| sidebarDepth |
|---|
4 |
Relevancy refers to the accuracy and effectiveness of search results. If search results are almost always appropriate, then they can be considered relevant, and vice versa.
Meilisearch has a number of features for fine-tuning the relevancy of search results. The most important tool among them is ranking rules.
In order to ensure relevant results, search responses are sorted based on a set of consecutive rules called ranking rules.
Each index possesses a list of ranking rules stored as an array in the settings object. This array is fully customizable, meaning you can delete existing rules, add new ones, and reorder them as needed.
Meilisearch uses a bucket sort algorithm to rank documents whenever a search query is made. The first ranking rule applies to all documents, while each subsequent rule is only applied to documents considered equal under the previous rule as a tiebreaker.
The order in which ranking rules are applied matters. The first rule in the array has the most impact, and the last rule has the least. Our default configuration meets most standard needs, but you can change it.
Deleting a rule means that Meilisearch will no longer sort results based on that rule. For example, if you delete the typo ranking rule, documents with typos will still be considered during search, but they will no longer be sorted by increasing number of typos.
Meilisearch contains six built-in ranking rules in the following order:
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness"
]Depending on your needs, you might want to change this order. To do so, you can use the update settings endpoint or update ranking rules endpoint.
Results are sorted by decreasing number of matched query terms. Returns documents that contain all query terms first.
The `words` rule works from right to left. Therefore, the order of the query string impacts the order of results.For example, if someone were to search batman dark knight, the words rule would rank documents containing all three terms first, documents containing only batman and dark second, and documents containing only batman third.
Results are sorted by increasing number of typos. Returns documents that match query terms with fewer typos first.
Results are sorted by increasing distance between matched query terms. Returns documents where query terms occur close together and in the same order as the query string first.
Results are sorted according to the attribute ranking order. Returns documents that contain query terms in more important attributes first.
Also, note the documents with attributes containing the query words at the beginning of the attribute will be considered more relevant than documents containing the query words at the end of the attributes.
Results are sorted according to parameters decided at query time. When the sort ranking rule is in a higher position, sorting is exhaustive: results will be less relevant but follow the user-defined sorting order more closely. When sort is in a lower position, sorting is relevant: results will be very relevant but might not always follow the order defined by the user.
Results are sorted by the similarity of the matched words with the query words. Returns documents that contain exactly the same terms as the ones queried first.
<Tabs.Container labels={["Typo", "Proximity", "Attribute", "Exactness"]}>
<Tabs.Content label="Typo">
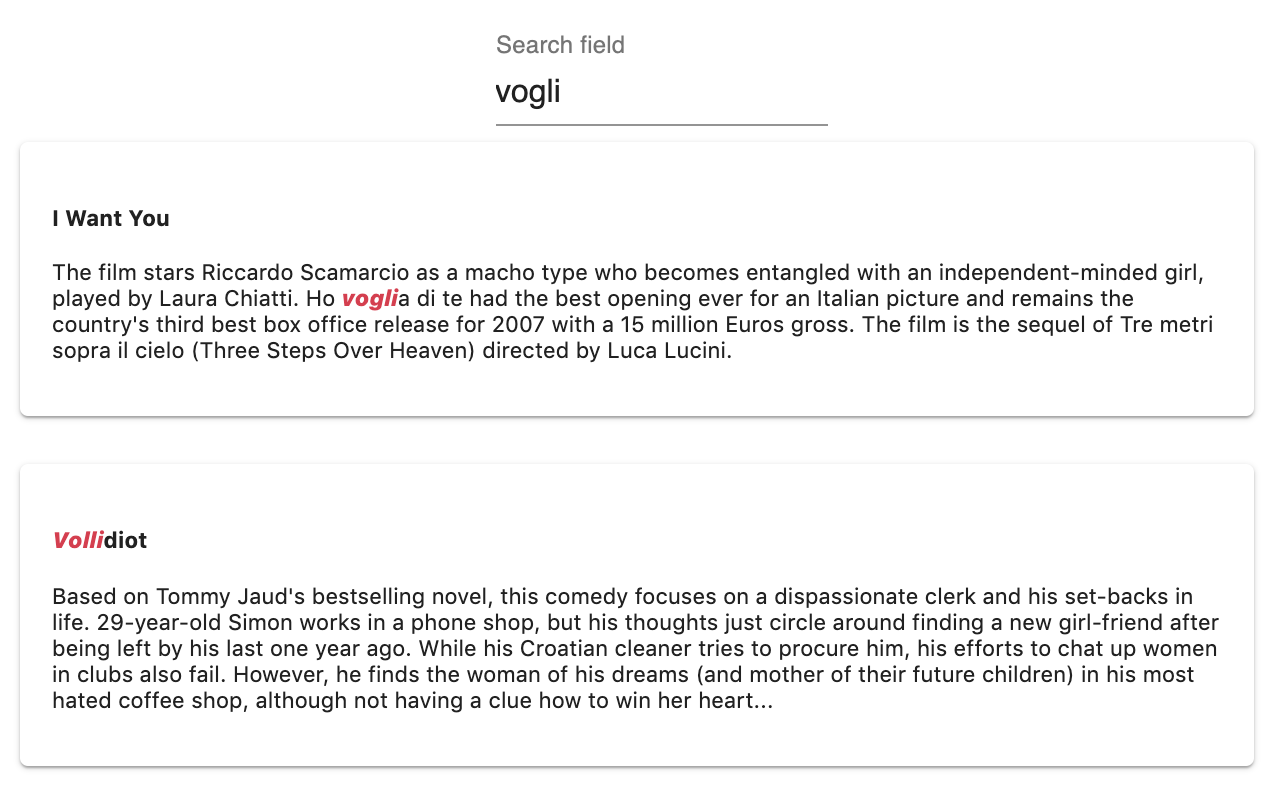
vogli: 0 typovolli: 1 typo
The typo rule sorts the results by increasing number of typos on matched query words.
</Tabs.Content>
<Tabs.Content label="Proximity">
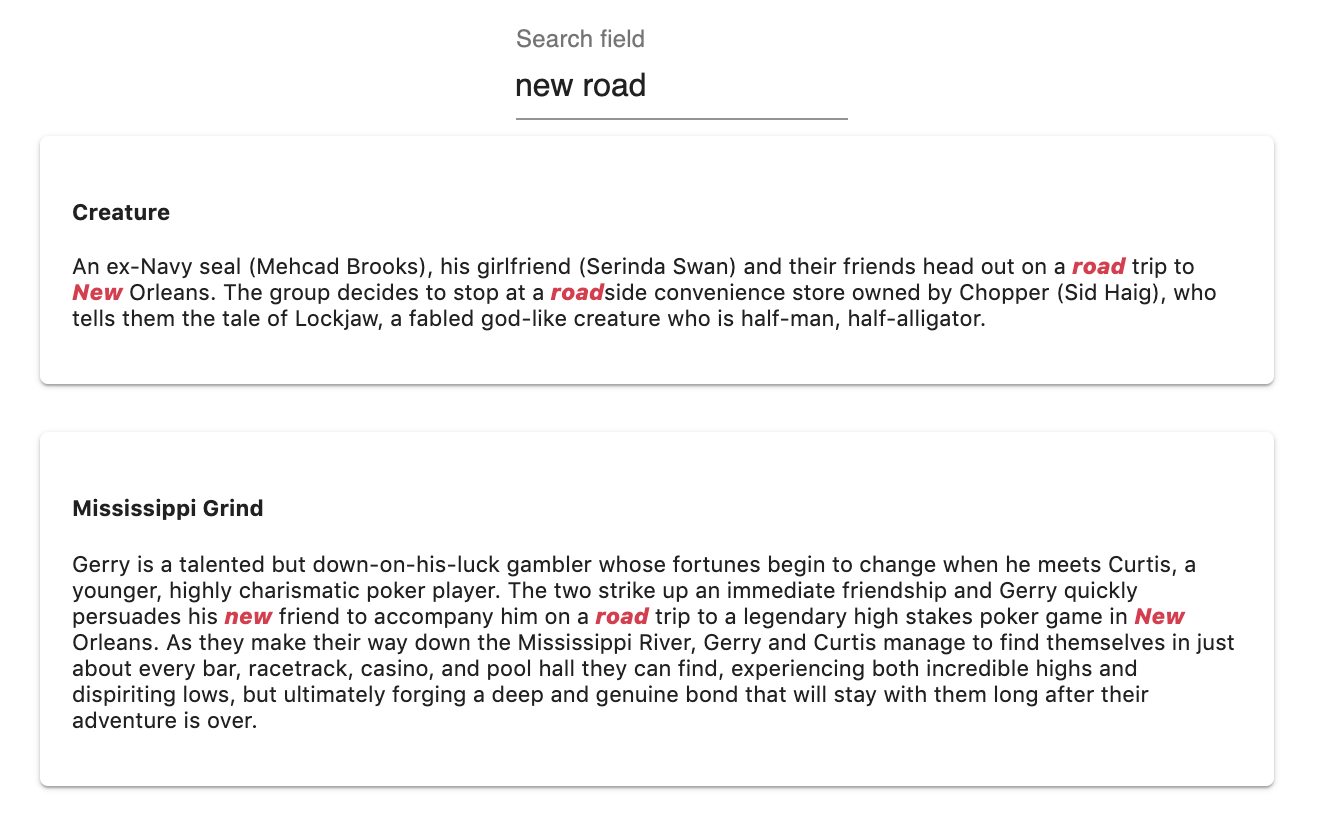
The reason why Creature is listed before Mississippi Grind is because of the proximity rule. The smallest distance between the matching words in creature is smaller than the smallest distance between the matching words in Mississippi Grind.
The proximity rule sorts the results by increasing distance between matched query terms.
</Tabs.Content>
<Tabs.Content label="Attribute">
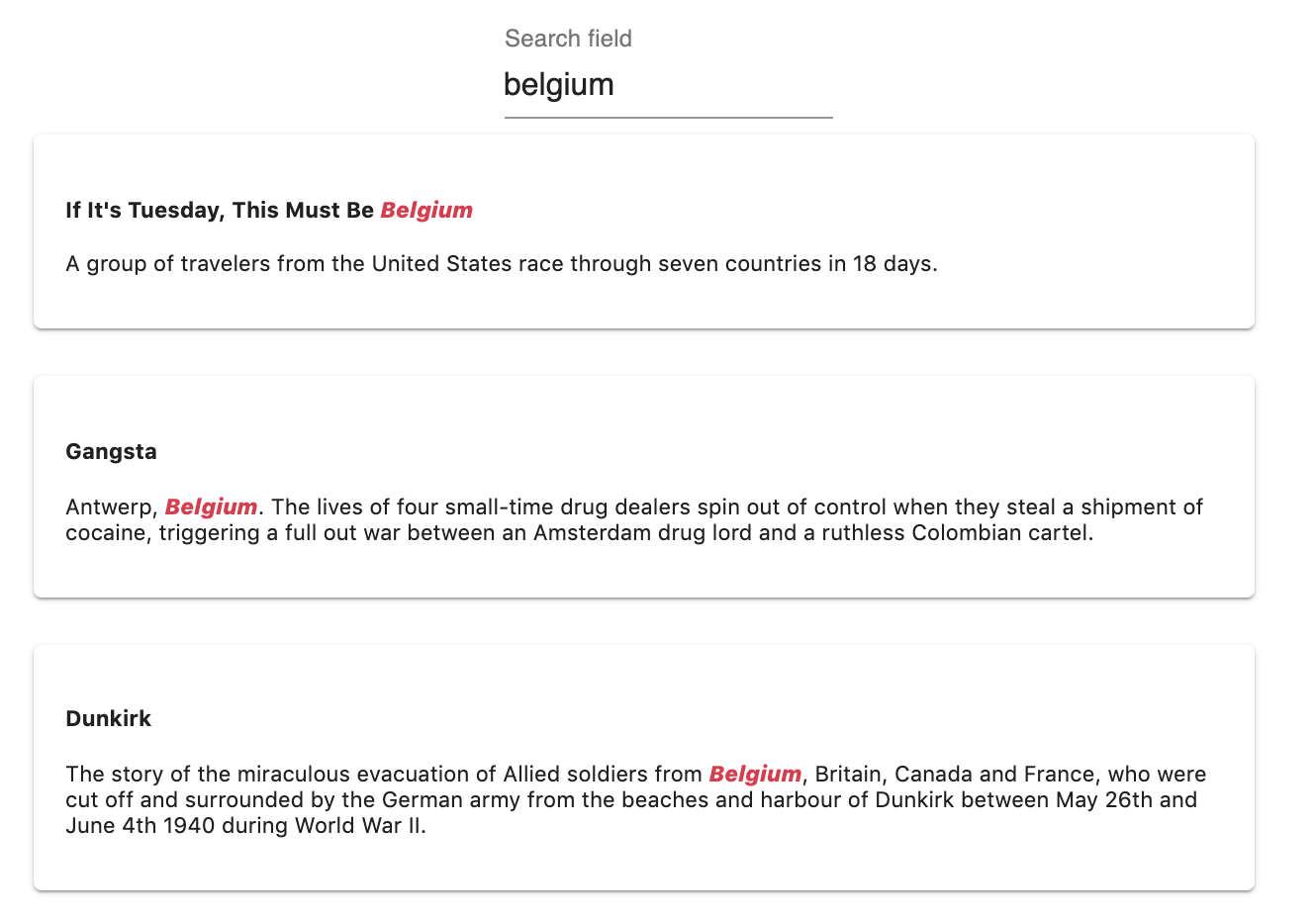
If It's Tuesday, This must be Belgium is the first document because the matched word Belgium is found in the title attribute and not the overview.
The attribute rule sorts the results by attribute importance.
</Tabs.Content>
<Tabs.Content label="Exactness">
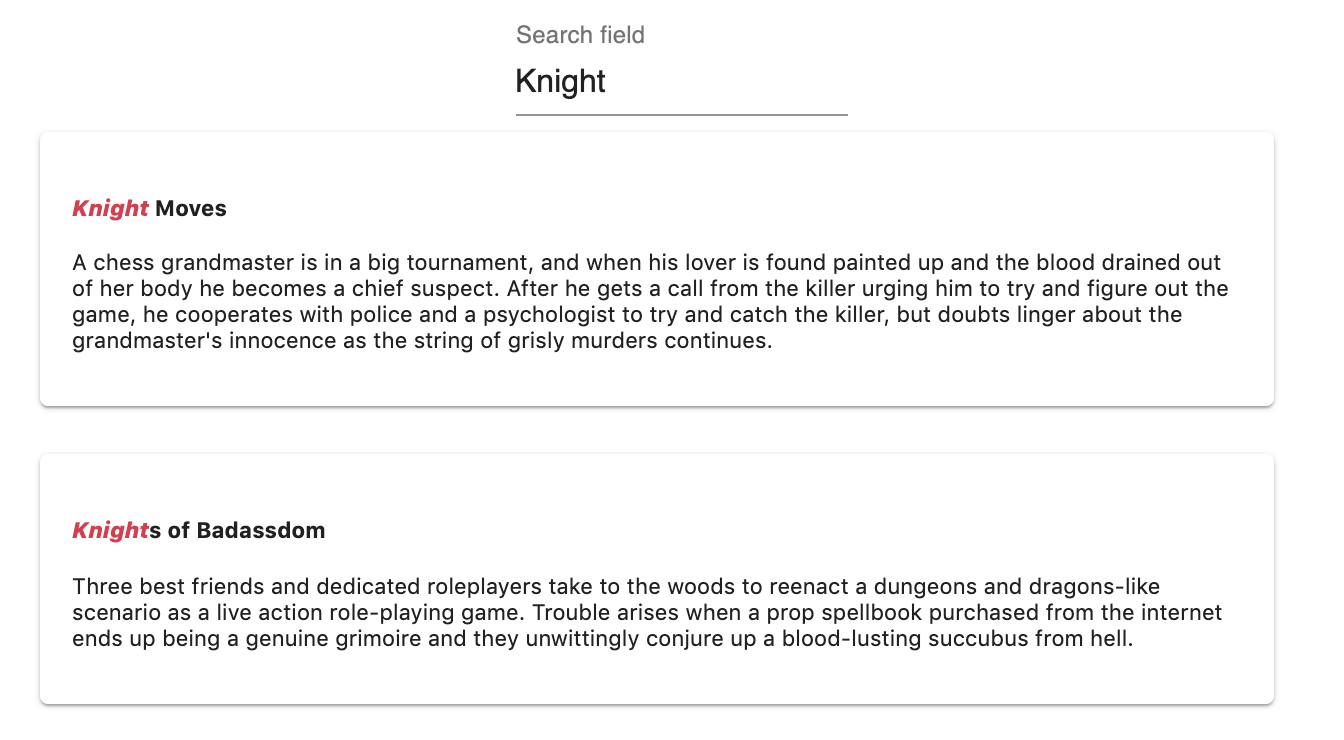
Knight Moves is displayed before Knights of Badassdom. Knight is exactly the same as the search query Knight whereas there is a letter of difference between Knights and the search query Knight.
</Tabs.Content>
</Tabs.Container>
For now, Meilisearch supports two custom rules: one for ascending sort and one for descending sort.
To add a custom ranking rule, you have to communicate the attribute name followed by a colon (:) and either asc for ascending order or desc for descending order.
-
To apply an ascending sort (results sorted by increasing value of the attribute):
attribute_name:asc -
To apply a descending sort (results sorted by decreasing value of the attribute):
attribute_name:desc
The attribute must have either a numeric or a string value in all of the documents contained in that index.
You can add this rule to the existing list of ranking rules using the update settings endpoint or update ranking rules endpoint.
Let's say you have a movie dataset. The documents contain the fields release_date with a timestamp as value, and movie_ranking, an integer that represents its ranking.
The following example will create a rule that makes older movies more relevant than recent ones. A movie released in 1999 will appear before a movie released in 2020.
release_date:asc
The following example will create a rule that makes movies with a good rank more relevant than movies with a lower rank. Movies with a higher ranking will appear first.
movie_ranking:desc
To add a rule to the existing ranking rule, you have to add the rule to the existing ordered rules array using the settings route,
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness",
"release_date:asc",
"movie_ranking:desc"
]Meilisearch allows users to define sorting order at query time by using the sort search parameter. There is some overlap between sorting and custom ranking rules, but the two do have different uses.
In general, sort will be most useful when you want to allow users to define what type of results they want to see first. A good use-case for sort is creating a webshop interface where customers can sort products by descending or ascending product price.
Custom ranking rules, instead, are always active once configured and will be useful when you want to promote certain types of results. A good use-case for custom ranking rules is ensuring discounted products in a webshop always feature among the top results.
In a typical dataset, some fields are more relevant to search than others. A title, for example, has a value more meaningful to a movie search than its overview or its release_date.
By default, the attribute ranking order is generated automatically based on the order in which Meilisearch encounters attributes in the indexed documents. In other words, if your first indexed document looks like this:
{
"a": "some data",
"b": "more data",
"c": "other data"
}The automatically generated attribute ranking order will be ["a", "b", "c"]. If you then add a second document that looks like this:
{
"c": "other data",
"d": "surprise data!",
"a": "some data",
"b": "more data"
}The attribute ranking order will be updated to ["a", "b", "c", "d"]. In other words, when Meilisearch encounters new attributes in subsequently indexed documents, they are added to the bottom of the attribute ranking order.
The attribute ranking order can also be set manually. For a more detailed look at this subject, see the searchable attributes list.
[
"title",
"overview",
"release_date"
]With the above attribute ranking order, matching words found in the title field would have a higher impact on relevancy than the same words found in overview or release_date. If you searched "1984", for example, results like Michael Radford's film "1984" would be ranked higher than movies released in the year 1984.