예비 답안 보기 (👈 Click)
-
단발성으로 대용량 데이터를 처리하는 프레임워크로 Spring의 특성인 DI, AOP, PSA를 사용할수 있고 JDBC와 JPA를 지원한다.
-
사용 이유
- 대용량의 데이터를 처리하는데 사용빈도가 적고 애플리케이션 서비스 기능에 영향을 미치지 않으며 중복 처리를 방지하기 위함.
-
조건
- 대용량 : 대량의 데이터를 읽고, 쓰고, 계산할 수 있어야 한다.
- 자동화 : 사용자의 개입없이 작동할 수 있어야 한다.
- 견고성 : 잘못된 데이터에 대해 충돌, 중단 없이 처리할 수 있어야 한다.
- 신뢰성 : 잘못 된 곳을 추적할 수 있어야 한다.
- 성능 : 지정 시간안에 작업을 처리하거나 다른 서비스를 방해하지 않아야한다.
예비 답안 보기 (👈 Click)
- Job이 실행되면 해당 Job에 대한 작업 데이터인 Batch 메타 데이터가 생성되는데, Batch 메타 데이터를 저장할 메타 데이터 테이블이 필수로 필요하다.
- 필요 이유
- 작업에 대한 실행 정보, 실패 여부 등을 저장하여 모니터링 하기 위함이다.
- 종류
- Batch Job Instance
- Job의 생성정보
- job Id, version, job name, job key (job 중복 수행 체크를 위한 고유 키, job name과 파라미터로 키값이 결정됨)
- Batch Job Execution
- Job의 실행 정보
- Job의 실행 상태, Job 정보 등..
- Batch status : 실행 상태
- Exit status : 실행 후 실행 결과 상태
- Batch Job Execution Param
- Job에서 사용된 파라미터 정보
- Job Execution과 1대1 매칭
- Batch Job Execution Context
- Job Execution와 1대1로 매핑되어있으며 작업 중 사용되는 정보 저장
- Batch Step Execution
- Job에서 실행되는 step 실행 정보를 담는 테이블
- Batch Step Execution Context
- step에서 사용되는 모든 정보를 기록하는 테이블
- Batch Job Instance
예비 답안 보기 (👈 Click)
- Architecture
- Application
- Core
- Infrastructure
- 구조
-

-
Job
- 하나의 배치 작업
-
Step
- Job에서의 작업 단계
-
Tasket
- Step에서 실질적 작업을 다루는 부분으로 하나의 정의된 작업만 수행한다.
- Step은 작업을 한곳에서 수행하는 Tasklet이 있고 작업을 역할별로 분리한 Reader, Processor, Writer로 구성된 Tasklet이 있다.
-
예비 답안 보기 (👈 Click)
-
기본 Spring에서 제공하는 bean scope는 Singletone으로 애플리케이션 실행시점에 빈을 생성하여 사용한다. Spring batch에서는 애플리케이션 실행 시점이 아닌 호출 시점까지 Bean의 생성을 지연시키는 @JobScope와 @StepScope가 있다.
-
@JobScope는 Job실행시점에 인스턴스를 생성
-
@StepScope는 Step실행시점에 인스턴스 생성
-
Spring의 request scope처럼 요청시에 빈이 생성된다.
-
사용 이유
-
동일 컴포넌트 병렬처리 또는 동시처리 가능
- Step에서 Tasklet이 있고 해당 Tasklet이 지역변수를 가지고 있고 이 지역변수를 변경하는 작업을 하는 경우, 해당 Tasklet를 SingleTone으로 빈을 생성하게 되면 병렬적으로 처리할때 다른 곳에서 Tasklet을 사용할때 데이터가 오염 된다. 그렇기 때문에 호출 시점에 빈을 생성하게 되면 각 Step은 별도의 Tasklet을 가지고 작업을 수행하기때문에 다른 Tasklet에 영향을 미치지 않게 된다.
-
Late Binding
-
JobParameter는 애플리케이션 실행시점에 꼭 할당하지 않아도 특정 시점에 자유롭게 할당시킬수 있다. 그렇기 때문에 JobParameter를 Job이나 Step에서 사용할때 언제 할당될지 모르기 때문에 지정 scope가 실행될때까지 Bean생성을 지연시켰다가 JobParameter를 바인딩 하여 사용한다.
만약, 미리 Application실행시점에 Bean을 등록해 놓는다면 JobParameter는 아직 바인딩이 안되어있는 상태이기 때문에 jobparameter를 찾을수 없다는 에러를 발생시킨다. (뇌피셜)
-
Batch 컴포넌트에 동적인 파라미터를 전달하는 JobParmeter는 지정한 scope의 bean이 실행되는 시점에 호출되게 된다. 그렇기 때문에 singletone으로 생성된 Batch 컴포넌트에 JobParameter를 선언하게 되면 "not found jobparameter" 가 발생하기 때문에 실행되는 시점에 bean을 생성하는 @JobScope와 @StepScope가 지정된 Batch 컴포넌트에 JobParameter를 선언하여 사용할수 있다. (추상적 대답)
-
-
-
주의 사항
- @JobScope나 @StepScope가 지정된 Batch 컴포넌트는 반환되는 타입을 프록시 객체로 감싸서 반환하게 된다. 그렇기 때문에 인터페이스를 반환하게 되면 인터페이스가 가지고 있는 메소드를 오버라이딩하여 사용되기 때문에 해당 Batch 컴포넌트에서 반환되는 값을 가지고 사용하는 곳에서 NPE과 같은 에러를 발생시킬수 있습니다. 그렇기 때문에 scope를 지정한 Batch 컴포넌트에서는 구현체를 반환 타입으로 지정해줘야 한다.
예비 답안 보기 (👈 Click)
-

-
Chunk는 한번에 하나씩 데이터를 읽어서 Chunk단위를 만들고 Chunk단위로 트랜잭션을 다루는 것.
-
Chunk지향인 이유
청크지향 프로세싱이란, 일반적으로 대용량 데이터를 처리하는 배치 프로세스의 특성상 대상 데이터들을 하나의 트랜잭션으로 처리하기에는 어려움이 있기때문에 대상 데이터를 임의의Chunk단위로 트랜잭션 동작을 수행하는것을 말합니다.
