diff --git a/docs/en/advanced_guides/customize_datasets.md b/docs/en/advanced_guides/customize_datasets.md
index 202d23c13c..aec7520a30 100644
--- a/docs/en/advanced_guides/customize_datasets.md
+++ b/docs/en/advanced_guides/customize_datasets.md
@@ -213,7 +213,7 @@ The following dataset wrappers are supported in [MMEngine](https://github.com/op
### CombinedDataset
-MMPose provides `CombinedDataset` to combine multiple datasets with different annotations. A combined dataset can be defined in config files as:
+MMPose provides [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) to combine multiple datasets with different annotations. A combined dataset can be defined in config files as:
```python
dataset_1 = dict(
@@ -250,6 +250,6 @@ combined_dataset = dict(
- **MetaInfo of combined dataset** determines the annotation format. Either metainfo of a sub-dataset or a customed dataset metainfo is valid here. To custom a dataset metainfo, please refer to [Create a custom dataset_info config file for the dataset](#create-a-custom-datasetinfo-config-file-for-the-dataset).
-- **Converter transforms of sub-datasets** are applied when there exist mismatches of annotation format between sub-datasets and the combined dataset. For example, the number and order of keypoints might be different in the combined dataset and the sub-datasets. Then `KeypointConverter` can be used to unify the keypoints number and order.
+- **Converter transforms of sub-datasets** are applied when there exist mismatches of annotation format between sub-datasets and the combined dataset. For example, the number and order of keypoints might be different in the combined dataset and the sub-datasets. Then [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) can be used to unify the keypoints number and order.
-- More details about `CombinedDataset` and `KeypointConverter` can be found in Advanced Guides-[Training with Mixed Datasets](../user_guides/mixed_datasets.md).
+- More details about [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) and [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) can be found in [Advanced Guides - Training with Mixed Datasets](../user_guides/mixed_datasets.md).
diff --git a/docs/en/user_guides/inference.md b/docs/en/user_guides/inference.md
index 518b2e89d3..127c52ff74 100644
--- a/docs/en/user_guides/inference.md
+++ b/docs/en/user_guides/inference.md
@@ -9,11 +9,11 @@ In MMPose, a model is defined by a configuration file, while its pre-existing pa
## Inferencer: a Unified Inference Interface
-MMPose offers a comprehensive API for inference, known as `MMPoseInferencer`. This API enables users to perform inference on both images and videos using all the models supported by MMPose. Furthermore, the API provides automatic visualization of inference results and allows for the convenient saving of predictions.
+MMPose offers a comprehensive API for inference, known as [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24). This API enables users to perform inference on both images and videos using all the models supported by MMPose. Furthermore, the API provides automatic visualization of inference results and allows for the convenient saving of predictions.
### Basic Usage
-The `MMPoseInferencer` can be used in any Python program to perform pose estimation. Below is an example of inference on a given image using the pre-trained human pose estimator within the Python shell.
+The [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) can be used in any Python program to perform pose estimation. Below is an example of inference on a given image using the pre-trained human pose estimator within the Python shell.
```python
from mmpose.apis import MMPoseInferencer
@@ -80,7 +80,7 @@ python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
--pose2d 'human' --show --pred-out-dir 'predictions'
```
-The predictions will be save in `predictions/000000000785.json`. The argument names correspond with the `MMPoseInferencer`, which serves as an API.
+The predictions will be save in `predictions/000000000785.json`. The argument names correspond with the [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24), which serves as an API.
The inferencer is capable of processing a range of input types, which includes the following:
@@ -219,7 +219,7 @@ result = next(result_generator)
### Arguments of Inferencer
-The `MMPoseInferencer` offers a variety of arguments for customizing pose estimation, visualization, and saving predictions. Below is a list of the arguments available when initializing the inferencer and their descriptions:
+The [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) offers a variety of arguments for customizing pose estimation, visualization, and saving predictions. Below is a list of the arguments available when initializing the inferencer and their descriptions:
| Argument | Description |
| ---------------- | ---------------------------------------------------------------------------------------------------------------- |
@@ -233,7 +233,7 @@ The `MMPoseInferencer` offers a variety of arguments for customizing pose estima
| `device` | The device to perform the inference. If left `None`, the Inferencer will select the most suitable one. |
| `scope` | The namespace where the model modules are defined. |
-The inferencer is designed for both visualization and saving predictions. The table below presents the list of arguments available when using the `MMPoseInferencer` for inference, along with their compatibility with 2D and 3D inferencing:
+The inferencer is designed for both visualization and saving predictions. The table below presents the list of arguments available when using the [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) for inference, along with their compatibility with 2D and 3D inferencing:
| Argument | Description | 2D | 3D |
| ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- | --- | --- |
@@ -258,7 +258,7 @@ The inferencer is designed for both visualization and saving predictions. The ta
### Model Alias
-The MMPose library has predefined aliases for several frequently used models. These aliases can be utilized as a shortcut when initializing the `MMPoseInferencer`, as an alternative to providing the full model configuration name. Here are the available 2D model aliases and their corresponding configuration names:
+The MMPose library has predefined aliases for several frequently used models. These aliases can be utilized as a shortcut when initializing the [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24), as an alternative to providing the full model configuration name. Here are the available 2D model aliases and their corresponding configuration names:
| Alias | Configuration Name | Task | Pose Estimator | Detector |
| --------- | -------------------------------------------------- | ------------------------------- | -------------- | ------------------- |
diff --git a/docs/en/user_guides/mixed_datasets.md b/docs/en/user_guides/mixed_datasets.md
index 9478ddfd1e..041bd7c656 100644
--- a/docs/en/user_guides/mixed_datasets.md
+++ b/docs/en/user_guides/mixed_datasets.md
@@ -1,10 +1,10 @@
# Use Mixed Datasets for Training
-MMPose offers a convenient and versatile solution for training with mixed datasets through its `CombinedDataset` tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing `CombinedDataset` is illustrated in the following figure.
+MMPose offers a convenient and versatile solution for training with mixed datasets through its [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) is illustrated in the following figure.
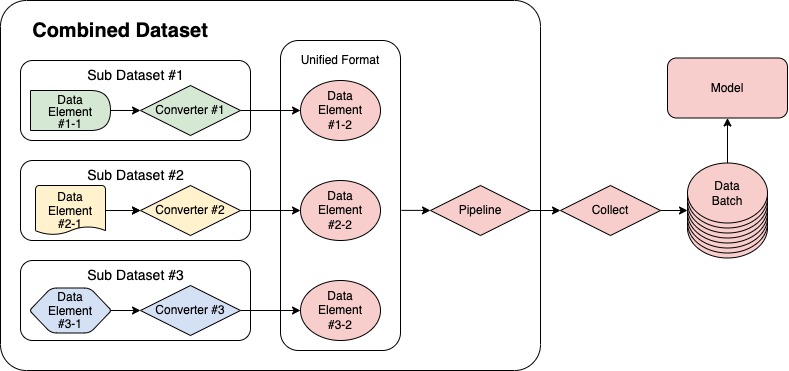
-The following section will provide a detailed description of how to configure `CombinedDataset` with an example that combines the COCO and AI Challenger (AIC) datasets.
+The following section will provide a detailed description of how to configure [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) with an example that combines the COCO and AI Challenger (AIC) datasets.
## COCO & AIC example
@@ -39,7 +39,7 @@ dataset_coco = dict(
)
```
-For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a `KeypointConverter` transform to achieve this. Here's an example of how to configure the AIC sub dataset:
+For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) transform to achieve this. Here's an example of how to configure the AIC sub dataset:
```python
dataset_aic = dict(
@@ -70,9 +70,9 @@ dataset_aic = dict(
)
```
-By using the `KeypointConverter`, the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the `mapping` argument, they will be set as invisible and won't be used in training.
+By using the [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11), the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the `mapping` argument, they will be set as invisible and won't be used in training.
-Once the sub datasets are configured, the `CombinedDataset` wrapper can be defined as follows:
+Once the sub datasets are configured, the [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) wrapper can be defined as follows:
```python
dataset = dict(
@@ -100,7 +100,7 @@ The previously mentioned method discards some annotations in the AIC dataset. If

-In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using `KeypointConverter`:
+In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11):
```python
dataset_coco = dict(
@@ -172,7 +172,7 @@ When training with mixed datasets, users often encounter the problem of inconsis
### Adjust the sampling ratio of each sub dataset
-In `CombinedDataset`, we provide the `sample_ratio_factor` argument to adjust the sampling ratio of each sub dataset.
+In [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15), we provide the `sample_ratio_factor` argument to adjust the sampling ratio of each sub dataset.
For example:
diff --git a/docs/zh_cn/advanced_guides/customize_datasets.md b/docs/zh_cn/advanced_guides/customize_datasets.md
index 2ff16bf9d0..9d1db35ceb 100644
--- a/docs/zh_cn/advanced_guides/customize_datasets.md
+++ b/docs/zh_cn/advanced_guides/customize_datasets.md
@@ -217,14 +217,14 @@ test_dataloader = dict(
## 数据集封装
-目前 [MMEngine](https://github.com/open-mmlab/mmengine) 支持以下数据集封装:
+在 MMPose 中,支持使用 MMPose 实现的数据集封装和 [MMEngine](https://github.com/open-mmlab/mmengine) 实现的数据集封装。目前 [MMEngine](https://github.com/open-mmlab/mmengine) 支持以下数据集封装:
- [ConcatDataset](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html#concatdataset)
- [RepeatDataset](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html#repeatdataset)
### CombinedDataset
-MMPose 提供了一个 `CombinedDataset` 类,它可以将多个数据集封装成一个数据集。它的使用方法如下:
+MMPose 提供了一个 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 类,它可以将多个数据集封装成一个数据集。它的使用方法如下:
```python
dataset_1 = dict(
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index 4017b32d84..f8efa74dc9 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -1,18 +1,18 @@
# 使用现有模型进行推理
-MMPose为姿态估计提供了大量可以从[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到的预测训练模型。本指南将演示**如何执行推理**,或使用训练过的模型对提供的图像或视频运行姿态估计。
+MMPose 为姿态估计提供了大量可以从 [模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html) 中找到的预测训练模型。本指南将演示**如何执行推理**,或使用训练过的模型对提供的图像或视频运行姿态估计。
有关在标准数据集上测试现有模型的说明,请参阅本指南。
-在MMPose,模型由配置文件定义,而其已计算好的参数存储在权重文件(checkpoint file)中。您可以在[模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html)中找到模型配置文件和相应的权重文件的URL。我们建议从使用HRNet模型的[配置文件](https://github.com/open-mmlab/mmpose/blob/main/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py)和[权重文件](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth)开始。
+在 MMPose,模型由配置文件定义,而其已计算好的参数存储在权重文件(checkpoint file)中。您可以在 [模型库](https://mmpose.readthedocs.io/en/latest/model_zoo.html) 中找到模型配置文件和相应的权重文件的 URL。我们建议从使用 HRNet 模型的[配置文件](https://github.com/open-mmlab/mmpose/blob/main/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py)和 [权重文件](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth) 开始。
## 推理器:统一的推理接口
-MMPose提供了一个被称为`MMPoseInferencer`的、全面的推理API。这个API使得用户得以使用所有MMPose支持的模型来对图像和视频进行模型推理。此外,该API可以完成推理结果自动化,并方便用户保存预测结果。
+MMPose提供了一个被称为 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 的、全面的推理 API。这个 API 使得用户得以使用所有 MMPose 支持的模型来对图像和视频进行模型推理。此外,该API可以完成推理结果自动化,并方便用户保存预测结果。
### 基本用法
-`MMPoseInferencer`可以在任何Python程序中被用来执行姿态估计任务。以下是在一个在Python Shell中使用预训练的人体姿态模型对给定图像进行推理的示例。
+[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 可以在任何 Python 程序中被用来执行姿态估计任务。以下是在一个在 Python Shell 中使用预训练的人体姿态模型对给定图像进行推理的示例。
```python
from mmpose.apis import MMPoseInferencer
@@ -75,7 +75,7 @@ python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
--pose2d 'human' --show --pred-out-dir 'predictions'
```
-预测结果将被保存在路径`predictions/000000000785.json`。作为一个API,`inferencer_demo.py`的输入参数与`MMPoseInferencer`的相同。前者能够处理一系列输入类型,包括以下内容:
+预测结果将被保存在路径 `predictions/000000000785.json` 。作为一个API,`inferencer_demo.py` 的输入参数与 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 的相同。前者能够处理一系列输入类型,包括以下内容:
- 图像路径
@@ -87,7 +87,7 @@ python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \
- 表示图像的 numpy array 列表 (在命令行界面工具中未支持)
-- 摄像头(在这种情况下,输入参数应该设置为`webcam`或`webcam:{CAMERA_ID}`)
+- 摄像头(在这种情况下,输入参数应该设置为 `webcam` 或 `webcam:{CAMERA_ID}`)
当输入对应于多个图像时,例如输入为**视频**或**文件夹**路径时,推理生成器必须被遍历,以便推理器对视频/文件夹中的所有帧/图像进行推理。以下是一个示例:
@@ -102,7 +102,7 @@ results = [result for result in result_generator]
### 自定义姿态估计模型
-`MMPoseInferencer`提供了几种可用于自定义所使用的模型的方法:
+[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了几种可用于自定义所使用的模型的方法:
```python
# 使用模型别名构建推断器
@@ -122,7 +122,7 @@ inferencer = MMPoseInferencer(
模型别名的完整列表可以在模型别名部分中找到。
-此外,自顶向下的姿态估计器还需要一个对象检测模型。`MMPoseInferencer`能够推断用MMPose支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型:
+此外,自顶向下的姿态估计器还需要一个对象检测模型。[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 能够推断用 MMPose 支持的数据集训练的模型的实例类型,然后构建必要的对象检测模型。用户也可以通过以下方式手动指定检测模型:
```python
# 通过别名指定检测模型
@@ -157,29 +157,29 @@ inferencer = MMPoseInferencer(
在执行姿态估计推理任务之后,您可能希望保存结果以供进一步分析或处理。本节将指导您将预测的关键点和可视化结果保存到本地。
-要将预测保存在JSON文件中,在运行`MMPoseInferencer`的实例`inferencer`时使用`pred_out_dir`参数:
+要将预测保存在JSON文件中,在运行 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 的实例 `inferencer` 时使用 `pred_out_dir` 参数:
```python
result_generator = inferencer(img_path, pred_out_dir='predictions')
result = next(result_generator)
```
-预测结果将以JSON格式保存在`predictions/`文件夹中,每个文件以相应的输入图像或视频的名称命名。
+预测结果将以 JSON 格式保存在 `predictions/` 文件夹中,每个文件以相应的输入图像或视频的名称命名。
-对于更高级的场景,还可以直接从`inferencer`返回的`result`字典中访问预测结果。其中,`predictions`包含输入图像或视频中每个单独实例的预测关键点列表。然后,您可以使用您喜欢的方法操作或存储这些结果。
+对于更高级的场景,还可以直接从 `inferencer` 返回的 `result` 字典中访问预测结果。其中,`predictions` 包含输入图像或视频中每个单独实例的预测关键点列表。然后,您可以使用您喜欢的方法操作或存储这些结果。
-请记住,如果你想将可视化图像和预测文件保存在一个文件夹中,你可以使用`out_dir`参数:
+请记住,如果你想将可视化图像和预测文件保存在一个文件夹中,你可以使用 `out_dir` 参数:
```python
result_generator = inferencer(img_path, out_dir='output')
result = next(result_generator)
```
-在这种情况下,可视化图像将保存在`output/visualization/`文件夹中,而预测将存储在`output/forecasts/`文件夹中。
+在这种情况下,可视化图像将保存在 `output/visualization/` 文件夹中,而预测将存储在 `output/forecasts/` 文件夹中。
### 可视化
-推理器`inferencer`可以自动对输入的图像或视频进行预测。可视化结果可以显示在一个新的窗口中,并保存在本地。
+推理器 `inferencer` 可以自动对输入的图像或视频进行预测。可视化结果可以显示在一个新的窗口中,并保存在本地。
要在新窗口中查看可视化结果,请使用以下代码:
@@ -187,7 +187,7 @@ result = next(result_generator)
- 如果输入视频来自网络摄像头,默认情况下将在新窗口中显示可视化结果,以此让用户看到输入
-- 如果平台上没有GUI,这个步骤可能会卡住
+- 如果平台上没有 GUI,这个步骤可能会卡住
要将可视化结果保存在本地,可以像这样指定`vis_out_dir`参数:
@@ -196,9 +196,9 @@ result_generator = inferencer(img_path, vis_out_dir='vis_results')
result = next(result_generator)
```
-输入图片或视频的可视化预测结果将保存在`vis_results/`文件夹中
+输入图片或视频的可视化预测结果将保存在 `vis_results/` 文件夹中
-在开头展示的滑雪图中,姿态的可视化估计结果由关键点(用实心圆描绘)和骨架(用线条表示)组成。这些视觉元素的默认大小可能不会产生令人满意的结果。用户可以使用`radius`和`thickness`参数来调整圆的大小和线的粗细,如下所示:
+在开头展示的滑雪图中,姿态的可视化估计结果由关键点(用实心圆描绘)和骨架(用线条表示)组成。这些视觉元素的默认大小可能不会产生令人满意的结果。用户可以使用 `radius` 和 `thickness` 参数来调整圆的大小和线的粗细,如下所示:
```python
result_generator = inferencer(img_path, show=True, radius=4, thickness=2)
@@ -207,7 +207,7 @@ result = next(result_generator)
### 推理器参数
-`MMPoseInferencer`提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述:
+[MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 提供了各种自定义姿态估计、可视化和保存预测结果的参数。下面是初始化推断器时可用的参数列表及对这些参数的描述:
| Argument | Description |
| ---------------- | ------------------------------------------------------------ |
@@ -221,7 +221,7 @@ result = next(result_generator)
| `device` | 执行推理的设备。如果为 `None`,推理器将选择最合适的一个。 |
| `scope` | 定义模型模块的名称空间 |
-推理器被设计用于可视化和保存预测。以下表格列出了在使用 `MMPoseInferencer` 进行推断时可用的参数列表,以及它们与 2D 和 3D 推理器的兼容性:
+推理器被设计用于可视化和保存预测。以下表格列出了在使用 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 进行推断时可用的参数列表,以及它们与 2D 和 3D 推理器的兼容性:
| 参数 | 描述 | 2D | 3D |
| ------------------------- | -------------------------------------------------------------------------------------------------------------------------- | --- | --- |
@@ -246,7 +246,7 @@ result = next(result_generator)
### 模型别名
-MMPose为常用模型提供了一组预定义的别名。在初始化 `MMPoseInferencer` 时,这些别名可以用作简略的表达方式,而不是指定完整的模型配置名称。下面是可用的模型别名及其对应的配置名称的列表:
+MMPose 为常用模型提供了一组预定义的别名。在初始化 [MMPoseInferencer](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/apis/inferencers/mmpose_inferencer.py#L24) 时,这些别名可以用作简略的表达方式,而不是指定完整的模型配置名称。下面是可用的模型别名及其对应的配置名称的列表:
| 别名 | 配置文件名称 | 对应任务 | 姿态估计模型 | 检测模型 |
| --------- | -------------------------------------------------- | ------------------------------- | ------------- | ------------------- |
diff --git a/docs/zh_cn/user_guides/mixed_datasets.md b/docs/zh_cn/user_guides/mixed_datasets.md
index d62ace5f5d..6839da3b3d 100644
--- a/docs/zh_cn/user_guides/mixed_datasets.md
+++ b/docs/zh_cn/user_guides/mixed_datasets.md
@@ -1,10 +1,10 @@
# 混合数据集训练
-MMPose 提供了一个灵活、便捷的工具 `CombinedDataset` 来进行混合数据集训练。它作为一个封装器,可以包含多个子数据集,并将来自不同子数据集的数据转换成一个统一的格式,以用于模型训练。使用 `CombinedDataset` 的数据处理流程如下图所示。
+MMPose 提供了一个灵活、便捷的工具 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 来进行混合数据集训练。它作为一个封装器,可以包含多个子数据集,并将来自不同子数据集的数据转换成一个统一的格式,以用于模型训练。使用 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 的数据处理流程如下图所示。

-本篇教程的后续部分将通过一个结合 COCO 和 AI Challenger (AIC) 数据集的例子详细介绍如何配置 `CombinedDataset`。
+本篇教程的后续部分将通过一个结合 COCO 和 AI Challenger (AIC) 数据集的例子详细介绍如何配置 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15)。
## COCO & AIC 数据集混合案例
@@ -39,7 +39,7 @@ dataset_coco = dict(
)
```
-对于 AIC 数据集,需要转换关键点的顺序。MMPose 提供了一个 `KeypointConverter` 转换器来实现这一点。以下是配置 AIC 子数据集的示例:
+对于 AIC 数据集,需要转换关键点的顺序。MMPose 提供了一个 [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) 转换器来实现这一点。以下是配置 AIC 子数据集的示例:
```python
dataset_aic = dict(
@@ -70,9 +70,9 @@ dataset_aic = dict(
)
```
-`KeypointConverter` 会将原序号在 0 到 11 之间的关键点的序号转换为在 5 到 16 之间的对应序号。同时,在 AIC 中序号为为 12 和 13 的关键点将被删除。另外,目标序号在 0 到 4 之间的关键点在 `mapping` 参数中没有定义,这些点将被设为不可见,并且不会在训练中使用。
+[KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) 会将原序号在 0 到 11 之间的关键点的序号转换为在 5 到 16 之间的对应序号。同时,在 AIC 中序号为为 12 和 13 的关键点将被删除。另外,目标序号在 0 到 4 之间的关键点在 `mapping` 参数中没有定义,这些点将被设为不可见,并且不会在训练中使用。
-子数据集都完成配置后, 混合数据集 `CombinedDataset` 可以通过如下方式配置:
+子数据集都完成配置后, 混合数据集 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 可以通过如下方式配置:
```python
dataset = dict(
@@ -98,7 +98,7 @@ MMPose 提供了一份完整的 [配置文件](https://github.com/open-mmlab/mmp
-在这种情况下,COCO 和 AIC 数据集都需要使用 `KeypointConverter` 来调整它们关键点的顺序:
+在这种情况下,COCO 和 AIC 数据集都需要使用 [KeypointConverter](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/converting.py#L11) 来调整它们关键点的顺序:
```python
dataset_coco = dict(
@@ -145,7 +145,7 @@ dataset_aic = dict(
- 在 `skeleton_info` 中添加了“头顶”和“颈部”间的连线;
- 拓展 `joint_weights` 和 `sigmas` 以添加新增关键点的信息。
-完成以上步骤后,合并数据集 `CombinedDataset` 可以通过以下方式配置:
+完成以上步骤后,合并数据集 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 可以通过以下方式配置:
```python
dataset = dict(
@@ -170,7 +170,7 @@ dataset = dict(
### 调整每个子数据集的采样比例
-在 `CombinedDataset` 中,我们提供了 `sample_ratio_factor` 参数来调整每个子数据集的采样比例。
+在 [CombinedDataset](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/dataset_wrappers.py#L15) 中,我们提供了 `sample_ratio_factor` 参数来调整每个子数据集的采样比例。
例如: