The stable diffusion webui training aid extension helps you quickly and visually train models such as Lora.
一个 stable-diffusion-webui 的训练辅助扩展,可以帮助你快速、直观地训练 Lora 等模型。
English (TODO) google translate
在 stable-diffusion-webui 的 Extensions 页面中安装:
在 URL for extension's git repository 中填入: https://github.com/liasece/sd-webui-train-tools

安装完成后,重启 stable-diffusion-webui。可以看到多一个标签页 Train Tools :

由于一个 Lora 的训练可能会经过很多过程,会不断地调整训练参数,所以要有管理的概念。
工程名字就是你的 Lora 的名字,通常是一个主题,或者一个画风,或者一个人物。

-
如果你觉得你的数据落后了,或者你刚刷新了网页但是没有重启 stable-diffusion-webui ,你应该点击刷新按钮确保你页面上的数据是最新的。
-
点击创建工程按钮,输入工程名字,点击确定。
版本是工程的一个子集,你可以在一个工程中创建多个版本,每个版本都有自己的训练参数。
创建版本步骤和创建工程类似。

-
该区域为系统接受到的训练数据,和你上传的文件可能会有区别,因为训练的数据会经过处理。
-
该区域是你上传训练数据并且设置处理参数的区域。
每个每个工程的每个版本的训练数据都是独立的,你可以在一个工程中创建多个版本,每个版本都可以使用不同的训练数据。
你可以一次性选择多张图片上传:
数据上传完成之后,需要进行一些处理。这里有一些处理的参数,你可以根据自己的需要进行调整。默认参数已经可以满足一般情况。
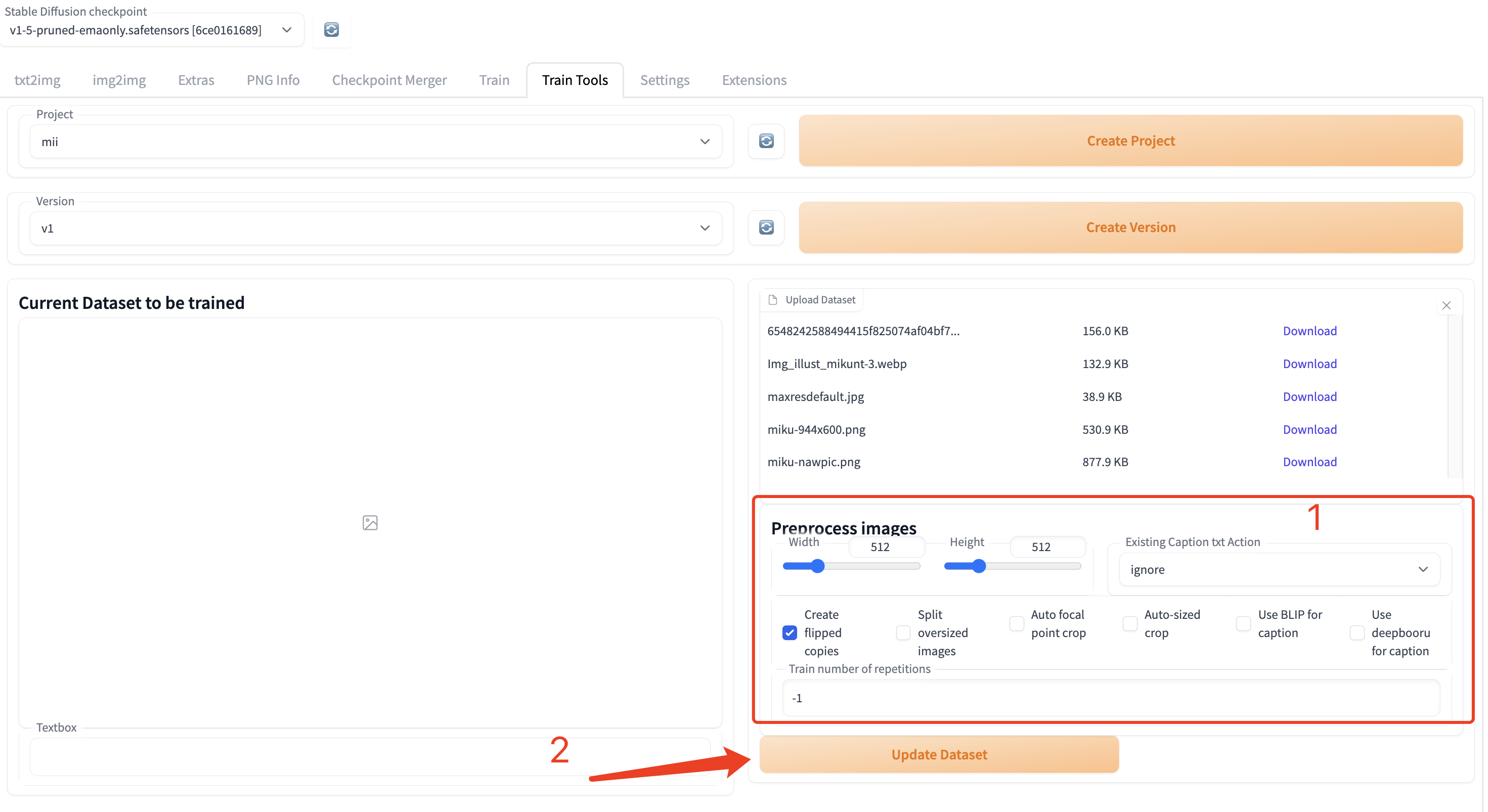
你上传的数据源文件会被保留,但是不会真正用于训练。真正被用到训练中的是左边展示的数据。
我们推荐你使用另外的一个扩展 sd-webui-dataset-tag-editor ,这个插件做得很优秀!能够很好地管理数据集图片的 tag。
为了能让你更方便地使用这个插件,我们在数据集下方显示了这个数据集的绝对路径,你可以直接复制这个路径粘贴到这个插件的 Dataset directory 中。
将正则化的图片放在: outputs/train_tools/projects/[project]/versions/[version]/dataset/reg 目录下,和 processed 文件夹同级。例如: dataset/processed/40_object 对应的正则化图片目录为: dataset/reg/10_object
准备好训练数据,确认待训练数据窗口中的数据是你想要的之后,就可以开始训练了。

-
这个区域显示了真正会用于训练的数据。
-
这个区域是训练的参数设置区域。
这里有一些训练的参数,你可以根据自己的需要进行调整。默认参数已经可以满足一般情况。Train base model 很重要,一个好的基础模型很大程度影响你的训练效果。

-
训练配置区域。
-
预览参数配置区域。因为训练结束后可以自动预览训练结果,所以这里有一些预览的参数可以一并配置。参考 预览训练结果 。
-
训练完成后自动运行预览图生成。
-
开始训练。
第一次训练时,会去下载一些模型,你可以在命令行中看到下载进度。

在 stable-diffusion-webui 的运行命令行中可以看到训练的过程及进度。
请正确勾选 Base on Stable Diffusion V2 或者 Base on Stable Diffusion XL ,否则会导致训练失败。
在 Append or override the sd_script args. 文本框中输入参数,务必使用 -- 开头的参数,例如:--lr_scheduler="constant_with_warmup" --max_grad_norm=0.0 。插件代码中会使用 -- 分隔符作为参数间的分隔符。
有时,一套训练配置可能并不是最优的。等待你的训练结束然后再重新开始训练,这样的效率太低了。因此,你可以一次性配置多种参数,点击一次训练,自动组合不同的参数进行训练。
你可以直接使用 , 分隔不同的参数,如果这个参数支持多选,例如:

-
一次性训练学习率为
0.0002,0.0003,0.0004,0.0005的模型。 -
一次性训练优化器为
Lion,AdamW的模型。
如果你认为还有别的参数值得多选,可以提交 Issue 或者 Pull request 告诉我。
在这个例子中,你一次性训练了 8 个模型。分别为: Lion,0.0002 、 Lion,0.0003 、 Lion,0.0004 、 Lion,0.0005 、 AdamW,0.0002 、 AdamW,0.0003 、 AdamW,0.0004 、 AdamW,0.0005 。
训练完成后,你可以在 预览训练结果 中看到一个下拉框:

意思很明显,这个命名如 v1-5-pruned-emaonly-bs-10-ep-10-op-Lion-lr-0_0001-net-128-ap-64 表示:
-
这个训练结果集基于
v1-5-pruned-emaonly基础模型。 -
训练时的 batch size 为 10。
-
训练时的 epoch 为 10。
-
训练时的优化器为 Lion。
-
训练时的学习率为 0.0001。
-
训练时的 Net dim 大小为 128。
-
训练时的 Alpha 为 64。
每个训练参数的结果集底下都会有基于 Save every n epochs 的检查点。即使你在某个版本中一直调整训练参数去训练,你也基本不会丢失你的训练结果。
不同的训练数据/训练参数/训练次数都会导致训练的效果不一样。你可以在这里预览训练结果。方便地挑选较好的结果。
预览域也有一些参数,这些参数和 txt2img 中的含义基本一致。
关键词中会自动添加每个训练检查点的 lora:xx:xx ,你不用手动添加。
你在这里输入的其他 Lora 将无效,因为这会污染你的判断。
这里还有一些类似于 txt2img 中 xyz plot 的功能,默认值已经可以满足一般情况。这里的部分值是可以多选的,值之间用 "," 分隔。

-
要在检查点上预览的关键词。和 txt2img 中的含义基本一致。
-
如果显存允许,你可以设置成 4 或者 9 等 n*n 的值,这样可以在一个图中预览更多的结果。
-
这里是你想为每个检查点预测几个 Lora 权重,用 "," 分隔。
-
点击这个按钮,将为下面列表中的所有检查点执行相同的 seed 的预测图片生成,这样可以更方便地对比不同检查点的效果。
-
这个检查点的保存路径。如果你认为它的结果好,可以去这里找到它。
-
类似于 xyz 脚本,这一张图列出了所有参数下它的预测结果。
-
每个检查点下都有自己的预测按钮,点击它就会只用这个检查点生成图片。
目前没有在 UI 中提供下载模型的功能,你可以去你 stable-diffusion-webui > output > train_tools > 工程名 > versions > 版本名 > checkpoints 中找到你训练好的模型。
-
禁用其他插件,防止依赖冲突。
-
重启 stable-diffusion-webui。
-
如果还是不行,提交 Issue 告诉我。
上传数据集后,如果你的一些预处理参数需要下载额外模型,那么网页上会有一段时间没有反应,这是正常的。你可以在命令行中看到进度。
训练时间是很长的,这个过程可能会导致网页没响应,你可以在命令行中看到进度。
预览生成图片的过程可能会导致网页没响应,你可以在命令行中看到进度。或者如果预览信息太大图片太多导致网页失去相应的话,你需要刷新 UI 或者重启 stable-diffusion-webui。
你可以点击工程或者版本后面的刷新按钮,这会从服务器重新拉取页面数据。包括图片。刷新网页可能不会解决问题,需要点击工程或者版本后面的刷新按钮。
检查图片格式,可能是图片格式不支持。目前支持 .png .jpg .jpeg .bmp .webp
-
提高你的训练图片质量。检查你的训练数据,可能是你的训练数据中有一些奇怪的东西。比如你的训练数据中有一些奇怪的图片,或者你的训练数据中有一些奇怪的文字。
-
如果是训练图片中的对象,而不是画风,在处理数据时勾选 "Use BLIP for caption" 或者 "Use deepbooru for caption"。进阶:想要取得好的效果,你要对这个处理后得到的提示文本进行修剪,默认情况下,这个文本会生成到
outputs/train_tools/projects/[project]/versions/[version]/dataset/processed/[dataset]/[image name].txt,你可以手动修改这个文件,将当中你想保留的特征去除(⚠️ 是在这些文本中去除你想保留的特征。如果你想为你的 Lora 保留关键字,那就在这个文本中留下这个关键字),然后重新训练。(这种功能应该集成在工具中,待开发) -
判断是不是训练次数不足,提高训练配置中的 "Number of epochs"。
-
提高训练配置中的 "Batch size"。这对显存容量的要求很高。24G 显存的显卡可以最高选到 10 左右。
参考上面这个问题。
训练过程需要的时间大致等于:
C * (n * [Number of epochs]) / ([Batch size] * p)
其中:
C: 常数,跟基础模型和训练数据集大小等因素有关
n: 训练数据集图片数量 "Train number of repetitions" (-1 时表示训练图片数为 min(512 / 上传图片数, 4) )。大多数情况下你不需要修改默认值,你可以改成你上传的图片数量的 k 倍
p: 你的显卡性能
所以,如果想要提高训练速度,你可以:
-
提高 "Batch size"。这对显存容量的要求很高。24G 显存的显卡可以最高选到 10 左右。
-
降低 "Number of epochs"。这会导致训练效果变差。(相当于降低训练步数)
-
降低 "Train number of repetitions"。这会导致训练效果变差。(相当于降低训练步数)
-
使用算力更高的显卡。
正确的 reg 子目录结构应该是和待训练数据拥有同样关键词的目录,例如:
dataset/processed/40_object
对应的正则化图片目录为:
dataset/reg/10_object
必须在 reg 目录下创建一个和待训练数据拥有同样关键词的目录,而不是直接放到/reg 下就可以了。
已知新版 gradio 在数据传输量太大时会出现这个问题,此时可以清除部分预览图,减少页面上图片数量。
工具也作出了修改,如果 Lora 检查点超过 10 个,后面的检查点将不再显示。
如果仍然存在疑问,可以参考 webui 这里 的讨论。
如果你只想解决问题,可以尝试 这个 issues 的方案,在启动 webui 时添加参数:--no-gradio-queue
本插件的训练脚本引用自 sd-scripts 。由于 sd-scripts 本身是一个非常优秀的工具,所以我没有对它进行修改,而是直接引用了它。