Chicago is a small-scale data warehouse library written in Ruby.
This library focuses on the following:
- Defining a model that represents a Star Schema.
- Creation of migrations to manipulate one or more concrete database schemas to reflect the model.
- Querying data in a Star Schema.
It heavily uses and is influenced by the sequel library. This library itself provides no ETL functionality; there is a highly unfinished/experimental library for this at chicago-etl
gem install chicagowarehouse
If you are new to star schemas in general, I recommend reading The Data Warehouse Toolkit by Ralph Kimball & Margy Ross. Briefly though, a star schema is a sem-denormalised style of database design optimized for reporting-style queries. In a star schema, there are two types of tables:
- Fact tables store measures that can be summed or averaged, together with keys to Dimensions.
- Dimension tables store denormalised data with which you may want to group or filter facts.
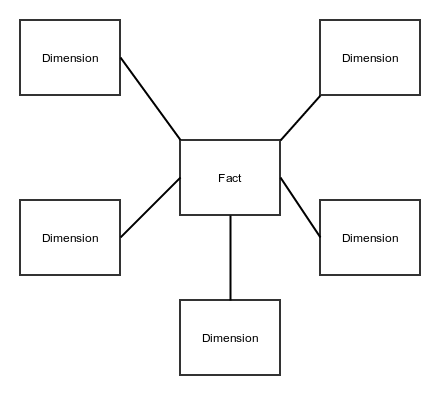
Generally speaking, the only links are between 1 fact table and several dimension tables: facts are not joined to facts, dimensions are not joined to dimensions - this gives the star schema its name, as you can see in the picture below:
Not all standard star schema features are implemented yet - probably the most important ommission is that Type II and Type III dimensions are not supported (dimensions that retain historic information).
Features that are supported include:
- Fact & Type I Dimensions tables
- Measures, additive & semi-additive
- Degenerate Dimensions
- Null Records
- Dimensions with predetermined values
- Key tables for ETL processes, supporting both single integer keys and hash keys for dimensions without an original primary key
- Calculated columns
Defining models:
require 'chicago'
SCHEMA = Chicago::StarSchema.new
SCHEMA.define_dimension(:product) do
columns do
integer :original_id
string :name, :default => "Unknown Product"
money :price
# ...
end
identified_by :name
natural_key :original_id
null_record :original_id => 0
end
# ...
SCHEMA.define_fact(:sales) do
dimensions :product, :customer
degenerate_dimensions do
integer :order_id
end
measures do
money :total
integer :number_of_items
end
endOnce you have a schema defined, you can use the inbuilt tasks to create the underlying database schema in your Rakefile:
DB = Sequel.connect() # with your db connection parameters
Chicago::RakeTasks.new(SCHEMA, :staging_db => DB)Which gives the following tasks:
db:write_migrations- creates migration files in a migrations directory - use the standard Sequel migration tool to run them;db:create_null_records- creates null records in the database.
After you have some data, you can query your schema like so:
query = {
:table_name => "sales",
:query_type => "fact",
:columns => ["sales.product.name",
{:column => "sales.total", :op => "sum"}]
}
sequel_dataset = Chicago::Query.new(SCHEMA, query).dataset
# Do whatever you like with this dataset, for example just returning
# all records:
sequel_dataset.allThe query hash is intended to be easy to represent in JSON. Notice how
unlike just using base Sequel, you didn't have to define any JOIN or
GROUP BY parts to the query - these are inferred from the model.
To get specs passing, you'll need to create a test myqsl database, and copy spec/database.yml.dist to spec/database.yml and populate it appropriately.