-
Spring Batch는 Chunk 지향으로써 Chunk 지향 처리를 위해 ChunkOrientedTasklet을 사용한다.
-
ChunkOrientedTasklet
- Chunk지향 처리의 전체로직을 다루는 클래스.
- Chunk지향은 Chunk단위 별로 트랜잭션을 생성하고 세션을 종료한다.
- 구조
- Reader : ChunkSize만큼의 데이터를 하나씩 읽어온다.
- Processor : ChunkSize만큼 읽어온 데이터를 하나씩 가공한다.
- Writer : ChunkSize만큼 쌓이고 가공된 데이터를 처리한다.
예비 답안 보기 (👈 Click)
-
Spring Batch에서 PagingItemReader를 통해 데이터를 읽어오는 경우가 있다.
-
이때 pageSize는 데이터를 한번에 조회할 Item의 양을 얘기하며 chunkSize는 트랜잭션 처리를 위한 Item의 양이다.
- 12개의 데이터가 있고, chunksize가 5라면 3번의 itemRead가 발생
-
예를 들어 pageSize가 10이고 chunkSize가 50이면 한번의 doRead()에서 10개의 데이터를 가져오고 chunkSize를 맞춰주기 위해 총 5번의 doRead()가 발생한다.
-
PageSize와 ChunkSize는 동일하게 설정하는 것을 지향한다.
- pageSize와 chunkSize를 다르게 설정하면 chunkSize를 맞추기 위해 page만큼의 추가 조회 쿼리가 생성되는데 이로 인해 성능 이슈가 발생할 수 있고 영속성 컨텍스트가 깨지는 문제가 발생 수 있기 때문이다.(JpaPagingItemReader)
- pageSize와 chunkSize를 같게 설정해주지 않으면 총 5번의 쿼리가 발생했다고 했을때(doRead()) 마지막 쿼리를 제외하고 앞에 4개의 결과의 트랜잭션 세션이 끊기게 되어 LazyInitializationException이 발생하게된다.
- pageSize와 chunkSize를 다르게 설정하면 chunkSize를 맞추기 위해 page만큼의 추가 조회 쿼리가 생성되는데 이로 인해 성능 이슈가 발생할 수 있고 영속성 컨텍스트가 깨지는 문제가 발생 수 있기 때문이다.(JpaPagingItemReader)
예비 답안 보기 (👈 Click)
- Chunk지향 처리를 위해 ItemReader, ItemProcessor, ItemWriter로 구성된 ChunkOrientedTasklet 중 데이터를 읽어오는 역할.
- 구조
- ItemReader 인터페이스 : 데이터를 읽어오는 read() 정의
- ItemStream 인터페이스
- open : ItemReader에서 필요한 상태를 초기화 (데이터 베이스 연결, Job 재시작시 이전 상태 복원 등)
- update : Job의 상태를 갱신하는 처리
- Close : ItemReader를 닫을 때
- 종류
- Cursor 기반의 ItemReader
- ResultSet의 next()를 통해 stream으로 데이터를 하나씩 꺼내온다.
- Cursor는 하나의 connection으로 데이터베이스와 애플리케이션이 통신하는데 Batch 작업이 끝나기 전에 connection 세션이 종료될 수 있기 때문에 timeout을 크게 설정해야한다. 만약 Batch 수행이 오래걸리는 경우 PagingItemReader를 사용하는 것이 좋다.
- 장단점
- 장점
- 모든 데이터를 조회한 뒤 cursor를 이동하는 방식으로 데이터를 가져오기 때문에 높은 성능을 보장한다.
- 스냅샷 방식으로 동작하기 때문에 데이터의 변경에 안전하다.
- connection이 종료될때까지 다른 트랜잭션의 결과를 무시한다.
- 단점
- 스냅샷방식을 사용하기 때문에 많은 메모리를 사용하다.
- 단일 ResultSet을 가지기 때문에 Thread safe 하지 않다.
- 긴 timeout이 필요하다.
- 장점
- 종류 : JdbcCursorItemReader, HibernateCursorItemReader
- Paging 기반의 ItemReader
- limit (행의 개수)와 offset (시작 행 번호)을 지정하여 paging쿼리마다 connection 연결로 통신한다.
- 데이터베이스마다 paging 전략이 있기 때문에 PagingQueryProvider에 datasource를 설정하여 queryProvider속성에 설정하면 자동으로 데이터베이스에 맞는 provider를 제공해준다.
- 장단점
- 장점
- 스냅샷을 찍지 않아 메모리 이슈가 없다
- timeout에 자유롭다
- 병럴처리가 가능하다.
- 단점
- 매번 connection과 sort가 발생하기 때문에 느리다
- 실시간 데이터를 조회하기 때문에 데이터 무결성이 깨질수도 있다
- 정렬이 필수적으로 필요하다.
- 장점
- 종류 JdbcPagingItemReader, HibernatePagingItemReader, JpaPagingItemReader
- PagingItemReader 주의 사항
-
데이터를 조회해서 조건절을 update할때 limit은 동일하게 0부터 offeset만큼 증가하게 된다. 하지만 데이터 조회시에는 이전에 변경된 데이터는 제외되어 조회되기 때문에 offeset이 건너뛰어지는 이슈가 발생한다. 그렇기 때문에 JpaPagingItemReader에서
getPage를 오버라이딩하여 0을 항상 반환하게 하면 특정 offeset을 건너뛰지 않게 된다. -
-
Paging시 정렬 기준을 선언하지 않는다면 페이징 별 쿼리가 독립적인 정렬기준을 만들어 앞에 조회되었던 데이터가 다음 조회에 포함되거나 빠지기도 한다. 그렇기 때문에
Order by id와 같은 정렬을 선언해주거나CursorItemReader를 사용한다.
