Many problems during recovery #425
Comments
|
|
Switched all cluster from corosync to zookeeper. That definitely made it more robust & responsive. |
|
Just a moment ago gateway node ( and it crashed, and systemd-journal logged coredump, rather small; |
|
Recovery finally succeeded this morning. With no crashes yet. Now the disks are working, but throughput has lowered down drastically. It does not saturate any of CPU/Disk/Network. Sometimes looks like does not even move, when I'm trying to read the vdi. As a result VMs are extremely slow (but working). I had no performance problems before the outage. Using Is there a specific reason for losing cluster performance? and is there a way to fix it? |
|
have you tune number of threads and throttling of recovery process? |
|
After realizing that recovery was hard on disks, yes. I have enabled throttling. But I was late for it. Also another update; cluster performance is back improving now. I did not touch any thread numbers. |
|
3 days later, sheep processes starting crashing (segfaults) randomly here and there and cluster is down again. |
|
I've seen a new behavior this time, first time since I've started using sheepdog; It just hangs there. (on all nodes of the cluster. None of them answers this question.) |
|
Only one node showing a different, but not less strange behavior. It says; "There are no active sheep daemons" |
|
Ok. This time looks like zookeeper went crazy. nodes were blocked on their init while trying to join the cluster, thus not answering cli calls. All the troubles in the world concentrated here. So, I have replaced zookeeper with etcd + zetcd. That (for now) gave me a robust/working/lightweight cluster and my nodes are happy for now. (recovering...) |
|
A question at this point; Is this huge recovery process caused by automatic vnode assignment? |
|
Status is the morning; I have managed to get dog client lockups again. I am suspecting this is probably due to some cluster locks being stucked in a locked state? And started thinking that was my probably problem with original zookeeper too? After that, in etcd logs I have spotted time difference between nodes, does this have a big impact? |
|
Ok. on one of the nodes, I have this => I'll try to fix that and see what happens. |
|
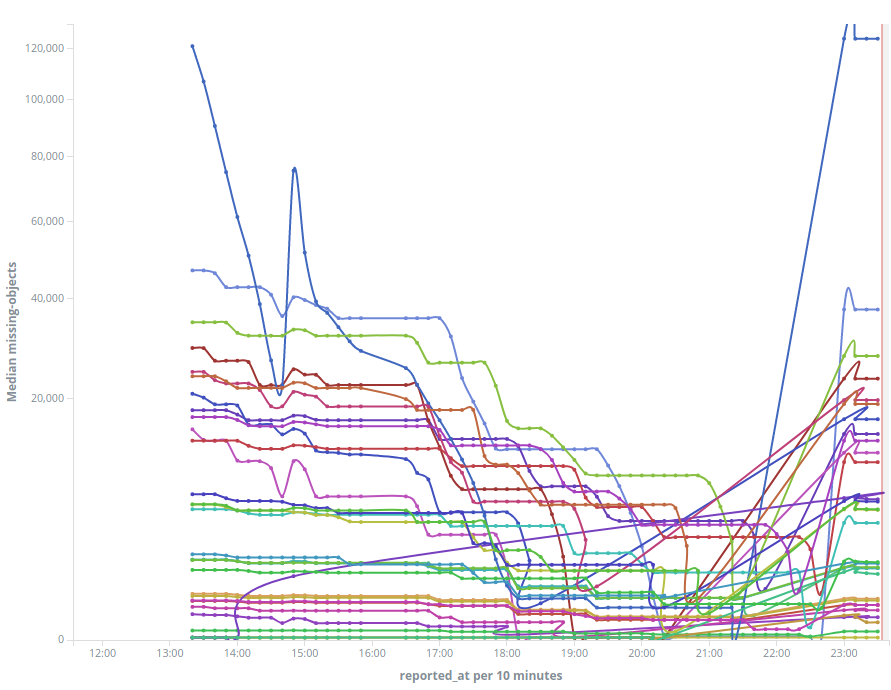
Yes. Looks like that problem in single node in cluster blocked the whole cluster. When I restarted that node, everything started to move again. Lost object counts increased a bit for some volumes. (Graph of recovery; lost object count per volume) |

|
Another constant problem I am experiencing is;
|
|
After this last restart, recovery is almost not proceeding at all.. getting this error in some of the nodes; after checking all, seems like some are lacking behind, like below; Restarting the ones lacking behind... Ok. Question; If some nodes realize that they're old (have old cluster epoch, whatever), why wouldn't they kill themselves, or just upgrade their knowledge about the cluster somehow? |
|
sorry, i don't think that sheepdog stable enough to handle unexpected failures and recovery. |
Was it because of this? => #371 |
|
I think that this is not only one issue that can damage data. |
|
the amount of space that |
|
I understand the file names are in For example in this file, epoch number is 56. But my last working, completely recovered cluster epoch is higher than that. Would that be OKAY to delete that file in this case? |
|
A bit more digging into The very same object with same contents, but copies for multiple epochs in |
|
Oh please Lines 2082 to 2085 in 929d401 |
I am using v1.0.1, compiled from github tag, on ubuntu14.04, with corosync. 7~10 TB total md size.
I had 7 nodes on my experimental setup. One of the nodes suddenly failed, and automatic-recovery (reweight) kicked in, which caused lots of IO on other nodes. And that caused some other nodes to crash.
My nodes are set to restart after crash. But now my cluster is in recovery loop that never succeeds.
Also it continuously increases disk usage until disk is full on some nodes (in .stall folder). If the disk is full, the node cannot start again, and other nodes cannot see the objects those nodes have, and cannot properly recover.
Lot's of points could be suggested to improve at this point, like;
dog cluster recovery disabledoes not work until the cluster is healthy. An option to disable recovery on init would be helpful. Otherwise everytime a node dies/comes-back, the whole operation is restarting, which takes hours and hours to recover each node.I'm currently still trying to recover the cluster (for the last 30~40 hours).
Any suggestions would be really helpful.
The text was updated successfully, but these errors were encountered: