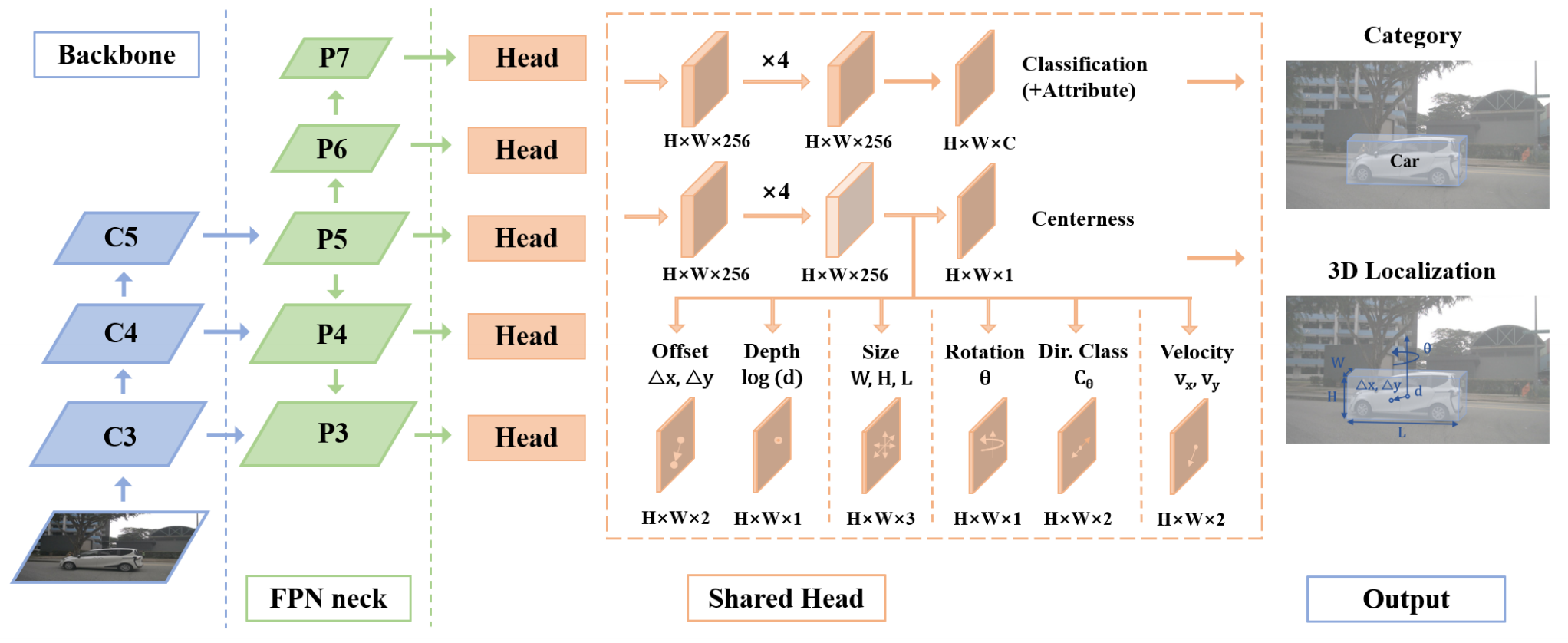
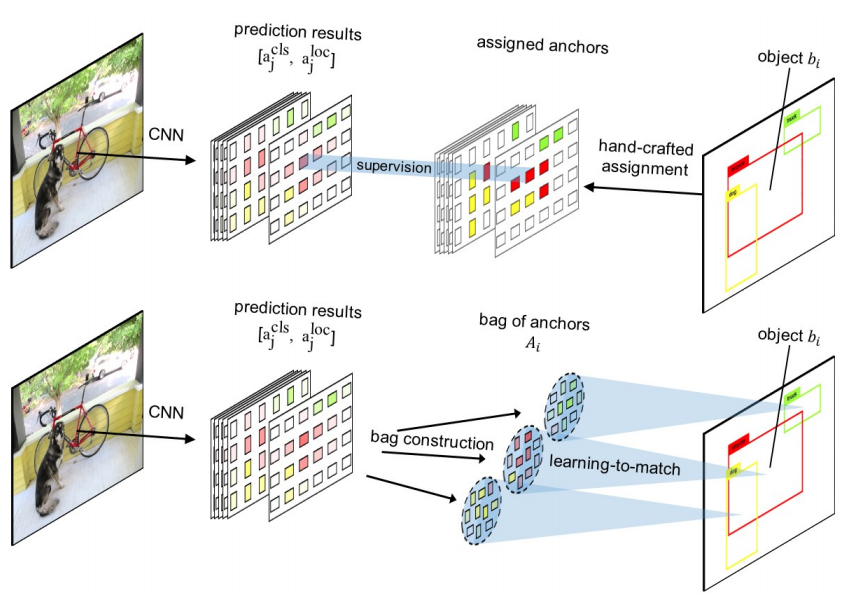
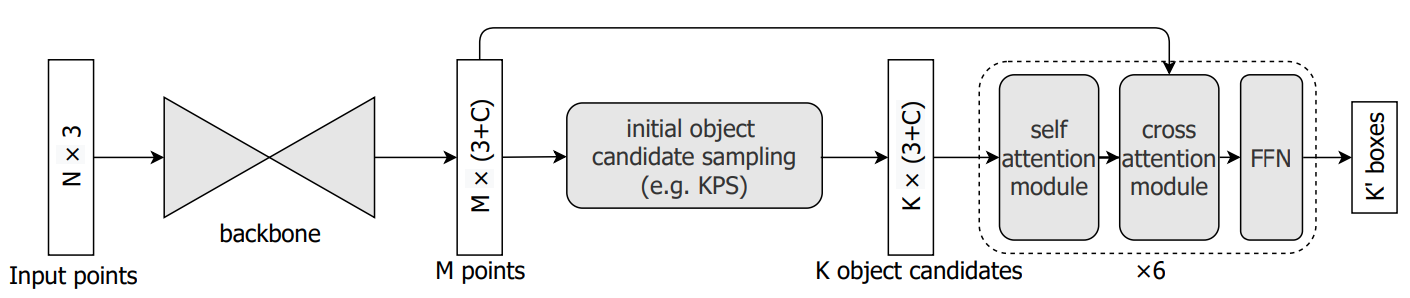
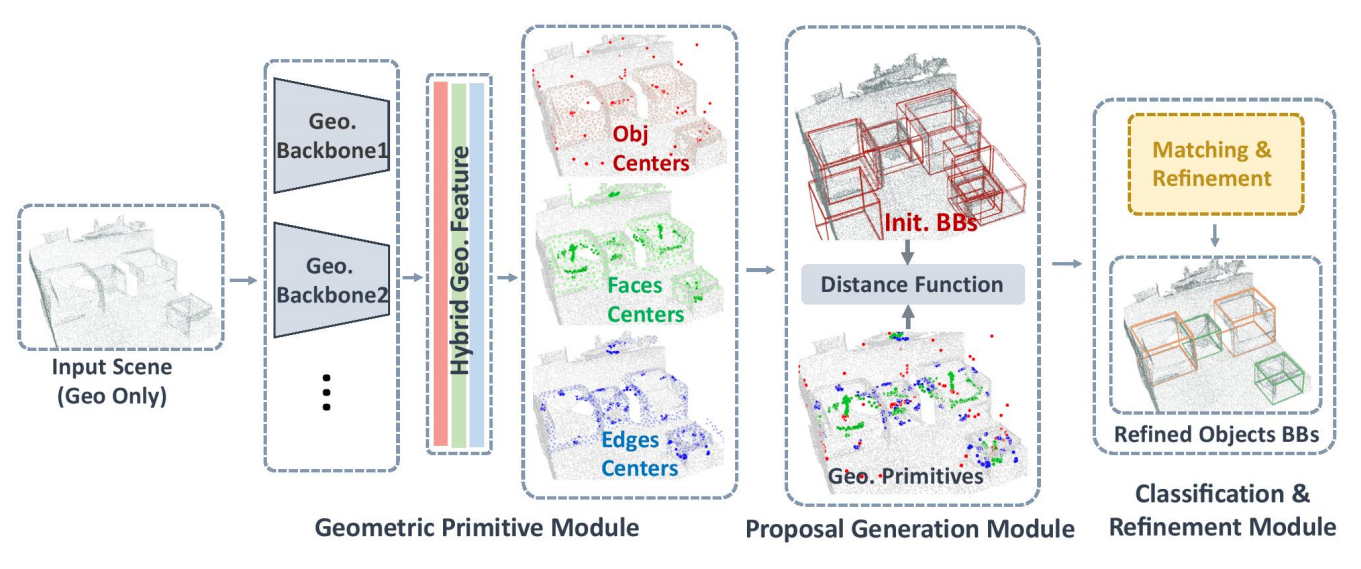
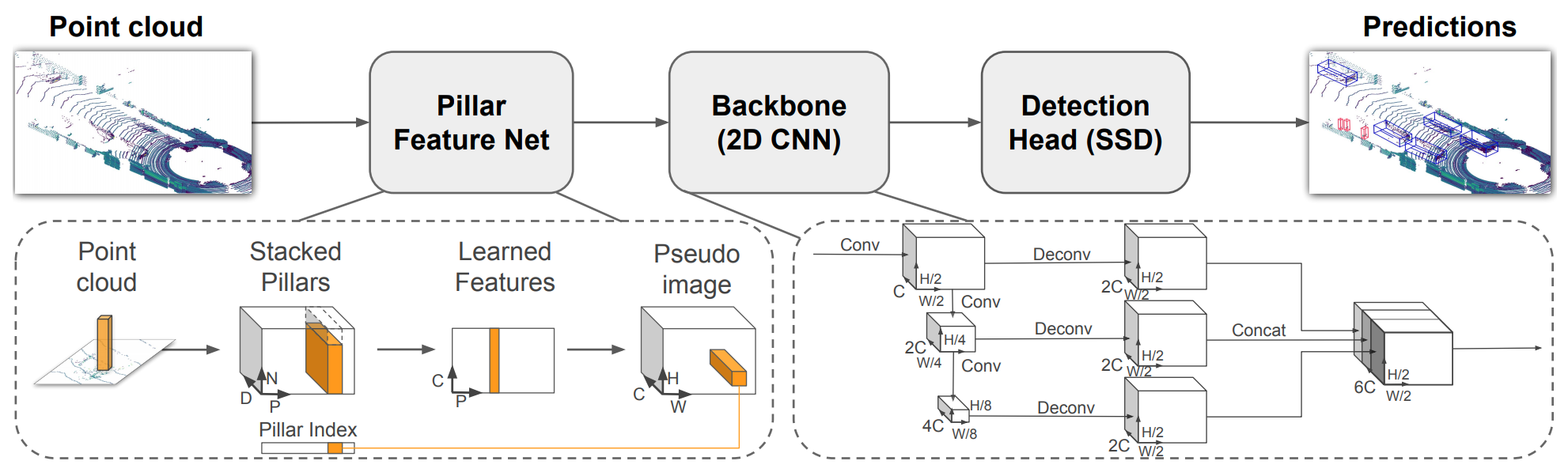
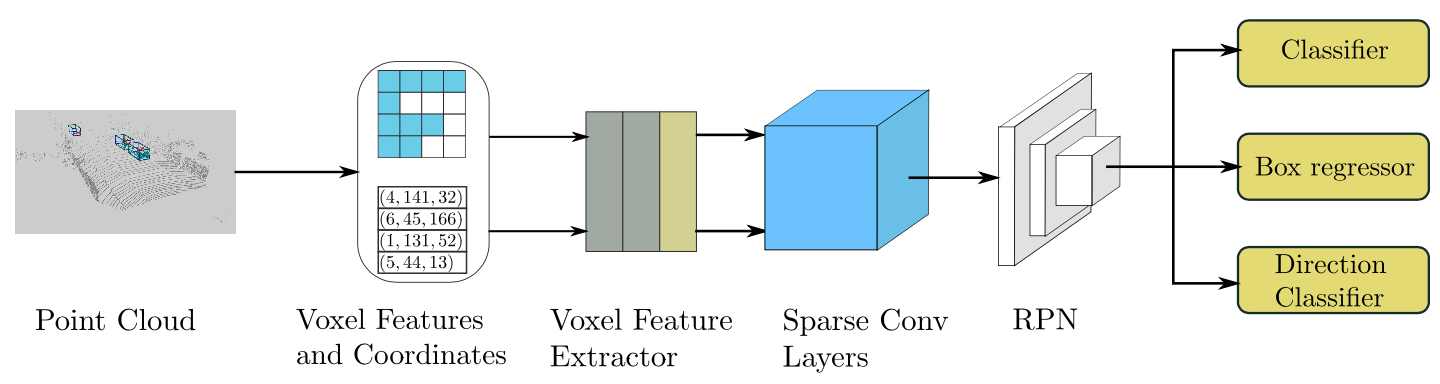
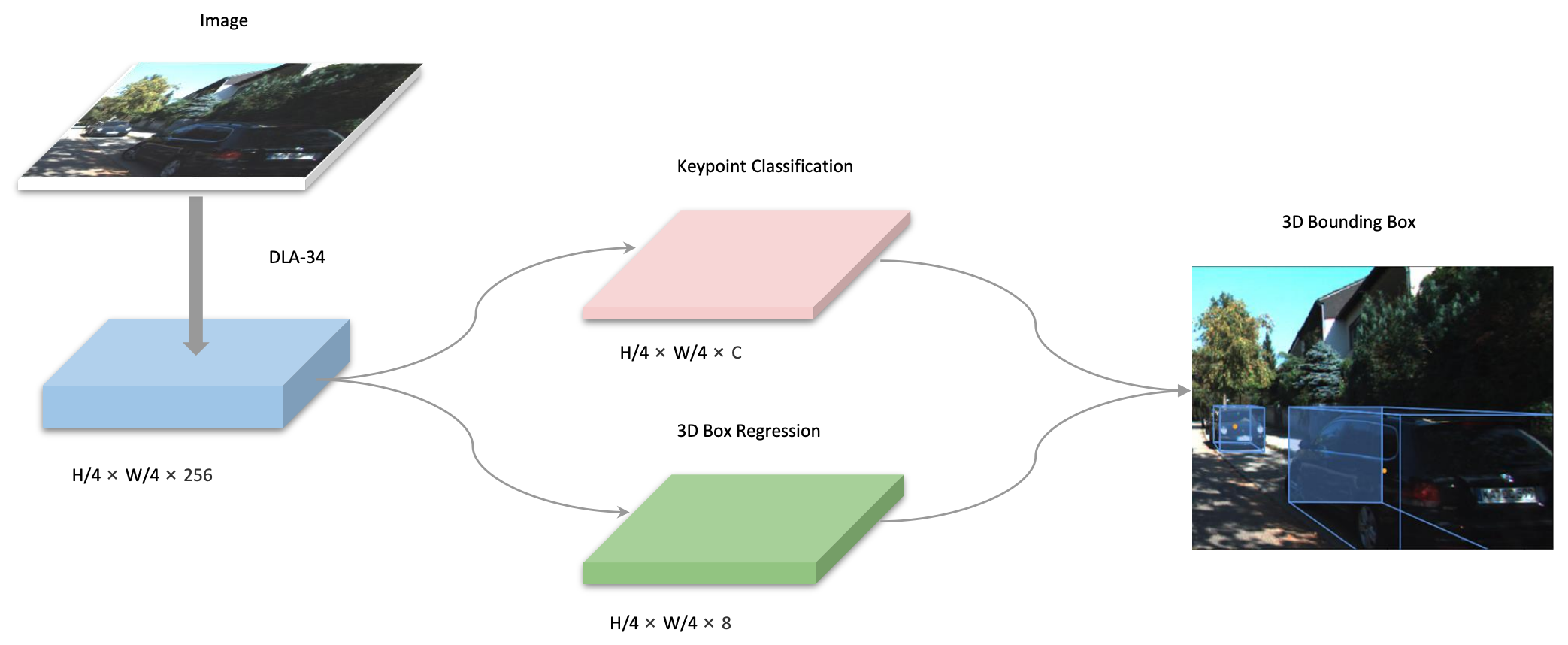
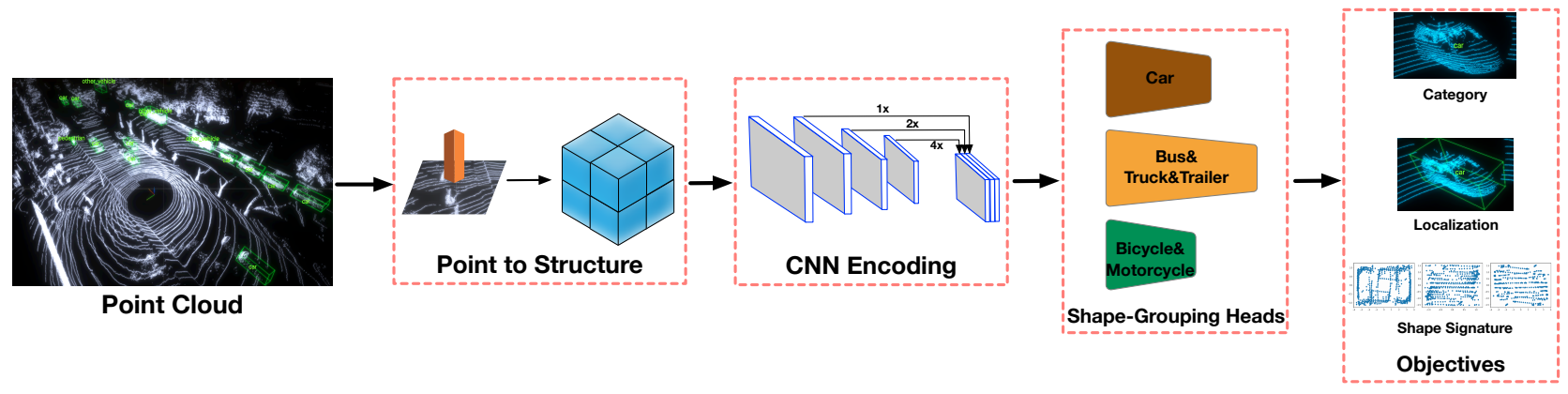
diff --git a/configs/3dssd/README.md b/configs/3dssd/README.md
index 61d9c71afb..579ed25cd3 100644
--- a/configs/3dssd/README.md
+++ b/configs/3dssd/README.md
@@ -1,44 +1,28 @@
# 3DSSD: Point-based 3D Single Stage Object Detector
-## Abstract
+> [3DSSD: Point-based 3D Single Stage Object Detector](https://arxiv.org/abs/2002.10187)
-
+
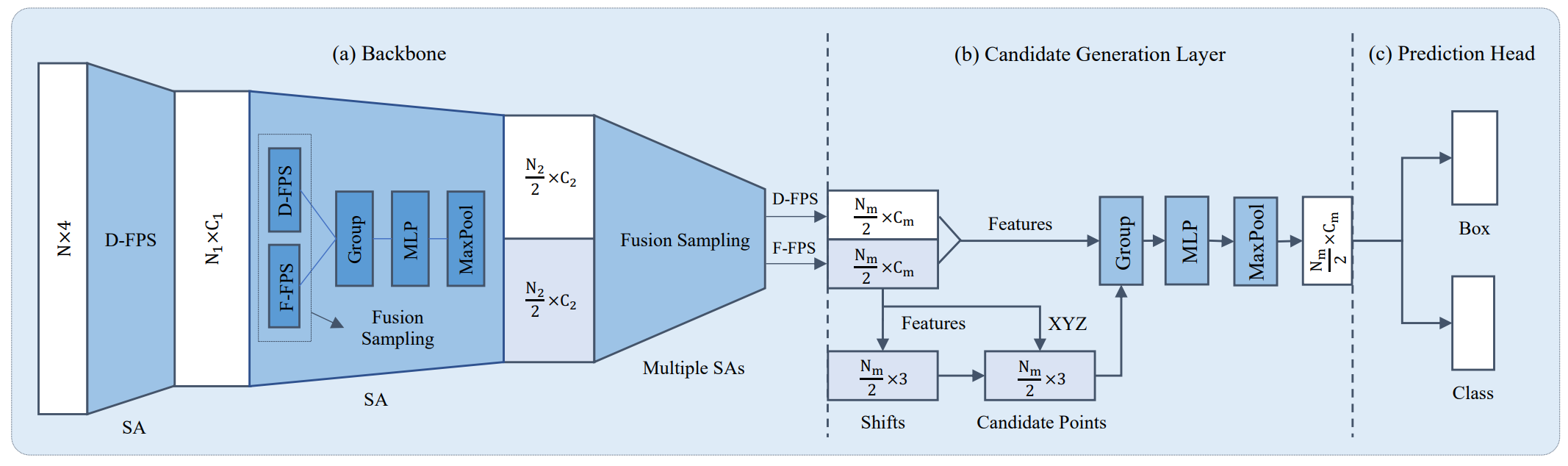
-Currently, there have been many kinds of voxel-based 3D single stage detectors, while point-based single stage methods are still underexplored. In this paper, we first present a lightweight and effective point-based 3D single stage object detector, named 3DSSD, achieving a good balance between accuracy and efficiency. In this paradigm, all upsampling layers and refinement stage, which are indispensable in all existing point-based methods, are abandoned to reduce the large computation cost. We novelly propose a fusion sampling strategy in downsampling process to make detection on less representative points feasible. A delicate box prediction network including a candidate generation layer, an anchor-free regression head with a 3D center-ness assignment strategy is designed to meet with our demand of accuracy and speed. Our paradigm is an elegant single stage anchor-free framework, showing great superiority to other existing methods. We evaluate 3DSSD on widely used KITTI dataset and more challenging nuScenes dataset. Our method outperforms all state-of-the-art voxel-based single stage methods by a large margin, and has comparable performance to two stage point-based methods as well, with inference speed more than 25 FPS, 2x faster than former state-of-the-art point-based methods.
+## Abstract
-
+Currently, there have been many kinds of voxel-based 3D single stage detectors, while point-based single stage methods are still underexplored. In this paper, we first present a lightweight and effective point-based 3D single stage object detector, named 3DSSD, achieving a good balance between accuracy and efficiency. In this paradigm, all upsampling layers and refinement stage, which are indispensable in all existing point-based methods, are abandoned to reduce the large computation cost. We novelly propose a fusion sampling strategy in downsampling process to make detection on less representative points feasible. A delicate box prediction network including a candidate generation layer, an anchor-free regression head with a 3D center-ness assignment strategy is designed to meet with our demand of accuracy and speed. Our paradigm is an elegant single stage anchor-free framework, showing great superiority to other existing methods. We evaluate 3DSSD on widely used KITTI dataset and more challenging nuScenes dataset. Our method outperforms all state-of-the-art voxel-based single stage methods by a large margin, and has comparable performance to two stage point-based methods as well, with inference speed more than 25 FPS, 2x faster than former state-of-the-art point-based methods.
-
-
-
## Introduction
-
-
We implement 3DSSD and provide the results and checkpoints on KITTI datasets.
-```
-@inproceedings{yang20203dssd,
- author = {Zetong Yang and Yanan Sun and Shu Liu and Jiaya Jia},
- title = {3DSSD: Point-based 3D Single Stage Object Detector},
- booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- year = {2020}
-}
-```
-
-### Experiment details on KITTI datasets
-
Some settings in our implementation are different from the [official implementation](https://github.com/Jia-Research-Lab/3DSSD), which bring marginal differences to the performance on KITTI datasets in our experiments. To simplify and unify the models of our implementation, we skip them in our models. These differences are listed as below:
1. We keep the scenes without any object while the official code skips these scenes in training. In the official implementation, only 3229 and 3394 samples are used as training and validation sets, respectively. In our implementation, we keep using 3712 and 3769 samples as training and validation sets, respectively, as those used for all the other models in our implementation on KITTI datasets.
2. We do not modify the decay of `batch normalization` during training.
3. While using [`DataBaseSampler`](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/datasets/pipelines/dbsampler.py#L80) for data augmentation, the official code uses road planes as reference to place the sampled objects while we do not.
