language-model.md - vscode-docs [GitHub] - Visual Studio Code - GitHub #676
Comments
Related issues#393: llm-vscode - Visual Studio Marketplace### DetailsSimilarity score: 0.88 - [ ] [llm-vscode - Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode)LLM-powered Development for VSCode
Note: When using the Inference API, you may encounter limitations. Consider subscribing to the PRO plan to avoid rate limiting on the free tier. Hugging Face Pricing 💻 Features
🚀 InstallationInstall By default, this extension uses 🔑 HF API TokenSupply your HF API token (
If you previously logged in with ⚙ ConfigurationCheck the full list of configuration settings by opening your settings page Suggested labels{ "key": "llm-vscode", "value": "VSCode extension for LLM powered development with Hugging Face Inference API" }#498: CodeGPTPlus/deepseek-coder-1.3b-typescript · Hugging Face### DetailsSimilarity score: 0.86 - [ ] [CodeGPTPlus/deepseek-coder-1.3b-typescript · Hugging Face](https://huggingface.co/CodeGPTPlus/deepseek-coder-1.3b-typescript)CodeGPTPlus/deepseek-coder-1.3b-typescriptThis is a fine-tuned model by the CodeGPT team, specifically crafted for generating expert code in TypeScript. It is fine-tuned from The model uses a 16K window size and an additional fill-in-the-middle task for project-level code completion. How to UseThis model is for completion purposes only. Here are some examples of how to use the model: Running the model on a GPUfrom transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("CodeGPTPlus/deepseek-coder-1.3b-typescript", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("CodeGPTPlus/deepseek-coder-1.3b-typescript", trust_remote_code=True).cuda()
input_text = """<|fim begin|>function quickSort(arr: number[]): number[] {
if (arr.length <= 1) {
return arr;
}
const pivot = arr[0];
const left = [];
const right = [];
<|fim hole|>
return [...quickSort(left), pivot, ...quickSort(right)];
}<|fim end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Running with Ollama
Running with Ollama and CodeGPT Autocomplete in VSCode
Fill In the Middle (FIM)<|fim begin|>function quickSort(arr: number[]): number[] {
if (arr.length <= 1) {
return arr;
}
const pivot = arr[0];
const left = [];
const right = [];
<|fim hole|>
return [...quickSort(left), pivot, ...quickSort(right)];
}<|fim end|>Training ProcedureThe model was trained using the following hyperparameters:
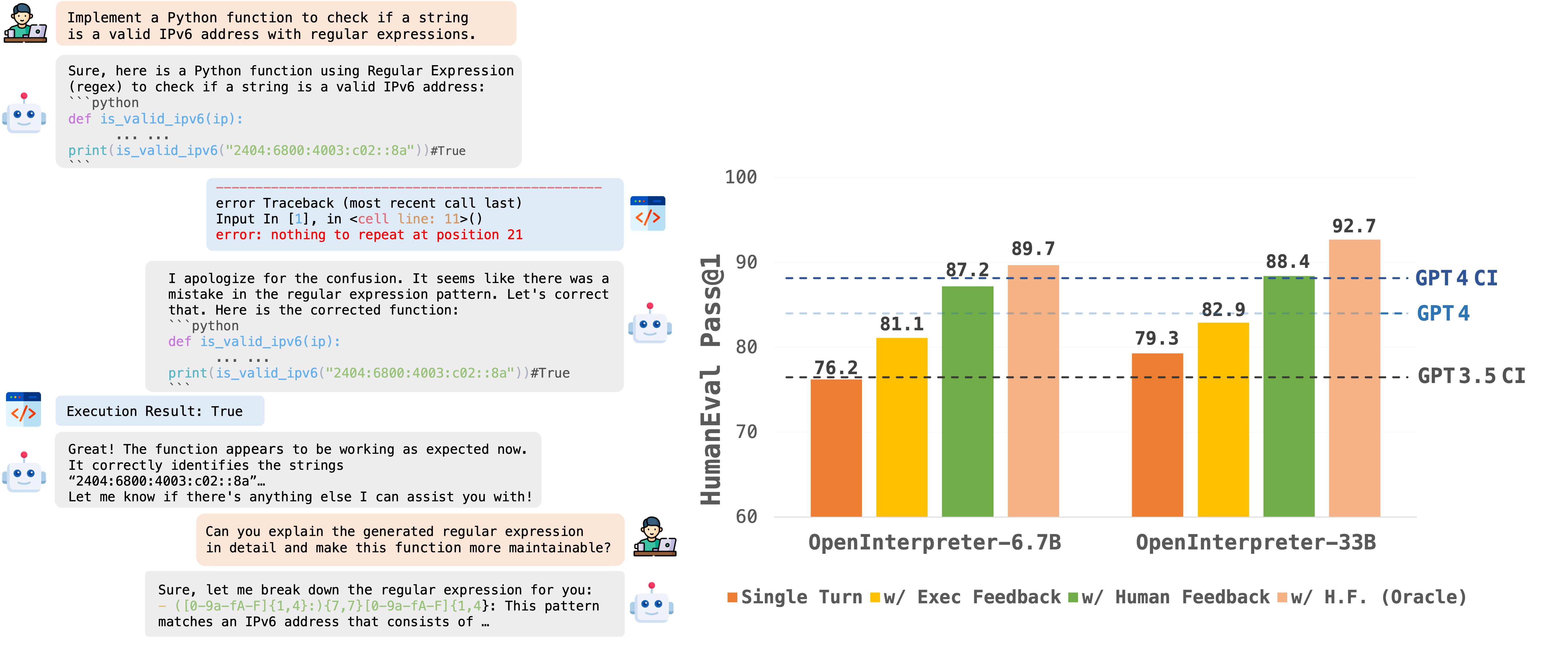
For more information, visit the model page. Suggested labels{ "label-name": "TypeScript-Code-Generation", "description": "Model for generating TypeScript code", "repo": "CodeGPTPlus/deepseek-coder-1.3b-typescript", "confidence": 70.59 }#658: OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter### DetailsSimilarity score: 0.86 - [ ] [OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/README.md?plain=1)OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreterDescriptionOpenCodeInterpreter: Integrating Code Generation with Execution and Refinement
🌟 Upcoming Features
🔔News🛠️[2024-02-28]: We have open-sourced the Demo Local Deployment Code with a Setup Guide. ✨[2024-02-26]: We have open-sourced the OpenCodeInterpreter-DS-1.3b Model. 📘[2024-02-26]: We have open-sourced the CodeFeedback-Filtered-Instruction Dataset. 🚀[2024-02-23]: We have open-sourced the datasets used in our project named Code-Feedback. 🔥[2024-02-19]: We have open-sourced all models in the OpenCodeInterpreter series! We welcome everyone to try out our models and look forward to your participation! 😆 IntroductionOpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities. ModelsAll models within the OpenCodeInterpreter series have been open-sourced on Hugging Face. You can access our models via the following link: OpenCodeInterpreter Models. Data CollectionSupported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter incorporates execution and human feedback for dynamic code refinement. EvaluationOur evaluation framework primarily utilizes HumanEval and MBP, alongside their extended versions, HumanEval+ and MBPP+, leveraging the EvalPlus framework for a more comprehensive assessment. ContactIf you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. Suggested labels{'label-name': 'frameworks', 'label-description': 'Frameworks and tools used for evaluation and assessment.', 'gh-repo': 'OpenCodeInterpreter/OpenCodeInterpreter', 'confidence': 58.17}#515: neulab/external-knowledge-codegen: Code and data for ACL20 paper "Incorporating External Knowledge through Pre-training for Natural Language to Code Generation"### DetailsSimilarity score: 0.86 - [ ] [neulab/external-knowledge-codegen: Code and data for ACL20 paper "Incorporating External Knowledge through Pre-training for Natural Language to Code Generation"](https://github.com/neulab/external-knowledge-codegen)TITLE: neulab/external-knowledge-codegen: Code and data for ACL20 paper "Incorporating External Knowledge through Pre-training for Natural Language to Code Generation"DESCRIPTION: Incorporating External Knowledge through Pre-training for Natural Language to Code GenerationThis repository contains code and resources for the ACL20 paper "Incorporating External Knowledge through Pre-training for Natural Language to Code Generation". Some of the code is borrowed from the awesome TranX semantic parsing software. If you are interested in the underlying neural code generation model used in this paper, please have a look! TL;DROpen-domain code generation aims to generate code in a general-purpose programming language (such as Python) from natural language (NL) intents. Motivated by the intuition that developers usually retrieve resources on the web when writing code, we explore the effectiveness of incorporating two varieties of external knowledge into NL-to-code generation: automatically mined NL-code pairs from the online programming QA forum StackOverflow and programming language API documentation. Our evaluations show that combining the two sources with data augmentation and retrieval-based data re-sampling improves the current state-of-the-art by up to 2.2% absolute BLEU score on the code generation testbed CoNaLa. If you want to try out our strong pre-trained English-to-Python generation models, check out this section. Our approach: incorporating external knowledge by data re-sampling, pre-training and fine-tuning. Examples from Python API documentation and pre-processed code snippets, including class constructors, methods, and top-level functions. We use red, blue, and green to denote required, optional positional, and optional keyword arguments respectively.Performance comparison of different strategies to incorporate external knowledge.Prepare EnvironmentWe recommend using conda to manage the environment: Some key dependencies and their versions are: Getting and Preprocessing External ResourcesOne of the most important steps presented in the paper is the external knowledge/resources used for pre-training the code generation model. We will show how we obtain the StackOverflow mined data as well as the Python API documentation and the preprocessing steps. Mined StackOverflow PairsDownload conala-corpus-v1.1.zip and unzip the content into data/conala/. Make sure you have conala-(mined|train|test).jsonl in that directory. Python Standard Library API DocumentationWe provide our processed API documents into our data format which is the same as the aforementioned Conala dataset. You can find the preprocessed NL-code pairs at apidocs/python-docs.jsonl. However, if you prefer to process the API documents from scratch, you need to first download the official Python source code from here, in this paper, we use the documentation from Python 3.7.5. extract everything into apidocs/Python-3.7.5. Then cd into that directory, and follow the instructions to build the HTML version of the Python documentation. Basically it's make venv followed by make html. After this, please check apidocs/Python-3.7.5/Doc/build/html/library directory to see if the generated HTML library documentations are there. Yay! To actually parse all the documentation and output the same NL-code pair format as the model supports, please run apidocs/doc_parser.py, which would generate apidocs/python-docs.jsonl. Resampling API KnowledgeAs we found in the paper, external knowledge from different sources has different characteristics. NL-code pairs automatically mined from StackOverflow are good representatives of the questions that developers may ask, but are inevitably noisy. NL-code pairs from API documentation are clean, but there may be a topical distribution shift from real questions asked by developers. We show that resampling the API documentation is crucial to minimize the distribution gap and improve pretraining performance. You can find resampled API corpus as used in the experiments in the paper in apidocs/processed. direct contains corpus resampled via "direct retrieval". distsmpl contains corpus resampled via "distribution estimation". Both are compared in the experiments, and distsmpl has better performance. The filenames of the resampled corpus represent different strategies. snippet or intent means retrieved by code snippet or NL intent. tempX means the temperature parameter is X. topK means top K retrieval results are used for resampling. If you are interested in performing the resampling step on your own, you will need to load python-docs.jsonl into an ElasticSearch instance that provides retrieval functionality. Check out apidocs/index_es.py for indexing the API documents, and apidocs/retrieve.py for actual retrieval and resampling. Pretraining and Finetuning Underlying Code Generation ModelFor this part, our underlying model is TranX for code generation, and the code is modified and integrated in this repo. Our paper's training strategy is basically 3-step: pretrain on mined + API data, finetune on CoNaLa dataset, and rerank. Preprocess all the data into binarized dataset and vocab. All related operations are in datasets/conala/dataset.py. For our best performing experiment, with is mined (top 100K) + API (dist. resampled w/ code, k = 1 and t = 2), run the following to create the dataset: By default things should be preprocessed and saved to data/conala. Check out those .bin files. PretrainingCheck out the script scripts/conala/train_retrieved_distsmpl.sh for our best performing strategy. Under the directory you could find scripts for other strategies compared in the experiments as well. Basically, you have to specify number of mined pairs (50k or 100k), retrieval method (snippet_count100k_topk1_temp2, etc.): If anything goes wrong, make sure you have already preprocessed the corresponding dataset/strategy in the previous step. The best model will be saved to saved_models/conala FinetuningCheck out the script scripts/conala/finetune_retrieved_distsmpl.sh for best performing finetuning on CoNaLa training dataset (clean). The parameters are similar as above, number of mined pairs (50k or 100k), retrieval method (snippet_count100k_topk1_temp2, etc.), and additionally, the previous pretrained model path: For other strategies, modify accordingly and refer to other finetune_xxx.sh scripts. The best model will also be saved to saved_models/conala. RerankingReranking is not the core part of this paper, please refer to this branch and the paper. This is an orthogonal post-processing step. In general, you will first need to obtain the decoded hypothesis list after beam-search of the train/dev/test set in CoNaLA, and train the reranking weight on it. To obtain decodes, run scripts/conala/decode.sh <train/dev/test_data_file> <model_file>. The outputs will be saved at decodes/conala Then, train the reranker by scripts/conala/rerank.sh <decode_file_prefix>.dev.bin.decode/.test.decode For easy use, Suggested labelsnull#189: deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2 · Hugging Face### DetailsSimilarity score: 0.85 - [ ] I cannot get this to output anything but gibberish. - [x] [LoneStriker/deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2 · Hugging Face](https://huggingface.co/LoneStriker/deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2)
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks. |
language-model.md - vscode-docs [GitHub] - Visual Studio Code - GitHub
DESCRIPTION:
DO NOT TOUCH — Managed by doc writer
ContentId: 9bdc3d4e-e6ba-43d3-bd09-2e127cb63ce7
DateApproved: 02/28/2024
Summarize the whole topic in less than 300 characters for SEO purpose
MetaDescription: A guide to adding AI-powered features to a VS Code extension by using language models and natural language understanding.
Language Model API
package.jsonto make it easy for users to find your extension. Add "AI" to thecategoriesfield in yourpackage.json. If your extension contributes a Chat Participant, add "Chat" as well.Related content
URL: language-model.md
Suggested labels
{'label-name': 'VSCode-Extension-Guide', 'label-description': 'Content related to creating VS Code extensions with language models.', 'gh-repo': 'microsoft/vscode-docs', 'confidence': 62.54}
The text was updated successfully, but these errors were encountered: