An MVP Chef cookbook for configuring a PostgreSQL cluster (9.4 WAL streaming with repmgr and pgpool), using Chef Provisioning
- ChefDK 0.9.0 or greater
- Follow the instructions to set ChefDK as your system Ruby and Gemset
- AWS configuration ( default: see [https://github.com/irvingpop/chef-provisioning-aws-helper])
- Vagrant and Virtualbox (optional)
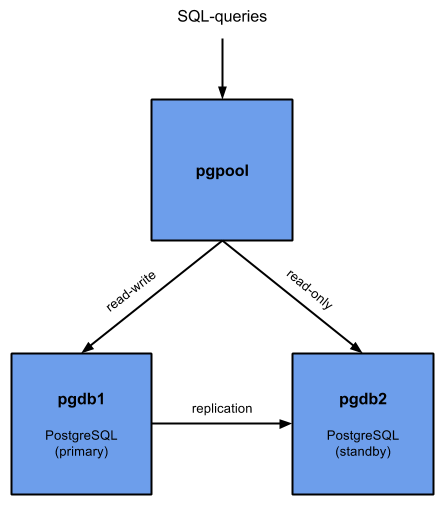
This cookbook will create an example cluster with two PostgreSQL servers (primary/standby) and configure streaming replication using repmgr. For platform compatibility with the latest versions of postgres, this cookbook uses the PostgreSQL Development Group (PGDG) packages.
Once Postgres clustering has been configured, this cookbook will also create an additional server running pgpool-II. Pgpool is configured to act as both a proxy (it accepts postgres connections and routes them to the correct backend host) as well as a failover controller. Failover scripts have been implemented which allow pgpool to trigger a failover and recover a former primary as a standby node.
It was tested on RHEL 7.1 and Ubuntu 14.04 using the Postgres PGDG 9.4 packages.
Credit to this article by Jens Depuydt for the detailed setup description, which I turned into cookbook form.
Starting up a cluster:
rake upConnecting to your cluster nodes (on AWS):
ssh -i .chef/keys/$USER@postgresql-cluster -l ubuntu <ip of instance>Connecting to your cluster nodes (on Vagrant):
cd vagrants ; vagrant ssh postgresql-bdr1.example.comDestroying the cluster
rake destroyFrom pgpool's point of view, use the show commands from psql
ubuntu@pgpool-1:~$ psql -U replication -h 127.0.0.1 template1
Password for user replication:
psql (9.4.5)
Type "help" for help.
template1=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
---------+--------------------------+------+--------+-----------+---------
0 | postgresql-1.example.com | 5432 | 2 | 0.500000 | primary
1 | postgresql-2.example.com | 5432 | 2 | 0.500000 | standby
(2 rows)If you're on one of the database nodes, you could also use repmgr's built-in status:
root@postgresql-1:~# repmgr -f /etc/repmgr/9.4/repmgr.conf cluster show
Role | Connection String
* master | host=postgresql-1.example.com dbname=repmgr_db user=replication password=replication
standby | host=postgresql-2.example.com dbname=repmgr_db user=replication password=replicationrepmgr also has a built-in database where it stores interesting cluster status information:
ubuntu@pgpool-1:~$ psql -U replication -h 127.0.0.1 repmgr_db -c 'select * from repmgr_example.repl_nodes'
Password for user replication:
id | type | upstream_node_id | cluster | name | conninfo | slot_name | priority | active
----+---------+------------------+---------+--------------------------+--------------------------------------------------------------------------------------+---------------+----------+--------
1 | master | | example | postgresql-1.example.com | host=postgresql-1.example.com dbname=repmgr_db user=replication password=replication | repmgr_slot_1 | 100 | t
2 | standby | 1 | example | postgresql-2.example.com | host=postgresql-2.example.com dbname=repmgr_db user=replication password=replication | repmgr_slot_2 | 100 | t
(2 rows)
ubuntu@pgpool-1:~$ psql -U replication -h 127.0.0.1 repmgr_db -c 'select * from repmgr_example.repl_events'
Password for user replication:
node_id | event | successful | event_timestamp | details
---------+------------------+------------+-------------------------------+--------------------------------------------------------------------------------------------------
1 | master_register | t | 2015-11-23 22:45:21.005466+00 |
2 | standby_clone | t | 2015-11-23 22:46:44.076196+00 | Cloned from host 'postgresql-1.example.com', port 5432; backup method: pg_basebackup; --force: N
2 | standby_register | t | 2015-11-23 22:46:46.480539+00 |
2 | standby_promote | t | 2015-11-23 23:11:53.618222+00 | Node 2 was successfully promoted to master
1 | standby_clone | t | 2015-11-23 23:42:59.512662+00 | Cloned from host 'postgresql-2.example.com', port 5432; backup method: pg_basebackup; --force: N
1 | standby_clone | t | 2015-11-24 00:07:51.285216+00 | Cloned from host 'postgresql-2.example.com', port 5432; backup method: pg_basebackup; --force: N
1 | standby_clone | t | 2015-11-24 00:16:36.125158+00 | Cloned from host 'postgresql-2.example.com', port 5432; backup method: pg_basebackup; --force: N
1 | standby_clone | t | 2015-11-24 00:18:34.342322+00 | Cloned from host 'postgresql-2.example.com', port 5432; backup method: pg_basebackup; --force: N
1 | standby_clone | t | 2015-11-24 00:20:05.341037+00 | Cloned from host 'postgresql-2.example.com', port 5432; backup method: pg_basebackup; --force: N
1 | standby_register | t | 2015-11-24 00:20:06.973346+00 |
1 | standby_promote | t | 2015-11-24 17:55:06.736698+00 | Node 1 was successfully promoted to master
2 | standby_clone | t | 2015-11-24 17:55:10.9034+00 | Cloned from host 'postgresql-1.example.com', port 5432; backup method: pg_basebackup; --force: N
2 | standby_register | t | 2015-11-24 17:55:12.527884+00 |
(13 rows)
As a simple example, let's stop Postgres on the primary node:
root@postgresql-1:~# /etc/init.d/postgresql stop
* Stopping PostgreSQL 9.4 database server 2015-11-24 23:05:57 UTC LOG: received fast shutdown request
2015-11-24 23:05:57 UTC LOG: aborting any active transactions
2015-11-24 23:05:57 UTC FATAL: terminating connection due to administrator command
2015-11-24 23:05:57 UTC FATAL: terminating connection due to administrator command
2015-11-24 23:05:57 UTC FATAL: terminating connection due to administrator command
2015-11-24 23:05:57 UTC FATAL: terminating connection due to administrator command
2015-11-24 23:05:57 UTC FATAL: terminating connection due to administrator command
2015-11-24 23:05:57 UTC FATAL: terminating connection due to administrator command
2015-11-24 23:05:57 UTC FATAL: terminating connection due to administrator command
2015-11-24 23:05:57 UTC LOG: autovacuum launcher shutting down
2015-11-24 23:05:57 UTC LOG: shutting down
2015-11-24 23:05:57 UTC LOG: database system is shut down
2015-11-24 23:05:57 UTC FATAL: the database system is shutting down
2015-11-24 23:05:57 UTC FATAL: the database system is shutting down
pgpool will immediately react and do several things:
- Use the
failover.shscript to promote the standby (postgresql-2) to a primary - Attempt to perform an online recovery of the newly demoted node (postgresql-1)
what this looks like from a pgpool log perspective
Nov 24 23:05:56 ip-33-33-33-181 pgpool[14920]: s_do_auth: expecting R got E
Nov 24 23:05:56 ip-33-33-33-181 pgpool[14920]: make_persistent_db_connection: s_do_auth failed
Nov 24 23:05:56 ip-33-33-33-181 pgpool[14920]: s_do_auth: expecting R got E
Nov 24 23:05:56 ip-33-33-33-181 pgpool[14920]: make_persistent_db_connection: s_do_auth failed
Nov 24 23:05:56 ip-33-33-33-181 pgpool[14920]: health check failed. 0 th host postgresql-1.example.com at port 5432 is down
Nov 24 23:05:56 ip-33-33-33-181 pgpool[14920]: health check retry sleep time: 1 second(s)
Nov 24 23:05:57 ip-33-33-33-181 pgpool[14920]: connect_inet_domain_socket: getsockopt() detected error: Connection refused
Nov 24 23:05:57 ip-33-33-33-181 pgpool[14920]: make_persistent_db_connection: connection to postgresql-1.example.com(5432) failed
Nov 24 23:05:57 ip-33-33-33-181 pgpool[14920]: health check failed. 0 th host postgresql-1.example.com at port 5432 is down
Nov 24 23:05:57 ip-33-33-33-181 pgpool[14920]: health check retry sleep time: 1 second(s)
Nov 24 23:05:58 ip-33-33-33-181 pgpool[14920]: connect_inet_domain_socket: getsockopt() detected error: Connection refused
Nov 24 23:05:58 ip-33-33-33-181 pgpool[14920]: make_persistent_db_connection: connection to postgresql-1.example.com(5432) failed
Nov 24 23:05:58 ip-33-33-33-181 pgpool[14920]: health check failed. 0 th host postgresql-1.example.com at port 5432 is down
Nov 24 23:05:58 ip-33-33-33-181 pgpool[14920]: health check retry sleep time: 1 second(s)
Nov 24 23:05:59 ip-33-33-33-181 pgpool[14920]: connect_inet_domain_socket: getsockopt() detected error: Connection refused
Nov 24 23:05:59 ip-33-33-33-181 pgpool[14920]: make_persistent_db_connection: connection to postgresql-1.example.com(5432) failed
Nov 24 23:05:59 ip-33-33-33-181 pgpool[14920]: health check failed. 0 th host postgresql-1.example.com at port 5432 is down
Nov 24 23:05:59 ip-33-33-33-181 pgpool[14920]: set 0 th backend down status
Nov 24 23:05:59 ip-33-33-33-181 pgpool[14920]: starting degeneration. shutdown host postgresql-1.example.com(5432)
Nov 24 23:05:59 ip-33-33-33-181 pgpool[14920]: Restart all children
Nov 24 23:05:59 ip-33-33-33-181 pgpool[14920]: execute command: /etc/pgpool2/failover.sh postgresql-1.example.com postgresql-2.example.com
Nov 24 23:05:59 ip-33-33-33-181 pgpool: Tue Nov 24 23:05:59 UTC 2015
Nov 24 23:05:59 ip-33-33-33-181 pgpool: Failed node: postgresql-1.example.com
Nov 24 23:05:59 ip-33-33-33-181 pgpool: + /usr/bin/ssh -T -o StrictHostKeyChecking=no -i /var/lib/postgresql/.ssh/id_rsa -l postgres postgresql-2.example.com /usr/lib/postgresql/9.4/bin/repmgr -f /etc/repmgr/9.4/repmgr.conf standby promote 2>/dev/null 1>/dev/null <&-
Nov 24 23:06:01 ip-33-33-33-181 pgpool[15274]: connect_inet_domain_socket: getsockopt() detected error: Connection refused
Nov 24 23:06:01 ip-33-33-33-181 pgpool[15274]: make_persistent_db_connection: connection to postgresql-1.example.com(5432) failed
Nov 24 23:06:01 ip-33-33-33-181 pgpool[15274]: check_replication_time_lag: could not connect to DB node 0, check sr_check_user and sr_check_password
Nov 24 23:06:04 ip-33-33-33-181 pgpool[14920]: find_primary_node_repeatedly: waiting for finding a primary node
Nov 24 23:06:04 ip-33-33-33-181 pgpool[14920]: find_primary_node: primary node id is 1
Nov 24 23:06:04 ip-33-33-33-181 pgpool[14920]: starting follow degeneration. shutdown host postgresql-1.example.com(5432)
Nov 24 23:06:04 ip-33-33-33-181 pgpool[14920]: failover: 1 follow backends have been degenerated
Nov 24 23:06:04 ip-33-33-33-181 pgpool[14920]: failover: set new primary node: 1
Nov 24 23:06:04 ip-33-33-33-181 pgpool[14920]: failover: set new master node: 1
Nov 24 23:06:04 ip-33-33-33-181 pgpool[15398]: start triggering follow command.
Nov 24 23:06:04 ip-33-33-33-181 pgpool[15398]: execute command: /etc/pgpool2/follow_master.sh /var/lib/postgresql/9.4/main postgresql-1.example.com postgresql-2.example.com
Nov 24 23:06:04 ip-33-33-33-181 pgpool[15274]: worker process received restart request
Nov 24 23:06:04 ip-33-33-33-181 pgpool[14920]: failover done. shutdown host postgresql-1.example.com(5432)
Nov 24 23:06:04 ip-33-33-33-181 pgpool: Performing online recovery of postgresql-1.example.com at Tue Nov 24 23:06:04 UTC 2015
Nov 24 23:06:04 ip-33-33-33-181 pgpool: + /usr/bin/ssh -T -o StrictHostKeyChecking=no -i /var/lib/postgresql/.ssh/id_rsa -l postgres postgresql-1.example.com test -f /var/lib/postgresql/9.4/main/postmaster.pid && /usr/lib/postgresql/9.4/bin/pg_ctl stop -D /var/lib/postgresql/9.4/main --mode=immediate || echo 'postgres not running, no pid file'
Nov 24 23:06:04 ip-33-33-33-181 pgpool: postgres not running, no pid file
Nov 24 23:06:04 ip-33-33-33-181 pgpool: + /usr/bin/ssh -T -o StrictHostKeyChecking=no -i /var/lib/postgresql/.ssh/id_rsa -l postgres postgresql-1.example.com rm -rf /var/lib/postgresql/9.4/main
Nov 24 23:06:04 ip-33-33-33-181 pgpool: + /usr/bin/ssh -T -o StrictHostKeyChecking=no -i /var/lib/postgresql/.ssh/id_rsa -l postgres postgresql-1.example.com PGPASSWORD=replication /usr/lib/postgresql/9.4/bin/repmgr -f /etc/repmgr/9.4/repmgr.conf -d repmgr_db -U replication --verbose standby clone postgresql-2.example.com
Nov 24 23:06:05 ip-33-33-33-181 pgpool: [2015-11-24 23:06:06] [NOTICE] opening configuration file: /etc/repmgr/9.4/repmgr.conf
Nov 24 23:06:05 ip-33-33-33-181 pgpool: [2015-11-24 23:06:06] [INFO] connecting to upstream node
Nov 24 23:06:05 ip-33-33-33-181 pgpool: [2015-11-24 23:06:06] [INFO] connected to upstream node, checking its state
Nov 24 23:06:05 ip-33-33-33-181 pgpool: [2015-11-24 23:06:06] [INFO] Successfully connected to upstream node. Current installation size is 51 MB
Nov 24 23:06:05 ip-33-33-33-181 pgpool: [2015-11-24 23:06:06] [NOTICE] starting backup...
Nov 24 23:06:05 ip-33-33-33-181 pgpool: [2015-11-24 23:06:06] [INFO] creating directory "/var/lib/postgresql/9.4/main"...
Nov 24 23:06:05 ip-33-33-33-181 pgpool: [2015-11-24 23:06:06] [INFO] executing: '/usr/lib/postgresql/9.4/bin/pg_basebackup -l "repmgr base backup" -D /var/lib/postgresql/9.4/main -h postgresql-2.example.com -p 5432 -U replication '
Nov 24 23:06:05 ip-33-33-33-181 pgpool[15273]: pcp child process received restart request
Nov 24 23:06:05 ip-33-33-33-181 pgpool[14920]: PCP child 15273 exits with status 256 in failover()
Nov 24 23:06:05 ip-33-33-33-181 pgpool[14920]: fork a new PCP child pid 15439 in failover()
Nov 24 23:06:05 ip-33-33-33-181 pgpool[14920]: worker child 15274 exits with status 256
Nov 24 23:06:05 ip-33-33-33-181 pgpool[14920]: fork a new worker child pid 15440
Nov 24 23:06:06 ip-33-33-33-181 pgpool: NOTICE: pg_stop_backup complete, all required WAL segments have been archived
Nov 24 23:06:06 ip-33-33-33-181 pgpool: [2015-11-24 23:06:07] [NOTICE] copying configuration files from master
Nov 24 23:06:06 ip-33-33-33-181 pgpool: [2015-11-24 23:06:08] [INFO] standby clone: master ident file '/etc/postgresql/9.4/main/pg_ident.conf'
Nov 24 23:06:06 ip-33-33-33-181 pgpool: [2015-11-24 23:06:08] [INFO] rsync command line: 'rsync --archive --checksum --compress --progress --omit-link-times --rsh="ssh -o \"StrictHostKeyChecking no\"" postgresql-2.example.com:/etc/postgresql/9.4/main/pg_ident.conf /etc/postgresql/9.4/main/pg_ident.conf'
Nov 24 23:06:07 ip-33-33-33-181 pgpool: receiving incremental file list
Nov 24 23:06:07 ip-33-33-33-181 pgpool: [2015-11-24 23:06:08] [NOTICE] standby clone (using pg_basebackup) complete
Nov 24 23:06:07 ip-33-33-33-181 pgpool: [2015-11-24 23:06:08] [NOTICE] HINT: you can now start your PostgreSQL server
Nov 24 23:06:07 ip-33-33-33-181 pgpool: [2015-11-24 23:06:08] [NOTICE] for example : /etc/init.d/postgresql start
Nov 24 23:06:07 ip-33-33-33-181 pgpool: + /usr/bin/ssh -T -o StrictHostKeyChecking=no -i /var/lib/postgresql/.ssh/id_rsa -l postgres postgresql-1.example.com /usr/lib/postgresql/9.4/bin/pg_ctl start -D /var/lib/postgresql/9.4/main -w < /dev/null >& /dev/null
Nov 24 23:06:08 ip-33-33-33-181 pgpool: + /usr/bin/ssh -T -o StrictHostKeyChecking=no -i /var/lib/postgresql/.ssh/id_rsa -l postgres postgresql-1.example.com /usr/lib/postgresql/9.4/bin/repmgr -f /etc/repmgr/9.4/repmgr.conf --verbose --force standby register
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:09] [NOTICE] opening configuration file: /etc/repmgr/9.4/repmgr.conf
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:09] [INFO] connecting to standby database
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:10] [INFO] connecting to master database
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:10] [INFO] finding node list for cluster 'example'
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:10] [INFO] checking role of cluster node '1'
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:10] [INFO] checking role of cluster node '2'
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:10] [INFO] registering the standby
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:10] [INFO] standby registration complete
Nov 24 23:06:08 ip-33-33-33-181 pgpool: [2015-11-24 23:06:10] [NOTICE] standby node correctly registered for cluster example with id 1 (conninfo: host=postgresql-1.example.com dbname=repmgr_db user=replication password=replication)
Nov 24 23:06:08 ip-33-33-33-181 pgpool: + date
Nov 24 23:06:08 ip-33-33-33-181 pgpool: + echo Online recovery of postgresql-1.example.com completed successfully at Tue Nov 24 23:06:08 UTC 2015
Nov 24 23:06:08 ip-33-33-33-181 pgpool: Online recovery of postgresql-1.example.com completed successfully at Tue Nov 24 23:06:08 UTC 2015
pgpool now shows node_id 1 (postgresql-2) as the new primary, in status 2 (healthy and connected). The old primary (postgresql-1) is shown in status 3, which means disconnected:
ubuntu@pgpool-1:~$ psql -U replication -h 127.0.0.1 repmgr_db -c 'show pool_nodes'
Password for user replication:
node_id | hostname | port | status | lb_weight | role
---------+--------------------------+------+--------+-----------+---------
0 | postgresql-1.example.com | 5432 | 3 | 0.500000 | standby
1 | postgresql-2.example.com | 5432 | 2 | 0.500000 | primary
(2 rows)Let's reattach that node to get our cluster back into a non-degraded state:
root@pgpool-1:~# pcp_attach_node 10 localhost 9898 replication replication 0
Nov 24 23:16:12 ip-33-33-33-181 pgpool[15439]: send_failback_request: fail back 0 th node request from pid 15439
Nov 24 23:16:12 ip-33-33-33-181 pgpool[14920]: starting fail back. reconnect host postgresql-1.example.com(5432)
Nov 24 23:16:12 ip-33-33-33-181 pgpool[14920]: execute command: /etc/pgpool2/failover.sh postgresql-1.example.com postgresql-1.example.com
root@pgpool-1:~# Nov 24 23:16:12 ip-33-33-33-181 pgpool: Tue Nov 24 23:16:12 UTC 2015
Nov 24 23:16:12 ip-33-33-33-181 pgpool: Failed node: postgresql-1.example.com
Nov 24 23:16:12 ip-33-33-33-181 pgpool: + /usr/bin/ssh -T -o StrictHostKeyChecking=no -i /var/lib/postgresql/.ssh/id_rsa -l postgres postgresql-1.example.com /usr/lib/postgresql/9.4/bin/repmgr -f /etc/repmgr/9.4/repmgr.conf standby promote 2>/dev/null 1>/dev/null <&-
Nov 24 23:16:13 ip-33-33-33-181 pgpool[14920]: Do not restart children because we are failbacking node id 0 hostpostgresql-1.example.com port:5432 and we are in streaming replication mode
Nov 24 23:16:13 ip-33-33-33-181 pgpool[14920]: find_primary_node_repeatedly: waiting for finding a primary node
Nov 24 23:16:13 ip-33-33-33-181 pgpool[14920]: find_primary_node: primary node id is 1
Nov 24 23:16:13 ip-33-33-33-181 pgpool[14920]: failover: set new primary node: 1
Nov 24 23:16:13 ip-33-33-33-181 pgpool[14920]: failover: set new master node: 0
Nov 24 23:16:13 ip-33-33-33-181 pgpool[14920]: failback done. reconnect host postgresql-1.example.com(5432)
Nov 24 23:16:13 ip-33-33-33-181 pgpool[15440]: worker process received restart request
Nov 24 23:16:14 ip-33-33-33-181 pgpool[15439]: pcp child process received restart request
Nov 24 23:16:14 ip-33-33-33-181 pgpool[14920]: PCP child 15439 exits with status 256 in failover()
Nov 24 23:16:14 ip-33-33-33-181 pgpool[14920]: fork a new PCP child pid 15458 in failover()
Nov 24 23:16:14 ip-33-33-33-181 pgpool[14920]: worker child 15440 exits with status 256
Nov 24 23:16:14 ip-33-33-33-181 pgpool[14920]: fork a new worker child pid 15459
and now node_id 0 returns back to status 2:
ubuntu@pgpool-1:~$ psql -U replication -h 127.0.0.1 repmgr_db -c 'show pool_nodes'
Password for user replication:
node_id | hostname | port | status | lb_weight | role
---------+--------------------------+------+--------+-----------+---------
0 | postgresql-1.example.com | 5432 | 2 | 0.500000 | standby
1 | postgresql-2.example.com | 5432 | 2 | 0.500000 | primary
(2 rows)
- pgpool clustering and watchdog
- better handling of pre-setup master/slave election and then respecting the cluster state post installation
- better handling of users, passwords and databases
- randomly generating passwords and/or using databags
- providing primitives for user and database creation, allowing them to be wrapped
- factoring:
- master/slave node setup into separate recipes
- various TODO comments sprinkled in the code :)