本文介绍如何在新一代
Kaldi训练框架icefall中训练一个 识别中文的流式模型。同时也描述如何在服务端框架sherpa中 部署训练好的模型。本文也提供预训练模型的链接,供大家下载, 方便大家在
sherpa中进行尝试。
新一代 Kaldi 训练框架 icefall 中,目前支持
以下 3 种基于 RNN-T 的流式识别模型:
本文介绍如何基于第 3 种 Conformer-based
模型,利用 WenetSpeech 中文数据集,
训练一个识别中文的流式模型。
同时,我们也会介绍如何利用新一代 Kaldi 的服务端框架 sherpa 部署训练好的流式识别模型。
本文不涉及流式识别模型的内部工作原理。感兴趣的读者
可以自行阅读 icefall 中相关的源代码。
开始训练之前,我们先要配置训练所需的环境,安装所需的软件。
下述链接:
https://icefall.readthedocs.io/en/latest/
提供了详细的安装步骤,此处不再赘述。
如果大家在配置环境的时候,碰到了自己无法解决的问题,可以通过以下两种方式 获得帮助:
- 在 https://github.com/k2-fsa/icefall/issues 提一个 issue,详细描述所碰到的问题。
- 关注
新一代 Kaldi 公众号,从中找到工作人员的微信号,添加好友,然后加入Next-gen Kaldi 交流群,进而寻求帮助。
配置好 icefall 所需环境后,紧接着的一步就是准备数据,提取特征了。
我们假设读者已经下载好了 WenetSpeech 数据集。生成训练所需的数据命令如下:
cd egs/wenetspeech/ASR
./prepare.sh对的,就是这么简单!
我们强烈建议读者阅读 prepare.sh,并修改其中指向 WenetSpeech 数据集所在的路径。
准备好训练所需的数据之后,我们就可以开始训练了。训练所需命令如下:
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
python3 ./pruned_transducer_stateless5/train.py \
--lang-dir data/lang_char \
--exp-dir pruned_transducer_stateless5/exp_L_streaming \
--world-size 8 \
--num-epochs 15 \
--start-epoch 1 \
--max-duration 140 \
--valid-interval 3000 \
--model-warm-step 3000 \
--save-every-n 8000 \
--average-period 1000 \
--training-subset L \
--dynamic-chunk-training True \
--causal-convolution True \
--short-chunk-size 25 \
--num-left-chunks 4训练中的 checkpoints epoch-1.pt、epoch-2.pt 等保存在上述指定的目录 --exp-dir 中,
即 pruned_transducer_stateless5/exp_L_streaming.
当我们有上一步的 checkpoints 时,就可以开始解码了。解码命令如下:
python3 pruned_transducer_stateless5/streaming_decode.py \
--epoch 6 \
--avg 1 \
--decode-chunk-size 16 \
--left-context 64 \
--right-context 0 \
--exp-dir ./pruned_transducer_stateless5/exp_L_streaming \
--use-averaged-model True \
--decoding-method greedy_search \
--num-decode-streams 200在 WenetSpeech 的 3 个测试集 Dev、Test_Net 和
Test_Meeting 上的 CER 如下表所示。
| Checkpoint | Decoding method | Dev | Test_Net | Test_Meeting |
|---|---|---|---|---|
| epoch-5 | greedy search | 8.79 | 10.80 | 16.82 |
| epoch-6 | greedy search | 8.79 | 10.47 | 16.34 |
如果想看更详细的结果,请各位读者访问如下链接:
下面的截图,是来自 wenet 中的结果:
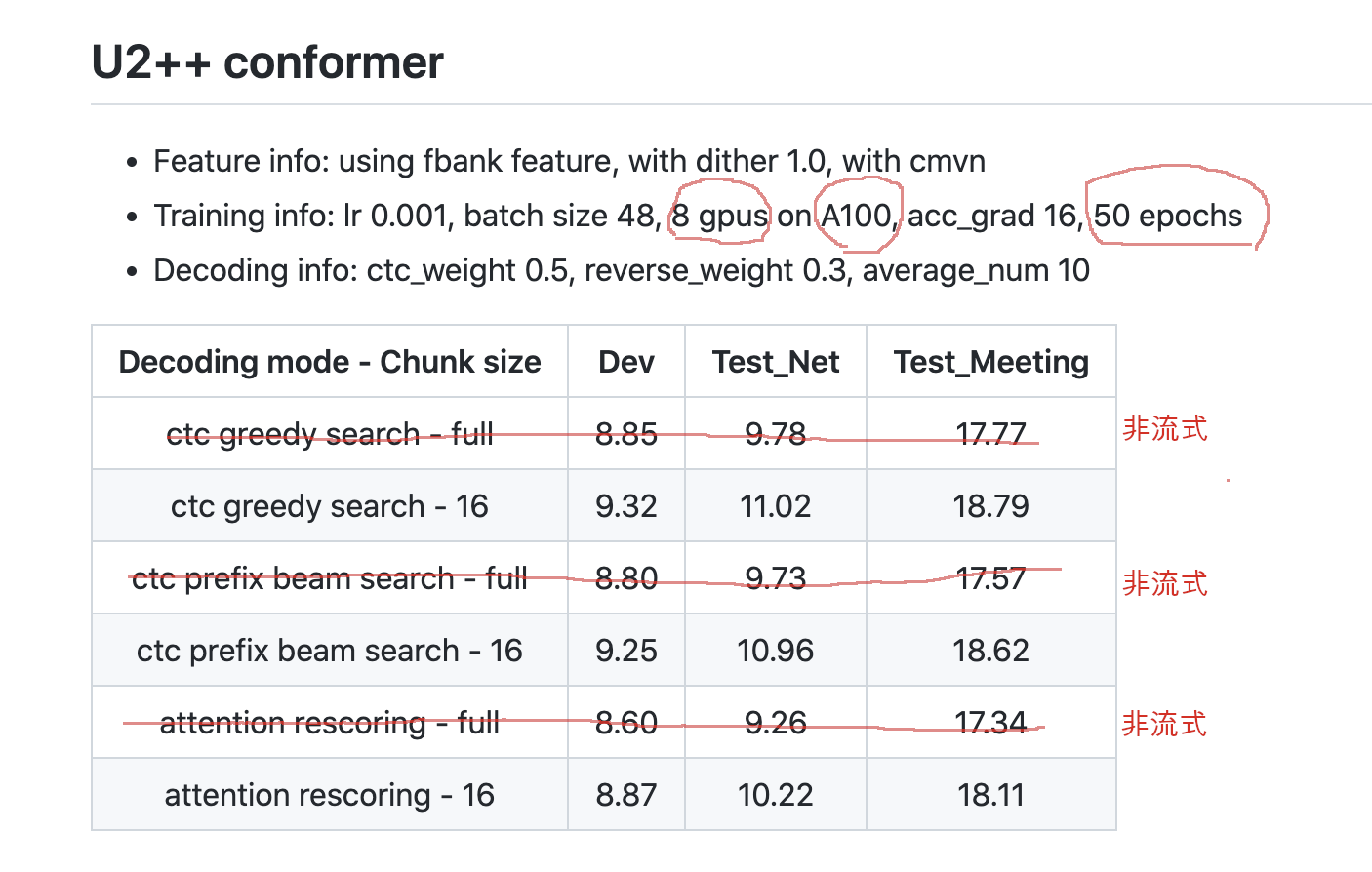
值得注意的是,wenet 中,使用 8 个 A100 GPU (文档中未注明 GPU RAM 是 40 GB 还是 80 GB)训
练了 50 个 epoch。而 icefall 使用 8 个 V100 GPU (32 GB RAM)训练 5 个 epoch 就可以达到
wenet 中同样的效果,甚至更好。
我们提供的预训练模型下载链接如下:
欢迎各位读者尝试,并比较解码速度。
有了上面训练好的模型之后,接下来的工作,就是怎么把它用起来。这就是服务端框架
sherpa 所要做的事情。
sherpa 的安装方法可以参考如下链接:
https://k2-fsa.github.io/sherpa/installation/index.html
接下来我们介绍,如何部署上面的预训练模型。
我们提供的模型存储在 Hugging face 上,通过 git lfs
管理。模型下载命令为:
sudo apt-get install git-lfs
git lfs install
cd /path/to/sherpa
git clone https://huggingface.co/luomingshuang/icefall_asr_wenetspeech_pruned_transducer_stateless5_streaming下载好模型之后,我们就可以启动服务器了。命令如下:
./sherpa/bin/streaming_conformer_rnnt/streaming_server.py \
--port 6006 \
--max-batch-size 50 \
--max-wait-ms 5 \
--nn-pool-size 1 \
--nn-model-filename ./icefall_asr_wenetspeech_pruned_transducer_stateless5_streaming/exp/cpu_jit_epoch_5_avg_1_torch.1.7.1.pt \
--token-filename ./icefall_asr_wenetspeech_pruned_transducer_stateless5_streaming/data/lang_char/tokens.txt启动好服务器后,我们就可以运行客户端了。新开一个命令行窗口,输入如下命令:
cd /path/to/sherpa
cd ./sherpa/bin/web
python3 -m http.server 6008然后打开浏览器,访问如下链接:
http://localhost:6008/streaming_record.html
出现如下界面:
点击 Streaming-Record 按钮,然后说话,就可以实时的看见识别的结果了。
具体的识别效果,可以访问如下视频:
2022-07-22-zengwei-chinese-streaming-asr.mp4
我们介绍了如何在新一代 Kaldi 中训练和部署一个中文流式识别模型。并在
WenetSpeech 三个测试集上与 wenet 在 CER 上进行了对比。结果表明,
新一代 Kaldi 具有收敛速度快的优点。