简体中文🀄 | English🌎







Features | Installation | Quick Start | API Reference | Community
PaddleNLP is a NLP library that is both easy to use and powerful. It aggregates high-quality pretrained models in the industry and provides a plug-and-play development experience, covering a model library for various NLP scenarios. With practical examples from industry practices, PaddleNLP can meet the needs of developers who require flexible customization.
-
2024.01.04 PaddleNLP v2.7: The LLM experience is fully upgraded, and the tool chain LLM entrance is unified. Unify the implementation code of pre-training, fine-tuning, compression, inference and deployment to the
PaddleNLP/llmdirectory. The new LLM Toolchain Documentation provides one-stop guidance for users from getting started with LLM to business deployment and launch. The full breakpoint storage mechanism Unified Checkpoint greatly improves the versatility of LLM storage. Efficient fine-tuning upgrade supports the simultaneous use of efficient fine-tuning + LoRA, and supports QLoRA and other algorithms. -
2023.08.15 PaddleNLP v2.6: Release Full-process LLM toolchain , covering all aspects of pre-training, fine-tuning, compression, inference and deployment, providing users with end-to-end LLM solutions and one-stop development experience; built-in 4D parallel distributed Trainer, Efficient fine-tuning algorithm LoRA/Prefix Tuning, Self-developed INT8/INT4 quantization algorithm, etc.; fully supports LLaMA 1/2, BLOOM, ChatGLM 1/2, GLM, OPT and other mainstream LLMs.
- python >= 3.7
- paddlepaddle >= 2.6.0
More information about PaddlePaddle installation please refer to PaddlePaddle's Website.
pip install --upgrade paddlenlp
or you can install the latest develop branch code with the following command:
pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.htmlTaskflow aims to provide off-the-shelf NLP pre-built task covering NLU and NLG technique, in the meanwhile with extremely fast inference satisfying industrial scenario.
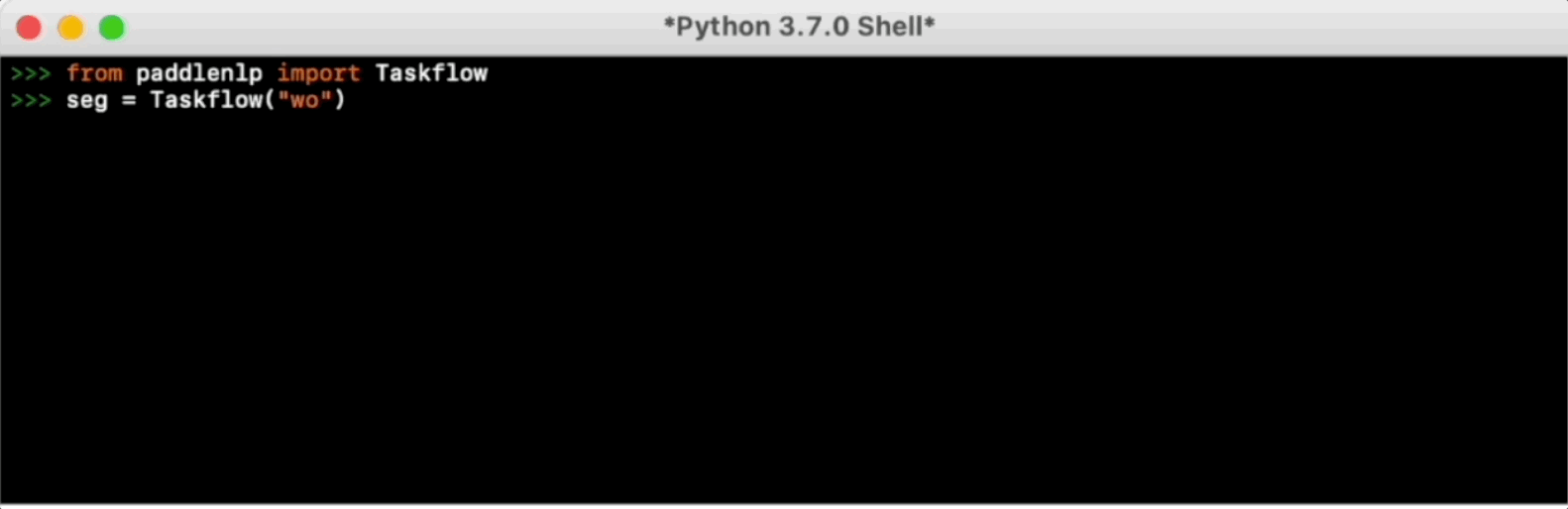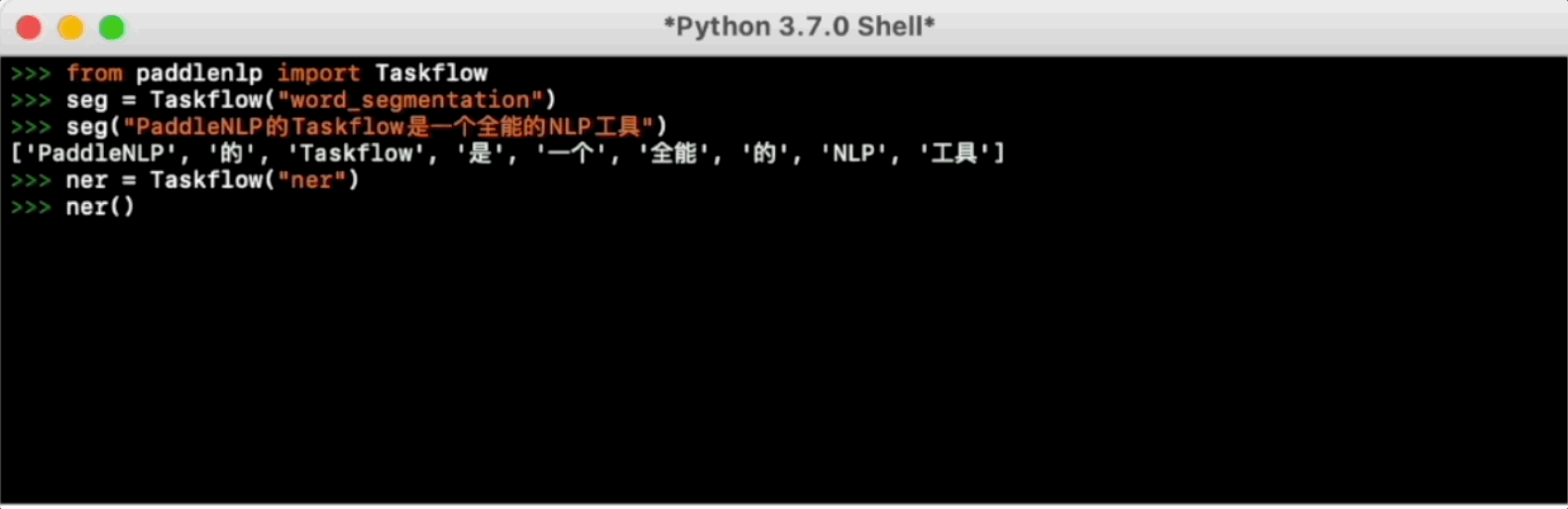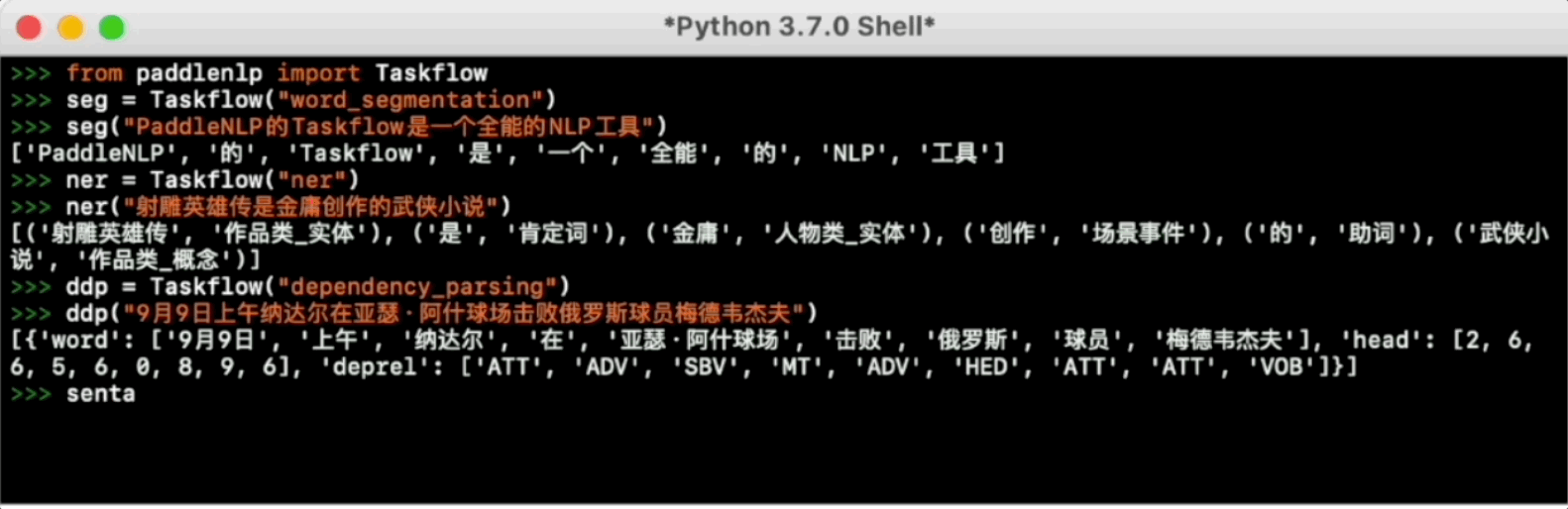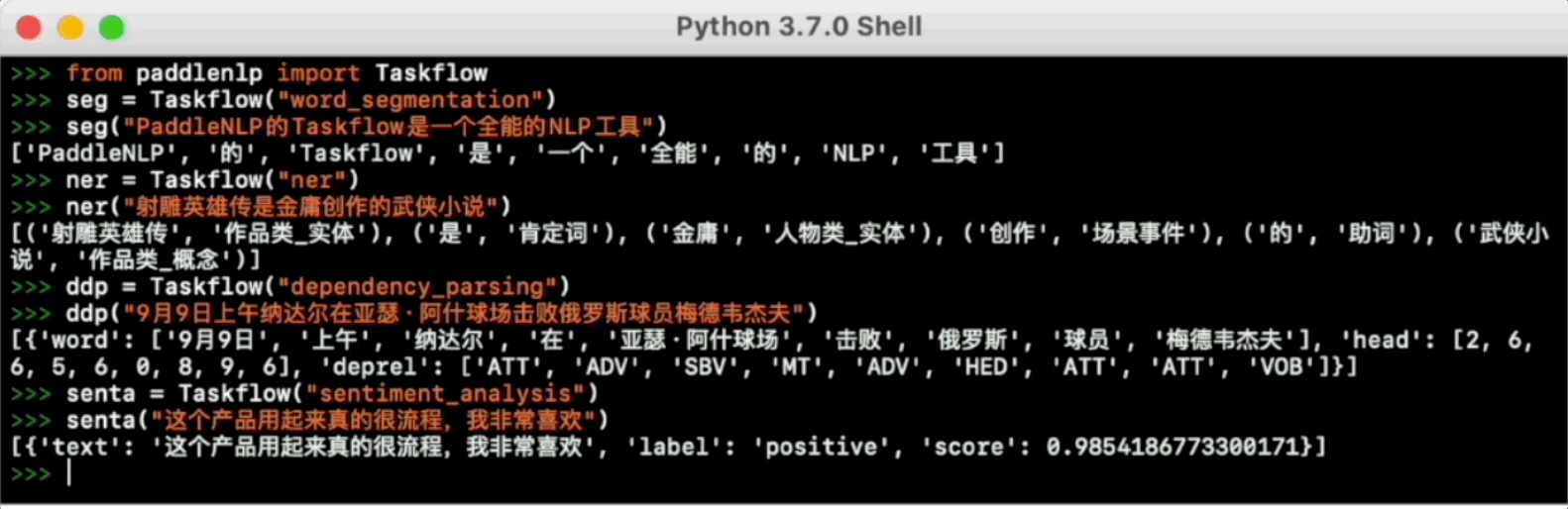
For more usage please refer to Taskflow Docs.
We provide 45+ network architectures and over 500+ pretrained models. Not only includes all the SOTA model like ERNIE, PLATO and SKEP released by Baidu, but also integrates most of the high-quality Chinese pretrained model developed by other organizations. Use AutoModel API to ⚡SUPER FAST⚡ download pretrained models of different architecture. We welcome all developers to contribute your Transformer models to PaddleNLP!
from paddlenlp.transformers import *
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
bert = AutoModel.from_pretrained('bert-wwm-chinese')
albert = AutoModel.from_pretrained('albert-chinese-tiny')
roberta = AutoModel.from_pretrained('roberta-wwm-ext')
electra = AutoModel.from_pretrained('chinese-electra-small')
gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')Due to the computation limitation, you can use the ERNIE-Tiny light models to accelerate the deployment of pretrained models.
# 6L768H
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
# 6L384H
ernie = AutoModel.from_pretrained('ernie-3.0-mini-zh')
# 4L384H
ernie = AutoModel.from_pretrained('ernie-3.0-micro-zh')
# 4L312H
ernie = AutoModel.from_pretrained('ernie-3.0-nano-zh')Unified API experience for NLP task like semantic representation, text classification, sentence matching, sequence labeling, question answering, etc.
import paddle
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
text = tokenizer('natural language processing')
# Semantic Representation
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
# Text Classificaiton and Matching
model = AutoModelForSequenceClassification.from_pretrained('ernie-3.0-medium-zh')
# Sequence Labeling
model = AutoModelForTokenClassification.from_pretrained('ernie-3.0-medium-zh')
# Question Answering
model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')PaddleNLP provides rich examples covering mainstream NLP task to help developers accelerate problem solving. You can find our powerful transformer Model Zoo, and wide-range NLP application examples with detailed instructions.
Also you can run our interactive Notebook tutorial on AI Studio, a powerful platform with FREE computing resource.
PaddleNLP Transformer model summary (click to show details)
| Model | Sequence Classification | Token Classification | Question Answering | Text Generation | Multiple Choice |
|---|---|---|---|---|---|
| ALBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
| BERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BlenderBot | ❌ | ❌ | ❌ | ✅ | ❌ |
| ChineseBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| CTRL | ✅ | ❌ | ❌ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE-CTM | ❌ | ✅ | ❌ | ❌ | ❌ |
| ERNIE-Doc | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-GEN | ❌ | ❌ | ❌ | ✅ | ❌ |
| ERNIE-Gram | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-M | ✅ | ✅ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| Funnel-Transformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| GPT | ✅ | ✅ | ❌ | ✅ | ❌ |
| LayoutLM | ✅ | ✅ | ❌ | ❌ | ❌ |
| LayoutLMv2 | ❌ | ✅ | ❌ | ❌ | ❌ |
| LayoutXLM | ❌ | ✅ | ❌ | ❌ | ❌ |
| LUKE | ❌ | ✅ | ✅ | ❌ | ❌ |
| mBART | ✅ | ❌ | ✅ | ❌ | ✅ |
| MegatronBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| MobileBERT | ✅ | ❌ | ✅ | ❌ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| NEZHA | ✅ | ✅ | ✅ | ❌ | ✅ |
| PP-MiniLM | ✅ | ❌ | ❌ | ❌ | ❌ |
| ProphetNet | ❌ | ❌ | ❌ | ✅ | ❌ |
| Reformer | ✅ | ❌ | ✅ | ❌ | ❌ |
| RemBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ❌ | ❌ |
| SKEP | ✅ | ✅ | ❌ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| T5 | ❌ | ❌ | ❌ | ✅ | ❌ |
| TinyBERT | ✅ | ❌ | ❌ | ❌ | ❌ |
| UnifiedTransformer | ❌ | ❌ | ❌ | ✅ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ❌ | ✅ |
For more pretrained model usage, please refer to Transformer API Docs.
We provide high value scenarios including information extraction, semantic retrieval, question answering high-value.
For more details industrial cases please refer to Applications.
For more details please refer to Neural Search.
We provide question answering pipeline which can support FAQ system, Document-level Visual Question answering system based on 🚀RocketQA.

For more details please refer to Question Answering and Document VQA.
We build an opinion extraction system for product review and fine-grained sentiment analysis based on SKEP Model.

For more details please refer to Sentiment Analysis.
Integrated ASR Model, Information Extraction, we provide a speech command analysis pipeline that show how to use PaddleNLP and PaddleSpeech to solve Speech + NLP real scenarios.

For more details please refer to Speech Command Analysis.
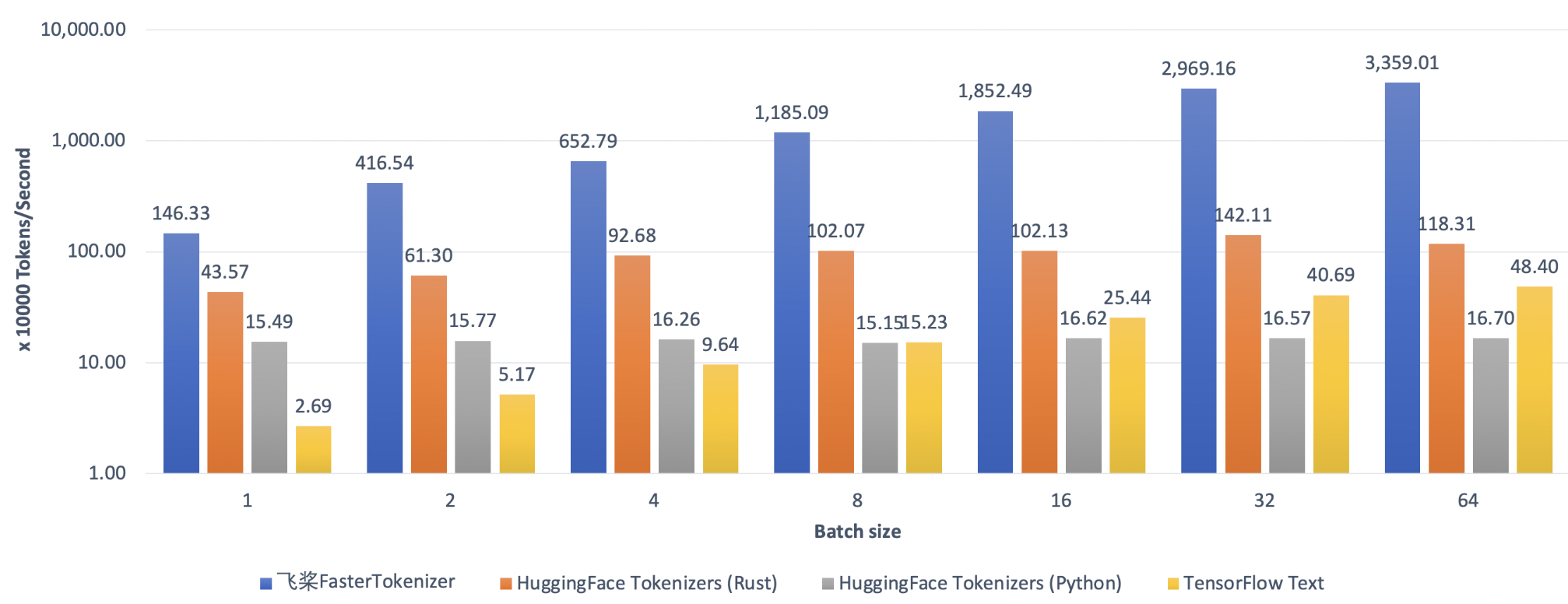
AutoTokenizer.from_pretrained("ernie-3.0-medium-zh", use_fast=True)Set use_fast=True to use C++ Tokenizer kernel to achieve 100x faster on text pre-processing. For more usage please refer to FastTokenizer.

model = GPTLMHeadModel.from_pretrained('gpt-cpm-large-cn')
...
outputs, _ = model.generate(
input_ids=inputs_ids, max_length=10, decode_strategy='greedy_search',
use_fast=True)Set use_fast=True to achieve 5x speedup for Transformer, GPT, BART, PLATO, UniLM text generation. For more usage please refer to FastGeneration.

For more super large-scale model pre-training details please refer to GPT-3.
Taskflow aims to provide off-the-shelf NLP pre-built task covering NLU and NLG scenario, in the meanwhile with extremely fast inference satisfying industrial applications.
from paddlenlp import Taskflow
# Chinese Word Segmentation
seg = Taskflow("word_segmentation")
seg("第十四届全运会在西安举办")
>>> ['第十四届', '全运会', '在', '西安', '举办']
# POS Tagging
tag = Taskflow("pos_tagging")
tag("第十四届全运会在西安举办")
>>> [('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')]
# Named Entity Recognition
ner = Taskflow("ner")
ner("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
>>> [('《', 'w'), ('孤女', '作品类_实体'), ('》', 'w'), ('是', '肯定词'), ('2010年', '时间类'), ('九州出版社', '组织机构类'), ('出版', '场景事件'), ('的', '助词'), ('小说', '作品类_概念'), (',', 'w'), ('作者', '人物类_概念'), ('是', '肯定词'), ('余兼羽', '人物类_实体')]
# Dependency Parsing
ddp = Taskflow("dependency_parsing")
ddp("9月9日上午纳达尔在亚瑟·阿什球场击败俄罗斯球员梅德韦杰夫")
>>> [{'word': ['9月9日', '上午', '纳达尔', '在', '亚瑟·阿什球场', '击败', '俄罗斯', '球员', '梅德韦杰夫'], 'head': [2, 6, 6, 5, 6, 0, 8, 9, 6], 'deprel': ['ATT', 'ADV', 'SBV', 'MT', 'ADV', 'HED', 'ATT', 'ATT', 'VOB']}]
# Sentiment Analysis
senta = Taskflow("sentiment_analysis")
senta("这个产品用起来真的很流畅,我非常喜欢")
>>> [{'text': '这个产品用起来真的很流畅,我非常喜欢', 'label': 'positive', 'score': 0.9938690066337585}]- Support LUGE dataset loading and compatible with Hugging Face Datasets. For more details please refer to Dataset API.
- Using Hugging Face style API to load 500+ selected transformer models and download with fast speed. For more information please refer to Transformers API.
- One-line of code to load pre-trained word embedding. For more usage please refer to Embedding API.
Please find all PaddleNLP API Reference from our readthedocs.
To connect with other users and contributors, welcome to join our Slack channel.
Scan the QR code below with your Wechat⬇️. You can access to official technical exchange group. Look forward to your participation.

If you find PaddleNLP useful in your research, please consider cite
@misc{=paddlenlp,
title={PaddleNLP: An Easy-to-use and High Performance NLP Library},
author={PaddleNLP Contributors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleNLP}},
year={2021}
}
We have borrowed from Hugging Face's Transformers🤗 excellent design on pretrained models usage, and we would like to express our gratitude to the authors of Hugging Face and its open source community.
PaddleNLP is provided under the Apache-2.0 License.