
diff --git a/projects/rtmpose/README.md b/projects/rtmpose/README.md
index c52f4a6970..b722d4cec8 100644
--- a/projects/rtmpose/README.md
+++ b/projects/rtmpose/README.md
@@ -44,13 +44,22 @@ ______________________________________________________________________
## 🥳 🚀 What's New [🔝](#-table-of-contents)
+- Aug. 2023:
+ - Support distilled 133-keypoint WholeBody models powered by [DWPose](https://github.com/IDEA-Research/DWPose/tree/main).
+ - You can try DWPose/RTMPose with [sd-webui-controlnet](https://github.com/Mikubill/sd-webui-controlnet) now! Just update your sd-webui-controlnet >= v1.1237, then choose `dw_openpose_full` as preprocessor.
+ - You can try our DWPose with this [Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) by choosing `wholebody`!
- Jul. 2023:
+ - Add [Online RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose).
- Support 17-keypoint Body models trained on Human-Art.
- - Support 133-keypoint WholeBody models trained on combined datasets.
- Jun. 2023:
- Release 26-keypoint Body models trained on combined datasets.
- May. 2023:
- - Add [code examples](./examples/) of RTMPose.
+ - Exported SDK models (ONNX, TRT, ncnn, etc.) can be downloaded from [OpenMMLab Deploee](https://platform.openmmlab.com/deploee).
+ - [Online Conversion](https://platform.openmmlab.com/deploee/task-convert-list) of `.pth` models into SDK models (ONNX, TensorRT, ncnn, etc.).
+ - Add [code examples](./examples/) of RTMPose, such as:
+ - Pure Python inference without MMDeploy, MMCV etc.
+ - C++ examples with ONNXRuntime and TensorRT backends.
+ - Android examples with ncnn backend.
- Release Hand, Face, Body models trained on combined datasets.
- Mar. 2023: RTMPose is released. RTMPose-m runs at 430+ FPS and achieves 75.8 mAP on COCO val set.
@@ -137,6 +146,7 @@ Feel free to join our community group for more help:
- ncnn 20221128
- cuDNN 8.3.2
- CUDA 11.3
+- **Updates**: We recommend you to try `Body8` models trained on combined datasets, see [here](#body-2d).
| Detection Config | Pose Config | Input Size
(Det/Pose) | Model AP
(COCO) | Pipeline AP
(COCO) | Params (M)
(Det/Pose) | Flops (G)
(Det/Pose) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Download |
| :------------------------------------------------------------------ | :---------------------------------------------------------------------------- | :---------------------------: | :---------------------: | :------------------------: | :---------------------------: | :--------------------------: | :--------------------------------: | :---------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
@@ -167,14 +177,14 @@ Feel free to join our community group for more help:
AIC+COCO
-| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
-| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------: |
-| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) |
-| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) |
-| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) |
-| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) |
-| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) |
-| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) |
+| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
+| :---------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------: |
+| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 91.28 | 63.38 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) |
+| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 92.95 | 66.19 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) |
+| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 94.13 | 68.53 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) |
+| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 94.35 | 68.98 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) |
+| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 94.32 | 69.85 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) |
+| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 94.54 | 70.14 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) |
@@ -191,15 +201,15 @@ Feel free to join our community group for more help:
- [PoseTrack18](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#posetrack18)
- `Body8` denotes the addition of the [OCHuman](https://mmpose.readthedocs.io/en/latest/dataset_zoo/2d_body_keypoint.html#ochuman) dataset, in addition to the 7 datasets mentioned above, for evaluation.
-| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
-| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------: |
-| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth) |
-| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth) |
-| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth) |
-| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth) |
-| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth) |
-| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth) |
-| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth) |
+| Config | Input Size | AP
(COCO) | PCK@0.1
(Body8) | AUC
(Body8) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
+| :-----------------------------------------------------------------------------: | :--------: | :---------------: | :---------------------: | :-----------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------: |
+| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.9 | 91.44 | 63.18 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7_420e-256x192-026a1439_20230504.pth) |
+| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.7 | 92.45 | 65.15 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7_420e-256x192-acd4a1ef_20230504.pth) |
+| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 74.9 | 94.25 | 68.59 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-256x192-e48f03d0_20230504.pth) |
+| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.7 | 95.08 | 70.14 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-256x192-4dba18fc_20230504.pth) |
+| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 76.6 | 94.64 | 70.38 | 13.72 | 4.33 | 24.78 | 3.66 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7_420e-384x288-65e718c4_20230504.pth) |
+| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 78.3 | 95.36 | 71.58 | 27.79 | 9.35 | - | 6.05 | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7_420e-384x288-3f5a1437_20230504.pth) |
+| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_coco-384x288.py) | 384x288 | 78.8 | - | - | 49.43 | 17.22 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7_700e-384x288-71d7b7e9_20230629.pth) |
@@ -209,12 +219,12 @@ Feel free to join our community group for more help:
- RTMPose for Human-Centric Artificial Scenes is supported by [Human-Art](https://github.com/IDEA-Research/HumanArt)
-  -| Config | Input Size | AP
-| Config | Input Size | AP
(Human-Art GT) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
-| :-----------------------------------------------------------------------------: | :--------: | :-----------------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------: |
-| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.5 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.pth) |
-| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.8 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.pth) |
-| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 72.8 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.pth) |
-| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 75.3 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.pth) |
+| Config | Input Size | AP
(Human-Art GT) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
+| :-----------------------------------------------------------------------------: | :--------: | :-----------------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------: |
+| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 65.5 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_8xb256-420e_humanart-256x192-60b68c98_20230612.pth) |
+| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 69.8 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_8xb256-420e_humanart-256x192-5a3ac943_20230611.pth) |
+| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 72.8 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_8xb256-420e_humanart-256x192-8430627b_20230611.pth) |
+| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 75.3 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_8xb256-420e_humanart-256x192-389f2cb0_20230611.pth) |
@@ -224,15 +234,15 @@ Feel free to join our community group for more help:
-  - Models are trained and evaluated on `Body8`.
-| Config | Input Size | PCK@0.1
- Models are trained and evaluated on `Body8`.
-| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
-| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------: |
-| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth) |
-| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth) |
-| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth) |
-| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth) |
-| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth) |
-| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth) |
-| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth) |
+| Config | Input Size | PCK@0.1
(Body8) | AUC
(Body8) | Params(M) | FLOPS(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
+| :---------------------------------------------------------------------------------------: | :--------: | :---------------------: | :-----------------: | :-------: | :------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------: |
+| [RTMPose-t\*](./rtmpose/body_2d_keypoint/rtmpose-t_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 91.89 | 66.35 | 3.51 | 0.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-body7_pt-body7-halpe26_700e-256x192-6020f8a6_20230605.pth) |
+| [RTMPose-s\*](./rtmpose/body_2d_keypoint/rtmpose-s_8xb1024-700e_body8-halpe26-256x192.py) | 256x192 | 93.01 | 68.62 | 5.70 | 0.70 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-body7_pt-body7-halpe26_700e-256x192-7f134165_20230605.pth) |
+| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 94.75 | 71.91 | 13.93 | 1.95 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-256x192-4d3e73dd_20230605.pth) |
+| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-256x192.py) | 256x192 | 95.37 | 73.19 | 28.11 | 4.19 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-256x192-2abb7558_20230605.pth) |
+| [RTMPose-m\*](./rtmpose/body_2d_keypoint/rtmpose-m_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.15 | 73.56 | 14.06 | 4.37 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-body7_pt-body7-halpe26_700e-384x288-89e6428b_20230605.pth) |
+| [RTMPose-l\*](./rtmpose/body_2d_keypoint/rtmpose-l_8xb512-700e_body8-halpe26-384x288.py) | 384x288 | 95.56 | 74.38 | 28.24 | 9.40 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-body7_pt-body7-halpe26_700e-384x288-734182ce_20230605.pth) |
+| [RTMPose-x\*](./rtmpose/body_2d_keypoint/rtmpose-x_8xb256-700e_body8-halpe26-384x288.py) | 384x288 | 95.74 | 74.82 | 50.00 | 17.29 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-body7_pt-body7-halpe26_700e-384x288-7fb6e239_20230606.pth) |
#### Model Pruning
@@ -240,9 +250,9 @@ Feel free to join our community group for more help:
- Model pruning is supported by [MMRazor](https://github.com/open-mmlab/mmrazor)
-| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
-| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------: |
-| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [Model](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) |
+| Config | Input Size | AP
(COCO) | Params
(M) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | ncnn-FP16-Latency
(ms)
(Snapdragon 865) | Download |
+| :-----------------------: | :--------: | :---------------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-----------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------: |
+| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [pth](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) |
For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pruning/README.md).
@@ -256,10 +266,10 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
| Config | Input Size | Whole AP | Whole AR | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: |
-| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) |
-| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) |
-| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) |
-| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) |
+| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 58.2 | 67.4 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) |
+| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 61.1 | 70.0 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) |
+| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 64.8 | 73.0 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) |
+| [RTMPose-x](./rtmpose/wholebody_2d_keypoint/rtmpose-x_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 65.3 | 73.3 | 18.1 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-x_simcc-coco-wholebody_pt-body7_270e-384x288-401dfc90_20230629.pth) |
@@ -273,11 +283,11 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
| Config | Input Size | Whole AP | Whole AR | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
| :------------------------------ | :--------: | :------: | :------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :-------------------------------: |
-| [RTMPose-t](./rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 48.5 | 58.4 | 2.22 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) |
-| [RTMPose-s](./rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 53.8 | 63.2 | 4.52 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth) |
-| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth) |
-| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth) |
-| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth) |
+| [RTMPose-t](./rtmpose/wholebody_2d_keypoint/rtmpose-t_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 48.5 | 58.4 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-ucoco_dw-ucoco_270e-256x192-dcf277bf_20230728.pth) |
+| [RTMPose-s](./rtmpose/wholebody_2d_keypoint/rtmpose-s_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 53.8 | 63.2 | - | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-ucoco_dw-ucoco_270e-256x192-3fd922c8_20230728.pth) |
+| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.6 | 69.5 | 2.22 | 13.50 | 4.00 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ucoco_dw-ucoco_270e-256x192-c8b76419_20230728.pth) |
+| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.1 | 71.7 | 4.52 | 23.41 | 5.67 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-256x192-4d6dfc62_20230728.pth) |
+| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 66.5 | 74.3 | 10.07 | 44.58 | 7.68 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-l_simcc-ucoco_dw-ucoco_270e-384x288-2438fd99_20230728.pth) |
@@ -288,7 +298,7 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
| Config | Input Size | AP
(AP10K) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
| :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: |
-| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth) |
+| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth) |
### Face 2d (106 Keypoints)
@@ -308,9 +318,9 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
| Config | Input Size | NME
(LaPa) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
| :----------------------------: | :--------: | :----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------: |
-| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) |
-| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) |
-| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) |
+| [RTMPose-t\*](./rtmpose/face_2d_keypoint/rtmpose-t_8xb256-120e_lapa-256x256.py) | 256x256 | 1.67 | 0.652 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-t_simcc-face6_pt-in1k_120e-256x256-df79d9a5_20230529.pth) |
+| [RTMPose-s\*](./rtmpose/face_2d_keypoint/rtmpose-s_8xb256-120e_lapa-256x256.py) | 256x256 | 1.59 | 1.119 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-s_simcc-face6_pt-in1k_120e-256x256-d779fdef_20230529.pth) |
+| [RTMPose-m\*](./rtmpose/face_2d_keypoint/rtmpose-m_8xb256-120e_lapa-256x256.py) | 256x256 | 1.44 | 2.852 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-face6_pt-in1k_120e-256x256-72a37400_20230529.pth) |
@@ -333,9 +343,9 @@ For more details, please refer to [GroupFisher Pruning for RTMPose](./rtmpose/pr
- [RHD2d](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html)
- [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/)
-| Config | Input Size | PCK@0.2
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
-| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------: |
-| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth) |
+| Config | Input Size | PCK@0.2
(COCO-Wholebody-Hand) | PCK@0.2
(Hand5) | AUC
(Hand5) | FLOPS
(G) | ORT-Latency
(ms)
(i7-11700) | TRT-FP16-Latency
(ms)
(GTX 1660Ti) | Download |
+| :-------------------------------------------------------------------------------------------------------------------: | :--------: | :-----------------------------------: | :---------------------: | :-----------------: | :---------------: | :-----------------------------------------: | :------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------: |
+| [RTMPose-m\*
(alpha version)](./rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | 96.4 | 83.9 | 2.581 | - | - | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-hand5_pt-aic-coco_210e-256x256-74fb594_20230320.pth) |
@@ -348,10 +358,10 @@ We provide the UDP pretraining configs of the CSPNeXt backbone. Find more detail
| Model | Input Size | Params
(M) | Flops
(G) | AP
(GT) | AR
(GT) | Download |
| :----------: | :--------: | :----------------: | :---------------: | :-------------: | :-------------: | :---------------------------------------------------------------------------------------------------------------: |
-| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) |
-| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) |
-| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) |
-| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) |
+| CSPNeXt-tiny | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) |
+| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) |
+| CSPNeXt-m | 256x192 | 17.53 | 3.05 | 74.8 | 77.7 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) |
+| CSPNeXt-l | 256x192 | 32.44 | 5.32 | 77.2 | 79.9 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) |
@@ -370,13 +380,13 @@ We provide the UDP pretraining configs of the CSPNeXt backbone. Find more detail
| Model | Input Size | Params
(M) | Flops
(G) | AP
(COCO) | PCK@0.2
(Body8) | AUC
(Body8) | Download |
| :------------: | :--------: | :----------------: | :---------------: | :---------------: | :---------------------: | :-----------------: | :--------------------------------------------------------------------------------: |
-| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) |
-| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) |
-| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) |
-| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) |
-| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) |
-| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) |
-| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) |
+| CSPNeXt-tiny\* | 256x192 | 6.03 | 1.43 | 65.9 | 96.34 | 63.80 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-tiny_udp-body7_210e-256x192-a3775292_20230504.pth) |
+| CSPNeXt-s\* | 256x192 | 8.58 | 1.78 | 68.7 | 96.59 | 64.92 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-s_udp-body7_210e-256x192-8c9ccbdb_20230504.pth) |
+| CSPNeXt-m\* | 256x192 | 17.53 | 3.05 | 73.7 | 97.42 | 68.19 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-256x192-e0c9327b_20230504.pth) |
+| CSPNeXt-l\* | 256x192 | 32.44 | 5.32 | 75.7 | 97.76 | 69.57 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-256x192-5e9558ef_20230504.pth) |
+| CSPNeXt-m\* | 384x288 | 17.53 | 6.86 | 75.8 | 97.60 | 70.18 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-m_udp-body7_210e-384x288-b9bc2b57_20230504.pth) |
+| CSPNeXt-l\* | 384x288 | 32.44 | 11.96 | 77.2 | 97.89 | 71.23 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-l_udp-body7_210e-384x288-b15bc30d_20230504.pth) |
+| CSPNeXt-x\* | 384x288 | 54.92 | 19.96 | 78.1 | 98.00 | 71.79 | [pth](https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/cspnext-x_udp-body7_210e-384x288-d28b58e6_20230529.pth) |
@@ -386,11 +396,11 @@ We also provide the ImageNet classification pre-trained weights of the CSPNeXt b
| Model | Input Size | Params
(M) | Flops
(G) | Top-1 (%) | Top-5 (%) | Download |
| :----------: | :--------: | :----------------: | :---------------: | :-------: | :-------: | :---------------------------------------------------------------------------------------------------------------------------: |
-| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) |
-| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) |
-| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) |
-| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) |
-| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) |
+| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) |
+| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) |
+| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) |
+| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) |
+| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [pth](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) |
## 👀 Visualization [🔝](#-table-of-contents)
@@ -403,8 +413,10 @@ We also provide the ImageNet classification pre-trained weights of the CSPNeXt b
We provide two appoaches to try RTMPose:
-- MMPose demo scripts
-- Pre-compiled MMDeploy SDK (Recommend, 6-10 times faster)
+- [Online RTMPose Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose)
+- [Examples](https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmpose/examples/onnxruntime) based on Python and ONNXRuntime (without mmcv)
+- MMPose demo scripts (based on Pytorch)
+- Pre-compiled MMDeploy SDK (Recommended, 6-10 times faster)
### MMPose demo scripts
diff --git a/projects/rtmpose/README_CN.md b/projects/rtmpose/README_CN.md
index bed9809020..1a73b2d988 100644
--- a/projects/rtmpose/README_CN.md
+++ b/projects/rtmpose/README_CN.md
@@ -40,13 +40,22 @@ ______________________________________________________________________
## 🥳 最新进展 [🔝](#-table-of-contents)
+- 2023 年 8 月:
+ - 支持基于 RTMPose 模型蒸馏的 133 点 WholeBody 模型(由 [DWPose](https://github.com/IDEA-Research/DWPose/tree/main) 提供)。
+ - 你可以在 [sd-webui-controlnet](https://github.com/Mikubill/sd-webui-controlnet) 中使用 DWPose/RTMPose 作为姿态估计后端进行人物图像生成。升级 sd-webui-controlnet >= v1.1237 并选择 `dw_openpose_full` 即可使用。
+ - [在线 Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose) 已支持 DWPose,试玩请选择 `wholebody`。
- 2023 年 7 月:
+ - 在线 RTMPose 试玩 [Demo](https://openxlab.org.cn/apps/detail/mmpose/RTMPose)。
- 支持面向艺术图片人体姿态估计的 17 点 Body 模型。
- - 支持混合数据集蒸馏训练的 133 点 WholeBody 模型。
- 2023 年 6 月:
- 发布混合数据集训练的 26 点 Body 模型。
- 2023 年 5 月:
- - 添加 [代码示例](./examples/)
+ - 已导出的 SDK 模型(ONNX、TRT、ncnn 等)可以从 [OpenMMLab Deploee](https://platform.openmmlab.com/deploee) 直接下载。
+ - [在线导出](https://platform.openmmlab.com/deploee/task-convert-list) SDK 模型(ONNX、TRT、ncnn 等)。
+ - 添加 [代码示例](./examples/),包括:
+ - 纯 Python 推理代码示例,无 MMDeploy、MMCV 依赖
+ - C++ 代码示例:ONNXRuntime、TensorRT
+ - Android 项目示例:基于 ncnn
- 发布混合数据集训练的 Hand, Face, Body 模型。
- 2023 年 3 月:发布 RTMPose。RTMPose-m 取得 COCO 验证集 75.8 mAP,推理速度达到 430+ FPS 。
@@ -128,6 +137,7 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
- TensorRT 8.4.3.1
- cuDNN 8.3.2
- CUDA 11.3
+- **更新**:我们推荐你使用混合数据集训练的 `Body8` 模型,性能高于下表中提供的模型,[传送门](#人体-2d-关键点)。
| Detection Config | Pose Config | Input Size
(Det/Pose) | Model AP
(COCO) | Pipeline AP
(COCO) | Params (M)
(Det/Pose) | Flops (G)
(Det/Pose) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Download |
| :------------------------------------------------------------------ | :---------------------------------------------------------------------------- | :---------------------------: | :---------------------: | :------------------------: | :---------------------------: | :--------------------------: | :--------------------------------: | :---------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
@@ -158,14 +168,14 @@ RTMPose 是一个长期优化迭代的项目,致力于业务场景下的高性
AIC+COCO
-| Config | Input Size | AP
(COCO) | PCK@0.1 
 diff --git a/projects/rtmpose/README.md b/projects/rtmpose/README.md
index dc5b0dbe23..41c77a0731 100644
--- a/projects/rtmpose/README.md
+++ b/projects/rtmpose/README.md
@@ -689,9 +689,10 @@ Before starting the deployment, please make sure you install MMPose and MMDeploy
Depending on the deployment backend, some backends require compilation of custom operators, so please refer to the corresponding document to ensure the environment is built correctly according to your needs:
-- [ONNX RUNTIME SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html)
-- [TENSORRT SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html)
-- [OPENVINO SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html)
+- [ONNX](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html)
+- [TensorRT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html)
+- [OpenVINO](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html)
+- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html)
- [More](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends)
### 🛠️ Step2. Convert Model
@@ -702,12 +703,20 @@ The detailed model conversion tutorial please refer to the [MMDeploy document](h
Here we take converting RTMDet-nano and RTMPose-m to ONNX/TensorRT as an example.
-- If you only want to use ONNX, please use:
+- ONNX
- [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_onnxruntime_static.py) for RTMDet.
- [`pose-detection_simcc_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py) for RTMPose.
-- If you want to use TensorRT, please use:
+- TensorRT
- [`detection_tensorrt_static-320x320.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_tensorrt_static-320x320.py) for RTMDet.
- [`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py) for RTMPose.
+- More
+ | Backend | Config |
+ | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+ | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) |
+ | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) |
+ | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) |
+ | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) |
+ | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) |
If you want to customize the settings in the deployment config for your requirements, please refer to [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/en/latest/02-how-to-run/write_config.html).
diff --git a/projects/rtmpose/README_CN.md b/projects/rtmpose/README_CN.md
index 30bddf9ecd..bf134ab260 100644
--- a/projects/rtmpose/README_CN.md
+++ b/projects/rtmpose/README_CN.md
@@ -683,6 +683,7 @@ python demo/topdown_demo_with_mmdet.py \
- [ONNX](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/onnxruntime.html)
- [TensorRT](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/tensorrt.html)
- [OpenVINO](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/openvino.html)
+- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html)
- [更多](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends)
### 🛠️ 模型转换
@@ -703,6 +704,16 @@ python demo/topdown_demo_with_mmdet.py \
\- RTMPose:[`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py)
+- 更多
+
+ | Backend | Config |
+ | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+ | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) |
+ | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) |
+ | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) |
+ | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) |
+ | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) |
+
如果你需要对部署配置进行修改,请参考 [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/zh_CN/latest/02-how-to-run/write_config.html).
本教程中使用的文件结构如下:
From 964bca7cbd8550fdc6a8d53cb9811916eac5a5c0 Mon Sep 17 00:00:00 2001
From: Tau
diff --git a/projects/rtmpose/README.md b/projects/rtmpose/README.md
index dc5b0dbe23..41c77a0731 100644
--- a/projects/rtmpose/README.md
+++ b/projects/rtmpose/README.md
@@ -689,9 +689,10 @@ Before starting the deployment, please make sure you install MMPose and MMDeploy
Depending on the deployment backend, some backends require compilation of custom operators, so please refer to the corresponding document to ensure the environment is built correctly according to your needs:
-- [ONNX RUNTIME SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html)
-- [TENSORRT SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html)
-- [OPENVINO SUPPORT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html)
+- [ONNX](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/onnxruntime.html)
+- [TensorRT](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/tensorrt.html)
+- [OpenVINO](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/openvino.html)
+- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html)
- [More](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends)
### 🛠️ Step2. Convert Model
@@ -702,12 +703,20 @@ The detailed model conversion tutorial please refer to the [MMDeploy document](h
Here we take converting RTMDet-nano and RTMPose-m to ONNX/TensorRT as an example.
-- If you only want to use ONNX, please use:
+- ONNX
- [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_onnxruntime_static.py) for RTMDet.
- [`pose-detection_simcc_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py) for RTMPose.
-- If you want to use TensorRT, please use:
+- TensorRT
- [`detection_tensorrt_static-320x320.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmdet/detection/detection_tensorrt_static-320x320.py) for RTMDet.
- [`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py) for RTMPose.
+- More
+ | Backend | Config |
+ | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+ | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) |
+ | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) |
+ | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) |
+ | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) |
+ | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) |
If you want to customize the settings in the deployment config for your requirements, please refer to [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/en/latest/02-how-to-run/write_config.html).
diff --git a/projects/rtmpose/README_CN.md b/projects/rtmpose/README_CN.md
index 30bddf9ecd..bf134ab260 100644
--- a/projects/rtmpose/README_CN.md
+++ b/projects/rtmpose/README_CN.md
@@ -683,6 +683,7 @@ python demo/topdown_demo_with_mmdet.py \
- [ONNX](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/onnxruntime.html)
- [TensorRT](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/tensorrt.html)
- [OpenVINO](https://mmdeploy.readthedocs.io/zh_CN/latest/05-supported-backends/openvino.html)
+- [TorchScript](https://mmdeploy.readthedocs.io/en/latest/05-supported-backends/torchscript.html)
- [更多](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/05-supported-backends)
### 🛠️ 模型转换
@@ -703,6 +704,16 @@ python demo/topdown_demo_with_mmdet.py \
\- RTMPose:[`pose-detection_simcc_tensorrt_dynamic-256x192.py`](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py)
+- 更多
+
+ | Backend | Config |
+ | :---------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+ | ncnn-fp16 | [pose-detection_simcc_ncnn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_ncnn-fp16_static-256x192.py) |
+ | CoreML | [pose-detection_simcc_coreml_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_coreml_static-256x192.py) |
+ | OpenVINO | [pose-detection_simcc_openvino_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_openvino_static-256x192.py) |
+ | RKNN | [pose-detection_simcc_rknn-fp16_static-256x192.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_simcc_rknn-fp16_static-256x192.py) |
+ | TorchScript | [pose-detection_torchscript.py](https://github.com/open-mmlab/mmdeploy/blob/main/configs/mmpose/pose-detection_torchscript.py) |
+
如果你需要对部署配置进行修改,请参考 [MMDeploy config tutorial](https://mmdeploy.readthedocs.io/zh_CN/latest/02-how-to-run/write_config.html).
本教程中使用的文件结构如下:
From 964bca7cbd8550fdc6a8d53cb9811916eac5a5c0 Mon Sep 17 00:00:00 2001
From: Tau 
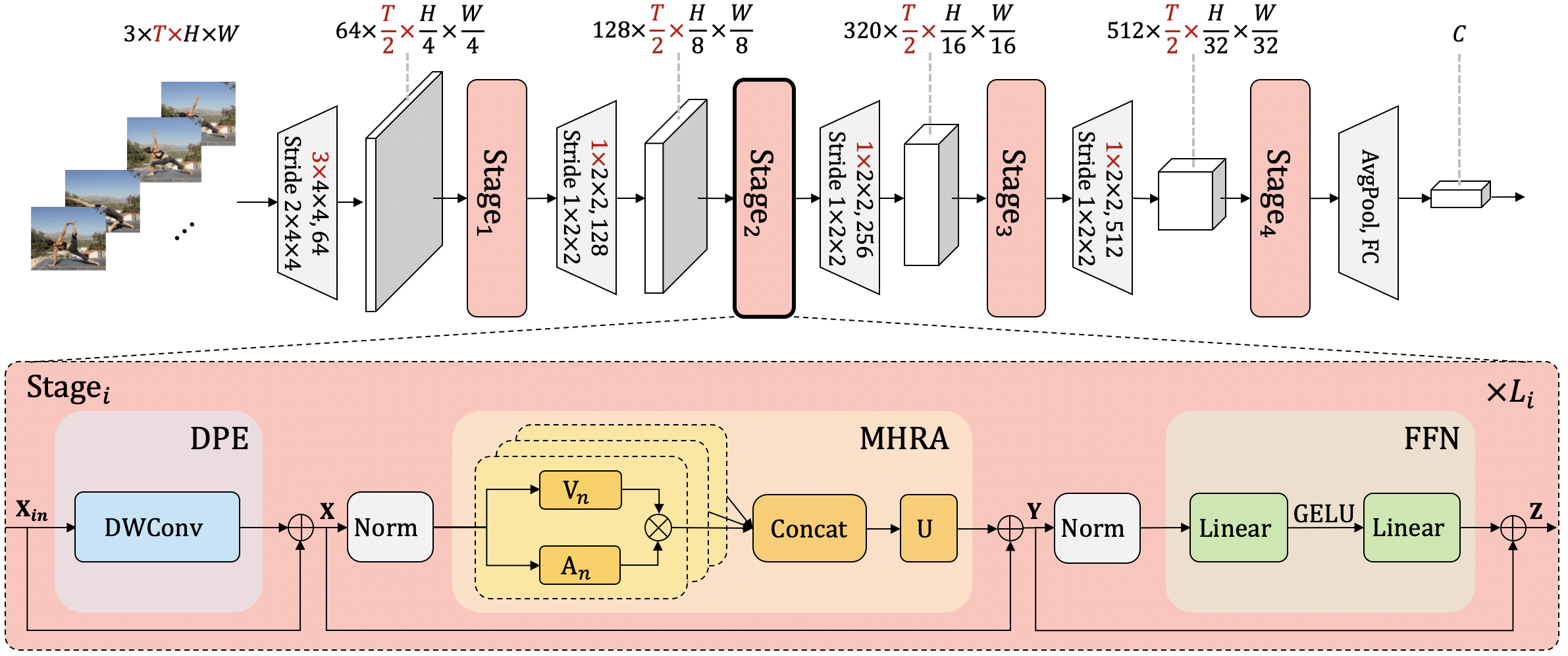
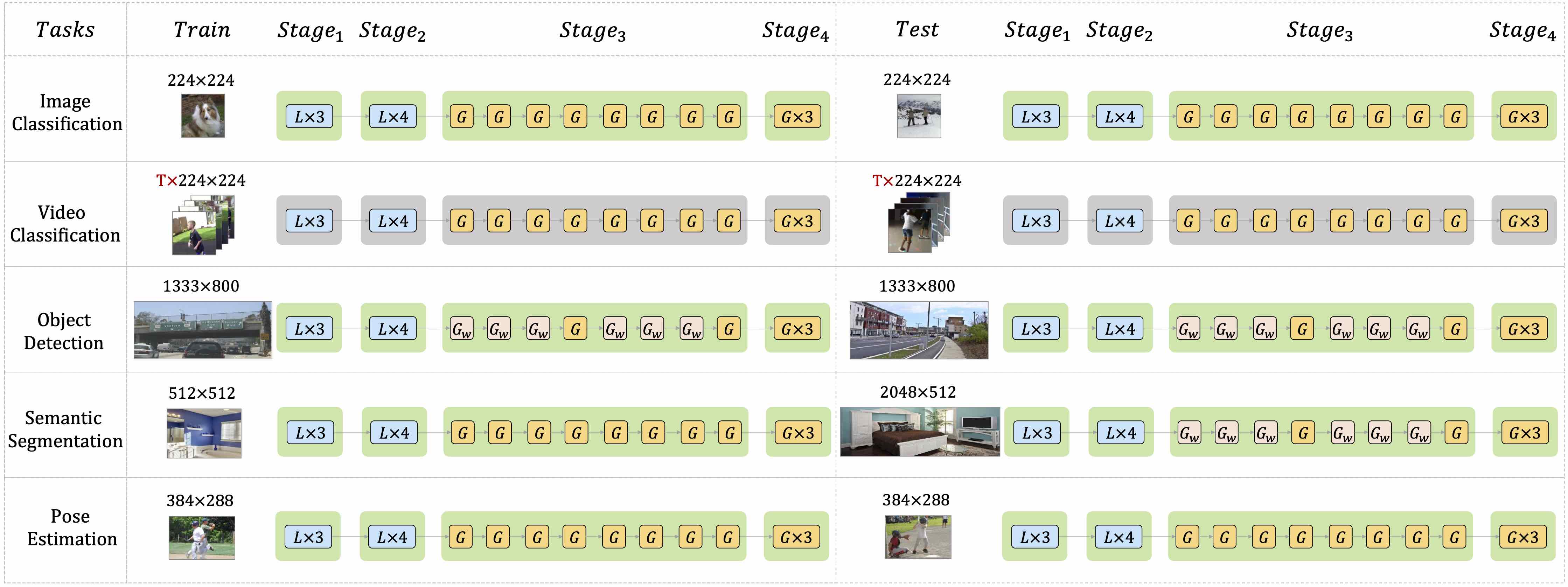

 +
+




 +
+ +
+