid E\right)=\sum_w P\left(L_i=\ell \text { for some } i \in\{1,2,3,4,5\} \mid W=w\right) P(W=w \mid E) .
$$