Question reference
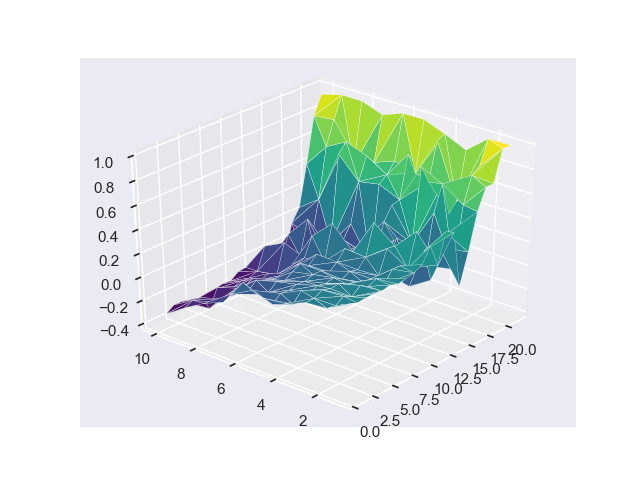
Optimal value function V* with Monte-Carlo Agent running 100,000 episodes
Q Function Update V(St) ← V(St) + α (Rt - V(St))
Q Function Update V(St) ← V(St) + α (Rt+1 + yV(St+1) - V(St))
| MSE Per Lambda | MSE Per Episode |
|---|---|
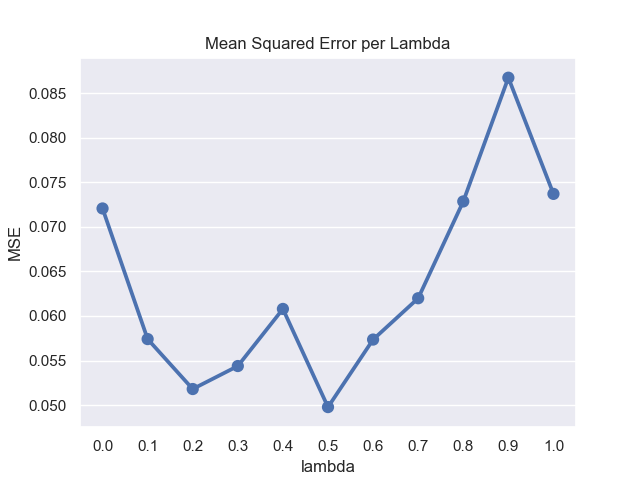 |
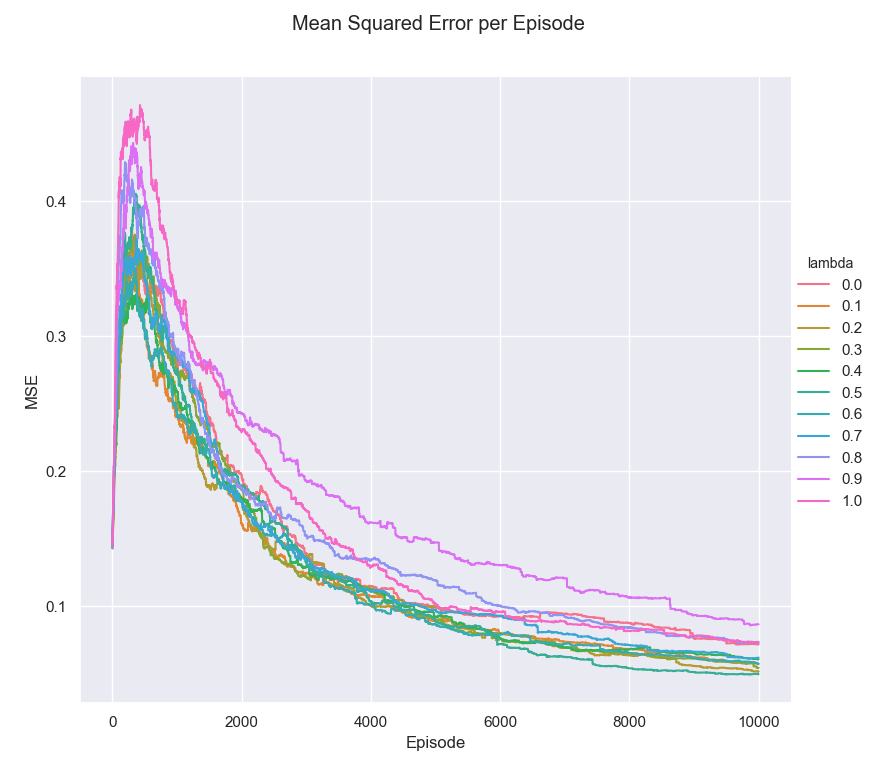 |
| MSE Per Lambda | MSE Per Episode |
|---|---|
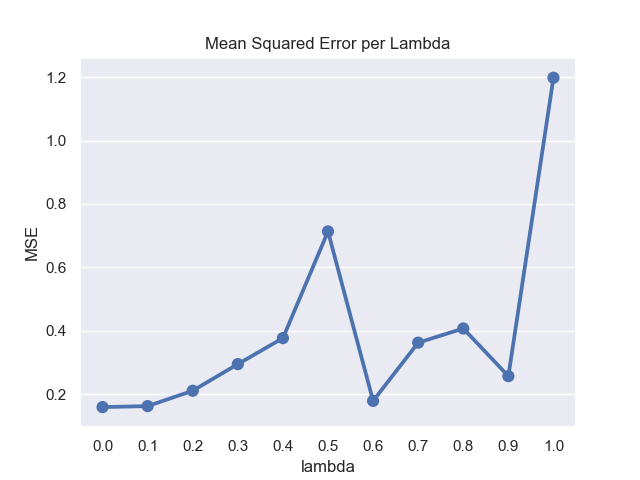 |
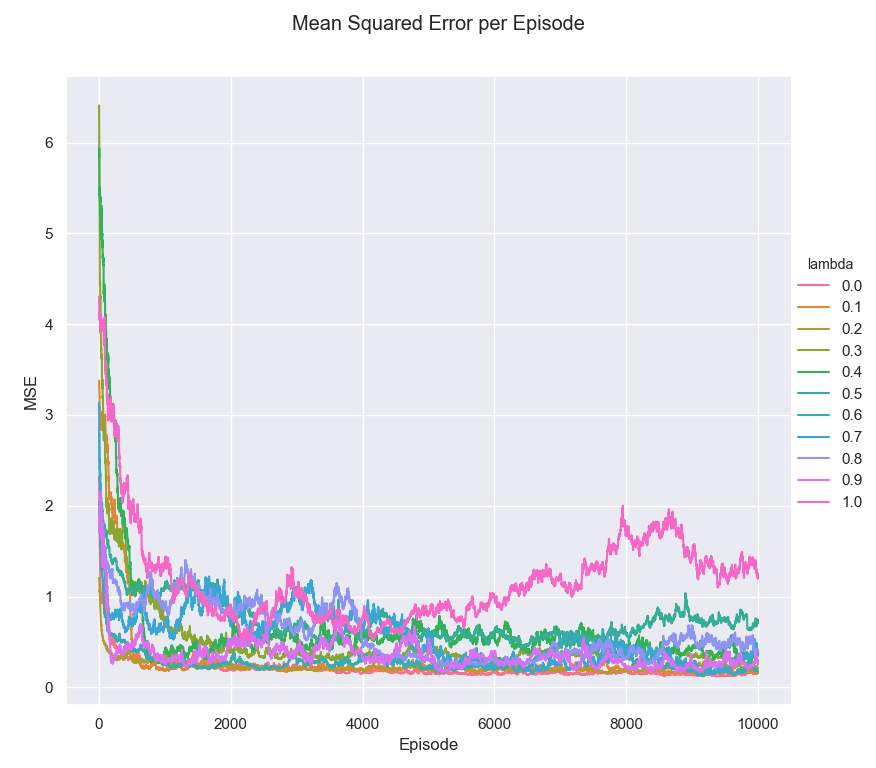 |