4. We perform detection using LIDAR coordinates while the official code uses camera coordinates.
-## Results
+## Results and models
### KITTI
@@ -47,3 +31,14 @@ Some settings in our implementation are different from the [official implementat
| [PointNet2SAMSG](./3dssd_4x4_kitti-3d-car.py)| Car |72e|4.7||78.69(81.27)1|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/3dssd/3dssd_kitti-3d-car_20210602_124438-b4276f56.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/3dssd/3dssd_kitti-3d-car_20210602_124438.log.json)|
[1]: We report two different 3D object detection performance here. 78.69mAP is evaluated by our evaluation code and 81.27mAP is evaluated by the official development kit (so as that used in the paper and official code of 3DSSD ). We found that the commonly used Python implementation of [`rotate_iou`](https://github.com/traveller59/second.pytorch/blob/e42e4a0e17262ab7d180ee96a0a36427f2c20a44/second/core/non_max_suppression/nms_gpu.py#L605) which is used in our KITTI dataset evaluation, is different from the official implementation in [KITTI benchmark](http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d).
+
+## Citation
+
+```latex
+@inproceedings{yang20203dssd,
+ author = {Zetong Yang and Yanan Sun and Shu Liu and Jiaya Jia},
+ title = {3DSSD: Point-based 3D Single Stage Object Detector},
+ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ year = {2020}
+}
+```
diff --git a/configs/centerpoint/README.md b/configs/centerpoint/README.md
index 9b545a7428..76016cb789 100644
--- a/configs/centerpoint/README.md
+++ b/configs/centerpoint/README.md
@@ -1,24 +1,19 @@
# Center-based 3D Object Detection and Tracking
-## Abstract
+> [Center-based 3D Object Detection and Tracking](https://arxiv.org/abs/2006.11275)
-
+
-Three-dimensional objects are commonly represented as 3D boxes in a point-cloud. This representation mimics the well-studied image-based 2D bounding-box detection but comes with additional challenges. Objects in a 3D world do not follow any particular orientation, and box-based detectors have difficulties enumerating all orientations or fitting an axis-aligned bounding box to rotated objects. In this paper, we instead propose to represent, detect, and track 3D objects as points. Our framework, CenterPoint, first detects centers of objects using a keypoint detector and regresses to other attributes, including 3D size, 3D orientation, and velocity. In a second stage, it refines these estimates using additional point features on the object. In CenterPoint, 3D object tracking simplifies to greedy closest-point matching. The resulting detection and tracking algorithm is simple, efficient, and effective. CenterPoint achieved state-of-the-art performance on the nuScenes benchmark for both 3D detection and tracking, with 65.5 NDS and 63.8 AMOTA for a single model. On the Waymo Open Dataset, CenterPoint outperforms all previous single model method by a large margin and ranks first among all Lidar-only submissions.
+## Abstract
-
+Three-dimensional objects are commonly represented as 3D boxes in a point-cloud. This representation mimics the well-studied image-based 2D bounding-box detection but comes with additional challenges. Objects in a 3D world do not follow any particular orientation, and box-based detectors have difficulties enumerating all orientations or fitting an axis-aligned bounding box to rotated objects. In this paper, we instead propose to represent, detect, and track 3D objects as points. Our framework, CenterPoint, first detects centers of objects using a keypoint detector and regresses to other attributes, including 3D size, 3D orientation, and velocity. In a second stage, it refines these estimates using additional point features on the object. In CenterPoint, 3D object tracking simplifies to greedy closest-point matching. The resulting detection and tracking algorithm is simple, efficient, and effective. CenterPoint achieved state-of-the-art performance on the nuScenes benchmark for both 3D detection and tracking, with 65.5 NDS and 63.8 AMOTA for a single model. On the Waymo Open Dataset, CenterPoint outperforms all previous single model method by a large margin and ranks first among all Lidar-only submissions.
-
-
-
## Introduction
-
-
We implement CenterPoint and provide the result and checkpoints on nuScenes dataset.
We follow the below style to name config files. Contributors are advised to follow the same style.
@@ -42,15 +37,6 @@ We follow the below style to name config files. Contributors are advised to foll
`{dataset}`: dataset like nus-3d, kitti-3d, lyft-3d, scannet-3d, sunrgbd-3d. We also indicate the number of classes we are using if there exist multiple settings, e.g., kitti-3d-3class and kitti-3d-car means training on KITTI dataset with 3 classes and single class, respectively.
-```
-@article{yin2021center,
- title={Center-based 3D Object Detection and Tracking},
- author={Yin, Tianwei and Zhou, Xingyi and Kr{\"a}henb{\"u}hl, Philipp},
- journal={CVPR},
- year={2021},
-}
-```
-
## Usage
### Test time augmentation
@@ -118,7 +104,7 @@ data = dict(
```
-## Results
+## Results and models
### CenterPoint
@@ -139,3 +125,14 @@ data = dict(
|above w/o circle nms|pillar (0.2)|✗|✗| | |49.12|59.66||
|[SECFPN](./centerpoint_02pillar_second_secfpn_dcn_4x8_cyclic_20e_nus.py)|pillar (0.2)|✓|✗| 4.6| |48.8 |59.67 |[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/centerpoint/centerpoint_02pillar_second_secfpn_dcn_4x8_cyclic_20e_nus/centerpoint_02pillar_second_secfpn_dcn_4x8_cyclic_20e_nus_20200930_103722-3bb135f2.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/centerpoint/centerpoint_02pillar_second_secfpn_dcn_4x8_cyclic_20e_nus/centerpoint_02pillar_second_secfpn_dcn_4x8_cyclic_20e_nus_20200930_103722.log.json)|
|above w/ circle nms|pillar (0.2)|✓|✓| | |48.79|59.65||
+
+## Citation
+
+```latex
+@article{yin2021center,
+ title={Center-based 3D Object Detection and Tracking},
+ author={Yin, Tianwei and Zhou, Xingyi and Kr{\"a}henb{\"u}hl, Philipp},
+ journal={CVPR},
+ year={2021},
+}
+```
diff --git a/configs/dgcnn/README.md b/configs/dgcnn/README.md
index 5b4bddca74..20819f5b25 100644
--- a/configs/dgcnn/README.md
+++ b/configs/dgcnn/README.md
@@ -1,38 +1,24 @@
# Dynamic Graph CNN for Learning on Point Clouds
-## Abstract
+> [Dynamic Graph CNN for Learning on Point Clouds](https://arxiv.org/abs/1801.07829)
-
+
-Point clouds provide a flexible geometric representation suitable for countless applications in computer graphics; they also comprise the raw output of most 3D data acquisition devices. While hand-designed features on point clouds have long been proposed in graphics and vision, however, the recent overwhelming success of convolutional neural networks (CNNs) for image analysis suggests the value of adapting insight from CNN to the point cloud world. Point clouds inherently lack topological information so designing a model to recover topology can enrich the representation power of point clouds. To this end, we propose a new neural network module dubbed EdgeConv suitable for CNN-based high-level tasks on point clouds including classification and segmentation. EdgeConv acts on graphs dynamically computed in each layer of the network. It is differentiable and can be plugged into existing architectures. Compared to existing modules operating in extrinsic space or treating each point independently, EdgeConv has several appealing properties: It incorporates local neighborhood information; it can be stacked applied to learn global shape properties; and in multi-layer systems affinity in feature space captures semantic characteristics over potentially long distances in the original embedding. We show the performance of our model on standard benchmarks including ModelNet40, ShapeNetPart, and S3DIS.
+## Abstract
-
+Point clouds provide a flexible geometric representation suitable for countless applications in computer graphics; they also comprise the raw output of most 3D data acquisition devices. While hand-designed features on point clouds have long been proposed in graphics and vision, however, the recent overwhelming success of convolutional neural networks (CNNs) for image analysis suggests the value of adapting insight from CNN to the point cloud world. Point clouds inherently lack topological information so designing a model to recover topology can enrich the representation power of point clouds. To this end, we propose a new neural network module dubbed EdgeConv suitable for CNN-based high-level tasks on point clouds including classification and segmentation. EdgeConv acts on graphs dynamically computed in each layer of the network. It is differentiable and can be plugged into existing architectures. Compared to existing modules operating in extrinsic space or treating each point independently, EdgeConv has several appealing properties: It incorporates local neighborhood information; it can be stacked applied to learn global shape properties; and in multi-layer systems affinity in feature space captures semantic characteristics over potentially long distances in the original embedding. We show the performance of our model on standard benchmarks including ModelNet40, ShapeNetPart, and S3DIS.
-
-
-
## Introduction
-
-
We implement DGCNN and provide the results and checkpoints on S3DIS dataset.
-```
-@article{dgcnn,
- title={Dynamic Graph CNN for Learning on Point Clouds},
- author={Wang, Yue and Sun, Yongbin and Liu, Ziwei and Sarma, Sanjay E. and Bronstein, Michael M. and Solomon, Justin M.},
- journal={ACM Transactions on Graphics (TOG)},
- year={2019}
-}
-```
-
**Notice**: We follow the implementations in the original DGCNN paper and a PyTorch implementation of DGCNN [code](https://github.com/AnTao97/dgcnn.pytorch).
-## Results
+## Results and models
### S3DIS
@@ -56,3 +42,14 @@ We implement DGCNN and provide the results and checkpoints on S3DIS dataset.
## Indeterminism
Since DGCNN testing adopts sliding patch inference which involves random point sampling, and the test script uses fixed random seeds while the random seeds of validation in training are not fixed, the test results may be slightly different from the results reported above.
+
+## Citation
+
+```latex
+@article{dgcnn,
+ title={Dynamic Graph CNN for Learning on Point Clouds},
+ author={Wang, Yue and Sun, Yongbin and Liu, Ziwei and Sarma, Sanjay E. and Bronstein, Michael M. and Solomon, Justin M.},
+ journal={ACM Transactions on Graphics (TOG)},
+ year={2019}
+}
+```
diff --git a/configs/dynamic_voxelization/README.md b/configs/dynamic_voxelization/README.md
index e41b438e43..18ac4309cc 100644
--- a/configs/dynamic_voxelization/README.md
+++ b/configs/dynamic_voxelization/README.md
@@ -1,27 +1,34 @@
# Dynamic Voxelization
-## Abstract
+> [End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds](https://arxiv.org/abs/1910.06528)
-
+
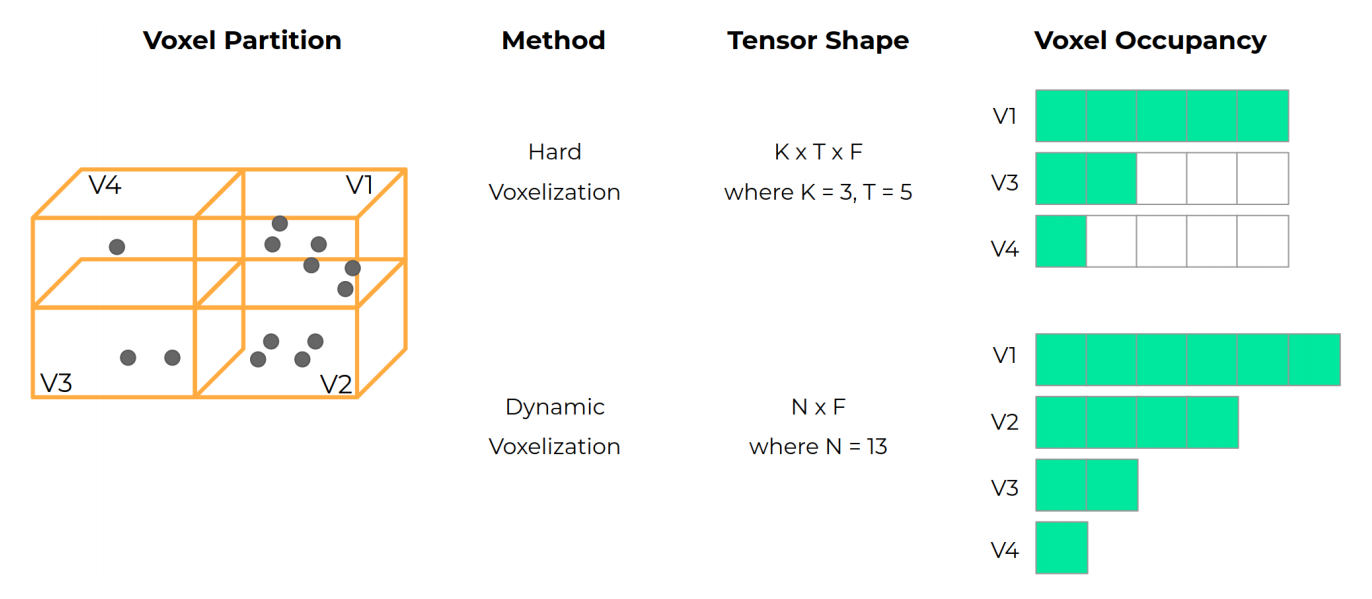
-Recent work on 3D object detection advocates point cloud voxelization in birds-eye view, where objects preserve their physical dimensions and are naturally separable. When represented in this view, however, point clouds are sparse and have highly variable point density, which may cause detectors difficulties in detecting distant or small objects (pedestrians, traffic signs, etc.). On the other hand, perspective view provides dense observations, which could allow more favorable feature encoding for such cases. In this paper, we aim to synergize the birds-eye view and the perspective view and propose a novel end-to-end multi-view fusion (MVF) algorithm, which can effectively learn to utilize the complementary information from both. Specifically, we introduce dynamic voxelization, which has four merits compared to existing voxelization methods, i) removing the need of pre-allocating a tensor with fixed size; ii) overcoming the information loss due to stochastic point/voxel dropout; iii) yielding deterministic voxel embeddings and more stable detection outcomes; iv) establishing the bi-directional relationship between points and voxels, which potentially lays a natural foundation for cross-view feature fusion. By employing dynamic voxelization, the proposed feature fusion architecture enables each point to learn to fuse context information from different views. MVF operates on points and can be naturally extended to other approaches using LiDAR point clouds. We evaluate our MVF model extensively on the newly released Waymo Open Dataset and on the KITTI dataset and demonstrate that it significantly improves detection accuracy over the comparable single-view PointPillars baseline.
+## Abstract
-
+Recent work on 3D object detection advocates point cloud voxelization in birds-eye view, where objects preserve their physical dimensions and are naturally separable. When represented in this view, however, point clouds are sparse and have highly variable point density, which may cause detectors difficulties in detecting distant or small objects (pedestrians, traffic signs, etc.). On the other hand, perspective view provides dense observations, which could allow more favorable feature encoding for such cases. In this paper, we aim to synergize the birds-eye view and the perspective view and propose a novel end-to-end multi-view fusion (MVF) algorithm, which can effectively learn to utilize the complementary information from both. Specifically, we introduce dynamic voxelization, which has four merits compared to existing voxelization methods, i) removing the need of pre-allocating a tensor with fixed size; ii) overcoming the information loss due to stochastic point/voxel dropout; iii) yielding deterministic voxel embeddings and more stable detection outcomes; iv) establishing the bi-directional relationship between points and voxels, which potentially lays a natural foundation for cross-view feature fusion. By employing dynamic voxelization, the proposed feature fusion architecture enables each point to learn to fuse context information from different views. MVF operates on points and can be naturally extended to other approaches using LiDAR point clouds. We evaluate our MVF model extensively on the newly released Waymo Open Dataset and on the KITTI dataset and demonstrate that it significantly improves detection accuracy over the comparable single-view PointPillars baseline.
-
-
-
## Introduction
-
-
We implement Dynamic Voxelization proposed in and provide its results and models on KITTI dataset.
-```
+## Results and models
+
+### KITTI
+
+| Model |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
+| :---------: | :-----: |:-----: | :------: | :------------: | :----: | :------: |
+|[SECOND](./dv_second_secfpn_6x8_80e_kitti-3d-car.py)|Car |cyclic 80e|5.5||78.83|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_6x8_80e_kitti-3d-car/dv_second_secfpn_6x8_80e_kitti-3d-car_20200620_235228-ac2c1c0c.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_6x8_80e_kitti-3d-car/dv_second_secfpn_6x8_80e_kitti-3d-car_20200620_235228.log.json)|
+|[SECOND](./dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class.py)| 3 Class|cosine 80e|5.5||65.10|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class_20200620_231010-6aa607d3.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class_20200620_231010.log.json)|
+|[PointPillars](./dv_pointpillars_secfpn_6x8_160e_kitti-3d-car.py)| Car|cyclic 80e|4.7||77.76|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20200620_230844-ee7b75c9.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20200620_230844.log.json)|
+
+## Citation
+
+```latex
@article{zhou2019endtoend,
title={End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds},
author={Yin Zhou and Pei Sun and Yu Zhang and Dragomir Anguelov and Jiyang Gao and Tom Ouyang and James Guo and Jiquan Ngiam and Vijay Vasudevan},
@@ -30,15 +37,4 @@ We implement Dynamic Voxelization proposed in and provide its results and model
archivePrefix={arXiv},
primaryClass={cs.CV}
}
-
```
-
-## Results
-
-### KITTI
-
-| Model |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
-| :---------: | :-----: |:-----: | :------: | :------------: | :----: | :------: |
-|[SECOND](./dv_second_secfpn_6x8_80e_kitti-3d-car.py)|Car |cyclic 80e|5.5||78.83|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_6x8_80e_kitti-3d-car/dv_second_secfpn_6x8_80e_kitti-3d-car_20200620_235228-ac2c1c0c.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_6x8_80e_kitti-3d-car/dv_second_secfpn_6x8_80e_kitti-3d-car_20200620_235228.log.json)|
-|[SECOND](./dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class.py)| 3 Class|cosine 80e|5.5||65.10|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class_20200620_231010-6aa607d3.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class/dv_second_secfpn_2x8_cosine_80e_kitti-3d-3class_20200620_231010.log.json)|
-|[PointPillars](./dv_pointpillars_secfpn_6x8_160e_kitti-3d-car.py)| Car|cyclic 80e|4.7||77.76|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20200620_230844-ee7b75c9.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/dynamic_voxelization/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car/dv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20200620_230844.log.json)|
diff --git a/configs/fcos3d/README.md b/configs/fcos3d/README.md
index e95a34c76f..be517ec405 100644
--- a/configs/fcos3d/README.md
+++ b/configs/fcos3d/README.md
@@ -1,45 +1,24 @@
# FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection
-## Abstract
+> [FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection](https://arxiv.org/abs/2104.10956)
-
+
-Monocular 3D object detection is an important task for autonomous driving considering its advantage of low cost. It is much more challenging than conventional 2D cases due to its inherent ill-posed property, which is mainly reflected in the lack of depth information. Recent progress on 2D detection offers opportunities to better solving this problem. However, it is non-trivial to make a general adapted 2D detector work in this 3D task. In this paper, we study this problem with a practice built on a fully convolutional single-stage detector and propose a general framework FCOS3D. Specifically, we first transform the commonly defined 7-DoF 3D targets to the image domain and decouple them as 2D and 3D attributes. Then the objects are distributed to different feature levels with consideration of their 2D scales and assigned only according to the projected 3D-center for the training procedure. Furthermore, the center-ness is redefined with a 2D Gaussian distribution based on the 3D-center to fit the 3D target formulation. All of these make this framework simple yet effective, getting rid of any 2D detection or 2D-3D correspondence priors. Our solution achieves 1st place out of all the vision-only methods in the nuScenes 3D detection challenge of NeurIPS 2020.
+## Abstract
-
+Monocular 3D object detection is an important task for autonomous driving considering its advantage of low cost. It is much more challenging than conventional 2D cases due to its inherent ill-posed property, which is mainly reflected in the lack of depth information. Recent progress on 2D detection offers opportunities to better solving this problem. However, it is non-trivial to make a general adapted 2D detector work in this 3D task. In this paper, we study this problem with a practice built on a fully convolutional single-stage detector and propose a general framework FCOS3D. Specifically, we first transform the commonly defined 7-DoF 3D targets to the image domain and decouple them as 2D and 3D attributes. Then the objects are distributed to different feature levels with consideration of their 2D scales and assigned only according to the projected 3D-center for the training procedure. Furthermore, the center-ness is redefined with a 2D Gaussian distribution based on the 3D-center to fit the 3D target formulation. All of these make this framework simple yet effective, getting rid of any 2D detection or 2D-3D correspondence priors. Our solution achieves 1st place out of all the vision-only methods in the nuScenes 3D detection challenge of NeurIPS 2020.
-
-
-
## Introduction
-
-
FCOS3D is a general anchor-free, one-stage monocular 3D object detector adapted from the original 2D version FCOS.
It serves as a baseline built on top of mmdetection and mmdetection3d for 3D detection based on monocular vision.
Currently we first support the benchmark on the large-scale nuScenes dataset, which achieved 1st place out of all the vision-only methods in the [nuScenes 3D detecton challenge](https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Camera) of NeurIPS 2020.
-```
-@inproceedings{wang2021fcos3d,
- title={{FCOS3D: Fully} Convolutional One-Stage Monocular 3D Object Detection},
- author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
- year={2021}
-}
-# For the original 2D version
-@inproceedings{tian2019fcos,
- title = {{FCOS: Fully} Convolutional One-Stage Object Detection},
- author = {Tian, Zhi and Shen, Chunhua and Chen, Hao and He, Tong},
- booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
- year = {2019}
-}
-```
-

## Usage
@@ -67,7 +46,7 @@ Due to the scale and measurements of depth is different from those of other regr
We also provide visualization functions to show the monocular 3D detection results. Simply follow the [documentation](https://mmdetection3d.readthedocs.io/en/latest/1_exist_data_model.html#test-existing-models-on-standard-datasets) and use the `single-gpu testing` command. You only need to add the `--show` flag and specify `--show-dir` to store the visualization results.
-## Results
+## Results and models
### NuScenes
@@ -76,3 +55,21 @@ We also provide visualization functions to show the monocular 3D detection resul
|[ResNet101 w/ DCN](./fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d.py)|1x|8.69||29.8|37.7|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_20210715_235813-4bed5239.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_20210715_235813.log.json)|
|[above w/ finetune](./fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune.py)|1x|8.69||32.1|39.5|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune_20210717_095645-8d806dc2.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune_20210717_095645.log.json)|
|above w/ tta|1x|8.69||33.1|40.3||
+
+## Citation
+
+```latex
+@inproceedings{wang2021fcos3d,
+ title={{FCOS3D: Fully} Convolutional One-Stage Monocular 3D Object Detection},
+ author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
+ year={2021}
+}
+# For the original 2D version
+@inproceedings{tian2019fcos,
+ title = {{FCOS: Fully} Convolutional One-Stage Object Detection},
+ author = {Tian, Zhi and Shen, Chunhua and Chen, Hao and He, Tong},
+ booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
+ year = {2019}
+}
+```
diff --git a/configs/free_anchor/README.md b/configs/free_anchor/README.md
index 42110465d7..c92a43952a 100644
--- a/configs/free_anchor/README.md
+++ b/configs/free_anchor/README.md
@@ -1,38 +1,23 @@
# FreeAnchor for 3D Object Detection
-## Abstract
+> [FreeAnchor: Learning to Match Anchors for Visual Object Detection](https://arxiv.org/abs/1909.02466)
-
+
-Modern CNN-based object detectors assign anchors for ground-truth objects under the restriction of object-anchor Intersection-over-Unit (IoU). In this study, we propose a learning-to-match approach to break IoU restriction, allowing objects to match anchors in a flexible manner. Our approach, referred to as FreeAnchor, updates hand-crafted anchor assignment to “free" anchor matching by formulating detector training as a maximum likelihood estimation (MLE) procedure. FreeAnchor targets at learning features which best explain a class of objects in terms of both classification and localization. FreeAnchor is implemented by optimizing detection customized likelihood and can be fused with CNN-based detectors in a plug-and-play manner. Experiments on COCO demonstrate that FreeAnchor consistently outperforms the counterparts with significant margins.
+## Abstract
-
+Modern CNN-based object detectors assign anchors for ground-truth objects under the restriction of object-anchor Intersection-over-Unit (IoU). In this study, we propose a learning-to-match approach to break IoU restriction, allowing objects to match anchors in a flexible manner. Our approach, referred to as FreeAnchor, updates hand-crafted anchor assignment to “free" anchor matching by formulating detector training as a maximum likelihood estimation (MLE) procedure. FreeAnchor targets at learning features which best explain a class of objects in terms of both classification and localization. FreeAnchor is implemented by optimizing detection customized likelihood and can be fused with CNN-based detectors in a plug-and-play manner. Experiments on COCO demonstrate that FreeAnchor consistently outperforms the counterparts with significant margins.
-
-
-
## Introduction
-
-
We implement FreeAnchor in 3D detection systems and provide their first results with PointPillars on nuScenes dataset.
With the implemented `FreeAnchor3DHead`, a PointPillar detector with a big backbone (e.g., RegNet-3.2GF) achieves top performance
on the nuScenes benchmark.
-```
-@inproceedings{zhang2019freeanchor,
- title = {{FreeAnchor}: Learning to Match Anchors for Visual Object Detection},
- author = {Zhang, Xiaosong and Wan, Fang and Liu, Chang and Ji, Rongrong and Ye, Qixiang},
- booktitle = {Neural Information Processing Systems},
- year = {2019}
-}
-```
-
## Usage
### Modify config
@@ -91,7 +76,7 @@ model = dict(
pts=dict(code_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.25, 0.25])))
```
-## Results
+## Results and models
### PointPillars
@@ -107,3 +92,14 @@ model = dict(
|[RegNetX-3.2GF-FPN](./hv_pointpillars_regnet-3.2gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d.py)*|✓|3x|29.5||55.09|63.5|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/free_anchor/hv_pointpillars_regnet-3.2gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d/hv_pointpillars_regnet-3.2gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d_20200629_181452-297fdc66.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/free_anchor/hv_pointpillars_regnet-3.2gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d/hv_pointpillars_regnet-3.2gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d_20200629_181452.log.json)|
**Note**: Models noted by `*` means it is trained using stronger augmentation with vertical flip under bird-eye-view, global translation, and larger range of global rotation.
+
+## Citation
+
+```latex
+@inproceedings{zhang2019freeanchor,
+ title = {{FreeAnchor}: Learning to Match Anchors for Visual Object Detection},
+ author = {Zhang, Xiaosong and Wan, Fang and Liu, Chang and Ji, Rongrong and Ye, Qixiang},
+ booktitle = {Neural Information Processing Systems},
+ year = {2019}
+}
+```
diff --git a/configs/groupfree3d/README.md b/configs/groupfree3d/README.md
index f8d734738f..5c0a104b09 100644
--- a/configs/groupfree3d/README.md
+++ b/configs/groupfree3d/README.md
@@ -1,36 +1,22 @@
# Group-Free 3D Object Detection via Transformers
-## Abstract
+> [Group-Free 3D Object Detection via Transformers](https://arxiv.org/abs/2104.00678)
-
+
-Recently, directly detecting 3D objects from 3D point clouds has received increasing attention. To extract object representation from an irregular point cloud, existing methods usually take a point grouping step to assign the points to an object candidate so that a PointNet-like network could be used to derive object features from the grouped points. However, the inaccurate point assignments caused by the hand-crafted grouping scheme decrease the performance of 3D object detection. In this paper, we present a simple yet effective method for directly detecting 3D objects from the 3D point cloud. Instead of grouping local points to each object candidate, our method computes the feature of an object from all the points in the point cloud with the help of an attention mechanism in the Transformers, where the contribution of each point is automatically learned in the network training. With an improved attention stacking scheme, our method fuses object features in different stages and generates more accurate object detection results. With few bells and whistles, the proposed method achieves state-of-the-art 3D object detection performance on two widely used benchmarks, ScanNet V2 and SUN RGB-D.
+## Abstract
-
+Recently, directly detecting 3D objects from 3D point clouds has received increasing attention. To extract object representation from an irregular point cloud, existing methods usually take a point grouping step to assign the points to an object candidate so that a PointNet-like network could be used to derive object features from the grouped points. However, the inaccurate point assignments caused by the hand-crafted grouping scheme decrease the performance of 3D object detection. In this paper, we present a simple yet effective method for directly detecting 3D objects from the 3D point cloud. Instead of grouping local points to each object candidate, our method computes the feature of an object from all the points in the point cloud with the help of an attention mechanism in the Transformers, where the contribution of each point is automatically learned in the network training. With an improved attention stacking scheme, our method fuses object features in different stages and generates more accurate object detection results. With few bells and whistles, the proposed method achieves state-of-the-art 3D object detection performance on two widely used benchmarks, ScanNet V2 and SUN RGB-D.
-
-
-
## Introduction
-
-
We implement Group-Free-3D and provide the result and checkpoints on ScanNet datasets.
-```
-@article{liu2021,
- title={Group-Free 3D Object Detection via Transformers},
- author={Liu, Ze and Zhang, Zheng and Cao, Yue and Hu, Han and Tong, Xin},
- journal={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
- year={2021}
-}
-```
-
-## Results
+## Results and models
### ScanNet
@@ -45,3 +31,14 @@ We implement Group-Free-3D and provide the result and checkpoints on ScanNet dat
- We report the best results (AP@0.50) on validation set during each training. * means the evaluation method in the paper: we train each setting 5 times and test each training trial 5 times, then the average performance of these 25 trials is reported to account for algorithm randomness.
- We use 4 GPUs for training by default as the original code.
+
+## Citation
+
+```latex
+@article{liu2021,
+ title={Group-Free 3D Object Detection via Transformers},
+ author={Liu, Ze and Zhang, Zheng and Cao, Yue and Hu, Han and Tong, Xin},
+ journal={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
+ year={2021}
+}
+```
diff --git a/configs/h3dnet/README.md b/configs/h3dnet/README.md
index 3a9e2f28e0..c01338930c 100644
--- a/configs/h3dnet/README.md
+++ b/configs/h3dnet/README.md
@@ -1,36 +1,22 @@
# H3DNet: 3D Object Detection Using Hybrid Geometric Primitives
-## Abstract
+> [H3DNet: 3D Object Detection Using Hybrid Geometric Primitives](https://arxiv.org/abs/2006.05682)
-
+
-We introduce H3DNet, which takes a colorless 3D point cloud as input and outputs a collection of oriented object bounding boxes (or BB) and their semantic labels. The critical idea of H3DNet is to predict a hybrid set of geometric primitives, i.e., BB centers, BB face centers, and BB edge centers. We show how to convert the predicted geometric primitives into object proposals by defining a distance function between an object and the geometric primitives. This distance function enables continuous optimization of object proposals, and its local minimums provide high-fidelity object proposals. H3DNet then utilizes a matching and refinement module to classify object proposals into detected objects and fine-tune the geometric parameters of the detected objects. The hybrid set of geometric primitives not only provides more accurate signals for object detection than using a single type of geometric primitives, but it also provides an overcomplete set of constraints on the resulting 3D layout. Therefore, H3DNet can tolerate outliers in predicted geometric primitives. Our model achieves state-of-the-art 3D detection results on two large datasets with real 3D scans, ScanNet and SUN RGB-D.
+## Abstract
-
+We introduce H3DNet, which takes a colorless 3D point cloud as input and outputs a collection of oriented object bounding boxes (or BB) and their semantic labels. The critical idea of H3DNet is to predict a hybrid set of geometric primitives, i.e., BB centers, BB face centers, and BB edge centers. We show how to convert the predicted geometric primitives into object proposals by defining a distance function between an object and the geometric primitives. This distance function enables continuous optimization of object proposals, and its local minimums provide high-fidelity object proposals. H3DNet then utilizes a matching and refinement module to classify object proposals into detected objects and fine-tune the geometric parameters of the detected objects. The hybrid set of geometric primitives not only provides more accurate signals for object detection than using a single type of geometric primitives, but it also provides an overcomplete set of constraints on the resulting 3D layout. Therefore, H3DNet can tolerate outliers in predicted geometric primitives. Our model achieves state-of-the-art 3D detection results on two large datasets with real 3D scans, ScanNet and SUN RGB-D.
-
-
-
## Introduction
-
-
We implement H3DNet and provide the result and checkpoints on ScanNet datasets.
-```
-@inproceedings{zhang2020h3dnet,
- author = {Zhang, Zaiwei and Sun, Bo and Yang, Haitao and Huang, Qixing},
- title = {H3DNet: 3D Object Detection Using Hybrid Geometric Primitives},
- booktitle = {Proceedings of the European Conference on Computer Vision},
- year = {2020}
-}
-```
-
-## Results
+## Results and models
### ScanNet
@@ -45,3 +31,14 @@ python ./tools/model_converters/convert_h3dnet_checkpoints.py ${ORIGINAL_CHECKPO
```
Then you can use the converted checkpoints following [getting_started.md](../../docs/en/getting_started.md).
+
+## Citation
+
+```latex
+@inproceedings{zhang2020h3dnet,
+ author = {Zhang, Zaiwei and Sun, Bo and Yang, Haitao and Huang, Qixing},
+ title = {H3DNet: 3D Object Detection Using Hybrid Geometric Primitives},
+ booktitle = {Proceedings of the European Conference on Computer Vision},
+ year = {2020}
+}
+```
diff --git a/configs/imvotenet/README.md b/configs/imvotenet/README.md
index 038e8e9cd6..5e1d66ccb9 100644
--- a/configs/imvotenet/README.md
+++ b/configs/imvotenet/README.md
@@ -1,37 +1,22 @@
# ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
-## Abstract
+> [ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes](https://arxiv.org/abs/2001.10692)
-
+
-3D object detection has seen quick progress thanks to advances in deep learning on point clouds. A few recent works have even shown state-of-the-art performance with just point clouds input (e.g. VOTENET). However, point cloud data have inherent limitations. They are sparse, lack color information and often suffer from sensor noise. Images, on the other hand, have high resolution and rich texture. Thus they can complement the 3D geometry provided by point clouds. Yet how to effectively use image information to assist point cloud based detection is still an open question. In this work, we build on top of VOTENET and propose a 3D detection architecture called IMVOTENET specialized for RGB-D scenes. IMVOTENET is based on fusing 2D votes in images and 3D votes in point clouds. Compared to prior work on multi-modal detection, we explicitly extract both geometric and semantic features from the 2D images. We leverage camera parameters to lift these features to 3D. To improve the synergy of 2D-3D feature fusion, we also propose a multi-tower training scheme. We validate our model on the challenging SUN RGB-D dataset, advancing state-of-the-art results by 5.7 mAP. We also provide rich ablation studies to analyze the contribution of each design choice.
+## Abstract
-
+3D object detection has seen quick progress thanks to advances in deep learning on point clouds. A few recent works have even shown state-of-the-art performance with just point clouds input (e.g. VOTENET). However, point cloud data have inherent limitations. They are sparse, lack color information and often suffer from sensor noise. Images, on the other hand, have high resolution and rich texture. Thus they can complement the 3D geometry provided by point clouds. Yet how to effectively use image information to assist point cloud based detection is still an open question. In this work, we build on top of VOTENET and propose a 3D detection architecture called IMVOTENET specialized for RGB-D scenes. IMVOTENET is based on fusing 2D votes in images and 3D votes in point clouds. Compared to prior work on multi-modal detection, we explicitly extract both geometric and semantic features from the 2D images. We leverage camera parameters to lift these features to 3D. To improve the synergy of 2D-3D feature fusion, we also propose a multi-tower training scheme. We validate our model on the challenging SUN RGB-D dataset, advancing state-of-the-art results by 5.7 mAP. We also provide rich ablation studies to analyze the contribution of each design choice.
-
-
-
## Introduction
-
-
We implement ImVoteNet and provide the result and checkpoints on SUNRGBD.
-```
-@inproceedings{qi2020imvotenet,
- title={Imvotenet: Boosting 3D object detection in point clouds with image votes},
- author={Qi, Charles R and Chen, Xinlei and Litany, Or and Guibas, Leonidas J},
- booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
- pages={4404--4413},
- year={2020}
-}
-```
-
-## Results
+## Results and models
### SUNRGBD-2D (Stage 1, image branch pre-train)
@@ -44,3 +29,15 @@ We implement ImVoteNet and provide the result and checkpoints on SUNRGBD.
| Backbone | Lr schd | Mem (GB) | Inf time (fps) | AP@0.25 |AP@0.5| Download |
| :---------: | :-----: | :------: | :------------: | :----: |:----: | :------: |
| [PointNet++](./imvotenet_stage2_16x8_sunrgbd-3d-10class.py) | 3x |9.4| |64.04||[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/imvotenet/imvotenet_stage2_16x8_sunrgbd-3d-10class/imvotenet_stage2_16x8_sunrgbd-3d-10class_20210323_184021-d44dcb66.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/imvotenet/imvotenet_stage2_16x8_sunrgbd-3d-10class/imvotenet_stage2_16x8_sunrgbd-3d-10class_20210323_184021.log.json)|
+
+## Citation
+
+```latex
+@inproceedings{qi2020imvotenet,
+ title={Imvotenet: Boosting 3D object detection in point clouds with image votes},
+ author={Qi, Charles R and Chen, Xinlei and Litany, Or and Guibas, Leonidas J},
+ booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
+ pages={4404--4413},
+ year={2020}
+}
+```
diff --git a/configs/imvoxelnet/README.md b/configs/imvoxelnet/README.md
index 6746deeb7c..e79975442e 100644
--- a/configs/imvoxelnet/README.md
+++ b/configs/imvoxelnet/README.md
@@ -1,29 +1,34 @@
# ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection
-## Abstract
+> [ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection](https://arxiv.org/abs/2106.01178)
-
+
-In this paper, we introduce the task of multi-view RGB-based 3D object detection as an end-to-end optimization problem. To address this problem, we propose ImVoxelNet, a novel fully convolutional method of 3D object detection based on posed monocular or multi-view RGB images. The number of monocular images in each multiview input can variate during training and inference; actually, this number might be unique for each multi-view input. ImVoxelNet successfully handles both indoor and outdoor scenes, which makes it general-purpose. Specifically, it achieves state-of-the-art results in car detection on KITTI (monocular) and nuScenes (multi-view) benchmarks among all methods that accept RGB images. Moreover, it surpasses existing RGB-based 3D object detection methods on the SUN RGB-D dataset. On ScanNet, ImVoxelNet sets a new benchmark for multi-view 3D object detection.
+## Abstract
-
+In this paper, we introduce the task of multi-view RGB-based 3D object detection as an end-to-end optimization problem. To address this problem, we propose ImVoxelNet, a novel fully convolutional method of 3D object detection based on posed monocular or multi-view RGB images. The number of monocular images in each multiview input can variate during training and inference; actually, this number might be unique for each multi-view input. ImVoxelNet successfully handles both indoor and outdoor scenes, which makes it general-purpose. Specifically, it achieves state-of-the-art results in car detection on KITTI (monocular) and nuScenes (multi-view) benchmarks among all methods that accept RGB images. Moreover, it surpasses existing RGB-based 3D object detection methods on the SUN RGB-D dataset. On ScanNet, ImVoxelNet sets a new benchmark for multi-view 3D object detection.
-
-
-
## Introduction
-
-
We implement a monocular 3D detector ImVoxelNet and provide its results and checkpoints on KITTI dataset.
Results for SUN RGB-D, ScanNet and nuScenes are currently available in ImVoxelNet authors
[repo](https://github.com/saic-vul/imvoxelnet) (based on mmdetection3d).
-```
+## Results and models
+
+### KITTI
+
+| Backbone |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
+| :---------: | :-----: |:-----: | :------: | :------------: | :----: |:----: |
+| [ResNet-50](./imvoxelnet_kitti-3d-car.py) | Car | 3x | | |17.4|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/imvoxelnet/imvoxelnet_kitti-3d-car_20210610_152323-b9abba85.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/imvoxelnet/imvoxelnet_kitti-3d-car_20210610_152323.log.json)|
+
+## Citation
+
+```latex
@article{rukhovich2021imvoxelnet,
title={ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection},
author={Danila Rukhovich, Anna Vorontsova, Anton Konushin},
@@ -31,11 +36,3 @@ Results for SUN RGB-D, ScanNet and nuScenes are currently available in ImVoxelNe
year={2021}
}
```
-
-## Results
-
-### KITTI
-
-| Backbone |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
-| :---------: | :-----: |:-----: | :------: | :------------: | :----: |:----: |
-| [ResNet-50](./imvoxelnet_kitti-3d-car.py) | Car | 3x | | |17.4|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/imvoxelnet/imvoxelnet_kitti-3d-car_20210610_152323-b9abba85.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/imvoxelnet/imvoxelnet_kitti-3d-car_20210610_152323.log.json)|
diff --git a/configs/mvxnet/README.md b/configs/mvxnet/README.md
index da7eb35da4..b2a34f101a 100644
--- a/configs/mvxnet/README.md
+++ b/configs/mvxnet/README.md
@@ -1,25 +1,32 @@
# MVX-Net: Multimodal VoxelNet for 3D Object Detection
+> [MVX-Net: Multimodal VoxelNet for 3D Object Detection](https://arxiv.org/abs/1904.01649)
+
+
+
## Abstract
Many recent works on 3D object detection have focused on designing neural network architectures that can consume point cloud data. While these approaches demonstrate encouraging performance, they are typically based on a single modality and are unable to leverage information from other modalities, such as a camera. Although a few approaches fuse data from different modalities, these methods either use a complicated pipeline to process the modalities sequentially, or perform late-fusion and are unable to learn interaction between different modalities at early stages. In this work, we present PointFusion and VoxelFusion: two simple yet effective early-fusion approaches to combine the RGB and point cloud modalities, by leveraging the recently introduced VoxelNet architecture. Evaluation on the KITTI dataset demonstrates significant improvements in performance over approaches which only use point cloud data. Furthermore, the proposed method provides results competitive with the state-of-the-art multimodal algorithms, achieving top-2 ranking in five of the six bird's eye view and 3D detection categories on the KITTI benchmark, by using a simple single stage network.
-
-
-
-
-
## Introduction
-
-
We implement MVX-Net and provide its results and models on KITTI dataset.
-```
+## Results and models
+
+### KITTI
+
+| Backbone |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
+| :---------: | :-----: | :------: | :------------: | :----: |:----: | :------: |
+| [SECFPN](./dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class.py)|3 Class|cosine 80e|6.7||63.0|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/mvxnet/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class_20200621_003904-10140f2d.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/mvxnet/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class_20200621_003904.log.json)|
+
+## Citation
+
+```latex
@inproceedings{sindagi2019mvx,
title={MVX-Net: Multimodal voxelnet for 3D object detection},
author={Sindagi, Vishwanath A and Zhou, Yin and Tuzel, Oncel},
@@ -28,13 +35,4 @@ We implement MVX-Net and provide its results and models on KITTI dataset.
year={2019},
organization={IEEE}
}
-
```
-
-## Results
-
-### KITTI
-
-| Backbone |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
-| :---------: | :-----: | :------: | :------------: | :----: |:----: | :------: |
-| [SECFPN](./dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class.py)|3 Class|cosine 80e|6.7||63.0|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/mvxnet/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class_20200621_003904-10140f2d.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/mvxnet/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class/dv_mvx-fpn_second_secfpn_adamw_2x8_80e_kitti-3d-3class_20200621_003904.log.json)|
diff --git a/configs/nuimages/README.md b/configs/nuimages/README.md
index 5d206e2f96..42267f239d 100644
--- a/configs/nuimages/README.md
+++ b/configs/nuimages/README.md
@@ -1,9 +1,9 @@
# NuImages Results
-## Introduction
-
+## Introduction
+
We support and provide some baseline results on [nuImages dataset](https://www.nuscenes.org/nuimages).
We follow the class mapping in nuScenes dataset, which maps the original categories into 10 foreground categories.
The convert script can be found [here](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/nuimage_converter.py).
@@ -25,7 +25,7 @@ python -u tools/data_converter/nuimage_converter.py --data-root ${DATA_ROOT} --v
- `--nproc`: number of workers for data preparation, defaults to `4`. Larger number could reduce the preparation time as images are processed in parallel.
- `--extra-tag`: extra tag of the annotations, defaults to `nuimages`. This can be used to separate different annotations processed in different time for study.
-## Results
+## Results and models
### Instance Segmentation
diff --git a/configs/paconv/README.md b/configs/paconv/README.md
index 6f1789005b..0b2bc7275e 100644
--- a/configs/paconv/README.md
+++ b/configs/paconv/README.md
@@ -1,40 +1,25 @@
# PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds
-## Abstract
+> [PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds](https://arxiv.org/abs/2103.14635)
+
+
-
+## Abstract
We introduce Position Adaptive Convolution (PAConv), a generic convolution operation for 3D point cloud processing. The key of PAConv is to construct the convolution kernel by dynamically assembling basic weight matrices stored in Weight Bank, where the coefficients of these weight matrices are self-adaptively learned from point positions through ScoreNet. In this way, the kernel is built in a data-driven manner, endowing PAConv with more flexibility than 2D convolutions to better handle the irregular and unordered point cloud data. Besides, the complexity of the learning process is reduced by combining weight matrices instead of brutally predicting kernels from point positions.
Furthermore, different from the existing point convolution operators whose network architectures are often heavily engineered, we integrate our PAConv into classical MLP-based point cloud pipelines without changing network configurations. Even built on simple networks, our method still approaches or even surpasses the state-of-the-art models, and significantly improves baseline performance on both classification and segmentation tasks, yet with decent efficiency. Thorough ablation studies and visualizations are provided to understand PAConv.
-
-
-
-
-
## Introduction
-
-
We implement PAConv and provide the result and checkpoints on S3DIS dataset.
-```
-@inproceedings{xu2021paconv,
- title={PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds},
- author={Xu, Mutian and Ding, Runyu and Zhao, Hengshuang and Qi, Xiaojuan},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- pages={3173--3182},
- year={2021}
-}
-```
-
**Notice**: The original PAConv paper used step learning rate schedule. We discovered that cosine schedule achieves slightly better results and adopt it in our implementations.
-## Results
+## Results and models
### S3DIS
@@ -52,3 +37,15 @@ We implement PAConv and provide the result and checkpoints on S3DIS dataset.
## Indeterminism
Since PAConv testing adopts sliding patch inference which involves random point sampling, and the test script uses fixed random seeds while the random seeds of validation in training are not fixed, the test results may be slightly different from the results reported above.
+
+## Citation
+
+```latex
+@inproceedings{xu2021paconv,
+ title={PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds},
+ author={Xu, Mutian and Ding, Runyu and Zhao, Hengshuang and Qi, Xiaojuan},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={3173--3182},
+ year={2021}
+}
+```
diff --git a/configs/parta2/README.md b/configs/parta2/README.md
index 4fc4a86fb3..2d1d4b0825 100644
--- a/configs/parta2/README.md
+++ b/configs/parta2/README.md
@@ -1,27 +1,33 @@
# From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network
-## Abstract
+> [From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network](https://arxiv.org/abs/1907.03670)
-
+
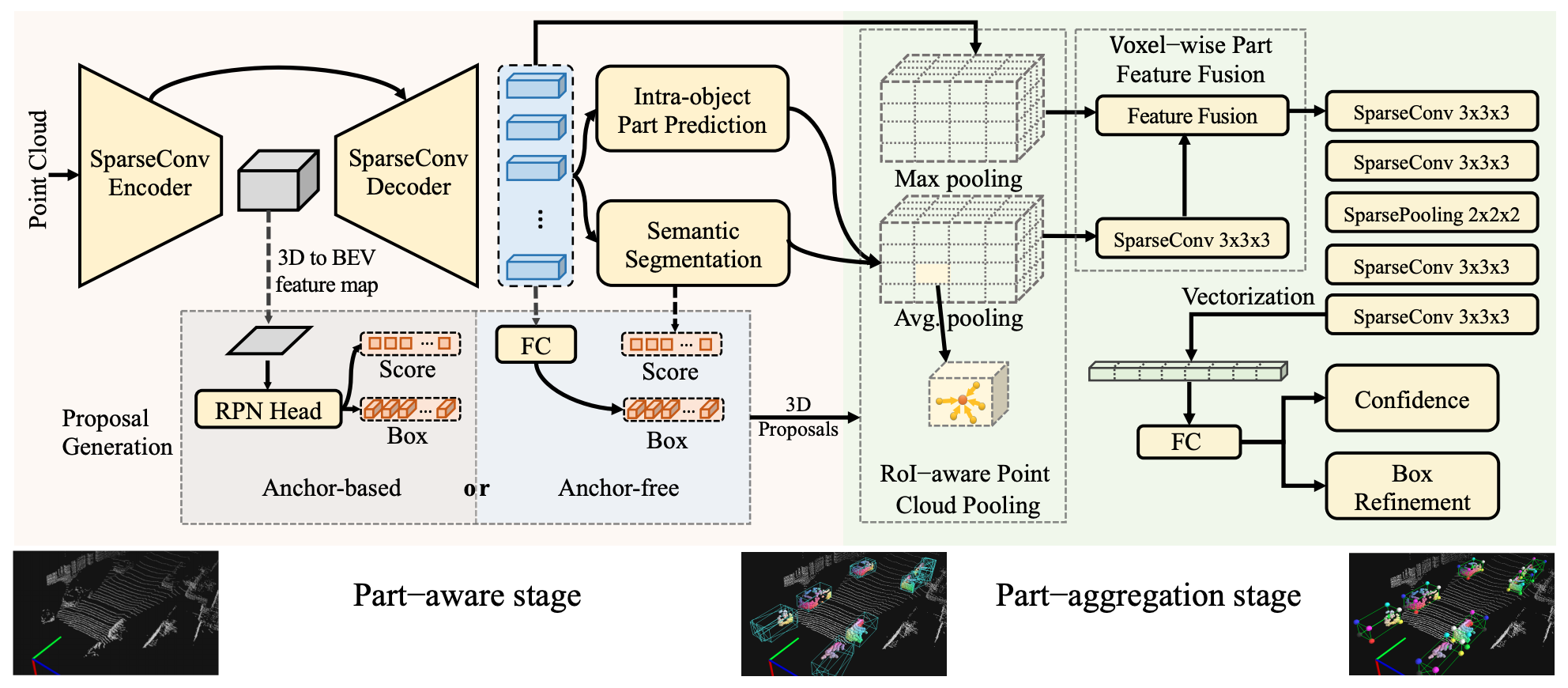
-3D object detection from LiDAR point cloud is a challenging problem in 3D scene understanding and has many practical applications. In this paper, we extend our preliminary work PointRCNN to a novel and strong point-cloud-based 3D object detection framework, the part-aware and aggregation neural network (Part-A2 net). The whole framework consists of the part-aware stage and the part-aggregation stage. Firstly, the part-aware stage for the first time fully utilizes free-of-charge part supervisions derived from 3D ground-truth boxes to simultaneously predict high quality 3D proposals and accurate intra-object part locations. The predicted intra-object part locations within the same proposal are grouped by our new-designed RoI-aware point cloud pooling module, which results in an effective representation to encode the geometry-specific features of each 3D proposal. Then the part-aggregation stage learns to re-score the box and refine the box location by exploring the spatial relationship of the pooled intra-object part locations. Extensive experiments are conducted to demonstrate the performance improvements from each component of our proposed framework. Our Part-A2 net outperforms all existing 3D detection methods and achieves new state-of-the-art on KITTI 3D object detection dataset by utilizing only the LiDAR point cloud data.
+## Abstract
-
+3D object detection from LiDAR point cloud is a challenging problem in 3D scene understanding and has many practical applications. In this paper, we extend our preliminary work PointRCNN to a novel and strong point-cloud-based 3D object detection framework, the part-aware and aggregation neural network (Part-A2 net). The whole framework consists of the part-aware stage and the part-aggregation stage. Firstly, the part-aware stage for the first time fully utilizes free-of-charge part supervisions derived from 3D ground-truth boxes to simultaneously predict high quality 3D proposals and accurate intra-object part locations. The predicted intra-object part locations within the same proposal are grouped by our new-designed RoI-aware point cloud pooling module, which results in an effective representation to encode the geometry-specific features of each 3D proposal. Then the part-aggregation stage learns to re-score the box and refine the box location by exploring the spatial relationship of the pooled intra-object part locations. Extensive experiments are conducted to demonstrate the performance improvements from each component of our proposed framework. Our Part-A2 net outperforms all existing 3D detection methods and achieves new state-of-the-art on KITTI 3D object detection dataset by utilizing only the LiDAR point cloud data.
-
-
-
## Introduction
-
-
We implement Part-A^2 and provide its results and checkpoints on KITTI dataset.
-```
+## Results and models
+
+### KITTI
+
+| Backbone |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
+| :---------: | :-----: |:-----: | :------: | :------------: | :----: |:----: |
+| [SECFPN](./hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class.py) |3 Class|cyclic 80e|4.1||67.9|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class_20200620_230724-a2672098.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class_20200620_230724.log.json)|
+| [SECFPN](./hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car.py) |Car |cyclic 80e|4.0||79.16|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car_20200620_230755-f2a38b9a.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car_20200620_230755.log.json)|
+
+## Citation
+
+```latex
@article{shi2020points,
title={From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network},
author={Shi, Shaoshuai and Wang, Zhe and Shi, Jianping and Wang, Xiaogang and Li, Hongsheng},
@@ -30,12 +36,3 @@ We implement Part-A^2 and provide its results and checkpoints on KITTI dataset.
publisher={IEEE}
}
```
-
-## Results
-
-### KITTI
-
-| Backbone |Class| Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
-| :---------: | :-----: |:-----: | :------: | :------------: | :----: |:----: |
-| [SECFPN](./hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class.py) |3 Class|cyclic 80e|4.1||67.9|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class_20200620_230724-a2672098.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-3class_20200620_230724.log.json)|
-| [SECFPN](./hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car.py) |Car |cyclic 80e|4.0||79.16|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car_20200620_230755-f2a38b9a.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/parta2/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car/hv_PartA2_secfpn_2x8_cyclic_80e_kitti-3d-car_20200620_230755.log.json)|
diff --git a/configs/pgd/README.md b/configs/pgd/README.md
index e10f2675ab..02e5aa5719 100644
--- a/configs/pgd/README.md
+++ b/configs/pgd/README.md
@@ -1,24 +1,19 @@
# Probabilistic and Geometric Depth: Detecting Objects in Perspective
-## Abstract
+> [Probabilistic and Geometric Depth: Detecting Objects in Perspective](https://arxiv.org/abs/2107.14160)
-
+
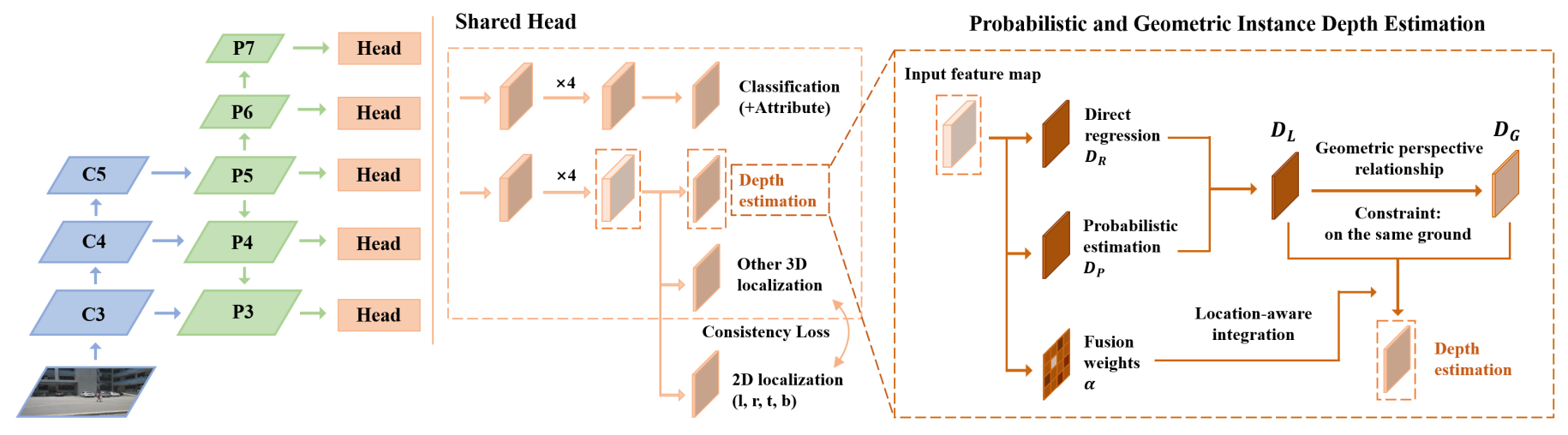
-3D object detection is an important capability needed in various practical applications such as driver assistance systems. Monocular 3D detection, as a representative general setting among image-based approaches, provides a more economical solution than conventional settings relying on LiDARs but still yields unsatisfactory results. This paper first presents a systematic study on this problem. We observe that the current monocular 3D detection can be simplified as an instance depth estimation problem: The inaccurate instance depth blocks all the other 3D attribute predictions from improving the overall detection performance. Moreover, recent methods directly estimate the depth based on isolated instances or pixels while ignoring the geometric relations across different objects. To this end, we construct geometric relation graphs across predicted objects and use the graph to facilitate depth estimation. As the preliminary depth estimation of each instance is usually inaccurate in this ill-posed setting, we incorporate a probabilistic representation to capture the uncertainty. It provides an important indicator to identify confident predictions and further guide the depth propagation. Despite the simplicity of the basic idea, our method, PGD, obtains significant improvements on KITTI and nuScenes benchmarks, achieving 1st place out of all monocular vision-only methods while still maintaining real-time efficiency. Code and models will be released at [this https URL](https://github.com/open-mmlab/mmdetection3d).
+## Abstract
-
+3D object detection is an important capability needed in various practical applications such as driver assistance systems. Monocular 3D detection, as a representative general setting among image-based approaches, provides a more economical solution than conventional settings relying on LiDARs but still yields unsatisfactory results. This paper first presents a systematic study on this problem. We observe that the current monocular 3D detection can be simplified as an instance depth estimation problem: The inaccurate instance depth blocks all the other 3D attribute predictions from improving the overall detection performance. Moreover, recent methods directly estimate the depth based on isolated instances or pixels while ignoring the geometric relations across different objects. To this end, we construct geometric relation graphs across predicted objects and use the graph to facilitate depth estimation. As the preliminary depth estimation of each instance is usually inaccurate in this ill-posed setting, we incorporate a probabilistic representation to capture the uncertainty. It provides an important indicator to identify confident predictions and further guide the depth propagation. Despite the simplicity of the basic idea, our method, PGD, obtains significant improvements on KITTI and nuScenes benchmarks, achieving 1st place out of all monocular vision-only methods while still maintaining real-time efficiency. Code and models will be released at [this https URL](https://github.com/open-mmlab/mmdetection3d).
-
-
-
## Introduction
-
-
PGD, also can be regarded as FCOS3D++, is a simple yet effective monocular 3D detector. It enhances the FCOS3D baseline by involving local geometric constraints and improving instance depth estimation.
We release the code and model for both KITTI and nuScenes benchmark, which is a good supplement for the original FCOS3D baseline (only supported on nuScenes).
@@ -27,23 +22,7 @@ For clean implementation, our preliminary release supports base models with prop
A more extensive study based on FCOS3D and PGD is on-going. Please stay tuned.
-```
-@inproceedings{wang2021pgd,
- title={{Probabilistic and Geometric Depth: Detecting} Objects in Perspective},
- author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
- booktitle={Conference on Robot Learning (CoRL) 2021},
- year={2021}
-}
-# For the baseline version
-@inproceedings{wang2021fcos3d,
- title={{FCOS3D: Fully} Convolutional One-Stage Monocular 3D Object Detection},
- author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
- booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
- year={2021}
-}
-```
-
-## Results
+## Results and models
### KITTI
@@ -70,3 +49,21 @@ Note: mAP represents Car moderate 3D strict AP11 / AP40 results. Because of the
|[ResNet101 w/ DCN](./pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d.py)|2x|9.20|33.6|40.9|[model](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/pgd/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d_20211112_125314-cb677266.pth) | [log](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/pgd/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d_20211112_125314.log.json)|
|[above w/ finetune](./pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d_finetune.py)|2x|9.20|35.8|42.5|[model](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/pgd/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d_finetune/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d_finetune_20211114_162135-5ec7c1cd.pth) | [log](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/pgd/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d_finetune/pgd_r101_caffe_fpn_gn-head_2x16_2x_nus-mono3d_finetune_20211114_162135.log.json)|
|above w/ tta|2x|9.20|36.8|43.1||
+
+## Citation
+
+```latex
+@inproceedings{wang2021pgd,
+ title={{Probabilistic and Geometric Depth: Detecting} Objects in Perspective},
+ author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
+ booktitle={Conference on Robot Learning (CoRL) 2021},
+ year={2021}
+}
+# For the baseline version
+@inproceedings{wang2021fcos3d,
+ title={{FCOS3D: Fully} Convolutional One-Stage Monocular 3D Object Detection},
+ author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
+ year={2021}
+}
+```
diff --git a/configs/point_rcnn/README.md b/configs/point_rcnn/README.md
index d4a28348bc..cf59e3f6c5 100644
--- a/configs/point_rcnn/README.md
+++ b/configs/point_rcnn/README.md
@@ -1,37 +1,22 @@
# PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
-## Abstract
+> [PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud](https://arxiv.org/abs/1812.04244)
-
+
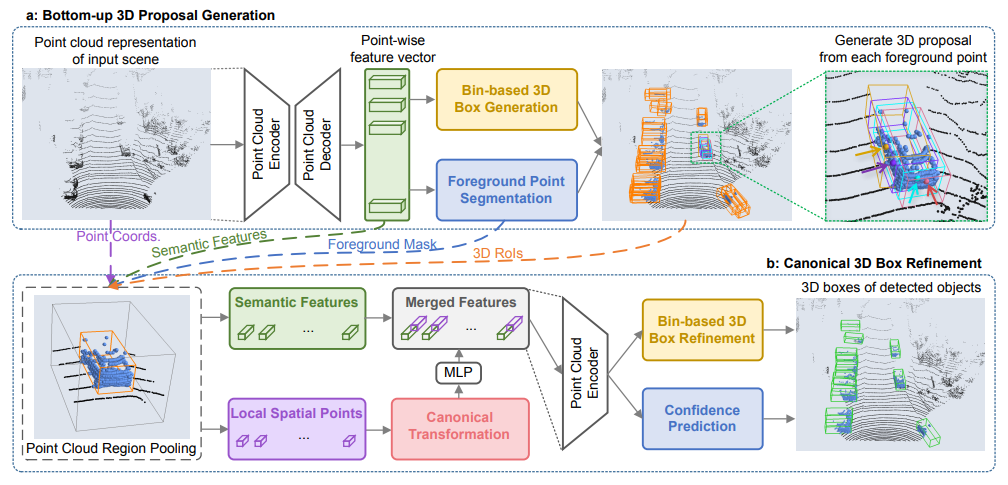
-In this paper, we propose PointRCNN for 3D object detection from raw point cloud. The whole framework is composed of two stages: stage-1 for the bottom-up 3D proposal generation and stage-2 for refining proposals in the canonical coordinates to obtain the final detection results. Instead of generating proposals from RGB image or projecting point cloud to bird's view or voxels as previous methods do, our stage-1 sub-network directly generates a small number of high-quality 3D proposals from point cloud in a bottom-up manner via segmenting the point cloud of the whole scene into foreground points and background. The stage-2 sub-network transforms the pooled points of each proposal to canonical coordinates to learn better local spatial features, which is combined with global semantic features of each point learned in stage-1 for accurate box refinement and confidence prediction. Extensive experiments on the 3D detection benchmark of KITTI dataset show that our proposed architecture outperforms state-of-the-art methods with remarkable margins by using only point cloud as input.
+## Abstract
-
+In this paper, we propose PointRCNN for 3D object detection from raw point cloud. The whole framework is composed of two stages: stage-1 for the bottom-up 3D proposal generation and stage-2 for refining proposals in the canonical coordinates to obtain the final detection results. Instead of generating proposals from RGB image or projecting point cloud to bird's view or voxels as previous methods do, our stage-1 sub-network directly generates a small number of high-quality 3D proposals from point cloud in a bottom-up manner via segmenting the point cloud of the whole scene into foreground points and background. The stage-2 sub-network transforms the pooled points of each proposal to canonical coordinates to learn better local spatial features, which is combined with global semantic features of each point learned in stage-1 for accurate box refinement and confidence prediction. Extensive experiments on the 3D detection benchmark of KITTI dataset show that our proposed architecture outperforms state-of-the-art methods with remarkable margins by using only point cloud as input.
-
-
-
## Introduction
-
-
We implement PointRCNN and provide the result with checkpoints on KITTI dataset.
-```
-@inproceedings{Shi_2019_CVPR,
- title = {PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud},
- author = {Shi, Shaoshuai and Wang, Xiaogang and Li, Hongsheng},
- booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- month = {June},
- year = {2019}
-}
-```
-
-## Results
+## Results and models
### KITTI
@@ -48,3 +33,15 @@ Detailed performance on KITTI 3D detection (3D) is as follows, evaluated by AP11
| Car | 89.13 | 78.72 | 78.24 |
| Pedestrian | 65.81 | 59.57 | 52.75 |
| Cyclist | 93.51 | 74.19 | 70.73 |
+
+## Citation
+
+```latex
+@inproceedings{Shi_2019_CVPR,
+ title = {PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud},
+ author = {Shi, Shaoshuai and Wang, Xiaogang and Li, Hongsheng},
+ booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2019}
+}
+```
diff --git a/configs/pointnet2/README.md b/configs/pointnet2/README.md
index 2cef3c91d7..e91c23f013 100644
--- a/configs/pointnet2/README.md
+++ b/configs/pointnet2/README.md
@@ -1,39 +1,24 @@
# PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
-## Abstract
+> [PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space](https://arxiv.org/abs/1706.02413)
-
+
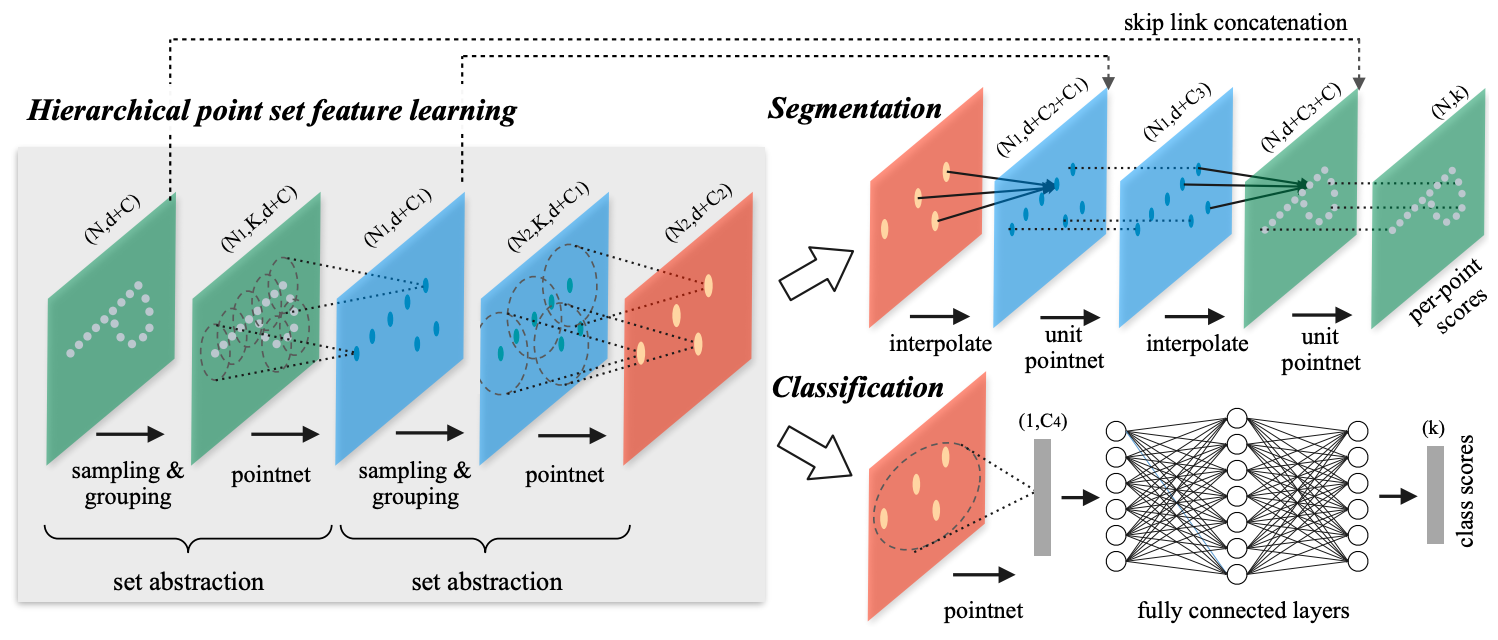
-Few prior works study deep learning on point sets. PointNet by Qi et al. is a pioneer in this direction. However, by design PointNet does not capture local structures induced by the metric space points live in, limiting its ability to recognize fine-grained patterns and generalizability to complex scenes. In this work, we introduce a hierarchical neural network that applies PointNet recursively on a nested partitioning of the input point set. By exploiting metric space distances, our network is able to learn local features with increasing contextual scales. With further observation that point sets are usually sampled with varying densities, which results in greatly decreased performance for networks trained on uniform densities, we propose novel set learning layers to adaptively combine features from multiple scales. Experiments show that our network called PointNet++ is able to learn deep point set features efficiently and robustly. In particular, results significantly better than state-of-the-art have been obtained on challenging benchmarks of 3D point clouds.
+## Abstract
-
+Few prior works study deep learning on point sets. PointNet by Qi et al. is a pioneer in this direction. However, by design PointNet does not capture local structures induced by the metric space points live in, limiting its ability to recognize fine-grained patterns and generalizability to complex scenes. In this work, we introduce a hierarchical neural network that applies PointNet recursively on a nested partitioning of the input point set. By exploiting metric space distances, our network is able to learn local features with increasing contextual scales. With further observation that point sets are usually sampled with varying densities, which results in greatly decreased performance for networks trained on uniform densities, we propose novel set learning layers to adaptively combine features from multiple scales. Experiments show that our network called PointNet++ is able to learn deep point set features efficiently and robustly. In particular, results significantly better than state-of-the-art have been obtained on challenging benchmarks of 3D point clouds.
-
-
-
## Introduction
-
-
We implement PointNet++ and provide the result and checkpoints on ScanNet and S3DIS datasets.
-```
-@inproceedings{qi2017pointnet++,
- title={PointNet++ deep hierarchical feature learning on point sets in a metric space},
- author={Qi, Charles R and Yi, Li and Su, Hao and Guibas, Leonidas J},
- booktitle={Proceedings of the 31st International Conference on Neural Information Processing Systems},
- pages={5105--5114},
- year={2017}
-}
-```
-
**Notice**: The original PointNet++ paper used step learning rate schedule. We discovered that cosine schedule achieves much better results and adopt it in our implementations. We also use a larger `weight_decay` factor because we find it consistently improves the performance.
-## Results
+## Results and models
### ScanNet
@@ -71,3 +56,15 @@ We implement PointNet++ and provide the result and checkpoints on ScanNet and S3
## Indeterminism
Since PointNet++ testing adopts sliding patch inference which involves random point sampling, and the test script uses fixed random seeds while the random seeds of validation in training are not fixed, the test results may be slightly different from the results reported above.
+
+## Citation
+
+```latex
+@inproceedings{qi2017pointnet++,
+ title={PointNet++ deep hierarchical feature learning on point sets in a metric space},
+ author={Qi, Charles R and Yi, Li and Su, Hao and Guibas, Leonidas J},
+ booktitle={Proceedings of the 31st International Conference on Neural Information Processing Systems},
+ pages={5105--5114},
+ year={2017}
+}
+```
diff --git a/configs/pointpillars/README.md b/configs/pointpillars/README.md
index dc8bebd930..ff817621bd 100644
--- a/configs/pointpillars/README.md
+++ b/configs/pointpillars/README.md
@@ -1,38 +1,22 @@
# PointPillars: Fast Encoders for Object Detection from Point Clouds
-## Abstract
+> [PointPillars: Fast Encoders for Object Detection from Point Clouds](https://arxiv.org/abs/1812.05784)
-
+
-Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.
+## Abstract
-
+Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.
-
-
-
## Introduction
-
-
We implement PointPillars and provide the results and checkpoints on KITTI, nuScenes, Lyft and Waymo datasets.
-```
-@inproceedings{lang2019pointpillars,
- title={Pointpillars: Fast encoders for object detection from point clouds},
- author={Lang, Alex H and Vora, Sourabh and Caesar, Holger and Zhou, Lubing and Yang, Jiong and Beijbom, Oscar},
- booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
- pages={12697--12705},
- year={2019}
-}
-
-```
-
-## Results
+## Results and models
### KITTI
@@ -80,3 +64,15 @@ We implement PointPillars and provide the results and checkpoints on KITTI, nuSc
stride of 1 for the first convolutional block). Different settings of voxelization, data augmentation and hyper parameters make these baselines outperform those in the paper by about 7 mAP for car and 4 mAP for pedestrian with only a subset of the whole dataset. All of these results are achieved without bells-and-whistles, e.g. ensemble, multi-scale training and test augmentation.
- **License Aggrement**: To comply the [license agreement of Waymo dataset](https://waymo.com/open/terms/), the pre-trained models on Waymo dataset are not released. We still release the training log as a reference to ease the future research.
- `FP16` means Mixed Precision (FP16) is adopted in training. With mixed precision training, we can train PointPillars with nuScenes dataset on 8 Titan XP GPUS with batch size of 2. This will cause OOM error without mixed precision training. The loss scale for PointPillars on nuScenes dataset is specifically tuned to avoid the loss to be Nan. We find 32 is more stable than 512, though loss scale 32 still cause Nan sometimes.
+
+## Citation
+
+```latex
+@inproceedings{lang2019pointpillars,
+ title={Pointpillars: Fast encoders for object detection from point clouds},
+ author={Lang, Alex H and Vora, Sourabh and Caesar, Holger and Zhou, Lubing and Yang, Jiong and Beijbom, Oscar},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={12697--12705},
+ year={2019}
+}
+```
diff --git a/configs/regnet/README.md b/configs/regnet/README.md
index 35704526e3..f981123937 100644
--- a/configs/regnet/README.md
+++ b/configs/regnet/README.md
@@ -1,39 +1,23 @@
# Designing Network Design Spaces
-## Abstract
+> [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678)
-
+
-In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.
+## Abstract
-
+In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.
-
-
-
## Introduction
-
-
We implement RegNetX models in 3D detection systems and provide their first results with PointPillars on nuScenes and Lyft dataset.
The pre-trained modles are converted from [model zoo of pycls](https://github.com/facebookresearch/pycls/blob/master/MODEL_ZOO.md) and maintained in [mmcv](https://github.com/open-mmlab/mmcv).
-```
-@article{radosavovic2020designing,
- title={Designing Network Design Spaces},
- author={Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Dollár},
- year={2020},
- eprint={2003.13678},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
## Usage
To use a regnet model, there are two steps to do:
@@ -62,7 +46,7 @@ For other pre-trained models or self-implemented regnet models, the users are re
**Note**: Although Fig. 15 & 16 also provide `w0`, `wa`, `wm`, `group_w`, and `bot_mul` for `arch`, they are quantized thus inaccurate, using them sometimes produces different backbone that does not match the key in the pre-trained model.
-## Results
+## Results and models
### nuScenes
@@ -82,3 +66,16 @@ For other pre-trained models or self-implemented regnet models, the users are re
|[RegNetX-400MF-SECFPN](./hv_pointpillars_regnet-400mf_secfpn_sbn-all_4x8_2x_lyft-3d.py)| 2x |15.9||14.9|15.1|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/regnet/hv_pointpillars_regnet-400mf_secfpn_sbn-all_2x8_2x_lyft-3d/hv_pointpillars_regnet-400mf_secfpn_sbn-all_2x8_2x_lyft-3d_20210524_092151-42513826.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/regnet/hv_pointpillars_regnet-400mf_secfpn_sbn-all_2x8_2x_lyft-3d/hv_pointpillars_regnet-400mf_secfpn_sbn-all_2x8_2x_lyft-3d_20210524_092151.log.json)|
|[FPN](../pointpillars/hv_pointpillars_fpn_sbn-all_2x8_2x_lyft-3d.py)|2x|9.2||14.9|15.1|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/pointpillars/hv_pointpillars_fpn_sbn-all_2x8_2x_lyft-3d/hv_pointpillars_fpn_sbn-all_2x8_2x_lyft-3d_20210517_202818-fc6904c3.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/pointpillars/hv_pointpillars_fpn_sbn-all_2x8_2x_lyft-3d/hv_pointpillars_fpn_sbn-all_2x8_2x_lyft-3d_20210517_202818.log.json)|
|[RegNetX-400MF-FPN](./hv_pointpillars_regnet-400mf_fpn_sbn-all_4x8_2x_lyft-3d.py)|2x|13.0||16.0|16.1|[model](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/regnet/hv_pointpillars_regnet-400mf_fpn_sbn-all_2x8_2x_lyft-3d/hv_pointpillars_regnet-400mf_fpn_sbn-all_2x8_2x_lyft-3d_20210521_115618-823dcf18.pth) | [log](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/regnet/hv_pointpillars_regnet-400mf_fpn_sbn-all_2x8_2x_lyft-3d/hv_pointpillars_regnet-400mf_fpn_sbn-all_2x8_2x_lyft-3d_20210521_115618.log.json)|
+
+## Citation
+
+```latex
+@article{radosavovic2020designing,
+ title={Designing Network Design Spaces},
+ author={Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Dollár},
+ year={2020},
+ eprint={2003.13678},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
diff --git a/configs/second/README.md b/configs/second/README.md
index 81f1e02f3d..6180656e07 100644
--- a/configs/second/README.md
+++ b/configs/second/README.md
@@ -1,37 +1,22 @@
# Second: Sparsely embedded convolutional detection
-## Abstract
+> [SECOND: Sparsely Embedded Convolutional Detection](https://www.mdpi.com/1424-8220/18/10/3337)
-
+
-LiDAR-based or RGB-D-based object detection is used in numerous applications, ranging from autonomous driving to robot vision. Voxel-based 3D convolutional networks have been used for some time to enhance the retention of information when processing point cloud LiDAR data. However, problems remain, including a slow inference speed and low orientation estimation performance. We therefore investigate an improved sparse convolution method for such networks, which significantly increases the speed of both training and inference. We also introduce a new form of angle loss regression to improve the orientation estimation performance and a new data augmentation approach that can enhance the convergence speed and performance. The proposed network produces state-of-the-art results on the KITTI 3D object detection benchmarks while maintaining a fast inference speed.
+## Abstract
-
+LiDAR-based or RGB-D-based object detection is used in numerous applications, ranging from autonomous driving to robot vision. Voxel-based 3D convolutional networks have been used for some time to enhance the retention of information when processing point cloud LiDAR data. However, problems remain, including a slow inference speed and low orientation estimation performance. We therefore investigate an improved sparse convolution method for such networks, which significantly increases the speed of both training and inference. We also introduce a new form of angle loss regression to improve the orientation estimation performance and a new data augmentation approach that can enhance the convergence speed and performance. The proposed network produces state-of-the-art results on the KITTI 3D object detection benchmarks while maintaining a fast inference speed.
-
-
-
## Introduction
-
-
We implement SECOND and provide the results and checkpoints on KITTI dataset.
-```
-@article{yan2018second,
- title={Second: Sparsely embedded convolutional detection},
- author={Yan, Yan and Mao, Yuxing and Li, Bo},
- journal={Sensors},
- year={2018},
- publisher={Multidisciplinary Digital Publishing Institute}
-}
-```
-
-## Results
+## Results and models
### KITTI
@@ -55,3 +40,15 @@ Note:
- See more details about metrics and data split on Waymo [HERE](https://github.com/open-mmlab/mmdetection3d/tree/master/configs/pointpillars). For implementation details, we basically follow the original settings. All of these results are achieved without bells-and-whistles, e.g. ensemble, multi-scale training and test augmentation.
- `FP16` means Mixed Precision (FP16) is adopted in training.
+
+## Citation
+
+```latex
+@article{yan2018second,
+ title={Second: Sparsely embedded convolutional detection},
+ author={Yan, Yan and Mao, Yuxing and Li, Bo},
+ journal={Sensors},
+ year={2018},
+ publisher={Multidisciplinary Digital Publishing Institute}
+}
+```
diff --git a/configs/smoke/README.md b/configs/smoke/README.md
index a7306eaa54..9c3a4bf3d8 100644
--- a/configs/smoke/README.md
+++ b/configs/smoke/README.md
@@ -1,37 +1,22 @@
# SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
-## Abstract
+> [SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation](https://arxiv.org/abs/2002.10111)
-
+
-Estimating 3D orientation and translation of objects is essential for infrastructure-less autonomous navigation and driving. In case of monocular vision, successful methods have been mainly based on two ingredients: (i) a network generating 2D region proposals, (ii) a R-CNN structure predicting 3D object pose by utilizing the acquired regions of interest. We argue that the 2D detection network is redundant and introduces non-negligible noise for 3D detection. Hence, we propose a novel 3D object detection method, named SMOKE, in this paper that predicts a 3D bounding box for each detected object by combining a single keypoint estimate with regressed 3D variables. As a second contribution, we propose a multi-step disentangling approach for constructing the 3D bounding box, which significantly improves both training convergence and detection accuracy. In contrast to previous 3D detection techniques, our method does not require complicated pre/post-processing, extra data, and a refinement stage. Despite of its structural simplicity, our proposed SMOKE network outperforms all existing monocular 3D detection methods on the KITTI dataset, giving the best state-of-the-art result on both 3D object detection and Bird's eye view evaluation.
+## Abstract
-
+Estimating 3D orientation and translation of objects is essential for infrastructure-less autonomous navigation and driving. In case of monocular vision, successful methods have been mainly based on two ingredients: (i) a network generating 2D region proposals, (ii) a R-CNN structure predicting 3D object pose by utilizing the acquired regions of interest. We argue that the 2D detection network is redundant and introduces non-negligible noise for 3D detection. Hence, we propose a novel 3D object detection method, named SMOKE, in this paper that predicts a 3D bounding box for each detected object by combining a single keypoint estimate with regressed 3D variables. As a second contribution, we propose a multi-step disentangling approach for constructing the 3D bounding box, which significantly improves both training convergence and detection accuracy. In contrast to previous 3D detection techniques, our method does not require complicated pre/post-processing, extra data, and a refinement stage. Despite of its structural simplicity, our proposed SMOKE network outperforms all existing monocular 3D detection methods on the KITTI dataset, giving the best state-of-the-art result on both 3D object detection and Bird's eye view evaluation.
-
-
-
## Introduction
-
-
We implement SMOKE and provide the results and checkpoints on KITTI dataset.
-```
-@inproceedings{liu2020smoke,
- title={Smoke: Single-stage monocular 3d object detection via keypoint estimation},
- author={Liu, Zechen and Wu, Zizhang and T{\'o}th, Roland},
- booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
- pages={996--997},
- year={2020}
-}
-```
-
-## Results
+## Results and models
### KITTI
@@ -48,3 +33,15 @@ Detailed performance on KITTI 3D detection (3D/BEV) is as follows, evaluated by
| Car | 16.92 / 22.97 | 13.85 / 18.32 | 11.90 / 15.88|
| Pedestrian | 11.13 / 12.61| 11.10 / 11.32 | 10.67 / 11.14|
| Cyclist | 0.99 / 1.47 | 0.54 / 0.65 | 0.55 / 0.67 |
+
+## Citation
+
+```latex
+@inproceedings{liu2020smoke,
+ title={Smoke: Single-stage monocular 3d object detection via keypoint estimation},
+ author={Liu, Zechen and Wu, Zizhang and T{\'o}th, Roland},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
+ pages={996--997},
+ year={2020}
+}
+```
diff --git a/configs/ssn/README.md b/configs/ssn/README.md
index eb027e9377..c1801397ce 100644
--- a/configs/ssn/README.md
+++ b/configs/ssn/README.md
@@ -1,36 +1,22 @@
# SSN: Shape Signature Networks for Multi-class Object Detection from Point Clouds
-## Abstract
+> [SSN: Shape Signature Networks for Multi-class Object Detection from Point Clouds](https://arxiv.org/abs/2004.02774)
-
+
-Multi-class 3D object detection aims to localize and classify objects of multiple categories from point clouds. Due to the nature of point clouds, i.e. unstructured, sparse and noisy, some features benefit-ting multi-class discrimination are underexploited, such as shape information. In this paper, we propose a novel 3D shape signature to explore the shape information from point clouds. By incorporating operations of symmetry, convex hull and chebyshev fitting, the proposed shape sig-nature is not only compact and effective but also robust to the noise, which serves as a soft constraint to improve the feature capability of multi-class discrimination. Based on the proposed shape signature, we develop the shape signature networks (SSN) for 3D object detection, which consist of pyramid feature encoding part, shape-aware grouping heads and explicit shape encoding objective. Experiments show that the proposed method performs remarkably better than existing methods on two large-scale datasets. Furthermore, our shape signature can act as a plug-and-play component and ablation study shows its effectiveness and good scalability.
+## Abstract
-
+Multi-class 3D object detection aims to localize and classify objects of multiple categories from point clouds. Due to the nature of point clouds, i.e. unstructured, sparse and noisy, some features benefit-ting multi-class discrimination are underexploited, such as shape information. In this paper, we propose a novel 3D shape signature to explore the shape information from point clouds. By incorporating operations of symmetry, convex hull and chebyshev fitting, the proposed shape sig-nature is not only compact and effective but also robust to the noise, which serves as a soft constraint to improve the feature capability of multi-class discrimination. Based on the proposed shape signature, we develop the shape signature networks (SSN) for 3D object detection, which consist of pyramid feature encoding part, shape-aware grouping heads and explicit shape encoding objective. Experiments show that the proposed method performs remarkably better than existing methods on two large-scale datasets. Furthermore, our shape signature can act as a plug-and-play component and ablation study shows its effectiveness and good scalability.
-
-
-
## Introduction
-
-
We implement PointPillars with Shape-aware grouping heads used in the SSN and provide the results and checkpoints on the nuScenes and Lyft dataset.
-```
-@inproceedings{zhu2020ssn,
- title={SSN: Shape Signature Networks for Multi-class Object Detection from Point Clouds},
- author={Zhu, Xinge and Ma, Yuexin and Wang, Tai and Xu, Yan and Shi, Jianping and Lin, Dahua},
- booktitle={Proceedings of the European Conference on Computer Vision},
- year={2020}
-}
-```
-
-## Results
+## Results and models
### NuScenes
@@ -54,3 +40,14 @@ Note:
The main difference of the shape-aware grouping heads with the original SECOND FPN heads is that the former groups objects with similar sizes and shapes together, and design shape-specific heads for each group. Heavier heads (with more convolutions and large strides) are designed for large objects while smaller heads for small objects. Note that there may appear different feature map sizes in the outputs, so an anchor generator tailored to these feature maps is also needed in the implementation.
Users could try other settings in terms of the head design. Here we basically refer to the implementation [HERE](https://github.com/xinge008/SSN).
+
+## Citation
+
+```latex
+@inproceedings{zhu2020ssn,
+ title={SSN: Shape Signature Networks for Multi-class Object Detection from Point Clouds},
+ author={Zhu, Xinge and Ma, Yuexin and Wang, Tai and Xu, Yan and Shi, Jianping and Lin, Dahua},
+ booktitle={Proceedings of the European Conference on Computer Vision},
+ year={2020}
+}
+```
diff --git a/configs/votenet/README.md b/configs/votenet/README.md
index 6293c5c8b3..1b847f8545 100644
--- a/configs/votenet/README.md
+++ b/configs/votenet/README.md
@@ -1,36 +1,22 @@
# Deep Hough Voting for 3D Object Detection in Point Clouds
-## Abstract
+> [Deep Hough Voting for 3D Object Detection in Point Clouds](https://arxiv.org/abs/1904.09664)
-
+
-Current 3D object detection methods are heavily influenced by 2D detectors. In order to leverage architectures in 2D detectors, they often convert 3D point clouds to regular grids (i.e., to voxel grids or to bird's eye view images), or rely on detection in 2D images to propose 3D boxes. Few works have attempted to directly detect objects in point clouds. In this work, we return to first principles to construct a 3D detection pipeline for point cloud data and as generic as possible. However, due to the sparse nature of the data -- samples from 2D manifolds in 3D space -- we face a major challenge when directly predicting bounding box parameters from scene points: a 3D object centroid can be far from any surface point thus hard to regress accurately in one step. To address the challenge, we propose VoteNet, an end-to-end 3D object detection network based on a synergy of deep point set networks and Hough voting. Our model achieves state-of-the-art 3D detection on two large datasets of real 3D scans, ScanNet and SUN RGB-D with a simple design, compact model size and high efficiency. Remarkably, VoteNet outperforms previous methods by using purely geometric information without relying on color images.
+## Abstract
-
+Current 3D object detection methods are heavily influenced by 2D detectors. In order to leverage architectures in 2D detectors, they often convert 3D point clouds to regular grids (i.e., to voxel grids or to bird's eye view images), or rely on detection in 2D images to propose 3D boxes. Few works have attempted to directly detect objects in point clouds. In this work, we return to first principles to construct a 3D detection pipeline for point cloud data and as generic as possible. However, due to the sparse nature of the data -- samples from 2D manifolds in 3D space -- we face a major challenge when directly predicting bounding box parameters from scene points: a 3D object centroid can be far from any surface point thus hard to regress accurately in one step. To address the challenge, we propose VoteNet, an end-to-end 3D object detection network based on a synergy of deep point set networks and Hough voting. Our model achieves state-of-the-art 3D detection on two large datasets of real 3D scans, ScanNet and SUN RGB-D with a simple design, compact model size and high efficiency. Remarkably, VoteNet outperforms previous methods by using purely geometric information without relying on color images.
-
-
-
## Introduction
-
-
We implement VoteNet and provide the result and checkpoints on ScanNet and SUNRGBD datasets.
-```
-@inproceedings{qi2019deep,
- author = {Qi, Charles R and Litany, Or and He, Kaiming and Guibas, Leonidas J},
- title = {Deep Hough Voting for 3D Object Detection in Point Clouds},
- booktitle = {Proceedings of the IEEE International Conference on Computer Vision},
- year = {2019}
-}
-```
-
-## Results
+## Results and models
### ScanNet
@@ -69,3 +55,14 @@ iou_loss=dict(type='AxisAlignedIoULoss', reduction='sum', loss_weight=10.0 / 3.0
| [PointNet++](./votenet_iouloss_8x8_scannet-3d-18class.py) | 3x |4.1||63.81|44.21|/|
For now, we only support calculating IoU loss for axis-aligned bounding boxes since the CUDA op of general 3D IoU calculation does not implement the backward method. Therefore, IoU loss can only be used for ScanNet dataset for now.
+
+## Citation
+
+```latex
+@inproceedings{qi2019deep,
+ author = {Qi, Charles R and Litany, Or and He, Kaiming and Guibas, Leonidas J},
+ title = {Deep Hough Voting for 3D Object Detection in Point Clouds},
+ booktitle = {Proceedings of the IEEE International Conference on Computer Vision},
+ year = {2019}
+}
+```