-
- Cursor 기반의 ItemReader
- ItemReader 주의사항
- JpaRepository를 사용해서 조회쿼리를 쉽게 하기 위해 ListItemReader, QueueItemReader를 사용할때 Chunk단위 트랜잭션은 지원해주지만 paging과 cursor를 지원해주지 않기 때문에 대용량 데이터를 처리하는데 어려움이 있다. 이때 RepositoryItemReader를 사용하면 JpaRepository를 사용할수 있으면서 paging기능을 제공받을 수 있다.

예비 답안 보기 (👈 Click)
- JPA로 paging 기능을 제공하는 ItemReader
- ItemReader 생성시 EntityManager를 추가로 선언해야한다.
- 과정
- ChunkProvider의 provider에서 chunk size만큼 doRead() 호출
- AbstractItemCountingItemStreamItemReader (추상클래스).doRead()이 호출되고 해당 메소드는 PagingItemReader의 추상클래스인 AbstractPagingItemReader의 doRead()를 호출한다.
- read가 처음이거나 다음 페이지를 호출해야하는 경우 doReadPage() 호출
- AbstractPagingItemReader (JpaPagingItemReader 부모클래스)
- doReadPage()에서 추가적인 조회 쿼리를 요청하여 결과를 전부 저장한다.
- ChunkProvider의 provider에서 chunk size만큼 doRead() 호출
- PagingItemReader를 수행할때, chunk size = page size를 동일하게 하였다면, 처음 doRead()로 데이터를 읽어올때 doReadPage()에서 한번의 쿼리로 요청 데이터를 모두 읽어온다. 그 후, results에 모든 데이터를 저장해놓고 chunk size만큼 chunkProvider에서 doRead()를 요청하는데, 쿼리를 반복해서 요청하는 것이 아닌, 처음에 저장해놓은 results를 캐싱해놓고 캐싱된 결과를 index로 chunk size가 될때까지 하나하나 읽어오는 것이다. 즉, doRead()는 chunk size만큼 호출되지만 한번의 쿼리로 결과를 캐싱해놓고 읽어오는것.
- 주의할 점
- JpaPagingItemReader는 추가 페이징 쿼리를 요청할때 독자적인 트랜잭션을 사용하기 때문에 페이징 처리 후 트랜잭션을 초기화 한다. 그렇기 때문에 여러개의 페이징 쿼리가 생성되었을 때, 마지막 쿼리를 제외하고 앞의 쿼리에서는 트랜잭션 세션이 종료되어 lazy 로딩이 불가능하다. (chunk단위 트랜잭션은 보장) 해결방법으로 pageSize와 chunkSize를 동일하게 설정하여 모든 데이터가 영속성 관리를 받을 수 있게 한다. (pageSize와 chunkSize를 동일하게 해야하는 이유)
예비 답안 보기 (👈 Click)
- Spring Batch에서 JPA를 사용하여 ToMany관계의 엔티티를 조회할때 N+1 문제가 발생한다.
- HibernatePagingItemReader, HibernateCursorItemReader들은 @BatchSize를 선언해주어 In 쿼리를 생성하거나 fetch join을 사용해서 N+1문제를 해결할 수 있다.
- 하지만 JpaPagingItemReader에서는 fetch join이나 BatchSize설정으로도 N+1문제가 발생한다.
- Batch는 트랜잭션 내부에서 수행되게 된다.
- 다른 ItemReader에서는 Chunk단위로 트랜잭션이 관리되지만 JpaPagingItemReader인 경우 Reader (doReadPage())에서 진행하기 때문에 각 paging 쿼리가 생성될 때마다 별개의 트랜잭션으로 진행되기 때문에 이전의 요청은 트랜잭션 세션이 종료된 상태이기 때문에 BatchSize가 적용되지 않아 추가 조회 쿼리를 생성해야한다.
- 해결방법
- JpaPagingItemReader에서 doReadPage에서의 트랜잭션을 제거하면 Chunk단위로 트랜잭이 관리되어 N+1을 해결할 수있다.
- 하지만 안정성이 확실하지 않기 때문에 추천하는 방법은 아니다.
예비 답안 보기 (👈 Click)
-
ChunkOrientedTasklet에서 Chunk단위로 읽어온 item list를 다루는 역할.
-
chunk 단위로 ItemWriter를 하는 이유는 애플리케이션과 데이터베이스 간의 connection 횟수를 최소화 하기 위함.
-
종류 : JdbcBatchItemWriter, HibernateItemWriter, JpaItemWriter
-
JdbcBatchItemWriter
- JdbBatchItemWriterBuilder의 속성
- columnMapped : key,value 형식으로 Insert SQL의 values를 매핑
- beanMapped : Pojo 기반으로 Insert SQL의 values를 매핑
- JdbBatchItemWriterBuilder의 속성
-
JpaItemWriter
- JdbcBatchItemWriterBuilder와 속성은 동일하고 entityManger 속성만 추가
- JdbcBatchItemWriter는 Dto를 가져와 SQL로 지정된 쿼리가 실행되지만 JpaItemWriter는 넘어온 Item을 그대로 merge하여 테이블에 반영하기 때문에 Entity타입을 제네릭 타입으로 선언해야한다.
-
CustomWriter
- 읽어온 데이터를 외부 API로 전달하거나 여러 Entity를 동시에 save할때 등의 경우에는 Writer를 custom하여 사용해야한다.
- ItemWriter를 상속받아 writer() 메소드를 오버라이드 하여 customwriter를 구현한다.
-

예비 답안 보기 (👈 Click)
-
ItemReader에서 넘겨준 item list를 개별로 가공하거나 필터링 한다.
-
ItemProcess에는 두개의 제네릭 타입이 필요하다.
-

- <Reader에서 받아올 타입, Writer에 넘겨줄 타입>
- chunk기반으로 트랜잭션이 관리되기 때문에 lazy로딩 가능.
-
-
CompositeItemProcessor
- 여러 processor를 사용하고 싶을때 processor간 체이닝을 지원해서 processor의 작업을 분리할 수 있다.
- CompositeItemProcessor를 생성해서 processor를 담은 list를 CompositeItemProcessor의 delegates에 설정해준다.
-

예비 답안 보기 (👈 Click)
- 멱등성 : 연산을 여러번 해도 결과가 달라지지 않는 성질
- 멱등성을 유지하는 기능
- 첫번째로 값을 Update하고 N-1번 반복되는 기능을 요청했을때 앞의 요청과 동일한 결과가 나오는 기능.
- 멱등성이 깨진 경우
- 내부에 LocalDate.now()를 사용해 오늘 생성된 데이터로 작업을 하는 Batch 작업이 있다고 할때, 날짜별로 기능을 수행하게 되면 다른 결과가 나오게되며 특정 날짜에 대한 결과를 반환하고 싶을땐 내부 코드를 수정해야하기 때문에 제어되지 않는 코드이므로 멱등성이 깨진 기능이다.
- JobParameter를 사용해서 특정 날짜를 파라미터로 보내게되면 요청하는 날짜에 대한 결과는 동일하게 반환되기 때문에 멱등성이 유지되게 된다.
- Http공식문서에서 '전체 시퀀스의 단일 실행이 해당 시퀀스의 전체 또는 일부 재실행을 통해 변경되지 않는 결과를 생성하는 경우 시퀀스는 멱등성'이라고 한다. Get, Put, Delete가 멱등성이라 했고, 나는 다른 파라미터값을 가져도 각 파라미터값에 따라 불러오는 값은 결과는 결국 변경되지 않고 동일하게 반환되기 때문에 멱등성이 유지된다고 생각한다.
예비 답안 보기 (👈 Click)
-
작업 실패시 skip이나 retry를 통해 예외를 처리한다.
-
skip과 retry는 step설정에서 faultTolerant()를 선언하고 사용한다.
-
skip
- skip() : 선언 예외 발생시 건너뜀
- skipLimit() : 선언 횟수만큼의 skip 발생시 job 실패 처리
- noSkip() : 해당 예외 발생시 예외 발생
-
retry
- retry() : 선언 예외 발생시 재시도
- retryLimit() : 선언 횟수만큼 retry 발생시 실패처리
- noRetry() : 해당 예외발생시 예외 발생
예비 답안 보기 (👈 Click)
-
JobLauncher
- SimpleJobLauncher
- 주어진 Job과 JobParameter를 가지고 JobRepository를 통해 최근 jobExecution을 요청한다
- jobExecution을 통해 JobExecution의 status의 상태를 체크하여 유효성 검사를 수행한다.
- JobParameter 유효성 검사
- 동일한 JobInstance에 대해서는 동일한 JobParameter금지 (Job 중복 실행 방지)
- JobRepository를 통해 새로운 JobExecution 생성
- TaskExecutor를 통해 Runnable로 실행되는 Job을 실행시킨다.
- job.execute(jobExecution)
- SimpleJobLauncher
-
Job
- AbstractJob
- JobLauncher에게 전달받은 JobExecution에서 JobParameter의 유효성 검사.
- JobExecution상태가 STOPPING이 아니라면 STARTED로 변경하고 Job 구현체 호출
- SimpleJob의 doExecute(JobExecution execution)
- Job을 모두 완료했다면 JobRepository를 통해 해당 JobExecution을 업데이트한다.
- SimpleJob
- 전달받은 JobExecution의 Step을 찾아서 StepHandler에게 전달한다.
- handleStep(step, execution)
- StepHandler를 통해 마지막 StepExecution을 통해 JobExecution의 상태를 업데이트한다.
- 전달받은 JobExecution의 Step을 찾아서 StepHandler에게 전달한다.
- AbstractJob
-
StepHandler
- SimpleStepHandler
- Step과 JobExecution을 받아와서 Step의 최신 정보 StepExecution을 JobRepository를 통해 받아온다.
- StepExecution의 정보를 통해 실행가능하다면 새로운 StepExecution과 StepExecutionContext를 생성한다.
- step을 호출한다.
- step.execute(currentStepExecution)
- StepExecution결과를 JobRepository를 통해 저장한다.
- SimpleStepHandler
-
Step
-
AbstractStep
- 전달받은 StepExecution의 STATUS를 STARTED로 변경하고 EXITSTATUS를 EXECUTING으로 변경한다.
- 상태가 변경된 StepExecution을 구현체인 Step을 호출한다.
- doExecute(stepExecution)
-
TaskletStep
- Chunk지향 배치 작업을 할때는 TaskletStep을 사용한다.
- 해당 Step에서는 트랜잭션 단위로 Tasklet을 수행한다.
- TransactionTemplate를 만들고 ChunkTransactionCallback을 통해 작업을 수행한다.
- TaskletStep의 doInTransaction이 호출되고 내부적으로 tasklet을 호출한다.
- tasklet(contribution, chunkContext)
- TaskletStep의 doInTransaction이 호출되고 내부적으로 tasklet을 호출한다.
-
-
Tasklet
-
ChunkOrientedTasklet
- Tasklet의 구현체중 하나로서, Chunk지향 처리의 전체 로직을 다루는 클래스
- ChunkProvider
- ChunkProvider.provide()를 통해 읽기 작업 수행
- SimplChunkProvider에서 ChunkSize만큼 ItemReader를 통해 Item을 읽어온다.
- ChunkProcessor
- ChunkSize만큼 Item을 읽어왔다면 ChunkProcessor.process()를 통해 변경과 쓰기 작업을 수행
- transform을 통해 ItemProcesser를 수행
- write를 통해 chunk단위만큼 읽어온 Item을 ItemWriter를 통해 쓰기작업을 수행한다.
-
예비 답안 보기 (👈 Click)
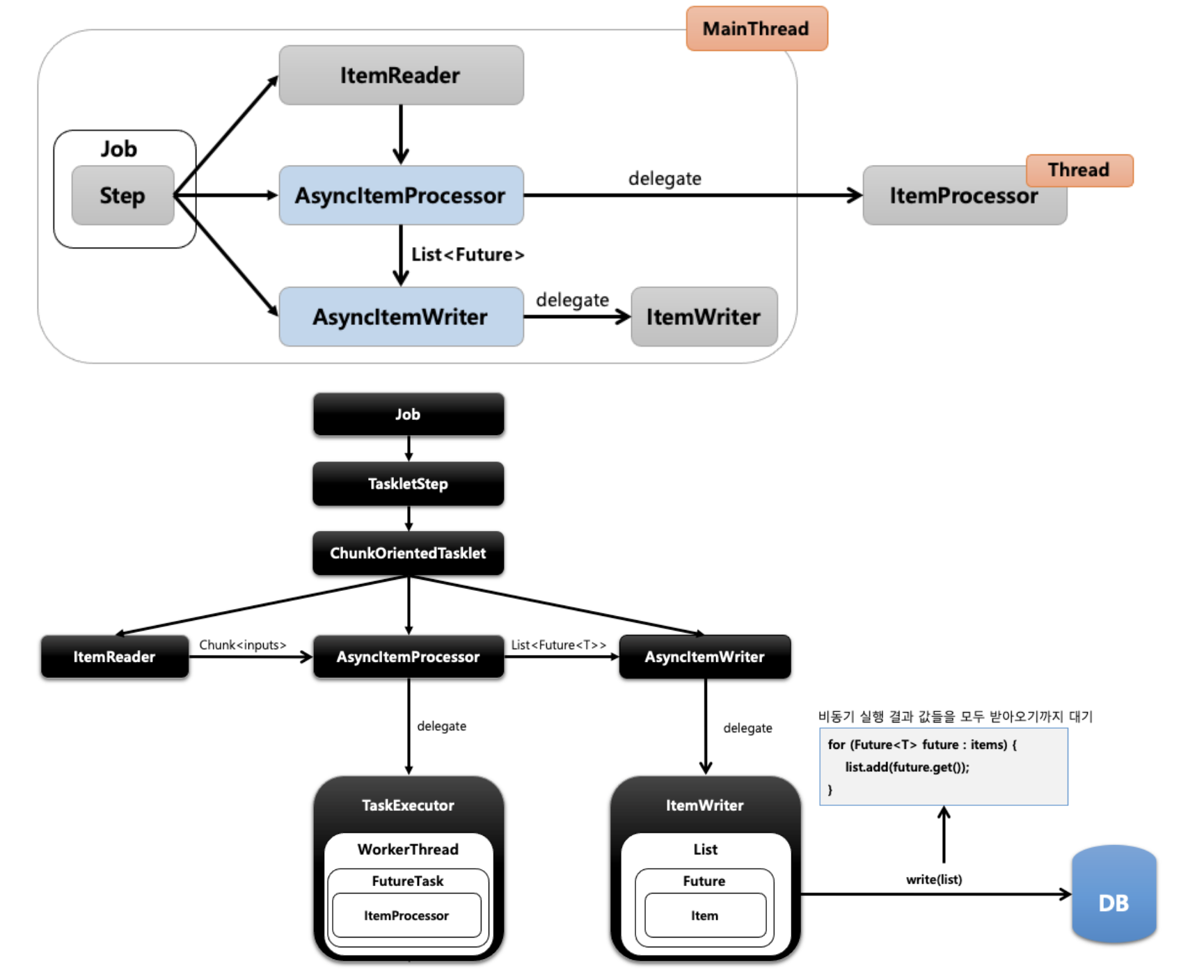
- AsyncItemProcessor / AsyncItemWriter
-
- ItemProcessor에게 별도의 스레드가 할당되어 작업을 처리하는 방식
- 과정
- ItemReader가 Chunk단위의 Items를 AsyncItemProcessor에게 전달
- AsyncItemProcessor가 ItemProcessor에게 작업을 위임
- AsyncItemProcessor는 TaskExecutor로 비동기 실행을 위한 스레드를 생성하고 해당 스레드는 FuturTask실행
- FuturTask는 Callback 인터페이스를 실행하며 그 안에서 ItemProcessor가 작업 처리
- AsyncItemProcessor를 실행하는 동안 메인 스레드는 AsyncItemWriter를 실행하고 AsyncItemWriter는 작업을 ItemWriter에게 위임
- ItemWriter는
List<Futur<T>>를 전달받는데 해당 결과(비동기 작업 by AsyncItemProcessor)를 전달받기 까지 대기 한 후 write 작업을 수행한다.
- ItemWriter는
-
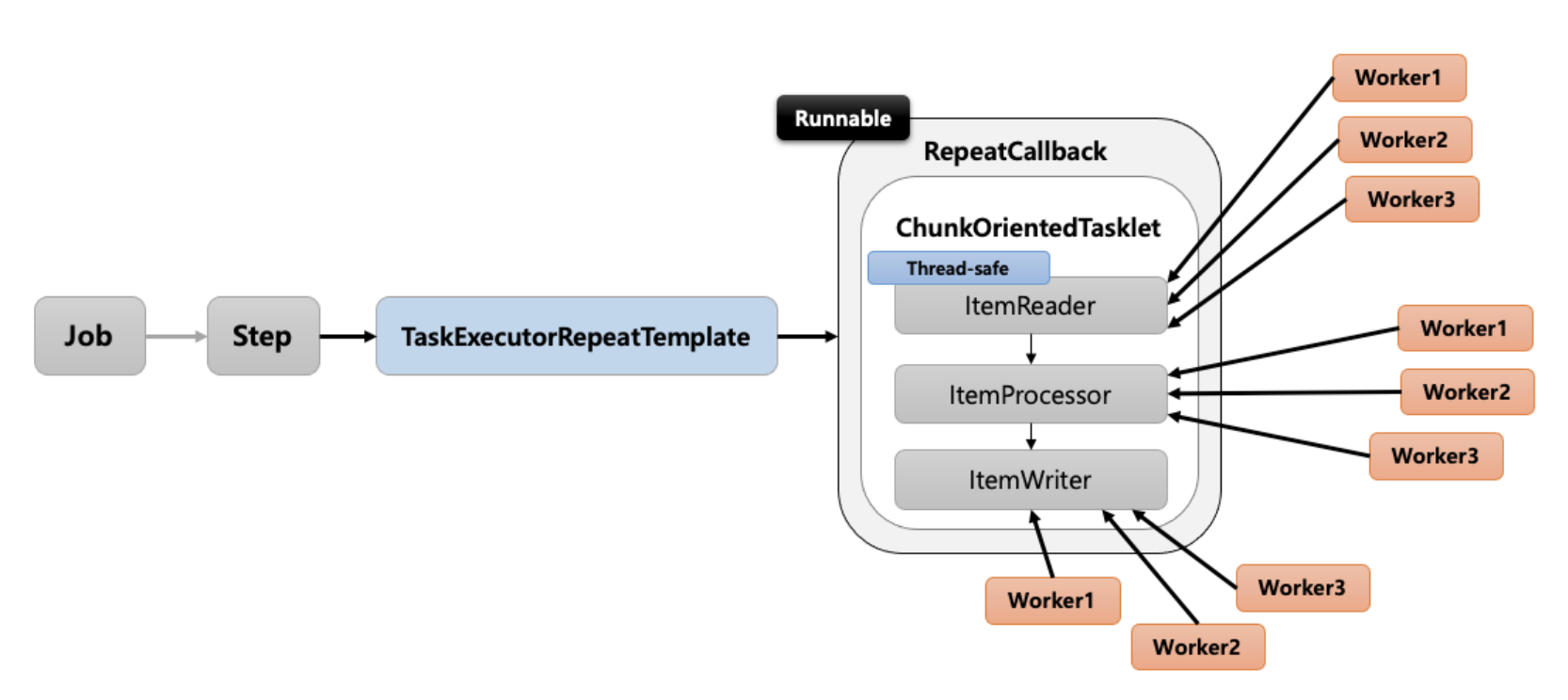
- Multi Thread Step
-
- Step내의 Chunk구조인 ItemReader, ItemProcessor, ItemWriter마다 여러 스레드가 할당되어 실행되는 방식 즉, Step내에 멀티스레드로 Chunk기반 처리가 이루어지는 구조
- StepBuilder시 멀티 스레드 사용을 위해 TaskExecutor를 선언해주고 throttleLimit으로 멀티 스레드에 사용할 스레드 개수를 선언
- 과정
- Step실행시 TaskExecutionRepeatTemplate 반복자를 이용해서 RepeatCallBack을 실행
- RepeatCallBack은 그 안에서 ChunOrientedTasklet을 반복적으로 실행한다.
- 주의사항
-
ItemReader와 ItemWriter는 Thread-Safe한 구현자를 사용해야한다.
- 스레드마다 중복 데이터를 읽지 않도록 동기화가 보장되어야한다.
- PagingItemReader는 thread-safe하지만 CursorItemReader는 thread-safe하지 않다.
- JpaItemWriter, HibernateItemWriter, JdbcBatchItemWriter는 thread-safe
- Thread-Safe하지 않은 ItemReader사용시 중복된 데이터를 읽어오고 예상한 결과를 보장할 수 없다.
SynchronizedItemStreamReader을 thread-safe하지 않은 ItemReader를 감싸서 사용하게 되면 Read작업이 synchronized메소드에 감싸져 호출되기 때문에 동기화된 읽기가 가능해진다.
-
ItemReader설정시 saveState() 옵션을 false로 선언해야한다.
- saveState(true)시 실패지점을 저장하고 재시작이 가능하게 한다.
- 단일스레드로 작업시 10개의 데이터가 있을때 8번째 작업에서 실패시 이전 7번째 데이터까지는 정상 처리되었다는 뜻이기 때문에 8번째 데이터부터 재실행이 가능하다.
- 하지만 멀티스레드 작업시 Chunk를 개별적으로 수행하기 때문에 이전 데이터가 정상 처리 여부를 알 수 없기때문에 실패지점 저장시 재실행지점이 오염될 수 있습니다.
-
-
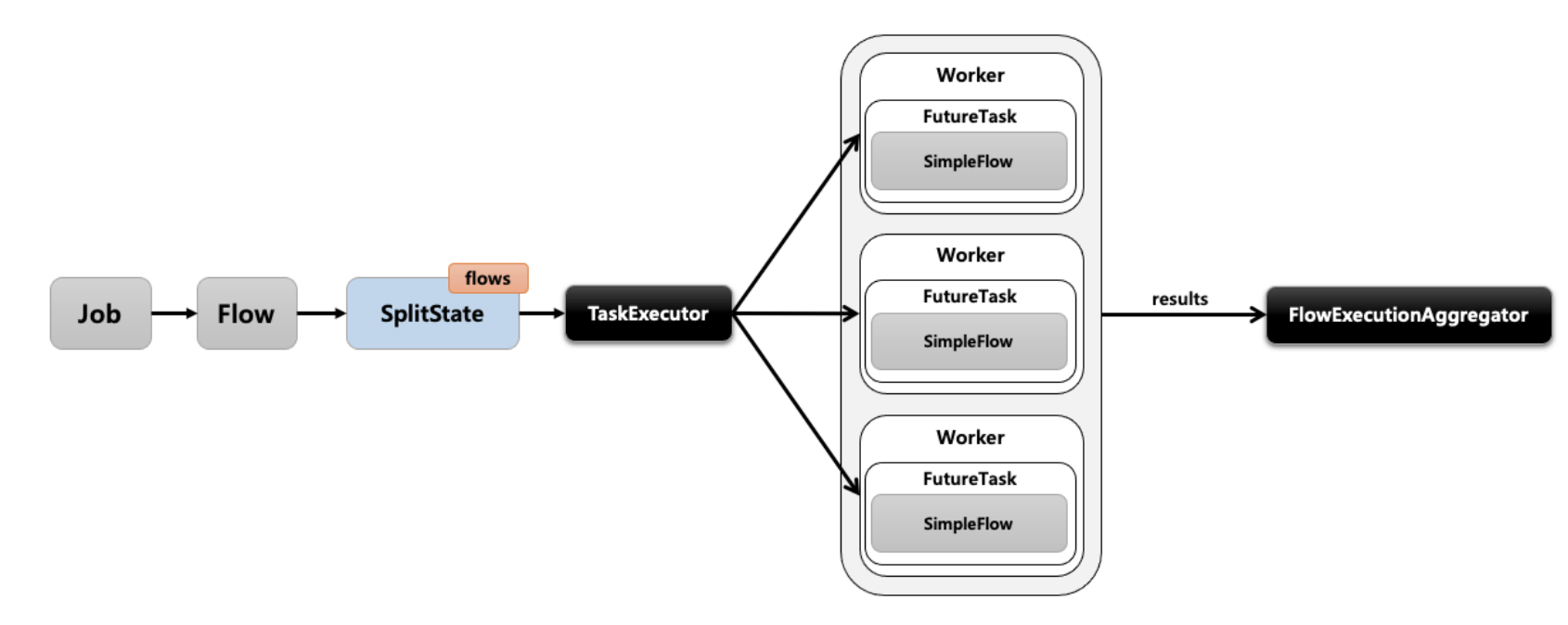
- Parallel Step
-
- 여러 Step을 SplitState를 통해 각 Flow(Step)에 스레드를 할당하여 병렬적으로 처리해주는 방식
-
- Partition
- Master/Slave방식으로 Master가 데이터를 파티셔닝하고 각 파티션에게 스레드를 할당하여 Slave가 독립적으로 작동하는 방식
- Remote Chunking
- 분산 환경처럼 Step처리가 여러 프로세스로 분할되어 다른 외부 서버로 전송되어 처리하는 방식
예비 답안 보기 (👈 Click)
- https://velog.io/@backtony/Spring-Batch-%EB%B0%98%EB%B3%B5-%EB%B0%8F-%EC%98%A4%EB%A5%98-%EC%A0%9C%EC%96%B4
- SpringBatch는 특정 조건이 만족할때까지 Job또는 Step을 반복하도록 애플리케이션을 구성할 수 있다.
