This repository contains a second implementation of TweetyNet, a convolutional neural network that processes spectrogram images of recorded bird song and assigns a syllable label to each discrete time step [1]. In other words, TweetyNet automates annotation of birdsong by syllable type.
Our work extends the original project by (1) validating network performance in the face of significant noise and (2) supporting multi-channel input to the network where each channel is a spectrogram representing an identical audio sample but is constructed with varying time-frequency resolution. Since, in this implementation, the input channels can have different dimensions we modify TweetyNet's first layer to convolve and pool each channel to common size if necessary. Below is a diagramatic representation of TweetyNet sourced from the original publication. This diagram accurately represents the architecture of our implementation (less changes like input dimensions) when the network is processing typical (non multi-channel) input [1].
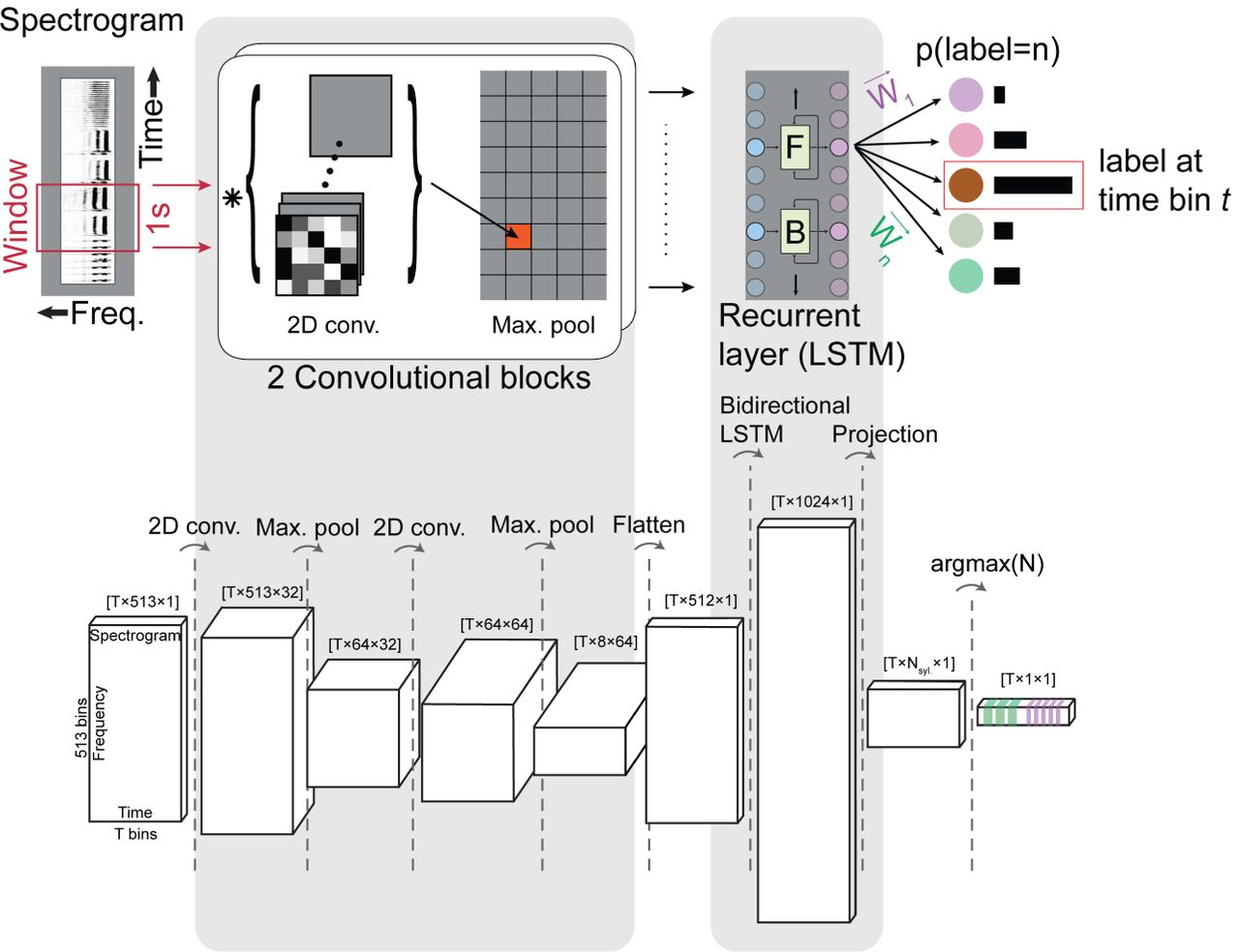
Tweetynet is a fully supervised the network that learns from labelled training data. In our experiments we exclusively relied on a publically available, labeled dataset of Bengalese Finch song [2]. To support usage of Multi-TweetyNet we also provide software to generate spectrograms and corresponding labels. The utilities for generating spectrograms are easily applied to novel audio datasets by making simple modifications, subject to the encoding of the source audio. Similarly, the software can be easily modified to support generating labels from novel annotation schemas.
To explore network performance with noisy audio we added gaussian noise to recordings from the aforementioned dataset. Images below offer an example of a noiseless and noisy spectrogram of 1 second of recorded song.


Our results validate previous reports from [1]. In addition, we demonstrate TweetyNet's sensitivity to input representation (particularly in the presence of noise) and the success of a multi-channel, "wideband" input. The later result comes with caveats discussed below. In the figures shown below the legend labels indicate the FFT size used to construct inputs to the network. The labels "Wideband" and "Extreme-Wideband" correspond to networks processing multi-channel inputs, each composed of input representations derived from FFT sizes of 256, 512, 1024 and 64, 128, 256, 512, 1024, 2048, 4096, respectively.


To get started, clone this repository. There are five fundamental pieces of source code found in main/src/ and corresponding parameter specifications found in main/parameters/. If possible, we highly recommend training the network on a CUDA enabled machine. Broadly speaking, the workflow to use this software from scratch is as follows:
- Collect the dataset from [2]
- Install dependencies. We recommend a conda based virtual environment. From
pipyou will need the following:evfuncs. Fromcondayou will needpytorch (last working test with v3.9.0)andtorchvision. If you are working on a machine with CUDA you will need to install additional software to properly leverage your compute. For the provideddemo.ipynbyou will needmatplotlibinstalled. You may also need to installipykernel. - Specify global parameters in
/main/parameters/params.py - Parameterize
/main/src/spect_writer.pyvia/main/parameters/spect_writer_params.pyin order to generate spectrograms - Parameterize
/main/src/labelvec_writer.pyvia/main/parameters/labelvec_writer_params.pyin order to generate labels - Tune the network architecture via
/main/parameters/network_params.py - Train the network.
We have had success installing and running the software on MacOS Big Sur (Intel) and Ubuntu 18.04.
For a demo detailing the full work flow described above see the notebook /main/demo.ipynb.
[1] https://www.biorxiv.org/content/10.1101/2020.08.28.272088v1.full
[2] https://figshare.com/articles/dataset/Bengalese_Finch_song_repository/4805749
Our re-implementation of TweetyNet was, in part, motivated by the hypothesis that we may be able to improve performance by varying the relative time-frequency resolution of input spectrograms. Applying the STFT to a discrete time signal we can generate a frequency-over-time representation of the signal. The critical parameters of this transformation include the FFT size and the window size, which dictate the number of discrete frequency bins to be computed and the number of samples over which to compute the sliding FFT, respectively. Since the FFT frequency resolution is determined by the length of the signal being analyzed and the sampling rate there exists a fundamental tradeoff between time and frequency resolution in the STFT.
To our knowledge there has been no systematic evaluation of the representational power of Bengalese Finch spectrograms computed with different time-frequency resolutions. Incidentally, Bengalese Finch song demonstrates complex temporal dynamics with variability in the length of both individual syllables and periods of non-singing. With this in mind, our goal was two-fold: evaluate how sensitive TweetyNet's performance is to variation in input representation time-frequency resolution and determine if the incorporation of less commmonly used representations into multi-channel inputs could result in improved performance.
Below we show a detailed schematic of the first convolution + max pooling layer of the network processing a multi-channel input. In effect, we process each channel independently with a convolutional and max-pooling kernel with an appropriate aspect ratio. The convolution is input size preserving; however, the max-pooling operation downsamples each channel to identical dimensions so the channels can be stacked before being processed by the second convolution-pooling layer.
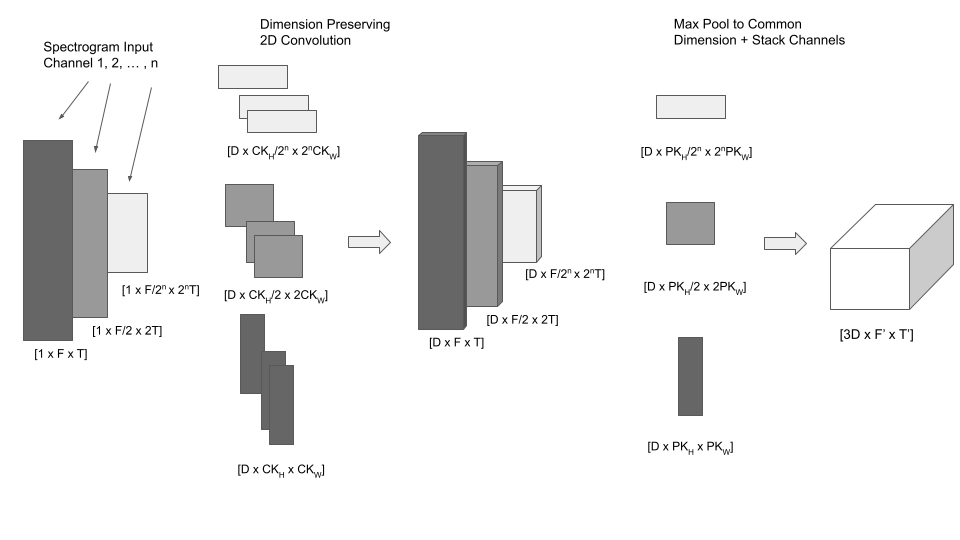
F and T correspond to the number of frequency and time bins in the channel containing the spectrogram with the greatest frequency resolution, which we will refer to as S. D is the number of filters used for each channel. CK and PK correspond to the convolution and max-pooling kernel size (subscripted by W and H for height and width).
Simply put, we did not find a reliable boost in performance when processing multi-channel input; however, one of the multi-channel configurations we studied performed approximately as well as the best single-channel inputs. Directions for future research could involve rigorously evaluating the contribution from particular input channels in the multi-channel approach to determine whether a multi-channel approach carries utility for domains where the best FFT parameterization is not known apriori.