Automated Test / Benchmark research #87
Comments
|
|
@b-g , I spend a bit of time thinking about this and here is a couple of things I'd like some feedback / inputs to be able to go forward on this. Very much looking for external look on this, I may be overcomplexifying this.... but it would be useless to spend time to build a non-meaningful benchmark Our initial idea is to compare the number of distinct Ids of the tracker with a "reality" number what we would have previously manually determine on some given footage. Let's take this "scene" as an example:
Observation:YOLO / Tracker is only able to detect a fraction of the total items in this scene, for example of the upper left corner nothing is detected.. If we were to manually count the number of distinct ids on this scene, we would count everything what we see with our eye, including those cars of the upper left corner. This isn't a problem, and even more this is good because it would give us some "score" against reality and enable us to compare different weights files of YOLO that might pick up more objects... But this could skew results for another reason. ProblemThe problem with the "metric" of the distinct ids are the id-reassignment that happens... For example, we could have this results:
Ideas of what we can doI think we need to associate the time with the ids.. and manually label reality with: "this item is tracked for 10s" etc etc... So then we would get (very simple example with 3 items): Reality:
Tracker results:
Then the question is how to compute a meaningful score from those results, I do not have much idea how to do it... More
|

MOT Challenge tracker benchmark / evaluation frameworkI looked up this, they have multiple metrics that they combine like False negative, False positive, Id switch, fragmented trajectory, etc...
No clear explanation of how this works, but there is a paper: https://arxiv.org/pdf/1906.04567.pdf , and the code is available: https://bitbucket.org/amilan/motchallenge-devkit ( in matlab 🤓 ) I tried to get some insights from the paper, they have a nice diagram explaining some of the metrics
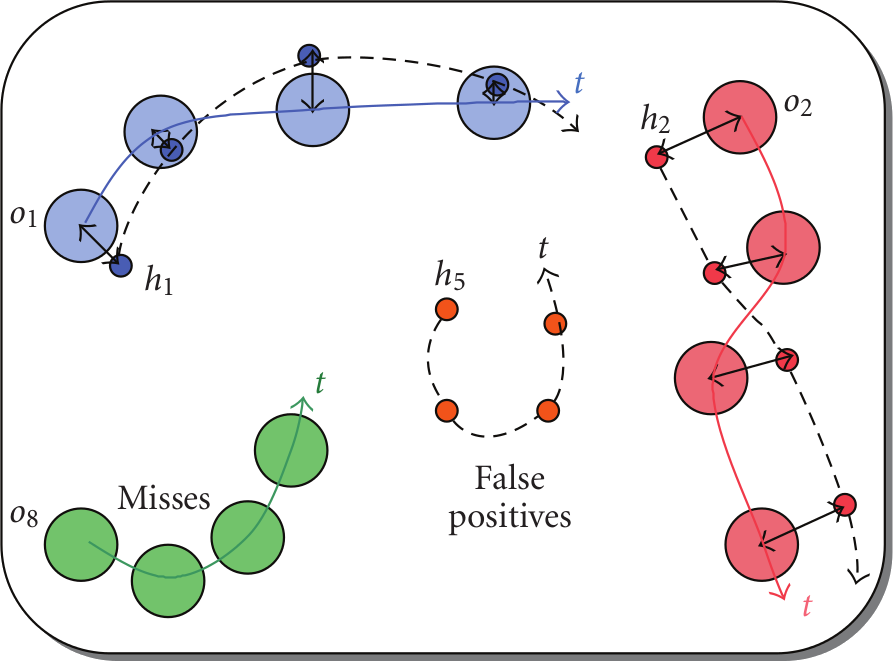
I didn't fully understand everything, but it seems to be that for every frame they perform a comparison for each bbox of the tracker output with the ground truth.... Just how they do it isn't clear would need to investigate the code.. But in definitive they seem to extract from this their metrics: false positive, false negative etc etc ... One idea could be to make our tracker compatible with the MOT in/out format and evaluate it there 😉 PymotGoogling around lead me to this github repo: https://github.com/Videmo/pymot , which implements a MOT evaluation in python (similar to the one of the MOT challenge), and takes in input JSON, also they are a schema explaining better the metrics ( dashed lines represent tracker hypothesis, whereas ground truth are the big circles)
The README is pretty great and explains:
If we were to go with this it seems that most of the work would be to annotate the ground truth, which would be to take some test footage and for each frame manually label all the bbox and assign them ids , and repeat this for XX frames... Then processing our tracker output into the format executed by this tool would be pretty simple. ConclusionThat quick research reinforced my opinion on that benchmarking the tracker isn't a simple task... but good news are that there are already plenty of literature / tool outhere... Let's discuss how it makes sense to go forward on this to move this project from an empiric "it seems to work nice" to fit it in a more robust evaluation framework 😉 |


|
Some quick follow-up with some other finding py-motmetricsThe lowest effort way to benchmark our tracker would be to test it with the MOT challenge data (for example this video 🤯: https://motchallenge.net/vis/CVPR19-03/gt/ ) , as we do not have to annotate ground truth videos... I found that there is python compatible implem of the evaluation framework: https://github.com/cheind/py-motmetrics (the official one is in Matlab) With this the only thing to do would be to write some script to convert our json output to the input of the MOT challenge, which seems pretty straithforward: https://motchallenge.net/instructions/ format:
<frame>, <id>, <bb_left>, <bb_top>, <bb_width>, <bb_height>, <conf>, <x>, <y>, <z>
example:
1, 3, 794.27, 247.59, 71.245, 174.88, -1, -1, -1, -1
1, 6, 1648.1, 119.61, 66.504, 163.24, -1, -1, -1, -1
1, 8, 875.49, 399.98, 95.303, 233.93, -1, -1, -1, -1this would give us a way to rank out tracker in those results for example: https://motchallenge.net/results/MOT17/
|

|
Hi @tdurand, many thanks for the brilliant write up! Sounds like best possible plan to compare our results with the ones of the MOT challenge. 👍 Q:
(Happy to jump an a quick call on Monday or Tuesday evening if faster to discuss) |
|
Thanks !
Let's discuss on to go forword on this on our next call, I don't plan to make any progress on this this week, I'll be travelling and have other issues I need to work on anyway (web version ..) |
|
I can initiate a sub project in my Institute, and outsource it to annotate the video. Any tools and sample video that you recommend? |
|
hello @shams3049 , thanks for this... will get back to you next week on this 😉 |
|
Things to discuss on our next meeting later today @b-g :
Bonus: V-IOU tracker ( something really similar with the approach we have ) ranked 3 on the overall MOT 2019 challenge: bochinski/iou-tracker#7 , and author will publish python implementation soon so this is also a good indicator we took the right approach for tracking and will gives you more input on how to improve it further |
|
Some update on this, Making node-moving-things-tracker compatible with MOT challenge input / outputThis is done, still in a separated branch but kind of ready to release, I've wrote a little documentation about it: https://github.com/opendatacam/node-moving-things-tracker/blob/mot/documentation/BENCHMARK.md Added a new mode in the command line tool:
The work is living in the Evaluating node-moving-things-tracker in the MOT ChallengeUsing https://github.com/cheind/py-motmetrics , a python version of the official MATLAB evaluation code of the mot challenge. Understanding how to use this tool was a bit tricky and I documented it https://github.com/opendatacam/node-moving-things-tracker/blob/mot/documentation/BENCHMARK.md . Some learnings to discuss:
FYI get this result: I can't rank against other competitor as the ranking is done of the test dataset and not training dataset... That said our MOTA score seems quite low (13.5%) ;-) .
Next stepsI think the next steps would be to:
|
Add a simple way to be able to test opendatacam to avoid regression when upgrading
The text was updated successfully, but these errors were encountered: