From 57924caff025006740be45f9b1ed666c76e3a358 Mon Sep 17 00:00:00 2001
From: Chi Song <27178119+squirrelsc@users.noreply.github.com>
Date: Tue, 26 Nov 2019 17:41:44 +0800
Subject: [PATCH] Chinese translation (#1684)
---
README_zh_CN.md | 4 +-
docs/en_US/Tutorial/QuickStart.md | 2 +-
docs/zh_CN/AdvancedFeature/MultiPhase.md | 2 +-
docs/zh_CN/CommunitySharings/TuningSystems.md | 10 +
docs/zh_CN/Compressor/AutoCompression.md | 10 +-
docs/zh_CN/Compressor/L1FilterPruner.md | 51 ++++
.../Compressor/LotteryTicketHypothesis.md | 23 ++
docs/zh_CN/Compressor/Overview.md | 161 +++++++----
docs/zh_CN/Compressor/Pruner.md | 159 ++++++++++-
docs/zh_CN/Compressor/Quantizer.md | 47 ++--
docs/zh_CN/Compressor/SlimPruner.md | 39 +++
docs/zh_CN/FeatureEngineering/GBDTSelector.md | 61 +++++
.../GradientFeatureSelector.md | 84 ++++++
docs/zh_CN/FeatureEngineering/Overview.md | 255 ++++++++++++++++++
docs/zh_CN/Makefile | 2 +-
docs/zh_CN/NAS/NasInterface.md | 177 ++++++++++++
docs/zh_CN/NAS/Overview.md | 109 ++++++++
docs/zh_CN/TrainingService/LocalMode.md | 5 +-
docs/zh_CN/TrainingService/PaiMode.md | 19 +-
.../TrainingService/RemoteMachineMode.md | 10 +-
docs/zh_CN/TrialExample/GbdtExample.md | 14 +-
docs/zh_CN/Tuner/BuiltinTuner.md | 4 +-
docs/zh_CN/Tutorial/Contributing.md | 3 +
docs/zh_CN/Tutorial/Nnictl.md | 33 +++
docs/zh_CN/Tutorial/QuickStart.md | 4 +-
docs/zh_CN/Tutorial/SearchSpaceSpec.md | 10 +-
docs/zh_CN/advanced.rst | 2 -
docs/zh_CN/feature_engineering.rst | 16 ++
docs/zh_CN/model_compression.rst | 28 ++
docs/zh_CN/nas.rst | 25 ++
docs/zh_CN/sdk_reference.rst | 22 +-
docs/zh_CN/tutorials.rst | 3 +
32 files changed, 1280 insertions(+), 114 deletions(-)
create mode 100644 docs/zh_CN/CommunitySharings/TuningSystems.md
create mode 100644 docs/zh_CN/Compressor/L1FilterPruner.md
create mode 100644 docs/zh_CN/Compressor/LotteryTicketHypothesis.md
create mode 100644 docs/zh_CN/Compressor/SlimPruner.md
create mode 100644 docs/zh_CN/FeatureEngineering/GBDTSelector.md
create mode 100644 docs/zh_CN/FeatureEngineering/GradientFeatureSelector.md
create mode 100644 docs/zh_CN/FeatureEngineering/Overview.md
create mode 100644 docs/zh_CN/NAS/NasInterface.md
create mode 100644 docs/zh_CN/NAS/Overview.md
create mode 100644 docs/zh_CN/feature_engineering.rst
create mode 100644 docs/zh_CN/model_compression.rst
create mode 100644 docs/zh_CN/nas.rst
diff --git a/README_zh_CN.md b/README_zh_CN.md
index a0cafb5a72..8df20fd24c 100644
--- a/README_zh_CN.md
+++ b/README_zh_CN.md
@@ -342,6 +342,7 @@ You can use these commands to get more information about the experiment
* 在 NNI 中运行 [神经网络架构结构搜索](examples/trials/nas_cifar10/README_zh_CN.md)
* [NNI 中的自动特征工程](examples/trials/auto-feature-engineering/README_zh_CN.md)
* 使用 NNI 的 [矩阵分解超参调优](https://github.com/microsoft/recommenders/blob/master/notebooks/04_model_select_and_optimize/nni_surprise_svd.ipynb)
+ * [scikit-nni](https://github.com/ksachdeva/scikit-nni) 使用 NNI 为 scikit-learn 开发的超参搜索。
* ### **相关文章**
* [超参数优化的对比](docs/zh_CN/CommunitySharings/HpoComparision.md)
@@ -349,6 +350,7 @@ You can use these commands to get more information about the experiment
* [并行化顺序算法:TPE](docs/zh_CN/CommunitySharings/ParallelizingTpeSearch.md)
* [使用 NNI 为 SVD 自动调参](docs/zh_CN/CommunitySharings/RecommendersSvd.md)
* [使用 NNI 为 SPTAG 自动调参](docs/zh_CN/CommunitySharings/SptagAutoTune.md)
+ * [使用 NNI 为 scikit-learn 查找超参](https://towardsdatascience.com/find-thy-hyper-parameters-for-scikit-learn-pipelines-using-microsoft-nni-f1015b1224c1)
* **博客** - [AutoML 工具(Advisor,NNI 与 Google Vizier)的对比](http://gaocegege.com/Blog/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/katib-new#%E6%80%BB%E7%BB%93%E4%B8%8E%E5%88%86%E6%9E%90) 作者:[@gaocegege](https://github.com/gaocegege) - kubeflow/katib 的设计与实现的总结与分析章节
## **反馈**
@@ -359,4 +361,4 @@ You can use these commands to get more information about the experiment
## **许可协议**
-代码库遵循 [MIT 许可协议](LICENSE)
+代码库遵循 [MIT 许可协议](LICENSE)
\ No newline at end of file
diff --git a/docs/en_US/Tutorial/QuickStart.md b/docs/en_US/Tutorial/QuickStart.md
index 929eaea0cd..3a357eed6e 100644
--- a/docs/en_US/Tutorial/QuickStart.md
+++ b/docs/en_US/Tutorial/QuickStart.md
@@ -100,7 +100,7 @@ If you want to use NNI to automatically train your model and find the optimal hy
with tf.Session() as sess:
mnist_network.train(sess, mnist)
test_acc = mnist_network.evaluate(mnist)
-+ nni.report_final_result(acc)
++ nni.report_final_result(test_acc)
if __name__ == '__main__':
- params = {'data_dir': '/tmp/tensorflow/mnist/input_data', 'dropout_rate': 0.5, 'channel_1_num': 32, 'channel_2_num': 64,
diff --git a/docs/zh_CN/AdvancedFeature/MultiPhase.md b/docs/zh_CN/AdvancedFeature/MultiPhase.md
index 23df19f7f5..2d07709234 100644
--- a/docs/zh_CN/AdvancedFeature/MultiPhase.md
+++ b/docs/zh_CN/AdvancedFeature/MultiPhase.md
@@ -79,7 +79,7 @@ trial_end
### 支持多阶段 Experiment 的 Tuner:
-[TPE](../Tuner/HyperoptTuner.md), [Random](../Tuner/HyperoptTuner.md), [Anneal](../Tuner/HyperoptTuner.md), [Evolution](../Tuner/EvolutionTuner.md), [SMAC](../Tuner/SmacTuner.md), [NetworkMorphism](../Tuner/NetworkmorphismTuner.md), [MetisTuner](../Tuner/MetisTuner.md), [BOHB](../Tuner/BohbAdvisor.md), [Hyperband](../Tuner/HyperbandAdvisor.md), [ENAS Tuner ](https://github.com/countif/enas_nni/blob/master/nni/examples/tuners/enas/nni_controller_ptb.py).
+[TPE](../Tuner/HyperoptTuner.md), [Random](../Tuner/HyperoptTuner.md), [Anneal](../Tuner/HyperoptTuner.md), [Evolution](../Tuner/EvolutionTuner.md), [SMAC](../Tuner/SmacTuner.md), [NetworkMorphism](../Tuner/NetworkmorphismTuner.md), [MetisTuner](../Tuner/MetisTuner.md), [BOHB](../Tuner/BohbAdvisor.md), [Hyperband](../Tuner/HyperbandAdvisor.md).
### 支持多阶段 Experiment 的训练平台:
diff --git a/docs/zh_CN/CommunitySharings/TuningSystems.md b/docs/zh_CN/CommunitySharings/TuningSystems.md
new file mode 100644
index 0000000000..8f753c32dc
--- /dev/null
+++ b/docs/zh_CN/CommunitySharings/TuningSystems.md
@@ -0,0 +1,10 @@
+# 使用 NNI 自动调优系统
+
+随着计算机系统和网络变得越来越复杂,通过显式的规则和启发式的方法来手工优化已经越来越难,甚至不可能了。 下面是使用 NNI 来优化系统的两个示例。 可根据这些示例来调优自己的系统。
+
+* [在 NNI 上调优 RocksDB](../TrialExample/RocksdbExamples.md)
+* [使用 NNI 调优 SPTAG (Space Partition Tree And Graph) 参数](SptagAutoTune.md)
+
+参考[论文](https://dl.acm.org/citation.cfm?id=3352031)了解详情:
+
+Mike Liang, Chieh-Jan, et al. "The Case for Learning-and-System Co-design." ACM SIGOPS Operating Systems Review 53.1 (2019): 68-74.
diff --git a/docs/zh_CN/Compressor/AutoCompression.md b/docs/zh_CN/Compressor/AutoCompression.md
index 62ab4bd0d8..686ed6aaa1 100644
--- a/docs/zh_CN/Compressor/AutoCompression.md
+++ b/docs/zh_CN/Compressor/AutoCompression.md
@@ -9,13 +9,13 @@
```python
from nni.compression.torch import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
-pruner = LevelPruner(config_list)
-pruner(model)
+pruner = LevelPruner(model, config_list)
+pruner.compress()
```
op_type 为 'default' 表示模块类型定义在了 [default_layers.py](https://github.com/microsoft/nni/blob/master/src/sdk/pynni/nni/compression/torch/default_layers.py)。
-因此 `{ 'sparsity': 0.8, 'op_types': ['default'] }` 表示 **所有指定 op_types 的层都会被压缩到 0.8 的稀疏度**。 当调用 `pruner(model)` 时,模型会通过掩码进行压缩。随后还可以微调模型,此时**被剪除的权重不会被更新**。
+因此 `{ 'sparsity': 0.8, 'op_types': ['default'] }` 表示 **所有指定 op_types 的层都会被压缩到 0.8 的稀疏度**。 当调用 `pruner.compress()` 时,模型会通过掩码进行压缩。随后还可以微调模型,此时**被剪除的权重不会被更新**。
## 然后,进行自动化
@@ -84,9 +84,9 @@ config_list_agp = [{'initial_sparsity': 0, 'final_sparsity': conv0_sparsity,
{'initial_sparsity': 0, 'final_sparsity': conv1_sparsity,
'start_epoch': 0, 'end_epoch': 3,
'frequency': 1,'op_name': 'conv1' },]
-PRUNERS = {'level':LevelPruner(config_list_level),'agp':AGP_Pruner(config_list_agp)}
+PRUNERS = {'level':LevelPruner(model, config_list_level),'agp':AGP_Pruner(model, config_list_agp)}
pruner = PRUNERS(params['prune_method']['_name'])
-pruner(model)
+pruner.compress()
... # fine tuning
acc = evaluate(model) # evaluation
nni.report_final_results(acc)
diff --git a/docs/zh_CN/Compressor/L1FilterPruner.md b/docs/zh_CN/Compressor/L1FilterPruner.md
new file mode 100644
index 0000000000..49c3e50d62
--- /dev/null
+++ b/docs/zh_CN/Compressor/L1FilterPruner.md
@@ -0,0 +1,51 @@
+NNI Compressor 中的 L1FilterPruner
+===
+
+## 1. 介绍
+
+L1FilterPruner 是在卷积层中用来修剪过滤器的通用剪枝算法。
+
+在 ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710) 中提出,作者 Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet 以及 Hans Peter Graf。
+
+
+
+> L1Filter Pruner 修剪**卷积层**中的过滤器
+>
+> 从第 i 个卷积层修剪 m 个过滤器的过程如下:
+>
+> 1. 对于每个过滤器 ,计算其绝对内核权重之和
+> 2. 将过滤器按 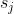 排序。
+> 3. 修剪 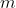 具有最小求和值及其相应特征图的筛选器。 在 下一个卷积层中,被剪除的特征图所对应的内核也被移除。
+> 4. 为第  和 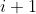 层创建新的内核举证,并保留剩余的内核 权重,并复制到新模型中。
+
+## 2. 用法
+
+PyTorch 代码
+
+```
+from nni.compression.torch import L1FilterPruner
+config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'], 'op_names': ['conv1', 'conv2'] }]
+pruner = L1FilterPruner(model, config_list)
+pruner.compress()
+```
+
+#### L1Filter Pruner 的用户配置
+
+- **sparsity:**,指定压缩的稀疏度。
+- **op_types:** 在 L1Filter Pruner 中仅支持 Conv2d。
+
+## 3. 实验
+
+我们实现了 ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710) 中的一项实验, 即论文中,在 CIFAR-10 数据集上修剪 **VGG-16** 的 **VGG-16-pruned-A**,其中大约剪除了 $64\%$ 的参数。 我们的实验结果如下:
+
+| 模型 | 错误率(论文/我们的) | 参数量 | 剪除率 |
+| --------------- | ----------- | -------- | ----- |
+| VGG-16 | 6.75/6.49 | 1.5x10^7 | |
+| VGG-16-pruned-A | 6.60/6.47 | 5.4x10^6 | 64.0% |
+
+实验代码在 [examples/model_compress](https://github.com/microsoft/nni/tree/master/examples/model_compress/)
+
+
+
+
+
diff --git a/docs/zh_CN/Compressor/LotteryTicketHypothesis.md b/docs/zh_CN/Compressor/LotteryTicketHypothesis.md
new file mode 100644
index 0000000000..8193d487a3
--- /dev/null
+++ b/docs/zh_CN/Compressor/LotteryTicketHypothesis.md
@@ -0,0 +1,23 @@
+Lottery Ticket 假设
+===
+
+## 介绍
+
+[The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks](https://arxiv.org/abs/1803.03635) 是主要衡量和分析的论文,它提供了非常有意思的见解。 为了在 NNI 上支持此算法,主要实现了找到*获奖彩票*的训练方法。
+
+本文中,作者使用叫做*迭代*修剪的方法:
+> 1. 随机初始化一个神经网络 f(x;theta_0) (其中 theta_0 为 D_{theta}).
+> 2. 将网络训练 j 次,得出参数 theta_j。
+> 3. 在 theta_j 修剪参数的 p%,创建掩码 m。
+> 4. 将其余参数重置为 theta_0 的值,创建获胜彩票 f(x;m*theta_0)。
+> 5. 重复步骤 2、3 和 4。
+
+如果配置的最终稀疏度为 P (e.g., 0.8) 并且有 n 次修建迭代,每次迭代修剪前一轮中剩余权重的 1-(1-P)^(1/n)。
+
+## 重现结果
+
+在重现时,在 MNIST 使用了与论文相同的配置。 [此处](https://github.com/microsoft/nni/tree/master/examples/model_compress/lottery_torch_mnist_fc.py)为实现代码。 在次实验中,修剪了10次,在每次修剪后,训练了 50 个 epoch。
+
+
+
+上图展示了全连接网络的结果。 `round0-sparsity-0.0` 是没有剪枝的性能。 与论文一致,修剪约 80% 也能获得与不修剪时相似的性能,收敛速度也会更快。 如果修剪过多(例如,大于 94%),则精度会降低,收敛速度会稍慢。 与本文稍有不同,论文中数据的趋势比较明显。
diff --git a/docs/zh_CN/Compressor/Overview.md b/docs/zh_CN/Compressor/Overview.md
index ddcf7f9bd5..db0482f7f5 100644
--- a/docs/zh_CN/Compressor/Overview.md
+++ b/docs/zh_CN/Compressor/Overview.md
@@ -5,12 +5,17 @@
NNI 提供了易于使用的工具包来帮助用户设计并使用压缩算法。 其使用了统一的接口来支持 TensorFlow 和 PyTorch。 只需要添加几行代码即可压缩模型。 NNI 中也内置了一些流程的模型压缩算法。 用户还可以通过 NNI 强大的自动调参功能来找到最好的压缩后的模型,详见[自动模型压缩](./AutoCompression.md)。 另外,用户还能使用 NNI 的接口,轻松定制新的压缩算法,详见[教程](#customize-new-compression-algorithms)。
## 支持的算法
+
NNI 提供了两种朴素压缩算法以及三种流行的压缩算法,包括两种剪枝算法以及三种量化算法:
| 名称 | 算法简介 |
| --------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [Level Pruner](./Pruner.md#level-pruner) | 根据权重的绝对值,来按比例修剪权重。 |
| [AGP Pruner](./Pruner.md#agp-pruner) | 自动的逐步剪枝(是否剪枝的判断:基于对模型剪枝的效果)[参考论文](https://arxiv.org/abs/1710.01878) |
+| [L1Filter Pruner](./Pruner.md#l1filter-pruner) | 剪除卷积层中最不重要的过滤器 (PRUNING FILTERS FOR EFFICIENT CONVNETS)[参考论文](https://arxiv.org/abs/1608.08710) |
+| [Slim Pruner](./Pruner.md#slim-pruner) | 通过修剪 BN 层中的缩放因子来修剪卷积层中的通道 (Learning Efficient Convolutional Networks through Network Slimming)[参考论文](https://arxiv.org/abs/1708.06519) |
+| [Lottery Ticket Pruner](./Pruner.md#agp-pruner) | "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks" 提出的剪枝过程。 它会反复修剪模型。 [参考论文](https://arxiv.org/abs/1803.03635) |
+| [FPGM Pruner](./Pruner.md#fpgm-pruner) | Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration [参考论文](https://arxiv.org/pdf/1811.00250.pdf) |
| [Naive Quantizer](./Quantizer.md#naive-quantizer) | 默认将权重量化为 8 位 |
| [QAT Quantizer](./Quantizer.md#qat-quantizer) | 为 Efficient Integer-Arithmetic-Only Inference 量化并训练神经网络。 [参考论文](http://openaccess.thecvf.com/content_cvpr_2018/papers/Jacob_Quantization_and_Training_CVPR_2018_paper.pdf) |
| [DoReFa Quantizer](./Quantizer.md#dorefa-quantizer) | DoReFa-Net: 通过低位宽的梯度算法来训练低位宽的卷积神经网络。 [参考论文](https://arxiv.org/abs/1606.06160) |
@@ -20,24 +25,26 @@ NNI 提供了两种朴素压缩算法以及三种流行的压缩算法,包括
通过简单的示例来展示如何修改 Trial 代码来使用压缩算法。 比如,需要通过 Level Pruner 来将权重剪枝 80%,首先在代码中训练模型前,添加以下内容([完整代码](https://github.com/microsoft/nni/tree/master/examples/model_compress))。
TensorFlow 代码
+
```python
from nni.compression.tensorflow import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
-pruner = LevelPruner(config_list)
-pruner(tf.get_default_graph())
+pruner = LevelPruner(tf.get_default_graph(), config_list)
+pruner.compress()
```
PyTorch 代码
+
```python
from nni.compression.torch import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
-pruner = LevelPruner(config_list)
-pruner(model)
+pruner = LevelPruner(model, config_list)
+pruner.compress()
```
可使用 `nni.compression` 中的其它压缩算法。 此算法分别在 `nni.compression.torch` 和 `nni.compression.tensorflow` 中实现,支持 PyTorch 和 TensorFlow。 参考 [Pruner](./Pruner.md) 和 [Quantizer](./Quantizer.md) 进一步了解支持的算法。
-函数调用 `pruner(model)` 接收用户定义的模型(在 Tensorflow 中,通过 `tf.get_default_graph()` 来获得模型,而 PyTorch 中 model 是定义的模型类),并修改模型来插入 mask。 然后运行模型时,这些 mask 即会生效。 mask 可在运行时通过算法来调整。
+函数调用 `pruner.compress()` 来修改用户定义的模型(在 Tensorflow 中,通过 `tf.get_default_graph()` 来获得模型,而 PyTorch 中 model 是定义的模型类),并修改模型来插入 mask。 然后运行模型时,这些 mask 即会生效。 mask 可在运行时通过算法来调整。
实例化压缩算法时,会传入 `config_list`。 配置说明如下。
@@ -54,6 +61,7 @@ pruner(model)
`list` 中的 `dict` 会依次被应用,也就是说,如果一个操作出现在两个配置里,后面的 `dict` 会覆盖前面的配置。
配置的简单示例如下:
+
```python
[
{
@@ -70,6 +78,7 @@ pruner(model)
}
]
```
+
其表示压缩操作的默认稀疏度为 0.8,但`op_name1` 和 `op_name2` 会使用 0.6,且不压缩 `op_name3`。
### 其它 API
@@ -77,17 +86,30 @@ pruner(model)
一些压缩算法使用 Epoch 来控制压缩进度(如[AGP](./Pruner.md#agp-pruner)),一些算法需要在每个批处理步骤后执行一些逻辑。 因此提供了另外两个 API。 一个是 `update_epoch`,可参考下例使用:
TensorFlow 代码
+
```python
pruner.update_epoch(epoch, sess)
```
+
PyTorch 代码
+
```python
pruner.update_epoch(epoch)
```
另一个是 `step`,可在每个批处理后调用 `pruner.step()`。 注意,并不是所有的算法都需要这两个 API,对于不需要它们的算法,调用它们不会有影响。
-__[TODO]__ 最后一个 API 可供用户导出压缩后的模型。 当完成训练后使用此 API,可得到压缩后的模型。 同时也可导出另一个文件用来存储 mask 的数值。
+使用下列 API 可轻松将压缩后的模型导出,稀疏模型的 `state_dict` 会保存在 `model.pth` 文件中,可通过 `torch.load('model.pth')` 加载。
+
+```
+pruner.export_model(model_path='model.pth')
+```
+
+`mask_dict` 和 `onnx` 格式的剪枝模型(需要指定 `input_shape`)可这样导出:
+
+```python
+pruner.export_model(model_path='model.pth', mask_path='mask.pth', onnx_path='model.onnx', input_shape=[1, 1, 28, 28])
+```
## 定制新的压缩算法
@@ -99,41 +121,49 @@ __[TODO]__ 最后一个 API 可供用户导出压缩后的模型。 当完成训
```python
# TensorFlow 中定制 Pruner。
-# 如果要在 PyTorch 中定制 Pruner,可将
+# PyTorch 的 Pruner,只需将
# nni.compression.tensorflow.Pruner 替换为
# nni.compression.torch.Pruner
class YourPruner(nni.compression.tensorflow.Pruner):
- def __init__(self, config_list):
- # 建议使用 NNI 定义的规范来进行配置
- super().__init__(config_list)
-
- def bind_model(self, model):
- # 此函数可通过成员变量,来保存模型和其权重,
- # 从而能在训练过程中获取这些信息。
- pass
-
- def calc_mask(self, weight, config, **kwargs):
- # weight 是目标的权重张量
- # config 是在 config_list 中为此层选定的 dict 对象
- # kwargs 包括 op, op_types, 和 op_name
- # 实现定制的 mask 并返回
+ def __init__(self, model, config_list):
+ """
+ 建议使用 NNI 定义的规范来配置
+ """
+ super().__init__(model, config_list)
+
+ def calc_mask(self, layer, config):
+ """
+ Pruner 需要重载此方法来为权重提供掩码
+ 掩码必须与权重有相同的形状和类型。
+ 将对权重执行 ``mul()`` 操作。
+ 此方法会挂载到模型的 ``forward()`` 方法上。
+
+ Parameters
+ ----------
+ layer: LayerInfo
+ 为 ``layer`` 的权重计算掩码
+ config: dict
+ 生成权重所需要的掩码
+ """
return your_mask
- # 注意, PyTorch 不需要 sess 参数
+ # PyTorch 版本不需要 sess 参数
def update_epoch(self, epoch_num, sess):
pass
- # 注意, PyTorch 不需要 sess 参数
+ # PyTorch 版本不需要 sess 参数
def step(self, sess):
- # 根据在 bind_model 函数中引用的模型或权重进行一些处理
+ """
+ 根据需要可基于 bind_model 方法中的模型或权重进行操作
+ """
pass
```
-对于最简单的算法,只需要重写 `calc_mask` 函数。 它可接收每层的权重,并选择对应的配置和操作的信息。 可在此函数中为此权重生成 mask 并返回。 NNI 会应用此 mask。
+对于最简单的算法,只需要重写 `calc_mask` 函数。 它会接收需要压缩的层以及其压缩配置。 可在此函数中为此权重生成 mask 并返回。 NNI 会应用此 mask。
-一些算法根据训练进度来生成 mask,如 Epoch 数量。 Pruner 可使用 `update_epoch` 来了解训练进度。
+一些算法根据训练进度来生成 mask,如 Epoch 数量。 Pruner 可使用 `update_epoch` 来了解训练进度。 应在每个 Epoch 之前调用它。
-一些算法可能需要全局的信息来生成 mask,例如模型的所有权重(用于生成统计信息),模型优化器的信息。 可使用 `bind_model` 来支持此类需求。 `bind_model` 接受完整模型作为参数,因而其记录了所有信息(例如,权重的引用)。 然后 `step` 可以根据算法来处理或更新信息。 可参考[内置算法的源码](https://github.com/microsoft/nni/tree/master/src/sdk/pynni/nni/compressors)作为示例。
+一些算法可能需要全局的信息来生成 mask,例如模型的所有权重(用于生成统计信息). 可在 Pruner 类中通过 `self.bound_model` 来访问权重。 如果需要优化器的信息(如在 Pytorch 中),可重载 `__init__` 来接收优化器等参数。 然后 `step` 可以根据算法来处理或更新信息。 可参考[内置算法的源码](https://github.com/microsoft/nni/tree/master/src/sdk/pynni/nni/compressors)作为示例。
### 量化算法
@@ -141,38 +171,79 @@ class YourPruner(nni.compression.tensorflow.Pruner):
```python
# TensorFlow 中定制 Quantizer。
-# 如果要在 PyTorch 中定制 Quantizer,可将
+# PyTorch 的 Quantizer,只需将
# nni.compression.tensorflow.Quantizer 替换为
# nni.compression.torch.Quantizer
class YourQuantizer(nni.compression.tensorflow.Quantizer):
- def __init__(self, config_list):
- # 建议使用 NNI 定义的规范来进行配置
- super().__init__(config_list)
-
- def bind_model(self, model):
- # 此函数可通过成员变量,来保存模型和其权重,
- # 从而能在训练过程中获取这些信息。
- pass
+ def __init__(self, model, config_list):
+ """
+ 建议使用 NNI 定义的规范来配置
+ """
+ super().__init__(model, config_list)
def quantize_weight(self, weight, config, **kwargs):
- # weight 是目标的权重张量
- # config 是在 config_list 中为此层选定的 dict 对象
- # kwargs 包括 op, op_types, 和 op_name
- # 实现定制的 Quantizer 并返回新的权重
+ """
+ quantize 需要重载此方法来为权重提供掩码
+ 此方法挂载于模型的 :meth:`forward`。
+
+ Parameters
+ ----------
+ weight : Tensor
+ 要被量化的权重
+ config : dict
+ 权重量化的配置
+ """
+
+ # 此处逻辑生成 `new_weight`
+
return new_weight
- # 注意, PyTorch 不需要 sess 参数
+ def quantize_output(self, output, config, **kwargs):
+ """
+ 重载此方法输出量化
+ 此方法挂载于模型的 `:meth:`forward`。
+
+ Parameters
+ ----------
+ output : Tensor
+ 需要被量化的输出
+ config : dict
+ 输出量化的配置
+ """
+
+ # 实现生成 `new_output`
+
+ return new_output
+
+ def quantize_input(self, *inputs, config, **kwargs):
+ """
+ 重载此方法量化输入
+ 此方法挂载于模型的 :meth:`forward`。
+
+ Parameters
+ ----------
+ inputs : Tensor
+ 需要量化的输入
+ config : dict
+ 输入量化用的配置
+ """
+
+ # 实现生成 `new_input`
+
+ return new_input
+
+ # Pytorch 版本不需要 sess 参数
def update_epoch(self, epoch_num, sess):
pass
- # 注意, PyTorch 不需要 sess 参数
+ # Pytorch 版本不需要 sess 参数
def step(self, sess):
- # 根据在 bind_model 函数中引用的模型或权重进行一些处理
+ """
+ 根据需要可基于 bind_model 方法中的模型或权重进行操作
+ """
pass
```
-__[TODO]__ 添加成员函数 `quantize_layer_output`,用于支持量化层输出的量化算法。
-
### 使用用户自定义的压缩算法
__[TODO]__ ...
diff --git a/docs/zh_CN/Compressor/Pruner.md b/docs/zh_CN/Compressor/Pruner.md
index 6dc16bb12c..ab57596a43 100644
--- a/docs/zh_CN/Compressor/Pruner.md
+++ b/docs/zh_CN/Compressor/Pruner.md
@@ -3,7 +3,7 @@ NNI Compressor 中的 Pruner
## Level Pruner
-这是个基本的 Pruner:可设置目标稀疏度(以分数表示,0.6 表示会剪除 60%)。
+这是个基本的一次性 Pruner:可设置目标稀疏度(以分数表示,0.6 表示会剪除 60%)。
首先按照绝对值对指定层的权重排序。 然后按照所需的稀疏度,将值最小的权重屏蔽为 0。
@@ -13,16 +13,16 @@ TensorFlow 代码
```
from nni.compression.tensorflow import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
-pruner = LevelPruner(config_list)
-pruner(model_graph)
+pruner = LevelPruner(model_graph, config_list)
+pruner.compress()
```
PyTorch 代码
```
from nni.compression.torch import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
-pruner = LevelPruner(config_list)
-pruner(model)
+pruner = LevelPruner(model, config_list)
+pruner.compress()
```
#### Level Pruner 的用户配置
@@ -31,7 +31,7 @@ pruner(model)
***
## AGP Pruner
-在 [To prune, or not to prune: exploring the efficacy of pruning for model compression](https://arxiv.org/abs/1710.01878)中,作者 Michael Zhu 和 Suyog Gupta 提出了一种逐渐修建权重的算法。
+这是一种迭代的 Pruner,在 [To prune, or not to prune: exploring the efficacy of pruning for model compression](https://arxiv.org/abs/1710.01878)中,作者 Michael Zhu 和 Suyog Gupta 提出了一种逐渐修建权重的算法。
> 我们引入了一种新的自动梯度剪枝算法。这种算法从初始的稀疏度值 si(一般为 0)开始,通过 n 步的剪枝操作,增加到最终所需的稀疏度 sf。从训练步骤 t0 开始,以 ∆t 为剪枝频率:  在神经网络训练时‘逐步增加网络稀疏度时,每训练 ∆t 步更新一次权重剪枝的二进制掩码。同时也允许训练步骤恢复因为剪枝而造成的精度损失。 根据我们的经验,∆t 设为 100 到 1000 个训练步骤之间时,对于模型最终精度的影响可忽略不计。 一旦模型达到了稀疏度目标 sf,权重掩码将不再更新。 公式背后的稀疏函数直觉。
### 用法
@@ -50,8 +50,8 @@ config_list = [{
'frequency': 1,
'op_types': 'default'
}]
-pruner = AGP_Pruner(config_list)
-pruner(tf.get_default_graph())
+pruner = AGP_Pruner(tf.get_default_graph(), config_list)
+pruner.compress()
```
PyTorch 代码
```python
@@ -62,10 +62,10 @@ config_list = [{
'start_epoch': 0,
'end_epoch': 10,
'frequency': 1,
- 'op_types': 'default'
+ 'op_types': ['default']
}]
-pruner = AGP_Pruner(config_list)
-pruner(model)
+pruner = AGP_Pruner(model, config_list)
+pruner.compress()
```
其次,在训练代码中每完成一个 Epoch,更新一下 Epoch 数值。
@@ -89,3 +89,140 @@ pruner.update_epoch(epoch)
***
+## Lottery Ticket 假设
+[The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks](https://arxiv.org/abs/1803.03635), 作者 Jonathan Frankle 和 Michael Carbin,提供了全面的测量和分析,并阐明了 *lottery ticket 假设*: 密集的、随机初始化的、包含子网络的前馈网络 (*winning tickets*) -- 在单独训练时 -- 在相似的迭代次数后达到了与原始网络相似的准确度。
+
+本文中,作者使用叫做*迭代*修剪的方法:
+> 1. 随机初始化一个神经网络 f(x;theta_0) (其中 theta_0 为 D_{theta}).
+> 2. 将网络训练 j 次,得出参数 theta_j。
+> 3. 在 theta_j 修剪参数的 p%,创建掩码 m。
+> 4. 将其余参数重置为 theta_0 的值,创建获胜彩票 f(x;m*theta_0)。
+> 5. 重复步骤 2、3 和 4。
+
+如果配置的最终稀疏度为 P (e.g., 0.8) 并且有 n 次修建迭代,每次迭代修剪前一轮中剩余权重的 1-(1-P)^(1/n)。
+
+### 用法
+
+PyTorch 代码
+```python
+from nni.compression.torch import LotteryTicketPruner
+config_list = [{
+ 'prune_iterations': 5,
+ 'sparsity': 0.8,
+ 'op_types': ['default']
+}]
+pruner = LotteryTicketPruner(model, config_list, optimizer)
+pruner.compress()
+for _ in pruner.get_prune_iterations():
+ pruner.prune_iteration_start()
+ for epoch in range(epoch_num):
+ ...
+```
+
+上述配置意味着有 5 次迭代修剪。 由于在同一次运行中执行了 5 次修剪,LotteryTicketPruner 需要 `model` 和 `optimizer` (**注意,如果使用 `lr_scheduler`,也需要添加**) 来在每次开始新的修剪迭代时,将其状态重置为初始值。 使用 `get_prune_iterations` 来获取修建迭代,并在每次迭代开始时调用 `prune_iteration_start`。 为了模型能较好收敛,`epoch_num` 最好足够大。因为假设是在后几轮中具有较高稀疏度的性能(准确度)可与第一轮获得的相当。 [这是](./LotteryTicketHypothesis.md)简单的重现结果。
+
+
+*稍后支持 TensorFlow 版本。*
+
+#### LotteryTicketPruner 的用户配置
+
+* **prune_iterations:** 迭代修剪的次数。
+* **sparsity:** 压缩完成后的最终稀疏度。
+
+***
+## FPGM Pruner
+这是一种一次性的 Pruner,FPGM Pruner 是论文 [Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration](https://arxiv.org/pdf/1811.00250.pdf) 的实现
+> 以前的方法使用 “smaller-norm-less-important” 准则来修剪卷积神经网络中规范值较小的。 本文中,分析了基于规范的准则,并指出其所依赖的两个条件不能总是满足:(1) 过滤器的规范偏差应该较大;(2) 过滤器的最小规范化值应该很小。 为了解决此问题,提出了新的过滤器修建方法,即 Filter Pruning via Geometric Median (FPGM),可不考虑这两个要求来压缩模型。 与以前的方法不同,FPGM 通过修剪冗余的,而不是相关性更小的部分来压缩 CNN 模型。
+
+### 用法
+首先,导入 Pruner 来为模型添加遮盖。
+
+TensorFlow 代码
+```python
+from nni.compression.tensorflow import FPGMPruner
+config_list = [{
+ 'sparsity': 0.5,
+ 'op_types': ['Conv2D']
+}]
+pruner = FPGMPruner(model, config_list)
+pruner.compress()
+```
+PyTorch 代码
+```python
+from nni.compression.torch import FPGMPruner
+config_list = [{
+ 'sparsity': 0.5,
+ 'op_types': ['Conv2d']
+}]
+pruner = FPGMPruner(model, config_list)
+pruner.compress()
+```
+注意:FPGM Pruner 用于修剪深度神经网络中的卷积层,因此 `op_types` 字段仅支持卷积层。
+
+另外,需要在每个 epoch 开始的地方添加下列代码来更新 epoch 的编号。
+
+TensorFlow 代码
+```python
+pruner.update_epoch(epoch, sess)
+```
+PyTorch 代码
+```python
+pruner.update_epoch(epoch)
+```
+查看示例进一步了解
+
+#### FPGM Pruner 的用户配置
+* **sparsity:** 卷积过滤器要修剪的百分比。
+
+***
+
+## L1Filter Pruner
+
+这是一种一次性的 Pruner,由 ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710) 提出,作者 Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet 和 Hans Peter Graf。
+
+
+
+> L1Filter Pruner 修剪**卷积层**中的过滤器
+>
+> 从第 i 个卷积层修剪 m 个过滤器的过程如下:
+>
+> 1. 对于每个过滤器 ,计算其绝对内核权重之和
+> 2. 将过滤器按 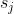 排序。
+> 3. 修剪 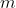 具有最小求和值及其相应特征图的筛选器。 在 下一个卷积层中,被剪除的特征图所对应的内核也被移除。
+> 4. 为第  和 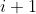 层创建新的内核举证,并保留剩余的内核 权重,并复制到新模型中。
+
+```
+from nni.compression.torch import L1FilterPruner
+config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }]
+pruner = L1FilterPruner(model, config_list)
+pruner.compress()
+```
+
+#### L1Filter Pruner 的用户配置
+
+- **sparsity:**,指定压缩的稀疏度。
+- **op_types:** 在 L1Filter Pruner 中仅支持 Conv2d。
+
+## Slim Pruner
+
+这是一次性的 Pruner,在 ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf) 中提出,作者 Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan 以及 Changshui Zhang。
+
+
+
+> Slim Pruner **会遮盖卷据层通道之后 BN 层对应的缩放因子**,训练时在缩放因子上的 L1 正规化应在批量正规化 (BN) 层之后来做。BN 层的缩放因子在修剪时,是**全局排序的**,因此稀疏模型能自动找到给定的稀疏度。
+
+### 用法
+
+PyTorch 代码
+
+```
+from nni.compression.torch import SlimPruner
+config_list = [{ 'sparsity': 0.8, 'op_types': ['BatchNorm2d'] }]
+pruner = SlimPruner(model, config_list)
+pruner.compress()
+```
+
+#### Slim Pruner 的用户配置
+
+- **sparsity:**,指定压缩的稀疏度。
+- **op_types:** 在 Slim Pruner 中仅支持 BatchNorm2d。
diff --git a/docs/zh_CN/Compressor/Quantizer.md b/docs/zh_CN/Compressor/Quantizer.md
index e87e73ea2c..6588963551 100644
--- a/docs/zh_CN/Compressor/Quantizer.md
+++ b/docs/zh_CN/Compressor/Quantizer.md
@@ -8,11 +8,11 @@ Naive Quantizer 将 Quantizer 权重默认设置为 8 位,可用它来测试
### 用法
Tensorflow
```python
-nni.compressors.tensorflow.NaiveQuantizer()(model_graph)
+nni.compressors.tensorflow.NaiveQuantizer(model_graph).compress()
```
PyTorch
```python
-nni.compressors.torch.NaiveQuantizer()(model)
+nni.compressors.torch.NaiveQuantizer(model).compress()
```
***
@@ -25,27 +25,36 @@ nni.compressors.torch.NaiveQuantizer()(model)
### 用法
可在训练代码前将模型量化为 8 位。
-TensorFlow 代码
-```python
-from nni.compressors.tensorflow import QAT_Quantizer
-config_list = [{ 'q_bits': 8, 'op_types': ['default'] }]
-quantizer = QAT_Quantizer(config_list)
-quantizer(tf.get_default_graph())
-```
PyTorch 代码
```python
from nni.compressors.torch import QAT_Quantizer
-config_list = [{ 'q_bits': 8, 'op_types': ['default'] }]
-quantizer = QAT_Quantizer(config_list)
-quantizer(model)
+model = Mnist()
+
+config_list = [{
+ 'quant_types': ['weight'],
+ 'quant_bits': {
+ 'weight': 8,
+ }, # 这里可以仅使用 `int`,因为所有 `quan_types` 使用了一样的位长,参考下方 `ReLu6` 配置。
+ 'op_types':['Conv2d', 'Linear']
+}, {
+ 'quant_types': ['output'],
+ 'quant_bits': 8,
+ 'quant_start_step': 7000,
+ 'op_types':['ReLU6']
+}]
+quantizer = QAT_Quantizer(model, config_list)
+quantizer.compress()
```
查看示例进一步了解
#### QAT Quantizer 的用户配置
-* **q_bits:** 指定需要被量化的位数。
-
+* **quant_types:**: 字符串列表 要应用的量化类型,当前支持 'weight', 'input', 'output'
+* **quant_bits:** int 或 {str : int} 的 dict 量化的位长,主键是量化类型,键值为长度,例如。 {'weight', 8}, 当类型为 int 时,所有量化类型都用同样的位长
+* **quant_start_step:** int 在运行到某步骤前,对模型禁用量化。这让网络在进入更稳定的 状态后再激活量化,这样不会配除掉一些分数显著的值,默认为 0
+### 注意
+当前不支持批处理规范化折叠。
***
## DoReFa Quantizer
@@ -58,18 +67,18 @@ TensorFlow 代码
```python
from nni.compressors.tensorflow import DoReFaQuantizer
config_list = [{ 'q_bits': 8, 'op_types': 'default' }]
-quantizer = DoReFaQuantizer(config_list)
-quantizer(tf.get_default_graph())
+quantizer = DoReFaQuantizer(tf.get_default_graph(), config_list)
+quantizer.compress()
```
PyTorch 代码
```python
from nni.compressors.torch import DoReFaQuantizer
config_list = [{ 'q_bits': 8, 'op_types': 'default' }]
-quantizer = DoReFaQuantizer(config_list)
-quantizer(model)
+quantizer = DoReFaQuantizer(model, config_list)
+quantizer.compress()
```
查看示例进一步了解
-#### QAT Quantizer 的用户配置
+#### DoReFa Quantizer 的用户配置
* **q_bits:** 指定需要被量化的位数。
diff --git a/docs/zh_CN/Compressor/SlimPruner.md b/docs/zh_CN/Compressor/SlimPruner.md
new file mode 100644
index 0000000000..f2c1a61c21
--- /dev/null
+++ b/docs/zh_CN/Compressor/SlimPruner.md
@@ -0,0 +1,39 @@
+NNI Compressor 中的 SlimPruner
+===
+
+## 1. Slim Pruner
+
+SlimPruner 是一种结构化的修剪算法,通过修剪卷积层后对应的 BN 层相应的缩放因子来修剪通道。
+
+在 ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf) 中提出,作者 Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan 以及 Changshui Zhang。
+
+
+
+> Slim Pruner **会遮盖卷据层通道之后 BN 层对应的缩放因子**,训练时在缩放因子上的 L1 正规化应在批量正规化 (BN) 层之后来做。BN 层的缩放因子在修剪时,是**全局排序的**,因此稀疏模型能自动找到给定的稀疏度。
+
+## 2. 用法
+
+PyTorch 代码
+
+```
+from nni.compression.torch import SlimPruner
+config_list = [{ 'sparsity': 0.8, 'op_types': ['BatchNorm2d'] }]
+pruner = SlimPruner(model, config_list)
+pruner.compress()
+```
+
+#### Filter Pruner 的用户配置
+
+- **sparsity:**,指定压缩的稀疏度。
+- **op_types:** 在 Slim Pruner 中仅支持 BatchNorm2d。
+
+## 3. 实验
+
+我们实现了 ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf) 中的一项实验。根据论文,对 CIFAR-10 上的 **VGGNet** 剪除了 $70\%$ 的通道,即约 $88.5\%$ 的参数。 我们的实验结果如下:
+
+| 模型 | 错误率(论文/我们的) | 参数量 | 剪除率 |
+| ------------- | ----------- | ------ | ----- |
+| VGGNet | 6.34/6.40 | 20.04M | |
+| Pruned-VGGNet | 6.20/6.26 | 2.03M | 88.5% |
+
+实验代码在 [examples/model_compress](https://github.com/microsoft/nni/tree/master/examples/model_compress/)
diff --git a/docs/zh_CN/FeatureEngineering/GBDTSelector.md b/docs/zh_CN/FeatureEngineering/GBDTSelector.md
new file mode 100644
index 0000000000..fa2ffddaee
--- /dev/null
+++ b/docs/zh_CN/FeatureEngineering/GBDTSelector.md
@@ -0,0 +1,61 @@
+## GBDTSelector
+
+GBDTSelector 基于 [LightGBM](https://github.com/microsoft/LightGBM),这是一个基于树学习算法的梯度提升框架。
+
+当将数据传递到 GBDT 模型时,该模型将构建提升树。 特征的重要性来自于构造时的分数,其表达了每个特征在模型构造提升决策树时有多有用。
+
+可使用此方法作为 Feature Selector 中较强的基准,特别是在使用 GBDT 模型进行分类或回归时。
+
+当前,支持的 `importance_type` 有 `split` 和 `gain`。 未来会支持定制 `importance_type`,也就是说用户可以定义如何计算`特征分数`。
+
+### 用法
+
+首先,安装依赖项:
+
+```
+pip install lightgbm
+```
+
+然后
+
+```python
+from nni.feature_engineering.gbdt_selector import GBDTSelector
+
+# 读取数据
+...
+X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
+
+# 初始化 Selector
+fgs = GBDTSelector()
+# 拟合数据
+fgs.fit(X_train, y_train, ...)
+# 获取重要的特征
+# 此处会返回重要特征的索引。
+print(fgs.get_selected_features(10))
+
+...
+```
+
+也可在 `/examples/feature_engineering/gbdt_selector/` 目录找到示例。
+
+
+**`fit` 函数参数要求**
+
+* **X** (数组,必需) - 训练的输入样本,shape = [n_samples, n_features]
+
+* **y** (数组,必需) - 目标值 (分类中为标签,回归中为实数),shape = [n_samples].
+
+* **lgb_params** (dict, 必需) - lightgbm 模型参数。 详情参考[这里](https://lightgbm.readthedocs.io/en/latest/Parameters.html)
+
+* **eval_ratio** (float, 必需) - 数据大小的比例 用于从 self.X 中拆分出评估和训练数据。
+
+* **early_stopping_rounds** (int, 必需) - lightgbm 中的提前终止设置。 详情参考[这里](https://lightgbm.readthedocs.io/en/latest/Parameters.html)。
+
+* **importance_type** (str, 必需) - 可为 'split' 或 'gain'。 'split' 表示 '结果包含特征在模型中使用的次数' 而 'gain' 表示 '结果包含此特征拆分出的总收益'。 详情参考[这里](https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.Booster.html#lightgbm.Booster.feature_importance)。
+
+* **num_boost_round** (int, 必需) - 提升的轮数。 详情参考[这里](https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html#lightgbm.train)。
+
+**`get_selected_features` 函数参数的要求**
+
+* **topk** (int, 必需) - 想要选择的 k 个最好的特征。
+
diff --git a/docs/zh_CN/FeatureEngineering/GradientFeatureSelector.md b/docs/zh_CN/FeatureEngineering/GradientFeatureSelector.md
new file mode 100644
index 0000000000..a5b170606a
--- /dev/null
+++ b/docs/zh_CN/FeatureEngineering/GradientFeatureSelector.md
@@ -0,0 +1,84 @@
+## GradientFeatureSelector
+
+GradinetFeatureSelector 的算法来源于 ["Feature Gradients: Scalable Feature Selection via Discrete Relaxation"](https://arxiv.org/pdf/1908.10382.pdf)。
+
+GradientFeatureSelector,基于梯度搜索算法的特征选择。
+
+1) 该方法扩展了一个近期的结果,即在亚线性数据中通过展示计算能迭代的学习(即,在迷你批处理中),在**线性的时间空间中**的特征数量 D 及样本大小 N。
+
+2) 这与在搜索领域的离散到连续的放松一起,可以在非常**大的数据集**上进行**高效、基于梯度**的搜索算法。
+
+3) 最重要的是,此算法能在特征和目标间为 N > D 和 N < D 都找到**高阶相关性**,这与只考虑一种情况和交互式的方法所不同。
+
+
+### 用法
+
+```python
+from nni.feature_engineering.gradient_selector import FeatureGradientSelector
+
+# 读取数据
+...
+X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
+
+# 初始化 Selector
+fgs = FeatureGradientSelector()
+# 拟合数据
+fgs.fit(X_train, y_train)
+# 获取重要的特征
+# 此处会返回重要特征的索引。
+print(fgs.get_selected_features())
+
+...
+```
+
+也可在 `/examples/feature_engineering/gradient_feature_selector/` 目录找到示例。
+
+**FeatureGradientSelector 构造函数的参数**
+
+* **order** (int, 可选, 默认为 4) - 要包含的交互顺序。 较高的顺序可能会更准确,但会增加运行时间。 12 是允许的顺序的最大值。
+
+* **penatly** (int, 可选, 默认为 1) - 乘以正则项的常数。
+
+* **n_features** (int, 可选, 默认为 None) - 如果为 None,会自动根据搜索来选择特征的数量。 否则,表示要选择的最好特征的数量。
+
+* **max_features** (int, 可选, 默认为 None) - 如果不为 None,会使用 'elbow method' 来确定以 max_features 为上限的特征数量。
+
+* **learning_rate** (float, 可选, 默认为 1e-1) - 学习率
+
+* **init** (*zero, on, off, onhigh, offhigh, 或 sklearn, 可选, 默认为zero*) - 如何初始化向量分数。 默认值为 'zero'。
+
+* **n_epochs** (int, 可选, 默认为 1) - 要运行的 Epoch 数量
+
+* **shuffle** (bool, 可选, 默认为 True) - 在 Epoch 之前需要随机化 "rows"。
+
+* **batch_size** (int, 可选, 默认为 1000) - 一次处理的 "rows" 数量。
+
+* **target_batch_size** (int, 可选, 默认为 1000) - 累计梯度的 "rows" 数量。 当行数过多无法读取到内存中,但估计精度所需。
+
+* **classification** (bool, 可选, 默认为 True) - 如果为 True,为分类问题,否则是回归问题。
+
+* **ordinal** (bool, 可选, 默认为 True) - 如果为 True,是有序的分类。 需要 classification 也为 True。
+
+* **balanced** (bool, 可选, 默认为 True) - 如果为 True,优化中每类的权重都一样,否则需要通过支持来对每类加权。 需要 classification 也为 True。
+
+* **prerocess** (str, 可选, 默认为 'zscore') - 'zscore' 是将数据中心化并归一化的党委方差,'center' 表示仅将数据均值调整到 0。
+
+* **soft_grouping** (bool, 可选, 默认为 True) - 如果为 True,将同一来源的特征分组到一起。 用于支持分组或组内特征的稀疏性。
+
+* **verbose** (int, 可选, 默认为 0) - 控制拟合时的信息详细程度。 设为 0 表示不打印,1 或更大值表示打印详细数量的步骤。
+
+* **device** (str, 可选, 默认为 'cpu') - 'cpu' 表示在 CPU 上运行,'cuda' 表示在 GPU 上运行。 在 GPU 上运行得更快
+
+
+**`fit` 函数参数要求**
+
+* **X** (数组,必需) - 训练的输入样本,shape = [n_samples, n_features]
+
+* **y** (数组,必需) - 目标值 (分类中为标签,回归中为实数),shape = [n_samples].
+
+* **groups** (数组, 可选, 默认为 None) - 必需选择为一个单元的列的分组。 例如 [0,0,1,2] 指定前两列是组的一部分。 形状是 [n_features]。
+
+**`get_selected_features` 函数参数的要求**
+
+ 目前, `get_selected_features` 函数没有参数。
+
diff --git a/docs/zh_CN/FeatureEngineering/Overview.md b/docs/zh_CN/FeatureEngineering/Overview.md
new file mode 100644
index 0000000000..d871c1a37c
--- /dev/null
+++ b/docs/zh_CN/FeatureEngineering/Overview.md
@@ -0,0 +1,255 @@
+# 特征工程
+
+我们很高兴的宣布,基于 NNI 的特征工程工具发布了 Alpha 版本。该版本仍处于试验阶段,根据使用反馈会进行改进。 诚挚邀请您使用、反馈,或更多贡献。
+
+当前支持以下特征选择器:
+- [GradientFeatureSelector](./GradientFeatureSelector.md)
+- [GBDTSelector](./GBDTSelector.md)
+
+
+# 如何使用
+
+```python
+from nni.feature_engineering.gradient_selector import GradientFeatureSelector
+# from nni.feature_engineering.gbdt_selector import GBDTSelector
+
+# 读取数据
+...
+X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
+
+# 初始化 Selector
+fgs = GradientFeatureSelector(...)
+# 拟合数据
+fgs.fit(X_train, y_train)
+# 获取重要的特征
+# 此处会返回重要特征的索引。
+print(fgs.get_selected_features(...))
+
+...
+```
+
+使用内置 Selector 时,需要 `import` 对应的特征选择器,并 `initialize`。 可在 Selector 中调用 `fit` 函数来传入数据。 之后,可通过 `get_seleteced_features` 来获得重要的特征。 不同 Selector 的函数参数可能不同,在使用前需要先检查文档。
+
+# 如何定制
+
+NNI 内置了_最先进的_特征工程算法的 Selector。 NNI 也支持定制自己的特征 Selector。
+
+如果要实现定制的特征 Selector,需要:
+
+1. 继承基类 FeatureSelector
+1. 实现 _fit_ 和 _get_selected_features_ 函数
+1. 与 sklearn 集成 (可选)
+
+示例如下:
+
+**1. 继承基类 FeatureSelector**
+
+```python
+from nni.feature_engineering.feature_selector import FeatureSelector
+
+class CustomizedSelector(FeatureSelector):
+ def __init__(self, ...):
+ ...
+```
+
+**2. 实现 _fit_ 和 _get_selected_features_ 函数**
+
+```python
+from nni.tuner import Tuner
+
+from nni.feature_engineering.feature_selector import FeatureSelector
+
+class CustomizedSelector(FeatureSelector):
+ def __init__(self, ...):
+ ...
+
+ def fit(self, X, y, **kwargs):
+ """
+ 将数据拟合到 FeatureSelector
+
+ 参数
+ ------------
+ X : numpy 矩阵
+ 训练输入样本,形状为 [n_samples, n_features]。
+ y: numpy 矩阵
+ 目标值 (分类中的类标签,回归中为实数)。 形状是 [n_samples]。
+ """
+ self.X = X
+ self.y = y
+ ...
+
+ def get_selected_features(self):
+ """
+ 获取重要特征
+
+ Returns
+ -------
+ list :
+ 返回重要特征的索引。
+ """
+ ...
+ return self.selected_features_
+
+ ...
+```
+
+**3. 与 sklearn 集成**
+
+`sklearn.pipeline.Pipeline` 可将模型连接在一起,例如特征选择,规范化,以及分类、回归,来组成一个典型的机器学习问题工作流。 下列步骤可帮助集成 sklearn,将定制的特征 Selector 作为管道的模块。
+
+1. 继承类 _sklearn.base.BaseEstimator_
+1. 实现 _BaseEstimator_ 中的 _get_params_ 和 _set_params_ 函数
+1. 继承类 _sklearn.feature_selection.base.SelectorMixin_
+1. 实现 _SelectorMixin_ 中的 _get_support_, _transform_ 和 _inverse_transform_ 函数
+
+示例如下:
+
+**1. 继承类 BaseEstimator 及其函数**
+
+```python
+from sklearn.base import BaseEstimator
+from nni.feature_engineering.feature_selector import FeatureSelector
+
+class CustomizedSelector(FeatureSelector, BaseEstimator):
+ def __init__(self, ...):
+ ...
+
+ def get_params(self, ...):
+ """
+ 为此 estimator 获取参数
+ """
+ params = self.__dict__
+ params = {key: val for (key, val) in params.items()
+ if not key.endswith('_')}
+ return params
+
+ def set_params(self, **params):
+ """
+ 为此 estimator 设置参数
+ """
+ for param in params:
+ if hasattr(self, param):
+ setattr(self, param, params[param])
+ return self
+
+```
+
+**2. 继承 SelectorMixin 类及其函数**
+```python
+from sklearn.base import BaseEstimator
+from sklearn.feature_selection.base import SelectorMixin
+
+from nni.feature_engineering.feature_selector import FeatureSelector
+
+class CustomizedSelector(FeatureSelector, BaseEstimator):
+ def __init__(self, ...):
+ ...
+
+ def get_params(self, ...):
+ """
+ 获取参数。
+ """
+ params = self.__dict__
+ params = {key: val for (key, val) in params.items()
+ if not key.endswith('_')}
+ return params
+
+ def set_params(self, **params):
+ """
+ 设置参数
+ """
+ for param in params:
+ if hasattr(self, param):
+ setattr(self, param, params[param])
+ return self
+
+ def get_support(self, indices=False):
+ """
+ 获取 mask,整数索引或选择的特征。
+
+ Parameters
+ ----------
+ indices : bool
+ 默认为 False. 如果为 True,返回值为整数数组,否则为布尔的 mask。
+
+ Returns
+ -------
+ list :
+ 返回 support: 从特征向量中选择保留的特征索引。
+ 如果 indices 为 False,布尔数据的形状为 [输入特征的数量],如果元素为 True,表示保留相对应的特征。
+ 如果 indices 为 True,整数数组的形状为 [输出特征的数量],值表示
+ 输入特征向量中的索引。
+ """
+ ...
+ return mask
+
+
+ def transform(self, X):
+ """将 X 减少为选择的特征。
+
+ Parameters
+ ----------
+ X : array
+ 形状为 [n_samples, n_features]
+
+ Returns
+ -------
+ X_r : array
+ 形状为 [n_samples, n_selected_features]
+ 仅输入选择的特征。
+ """
+ ...
+ return X_r
+
+
+ def inverse_transform(self, X):
+ """
+ 反转变换操作
+
+ Parameters
+ ----------
+ X : array
+ 形状为 [n_samples, n_selected_features]
+
+ Returns
+ -------
+ X_r : array
+ 形状为 [n_samples, n_original_features]
+ """
+ ...
+ return X_r
+```
+
+与 sklearn 继承后,可如下使用特征 Selector:
+```python
+from sklearn.linear_model import LogisticRegression
+
+# 加载数据
+...
+X_train, y_train = ...
+
+# 构造 pipeline
+pipeline = make_pipeline(XXXSelector(...), LogisticRegression())
+pipeline = make_pipeline(SelectFromModel(ExtraTreesClassifier(n_estimators=50)), LogisticRegression())
+pipeline.fit(X_train, y_train)
+
+# 分数
+print("Pipeline Score: ", pipeline.score(X_train, y_train))
+
+```
+
+# 基准测试
+
+`Baseline` 表示没有进行特征选择,直接将数据传入 LogisticRegression。 此基准测试中,仅用了 10% 的训练数据作为测试数据。
+
+| 数据集 | Baseline | GradientFeatureSelector | TreeBasedClassifier | 训练次数 | 特征数量 |
+| ------------- | -------- | ----------------------- | ------------------- | ---------- | --------- |
+| colon-cancer | 0.7547 | 0.7368 | 0.7223 | 62 | 2,000 |
+| gisette | 0.9725 | 0.89416 | 0.9792 | 6,000 | 5,000 |
+| avazu | 0.8834 | N/A | N/A | 40,428,967 | 1,000,000 |
+| rcv1 | 0.9644 | 0.7333 | 0.9615 | 20,242 | 47,236 |
+| news20.binary | 0.9208 | 0.6870 | 0.9070 | 19,996 | 1,355,191 |
+| real-sim | 0.9681 | 0.7969 | 0.9591 | 72,309 | 20,958 |
+
+此基准测试可在[这里](https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/)下载
+
diff --git a/docs/zh_CN/Makefile b/docs/zh_CN/Makefile
index 298ea9e213..51285967a7 100644
--- a/docs/zh_CN/Makefile
+++ b/docs/zh_CN/Makefile
@@ -16,4 +16,4 @@ help:
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
- @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
\ No newline at end of file
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/zh_CN/NAS/NasInterface.md b/docs/zh_CN/NAS/NasInterface.md
new file mode 100644
index 0000000000..372afc2e0d
--- /dev/null
+++ b/docs/zh_CN/NAS/NasInterface.md
@@ -0,0 +1,177 @@
+# NNI NAS 编程接口
+
+我们正在尝试通过统一的编程接口来支持各种 NAS 算法,当前处于试验阶段。 这意味着当前编程接口可能会进行重大变化。
+
+*先前的 [NAS annotation](../AdvancedFeature/GeneralNasInterfaces.md) 接口会很快被弃用。*
+
+## 模型的编程接口
+
+在两种场景下需要用于设计和搜索模型的编程接口。
+
+1. 在设计神经网络时,可能在层、子模型或连接上有多种选择,并且无法确定是其中一种或某些的组合的结果最好。 因此,需要简单的方法来表达候选的层或子模型。
+2. 在神经网络上应用 NAS 时,需要统一的方式来表达架构的搜索空间,这样不必为不同的搜索算法来更改代码。
+
+
+在用户代码中表示的神经网络搜索空间,可使用以下 API (以 PyTorch 为例):
+
+```python
+# 在 PyTorch module 类中
+def __init__(self):
+ ...
+ # 从 ``ops`` 中选择 ``ops``, 这是 PyTorch 中的 module。
+ # op_candidates: 在 PyTorch 中 ``ops`` 是 module 的 list,而在 TensorFlow 中是 Keras 层的 list。
+ # key: ``LayerChoice`` 实例的名称
+ self.one_layer = nni.nas.pytorch.LayerChoice([
+ PoolBN('max', channels, 3, stride, 1, affine=False),
+ PoolBN('avg', channels, 3, stride, 1, affine=False),
+ FactorizedReduce(channels, channels, affine=False),
+ SepConv(channels, channels, 3, stride, 1, affine=False),
+ DilConv(channels, channels, 3, stride, 2, 2, affine=False)],
+ key="layer_name")
+ ...
+
+def forward(self, x):
+ ...
+ out = self.one_layer(x)
+ ...
+```
+用户可为某层指定多个候选的操作,最后从其中选择一个。 `key` 是层的标识符,可被用来在多个 `LayerChoice` 间共享选项。 例如,两个 `LayerChoice` 有相同的候选操作,并希望能使用同样的选择,(即,如果第一个选择了第 `i` 个操作,第二个也应该选择第 `i` 个操作),则可给它们相同的 key。
+
+```python
+def __init__(self):
+ ...
+ # 从 ``n_candidates`` 个输入中选择 ``n_selected`` 个。
+ # n_candidates: 候选输入数量
+ # n_chosen: 选择的数量
+ # key: ``InputChoice`` 实例的名称
+ self.input_switch = nni.nas.pytorch.InputChoice(
+ n_candidates=3,
+ n_chosen=1,
+ key="switch_name")
+ ...
+
+def forward(self, x):
+ ...
+ out = self.input_switch([in_tensor1, in_tensor2, in_tensor3])
+ ...
+```
+`InputChoice` 是一个 PyTorch module,初始化时需要元信息,例如,从多少个输入后选中选择多少个输入,初始化的 `InputChoice` 名称。 真正候选的输入张量只能在 `forward` 函数中获得。 在 `InputChoice` 中,`forward` 会在调用时传入实际的候选输入张量。
+
+一些 [NAS Trainer](#one-shot-training-mode) 需要知道输入张量的来源层,因此在 `InputChoice` 中添加了输入参数 `choose_from` 来表示每个候选输入张量的来源层。 `choose_from` 是 str 的 list,每个元素都是 `LayerChoice` 和`InputChoice` 的 `key`,或者 module 的 name (详情参考[代码](https://github.com/microsoft/nni/blob/master/src/sdk/pynni/nni/nas/pytorch/mutables.py))。
+
+
+除了 `LayerChoice` 和 `InputChoice`,还提供了 `MutableScope`,可以让用户标记自网络,从而给 NAS Trainer 提供更多的语义信息 (如网络结构)。 示例如下:
+```python
+class Cell(mutables.MutableScope):
+ def __init__(self, scope_name):
+ super().__init__(scope_name)
+ self.layer1 = nni.nas.pytorch.LayerChoice(...)
+ self.layer2 = nni.nas.pytorch.LayerChoice(...)
+ self.layer3 = nni.nas.pytorch.LayerChoice(...)
+ ...
+```
+名为 `scope_name` 的 `MutableScope` 包含了三个 `LayerChoice` 层 (`layer1`, `layer2`, `layer3`)。 NAS Trainer 可获得这样的分层结构。
+
+
+## 两种训练模式
+
+在使用上述 API 在模型中嵌入 搜索空间后,下一步是从搜索空间中找到最好的模型。 有两种驯良模式:[one-shot 训练模式](#one-shot-training-mode) and [经典的分布式搜索](#classic-distributed-search)。
+
+### One-shot 训练模式
+
+与深度学习模型的优化器相似,从搜索空间中找到最好模型的过程可看作是优化过程,称之为 `NAS Trainer`。 NAS Trainer 包括 `DartsTrainer` 使用了 SGD 来交替训练架构和模型权重,`ENASTrainer` 使用 Controller 来训练模型。 新的、更高效的 NAS Trainer 在研究界不断的涌现出来。
+
+NNI 提供了一些流行的 NAS Trainer,要使用 NAS Trainer,用户需要在模型定义后初始化 Trainer:
+
+```python
+# 创建 DartsTrainer
+trainer = DartsTrainer(model,
+ loss=criterion,
+ metrics=lambda output, target: accuracy(output, target, topk=(1,)),
+ optimizer=optim,
+ num_epochs=args.epochs,
+ dataset_train=dataset_train,
+ dataset_valid=dataset_valid,)
+# 从搜索空间中找到最好的模型
+trainer.train()
+# 导出最好的模型
+trainer.export(file='./chosen_arch')
+```
+
+不同的 Trainer 可能有不同的输入参数,具体取决于其算法。 详细参数可参考具体的 [Trainer 代码](https://github.com/microsoft/nni/tree/master/src/sdk/pynni/nni/nas/pytorch)。 训练完成后,可通过 `trainer.export()` 导出找到的最好的模型。 无需通过 `nnictl` 来启动 NNI Experiment。
+
+[这里](./Overview.md#supported-one-shot-nas-algorithms)是所有支持的 Trainer。 [这里](https://github.com/microsoft/nni/tree/master/examples/nas/simple/train.py)是使用 NNI NAS API 的简单示例。
+
+[这里]()是完整示例的代码。
+
+### 经典分布式搜索
+
+神经网络架构搜索通过在 Trial 任务中独立运行单个子模型来实现。 NNI 同样支持这种搜索方法,其天然适用于 NNI 的超参搜索框架。Tuner 为每个 Trial 生成子模型,并在训练平台上运行。
+
+要使用此模式,不需要修改 NNI NAS API 的搜索空间定义 (即, `LayerChoice`, `InputChoice`, `MutableScope`)。 模型初始化后,在模型上调用 `get_and_apply_next_architecture`。 One-shot NAS Trainer 不能在此模式中使用。 简单示例:
+```python
+class Net(nn.Module):
+ # 使用 LayerChoice 和 InputChoice 的模型
+ ...
+
+model = Net()
+# 从 Tuner 中选择架构,并应用到模型上
+get_and_apply_next_architecture(model)
+# 训练模型
+train(model)
+# 测试模型
+acc = test(model)
+# 返回此架构的性能
+nni.report_final_result(acc)
+```
+
+搜索空间应自动生成,并发送给 Tuner。 通过 NNI NAS API,搜索空间嵌入在用户代码中,需要通过 "[nnictl ss_gen](../Tutorial/Nnictl.md)" 来生成搜索空间文件。 然后,将生成的搜索空间文件路径填入 `config.yml` 的 `searchSpacePath`。 `config.yml` 中的其它字段参考[教程](../Tutorial/QuickStart.md)。
+
+可使用 [NNI Tuner](../Tuner/BuiltinTuner.md) 来搜索。
+
+为了便于调试,其支持独立运行模式,可直接运行 Trial 命令,而不启动 NNI Experiment。 可以通过此方法来检查 Trial 代码是否可正常运行。 在独立模式下,`LayerChoice` 和 `InputChoice` 会选择最开始的候选项。
+
+[此处](https://github.com/microsoft/nni/tree/master/examples/nas/classic_nas/config_nas.yml)是完整示例。
+
+## NAS 算法的编程接口
+
+通过简单的接口,可在 NNI 上实现新的 NAS Trainer。
+
+### 在 NNI 上实现新的 NAS Trainer
+
+要实现新的 NAS Trainer,基本上只需要继承 `BaseMutator` 和 `BaseTrainer` 这两个类。
+
+在 `BaseMutator` 中,需要重载 `on_forward_layer_choice` 和 `on_forward_input_choice`,这是 `LayerChoice` 和 `InputChoice` 相应的实现。 可使用属性 `mutables` 来获得模型中所有的 `LayerChoice` 和 `InputChoice`。 然后实现新的 Trainer,来实例化新的 Mutator 并实现训练逻辑。 详细信息,可参考[代码](https://github.com/microsoft/nni/tree/master/src/sdk/pynni/nni/nas/pytorch),及支持的 Trainer,如 [DartsTrainer](https://github.com/microsoft/nni/tree/master/src/sdk/pynni/nni/nas/pytorch/darts)。
+
+### 为 NAS 实现 NNI Tuner
+
+NNI 中的 NAS Tuner 需要自动生成搜索空间。 `LayerChoice` 和 `InputChoice` 的搜索空间格式如下:
+```json
+{
+ "key_name": {
+ "_type": "layer_choice",
+ "_value": ["op1_repr", "op2_repr", "op3_repr"]
+ },
+ "key_name": {
+ "_type": "input_choice",
+ "_value": {
+ "candidates": ["in1_key", "in2_key", "in3_key"],
+ "n_chosen": 1
+ }
+ }
+}
+```
+
+相应的,生成的网络架构格式如下:
+```json
+{
+ "key_name": {
+ "_value": "op1_repr",
+ "_idx": 0
+ },
+ "key_name": {
+ "_value": ["in2_key"],
+ "_idex": [1]
+ }
+}
+```
\ No newline at end of file
diff --git a/docs/zh_CN/NAS/Overview.md b/docs/zh_CN/NAS/Overview.md
new file mode 100644
index 0000000000..7515d7dca6
--- /dev/null
+++ b/docs/zh_CN/NAS/Overview.md
@@ -0,0 +1,109 @@
+# 神经网络结构搜索在 NNI 上的应用
+
+自动化的神经网络架构(NAS)搜索在寻找更好的模型方面发挥着越来越重要的作用。 最近的研究工作证明了自动化 NAS 的可行性,并发现了一些超越手动设计和调整的模型。 代表算法有 [NASNet](https://arxiv.org/abs/1707.07012),[ENAS](https://arxiv.org/abs/1802.03268),[DARTS](https://arxiv.org/abs/1806.09055),[Network Morphism](https://arxiv.org/abs/1806.10282),以及 [Evolution](https://arxiv.org/abs/1703.01041) 等。 新的算法还在不断涌现。
+
+但是,要实现NAS算法需要花费大量的精力,并且很难在新算法中重用现有算法的代码。 为了促进 NAS 创新(例如,设计、实现新的 NAS 模型,并列比较不同的 NAS 模型),易于使用且灵活的编程接口非常重要。
+
+以此为动力,NNI 的目标是提供统一的体系结构,以加速NAS上的创新,并将最新的算法更快地应用于现实世界中的问题上。
+
+通过 [统一的接口](NasInterface.md),有两种方式进行架构搜索。 [第一种](#supported-one-shot-nas-algorithms)称为 one-shot NAS,基于搜索空间构建了一个超级网络,并使用 one-shot 训练来生成性能良好的子模型。 [第二种](.ClassicNas.md)是传统的搜索方法,搜索空间中每个子模型作为独立的 Trial 运行,将性能结果发给 Tuner,由 Tuner 来生成新的子模型。
+
+* [支持的 One-shot NAS 算法](#supported-one-shot-nas-algorithms)
+* [使用 NNI Experiment 的经典分布式 NAS](.NasInterface.md#classic-distributed-search)
+* [NNI NAS 编程接口](.NasInterface.md)
+
+## 支持的 One-shot NAS 算法
+
+NNI 现在支持以下 NAS 算法,并且正在添加更多算法。 用户可以重现算法或在自己的数据集上使用它。 鼓励用户使用 [NNI API](#use-nni-api) 实现其它算法,以使更多人受益。
+
+| 名称 | 算法简介 |
+| ------------------- | --------------------------------------------------------------------------------------------------------------------------------------------- |
+| [ENAS](#enas) | Efficient Neural Architecture Search via Parameter Sharing [参考论文](https://arxiv.org/abs/1802.03268) |
+| [DARTS](#darts) | DARTS: Differentiable Architecture Search [参考论文](https://arxiv.org/abs/1806.09055) |
+| [P-DARTS](#p-darts) | Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation [参考论文](https://arxiv.org/abs/1904.12760) |
+
+注意,这些算法**不需要 nnictl**,独立运行,仅支持 PyTorch。 将来的版本会支持 Tensorflow 2.0。
+
+### 依赖项
+
+* NNI 1.2+
+* tensorboard
+* PyTorch 1.2+
+* git
+
+### ENAS
+
+[Efficient Neural Architecture Search via Parameter Sharing](https://arxiv.org/abs/1802.03268). 在 ENAS 中,Contoller 学习在大的计算图中搜索最有子图的方式来发现神经网络。 它通过在子模型间共享参数来实现加速和出色的性能指标。
+
+#### 用法
+
+NNI 中的 ENAS 还在开发中,当前仅支持在 CIFAR10 上 Macro/Micro 搜索空间的搜索阶段。 在 PTB 上从头开始训练及其搜索空间尚未完成。
+
+```bash
+#如果未克隆 NNI 代码。 如果代码已被克隆,请忽略此行并直接进入代码目录。
+git clone https://github.com/Microsoft/nni.git
+
+# 搜索最好的网络架构
+cd examples/nas/enas
+
+# 在 Macro 搜索空间中搜索
+python3 search.py --search-for macro
+
+# 在 Micro 搜索空间中搜索
+python3 search.py --search-for micro
+
+# 查看更多选项
+python3 search.py -h
+```
+
+### DARTS
+
+[DARTS: Differentiable Architecture Search](https://arxiv.org/abs/1806.09055) 在算法上的主要贡献是,引入了一种在两级网络优化中使用的可微分算法。
+
+#### 用法
+
+```bash
+#如果未克隆 NNI 代码。 如果代码已被克隆,请忽略此行并直接进入代码目录。
+git clone https://github.com/Microsoft/nni.git
+
+# 搜索最好的架构
+cd examples/nas/darts
+python3 search.py
+
+# 训练最好的架构
+python3 retrain.py --arc-checkpoint ./checkpoints/epoch_49.json
+```
+
+### P-DARTS
+
+[Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation](https://arxiv.org/abs/1904.12760) 基于 [DARTS](#DARTS)。 它在算法上的主要贡献是引入了一种有效的算法,可在搜索过程中逐渐增加搜索的深度。
+
+#### 用法
+
+```bash
+#如果未克隆 NNI 代码。 如果代码已被克隆,请忽略此行并直接进入代码目录。
+git clone https://github.com/Microsoft/nni.git
+
+# 搜索最好的架构
+cd examples/nas/pdarts
+python3 search.py
+
+# 训练最好的架构,过程与 darts 相同。
+cd ../darts
+python3 retrain.py --arc-checkpoint ../pdarts/checkpoints/epoch_2.json
+```
+
+## 使用 NNI API
+
+注意,我们正在尝试通过统一的编程接口来支持各种 NAS 算法,当前处于试验阶段。 这意味着当前编程接口将来会有变化。
+
+*先前的 [NAS annotation](../AdvancedFeature/GeneralNasInterfaces.md) 接口会很快被弃用。*
+
+### 编程接口
+
+在两种场景下需要用于设计和搜索模型的编程接口。
+
+1. 在设计神经网络时,可能在层、子模型或连接上有多种选择,并且无法确定是其中一种或某些的组合的结果最好。 因此,需要简单的方法来表达候选的层或子模型。
+2. 在神经网络上应用 NAS 时,需要统一的方式来表达架构的搜索空间,这样不必为不同的搜索算法来更改代码。
+
+NNI 提出的 API 在[这里](https://github.com/microsoft/nni/tree/master/src/sdk/pynni/nni/nas/pytorch)。 [这里](https://github.com/microsoft/nni/tree/master/examples/nas/darts)包含了基于此 API 的 NAS 实现示例。
diff --git a/docs/zh_CN/TrainingService/LocalMode.md b/docs/zh_CN/TrainingService/LocalMode.md
index ec61ba8f19..9113653e6e 100644
--- a/docs/zh_CN/TrainingService/LocalMode.md
+++ b/docs/zh_CN/TrainingService/LocalMode.md
@@ -98,6 +98,7 @@
*builtinTunerName* 用来指定 NNI 中的 Tuner,*classArgs* 是传入到 Tuner的参数(内置 Tuner 在[这里](../Tuner/BuiltinTuner.md)),*optimization_mode* 表明需要最大化还是最小化 Trial 的结果。
**准备配置文件**:实现 Trial 的代码,并选择或实现自定义的 Tuner 后,就要准备 YAML 配置文件了。 NNI 为每个 Trial 样例都提供了演示的配置文件,用命令`cat ~/nni/examples/trials/mnist-annotation/config.yml` 来查看其内容。 大致内容如下:
+
```yaml
authorName: your_name
experimentName: auto_mnist
@@ -125,9 +126,9 @@ tuner:
optimize_mode: maximize
trial:
command: python mnist.py
- codeDir: ~/nni/examples/trialsmnist-annotation
+ codeDir: ~/nni/examples/trials/mnist-annotation
gpuNum: 0
- ```
+```
因为这个 Trial 代码使用了 NNI Annotation 的方法(参考[这里](../Tutorial/AnnotationSpec.md) ),所以*useAnnotation* 为 true。 *command* 是运行 Trial 代码所需要的命令,*codeDir* 是 Trial 代码的相对位置。 命令会在此目录中执行。 同时,也需要提供每个 Trial 进程所需的 GPU 数量。
diff --git a/docs/zh_CN/TrainingService/PaiMode.md b/docs/zh_CN/TrainingService/PaiMode.md
index 07bc8c328c..0191223f14 100644
--- a/docs/zh_CN/TrainingService/PaiMode.md
+++ b/docs/zh_CN/TrainingService/PaiMode.md
@@ -90,6 +90,23 @@ paiConfig:
portNumber: 1
```
+NNI 支持 OpenPAI 中的两种认证授权方法,即密码和 Token,[参考](https://github.com/microsoft/pai/blob/b6bd2ab1c8890f91b7ac5859743274d2aa923c22/docs/rest-server/API.md#2-authentication)。 认证在 `paiConfig` 字段中配置。
+密码认证的 `paiConfig` 配置如下:
+
+ paiConfig:
+ userName: your_pai_nni_user
+ passWord: your_pai_password
+ host: 10.1.1.1
+
+
+Token 认证的 `paiConfig` 配置如下:
+
+ paiConfig:
+ userName: your_pai_nni_user
+ token: your_pai_token
+ host: 10.1.1.1
+
+
完成并保存 NNI Experiment 配置文件后(例如可保存为:exp_pai.yml),运行以下命令:
nnictl create --config exp_pai.yml
@@ -109,7 +126,7 @@ paiConfig:
## 数据管理
-如果训练数据集不大,可放在 codeDir中,NNI会将其上传到 HDFS,或者构建 Docker 映像来包含数据。 如果数据集非常大,则不可放在 codeDir 中,可参考此[指南](https://github.com/microsoft/pai/blob/master/docs/user/storage.md)来将数据目录挂载到容器中。
+如果训练数据集不大,可放在 codeDir 中,NNI会将其上传到 HDFS,或者构建 Docker 映像来包含数据。 如果数据集非常大,则不可放在 codeDir 中,可参考此[指南](https://github.com/microsoft/pai/blob/master/docs/user/storage.md)来将数据目录挂载到容器中。
如果要将 Trial 的其它输出保存到 HDFS 上,如模型文件等,需要在 Trial 代码中使用 `NNI_OUTPUT_DIR` 来保存输出文件。NNI 的 SDK 会将文件从 Trial 容器的 `NNI_OUTPUT_DIR` 复制到 HDFS 上,目标路径为:`hdfs://host:port/{username}/nni/{experiments}/{experimentId}/trials/{trialId}/nnioutput`。
diff --git a/docs/zh_CN/TrainingService/RemoteMachineMode.md b/docs/zh_CN/TrainingService/RemoteMachineMode.md
index 3ad5d56fe8..fedae2dc7b 100644
--- a/docs/zh_CN/TrainingService/RemoteMachineMode.md
+++ b/docs/zh_CN/TrainingService/RemoteMachineMode.md
@@ -26,18 +26,18 @@ experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
-#可选项: local, remote, pai
+#choice: local, remote, pai
trainingServicePlatform: remote
# 搜索空间文件
searchSpacePath: search_space.json
-#可选项: true, false
+# 可选项: true, false
useAnnotation: true
tuner:
- #可选项: TPE, Random, Anneal, Evolution, BatchTuner
- #SMAC (SMAC 需要通过 nnictl 安装)
+ # 可选项: TPE, Random, Anneal, Evolution, BatchTuner
+ #SMAC (SMAC 需要先通过 nnictl 来安装)
builtinTunerName: TPE
classArgs:
- #可选项: maximize, minimize
+ # 可选项:: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
diff --git a/docs/zh_CN/TrialExample/GbdtExample.md b/docs/zh_CN/TrialExample/GbdtExample.md
index 9ea0b80092..6467d03213 100644
--- a/docs/zh_CN/TrialExample/GbdtExample.md
+++ b/docs/zh_CN/TrialExample/GbdtExample.md
@@ -48,7 +48,13 @@ GBDT 有很多超参,但哪些才会影响性能或计算速度呢? 基于
## 3. 如何运行 NNI
-### 3.1 准备 Trial 代码
+### 3.1 安装所有要求的包
+
+ pip install lightgbm
+ pip install pandas
+
+
+### 3.2 准备 Trial 代码
基础代码如下:
@@ -90,7 +96,7 @@ if __name__ == '__main__':
run(lgb_train, lgb_eval, PARAMS, X_test, y_test)
```
-### 3.2 准备搜索空间
+### 3.3 准备搜索空间
如果要调优 `num_leaves`, `learning_rate`, `bagging_fraction` 和 `bagging_freq`, 可创建一个 [search_space.json](https://github.com/Microsoft/nni/blob/master/examples/trials/auto-gbdt/search_space.json) 文件:
@@ -105,7 +111,7 @@ if __name__ == '__main__':
参考[这里](../Tutorial/SearchSpaceSpec.md),了解更多变量类型。
-### 3.3 在代码中使用 NNI SDK
+### 3.4 在代码中使用 NNI SDK
```diff
+import nni
@@ -153,7 +159,7 @@ if __name__ == '__main__':
run(lgb_train, lgb_eval, PARAMS, X_test, y_test)
```
-### 3.4 实现配置文件并运行
+### 3.5 实现配置文件并运行
在配置文件中,可以设置如下内容:
diff --git a/docs/zh_CN/Tuner/BuiltinTuner.md b/docs/zh_CN/Tuner/BuiltinTuner.md
index 87263a734e..76f6d694d2 100644
--- a/docs/zh_CN/Tuner/BuiltinTuner.md
+++ b/docs/zh_CN/Tuner/BuiltinTuner.md
@@ -120,7 +120,7 @@ tuner:
* **optimize_mode** (*maximize 或 minimize, 可选项, 默认值为 maximize*) - 如果为 'maximize',表示 Tuner 的目标是将指标最大化。 如果为 'minimize',表示 Tuner 的目标是将指标最小化。
-* **population_size** (*int 类型(大于 0), 可选项, 默认值为 20*) - 表示遗传 Tuner 中的种群(Trial 数量)。
+* **population_size** (*int 类型(大于 0), 可选项, 默认值为 20*) - 表示遗传 Tuner 中的种群(Trial 数量)。 建议 `population_size` 比 `concurrency` 取值更大,这样用户能充分利用算法(至少要等于 `concurrency`,否则 Tuner 在生成第一代参数的时候就会失败)。
**示例**
@@ -145,7 +145,7 @@ tuner:
**安装**
-SMAC 在第一次使用前,必须用下面的命令先安装。
+SMAC 在第一次使用前,必须用下面的命令先安装。 注意:SMAC 依赖于 `swig`,Ubuntu 下可通过 `apt` 命令来安装 `swig`。
```bash
nnictl package install --name=SMAC
diff --git a/docs/zh_CN/Tutorial/Contributing.md b/docs/zh_CN/Tutorial/Contributing.md
index 9c7ed85a2b..8f7c752b06 100644
--- a/docs/zh_CN/Tutorial/Contributing.md
+++ b/docs/zh_CN/Tutorial/Contributing.md
@@ -43,6 +43,9 @@
* NNI 遵循 [PEP8](https://www.python.org/dev/peps/pep-0008/) 的 Python 代码命名约定。在提交拉取请求时,请尽量遵循此规范。 可通过`flake8`或`pylint`的提示工具来帮助遵循规范。
* NNI 还遵循 [NumPy Docstring 风格](https://www.sphinx-doc.org/en/master/usage/extensions/example_numpy.html#example-numpy) 的 Python Docstring 命名方案。 Python API 使用了[sphinx.ext.napoleon](https://www.sphinx-doc.org/en/master/usage/extensions/napoleon.html) 来[生成文档](Contributing.md#documentation)。
+* 有关 docstrings,参考 [numpydoc docstring 指南](https://numpydoc.readthedocs.io/en/latest/format.html) 和 [pandas docstring 指南](https://python-sprints.github.io/pandas/guide/pandas_docstring.html)
+ * 函数的 docstring, **description**, **Parameters**, 以及**Returns**/**Yields** 是必需的。
+ * 类的 docstring, **description**, **Attributes** 是必需的。
## 文档
diff --git a/docs/zh_CN/Tutorial/Nnictl.md b/docs/zh_CN/Tutorial/Nnictl.md
index 42fe630ff9..91e89ad1e8 100644
--- a/docs/zh_CN/Tutorial/Nnictl.md
+++ b/docs/zh_CN/Tutorial/Nnictl.md
@@ -22,6 +22,7 @@ nnictl 支持的命令:
* [nnictl webui](#webui)
* [nnictl tensorboard](#tensorboard)
* [nnictl package](#package)
+* [nnictl ss_gen](#ss_gen)
* [nnictl --version](#version)
### 管理 Experiment
@@ -742,6 +743,38 @@ nnictl 支持的命令:
nnictl package show
```
+
+
+ `生成搜索空间`
+
+* **nnictl ss_gen**
+
+ * 说明
+
+ 从使用 NNI NAS API 的用户代码生成搜索空间。
+
+ * 用法
+
+ ```bash
+ nnictl ss_gen [OPTIONS]
+ ```
+
+ * 选项
+
+ | 参数及缩写 | 是否必需 | 默认值 | 说明 |
+ | --------------- | ----- | ---------------------------------- | ----------- |
+ | --trial_command | True | | Trial 代码的命令 |
+ | --trial_dir | False | ./ | Trial 代码目录 |
+ | --file | False | nni_auto_gen_search_space.json | 用来存储生成的搜索空间 |
+
+ * 示例
+
+ > 生成搜索空间
+
+ ```bash
+ nnictl ss_gen --trial_command="python3 mnist.py" --trial_dir=./ --file=ss.json
+ ```
+
 `检查 NNI 版本`
diff --git a/docs/zh_CN/Tutorial/QuickStart.md b/docs/zh_CN/Tutorial/QuickStart.md
index 2c92384b1b..1de21c9f9a 100644
--- a/docs/zh_CN/Tutorial/QuickStart.md
+++ b/docs/zh_CN/Tutorial/QuickStart.md
@@ -101,7 +101,7 @@ NNI 用来帮助超参调优。它的流程如下:
mnist_network.train(sess, mnist)
test_acc = mnist_network.evaluate(mnist)
-+ nni.report_final_result(acc)
++ nni.report_final_result(test_acc)
if __name__ == '__main__':
@@ -253,4 +253,4 @@ Experiment 相关信息会显示在界面上,配置和搜索空间等。 可
* [如何在多机上运行 Experiment?](../TrainingService/RemoteMachineMode.md)
* [如何在 OpenPAI 上运行 Experiment?](../TrainingService/PaiMode.md)
* [如何通过 Kubeflow 在 Kubernetes 上运行 Experiment?](../TrainingService/KubeflowMode.md)
-* [如何通过 FrameworkController 在 Kubernetes 上运行 Experiment?](../TrainingService/FrameworkControllerMode.md)
\ No newline at end of file
+* [如何通过 FrameworkController 在 Kubernetes 上运行 Experiment?](../TrainingService/FrameworkControllerMode.md)
diff --git a/docs/zh_CN/Tutorial/SearchSpaceSpec.md b/docs/zh_CN/Tutorial/SearchSpaceSpec.md
index 9e6a228dc0..961e555ecd 100644
--- a/docs/zh_CN/Tutorial/SearchSpaceSpec.md
+++ b/docs/zh_CN/Tutorial/SearchSpaceSpec.md
@@ -21,6 +21,8 @@
将第一行作为样例。 `dropout_rate` 定义了一个变量,先验分布为均匀分布,范围从 `0.1` 到 `0.5`。
+注意,搜索空间的效果与 Tuner 高度相关。 此处列出了内置 Tuner 所支持的类型。 对于自定义的 Tuner,不必遵循鞋标,可使用任何的类型。
+
## 类型
所有采样策略和参数如下:
@@ -78,12 +80,6 @@
* 这表示变量值会类似于 `round(exp(normal(mu, sigma)) / q) * q`
* 适用于值是“平滑”的离散变量,但某一边有界。
-* `{"_type": "mutable_layer", "_value": {mutable_layer_infomation}}`
-
- * [神经网络架构搜索空间](../AdvancedFeature/GeneralNasInterfaces.md)的类型。 值是字典类型,键值对表示每个 mutable_layer 的名称和搜索空间。
- * 当前,只能通过 Annotation 来使用这种类型的搜索空间。因此不需要为搜索空间定义 JSON 文件,它会通过 Trial 中的 Annotation 自动生成。
- * 具体用法参考[通用 NAS 接口](../AdvancedFeature/GeneralNasInterfaces.md)。
-
## 每种 Tuner 支持的搜索空间类型
| | choice | randint | uniform | quniform | loguniform | qloguniform | normal | qnormal | lognormal | qlognormal |
@@ -106,4 +102,4 @@
* 请注意,对于嵌套搜索空间:
* 只有 随机搜索/TPE/Anneal/Evolution Tuner 支持嵌套搜索空间
- * 不支持嵌套搜索空间 "超参" 的可视化,对其的改进通过 #1110(https://github.com/microsoft/nni/issues/1110) 来跟踪 。欢迎任何建议和贡献。
\ No newline at end of file
+ * 不支持嵌套搜索空间 "超参" 的可视化,对其的改进通过 [#1110](https://github.com/microsoft/nni/issues/1110) 来跟踪 。欢迎任何建议和贡献。
\ No newline at end of file
diff --git a/docs/zh_CN/advanced.rst b/docs/zh_CN/advanced.rst
index bd5c8e1112..d71726d83e 100644
--- a/docs/zh_CN/advanced.rst
+++ b/docs/zh_CN/advanced.rst
@@ -3,5 +3,3 @@
.. toctree::
多阶段<./AdvancedFeature/MultiPhase>
- 高级网络架构搜索<./AdvancedFeature/AdvancedNas>
- NAS 编程接口<./AdvancedFeature/GeneralNasInterfaces>
\ No newline at end of file
diff --git a/docs/zh_CN/feature_engineering.rst b/docs/zh_CN/feature_engineering.rst
new file mode 100644
index 0000000000..9244153c38
--- /dev/null
+++ b/docs/zh_CN/feature_engineering.rst
@@ -0,0 +1,16 @@
+#################
+特征工程
+#################
+
+很高兴的宣布 NNI 的特征工程包 Alpha 版本发布了。
+其仍处于试验阶段,会根据使用反馈来演化。
+诚挚邀请您使用、反馈,或更多贡献。
+
+详细信息,参考以下教程:
+
+.. toctree::
+ :maxdepth: 2
+
+ 概述
+ GradientFeatureSelector
+ GBDTSelector
diff --git a/docs/zh_CN/model_compression.rst b/docs/zh_CN/model_compression.rst
new file mode 100644
index 0000000000..34d05b4844
--- /dev/null
+++ b/docs/zh_CN/model_compression.rst
@@ -0,0 +1,28 @@
+#################
+模型压缩
+#################
+
+NNI 提供了易于使用的工具包来帮助用户设计并使用压缩算法。
+其使用了统一的接口来支持 TensorFlow 和 PyTorch。
+只需要添加几行代码即可压缩模型。
+NNI 中也内置了一些流程的模型压缩算法。
+用户可以进一步利用 NNI 的自动调优功能找到最佳的压缩模型,
+自动模型压缩部分有详细介绍。
+另一方面,用户可以使用 NNI 的接口自定义新的压缩算法。
+
+详细信息,参考以下教程:
+
+.. toctree::
+ :maxdepth: 2
+
+ 概述
+ Level Pruner
+ AGP Pruner
+ L1Filter Pruner
+ Slim Pruner
+ Lottery Ticket Pruner
+ FPGM Pruner
+ Naive Quantizer
+ QAT Quantizer
+ DoReFa Quantizer
+ 自动模型压缩
diff --git a/docs/zh_CN/nas.rst b/docs/zh_CN/nas.rst
new file mode 100644
index 0000000000..9bcb1483d8
--- /dev/null
+++ b/docs/zh_CN/nas.rst
@@ -0,0 +1,25 @@
+#################
+NAS 算法
+#################
+
+自动化的神经网络架构(NAS)搜索在寻找更好的模型方面发挥着越来越重要的作用。
+最近的研究工作证明了自动化 NAS 的可行性,并发现了一些超越手动设计和调整的模型。
+代表工作有 NASNet, ENAS, DARTS, Network Morphism, 以及 Evolution 等。 新的算法还在不断涌现。
+
+但是,要实现NAS算法需要花费大量的精力,并且很难在新算法中重用现有算法的代码。
+为了促进 NAS 创新 (如, 设计实现新的 NAS 模型,比较不同的 NAS 模型),
+易于使用且灵活的编程接口非常重要。
+
+以此为出发点,我们的目标是在 NNI 中提供统一的架构,
+来加速 NAS 创新,并更快的将最先进的算法用于现实世界的问题上。
+
+详细信息,参考以下教程:
+
+.. toctree::
+ :maxdepth: 2
+
+ 概述
+ NAS 接口
+ ENAS
+ DARTS
+ P-DARTS
diff --git a/docs/zh_CN/sdk_reference.rst b/docs/zh_CN/sdk_reference.rst
index 58aa6898a5..14e892ed0e 100644
--- a/docs/zh_CN/sdk_reference.rst
+++ b/docs/zh_CN/sdk_reference.rst
@@ -24,10 +24,10 @@ Tuner(调参器)
.. autoclass:: nni.evolution_tuner.evolution_tuner.EvolutionTuner
:members:
-.. autoclass:: nni.smac_tuner.smac_tuner.SMACTuner
+.. autoclass:: nni.smac_tuner.SMACTuner
:members:
-.. autoclass:: nni.gridsearch_tuner.gridsearch_tuner.GridSearchTuner
+.. autoclass:: nni.gridsearch_tuner.GridSearchTuner
:members:
.. autoclass:: nni.networkmorphism_tuner.networkmorphism_tuner.NetworkMorphismTuner
@@ -36,15 +36,27 @@ Tuner(调参器)
.. autoclass:: nni.metis_tuner.metis_tuner.MetisTuner
:members:
+.. autoclass:: nni.ppo_tuner.PPOTuner
+ :members:
+
+.. autoclass:: nni.batch_tuner.batch_tuner.BatchTuner
+ :members:
+
+.. autoclass:: nni.gp_tuner.gp_tuner.GPTuner
+ :members:
+
Assessor(评估器)
------------------------
.. autoclass:: nni.assessor.Assessor
:members:
-.. autoclass:: nni.curvefitting_assessor.curvefitting_assessor.CurvefittingAssessor
+.. autoclass:: nni.assessor.AssessResult
+ :members:
+
+.. autoclass:: nni.curvefitting_assessor.CurvefittingAssessor
:members:
-.. autoclass:: nni.medianstop_assessor.medianstop_assessor.MedianstopAssessor
+.. autoclass:: nni.medianstop_assessor.MedianstopAssessor
:members:
@@ -57,4 +69,4 @@ Advisor
:members:
.. autoclass:: nni.bohb_advisor.bohb_advisor.BOHB
- :members:
\ No newline at end of file
+ :members:
diff --git a/docs/zh_CN/tutorials.rst b/docs/zh_CN/tutorials.rst
index 7e96972c3f..e8e2c61919 100644
--- a/docs/zh_CN/tutorials.rst
+++ b/docs/zh_CN/tutorials.rst
@@ -9,6 +9,9 @@
实现 Trial<./TrialExample/Trials>
Tuner
Assessor
+ NAS (Beta)
+ 模型压缩 (Beta)
+ 特征工程 (Beta)
Web 界面
训练平台
如何使用 Docker