- Step과 Chunk의 반복을 RepeatOperation을 통해 처리
- 기본 구현체는 RepeatTemplate
- 구조
-

- Step은 RepeatTemplate을 사용해서 Tasklet을 반복적으로 사용
- ChunkOritentedTasklet은 내부적으로 ChunkProvider를 통해 ItemReader를 읽어오는데 RepeatTemplate를 통해 Chunk size만큼의 데이터를 반복적으로 읽어오게 한다.
-
- 반복 결정 여부 항복
-

-
ExceptionHandler
- RepeatCallback내부에서 예외가 발생하면 RepeatTemplate는 ExceptionHandler를 참조하여 예외를 던질지, 말지 결정
- 예외를 받아 던지게 된다면 반복이 종료되고 비정상 종료가 된다.
- 구현체
- SimpleLimitException : (default) 예외타입이 발생할때마다 카운터가 증가하고 선언한 한계(limit)초과시 예외를 던진다.
- LogOrRethrowException : 예외를 로그에 기록할지 던질지 결정
-
CompletionPolicy
- RepeatTemplate의 iterate에서 반복을 중단할지 결정하는 정책
- CompletionPolicy로 반복이 중단된다면 정상적인 종료로 처리
- 여러 정책이 있는 경우 먼저 만족되는 것이 있다면 종료된다.
- 구현체
- SimpleCompletionPolicy : (default) 특정 반복 횟수가 넘어가게 되면 반복 종료
- TimeoutTerminationPolicy : 특정 시간이 소요되면 종료
- CountingCompletionPolicy : 일정 횟수 또는 계산 조건을 만족하면 종료
-
RepeatStatus
- 해당 작업 처리가 끝났는지 판별하기 위한 Enum
- CONTINUABLE : 작업이 남아있음
- FINISHED : 더이상의 반복 없음
-
- FaultTolerant (장애허용시스템)
- 작업 중 오류가 발생해도 Step이 즉시 종료되지 않고 Retry또는 Skip기능을 활성화 함으로서 내결함성 서비스가 가능하다.
-
내결함성 : 일부 구성요소가 동작하지 않아도 계속 작동할 수 있는것.
-
Skip
- ItemReader, ItemProcessor, ItemWriter
-
Retry
- ItemProcessor, ItemWriter
-
-

- Skip
-

-
데이터를 처리하는 동안 설정된 Exception이 발생했을 경우, 해당 데이터 처리를 건너뛰는 기능
-
ItemReader
- Item을 한건씩 읽어오다가 예외 발생시 해당 Item을 skip하고 다음 item을 읽는다.
-
ItemProcessor
- item을 처리하다가 예외가 발생하면 Chunk의 첫 단계로 돌아가 ItemReader에게 Items을 다시 요청한다.
- 이때 ItemReader는 다시 데이터를 읽어오는 것이 아니라 캐시에 저장되어있는 Items를 다시 보내준다.
- 다시 Items를 받아온 ItemProcessor는 처음부터 작업을 수행하고 이전에 실패했던 Item에 대해서는 처리하지 않고 넘어간다.
-
ItemWriter
- item을 처리하다가 예외가 발생하면 Chunk의 첫 단계로 돌아가 ItemReader에게 Items를 다시 요청한다.
- 캐싱된 Items를 ItemProcessor에게 넘긴다.
- 예외 발생 후에는 ItemProcessor에서 전부 처리하고 ItemWriter에게 넘겨주는 것이 아닌 개별로 한개씩 ItemWriter로 보낸다.
-
- Retry
-

- ItemProcessor, ItemWriter에서 설정된 Exception이 발생했을 때, 지정한 정책에 따라 데이터를 재시도하는 기능.
- 예외 발생시 Chunk의 처음부터 다시 시작
- Retry Count는 Item마다 각각 가지고 있다.
- RetryLimit횟수 이후에도 재시도가 실패한다면 recover에서 후속작업을 처리할 수 있다.
- ItemPrcessor
- ItemProcessor에서 예외 발생시 Chunk단계의 처음부터 다시 시작
- ItemReader는 캐시된 Items를 다시 ItemProcessor에게 전달
- ItemWriter
- ItemWriter에서 예외 발생시 skip과 다르게 List로 한번에 받아 처리한다.
-
- Rollback
- 특정 예외가 발생한다면, 해당 예외에서는 롤백을 수행하지 않도록 한다.
- 작업 중 오류가 발생해도 Step이 즉시 종료되지 않고 Retry또는 Skip기능을 활성화 함으로서 내결함성 서비스가 가능하다.
예비 답안 보기 (👈 Click)
-
Spring Batch에서 Multi Thread Step으로 병렬작업을 하는 경우 Step Builder에 TaskExecutor를 적용하여 수행하게된다.
- 설정하는 TaskExecutor는 execute()만 선언하고 있기 때문에 shutdown과 같은 메서드가 없어 작업을 강제 종료 시킬 수 없다.
System.exit(SpringApplication.exit(SpringApplication.run(SpringBatchRealApplication.class, args)))- 위와 같은 설정을 통해 step을 병렬적으로 처리하는 경우 main스레드가 종료시 jvm을 강제 종료시킬수 있도록 하여 자식 그세드들이 성공적으로 작업을 마치고 종료됨을 보장해준다.
-
@Async를 사용할때 ThreadPoolTaskExecutor를 사용하는 경우
- ThreadPoolTaskExecutor를 사용하는 경우 스레드를 강제로 종료해줄수 있는
keepAliveSecond,allowCoreThreadTimeout메서드를 활용하여 특정 시간동안 task를 받지 못한 스레드를 강제 종료시켜버리고, coresize의 스레드도 강제 종료시켜준다.
- ThreadPoolTaskExecutor를 사용하는 경우 스레드를 강제로 종료해줄수 있는
예비 답안 보기 (👈 Click)
- 많은 데이터를 처리하는데 사용 빈도가 적으며 정해진 시간에 특정 데이터를 처리하기를 원했고, 애플리케이션 서비스에 영향을 받지 않도록 하기 위해 spring batch를 사용했습니다.
예비 답안 보기 (👈 Click)
- jobparameter를 통해 제어되지 않는 코드를 사용하지 않고 파라미터에 따라 동일한 요청을 여러번 요청해도 동일한 결과를 반환하게 하여 멱등성을 유지합니다.
예비 답안 보기 (👈 Click)
- batch job을 수행하게 되면 메타 데이터라는 수행 정보가 생성되는데 이를 저장하고 모니터링 하기 위해서는 메타 데이터 테이블이 필요합니다
- Batch job instance : job의 생성 정보
- batch job execution : job의 실행 정보
- batch job execution param : job에 사용된 파라미터 정보
- batch job context : job의 전체 실행 정보
- batch step execution : step의 실행 정보
- batch step context : step의 전체 실행 정보
- 가 있습니다.
예비 답안 보기 (👈 Click)
- 배치가 실패하면 메타 데이터 테이블로 발생 원인을 파악하고 해당 예외에 대해서 skip을 통해 건너뛰거나 retry를 통해 예외를 건너뛰어 문제를 처리합니다.
예비 답안 보기 (👈 Click)
-

-
Multi-thread-step
- 단일 Step을 수행할 때, 해당 Step 내의 각 Chunk를 별도의 여러 쓰레드에서 실행 하는 방법
- spring batch는 단일 스레드로 작업이 순차적으로 이루어지지만 ThreadPoolTaskExecutor를 통해 multi thread를 사용하면 step의 chunk 별로 작업이 병렬적으로 처리되어 빠르게 처리할 수 있습니다. 하지만 병렬적으로 처리되기 때문에 하나의 chunk가 성공했다고 이전의 chunk가 성공적으로 완료되었다는 보장이 없습니다. 그리고 멀티스레드를 사용할때 ItemReader나 ItemWriter는 thread-safe를 보장하는 구현체를 사용해야합니다. (pagingItemReader은 모두 보장) 만약 thread-safe하지 않는 구현체를 사용할때는 SynchronizedItemStreamReade나 SynchronizedItemStreamWriterr로 감싸줘서 사용해주어야 합니다. (read와 write메소드가 synchronized로 선언되어있음)
-
파티셔닝
- ㅇㅅㅇ
예비 답안 보기 (👈 Click)
- spring batch에서는 대용량 데이터를 다루기 때문에 하나의 트랜잭션으로 대량의 데이터를 관리하기에는 어려움이 있기 때문입닌다.
예비 답안 보기 (👈 Click)
- tasklet과 reader,processor, writer는 둘 다 step에서 작업을 수행하는 역할을 합니다.
- Tasklet은 하나의 덩어리에서 작업을 처리하기 때문에 비교적 쉽고 가벼운 로직에서 사용할 수 있습니다. 하지만 대용량 데이터를 한번에 처리하거나 여러 덩어리로 나누어 처리하기 쉽지 않습니다.
- reader, processor, writer는 chunk 기반으로 대량의 데이터를 역할을 나누어 작업 수행하기 때문에 Tasklet보다 효율과 유지비용이 좋습니다. 하지만 reader, processor, writer의 이해관계를 정확히 파악해야합니다.
예비 답안 보기 (👈 Click)
- cursor와 paging기반은 데이터를 읽어올때 방식으로 나뉘어집니다 cursor 기반은 하나의 connection으로 연결하여 stream으로 하나씩 데이터를 읽어오는 방법이고 paging은 limit와 offset을 사용하여 한번에 가져올 데이터를 나누어 읽어오는 방법입니다. cursor는 데이터를 순차적으로 읽어오기 때문에 정렬없이 데이터를 읽어 올수 있지만 하나의 connection으로 데이터를 가져오기 때문에 batch작업이 크다면 timeout으로 connection이 종료될 수 있습니다. paging은 하나의 paging쿼리마다 connection으로 데이터를 가져오기 때문에 대량의 데이터를 관리하기 효율적입니다. 하지만 각 paging 쿼리는 개별적으로 발생하기 때문에 정렬을 해주지 않으면 독자적으로 정렬 기준을 잡아 중복 데이터를 읽어올 수 있습니다.
예비 답안 보기 (👈 Click)
- 젠킨슨으로 자동 배포하여 사용할 수 있고 jobparameter를 쉽게 적용하여 멱등성을 유지할 수 있습니다.
- 저는 특정 시간에 수행되는 배치 작업을 구현했기 때문에 cron으로 job을 스케줄링하고 배포하여 nohup으로 실행 시켰습니다.
예비 답안 보기 (👈 Click)
- 제니퍼..?