Logspout stops posting logs from some containers #377
Comments
|
Same issue, similar config. I can see quite a few error messages like these: for various containers. Is that actually an error or not? Does it mean it didn't receive logs within a certain timeframe oder something actually broke? Running latest logspout including the #374 fix from our forked repo. |
|
I tried switching to TCP as I could as well see some "message too long" errors. Now I am not getting any logs in my ELK stack anymore, but Apparently Please shed some light. |
|
I experience a similar issue with streaming to a remote syslog at papertrailapp. Restarting the logspout container fixes it. Came here looking to see if I'm the only one; apparently I'm not. |
|
I had the same problem。Some containers log can't be send to logstash. Restarting the logstpout can fix it。But, after a few minutes, the problem has arisen again. There was no error message of logspout. Some information:
|
|
I've also ran into this issue multiple times. Before it was happening due to losing connection to papertrail. The logspout container logs did show that. But now its happening and there is no interesting log output from the logspout container. |
|
can someone provide full log output from do you see the following message? |
|
nothing more? |
|
@lionheart2016 setting the env var |
|
I might be having the same problem. I believe it is related to this: but I am not sure.
|
|
I'm looking into this, what I found is this loop inside pump.go: Line 234 in e671009 It looks to me like that loop is intended to spin around and around relatively slowly, basically, it is supposed to re-create this long-running streaming HTTP request to the docker API, whose response body contains the log stream from the desired container. However, in my environment, that loop spins around many many times per second, consuming half of the CPU cycles on the host!! Therefore, as an experiment, I tried setting to This way at least this silly loop will not spin any faster than once every 10 seconds. Also, due to the way I've also started looking at collecting metrics from the log pumps and then configuring them to be automatically re-booted when they stop reporting log lines being pumped. I have been testing it using this docker-compose: Due to that afformentioned bug in docker, with this setup, the stream of logs will cease when the log rotates: I am hoping to use this setup to test my metrics-based pump-restarter solution. |
It doesn't log anything. We see the log stream drop off in our log aggregation system (1 container at a time, not all at once) and there is zilcho in the logspout log around that time that it drops off. Even with DEBUG=1 logging on. Now, this statement is true (for us) but it might be a bit misleading for everyone else. Let me explain, like I mentioned before, in our environment that loop inside Line 235 in e671009 Line 251 in e671009 Line 249 in e671009 also, line 245 was changed, I changed TO So, besides those things which are called I was able to get my metrics-based "kick the tv to get the antenna to work" solution to at least "go off" in my test environment. If it helps us solve our problem for real, I will see what I can do to contribute it back. However its quite a hack at this point :( |
|
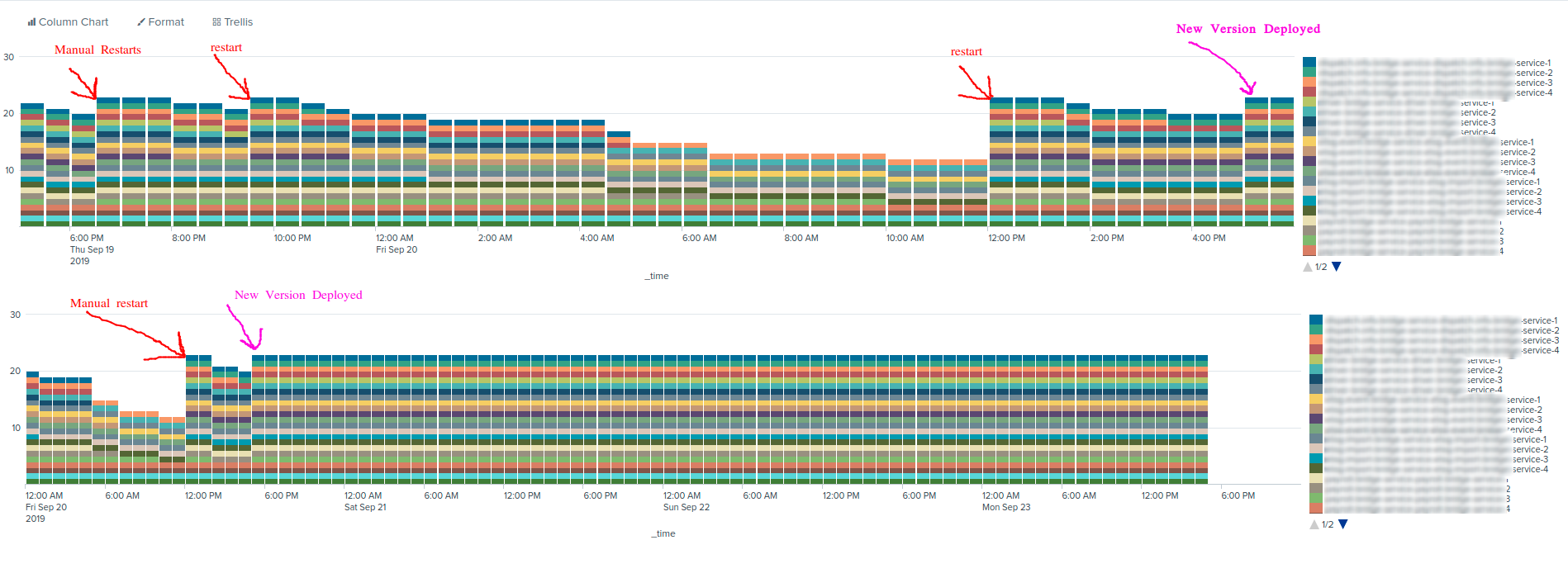
I was able to solve this by re-creating the pumps when metrics detect the log stream has halted un-expectedly. This is a graph of time intervals and whether or not they contained at least 1 log message from each of our container instances. As you can see prior to my changes the logs from certain containers would drop off over time. When I get time (when im not at work), I can push a slightly-cleaned-up version of my code to a fork for you guys. (Edit: over longer intervals of time my metrics based alert and re-create system proved to be imperfect. Usually on containers which log infrequently. Its possible for the alert to get confused about the difference between a container that logs infrequently and a container that died. when this happens it does not restart the pump and things can still die permanently) |
|
Please recognize that this is not meant to be a perfect contribution ready for merge. I am just sharing what I did in hopes that someone else can learn from it, take and run with it or use this as a stepping stone to discover a better solution. Note that I did not test this at all beyond running forestjohnsonpeoplenet@d927709 My code will attempt to send InfluxDB formatted metrics to a configurable endpoint as well (telegraf or influxdb). Remove this yourself if you wish. Otherwise you can leave it on in UDP mode and it will just scream into the void maybe?? Note that I also changed the default value for the inactivity timeout to 10s. And I added this sleep to prevent accidental DOS attacks against the docker API when the Docker API is being buggy: forestjohnsonpeoplenet@d927709#diff-c035a4a8cbe5cb4d97ac075d044b8b84R303 Also, note that my code will adjust Alternatively, you may be able to fix this issue by updating to the the latest verison of docker. I say that because I was not able to re-produce the issue on my local machine when using the latest version of Docker CE. |
|
Have this been fixed yet (or have @forestjohnsonpeoplenet solution been implemented)? I'm having the same issue, and not even @richardARPANET solution with |
|
Does logspout send logs only from currently running containers? I am not seeing logs from container which execute and then terminate. Logs are sent if the same container is kept running (and without the -t option). |
Hello there,
I use logspout in docker cloud where I have multiple app containers in the single server. However logspout sometimes stops sending logs to cloudwatch for some of them. I see no error, they are just missing. Logspout container restart helps. This is my configuration:
The text was updated successfully, but these errors were encountered: