diff --git a/TODO/a-primer-on-android-navigation.md b/TODO/a-primer-on-android-navigation.md
index 2411e4946c3..cfcf4555cce 100644
--- a/TODO/a-primer-on-android-navigation.md
+++ b/TODO/a-primer-on-android-navigation.md
@@ -3,89 +3,88 @@
> * 原文作者:[Liam Spradlin](https://medium.com/@LiamSpradlin)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-primer-on-android-navigation.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-primer-on-android-navigation.md)
-> * 译者:
-> * 校对者:
+> * 译者:[horizon13th](https://github.com/horizon13th)
+> * 校对者:[SumiMakito](https://github.com/sumimakito), [laiyun90](https://github.com/laiyun90)
-# A Primer on Android navigation
+# 安卓界面导航初识
-> Any vehicle someone uses to move between scenes in your interface — that’s navigation
+> 界面中任何引领用户跳转于页面之间的媒介 —— 这便是导航
-As soon as you link two screens together in an app, you have navigation. That link—whatever it may be—is the vehicle that carries users between those screens. And although creating navigation is relatively simple, creating the *right* navigation for your users isn’t always straightforward. In this post we’ll take a look at some of the most common navigation patterns used on Android, how they impact system-level navigation, and how to mix and match patterns to suit your interface and your users.
+当你的应用中的两个不同页面产生联系时,导航便由此而生。跳转链接(不论从哪跳到哪)便是页面间传递用户的媒介。创建导航相对容易,但想要把导航**做好**并不总是那么简单。这篇博文里,我们探讨一下安卓系统下最常见的导航模式,看看它们是怎样影响系统布局,以及如何为你的应用界面,用户量身打造导航栏。
---
-### ✏️ Defining navigation
+### ✏️ 定义导航
-Before digging into common navigation patterns, it’s worth stepping back and finding a starting point for thinking about navigation in your app.
+在深入探索导航模式前,让我们先退后一步回到起点,做一个小练习,回想一下你的应用中的导航。
-The Material Design spec has some [great guidance](https://material.io/guidelines/patterns/navigation.html#navigation-defining-your-navigation) on how to approach defining navigation structures, but for the purposes of this post we can boil everything down to two simple points:
+在 Material Design 网站中有许多 [优秀设计规范](https://material.io/guidelines/patterns/navigation.html#navigation-defining-your-navigation) 介绍了如何着手定义导航结构。但本文中我们把所有的理论归结为简单的两点:
-- Build navigation *based on* tasks and content
-- Build navigation *for* people
+- 基于**任务和内容**构建导航
+- 基于**用户**构建导航
-Building navigation based on tasks and content means breaking down what tasks people will be performing, and what they’ll see along the way, and mapping out relationships between the two. Determine how tasks relate to one another — which tasks are more or less important, which tasks are siblings, which ones nest inside one another, and which tasks will be performed more or less often.
+基于**任务和内容**构建导航意味着,将任务分步骤拆分。设想用户在完成任务的过程中应该做什么看到什么,怎样处理步骤之间的关系,决定哪一步更重要,哪些步骤是并列关系,哪些步骤是包含关系,哪些步骤常见或不常见。
-That’s where building navigation for people comes in — the people using your interface can tell you whether it’s working for them or not, and your navigation should be built around helping them succeed in your app.
+至于基于**用户**构建导航,只有真正使用过你设计的界面的用户才能告诉你这适不适合他们。你所设计的导航最好能帮助他们更好地使用应用,带给他们最大化的便利。
-Once you know how the tasks in your app work together, you can decide what content users need to see along the way and when and how to present it—this exercise should provide a good foundation for deciding which patterns best serve your app’s experience.
+当你搞清楚在你的应用中,多个任务怎样协同工作的,便可以着手设计。用户在完成任务的过程中可以看到什么内容,在什么时候,以什么方式来呈现。这个小练习能够让你从根本上思考什么样的设计模式能更好地服务于你的 app 体验。
-*📚 Find more detailed guidance on breaking down tasks and behaviors for navigation *[*in the Material spec*](https://material.io/guidelines/patterns/navigation.html)*.*
+📚 分解任务行为以设计导航更多内容,详见 [Material Design](https://material.io/guidelines/patterns/navigation.html)。
---
-### 🗂 Tabs
+### 🗂 标签页(Tabs)
-#### Definition
+#### 定义
-Tabs provide quick navigation between sibling views inside the same parent screen. They’re coplanar, meaning they can be swiped around, and they live in an extensible, identifiable tab bar.
+标签页提供了在相同父页面场景下,同级页面间的快速导航。所有的选项卡是位于同一平面的,这意味着,他们可以放置在同一可扩展的状态栏上,也可以相互改变位置。
-Tabs are great for filtering, segmenting, or providing depth to related pieces of content. Unrelated pieces of content, or content with its own deep hierarchy may be better served by using other navigation patterns.
+标签页是很好的页面内容过滤、分段、分级工具。但是对于毫无关联的内容,或是层级化结构内容,也许其它的导航模式会更合适。
-*📚 Find all the details on designing tabs *[*here*](https://material.io/guidelines/components/tabs.html#)*, and on implementing tabs *[*here*](https://developer.android.com/training/implementing-navigation/lateral.html)*.*
-
-#### Tabs in action
+📚 设计标签页的更多细节 [参考此处](https://material.io/guidelines/components/tabs.html#),更多实现 [参考此处](https://developer.android.com/training/implementing-navigation/lateral.html)。
+#### 标签页实例

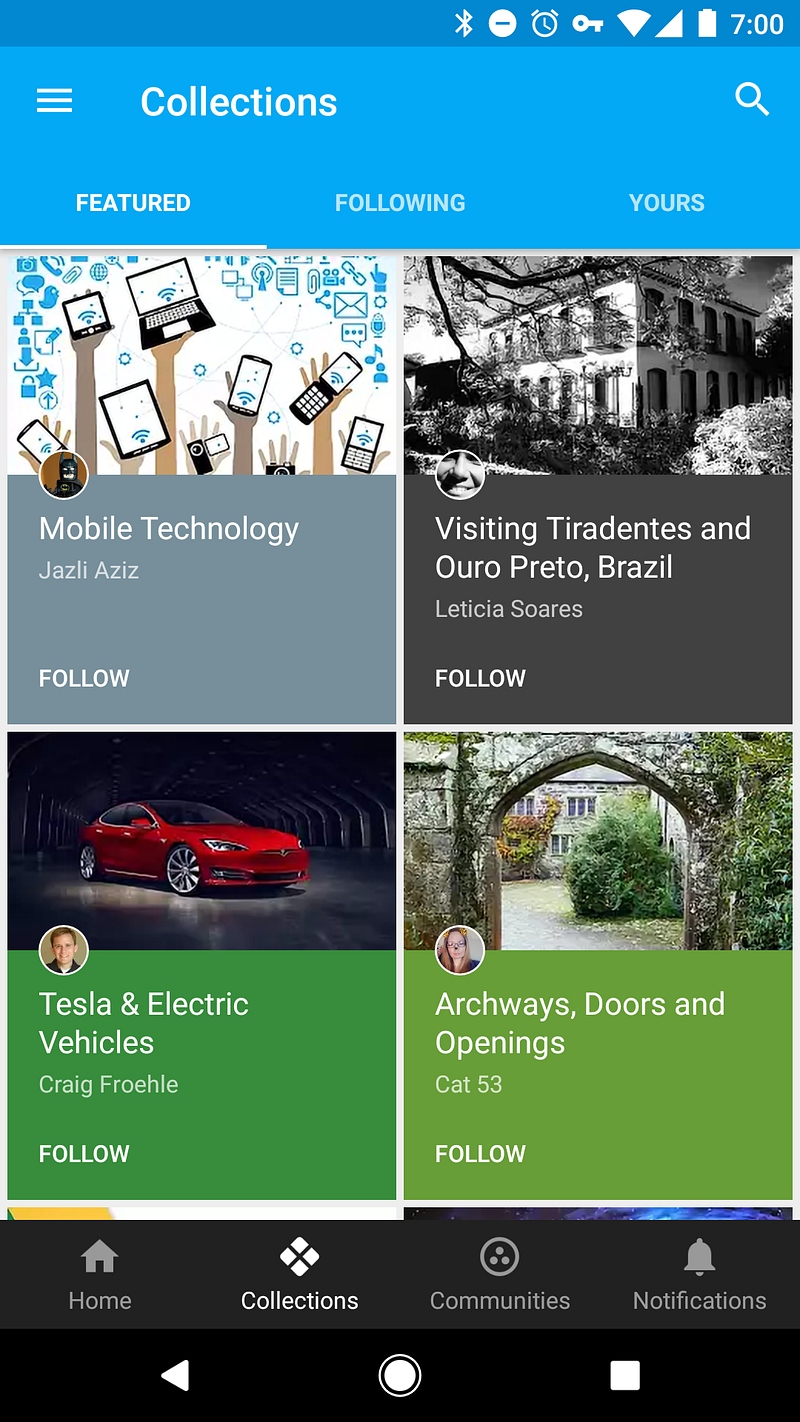
-Play Music, Google+, Play Newsstand
+Play Music 应用,Google+ 应用,Play Newsstand 应用
-Play Music *(above, left)* uses tabs to add depth to the music library, organizing the same general content in different ways to accommodate different means of exploration.
+Play Music 应用(左)使用标签页增加音乐库的探索深度,以不同的方式组织大致相同的内容,为用户定制不同的探索方法。
-Google+ *(above, center)* uses tabs to segment Collections, a single content type that leads to very heterogeneous content deeper in the app.
+Google+ 应用(中)使用标签页将收藏列表分块,每个类别下都是深层异构的内容。
-Play Newsstand *(above, right)* uses tabs on the Library screen to present different sets of the same information — one tab presents a holistic, multi-layered collection, while the other shows a condensed set of headlines.
+Play Newsstand 应用(右)在媒体库页面使用标签页来呈现相同信息的不同集合 - 其中一个选项卡呈现一个整体的多层次的集合,另一个选项卡显示浓缩集合的大标题。
-#### History
+#### 访问记录
-Tabs exist on one level together, inside the same parent screen. So navigating between tabs should not create history either for the system back button or for the app’s up button.
+标签页一般为同一级别,因此它们的布局在相同的父级页面下。两个标签页间的切换不需要为系统后退键或应用的返回键新建历史记录。
---
-### 🍔 Nav drawers
+### 🍔 侧边栏/抽屉式导航栏(Nav drawers)

-#### Definition
+#### 定义
-The navigation drawer is generally a vertical pane attached to the left edge of the canvas. Drawers can manifest off-screen or on, persistent or not, but they always share some common characteristics.
+侧边栏(抽屉式导航栏)可以理解为附于页面左部边缘的垂直面板。设计者可以将侧边栏设计在屏幕外或屏幕内可见,持续存在或者不用时隐藏,但这些不同的设计往往有相同的特点。
-Typically, the nav drawer lists parent destinations that are peers or siblings with one another. A nav drawer can be used in apps with several primary destinations, and some unique supporting destinations like settings or help.
+通常侧边栏会列出一些同级的父级页面们,尤其用于放置较重要的页面,又例如一些“设置”,“帮助”这类特殊页面。
-If you combine the drawer with another primary navigation component — bottom nav, for example — the drawer can contain secondary destinations, or important destinations that don’t directly follow in the hierarchy from the bottom nav.
+如果你将侧边栏和另一个导航控件相组合——底部导航栏,那么侧边栏可以放置一些二级链接,或者底部导航不能直接到达的重要链接。
-When using the nav drawer, be aware of what *kinds* of destinations you’re presenting — adding too many destinations or destinations that represent different levels in the app’s hierarchy can get confusing.
+当使用侧边栏时,要注意链接**类别**——放过多的链接,或展示过多不同级别的链接,都会让应用的层次结构显得混乱。
-Also be aware of visibility — the drawer can be good for reducing visibility or compacting navigation away from the main content area, but that can also be a drawback depending on how the destinations in your app need to be presented and accessed.
+还有需要注意的一点是界面的可视性。侧边栏可以很好的帮助应用减少可视性,压缩与主要内容无关的导航区。但是,这也可能成为应用的不足,取决于导航栏的目标链接在具体场景中如何呈现和被访问。
-*📚 Get detailed guidance on nav drawer design *[*here*](https://material.io/guidelines/patterns/navigation-drawer.html)*, and implementation *[*here*](https://developer.android.com/training/implementing-navigation/nav-drawer.html)*.*
+📚 设计侧边栏的更多细节[参考此处](https://material.io/guidelines/patterns/navigation-drawer.html),更多实现[参考此处](https://developer.android.com/training/implementing-navigation/nav-drawer.html)。
-#### Nav drawers in action
+#### 侧边栏实例

@@ -93,21 +92,19 @@ Also be aware of visibility — the drawer can be good for reducing visibili

-Play Store, Google Camera, Inbox
-
-The Play Store *(above, left)* uses the nav drawer to point to different sections of the store, each dedicated to a different type of content.
+Play Store 应用,Google Camera 应用,Inbox 应用
-Google Camera *(above, center)* uses the drawer for supporting destinations — these are mostly destinations that augment the capture experience, plus a path to settings.
+Play Store 应用(左上)使用侧边栏展示应用商店的不同区域,每一栏都链接到不同区域的内容。
-Inbox *(above, right)* has an extensible nav drawer that can get quite long. At the top are primary destinations that present different segments of your email, and below those are supporting segments called bundles.
+Google Camera(中上)使用侧边栏列出其它支持功能——大部分是提升照相体验的其他应用外链,当然了还有相机设置。
-Because the nav drawer in Inbox can get so long, the “settings” and “help & feedback” items are presented in a persistent sheet, accessible from anywhere in the drawer.
+Inbox(右上)邮箱应用使用了伸长版的侧边栏。顶端是电子邮箱的主要功能链接,用于展示不同类别的邮件,侧边栏的下方则为一些支持工具和扩展包。由于电子邮箱的侧边栏非常的长,“设置”和“帮助反馈”按钮固定在侧边栏底端,方便用户随时访问。
-#### History
+#### 访问记录
-Nav drawers should generally create history for the system back button when the app has a distinct “Home” destination. In the Play Store, the home destination is the Apps & Games entry, which actually presents the user with tab navigation to see highlighted content of all types. So the Play Store creates history to get back to that destination from other areas of the app.
+当应用程序有明显的“返回首页”功能时,侧边栏应当为系统创建“返回首页”的功能。例如,在 Play Store 应用商店中,点击“返回首页”按钮回到页面“应用程序及游戏”,展示给用户的是所有类别的精选应用。因而 Play Store 应用创建了从其它页面到主页面的返回功能。
-Google Camera likewise takes users back to the default, primary capture mode minus any augmentation.
+同样的,在使用 Google Camera 相机应用时,当用户点击返回键时,返回到相机的默认拍摄界面。

@@ -115,9 +112,9 @@ Google Camera likewise takes users back to the default, primary capture mode min

-The “start driving” entry augments the primary map view
+“开始导航” 圆形按钮增强主地图功能。
-The same goes for Google Maps *(above)* — any destination in the drawer is presented as either a layer on top of or an augmentation to the primary map screen, so the back button brings us back to a clean slate.
+谷歌地图(如上)也用了相同的方案,侧边栏的选项要么是在地图上加层,要么增强主地图提供辅助功能。所以当用户点击“返回”按钮时回到的也是默认地图界面。

@@ -125,27 +122,27 @@ The same goes for Google Maps *(above)* — any destination in the drawer is

-You may notice the Play Store *(above)* doesn’t change the nav drawer indicator in the toolbar to an “up” button once you navigate to a destination. This is because the primary destinations in the drawer are on an equal level in the app’s navigation hierarchy. Since you aren’t moving deeper into the app by selecting “Movies & TV” from the drawer, you can’t go further up. You’re still at the top level, just on a parallel screen.
+你可能会注意到,随着你进入其他页面,Play Store 谷歌商店(上图)工具栏中的侧边栏图标并未改变。这是因为侧边栏的按钮在应用的层级结构中为同一级别。由于用户并没有深入到子级页面(例如,点击“音乐与视频”),因而侧边栏的图标并不会改变成返回上一级的样式。用户始终在最顶级的页面,只不过是在同级页面中切换而已。
---
-### 🚨 Bottom nav
+### 🚨 底部导航(Bottom nav)

-#### Definition
+#### 定义
-On Android, the bottom nav component is comprised of between three and five primary destinations. Importantly, “more” is not a destination. Neither are menus nor dialogs.
+在安卓系统中,底部导航控件通常由三到五个目的地按钮构成。重要的一点是,“更多”按钮并不能看作一个目的地,更不是菜单或对话框。
-Bottom navigation works best when your app has a limited number of disparate top-level destinations (bottom nav should never scroll) that need to be instantly accessible. One of the main benefits of a “bottom bar” is being able to jump from a child screen to an unrelated parent screen instantly, without navigating back up to the current parent first.
+当你的应用只有有限个数的顶级页面需要被访问时,使用底部导航栏最合适(底部导航千万不能滚动)。底栏最主要的优点在于,可以从子页面迅速跳入毫无关联的顶级页面,而无需先导航到当前页面的父页面。
-It’s important to note that while destinations in the bottom bar should all be equal in the app’s navigation hierarchy, items in the bottom bar are not coplanar the way tabs are, and shouldn’t be presented as such.
+值得注意的是,尽管底部导航的链接应当在应用中有相同的层级结构,但是他们和标签页截然不同,也绝不能以标签页的形式展现。
-Swiping between destinations in the bottom bar suggests a relationship between destinations that doesn’t exist. Each destination should be a discrete parent, not a sibling of the other destinations. If the destinations in your app are similar or present similar content, they may be better suited for tabs.
+切换底部栏,暗示着两个面板是毫无关系的。每个面板是孤立的父节点,而不是其它面板的兄弟节点。如果你的应用中,两个面板有相同内容或者相同的父节点,也许用标签页是更好的选择。
-*📚 Find more detailed design guidance for bottom nav *[*here*](https://material.io/guidelines/components/bottom-navigation.html#)*, and implementation details *[*here*](https://developer.android.com/reference/android/support/design/widget/BottomNavigationView.html)*.*
+📚 设计底部导航的更多细节[参考此处](https://material.io/guidelines/components/bottom-navigation.html#),更多实现[参考此处](https://developer.android.com/reference/android/support/design/widget/BottomNavigationView.html)。
-#### Bottom nav in action
+#### 底部导航实例

@@ -153,41 +150,41 @@ Swiping between destinations in the bottom bar suggests a relationship between d

-Google Photos
+Google Photos 相册应用
-Bottom nav has some interesting considerations beyond its basic definition. Probably most complex is the notion of just *how* persistent the bottom bar should be. The answer, as with so many design decisions, is “it depends.”
+除了底部导航的基本定义,还有一些有意思的点值得考虑。也许最复杂的问题就是:底部导航栏是否要持续存在?答案和许多设计决策一样,那就是:“看情况”。
-Typically the bottom bar persists across the entire app, but there are some cases that could justify hiding the bottom bar. If the user enters a very shallow hierarchy — on single-purpose screens like message composition — or if the app wants to present a more immersive experience a step or two deep into the hierarchy, the bottom bar may be hidden.
+通常底部导航在整个应用中是持续存在的,但在某些情况下,导航栏是隐藏的状态。例如用户使用的应用只有很浅的层次结构,像收发短信这类单一功能的页面,又或者应用想给用户更深刻的用户体验,那底部导航或许隐藏起来更好。
-In Google Photos *(above)*, the bottom nav disappears inside albums. Albums are presented as a secondary layer in the hierarchy, and the only further navigational action is opening a photo, which itself opens on top of the album UI. This implementation satisfies the “single-purpose” rule for hiding the bottom nav while serving the goal of creating a more immersive experience once the user gets beyond the top level.
+在 Google Photos 相册应用中(上图),底部导航在相册中是隐藏的。相册在整个层级结构中处于第二层,比相册更深一层只有查看相片,打开它时从相册页面顶部展现。这种实现方式满足了隐藏底边导航以达到“唯一目的”的规则。当用户进入程序最顶层时,为其创造沉浸式体验。
-#### Additional considerations
+#### 其它考虑
-If the bar is persistent across the entire app, the next logical consideration would be behavior when jumping between destinations using the bar. If the user is several layers deep in a hierarchy stemming from one destination and they switch to another destination and then switch back to the first, what should they see? The parent screen, or the child screen on which they left off?
+如果底部导航在整个应用中持续存在,那么下一个需要考虑的问题便是底部导航的跳转逻辑。假设一个用户在深层层级结构中进行跳转,从一个子页面切换到另一个子页面,再点击返回跳转到前一个子页面,那他到底应该看到哪一个页面呢?父级页面?还是他停留过的子级页面?
-This decision should be informed by those using your app. In general, tapping an item in the bottom bar should go directly to the associated screen, not to a deeper layer of the hierarchy, but as with any guideline — *deviate with purpose.*
+这个功能应该取决于应用的使用者。一般来说,点击底部按钮应该直接跳转到关联页面,而不是更深层的页面。不过话说回来还是老问题,**看情况**。
-#### History
+#### 访问记录
-Bottom nav shouldn’t create history for the system back button. Going deeper into hierarchies stemming from bottom nav destinations can create history for the system back button *and* the app’s up button, but the bottom bar can serve as its own sort of historical navigation as well.
+底部导航栏的点按不应该为系统“返回键”创建历史记录。不过层级结构中进入深层级可以为系统“返回键”创造系统历史记录,为应用创建“返回上级”访问记录,但是底部栏其本身便是一种具有记录历史特性的导航结构。
-Tapping an item in bottom nav should take you straight to the associated destination, and tapping it again should navigate back to the parent level, or refresh the parent level if the user’s already there.
+点按底部导航按钮,应当直接跳转到关联页面。用户再次点击按钮应当跳转到该栏的父页面,或者当用户以及在父级页面时刷新页面。
---
-### 🕹 In-context navigation
+### 🕹 上下文导航(In-context navigation)

-#### Definition
+#### 定义
-In-context navigation is comprised of any navigational interaction outside of the components described above. This includes things like buttons, tiles, cards, and anything else that takes the user elsewhere in an app.
+上下文导航由所有非上述导航控件间的交互组成。这些控件包括像按钮、方块、卡片,还有其它应用内跳转的内容。
-In-context navigation is typically less linear than explicit navigation — interactions may transport the user through a hierarchy, between different steps in discrete hierarchies, or out of the app entirely.
+通常,上下文导航和常用导航形式相比,更多是非线性操作 —— 交互行为使用户在层级结构,离散型结构之间任意跳转,甚至跳转到应用之外。
-*📚 Look for more guidance on in-context navigation *[*here*](https://material.io/guidelines/patterns/navigation.html#navigation-combined-patterns)*.*
+📚 设计上下文导航的更多细节[参考此处](https://material.io/guidelines/patterns/navigation.html#navigation-combined-patterns)。
-#### In-context navigation in action
+#### 上下文导航实例

@@ -195,9 +192,9 @@ In-context navigation is typically less linear than explicit navigation —

-Clock, Google, and Google Calendar
+时钟应用,Google 搜索应用,Google 日历应用
-In the Clock app *(above, left)* there’s a FAB; the Google app *(above, middle) *relies primarily on information arranged inside cards; and Google Calendar *(above, right)* creates tiles for events.
+时钟应用(左上)设计的很巧妙,有一个浮动操作按钮;Google 搜索应用(中上)主要靠下部卡片维护信息;Google 日历(右上)给每一个日历时间创建块状条目。

@@ -205,25 +202,28 @@ In the Clock app *(above, left)* there’s a FAB; the Google app *(above, middle

-Activating the FAB in Clock *(above, left)* brings you to a world clock selection screen, tapping the weather card in the Google app *(above, center)* brings you to a search results page for “weather,” and tapping an event tile in Calendar *(above, right)* takes you to that event’s details.
+在时钟应用里(左上)通过点击浮动按钮,即刻查看世界时钟;在 Google 搜索应用(中上)里点击天气卡片,搜索引擎立马为你展示“天气”的搜索结果;Google 日历(右上)点击块状条目进入事件详情页。
-We also see in these screenshots the different ways in-context navigation can transport the user. In the Clock app we’re down one level from the clock itself, in the Google app we’ve ended up at essentially an augmentation of the main screen, and in Calendar we’ve opened [a full-screen dialog](https://material.io/guidelines/components/dialogs.html#dialogs-full-screen-dialogs).
+我们也能看出来,这些截图展现了上下文导航给用户带来不一样的跳转体验。时钟应用里,用户进入应用的子级页面;Google 搜索应用使用卡片以增强主屏幕,而 Google 日历是点击打开[全屏窗口](https://material.io/guidelines/components/dialogs.html#dialogs-full-screen-dialogs)。
-#### History
+#### 访问记录
-There’s no hard rule for creating history via in-context navigation. Whether history is created relies entirely on what kind of in-context navigation the app uses and where the user is taken. In cases where it’s not clear exactly what kind of history should be created, it’s good to know what the up and back buttons do in general.
+对于上下文导航,并没有对访问记录的硬性规定。访问记录的创建与否完全取决于使用什么形式的上下文导航,还有用户通过导航要去哪里。为了以防万一,在某些情况里应用创建什么类型的历史记录并不明确,设计者最好了解下,在通常情况点击返回键和向上键设置会产生什么操作。
---
-### ↖️ Up, back, and close buttons
+### ↖️ 向上键、返回键、关闭键(Up, back, and close buttons)

-The back, up, and close buttons are all important to navigating an Android UI, but are often misunderstood. The three buttons actually have pretty simple behavior from a UX perspective, so remembering the following rules should help get you out of any perplexing situation.
+返回键,向上键,关闭键这三个按键在安卓用户界面里都非常重要,但却常常被理解错误。实际上,从用户体验的角度,三个按钮都很简单,只要熟记下面的几条规则,保证再也不会陷入困惑。
+
-- **Up **isfound in the app’s toolbar when the user has descended the app’s hierarchy. It navigates back up the hierarchy in chronological order until the user reaches a parent screen. Since the up button doesn’t appear on parent screens, it should never lead out of an app.
-- **Back** is always present in the system nav bar. It navigates backward chronologically, irrespective of app hierarchy, even if the previous chronological screen was inside another app. It also dismisses temporary elements like dialogs, bottom sheets, and overlays.
-- **Close **is typically used to dismiss transient layers of the interface or discard changes in a [full-screen dialog](https://material.io/guidelines/components/dialogs.html#dialogs-full-screen-dialogs). Consider the event detail screen in Google Calendar *(shown below)*. The temporary nature of the detail screen becomes even more clear on larger screens. In Inbox *(below)*, the transition from inbox to message suggests the message is a layer on top of the inbox, so the close button is appropriate. Gmail *(below) *positions the message as a distinct level of the app and uses the up button.
+- **向上键**往往是当用户沿着应用层级结构返回上级菜单时使用到,常出现于应用工具栏。点击向上键,窗口延时间先后顺序后退直到用户到达最顶级父页面。由于顶级父页面无法再往上跳出应用,向上键不应该出现在顶极父页面中。
+
+- **返回键**存在于系统底部导航栏。它的导航作用是沿时间顺序后退,而非应用页面的层级关系,哪怕前一个时间节点是在其它应用中。它还用于关闭临时页面元素,比如对话框,底部表单等层叠面板。
+
+- **关闭键**通常用于关闭界面临时层,或者放弃修改[全屏对话框](https://material.io/guidelines/components/dialogs.html#dialogs-full-screen-dialogs)。例如 Google 日历事件详情页(下图)。全屏日历事件详情页面属于很明显是临时页,设计时使用关闭键。Google 邮箱应用(下图)中,从收件箱到邮件正文的渐进效果显示,邮件正文是收件箱页面的叠加层,因此使用关闭键较合适。 而 Gmail 应用中(下图)邮件正文是作为一个独立层存在于应用中的,因此返回键更合适。

@@ -231,13 +231,13 @@ The back, up, and close buttons are all important to navigating an Android UI, b

-Calendar, Inbox, and Gmail
+日历应用,邮箱应用,Gmail 应用
-*📚 Refer specifically to back vs up behavior in the Material Spec *[*here*](https://material.io/guidelines/patterns/navigation.html#navigation-up-back-buttons)*.*
+📚更多关于 后退键 vs 返回键 用户行为探讨,尽在 [Material Design](https://material.io/guidelines/patterns/navigation.html#navigation-up-back-buttons)。
-### 🔄 Combining patterns
+### 🔄 混合模式(Combining patterns)
-Throughout this primer we’ve seen examples of apps that successfully implement each of the various explicit navigation components. Many of these examples also succeed in combining navigation patterns to form a structure that makes sense for users. To wrap up, let’s review a couple of those examples with an eye toward mixing and matching.
+尽管在这份初学者指南中,我们主要分析了使用单个导航组件的成功案例。实际上,这些应用在组合运用多类导航时仍然表现出色,构建了合理的用户行为框架。在文章结尾,我们来看看几个混搭实例。

@@ -247,9 +247,9 @@ Throughout this primer we’ve seen examples of apps that successfully implement
Google+
-Maybe the most obvious example is Google+ *(above)*, which mixes all of the patterns we’ve discussed — tabs, a nav drawer, bottom nav, and in-context navigation.
+可能最显而易见的实例便是 Google+(上图),混合上述所有元素 —— 标签页、底部导航、上下文导航。
-To break it down, the bottom nav is the focus in G+. It provides access to four top-level destinations. Tabs augment two of those destinations by segmenting their content into sensible categories. The nav drawer contains other destinations, both primary and secondary, that might be accessed less frequently.
+分离来看,底部导航是 Google+ 的焦点,可以访问四个顶级页面。而标签页将页面结构化增强,通过不同类别拆分内容。而侧边栏囊括了剩余其它按钮,以访问频率区分主次。

@@ -257,11 +257,11 @@ To break it down, the bottom nav is the focus in G+. It provides access to four

-Play Store
+Google Play 应用商店
-The Play Store *(above)* primarily uses a nav drawer, frequently uses in-context navigation, and occasionally uses tabs.
+Google Play 应用商店(上图)使用侧边栏当作主要导航,大量使用上下文导航,局部使用标签页导航。
-In the shots above, we see destinations reached through the nav drawer. The drawer is still accessible on these screens because they’re all primary destinations. Just below the toolbar we see chips to navigate to filtered content selections, an example of in-context navigation. In app charts, tabs are used to sort the entire charted library into specific segments.
+上图中,我们看到所有从侧边栏进入的页面中,打开侧边栏的图标始终是可点按的,因为这些页面都是最顶级父页面。在顶端工具栏下方,小椭圆片帮助细分页面内容,是典型的上下文导航。在应用下载统计页面,标签页将排列好的应用分门别类。

@@ -269,17 +269,15 @@ In the shots above, we see destinations reached through the nav drawer. The draw

-Google Calendar
-
-Google Calendar *(above)* uses a nav drawer and in-context navigation, and uses both in really interesting ways.
+Google 日历应用
-The drawer in Calendar is non-standard, used mostly to augment the calendar. The calendar itself is controlled by an expanding toolbar panel, and colorful tiles lead users to event details.
+Google 日历应用(上图)巧妙得使用了侧边栏导航和上下文导航。此处侧边栏是一个非标准的日历增强面板。日历本身由可扩展的工具栏控制,不同颜色的色块表示用户的日历事项,点击进入详情即可查看详细日程。
-📚 *Read more about combining navigation patterns *[*here*](https://material.io/guidelines/patterns/navigation.html#navigation-patterns)*.*
+📚 更多混合导航实例[参考此处](https://material.io/guidelines/patterns/navigation.html#navigation-patterns)。
-### 🤔 Have more questions?
+### 🤔 更多问题?
-Navigation is a complex topic. Hopefully this primer provides a good foundation for understanding common navigation principles on Android. If you still have questions, leave a response or catch up on our first [#AskMaterial](https://twitter.com/search?q=%23AskMaterial) session with the [Material Design](http://Material.io) & Design Relations teams on Twitter [here](https://twitter.com/i/moments/884845596145836032)!
+导航本身是一个很复杂的话题,希望这篇导航初识能帮助到读者,对安卓导航的设计原理有一个较好的理解。如果你还有其它问题,欢迎留言或在推特 [#AskMaterial](https://twitter.com/search?q=%23AskMaterial) 话题下与 [Material Design](http://Material.io) 进行互动,当然还有我们团队账号,[猛戳这里](https://twitter.com/i/moments/884845596145836032)关注!
---
diff --git a/TODO/artificial-intelligence-in-ux-design.md b/TODO/artificial-intelligence-in-ux-design.md
index 22f5cf426cf..8b2ce608b77 100644
--- a/TODO/artificial-intelligence-in-ux-design.md
+++ b/TODO/artificial-intelligence-in-ux-design.md
@@ -3,109 +3,107 @@
> * 原文作者:[Mukund Krishna](https://www.sitepoint.com/author/mukund-krishna/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/artificial-intelligence-in-ux-design.md](https://github.com/xitu/gold-miner/blob/master/TODO/artificial-intelligence-in-ux-design.md)
- > * 译者:
- > * 校对者:
+ > * 译者:[Changkun Ou](https://github.com/changkun/)
+ > * 校对者:[Tina92](https://github.com/Tina92)、[shawnchenxmu](https://github.com/shawnchenxmu)
- # Can AI Solve Your UX Design Problems?
+# AI 能解决你的 UX 设计问题吗?

-One of Mark Zuckerberg’s key New Year resolutions for 2016 was to build his own “[simple AI bot](http://www.vanityfair.com/news/2016/12/mark-zuckerberg-spent-100-hours-building-his-own-robot-butler)” that could help him with the household tasks. Remember the image of the butler, Jarvis from Iron Man? That’s a classic Hollywood example of how AI works.
+马克·扎克伯格在 2016 年的重要新年决定之一就是建立属于自己的「[简单 AI 机器人](http://www.vanityfair.com/news/2016/12/mark-zuckerberg-spent-100-hours-building-his-own-robot-butler)」,来帮助他解决家务。还记得钢铁侠的管家 Jarvis 吗?这就是一个关于AI如何发挥作用的好莱坞经典范例。
-But, what precisely is Artificial Intelligence and how can it solve the most common UX problems today?
+那么,人工智能(artificial intelligence, AI)究竟是什么?它又如何能解决当今最常见的UX问题呢

-Tony Stark using Jarvis.
+Tony Stark 在使用 Jarvis。
-Artificial Intelligence (or AI) is an advanced human-like computerized system that has the ability to intelligently manage the activities and systems which humans usually do manually. While bots like Apple’s Siri and Amazon’s Echo are programmed to take on our most mundane tasks, bots like Google’s *Deep Dream* are inherently creative, helping users in problem-solving, thereby improving their experience.
+人工智能(或者说 AI)是一种先进的类人计算机系统,能够聪明的管理通常需要人类手动执行的活动和系统。当苹果的 Siri 和亚马逊的 Echo 这样的机器人还在处理我们最平凡的任务时,像 Google 的 **Deep Dream** 这样的机器人天生就具有创造性,并能帮助用户解决问题,从而改善他们的体验。
-AI is finding its application across multiple real-time scenarios:
+AI 正在多个实时场景中得到应用:
-- **Handle data explosion** – With the advent of smartphones and mobile devices, comes the explosion of data. As the amount of data grows, it is pertinent to have an AI system to analyze, process, organize, and interpret the data.
-- **The ability to decipher our intent** – Netflix can predict from your behavior what kind of TV show or movie will keep you glued to your sofa. Imagine if your AI system can adjust your car’s temperature and turn off the lights when you take your car out of the garage.
-- **Improving the customer experience** – AI can dig deep into details which human eye could probably miss and help you focus on the right data. For instance, [RightClick.io](https://rightclick.io/#/) is a chatbot that helps you create websites by involving you in a conversation. Even if you try to divert it with unrelated questions, this AI device will put you back to the actual job of website creation.
+- **处理数据爆炸**:随着智能手机和移动设备的出现,数据正爆炸式增长。随着数据量的增长,有一个 AI 系统来分析、处理、组织和解释数据。
+- **辨别我们的意图**:Netflix 可以从你的行为中预测什么样的电视节目或电影将让你待在沙发上。想象一下,你的 AI 系统可以调整汽车的温度,在你从车库出来时自动把灯关掉。
+- **改善客户体验**:AI 可深入挖掘人眼可能错过的细节,从而帮助你专注于正确的数据。 比如,[RightClick.io](https://rightclick.io/#/) 是一个聊天机器人,可以让你通过与其对话来创建网站。即使你试着对其用不相关的问题转移话题,这个 AI 设备还是会引导你返回网站创建的实际工作中去。
RightClick.io
-Artificial Intelligence is transforming the way we create user experiences. While movies like *Terminator* have given us a dystopian idea of AI, the reality is totally distinct. AI is a powerful technology that positively influences consumer behavior and enables businesses to provide a great user experience.
+人工智能正在改变我们创造用户体验的方式。 虽然**终结者**的电影给了我们一个 AI 的反乌托邦的想法,但现实是完全不同的。AI 是一种强大的技术,可以积极地影响消费者行为,并使企业能够提供出色的用户体验。
-## Understanding the role of AI in UX
+## 理解 AI 在 UX 中的作用
-To begin with, let us look at a few real-life scenarios of how AI is impacting UX today. Context-intelligent chatbots can delight your customer with prompt and timely advice or workarounds. Navigational apps could direct you to your destination effortlessly. With a few taps/clicks, you will receive your favorite meal at your doorstep.
+首先,让我们来看看如今现实生活中一些 AI 如何影响 UX 的场景。 能够感知上下文的聊天机器人可以通过提供一些及时的建议或解决方法从而取悦你的客户。导航应用程序可以毫不费力地将你引导到目的地。简单点几下,你就可以在家门口收到你最喜爱的餐点。
-### How does this work?
+### 这是怎么工作的?
-The very thought of developing AI came from the idea of science fictions, that described of machines that could talk, think or feel. AI is a combination of several nascent technologies- machine learning, deep learning, chat bots, augmented reality, virtual reality, robots- to name a few.
+开发 AI 的想法来自科幻小说,这些小说描述了可以说话、思考或感受的机器。AI 是多种新兴技术的组合,比如:机器学习、深度学习、聊天机器人、增强现实、虚拟现实和机器人等等。
-AI covers anything to do with infusing intelligence into machines/ devices so that they emulate the unique reasoning power of human beings. All of these can be accomplished by using algorithms that are capable of discovering human behavior patterns and generate insights from the data received and stored by the devices. Artificial Intelligence enabled devices or machines are programmed carefully so that they support in future decision-making.
+AI 涵盖了将智能注入到机器或设备的任何事情,使它们能模仿人类独特的推理能力。 所有这些,都可以通过使用能够发现人类行为模式、并从设备接收和存储的数据产生见解的算法来实现。应该细心的编写启用人工智能的设备或者机器,以便它们能在将来的决策中起到帮助。
-All this might sound simple, but these are interactions powered by the fast growing AI technology. In fact, when it comes to humanizing customer experience, AI will become an indispensable tool in a UX designer’s kit. However, besides architecting human-like conversations and actions, there is a lot more AI can do in the digital realm for generating outstanding UX.
+这一切可能听起来很简单,但这些交互都是由快速增长的 AI 技术提供的。事实上,当涉及人性化客户体验时,AI 将成为 UX 设计师套件中不可或缺的工具。然而,除了构建类似人类的对话和行动之外,AI 还能在数字领域中大显身手,创造出优秀的 UX。
-## 1. A platform to collaborate
+## 1. 一个面向协助的平台
-AI is going mainstream with bots and robots fostering human-like interactions with the power of cognitive intelligence. However, robots cannot replace humans completely. Instead, AI nurtures fruitful collaboration in the domain of UX.
+AI 正在伴随着机器人走向主流,而机器人则通过认知智能的力量培育出了像人一样的互动。然而,机器人不能完全取代人类。相反,AI 在 UX 的领域起到了卓有成效的协助作用。
-For example, [TheGrid.io](https://thegrid.io/) is an algorithm-driven design platform that lets you build highly impressive and optimized websites. The platform is built from the ground up around the concept of continuous A/B testing and refinement layouts. Designers can sift through the multiple options provided by such AI-driven tools and select what works for them.
+例如,[TheGrid.io](https://thegrid.io/) 是一个算法驱动的设计平台,可让您构建高度令人印象深刻和优化的网站。该平台是围绕连续 A/B 测试和细化布局的概念构建的。设计师可以筛选由这些 AI 驱动的工具提供的多个选项,并选择适合它们的功能。

-Like any good assistant, it usually does best when offering fresh options rather than making critical decisions. When designers have an intelligent platform to help them choose a template and verify the same by applying algorithms, it helps them to make more creative decisions.
+像任何好的助手一样,它通常在提供的新选项中做出最好的决定,而不是作出关键的决定。当设计师有一个智能平台帮助他们选择一个模板并通过应用算法来验证模板时,它可以帮助他们做出更多的创造性决策。
-## 2. Journey mapping with AI
+## 2. 用 AI 制定旅程
-Companies like [ReFUEL4](https://www.refuel4.com/) use the power of predictive analytics to understand the online journey of users and map them into segments based on their behavior. The most powerful UX is the one that understands and even predicts user interests and actions.
+像 [ReFUEL4](https://www.refuel4.com/) 这样的公司利用预测分析的力量来了解用户的线上行为,并根据他们的行为对其进行进一步的细化。最强大的 UX 是一个了解甚至能预测用户兴趣和行动的 UX。

-Once the designer is able to map a user’s journey, he can understand the paths a user is expected to travel in course of their digital interactions. AI-powered journey mapping allows you to create simple, engaging, and profitable UI.
+一旦设计师能够制定用户的行程,那么他就可以理解用户在交互过程中所期望路径。AI 驱动的行程制定可让你创建简单、有吸引力和有利可图的用户界面。
-## 3. Taking over repetitive, lower-value creative tasks
+## 3. 接管重复、低价值的创造性任务
-In a multi-device world, designers often have to come up with many graphics and variations of content to cater to multiple forms of a campaign. This can be quite mind-numbing and demands a lot of time.
+在多设备世界里,设计师经常必须提出许多图形和各种各样的内容,以满足各种形式的活动。 这可能很麻烦,要花很多时间。

-Netflix layout generation.
+Netflix 的布局生成。
-That’s why platforms like Netflix hand over these tedious tasks to algorithms. Human designers can map out the ‘rules’ for how a layout should work and then provide the system with a library of raw graphic elements to work with. Netflix’s system is then capable of combining the rules with the image assets to create original movie poster and banner units.
+这就是像 Netflix 这样的平台将这些繁琐的任务交给算法的原因。人类设计师可以绘制布局应如何工作的「规则」,然后为系统提供一个原始图形元素库来处理它们。Netflix 的系统能够将规则与图像素材相结合,以创建原始电影海报和横幅单元。
-When AI handles such tasks, designers can focus more on understanding the user journey and refining these rules. It’s not unlike a scenario where a senior designer is directing a team of junior designers. Each benefits from the other.
+当 AI 处理这些任务时,设计人员可以更多地关注理解用户之旅并完善这些规则。 这与高级设计师正在指导一支初级设计师团队没什么不同的,双赢。
-AI technologies like machine learning empowers digital marketers for granular targeting. For example, IBM’s Watson facilitates psychological user segmentation so that marketers can provide the right content to the right audience at the right time.
+像机器学习这样的 AI 技术可以使数字营销人员进行细粒度定位。例如,IBM 的 Watson 促进心理用户细分,使营销人员能够在正确的时间向正确的受众提供正确的内容。
-### Here is how Watson AI works:
+### Watson AI 的工作原理:
-Watson breaks down questions into different keywords or ‘sentences fragments’ in order to discover statistically related phrases. It not only creates a new algorithm for this operation but executes hundreds of analysis algorithms simultaneously.
+为了发现统计学上相关的短语,Watson 将问题分解成不同的关键字或「句子片段」。它不仅为此操作创建了一种新算法,而且同时执行了数百种分析算法。
-If more algorithms come up with the same answer independently, then Watson is more likely to be correct. Once Watson gets multiple solutions in hand, it verifies the potential workarounds against the database to ascertain if any of them makes sense.
+如果越多的算法独立出现相同的答案,那么 Watson 就越有可能是正确的。一旦 Watson 获得了多个解决方案,它将验证数据库的潜在解决方法,从而确定其中的任何一个是否有意义。
-## How do you mold AI for a better UX?
+## 你会怎样塑造 AI 来获得更好的 UX ?
-AI systems have the ability to analyze large amounts of data quickly and also learn and adjust their behavior in real-time. AI systems can infer from the context and you need to supply them with additional information in the form of business rules, questions, metadata and similar other conditions.
+AI 系统能够快速分析大量数据,并实时学习和调整其行为。 AI 系统可以从上下文中推断,你则需要给它们提供额外的关于业务规则、问题、元数据和类似的类似的其他条件的信息。
-As you work through each design phase to build a great user experience, you can constantly refine the questions that you ask your AI system. This will change the way it analyzes data.
+当你通过每个设计阶段建立良好的用户体验时,你可以不断完善您询问 AI 系统的问题。这将改变分析数据的方式。
-For example, if you are managing a health insurance website, ask plain questions like:
+例如,如果您正在管理健康保险网站,可以问如下问题:
-- How many people between the age 40-60 use your application?
-- How many expecting moms access the system?
+- 40 至 60岁之间有多少人使用你的应用程序?
+- 有多少准妈妈访问系统?
-The system takes your questions, analyzes the data and learns to throw up the best possible answers. Each time you feed a new data or criterion, the system conditions itself using AI technology to enhance your user experience.
+系统会收到你的问题,分析数据并学习给出最佳答案。每当你提供新的数据或标准时,系统会使用人工智能来改善自身的用户体验。
-## The beauty of molding AI is:
+## 塑造 AI 的艺术:
-- You can ask general to specific questions to your AI system. The system attends your questions, takes the data, and self-learns.
-- AI can analyze all the queries made on your search engine, collect more user analytics, identify trends, and generate richer findings.
-- Refine the quality of search results with data – AI can come up with better predictive search terms, provide recommendations, cross-topic referrals (similar to what Amazon offers), and bring more relevant content on top.
-- Above all, AI learns from everyone who has visited your application till now and serves your users with needed content. This makes way for a richer user experience.
-- Information Architecture with AI-AI analyzes both your internal and external data and helps you build information structure for your content management system and a navigation structure for your end users.
+- 你可以向你的 AI 系统询问从一般到特殊问题。系统则处理问题、拿到数据再自我学习。
+- AI 可以分析搜索引擎上的所有查询,收集更多的用户分析结果、识别趋势,并生成更丰富的结果。
+- 使用数据优化搜索结果的质量:AI 可以预测搜索条件、提供建议、跨主题推荐(类似于 Amazon 提供的),从而给出更多相关的内容。
+- 最重要的是,AI 能学习到目前为止所有访问过你应用的用户,并为你的用户提供了所需的内容。这产生了更丰富的用户体验。
+- 具有 AI 的信息架构:AI 分析你的内部和外部数据,并帮助你构建内容管理系统的信息结构和最终用户的导航结构。
-User experience is not necessarily about leveraging data insights, it’s about intelligence too. Artificial intelligence connects the dots by infusing intelligence into the disparate sources of data.
+用户体验不一定是利用对数据的见解,它也是关于智能的。人工智能通过向不同数据源注入智能,从而连接了各类独立的节点。
-Though AI technologies like machine learning, chatbots, VR, robots, AR and other systems are gaining momentum, the growth seems to be gradual. AI, when combined with UX becomes the icon of the future technology. Merging AI with UX is a formula that should lead us to enhanced content findability and reachability.
+虽然像机器学习、聊天机器人、VR、机器人、AR 等系统的 AI 技术正呈增长势头,但增长似乎是渐进的。 AI 与 UX 结合成为未来技术的标志。将 AI 与 UX 合并是一个公式,一个将引领我们增强内容的可查找性和可获取性的公式。
-
- ---
+---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
-
\ No newline at end of file
diff --git a/TODO/building-an-api-gateway-using-nodejs.md b/TODO/building-an-api-gateway-using-nodejs.md
index b4f04eb3e07..c5225c6b79d 100644
--- a/TODO/building-an-api-gateway-using-nodejs.md
+++ b/TODO/building-an-api-gateway-using-nodejs.md
@@ -3,157 +3,167 @@
> * 原文作者:[Péter Márton](https://twitter.com/slashdotpeter)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/building-an-api-gateway-using-nodejs.md](https://github.com/xitu/gold-miner/blob/master/TODO/building-an-api-gateway-using-nodejs.md)
- > * 译者:
- > * 校对者:
+ > * 译者:[MuYunyun](https://github.com/MuYunyun)
+ > * 校对者:[jasonxia23](https://github.com/jasonxia23)、[CACppuccino](https://github.com/CACppuccino)
- # Building an API Gateway using Node.js
+ # 使用 Node.js 搭建一个 API 网关
- Services in a microservices architecture share some common requirements regarding authentication and transportation when they need to be accessible by external clients. API Gateway s provide a **shared layer** to handle differences between service protocols and fulfills the requirements of specific clients like desktop browsers, mobile devices, and legacy systems.
+ 外部客户端访问微服务架构中的服务时,服务端会对认证和传输有一些常见的要求。API 网关提供**共享层**来处理服务协议之间的差异,并满足特定客户端(如桌面浏览器、移动设备和老系统)的要求。
-# Microservices and consumers
+# 微服务和消费者
-Microservices are a service oriented architecture where teams can design, develop and ship their applications independently. It allows **technology diversity** on various levels of the system, where teams can benefit from using the best language, database, protocol, and transportation layer for the given technical challenge. For example, one team can use JSON over HTTP REST while the other team can use gRPC over HTTP/2 or a messaging broker like RabbitMQ.
+微服务是面向服务的架构,团队可以独立设计、开发和发布应用程序。它允许在系统各个层面上的**技术多样性**,团队可以在给定的技术难题中使用最佳语言、数据库、协议和传输层,从而受益。例如,一个团队可以使用 HTTP REST 上的 JSON,而另一个团队可以使用 HTTP/2 上的 gRPC 或 RabbitMQ 等消息代理。
-Using different data serialization and protocols can be powerful in certain situations, but **clients** that want to consume our product may **have different requirements**. The problem can also occur in systems with homogeneous technology stack as consumers can vary from a desktop browser through mobile devices and gaming consoles to legacy systems. One client may expect XML format while the other one wants JSON. In many cases, you need to support both.
+在某些情况下使用不同的数据序列化和协议可能是强大的,但要使用我们的产品的**客户**可能**有不同的需求**。该问题也可能发生在具有同质技术栈的系统中,因为客户可以从桌面浏览器通过移动设备和游戏机到遗留系统。一个客户可能期望 XML 格式,而另一个客户可能希望 JSON 。在许多情况下,您需要同时支持它们。
-Another challenge that you can face when clients want to consume your microservices comes from generic **shared logic** like authentication, as you don't want to re-implement the same thing in all of your services.
+当客户想要使用您的微服务时,您可以面对的另一个挑战来自于通用的**共享逻辑**(如身份验证),因为您不想在所有服务中重新实现相同的事情。
-To summarize: we don't want to implement our internal services in our microservices architecture in a way to support multiple clients and re-implement the same logic all over. This is where the **API Gateway** comes into the picture and provides a **shared layer** to handle differences between service protocols and fulfills the requirements of specific clients.
+总结:我们不想在我们的微服务架构中实现我们的内部服务,以支持多个客户端并可以重复使用相同的逻辑。这就是 **API 网关**出现的原因,其作为**共享层**来处理服务协议之间的差异并满足特定客户端的要求。
-# What is an API Gateway?
+# 什么是 API 网关?
-API Gateway is a type of service in a microservices architecture which provides a shared layer and API for clients to communicate with internal services. The API Gateway can **route requests**, transform protocols, **aggregate data** and **implement shared logic** like authentication and rate-limiters.
+API 网关是微服务架构中的一种服务,它为客户端提供共享层和 API,以便与内部服务进行通信。API 网关可以进行**路由请求**、转换协议、**聚合数据**以及**实现共享逻辑**,如认证和速率限制器。
-You can think about API Gateway as the **entry point** to our microservices world.
+您可以将 API 网关视为我们的微服务世界的**入口点**。
-Our system can have one or multiple API Gateways, depending on the clients' requirements. For example, we can have a separate gateway for desktop browsers, mobile applications and public API(s) as well.
+我们的系统可以有一个或多个 API 网关,具体取决于客户的需求。例如,我们可以为桌面浏览器、移动应用程序和公共 API 提供单独的网关。
-*API Gateway as an entry point to microservices*
+
-## Node.js API Gateway for frontend teams
+**API 网关作为微服务的切入点**
-As API Gateway provides functionality for client applications like browsers - it can be implemented and managed by the team who is responsible for the frontend application.
+## Node.js 用于前端团队的 API 网关
-It also means that language the API Gateway is implemented in language should be chosen by the team who is responsible for the particular client. As JavaScript is the primary language to develop applications for the browser, Node.js can be an excellent choice to implement an API Gateway even if your microservices architecture is developed in a different language.
+由于 API 网关为客户端应用程序(如浏览器)提供了功能,它可以由负责开发前端应用程序的团队实施和管理。
-Netflix successfully uses Node.js API Gateways with their Java backend to support a broad range of clients - to learn more about their approach read [The "Paved Road" PaaS for Microservices at Netflix](https://www.infoq.com/news/2017/06/paved-paas-netflix) article.
+这也意味着用哪种语言实现 API Gateway 应由负责特定客户的团队选择。由于 JavaScript 是开发浏览器应用程序的主要语言,即使您的微服务架构以不同的语言开发,Node.js 也可以成为实现 API 网关的绝佳选择。
-*Netflix's approach to handle different clients, [source](https://www.slideshare.net/yunongx/paved-paas-to-microservices)*
+Netflix 成功地使用 Node.js API 网关及其 Java 后端来支持广泛的客户端 - 了解更多关于它们的方法阅读 [The "Paved Road" PaaS for Microservices at Netflix](https://www.infoq.com/news/2017/06/paved-paas-netflix) 这篇文章
+
-# API Gateway functionalities
+**Netflix 处理不同客户端的方法, [资源](https://www.slideshare.net/yunongx/paved-paas-to-microservices)**
-We discussed earlier that you can put generic shared logic into your API Gateway, this section will introduce the most common gateway responsibilities.
+# API 网关功能
-## Routing and versioning
+我们之前讨论过,可以将通用共享逻辑放入您的 API 网关,本节将介绍最常见的网关职责。
-We defined the API Gateway as the entry point to your microservices. In your gateway service, you can **route requests** from a client to specific services. You can even **handle versioning** during routing or change the backend interface while the publicly exposed interface can remain the same. You can also define new endpoints in your API gateway that cooperates with multiple services.
+## 路由和版本控制
-*API Gateway as microservices entry point*
+我们将 API 网关定义为您的微服务的入口点。在您的网关服务中,您可以指定从客户端路由到特定服务的**路由请求**。您甚至可以通过路由**处理版本**或更改后端接口,而公开的接口可以保持不变。您还可以在您的 API 网关中定义与多个服务配合的新端点。
-### Evolutionary design
+
-The API Gateway approach can also help you to **break down your monolith** application. In most of the cases rewriting your system from scratch as a microservices is not a good idea and also not possible as we need to ship features for the business during the transition.
+**API 网关作为微服务入口点**
-In this case, we can put a proxy or an API Gateway in front of our monolith application and implement **new functionalities as microservices** and route new endpoints to the new services while we can serve old endpoints via monolith. Later we can also break down the monolith with moving existing functionalities into new services.
+### 网关设计的升级
-With evolutionary design, we can have a **smooth transition** from monolith architecture to microservices.
+API 网关方法也可以帮助您**分解您的整体**应用程序。在大多数情况下,在微服务端重构一个系统不是一个好主意也是不可能的,因为我们需要在重构期间为业务发送新的以及原有的功能。
-*Evolutionary design with API Gateway*
+在这种情况下,我们可以将代理或 API 网关置于我们的整体应用程序之前,将**新功能作为微服务**实现,并将新端点路由到新服务,同时通过原有的路由服务旧端点。这样以后,我们也可以通过将原有功能转变为新服务来分解整体。
-## Authentication
+随着网关设计的升级,我们可以实现整体架构到微型服务的**平滑过渡**
-Most of the microservices infrastructure need to handle authentication. Putting **shared logic** like authentication to the API Gateway can help you to **keep your services small** and **domain focused**.
+
-In a microservices architecture, you can keep your services protected in a DMZ *(demilitarized zone)* via network configurations and **expose** them to clients **via the API Gateway**. This gateway can also handle more than one authentication method. For example, you can support both *cookie* and *token* based authentication.
+**API 网关设计的升级**
-*API Gateway with Authentication*
+## 认证
-## Data aggregation
+大多数微服务基础设施需要进行身份验证。将**共享逻辑**(如身份验证)添加到 API 网关可以帮助您**保持您的服务的体积变小**以及**可以集中管理域**。
-In a microservices architecture, it can happen that the client needs data in a different aggregation level, like **denormalizing data** entities that take place in various microservices. In this case, we can use our API Gateway to **resolve** these **dependencies** and collect data from multiple services.
+在微服务架构中,您可以通过网络配置将您的服务保护在 DMZ **(保护区)**中,并通过 API 网关向客户**公开**。该网关还可以处理多个身份验证方法。例如,您可以同时支持基于 **cookie** 和 **token** 的身份验证。
-In the following image you can see how the API Gateway merges and returns user and credit information as one piece of data to the client. Note, that these are owned and managed by different microservices.
+
+
+**具有认证功能的 API 网关**
+
+## 数据汇总
+
+在微服务架构中,可能客户端所需要的数据的聚合级别不同,比如对在各种微服务中产生的**非规范化数据**实体。在这种情况下,我们可以使用我们的 API 网关来**解决**这些**依赖关系**并从多个服务收集数据。
+
+在下图中,您可以看到 API 网关如何将用户和信用信息作为一个数据返回给客户端。请注意,这些数据由不同的微服务所拥有和管理。

-## Serialization format transformation
+## 序列化格式转换
-It can happen that we need to support clients with **different data serialization format** requirements.
+我们需要支持客户端**不同的数据序列化格式**这样子的需求可能会发生。
-Imagine a situation where our microservices uses JSON, but one of our customers can only consume XML APIs. In this case, we can put the JSON to XML conversion into the API Gateway instead of implementing it in all of the microservices.
+想象一下我们的微服务使用 JSON 的情况,但我们的客户只能使用 XML APIs。在这种情况下,我们可以在 API 网关中把 JSON 转换为 XML,而不是在所有的微服务器中分别进行实现。

-## Protocol transformation
+## 协议转换
-Microservices architecture allows **polyglot protocol transportation** to gain the benefit of different technologies. However most of the client support only one protocol. In this case, we need to transform service protocols for the clients.
+微服务架构允许**多通道协议传输**从而获取多种技术的优势。然而,大多数客户端只支持一个协议。在这种情况下,我们需要转换客户端的服务协议。
-An API Gateway can also handle protocol transformation between client and microservices.
+API 网关还可以处理客户端和微服务器之间的协议转换。
-In the next image, you can see how the client expects all of the communication through HTTP REST while our internal microservices uses gRPC and GraphQL.
+在下一张图片中,您可以看到客户端希望通过 HTTP REST 进行的所有通信,而内部的微服务使用 gRPC 和 GraphQL 。

-## Rate-limiting and caching
+## 速率限制和缓存
-In the previous examples, you could see that we can put generic shared logic like authentication into the API Gateway. Other than authentication you can also implement rate-limiting, caching and various reliability features in you API Gateway.
+在前面的例子中,您可以看到我们可以把通用的共享逻辑(如身份验证)放在 API 网关中。除了身份验证之外,您还可以在 API 网关中实现速率限制,缓存以及各种可靠性功能。
-## Overambitious API gateways
+## 超负荷的 API 网关
-While implementing your API Gateway, you should avoid putting non-generic logic - like domain specific data transformation - to your gateway.
+在实现您的 API 网关时,您应避免将非通用逻辑(如特定数据转换)放入您的网关。
-Services should always have **full ownership over** their **data domain**. Building an overambitious API Gateway **takes the control from service teams** that goes against the philosophy of microservices.
+服务应该始终拥有他们的**数据域**的**全部所有权**。构建一个超负荷的 API 网关,让**微服务团队**来控制,这违背了微服务的理念。
-This is why you should be careful with data aggregations in your API Gateway - it can be powerful but can also lead to domain specific data transformation or rule processing logic that you should avoid.
+这就是为什么你应该关注你的 API 网关中的数据聚合 - 你应该避免它有大量逻辑甚至可以包含特定的数据转换或规则处理逻辑。
-Always define **clear responsibilities** for your API Gateway and only include generic shared logic in it.
+始终为您的 API 网关定义**明确的责任**,并且只包括其中的通用共享逻辑。
-# Node.js API Gateways
+# Node.js API 网关
-While you want to do simple things in your API Gateway like routing requests to specific services you can **use a reverse proxy** like nginx. But at some point, you may need to implement logic that's not supported in general proxies. In this case, you can **implement your own** API Gateway in Node.js.
+当您希望在 API 网关中执行简单的操作,比如将请求路由到特定服务,您可以使用像 nginx 这样的**反向代理**。但在某些时候,您可能需要实现一般代理不支持的逻辑。在这种情况下,您可以在 Node.js 中**实现自己的** API 网关。
-In Node.js you can use the [http-proxy](https://www.npmjs.com/package/http-proxy) package to simply proxy requests to a particular service or you can use the more feature rich [express-gateway](http://www.express-gateway.io/) to create API gateways.
+在 Node.js 中,您可以使用 [http-proxy](https://www.npmjs.com/package/http-proxy) 软件包简单地代理对特定服务的请求,也可以使用更多丰富功能的 [express-gateway](http://www.express-gateway.io/) 来创建 API 网关。
-In our first API Gateway example, we authenticate the request before we proxy it to the *user* service.
+在我们的第一个 API 网关示例中,我们在将代码委托给 **user** 服务之前验证请求。
+```js
const express = require('express')
const httpProxy = require('express-http-proxy')
const app = express()
const userServiceProxy = httpProxy('https://user-service')
- // Authentication
+ // 身份认证
app.use((req, res, next) => {
- // TODO: my authentication logic
+ // TODO: 身份认证逻辑
next()
})
- // Proxy request
+ // 代理请求
app.get('/users/:userId', (req, res, next) => {
userServiceProxy(req, res, next)
})
+```
+另一种示例可能是在您的 API 网关中发出新的请求,并将响应返回给客户端:
-Another approach can be when you make a new request in your API Gateway, and you return the response to the client:
-
+```js
const express = require('express')
const request = require('request-promise-native')
const app = express()
- // Resolve: GET /users/me
+ // 解决: GET /users/me
app.get('/users/me', async (req, res) => {
const userId = req.session.userId
- const uri = `https://user-service/users/${userId}`const user = await request(uri)
+ const uri = `https://user-service/users/${userId}`
+ const user = await request(uri)
res.json(user)
})
+```
+## Node.js API 网关总结
-## Node.js API Gateways Summarized
-
-API Gateway provides a shared layer to serve client requirements with microservices architecture. It helps to keep your services small and domain focused. You can put different generic logic to your API Gateway, but you should avoid overambitious API Gateways as these take the control from service teams.
-
+API 网关提供了一个共享层,以通过微服务架构来满足客户需求。它有助于保持您的服务小而专注。您可以将不同的通用逻辑放入您的 API 网关,但是您应该避免 API 网关的过度使用,因为很多逻辑可以从服务团队中获得控制。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
-
\ No newline at end of file
diff --git a/TODO/contextual-chat-bots-with-tensorflow.md b/TODO/contextual-chat-bots-with-tensorflow.md
index a24c5e3ea95..c87786082c0 100644
--- a/TODO/contextual-chat-bots-with-tensorflow.md
+++ b/TODO/contextual-chat-bots-with-tensorflow.md
@@ -3,99 +3,98 @@
> * 原文作者:[gk_](https://chatbotsmagazine.com/@gk_)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/contextual-chat-bots-with-tensorflow.md](https://github.com/xitu/gold-miner/blob/master/TODO/contextual-chat-bots-with-tensorflow.md)
-> * 译者:
-> * 校对者:
+> * 译者:[edvardhua](https://github.com/edvardHua)
+> * 校对者:[lileizhenshuai](https://github.com/lileizhenshuai), [jasonxia23](https://github.com/jasonxia23)
-# Contextual Chatbots with Tensorflow
+# 基于 TensorFlow 的上下文机器人
-In conversations, **context is king!** We’ll build a chatbot framework using Tensorflow and add some context handling to show how this can be approached.
+在对话中, **语境决定了一切!** ,在这篇文章中我们将使用 TensorFlow 构建一个能够处理上下文的聊天机器人框架。
-
+有没有想过为什么大多数聊天机器人都不能够理解语境的上下文?
-“Whole World in your Hand” — Betty Newman-Maguire ([http://www.bettynewmanmaguire.ie/](http://www.bettynewmanmaguire.ie/))
-Ever wonder why most chat-bots lack conversational context?
+怎么可能在所有的对话中考虑到上下文的重要性?
-How is this possible given the importance of context in nearly all conversations?
+我们将创建一个“聊天机器人”框架,并为一个岛上的汽车出租店建立一个会话模型,这个小型的聊天机器人需要能够处理关于时间计算,预订选择等简单的功能。我们还希望他能够响应一些上下文的操作,譬如询问当天的租金。这样的话,我们的工作就可以减轻不少。
-We’re going to create a chat-bot framework and build a conversational model for an **island moped rental shop**. The chatbot for this small business needs to handle simple questions about hours of operation, reservation options and so on. We also want it to handle contextual responses such as inquiries about same-day rentals. Getting this right [could save a vacation](https://medium.com/p/how-a-messaging-app-saved-my-vacation-192b031a96f5)!
+我们将通过下面三步来实现这个功能:
-We’ll be working through 3 steps:
+- 首先,把对话意图的定义转换成 TensoFlow 模型
+- 接下来,我们构建一个聊天机器人框架来处理响应
+- 最后,我们将展示如何将基本的上下文合并到我们的相应处理模块中
-- We’ll transform conversational intent definitions to a Tensorflow model
-- Next, we will build a chat-bot framework to process responses
-- Lastly, we’ll show how basic context can be incorporated into our response processor
+我们将使用在 TensorFlow 上构建的高层次 API,也即 [**tflearn**](http://tflearn.org/) ,当然还有 [**Python**](https://www.python.org/) ,同时还使用 [**iPython notebook**](https://ipython.org/notebook.html) 来更好的完成我们的工作
-We’ll be using [**tflearn**](http://tflearn.org/), a layer above [**tensorflow**](https://www.tensorflow.org/), and of course [**Python**](https://www.python.org/). As always we’ll use [**iPython notebook**](https://ipython.org/notebook.html) as a tool to facilitate our work.
---
-#### Transform conversational intent definitions to a Tensorflow model
+#### 将会话意图的定义转换为 TensorFlow 模型
-The complete notebook for our first step is [here](https://github.com/ugik/notebooks/blob/master/Tensorflow%20chat-bot%20model.ipynb).
+这一部分的完整笔记在[这里](https://github.com/ugik/notebooks/blob/master/Tensorflow%20chat-bot%20model.ipynb)
-A chat-bot framework needs a structure in which conversational intents are defined. One clean way to do this is with a JSON file, like [this](https://github.com/ugik/notebooks/blob/master/intents.json).
+一个聊天机器人框架需要一个结构,而其中就定义了会话的意图,在这里我们使用了 json 文件来定义他,如这个[文件](https://github.com/ugik/notebooks/blob/master/intents.json)中所示

-chat-bot intents
-Each conversational intent contains:
+聊天机器人的意图
+每个对话的意图都包含:
-- a **tag** (a unique name)
-- **patterns** (sentence patterns for our neural network text classifier)
-- **responses** (one will be used as a response)
+- 一个 **标签**(tag,唯一标识的名字)
+- **模式**(神经网络文本分类器的句子模式)
+- **响应**(用作响应)
-And later on we’ll add *some basic contextual elements*.
+晚些我们将 **添加一些基本的上下文元素**
-First we take care of our imports:
+首先 import 需要的库
-```
-# things we need for NLP
+```Python
+# NLP 相关的处理库
import nltk
from nltk.stem.lancaster import LancasterStemmer
stemmer = LancasterStemmer()
-# things we need for Tensorflow
+# TensorFlow 相关的库
import numpy as np
import tflearn
import tensorflow as tf
import random
```
-Have a look at “[Deep Learning in 7 lines of code](https://chatbotslife.com/deep-learning-in-7-lines-of-code-7879a8ef8cfb)” for a primer or [here](https://chatbotslife.com/tensorflow-demystified-80987184faf7) if you need to demystify Tensorflow.
+如果你想入门 TensorFlow ,可以看[这篇文章](https://chatbotslife.com/deep-learning-in-7-lines-of-code-7879a8ef8cfb),若要进一步的了解的话可以看[这篇文章](https://chatbotslife.com/tensorflow-demystified-80987184faf7)。
-```
+```Python
# import our chat-bot intents file
import json
with open('intents.json') as json_data:
intents = json.load(json_data)
```
-With our intents JSON [file](https://github.com/ugik/notebooks/blob/master/intents.json) loaded, we can now begin to organize our documents, words and classification classes.
+意图的 JSON 文件被加载后,我们现在可以开始组织我们的文档、文字和分类器对应的类别。
-```
+
+```Python
words = []
classes = []
documents = []
ignore_words = ['?']
-# loop through each sentence in our intents patterns
+# 根据意图遍历所有的句子
for intent in intents['intents']:
for pattern in intent['patterns']:
- # tokenize each word in the sentence
+ # 分词
w = nltk.word_tokenize(pattern)
- # add to our words list
+ # 将词添加到列表中
words.extend(w)
- # add to documents in our corpus
+ # 将文档添加到词料库
documents.append((w, intent['tag']))
- # add to our classes list
+ # 将 Tag 添加到类别中
if intent['tag'] not in classes:
classes.append(intent['tag'])
-# stem and lower each word and remove duplicates
+# 将词小写然后去掉忽略的词
words = [stemmer.stem(w.lower()) for w in words if w not in ignore_words]
words = sorted(list(set(words)))
-# remove duplicates
+# 使用 set 去掉重复的词
classes = sorted(list(set(classes)))
print (len(documents), "documents")
@@ -103,109 +102,110 @@ print (len(classes), "classes", classes)
print (len(words), "unique stemmed words", words)
```
-We create a list of documents (sentences), each sentence is a list of *stemmed**words* and each document is associated with an intent (a class).
+我们创建了一个文档(句子)列表,每个句子都是一个词干的列表,每个文档都与一个意图(一个类)相关。
-```
+```Python
27 documents
9 classes ['goodbye', 'greeting', 'hours', 'mopeds', 'opentoday', 'payments', 'rental', 'thanks', 'today']
44 unique stemmed words ["'d", 'a', 'ar', 'bye', 'can', 'card', 'cash', 'credit', 'day', 'do', 'doe', 'good', 'goodby', 'hav', 'hello', 'help', 'hi', 'hour', 'how', 'i', 'is', 'kind', 'lat', 'lik', 'mastercard', 'mop', 'of', 'on', 'op', 'rent', 'see', 'tak', 'thank', 'that', 'ther', 'thi', 'to', 'today', 'we', 'what', 'when', 'which', 'work', 'you']
```
-The stem ‘tak’ will match ‘take’, ‘taking’, ‘takers’, etc. We could clean the words list and remove useless entries but this will suffice for now.
+词干 "tak" 将会和 "take", "taking","takers" 等词匹配。我们可以清理单词列表并删除无用的条目,但这就足够了。
-Unfortunately this data structure won’t work with Tensorflow, we need to transform it further: *from documents of words *into* tensors of numbers*.
+但是目前的数据结构不能够被 TensorFlow 利用,我们需要进一步的转换它: **也即将文档中的词转换成数字的张量。**
-```
-# create our training data
+
+```Python
+# 创建训练数据
training = []
output = []
-# create an empty array for our output
+# 创建一个空数组来储存输出
output_empty = [0] * len(classes)
-# training set, bag of words for each sentence
+# 每个句子的训练集和词袋
for doc in documents:
- # initialize our bag of words
+ # 初始化词袋
bag = []
- # list of tokenized words for the pattern
+ # 列出文档中所有的词
pattern_words = doc[0]
- # stem each word
+ # 让词成为词干
pattern_words = [stemmer.stem(word.lower()) for word in pattern_words]
- # create our bag of words array
+ # 创建我们的词袋数组
for w in words:
bag.append(1) if w in pattern_words else bag.append(0)
- # output is a '0' for each tag and '1' for current tag
+ # 如果是当前的标记输出 1 ,否的话输出 0
output_row = list(output_empty)
output_row[classes.index(doc[1])] = 1
training.append([bag, output_row])
-# shuffle our features and turn into np.array
+# 打乱训练集并且转换成 np.array 类型
random.shuffle(training)
training = np.array(training)
-# create train and test lists
+# 创建训练集
train_x = list(training[:,0])
train_y = list(training[:,1])
```
-Notice that our data is shuffled. Tensorflow will take some of this and use it as test data *to gauge accuracy for a newly fitted model*.
+注意,我们的数据被打乱了。TensorFlow 会使用其中一部分数据用作测试, **以评估训练模型的准确性。**
-If we look at a single x and y list element, we see ‘[bag of words](https://en.wikipedia.org/wiki/Bag-of-words_model)’ arrays, one for the intent pattern, the other for the intent class.
+下面是一个 x 和 y 的列表元素,也即[词袋](https://en.wikipedia.org/wiki/Bag-of-words_model)数组,一个是意图的模式,另一个是意图所对应的类。
-```
+```Python
train_x example: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1]
train_y example: [0, 0, 1, 0, 0, 0, 0, 0, 0]
```
-We’re ready to build our model.
+我们已经准备好了,可以创建我们的模型了。
-```
-# reset underlying graph data
+```Python
+# 重置底层图数据
tf.reset_default_graph()
-# Build neural network
+# 创建神经网络
net = tflearn.input_data(shape=[None, len(train_x[0])])
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, len(train_y[0]), activation='softmax')
net = tflearn.regression(net)
-# Define model and setup tensorboard
+# 定义模型并创建 tensorboard
model = tflearn.DNN(net, tensorboard_dir='tflearn_logs')
-# Start training (apply gradient descent algorithm)
+# 使用梯度下降方法训练模型
model.fit(train_x, train_y, n_epoch=1000, batch_size=8, show_metric=True)
model.save('model.tflearn')
```
-This is the same tensor structure as we used in our 2-layer neural network in [our ‘toy’ example](https://chatbotslife.com/deep-learning-in-7-lines-of-code-7879a8ef8cfb). Watching the model fit our training data never gets old…
+这个张量的结构与我们[之前在一篇文章](https://chatbotslife.com/deep-learning-in-7-lines-of-code-7879a8ef8cfb)中使用的 2 层神经网络是相同的,训练模型的方式是不会过时的。
+
-interactive build of a model in tflearn
-To complete this section of work, we’ll save (‘pickle’) our model and documents so the next notebook can use them.
+使用 tflearn 交互式构建模型
+为了完成这部分的工作,我们将序列化保存(pickle)模型和文档以便我们在以后的 Jupyter Notebook 中可以使用他们。
-```
-# save all of our data structures
+```Python
+# 保存我们所有的数据结构
import pickle
pickle.dump( {'words':words, 'classes':classes, 'train_x':train_x, 'train_y':train_y}, open( "training_data", "wb" ) )
```
---
-
-#### Building our chat-bot framework
+#### 创建我们的聊天机器人框架
-The complete notebook for our second step is [here](https://github.com/ugik/notebooks/blob/master/Tensorflow%20chat-bot%20response.ipynb).
+这部分的完整 notebook 在[这里](https://github.com/ugik/notebooks/blob/master/Tensorflow%20chat-bot%20response.ipynb)可以下载。
-We’ll build a simple state-machine to handle responses, using our intents model (from the previous step) as our classifier. That’s [how chat-bot’s work](https://medium.freecodecamp.com/how-chat-bots-work-dfff656a35e2).
+我们创建了一个简单的状态机来处理响应,用我们的意图模型(上一步训练的结果)作为分类器。 [聊天机器人是如何工作的](https://medium.freecodecamp.com/how-chat-bots-work-dfff656a35e2)
-> A contextual chat-bot framework is a classifier within a *state-machine*.
+> 上下文的聊天机器人框架是 **状态机** 内的一个分类器。
-After loading the same imports, we’ll *un-pickle* our model and documents as well as reload our intents file. Remember our chat-bot framework is separate from our model build — you don’t need to rebuild your model unless the intent patterns change. With several hundred intents and thousands of patterns the model could take several minutes to build.
+加载相同的导入模块后,我们将 **反序列化** 我们的模型和文档并且重新加载我们的意图文件。记住我们的 chat-bot 框架是和我们的模型分开来构建的—你不需要重新构建你的模型除非意图模式发生改变。因为有几百个意图和数千个模式,所以这个模型可能需要几分钟的时间来构建。
-```
-# restore all of our data structures
+```Python
+# 重置变量
import pickle
data = pickle.load( open( "training_data", "rb" ) )
words = data['words']
@@ -213,34 +213,34 @@ classes = data['classes']
train_x = data['train_x']
train_y = data['train_y']
-# import our chat-bot intents file
+# 导入聊天机器人的意图文件
import json
with open('intents.json') as json_data:
intents = json.load(json_data)
```
-Next we will load our saved Tensorflow (tflearn framework) model. Notice you first need to define the Tensorflow model structure just as we did in the previous section.
+接下来将加载我们保存在 TensorFlow (tflearn framework) 上的模型。首先我们需要和前面章节所述的一样来定义 TensorFlow 模型的结构。
-```
-# load our saved model
+```Python
+# 加载保存的模型
model.load('./model.tflearn')
```
-Before we can begin processing intents, we need a way to produce a bag-of-words *from user input*. This is the same technique as we used earlier to create our training documents.
+在开始处理意图之前,我们需要 **从用户的输入** 中生成词袋(bag-of-words),这和我们之前创建训练文档时使用的技术是一样的。
-```
+```Python
def clean_up_sentence(sentence):
- # tokenize the pattern
+ # 分词
sentence_words = nltk.word_tokenize(sentence)
- # stem each word
+ # 转换句子为词干
sentence_words = [stemmer.stem(word.lower()) for word in sentence_words]
return sentence_words
-# return bag of words array: 0 or 1 for each word in the bag that exists in the sentence
+# 返回词袋数组,每个数组的下标表示词的序号,如果句子包含该词,则该数组词为 1,否为 0
def bow(sentence, words, show_details=False):
- # tokenize the pattern
+ # pattern 分词
sentence_words = clean_up_sentence(sentence)
- # bag of words
+ # 词袋
bag = [0]*len(words)
for s in sentence_words:
for i,w in enumerate(words):
@@ -258,61 +258,60 @@ print (p)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0]
```
-We are now ready to build our response processor.
+我们现在可以构建我们的响应处理器了。
-```
+```Python
ERROR_THRESHOLD = 0.25
def classify(sentence):
- # generate probabilities from the model
+ # 得出预测的概率
results = model.predict([bow(sentence, words)])[0]
- # filter out predictions below a threshold
+ # 根据概率值过滤结果
results = [[i,r] for i,r in enumerate(results) if r>ERROR_THRESHOLD]
- # sort by strength of probability
+ # 根据返回值长度降序排序
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append((classes[r[0]], r[1]))
- # return tuple of intent and probability
+ # 返回包含意图和概率的元组
return return_list
def response(sentence, userID='123', show_details=False):
results = classify(sentence)
- # if we have a classification then find the matching intent tag
+ # results 不为空则循环找到匹配的 tag
if results:
- # loop as long as there are matches to process
+ # 循环找到匹配的 tag
while results:
for i in intents['intents']:
- # find a tag matching the first result
+ # 是否匹配
if i['tag'] == results[0][0]:
- # a random response from the intent
+ # 随机输出一个响应??
return print(random.choice(i['responses']))
-
results.pop(0)
```
-Each sentence passed to response() is classified. Our classifier uses **model.predict()** and is lighting fast. The probabilities returned by the model are lined-up with our intents definitions to produce a list of potential responses.
+句子传递到 response() 方法后会被分类。我们分类器使用 **model.predict()** 方法是响应很快的。模型返回的响应结果的概率列表是和我们的意图定义一起处理的。
-If one or more classifications are above a threshold, we see if a tag matches an intent and then process that. We’ll treat our classification list as a stack and pop off the stack looking for a suitable match until we find one, or it’s empty.
+如果一个或多个分类器超过一个阈值,那么我们就会看到一个标记是否匹配一个意图然后再处理它。分类器列表将会当成栈,然后不断的从栈中弹出一个元素来进行匹配是否符合,直到空栈为止。
-Let’s look at a classification example, the most likely tag and its probability are returned.
+让我们来看一个分类器的例子,我们看到最可能的标记和它所对应的概率值被返回了。
-```
+```Python
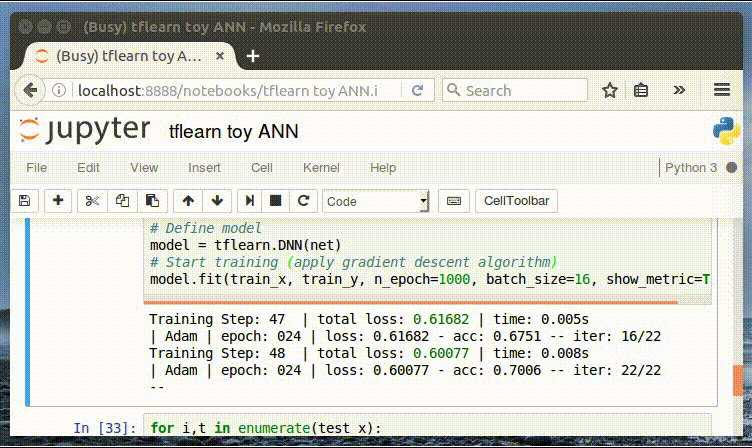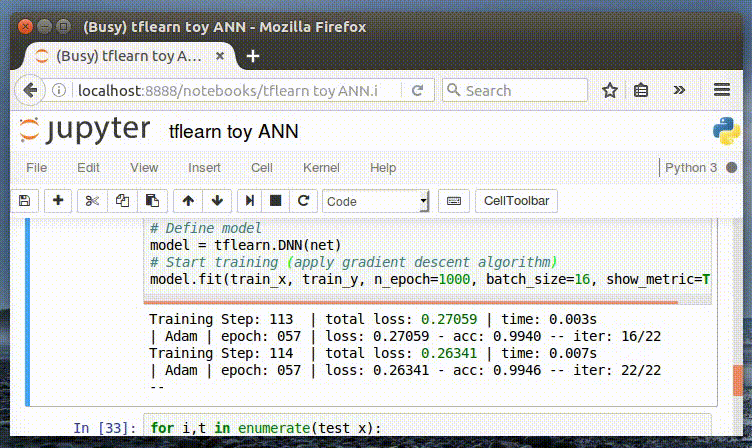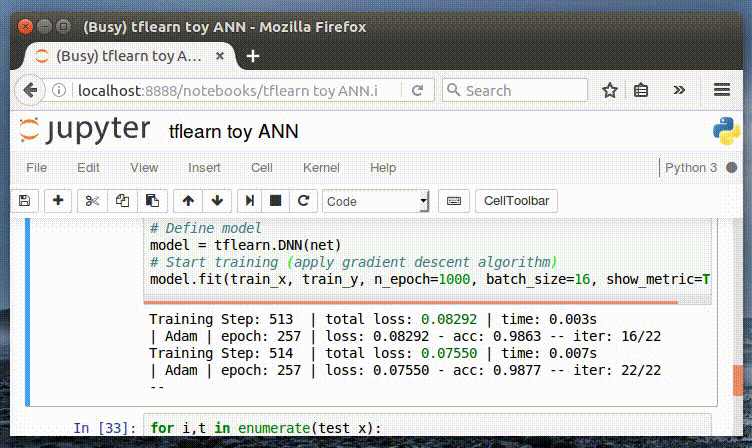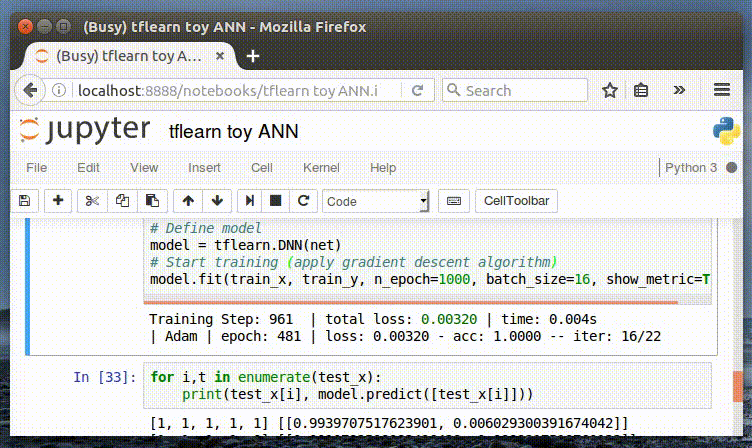
classify('is your shop open today?')
[('opentoday', 0.9264171123504639)]
```
-Notice that ‘is your shop open today?’ is not one of the patterns for this intent: *“patterns”: [“Are you open today?”, “When do you open today?”, “What are your hours today?”] *however the terms ‘open’ and ‘today’ proved irresistible to our model (they are prominent in the chosen intent).
+注意到“你的商店今天营业吗”并不是这种意图的模式之一: **模式:["你今天开着吗?","你今天什么时候开?","你今天营业几小时?"]** ,然而词“开”和“今天”对我们的模式来说是很重要的(也就是说他们决定了模型会选择什么意图)。
-We can now generate a chat-bot response from user-input:
+所以我们就可以根据用户的输入生成一个 chat-bot 的回应
-```
+```Python
response('is your shop open today?')
Our hours are 9am-9pm every day
```
-And other context-free responses…
+下面是另外一个上下文无关的响应。
-```
+```Python
response('do you take cash?')
We accept VISA, Mastercard and AMEX
response('what kind of mopeds do you rent?')
@@ -323,87 +322,83 @@ Bye! Come back again soon.
---
-
-Let’s work in some basic context into our moped rental chat-bot conversation.
+让我们给出租汽车的聊天机器人加入一些基本的上下文吧。
-#### Contextualization
+#### 情景化
-We want to handle a question about renting a moped and ask if the rental is for today. That clarification question is a simple contextual response. If the user responds ‘today’ *and the context is the rental timeframe* then it’s best they call the rental company’s 1–800 #. No time to waste.
+我们想要让聊天机器人处理关于出租汽车的对话,比如询问客户是否要今天租赁。这个问题是一个简单的上下文响应,如果用户回复“今天”,那么上下文就是租赁时间,这个时候就赶紧给租赁公司打电话吧,他不想错过这个订单的。
-To achieve this we will add the notion of ‘state’ to our framework. This is comprised of a data-structure to maintain state and specific code to manipulate it while processing intents.
+为了实现这一目的,我们在框架中添加了状态这个概念。这由一个保存状态的数据结构和操作状态的特定代码组成,以便处理意图。
-Because the state of our state-machine needs to be easily persisted, restored, copied, etc. it’s important to keep it all in a data structure such as a dictionary.
+因为状态机(state-machine)需要很容易地持久化、恢复、复制等等,所以把它保存在像字典这样的数据结构中是很重要的。
-Here’s our response process with basic contextualization:
+以下是我们对基本情景化的反应过程:
-```
-# create a data structure to hold user context
-context = {}
+```Python
+# 字典储存上下文
+context = {}
ERROR_THRESHOLD = 0.25
def classify(sentence):
- # generate probabilities from the model
+ # 得到的预测的结果(概率)列表
results = model.predict([bow(sentence, words)])[0]
- # filter out predictions below a threshold
+ # 根据错误阈值筛选预测的结果
results = [[i,r] for i,r in enumerate(results) if r>ERROR_THRESHOLD]
- # sort by strength of probability
+ # 根据概率值倒序排序
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append((classes[r[0]], r[1]))
- # return tuple of intent and probability
+ # 返回意图和概率的元组
return return_list
def response(sentence, userID='123', show_details=False):
results = classify(sentence)
- # if we have a classification then find the matching intent tag
+ # 根据分类结果匹配意图标签
if results:
- # loop as long as there are matches to process
+ # 循环匹配
while results:
for i in intents['intents']:
- # find a tag matching the first result
+ # 寻找与第一个结果匹配的标签
if i['tag'] == results[0][0]:
- # set context for this intent if necessary
+ # 在必要时为这个意图设置上下文
if 'context_set' in i:
if show_details: print ('context:', i['context_set'])
context[userID] = i['context_set']
-
- # check if this intent is contextual and applies to this user's conversation
+ # 检查这个意图是否与上下文相关然后与当前用户关联
if not 'context_filter' in i or \
(userID in context and 'context_filter' in i and i['context_filter'] == context[userID]):
if show_details: print ('tag:', i['tag'])
- # a random response from the intent
+ # 返回响应
return print(random.choice(i['responses']))
-
results.pop(0)
```
-Our context state is a dictionary, it will contain state for each user. We’ll use some unique identified for each user (eg. cell #). This allows our framework and state-machine to *maintain state for multiple users simultaneously*.
+我们的上下文状态是一个字典,他将包含每个用户的状态。每个用户都有唯一的标识符,从而达到让我们的框架能够 **无缝地维持多个用户之间的状态。**
-> # create a data structure to hold user context
+> # 使用字典来维持用户的上下文
> context = {}
-The context handlers are added within the intent processing flow, shown again below:
+上下文处理程序被添加到意图处理流中,如下所示:
+```Python
+ if i['tag'] == results[0][0]:
+ # 在必要时为这个意图设置上下文
+ if 'context_set' in i:
+ if show_details: print ('context:', i['context_set'])
+ context[userID] = i['context_set']
+ # 检查这个意图是否与上下文相关然后与当前用户关联
+ if not 'context_filter' in i or \
+ (userID in context and 'context_filter' in i and i['context_filter'] == context[userID]):
+ if show_details: print ('tag:', i['tag'])
+ # 返回响应
+ return print(random.choice(i['responses']))
```
- if i['tag'] == results[0][0]:
- # set context for this intent if necessary
- if 'context_set' in i:
- if show_details: print ('context:', i['context_set'])
- context[userID] = i['context_set']
- # check if this intent is contextual and applies to this user's conversation
- if not 'context_filter' in i or \
- (userID in context and 'context_filter' in i and i['context_filter'] == context[userID]):
- if show_details: print ('tag:', i['tag'])
- # a random response from the intent
- return print(random.choice(i['responses']))
-```
-
-If an intent wants to **set** context, it can do so:
+如果一个意图想要设置上下文,他可以这样做:
-```
+```Python
{“tag”: “rental”,
“patterns”: [“Can we rent a moped?”, “I’d like to rent a moped”, … ],
“responses”: [“Are you looking to rent today or later this week?”],
@@ -411,9 +406,9 @@ If an intent wants to **set** context, it can do so:
}
```
-If another intent wants to be contextually linked to a context, it can do that:
+如果另外一个意图想要和上下文联系,那么他可以这样做:
-```
+```Python
{“tag”: “today”,
“patterns”: [“today”],
“responses”: [“For rentals today please call 1–800-MYMOPED”, …],
@@ -421,23 +416,23 @@ If another intent wants to be contextually linked to a context, it can do that:
}
```
-In this way, if a user just typed ‘today’ out of the blue (no context), our ‘today’ intent won’t be processed. If they enter ‘today’ *as a response to our clarification question* (intent tag:‘rental’) then the intent is processed.
+用这种方式,当用户只是意料之外地输入“今天“的的时候(没有上下文),“今天” 这个意图就不会被处理。当他们输入的 “今天” 作为回复我们提出的问题的时候,那么这个意图就会被处理。
-```
+```Python
response('we want to rent a moped')
Are you looking to rent today or later this week?
response('today')
Same-day rentals please call 1-800-MYMOPED
```
-Our context state changed:
+我们的上下文状态就会改变
```
context
{'123': 'rentalday'}
```
-We defined our ‘greeting’ intent to clear context, as is often the case with small-talk. We add a ‘show_details’ parameter to help us see inside.
+我们定义“问候”的语句来清除上下文,就像闲聊时经常发生的那样。我们添加了一个 “查看详情” 的参数来帮助我们查看内部的运作。
```
response("Hi there!", show_details=True)
@@ -446,66 +441,60 @@ tag: greeting
Good to see you again
```
-Let’s try the ‘today’ input once again, a few notable things here…
+让我们再尝试一下输入 “今天”,这里有一些需要注意的东西...
-```
+```Python
response('today')
We're open every day from 9am-9pm
classify('today')
[('today', 0.5322513580322266), ('opentoday', 0.2611265480518341)]
```
-First, our response to the context-free ‘today’ was different. Our classification produced 2 suitable intents, and the ‘opentoday’ was selected because the ‘today’ intent, while higher probability, was bound to *a context that no longer applied*. Context matters!
+首先,我们对上下文无关的“今天”的反应是不同的。我们的分类产生了 2 个合适的意图,但是 'opentoday' 被选中, 'today' 意图虽然具备更高的可能性,但是却被限制在一个不再合适的环境中,**所以说上下文很重要**。
-```
+```Python
response("thanks, your great")
Happy to help!
```
---
-
-
-A few things to consider now that contextualization is happening…
+在语境化发生的情况下有几件事情需要考虑。
-#### With state comes statefulness
+#### 维持状态
-That’s right, your chat-bot will no longer be happy *as a stateless service*.
+没错,你的聊天机器人将不再是一种 **无状态的服务**。
-Unless you want to reconstitute state, reload your model and documents — with every call to your chat-bot framework, you’ll need to make it *stateful*.
+除非你想重新构建状态,重新加载模型和文档—每次调用你的聊天机器人框架时,你都需要使其成为有状态的。
-This isn’t that difficult. You can run a stateful chat-bot framework in its own process and call it using an RPC (remote procedure call) or RMI (remote method invocation), I recommend [Pyro](http://pythonhosted.org/Pyro4/).
+这并不是那么难,你可以运行一个有状态的聊天机器人框架的过程,也即使用远程过程调用 RPC 或者远程方法调用 RMI,在这里我推荐使用 [Pyro](http:/。pythonhosted.org/Pyro4/)。

-RMI client and server setup
-The user-interface (client) is typically stateless, eg. HTTP or SMS.
+RMI 客户端和服务器设置
+用户界面(客户端)通常是无状态的,例如。HTTP 或 SMS。
-Your chat-bot *client* will make a Pyro function call, which your stateful service will handle. Voila!
+你 **客户端** 的聊天机器人将会创建一个 Pyro 函数调用,你的有状态服务将会处理他。
-[Here](https://chatbotslife.com/build-a-working-sms-chat-bot-in-10-minutes-b8278d80cc7a)’s a step-by-step guide to build a Twilio SMS chat-bot client, and [here](https://chatbotnewsdaily.com/build-a-facebook-messenger-chat-bot-in-10-minutes-5f28fe0312cd)’s one for FB Messenger.
+这里有一篇一步一步指导你构建 Twilio SMS 聊天机器人客户端的[文章](https://chatbotslife.com/build-a-working-sms-chat-bot-in-10-minutes-b8278d80cc7a),另外一篇[文章](https://chatbotnewsdaily.com/build-a-facebook-messenger-chat-bot-in-10-minutes-5f28fe0312cd)是关于构建 FB Messenger 的。
-#### Thou shalt not store state in local variables
+#### 不可将状态储存在局部变量中
-All state information must be placed in a data structure such as a dictionary, easily persisted, reloaded, or copied atomically.
+所有的状态信息都必须放在像字典这样的数据结构中,很容易持久化、重新加载或复制。
-Each user’s conversation will carry context which will be carried statefully for that user. The user ID can be their cell #, a Facebook user ID, or some other unique identifier.
+每个用户的对话都将承载为该用户提供状态的上下文。用户的唯一标识 ID 可以是手机号,Facebook 的用户 ID 或者其他的唯一标识符
-There are scenarios where a user’s conversational state needs to be copied (by value) and then restored as a result of intent processing. If your state machine carries state across variables within your framework you will have a difficult time making this work in real life scenarios.
+在一些场景中用户的对话状态需要被复制然后重新储存起来被意图所处理。如果你的状态机携带的一些状态的变量在框架中是共用的话,则很难在实际场景中实现这一工作。
-> Python dictionaries are your friend.
+> Python 字典是你的朋友
---
-So now you have a chat-bot framework, a recipe for making it a stateful service, and a starting-point for adding context. Most chat-bot frameworks [in the future will treat context seamlessly](https://medium.com/@gk_/the-future-of-messaging-apps-590720cfa792).
-
-Think of creative ways for intents to impact and react to different context settings. Your users’ context dictionary can contain a wide-variety of conversation context.
-
-**Enjoy!**
+现在你已经知道如何构建一个聊天机器人的框架以及使它具备有服务状态的方法,[大部分聊天机器人框架都能够无缝地处理上下文](https://medium.com/@gk_/the-future-of-messaging-apps-590720cfa792)。
-
+多想一些有创意的方法来影响聊天机器人对不同上下文所做出设置。你的用户的上下文字典可以包含各种各样的对话上下文。
-credit: [https://wickedgoodweb.com](https://wickedgoodweb.com/seo-context-is-king/)
+**享受它吧!**
---
diff --git a/TODO/deep-learning-4-embedding-layers.md b/TODO/deep-learning-4-embedding-layers.md
index 7a1c4b0dc04..e948234b142 100644
--- a/TODO/deep-learning-4-embedding-layers.md
+++ b/TODO/deep-learning-4-embedding-layers.md
@@ -3,88 +3,87 @@
> * 原文作者:[Rutger Ruizendaal](https://medium.com/@r.ruizendaal)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/deep-learning-4-embedding-layers.md](https://github.com/xitu/gold-miner/blob/master/TODO/deep-learning-4-embedding-layers.md)
-> * 译者:
-> * 校对者:
+> * 译者:[Tobias Lee](http://tobiaslee.top)
+> * 校对者:[LJ147](https://github.com/LJ147)、[changkun](https://github.com/changkun)
-# Deep Learning 4: Why You Need to Start Using Embedding Layers
+# 深度学习系列4: 为什么你需要使用嵌入层
-## And how there’s more to it than word embeddings.
+## 除了词嵌入以外还有很多
-*This post is part of a series on deep learning. Checkout the other parts here:*
+**这是深度学习系列的其中一篇,其他文章地址如下**
-1. [Setting up AWS & Image Recognition](https://medium.com/towards-data-science/deep-learning-1-1a7e7d9e3c07)
-2. [Convolutional Neural Networks](https://medium.com/towards-data-science/deep-learning-2-f81ebe632d5c)
-3. [More on CNNs & Handling Overfitting](https://medium.com/towards-data-science/deep-learning-3-more-on-cnns-handling-overfitting-2bd5d99abe5d)
+1. [设置 AWS & 图像识别](https://github.com/xitu/gold-miner/blob/master/TODO/deep-learning-1-setting-up-aws-image-recognition.md)
+2. [卷积神经网络](https://github.com/xitu/gold-miner/blob/master/TODO/deep-learning-2-convolutional-neural-networks.md)
+3. [CNNs 以及应对过拟合的详细探讨](https://github.com/xitu/gold-miner/blob/master/TODO/deep-learning-3-more-on-cnns-handling-overfitting.md)
---
-Welcome to part 4 of this series on deep learning. As you might have noticed there has been a slight delay between the first three entries and this post. The initial goal of this series was to write along with the fast.ai course on deep learning. However, the concepts of the later lectures are often overlapping so I decided to finish the course first. This way I get to provide a more detailed overview of these topics. In this blog I want to cover a concept that spans multiple lectures of the course (4–6) and that has proven very useful to me in practice:Embedding Layers.
+欢迎阅读深度学习系列的第四部分,你可能注意到这一篇和前面三篇文章之间隔了一小段时间。我写这个系列最初的目的是想记录 fast.ai 上的深度学习课程,然而后面一部分课程的内容有所重叠,所以我决定先把课程完成,这样我能够更为细致地从整体上来把握这些主题。在这篇文章里我想介绍一个在很多节课中都有涉及,并且在实践中被证明非常有用的一个概念:嵌入层(Embedding layer)。
-Upon introduction the concept of the embedding layer can be quite foreign. For example, the Keras documentation provides no explanation other than “Turns positive integers (indexes) into dense vectors of fixed size”. A quick Google search might not get you much further either since these type of documentations are the first things to pop-up. However, in a sense Keras’ documentation describes all that happens. So why should you use an embedding layer? Here are the two main reasons:
+介绍嵌入层这个概念可能会让它变得更加难以理解。比如说,Keras 文档里是这么写的:“把正整数(索引)转换为固定大小的稠密向量”。你 Google 搜索也无济于事,因为文档通常会排在搜索结果的第一个(你还是不能获得更加详细的解释)。然而,从某种意义上来说,Keras 文档的描述是正确的。那么为什么你应该使用嵌入层呢?这里有两个主要原因:
-1. One-hot encoded vectors are high-dimensional and sparse. Let’s assume that we are doing Natural Language Processing (NLP) and have a dictionary of 2000 words. This means that, when using one-hot encoding, each word will be represented by a vector containing 2000 integers. And 1999 of these integers are zeros. In a big dataset this approach is not computationally efficient.
-2. The vectors of each embedding get updated while training the neural network. If you have seen the image at the top of this post you can see how similarities between words can be found in a multi-dimensional space. This allows us to visualize relationships between words, but also between everything that can be turned into a vector through an embedding layer.
+1. 独热编码(One-hot encoding)向量是高维且稀疏的。假如说我们在做自然语言处理(NLP)的工作,并且有一个包含 2000 个单词的字典。这意味着当我们使用独热编码时,每个单词由一个含有 2000 个整数的向量来表示,并且其中的 1999 个整数都是 0。在大数据集下这种方法的计算效率是很低的。
+2. 每个嵌入向量会在训练神经网络时更新。文章的最上方有几张图片,它们展示了在多维空间之中,词语之间的相似程度,这使得我们能够可视化词语之间的关系。同样,对于任何能够通过使用嵌入层而把它变成向量的东西,我们都能够这么做。
-This concept might still be a bit vague. Let’s have a look at what an embedding layer does with an example of words. Nevertheless, the origin of embeddings comes from word embeddings. You can look up [word2vec](https://arxiv.org/pdf/1301.3781.pdf) if you are interested in reading more. Let’s take this sentence as an example (do not take it to seriously):
+嵌入层这个概念可能还是有点模糊,让我们再来看嵌入层作用在词语上的一个例子。嵌入这个概念源自于词嵌入(Word embedding),如果你想了解更多的话可以看看 [word2vec](https://arxiv.org/pdf/1301.3781.pdf) 这篇论文。让我们用下面这个句子作为例子(随便举的一个例子,不用太认真对待):
> “deep learning is very deep”
-The first step in using an embedding layer is to encode this sentence by indices. In this case we assign an index to each unique word. The sentence than looks like this:
+使用嵌入层的第一步是通过索引对这个句子进行编码,在这个例子里,我们给句中每个不同的词一个数字索引,编码后的句子如下所示:
> 1 2 3 4 1
-The embedding matrix gets created next. We decide how many ‘latent factors’ are assigned to each index. Basically this means how long we want the vector to be. General use cases are lengths like 32 and 50. Let’s assign 6 latent factors per index in this post to keep it readable. The embedding matrix than looks like this:
+下一步是创建嵌入矩阵。我们要决定每个索引有多少“潜在因素”,这就是说,我们需要决定词向量的长度。一般我们会使用像 32 或者 50 这样的长度。出于可读性的考虑,在这篇文章里我们每个索引的“潜在因素”个数有 6 个。那么嵌入矩阵就如下图所示:

-Embedding Matrix
+嵌入矩阵
-So, instead of ending up with huge one-hot encoded vectors we can use an embedding matrix to keep the size of each vector much smaller. In short, all that happens is that the word “deep” gets represented by a vector [.32, .02, .48, .21, .56, .15]. However, not every word gets replaced by a vector. Instead, it gets replaced by index that is used to look-up the vector in the embedding matrix. Once again, this is computationally efficient when using very big datasets. Because the embedded vectors also get updated during the training process of the deep neural network, we can explore what words are similar to each other in a multi-dimensional space. By using dimensionality reduction techniques like [t-SNE ](https://lvdmaaten.github.io/tsne/)these similarities can be visualized.
+所以,和独热编码中每个词向量的长度相比,使用嵌入矩阵能够让每个词向量的长度大幅缩短。简而言之,我们用一个向量 [.32, .02, .48, .21, .56, .15]来代替了词语“deep”。然而并不是每个词被一个向量所代替,而是由其索引在嵌入矩阵中对应的向量代替。再次强调,在大数据集中,这种方法的计算效率是很高的。同时因为在训练深度神经网络过程中,词向量能够不断地被更新,所以我们同样能够在多维空间中探索各个词语之间的相似程度。通过使用像 [t-SNE ](https://lvdmaaten.github.io/tsne/) 这样的降维技术,我们能够把这些相似程度可视化出来。

-t-SNE visualization of word embeddings
+通过 t-SNE 可视化的词嵌入(向量)
---
-### Not Just Word Embeddings
+### 不仅仅是词嵌入
-These previous examples showed that word embeddings are very important in the world of Natural Language Processing. They allow us to capture relationships in language that are very difficult to capture otherwise. However, embedding layers can be used to embed many more things than just words. In my current research project I am using embedding layers to embed online user behavior. In this case I am assigning indices to user behavior like ‘page view on page type X on portal Y’ or ‘scrolled X pixels’. These indices are then used for constructing a sequence of user behavior.
+前面的例子体现了词嵌入在自然语言处理领域重要的地位,它能够帮助我们找到很难察觉的词语之间的关系。然而,嵌入层不仅仅可以用在词语上。在我现在的一个研究项目里,我用嵌入层来嵌入网上用户的使用行为:我为用户行为分配索引,比如“浏览类型 X 的网页(在门户 Y 上)”或“滚动了 X 像素”。然后,用这些索引构建用户的行为序列。
-In a comparison of ‘traditional’ machine learning models (SVM, Random Forest, Gradient Boosted Trees) with deep learning models (deep neural networks, recurrent neural networks) I found that this embedding approach worked very well for deep neural networks.
+深度学习模型(深度神经网络和循环神经网络)和“传统”的机器学习模型(支持向量机,随机森林,梯度提升决策树)相比,我觉得嵌入方法更适用于深度神经网络。
-The ‘traditional’ machine learning models rely on a tabular input that is feature engineered. This means that we, as researchers, decide what gets turned into a feature. In these cases features could be: amount of homepages visited, amount of searches done, total amount of pixels scrolled. However, it is very difficult to capture the spatial (time) dimension when doing feature-engineering. By using deep learning and embedding layers we can efficiently capture this spatial dimension by supplying a sequence of user behavior (as indices) as input for the model.
+“传统”的机器学习模型,非常依赖经过特征工程的表格式的输入,这意味着需要我们研究者来决定什么是一个特征。在我的那个项目里,作为特征的有:浏览的主页数量、搜索的次数、总共滚动的像素。然而,在特征工程时,我们很难把时间维度方面的特征考虑进去。利用深度学习和嵌入层,我们就能够把用户行为序列(通过索引)作为模型的输入,从而有效地捕捉到时间维度上的特征。
-In my research the Recurrent Neural Network with Gated Recurrent Unit/Long-Short Term Memory performed best. The results were very close. From the ‘traditional’ feature engineered models Gradient Boosted Trees performed best. I will write a blog post about this research in more detail in the future. I think my next blog post will explore Recurrent Neural Networks in more detail.
+在我的研究中,使用 GRU(Gated Recurrent Unit)或者是 LSTM(Long-Short Term Memory)技术的循环神经网络表现地最好,它们的结果很接近。在“传统” 的需要特征工程的模型中,梯度提升决策树表现地最好。关于我的研究项目,我以后会写一篇文章,我的下一篇文章会更细致地讨论关于循环神经网络的问题。
-Other research has explored the use of embedding layers to encode student behavior in MOOCs (Piech et al., 2016) and users’ path through an online fashion store (Tamhane et al., 2017).
+其他还有使用嵌入层来编码学生在慕课上行为的例子(Piech et al., 2016),以及用户浏览在线时尚商店的点击顺序(Tamhane et al., 2017)。
---
-#### Recommender Systems
+#### 推荐系统
-Embedding layers can even be used to deal with the sparse matrix problem in recommender systems. Since the deep learning course (fast.ai) uses recommender systems to introduce embedding layers I want to explore them here as well.
+嵌入层甚至可以用来处理推荐系统中的稀疏矩阵问题。在 fast.ai 的深度学习课程中利用推荐系统来介绍了嵌入层,这里我也想谈谈推荐系统。
-Recommender systems are being used everywhere and you are probably being influenced by them every day. The most common examples are Amazon’s product recommendation and Netflix’s program recommendation systems. Netflix actually held a $1,000,000 challenge to find the best collaborative filtering algorithm for their recommender system. You can see a visualization of one of these models [here](http://abeautifulwww.com/wp-content/uploads/2007/04/netflixAllMovies-blackBack3[5].jpg).
+推荐系统已经广泛地应用在各个领域了,你可能每天都被它们所影响着。亚马逊的产品推荐和 Netflix 的节目推荐系统,是两个最常见的例子。Netflix 举办了一个奖金为一百万美元的比赛,用来寻找最适合他们推荐系统的协同过滤算法。你可以在[这里](http://abeautifulwww.com/wp-content/uploads/2007/04/netflixAllMovies-blackBack3[5].jpg)看到其中一个模型的可视化结果。
-There are two main types of recommender systems and it is important to distinguish between the two.
+推荐系统主要有两种类型,区分它们是很重要的。
-1. Content-based filtering. This type of filtering is based on data about the item/product. For example, we have our users fill out a survey on what movies they like. If they say that they like sci-fi movies we recommend them sci-fi movies. In this case al lot of meta-information has to be available for all items.
-2. Collaborative filtering: Let’s find other people like you, see what they liked and assume you like the same things. People like you = people who rated movies that you watched in a similar way. In a large dataset this has proven to work a lot better than the meta-data approach. Essentially asking people about their behavior is less good compared to looking at their actual behavior. Discussing this further is something for the psychologists among us.
+1. 基于内容过滤:这种过滤是基于物品或者是产品的数据的。比如说,我们让用户填一份他们喜欢的电影的表格。如果他们说喜欢科幻电影,那么我们就给他推荐科幻电影。这种方法需要大量的对应产品的元数据。
+2. 协同过滤:找到和你相似的人,假设你们的爱好相同,看看他们喜欢什么。和你相似的人,意味着他们对你看过的电影有着相似的评价。在大数据集中,这个方法和元数据方法相比,效果更好。另外一点很重要的是,询问用户他们的行为和观察他们实际的行为之间是有出入的,这其中更深沉次的原因需要心理学家来解释。
-In order to solve this problem we can create a huge matrix of the ratings of all users against all movies. However, in many cases this will create an extremely sparse matrix. Just think of your Netflix account. What percentage of their total supply of series and movies have you watched? It’s probably a pretty small percentage. Then, through gradient descent we can train a neural network to predict how high each user would rate each movie. Let me know if you would like to know more about the use of deep learning in recommender systems and we can explore it further together. In conclusion, embedding layers are amazing and should not be overlooked.
+为了解决这个问题,我们可以创建一个巨大的所有用户对所有电影的评价矩阵。然而,在很多情况下,这个矩阵是非常稀疏的。想想你的 Netflix 账号,你看过的电影占他们全部电影的百分之多少?这可能是一个非常小的比例。创建矩阵之后,我们可以通过梯度下降算法训练我们的神经网络,来预测每个用户会给每部电影打多少分。如果你想知道更多关于在推荐系统中使用深度学习的话,请告诉我,我们可以一起来探讨更细节的问题。总而言之,嵌入层的作用是令人惊讶的,不可小觑。
-If you liked this posts be sure to recommend it so others can see it. You can also follow this profile to keep up with my process in the Fast AI course. See you there!
+如果你喜欢这篇文章,请把它推荐给你的朋友们,让更多人的看到它。你也可以按照这篇文章,跟上我在 Fast AI 课程中的进度。到时候那里见!
-#### References
+#### 参考文献
Piech, C., Bassen, J., Huang, J., Ganguli, S., Sahami, M., Guibas, L. J., & Sohl-Dickstein, J. (2015). *Deep knowledge tracing. In Advances in Neural Information Processing Systems* (pp. 505–513).
Tamhane, A., Arora, S., & Warrier, D. (2017, May). *Modeling Contextual Changes in User Behaviour in Fashion e-Commerce*. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 539–550). Springer, Cham.
-
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
diff --git a/TODO/embracing-java-8-language-features.md b/TODO/embracing-java-8-language-features.md
index a52b61a12e1..d53cf2e3083 100644
--- a/TODO/embracing-java-8-language-features.md
+++ b/TODO/embracing-java-8-language-features.md
@@ -3,20 +3,20 @@
> * 原文作者:[Jeroen Mols](https://jeroenmols.com/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/embracing-java-8-language-features.md](https://github.com/xitu/gold-miner/blob/master/TODO/embracing-java-8-language-features.md)
-> * 译者:
-> * 校对者:
+> * 译者:[tanglie1993](https://github.com/tanglie1993)
+> * 校对者:[lileizhenshuai](https://github.com/lileizhenshuai), [DeadLion](https://github.com/DeadLion)
-# Embracing Java 8 language features
+# 拥抱 Java 8 语言特性
-For years Android developers have been limited to Java 6 features. While RetroLambda or the experimental Jack toolchain would help, proper support from Google was notably missing.
+近年来,Android 开发者一直被限制在 Java 6 的特性中。虽然 RetroLambda 或者实验性的 Jack toolchain 会有一定帮助,来自 Google 官方的适当支持却一直缺失。
-Finally, Android Studio 3.0 brings (backported!) support for most Java 8 features. Continue reading to learn how those work and why you should upgrade.
+终于, Android Studio 3.0 带来了(已经向后移植!)对大多数 Java 8 特性的支持。继续阅读,你将看到其中的原理,以及升级的理由。
-## Enabling java 8 features
+## 引入 Java 8 特性
-While Android Studio already supported many features in the [Jack toolchain](https://developer.android.com/guide/platform/j8-jack.html), starting from Android Studio 3.0 they are supported in the default toolchain.
+虽然 Android Studio 已经支持 [Jack toolchain](https://developer.android.com/guide/platform/j8-jack.html) 中的大量特性,从 Android Studio 3.0 开始,它们会在默认的工具链中被支持。
-First of all, make sure you disable Jack by removing the following from your main `build.gradle`:
+首先,确保你已经把以下内容从你的主要 `build.gradle` 中移除,从而关闭了 Jack:
```
android {
@@ -31,7 +31,7 @@ android {
}
```
-And add the following configuration instead:
+然后加入以下的配置:
```
android {
@@ -43,7 +43,7 @@ android {
}
```
-Also make sure you have the latest Gradle plugin in your root `build.gradle` file:
+并且确保你在根 `build.gradle` 文件中有最新的 Gradle 插件:
```
buildscript {
@@ -54,13 +54,13 @@ buildscript {
}
```
-Congratulations, you can now use most Java 8 features on all API levels!
+恭喜,你现在可以在所有的 API 层级上使用大多数的 Java 8 特性了!
-> Note: In case you’re migrating from [RetroLambda](https://github.com/evant/gradle-retrolambda), the official documentation has a more extensive [migration guide](https://developer.android.com/studio/write/java8-support.html#migrate).
+> 注意:如果你要从 [RetroLambda](https://github.com/evant/gradle-retrolambda) 迁移过来,官方文档有一个更加全面的 [迁移指南](https://developer.android.com/studio/write/java8-support.html#migrate)。
-## Lambda’s
+## 有关 Lambda 表达式
-Passing a listener to another class in Java 6 is quite verbose. A typical case would be where you add an `OnClickListener` to a `View`:
+在 Java 6 中,向另一个类传入监听器的代码是相当冗长的。典型的情况是,你需要向 `View` 添加一个 `OnClickListener`:
```
button.setOnClickListener(new View.OnClickListener() {
@@ -71,83 +71,85 @@ button.setOnClickListener(new View.OnClickListener() {
});
```
-Lambda’s can dramatically simplify this to the following:
+Lambda 表达式可以把它显著地简化成下面这样:
```
button.setOnClickListener(view -> doSomething());
```
-Notice that almost all boilerplate is removed: no access modifier, no return type and no method name!
+注意:几乎全部模板代码都被删除了:没有访问控制修饰符,没有返回值,也没有方法名称!
-Now how do lambda’s actually work?
+Lambda 表达式究竟是怎么工作的呢?
-They are syntactic sugar that reduce the need for anonymous class creation whenever you have an interface with exactly one method. We call such interfaces functional interfaces and `OnClickListener` is an example:
+它们是语法糖,当你有一个只有一个方法的接口时,它们可以减少创建匿名类的需要。我们把这些接口称为功能接口,`OnClickListener` 就是一个例子:
```
-// A functional interface has exactly one method
+// 只有一个方法的功能接口
public interface OnClickListener {
void onClick(View view);
}
```
-Basically the lambda consists out of a three parts:
+基本上 lambda 表达式包括三个部分:
```
button.setOnClickListener((view) -> {doSomething()});
```
-1. declaration of all method arguments between brackets `()`
-2. an arrow `->`
-3. code that needs to execute between brackets `{}`
+1. 括号 `()` 中所有方法参数的声明
+2. 一个箭头 `->`
+3. 括号 `{}` 中需要执行的代码
-Note that in many cases even the brackets `()` and `{}` can be removed. For more details have a look at the [official documentation](https://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html).
+注意:在很多情况下,甚至 `()` 和 `{}` 这样的括号也可以被移除。更多细节,参见 [官方文档](https://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html)。
-## Method references
+## 方法引用
-Recall that lambda expressions remove a lot of boilerplate code for functional interfaces. Method references take that concept one step further when the lambda calls a method that already has a name.
+回忆一下 lambda 表达式为功能接口删除了大量样板代码的情形。当 lambda 表达式调用了一个已经有名字的方法时,方法引用把这个概念更推进了一步。
-In the following example:
+在下面的例子中:
```
button.setOnClickListener(view -> doSomething(view));
```
-All the lambda does is redirecting the work to an existing `doSomething()` method. In such a case, a method reference simplifies things further to:
+Lambda 只是把要做的所有事情重定向到已有的 `doSomething()` 方法。在这种情况下,方法引用把事情简化到:
```
button.setOnClickListener(this::doSomething);
```
-Note that the referenced method must take exactly the same parameters as the functional interface:
+注意,被引用的方法必须和功能接口接收相同的参数:
```
-// functional interface
+// 功能接口
public interface OnClickListener {
void onClick(View view);
}
-// referenced method: must take View as argument, because onClick() does
+// 被引用的方法:必须接收 View 作为参数,因为 onClick() 会这样做:
private void doSomething(View view) {
// do something here
}
```
-So how do method references work?
+那么,方法引用是如何工作的呢?
-They are again syntactic sugar to simplify a lambda expression that invokes an existing method. They can reference to:
+它们同样是语法糖,可以简化调用了现有方法的 lambda 表达式。他们可以引用:
-| static methods | MyClass::doSomething |
-| instance method of object | myObject::doSomething |
-| constructor | MyClass:: new |
-| instance method of any argument type | String::compare |
+| | |
+| - | - |
+| 静态方法 | MyClass::doSomething |
+| 对象的实例方法 | myObject::doSomething |
+| 构造方法 | MyClass:: new |
+| 任何参数类型的实例方法 | String::compare |
-For more examples about this have a look at the [official documentation](https://docs.oracle.com/javase/tutorial/java/javaOO/methodreferences.html).
+如果你需要更多关于这个的实例,请查看 [官方文档](https://docs.oracle.com/javase/tutorial/java/javaOO/methodreferences.html)。
-## Default interface Methods
+## 默认接口方法
-Default methods make it possible to add new methods to an interface without breaking all classes that implement that interface.
+默认方法使你可以在不破坏实现一个接口的所有的类的情况下,向该接口中加入新的方法。
-Imagine if you have a `MyView` interface that is implemented by a `MyFragment` (typical MVP scenario):
+假设你有一个 `MyView` 接口,它被一个 `MyFragment` 实现(典型 MVP 场景):
```
public interface MyView {
@@ -163,9 +165,9 @@ public class MyFragment implements MyView {
}
```
-When you now want to add an extra method to `MyView` your code will no longer compile, until `MyFragment` also implements that new method. This is annoying, and can be even problematic when many classes are implementing said interface.
+如果你现在想要向 MyView 中加入一个额外的方法,你的代码将不再能够编译,直到 `MyFragment` 同样实现了这个新方法。这很烦人,并且如果很多类都实现这个接口的话,可能会引发新的问题。
-Therefore Java 8 now allows you to define default methods that provide a standard implementation:
+因此 Java 8 允许你定义带有标准实现的默认方法:
```
public interface MyView {
@@ -176,37 +178,37 @@ public interface MyView {
}
```
-So how do default methods work?
+那么默认方法是如何工作的呢?
-Just define a method with the `default` keyword in the interface and provide an actual default method body.
+在接口中定义一个带有 `default` 关键字的方法,并提供一个真实的默认方法体。
-To learn more about this feature, have a look at the [official documentation](https://docs.oracle.com/javase/tutorial/java/IandI/defaultmethods.html).
+要学习关于这个特性的更多知识,请查看 [官方文档](https://docs.oracle.com/javase/tutorial/java/IandI/defaultmethods.html)。
-## How to get started
+## 如何开始
-While this all might seem a bit overwhelming, Android Studio actually offers amazing quick fixes once you enable Java 8 features.
+虽然这看起来有些吓人,但是一旦你打开了 Java 8 特性,Android Studio 就提供了非常好用的快速修复功能。
-Just use `alt/option` + `enter` to convert a functional interface to a lamba or a lambda to a method reference.
+只要使用 `alt/option` + `enter` 就可以把功能接口转化为一个 lambda 表达式,或把 lambda 转为方法引用。
-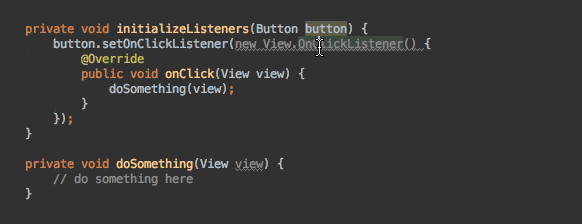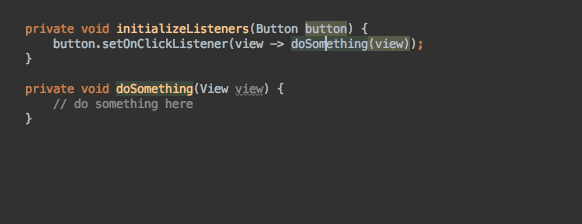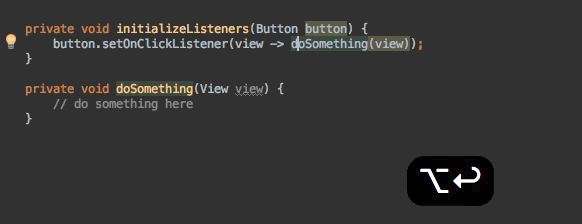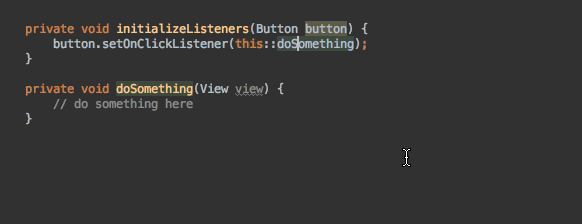
+
-This is a great way to get familiar with these new features and allows you to write code like you’re used to. After enough quick fixes by Android Studio you’ll learn in what cases a lambda or method reference would be possible and start writing them yourself.
+这是一种熟悉新特性的好办法,它使你可以按照自己习惯的方式写代码。在使用 Android Studio 的快速修复功能足够多次之后,你将学会 lambda 表达式和方法引用有哪些使用场景,并开始自己写它们。
-## Supported features
+## 支持的特性
-While not all Java 8 features have been backported yet, Android Studio 3.0 offers plenty more features:
+虽然并不是所有的 Java 8 特性都已经被向后移植,但是Android Studio 3.0 提供了很多其他的特性:
-- [static interface methods](https://docs.oracle.com/javase/tutorial/java/IandI/defaultmethods.html)
-- [type annotations](https://docs.oracle.com/javase/tutorial/java/annotations/type_annotations.html)
-- [repeating annotations](https://docs.oracle.com/javase/tutorial/java/annotations/repeating.html)
-- [try with resources](https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html) (all versions, no longer min SDK 19)
+- [静态接口方法](https://docs.oracle.com/javase/tutorial/java/IandI/defaultmethods.html)
+- [类型注解](https://docs.oracle.com/javase/tutorial/java/annotations/type_annotations.html)
+- [重复标记](https://docs.oracle.com/javase/tutorial/java/annotations/repeating.html)
+- [针对资源的 try 语句](https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html) (所有版本,最低版本不再是 SDK 19)
- Java 8 APIs (e.g. stream) -> min SDK 24
-## Wrap-up
+## 收尾
-Thanks to Java 8 features, a lot of code can be simplified into lambda’s or method references. Android Studio auto convert is the easiest way to start learning these features.
+Java 8 特性使得很多代码可以被简化为 lambda 表达式或方法引用。 Android Studio 自动转化是最简单的开始学习这些特性的方式。
-If you’ve made it this far, you should probably follow me on [Twitter](https://twitter.com/molsjeroen). Feel free leave a comment below!
+如果你已经读到这里了,你很可能应该在 [Twitter](https://twitter.com/molsjeroen) 上关注我。欢迎评论!
---
diff --git a/TODO/how-chat-bots-work.md b/TODO/how-chat-bots-work.md
index f3d356f67e0..5fafe6aaf88 100644
--- a/TODO/how-chat-bots-work.md
+++ b/TODO/how-chat-bots-work.md
@@ -1,60 +1,61 @@
- > * 原文地址:[Soul of the Machine: How Chatbots Work](https://medium.com/@gk_/how-chat-bots-work-dfff656a35e2)
- > * 原文作者:[George Kassabgi](https://medium.com/@gk_)
- > * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
- > * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/how-chat-bots-work.md](https://github.com/xitu/gold-miner/blob/master/TODO/how-chat-bots-work.md)
- > * 译者:
- > * 校对者:
+> * 原文地址:[Soul of the Machine: How Chatbots Work](https://medium.com/@gk_/how-chat-bots-work-dfff656a35e2)
+> * 原文作者:[George Kassabgi](https://medium.com/@gk_)
+> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
+> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/how-chat-bots-work.md](https://github.com/xitu/gold-miner/blob/master/TODO/how-chat-bots-work.md)
+> * 译者:[lsvih](https://github.com/lsvih)
+> * 校对者:[lileizhenshuai](https://github.com/lileizhenshuai),[jasonxia23](https://github.com/jasonxia23)
- # Soul of the Machine: How Chatbots Work
+# 机器之魂:聊天机器人是怎么工作的

-Since the early industrial age, we’ve been fascinated by self-operating devices. They represent the humanization of technology.
+自早期的工业时代以来,人类就被能自主操作的设备迷住了。因为,它们代表了科技的“人化”。
-Today, it is software that that’s becoming more human — most obviously “chatbots.”
+而在今天,各种软件也在逐渐变得人性化。其中变化最明显的当属“聊天机器人”。
-But how do these machines work? First, wind back time and explore an earlier — yet similar — technology.
+但是这些“机械”是如何运作的呢?首先,让我们回溯过去,探寻一种原始,但相似的技术。
-### How a music box works
+### 音乐盒是如何工作的

-An early example of automation — the mechanical music box.
-A set of tuned metallic teeth aligned on a comb-like structure are positioned next to a cylinder with pins. Each pin corresponds to a note at a specific interval.
+早期自动化的样例 —— 机械音乐盒。
+一组经过调音的金属齿排列成梳状结构,置于一个有针的圆柱边上。每根针都以一个特定的时间对应着一个音符。
-As the mechanism turns, it creates a tune by striking one or multiple pins at the predefined time. To play a different song, you can swap in a different cylindrical drum (assuming the set of unique notes is equivalent).
+当机械转动时,它便会在预定好的时间通过单个或者多个针的拨动来产生乐曲。如果要播放不同的歌,你得换不同的圆柱桶(假设不同的乐曲对应的特定音符是一样的)。
-In addition to striking a note, the movement of the drum can cause other automation, such as a moving figurine. Either way, the fundamental machinery of the music box remains the same.
+除了发出音符之外,圆筒的转动还可以附加一些其它的动作,例如移动小雕像等。不管怎样,这个音乐盒的基本机械结构是不会变的。
-### How a chatbot works
+### 聊天机器人是如何工作的
-Text input is processed by a software function called a “classifier”, this classification associates an input sentence with an “intent” (a conversational intent) which produces a response.
+输入的文本将经过一种名为“分类器”的函数处理,这种分类器会将一个输入的句子和一种“意图”(聊天的目的)联系起来,然后针对这种“意图”产生回应。

-[a chatbot example (http://lauragelston.ghost.io/speakeasy/](http://lauragelston.ghost.io/speakeasy/))
-Think of a classifier as a way of categorizing a piece of data (a sentence) into one of several categories (an intent). The input “how are you?” is classified as an intent, which is associated with a response such as “I’m good” or (better) “I am well.”
+[一个聊天机器人的例子](http://lauragelston.ghost.io/speakeasy/)
-We learned about classification early in elementary science: a chimpanzee is in the class “mammals”, a blue jay is in the class “birds”, the earth is in the class “planets” and so on. Simple.
+你可以将分类器看成是将一段数据(一句话)分入几个分类中的一种(即某种意图)的一种方式。输入一句话“how are you?”,将被分类成一种意图,然后将其与一种回应(例如“I’m good”或者更好的“I am well”)联系起来。
-Generally speaking, there are 3 different kinds of text classifiers. Think of these as software machinery, built for a specific purpose, like the drum of a music box.
+我们在基础科学中早学习了分类:黑猩猩属于“哺乳动物”类,蓝鸟属于“鸟”类,地球属于“行星”等等。
-### **Chatbot text classification approaches**
+一般来说,文本分类有 3 种不同的方法。可以将它们看做是为了一些特定目的制造的软件机械,就如同音乐盒的圆筒一样。
-- **Pattern matchers**
-- **Algorithms**
-- **Neural networks**
+### **聊天机器人的文本分类方法**
-Regardless of which type of classifier is used, the end-result is a response. Like a music box, there can be additional “movements” associated with the machinery. A response can make use of external information (like weather, a sports score, a web lookup, etc.) but this isn’t specific to chatbots, it’s just additional code. A response may reference specific “parts of speech” in the sentence, for example: a proper noun. Also the response (for an intent) can use conditional logic to provide different responses depending on the “state” of the conversation, this can be a random selection (to insert some ‘natural’ feeling).
+- **模式匹配**
+- **算法**
+- **神经网络**
-### Pattern matchers
+无论你使用哪种分类器,最终的结果一定是给出一个回应。音乐盒可以利用一些机械机构的联系来完成一些额外的“动作”,聊天机器人也如此。回应中可以使用一些额外的信息(例如天气、体育比赛比分、网络搜索等等),但是这些信息并不是聊天机器人的组成部分,它们仅仅是一些额外的代码。也可以根据句子中的某些特定“词性”来产生回应(例如某个专有名词)。此外,符合意图的回应也可以使用逻辑条件来判断对话的“状态”,以提供一些不同的回应,这也可以通过随机选择实现(好让对话更加“自然”)。
-Early chatbots used pattern matching to classify text and produce a response. This is often referred to as “brute force” as the author of the system needs to describe every pattern for which there is a response.
+### 模式匹配
-A standard structure for these patterns is “AIML” (artificial intelligence markup language). Its use of the term “artificial intelligence” is quite an embellishment, but [that’s another story](https://medium.com/@gk_/the-ai-label-is-bullshit-559b171867ff).
+早期的聊天机器人通过模式匹配来进行文本分类以及产生回应。这种方法常常被称为“暴力法”,因为系统的作者需要为某个回应详细描述所有模式。
-A simple pattern matching definition:
+这些模式的标准结构是“AIML”(人工智能标记语言)。这个名词里用了“人工智能”作为修饰词,但是[它们完全不是一码事](https://medium.com/@gk_/the-ai-label-is-bullshit-559b171867ff)。
+
+下面是一个简单的模式匹配定义:
```
@@ -77,90 +78,92 @@ A simple pattern matching definition:
```
-The machine then produces:
+然后机器经过处理会回答:
- Human: Do you know who Albert Einstein is
- Robot: Albert Einstein was a German physicist.
+ Human: Do you know who Albert Einstein is
+ Robot: Albert Einstein was a German physicist.
-It knows who a physicist is only because his or her name has an associated pattern. Likewise it responds to anything solely because of an authored pattern. Given hundreds or thousands of patterns you might see a chatbot “persona” emerge.
+它之所以知道别人问的是哪个物理学家,只是靠着与他或者她名字相关联的模式匹配。同样的,它靠着创作者预设的模式可以对任何意图进行回应。在给予它成千上万种模式之后,你终将能看到一个“类人”的聊天机器人出现。
-In 2000 a chatbot built using this approach was [in the news](http://mashable.com/2014/06/12/eugene-goostman-turing-test/) for passing the “Turing test”, built by John Denning and colleagues. It was built to emulate the replies of a 13 year old boy from Ukraine (broken English and all). I met with John in 2015 and he made no false pretenses about the internal workings of this automaton. It may have been “brute force” but it proved a point: parts of a conversation can be made to appear “natural” using a sufficiently large definition of patterns. It proved Alan Turing’s assertion, that this question of a machine fooling humans was “meaningless”.
+2000 年的时候,John Denning 和他的同事就以这种方法做了个聊天机器人([相关新闻](http://mashable.com/2014/06/12/eugene-goostman-turing-test/)),并通过了“图灵测试”。它设计的目标是模仿来自乌克兰的一个 13 岁的男孩,这孩子的英语水平很蹩脚。我在 2015 年的时候和 John 见过面,他没有矢口否认这个自动机的内部原理。因此,这个聊天机器人很可能就是用“暴力”的方法进行模式匹配。但它也证明了一点:在足够大的模式匹配定义的支持下,可以让大部分对话都贴近“自然”的程度。同时也符合了图灵(Alan Turing)的断言:制作用来糊弄人类的机器是“毫无意义”的。
-An example of this approach used in building chatbots is [PandoraBots,](http://www.pandorabots.com/) they claim over 285k chatbots have been constructed using their framework.
+使用这种方法做机器人的典型案例还有 [PandoraBots](http://www.pandorabots.com/),他们宣称已经用他们的框架构建了超过 28.5 万个聊天机器人。
-### Algorithms
+### 算法
-The brute-force mechanism is daunting: for each unique input a pattern must be available to specify a response. This creates a hierarchical structure of patterns, the inspiration for the idiom “rats nest”.
+暴力穷举法做自动机让人望而却步:对于每个输入都得有可用的模式来匹配其回应。人们由“老鼠洞”得到灵感,创建了模式的层级结构。
-To reduce the classifier to a more manageable machine, we can approach the work *algorithmically*, that is to say: we can build an equation for it. This is what computer scientists call a “reductionist” approach: the problem is *reduced* so that the solution is simplified.
+我们可以使用**算法**这种方法来减少分类器以便对机器进行管理,或者也可以说我们为它创建一个方程。这种方法是计算机科学家们称为“简化”的方法:问题需要**缩减**,那么解决问题的方法就是将其简化。
-A classic text classification algorithm is called “Multinomial Naive Bayes”, [taught in courses at Stanford](http://nlp.stanford.edu/IR-book/pdf/13bayes.pdf) and elsewhere. Here is the equation:
+有一种叫做“朴素贝叶斯多项式模型”的经典文本分类算法,你可以在[这儿](http://nlp.stanford.edu/IR-book/pdf/13bayes.pdf)或者别的地方学习它。下面是它的公式:
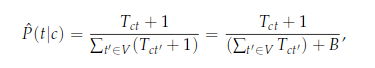
-This is a lot less complicated than it appears. Given a set of sentences, each belonging to a class, and a new input sentence, we can count the occurrence of each word in each class, account for its commonality and assign each class a *score*. Factoring for commonality is important: matching the word “it” is considerably less meaningful than a match for the word “cheese”. The class with the highest score is the one most likely to belong to the input sentence. This is a slight oversimplification as words need to be reduced to their [stems](https://en.wikipedia.org/wiki/Stemming), but you get the basic idea.
-
-A sample training set:
+实际用起它来比看上去要简单的多。给定一组句子,每个句子对应一个分类;接着输入一个新的句子,我们可以通过计算这个句子的单词在各个分类中的词频,找出各个分类的共性,并给每个分类一个**分值**(找出共性这点是很重要的:例如匹配到单词“cheese”(奶酪)比匹配到单词“it”要有意义的多)。最后,得到最高分值的分类很可能就是输入句子的同类。当然以上的说法是经过简化的,例如你还得先找到每个单词的[词干](https://en.wikipedia.org/wiki/Stemming)才行。不过,现在你应该对这种算法已经有了基本的概念。
- class: weather
- "is it nice outside?"
- "how is it outside?"
- "is the weather nice?"
+下面是一个简单的训练集:
- class: greeting
- "how are you?"
- "hello there"
- "how is it going?"
+ class: weather
+ "is it nice outside?"
+ "how is it outside?"
+ "is the weather nice?"
+
+ class: greeting
+ "how are you?"
+ "hello there"
+ "how is it going?"
-Let’s classify a few sample input sentences:
+让我们来对几个简单的输入句子进行分类:
- input: "Hi there"
- term: "hi" (**no matches)**
- term: "there" **(class: greeting)**
- classification: **greeting **(score=1)
+ input: "Hi there"
+ term: "hi" (**no matches)**
+ term: "there" **(class: greeting)**
+ classification: **greeting **(score=1)
+
+ input: "What’s it like outside?"
+ term: "it" **(class: weather (2), greeting)**
+ term: "outside **(class: weather (2) )**
+ classification: **weather **(score=4)
- input: "What’s it like outside?"
- term: "it" **(class: weather (2), greeting)**
- term: "outside **(class: weather (2) )**
- classification: **weather **(score=4)
+请注意,“What’s it like outside”在分类时找到了另一个分类的单词,但是正确的分类给了单词较高的分值。通过算法公式,我们可以为句子计算匹配每个分类对应的词频,因此不需要去标明所有的模式。
-Notice that the classification for “What’s it like outside” found a term in another class but the term similarities to the desired class produced a higher score. By using an equation we are looking for word matches given some sample sentences for each class, and we avoid having to identify every pattern.
+这种分类器通过标定分类分值(计算词频)的方法给出最匹配语句的分类,但是它仍然有局限性。分值与概率不同,它仅仅能告诉我们句子的意图最有可能是哪个分类,而不能告诉我们它的所有匹配分类的可能性。因此,很难去给出一个阈值来判定是接受这个得分结果还是不接受这个结果。这种类型的算法给出的最高分仅仅能作为判断相关性的基础,它本质上作为分类器的效果还是比较差的。此外,这个算法不能接受 *is not* 类型的句子,因为它仅仅计算了 *it* 可能是什么。也就是说这种方法不适合做为包含 *not* 的否定句的分类。
-The classification score produced identifies the class with the highest term matches (accounting for commonality of words) but this has limitations. A score is not the same as a probability, a score tells us which intent is most like the sentence but not the likelihood of it being a match. Thus it is difficult to apply a threshold for which classification scores to accept or not. Having the highest score from this type of algorithm only provides a relative basis, it may still be an inherently weak classification. Also the algorithm doesn’t account for what a sentence *is not*, it only counts what it *is* like. You might say this approach doesn’t consider what makes a sentence *not* a given class.
+有许多的聊天机器人框架[都是用这种方法来判断意图分类](https://medium.com/@gk_/text-classification-using-algorithms-e4d50dcba45#.ewnhttxa4)。而且大多数都是针对训练集进行词频计算,这种“幼稚”的方法有时还意外的有效。
-Many chatbot frameworks use [algorithms such as this to classify intent](https://medium.com/@gk_/text-classification-using-algorithms-e4d50dcba45#.ewnhttxa4). Most of what’s taking place is word counting against training datasets, it’s “naive” but surprisingly effective.
-### Neural Networks
+### 神经网络
-Artificial neural networks, invented in the 1940’s, are a way of calculating an output from an input (a classification) using weighted connections (“synapses”) that are calculated from repeated iterations through training data. Each pass through the training data alters the weights such that the neural network produces the output with greater “accuracy” (lower error rate).
+人工神经网络发明于 20 世纪 40 年代,它通过迭代计算训练数据得到连接的加权值(“突触”),然后用于对输入数据进行分类。通过一次次使用训练数据计算改变加权值以使得神经网络的输出得到更高的“准确率”(低错误率)。
-a neural network structure: nodes (circles) and synapses (lines)
-There’s not much new about these structures, except today’s software is using much faster processors and can work with a lot more memory. The combination of working memory and speed is crucial when you’re doing hundreds of thousands of matrix multiplications (the neural network’s essential math operation).
+上图为一种神经网络结构,其中包括神经元(圆)和突触(线)
+
+其实除了当今的软件可以用更快的处理器、更大的内存外,这些结构并没有出现什么新奇的东西。当做数十万次的矩阵乘法(神经网络中的基本数学运算)的时候,运行内存和计算速度成为了关键问题。
-As in the prior method, each class is given with some number of example sentences. Once again each sentence is broken down by word (stemmed) and each word becomes an input for the neural network. The synaptic weights are then calculated by iterating through the training data thousands of times, each time adjusting the weights slightly to greater accuracy. By recalculating back across multiple layers (“back-propagation”) the weights of all synapses are calibrated while the results are compared to the training data output. These weights are like a ‘strength’ measure, in a neuron the synaptic weight is what causes something to be more memorable than not. You remember a thing more because you’ve seen it more times: each time the ‘weight’ increases slightly.
+在前面的方法里,每个分类都会给定一些例句。接着,根据词干进行分句,将所有单词作为神经网络的输入。然后遍历数据,进行成千上万次迭代计算,每次迭代都通过改变突触权重来得到更高的准确率。接着反过来通过对训练集输出值和神经网络计算结果的对比,对各层重新进行计算权重(反向传播)。这个“权重”可以类比成神经突触想记住某个东西的“力度”,你能记住某个东西是因为你曾多次见过它,在每次见到它的时候这个“权重”都会轻微地上升。
-At some point the adjustment reaches a point of diminishing returns, this is called “over-fitting” and going beyond this is counter-productive.
+有时,在权重调整到某个程度后反而会使得结果逐渐变差,这种情况称为“过拟合”,在出现过拟合的情况下继续进行训练,反而会适得其反。
-The trained neural network is less code than an comparable algorithm but it requires a potentially large matrix of “weights”. In a relatively small sample, where the training sentences have 150 unique words and 30 classes this would be a matrix of 150x30. Imagine multiplying a matrix of this size 100,000 times to establish a sufficiently low error rate. This is where processing speed comes in.
+训练好的神经网络模型的代码量其实很小,不过它需要一个很大的潜在权重矩阵。举个相对较小的样例,它的训练句子包括了 150 个单词、30 种分类,这可能产生一个 150x30 大小的矩阵;你可以想象一下,为了降低错误率,这么大的一个矩阵需要反复的进行 10 万次矩阵乘法。这也是为什么说需要高性能处理器的原因。
-If the neural network sounds magnificently sophisticated, relax, it boils down to [matrix multiplication](https://www.khanacademy.org/math/precalculus/precalc-matrices/multiplying-matrices-by-matrices/v/matrix-multiplication-intro) and a [formula for reducing values](https://en.wikipedia.org/wiki/Sigmoid_function) between -1 and 1 or some other minimal range. A middle-school math student could learn this in a few hours. The hard work is achieving clean training data.
+神经网络之所以能够做到既复杂又稀疏,归结于[矩阵乘法](https://www.khanacademy.org/math/precalculus/precalc-matrices/multiplying-matrices-by-matrices/v/matrix-multiplication-intro)和一种[缩小值至 -1,1 区间的公式](https://en.wikipedia.org/wiki/Sigmoid_function)(即激活函数,这里指的是 Sigmoid),一个中学生也能在几小时内学会它。其实真正困难的工作是清洗训练数据。
-Just as there are variations in pattern matching code and in algorithms, there are variations in neural networks, some more complex than others. The basic machinery is the same. The essential work is that of classification.
+就像前面的模式匹配和算法匹配一样,神经网络也有各种各样的变体,有一些变体会十分复杂。不过它的基本原理是相同的,做的主要工作也都是进行分类。

-The mechanical music box knows nothing about music theory, likewise **chatbot machinery knows nothing about language**.
+机械音乐盒并不了解乐理,同样的,**聊天机器人并不了解语言**。
-Chatbot machinery is looking for patterns in collections of terms, each term is reduced to a token. In this machine* words have no meaning* except for their patterned existence within training data. The label “artificial intelligence” applied to such machinery [is mostly BS](https://medium.com/@gk_/the-ai-label-is-bullshit-559b171867ff#.3tlhftemt).
+聊天机器人实质上就是寻找短语集合中的模式,每个短语还能再分割成单个单词。在聊天机器人内部,除了它们存在的模式以及训练数据之外的**单词其实并没有意义**。为这样的“机器人”贴上“人工智能”的标签其实[也很糟糕](https://medium.com/@gk_/the-ai-label-is-bullshit-559b171867ff#.3tlhftemt)。
-The chatbot is like the mechanical music box: it’s *a machine that produces output according to patterns*. Rather than using pins and cylindrical drums the chatbot uses software code and mathematics.
+总结:聊天机器人就像机械音乐盒一样:它就是**一个根据模式来进行输出的机器**,只不过它不用圆筒和针,而是使用软件代码和数学原理。
---
- > [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
-
\ No newline at end of file
+> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#%E5%89%8D%E7%AB%AF)、[后端](https://github.com/xitu/gold-miner#%E5%90%8E%E7%AB%AF)、[产品](https://github.com/xitu/gold-miner#%E4%BA%A7%E5%93%81)、[设计](https://github.com/xitu/gold-miner#%E8%AE%BE%E8%AE%A1) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
+
diff --git a/TODO/learning-react-js-is-easier-than-you-think.md b/TODO/learning-react-js-is-easier-than-you-think.md
index 8a2731c111b..a31aee8a7c5 100644
--- a/TODO/learning-react-js-is-easier-than-you-think.md
+++ b/TODO/learning-react-js-is-easier-than-you-think.md
@@ -3,61 +3,60 @@
> * 原文作者:[Samer Buna](https://edgecoders.com/@samerbuna)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/learning-react-js-is-easier-than-you-think.md](https://github.com/xitu/gold-miner/blob/master/TODO/learning-react-js-is-easier-than-you-think.md)
-> * 译者:
-> * 校对者:
+> * 译者:[Cherry](https://github.com/sunshine940326)
+> * 校对者:[LeviDing](https://github.com/leviding)、[undead25](https://github.com/undead25)
-# Learning React.js is easier than you think
+# 学习 React.js 比你想象的要简单
-## Learn the fundamentals of React.js in one Medium article
+## 通过 Medium 中的一篇文章来学习 React.js 的基本原理

-Have you ever noticed that there is a Star of David hidden in the React logo? Just saying…
-Last year I wrote a short book on learning React.js which turned out to be about 100 pages. This year, I am going to challenge myself to summarize it as an article on Medium.
+你有没有注意到在 React 的 logo 中隐藏着一个六角星?只是顺便提下...
+去年我写了一本简短的关于学习 React.js 的书,有 100 页左右。今年,我要挑战自己 —— 将其总结成一篇文章,并向 Medium 投稿。
-This article is not going to cover what React is or [why you should learn it](https://medium.freecodecamp.org/yes-react-is-taking-over-front-end-development-the-question-is-why-40837af8ab76). This is just a practical introduction for the fundamentals of React.js for those who are already familiar with JavaScript and know the basics of [the DOM API](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model).
+这篇文章不是讲什么是 React 或者 [你该怎样学习 React](https://medium.freecodecamp.org/yes-react-is-taking-over-front-end-development-the-question-is-why-40837af8ab76)。这是在面向那些已经熟悉了 JavaScript 和 [DOM API](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model) 的人的 React.js 基本原理介绍
-> This article uses embedded jsComplete code snippets which needs a decent screen width to be readable.
+> 本文采用嵌入式 jsComplete 代码段,所以为了方便阅读,你需要一个合适的屏幕宽度。
-All code examples below are labeled for reference. They are also purely intended to provide examples of concepts. Most of them can be written in a much better way.
+下面所有的代码都仅供参考。它们也纯粹是为了表达概念而提供的例子。它们中的大多数有更好的实践方式。
-You can edit and execute any code snippet below. Use *Ctrl+Enter* to execute the code. The bottom-right corner of each snippet has a link to edit/run the code full-screen at [jsComplete/repl](https://jscomplete.com/repl).
+您可以编辑和执行下面的任何代码段。使用 **Ctrl+Enter** 执行代码。每一段的右下角有一个点击后可以在 [jsComplete/repl](https://jscomplete.com/repl) 进行全屏模式编辑或运行代码的链接。
---
-#### 1 — React is all about components
+#### 1 React 全部都是组件化的
-React is designed around the concept of reusable components. You define small components and you put them together to form bigger components.
+React 是围绕可重用组件的概念设计的。你定义小组件并将它们组合在一起形成更大的组件。
-All components small or big are reusable, even across different projects.
+无论大小,所有组件都是可重用的,甚至在不同的项目中也是如此。
-A React component — in its simplest form — is just a plain-old JavaScript function:
+React 组件最简单的形式,就是一个普通的 JavaScript 函数:
-```
+```js
function Button (props) {
- // Returns a DOM element here. For example:
+ // 这里返回一个 DOM 元素,例如:
return ;
}
-
-// To render the Button component to the browser
+// 将按钮组件呈现给浏览器
ReactDOM.render(, mountNode)
```
-Example 1 — Edit code above and press Ctrl+Enter to execute
+例 1:编辑上面的代码并按 Ctrl+Enter 键执行(译者注:译文暂时没有这个功能,请访问原文使用此功能,下同)
-> The curly braces used for the button label are explained below. Don’t worry about them now. `ReactDOM` will also be explained later, but if you want to test this example and all upcoming code examples, the above `render` function is what you need. (The second argument to `ReactDOM.render` is the destination DOM element which React is going to take over and control. In a jsComplete REPL, you can just use the special variable `mountNode`)
+> 括号中的 button 标签将稍后解释。现在不要担心它们。`ReactDOM` 也将稍后解释,但如果你想测试这个例子和所有接下来的例子,上述 `render` 函数是必须的。(React 将要接管和控制的是 `ReactDOM.render` 的第 2 个参数即目标 DOM 元素)。在 jsComplete REPL 中,你可以使用特殊的变量 `mountNode`。
-Note the following about Example 1:
+例 1 的注意事项:
-- The component name is TitleCase-ed, `Button`. This is required since we will be dealing with a mix of HTML elements and React elements. Lowercase names are reserved for HTML elements. In fact, go ahead and try to name the React component just “button” and see how ReactDOM will ignore the function and just renders a regular empty HTML button.
-- Every component receives a list of attributes, just like HTML elements. In React, this list is called *props*. With a function component, you can name it anything though.
-- We weirdly wrote what looks like HTML in the returned output of the `Button` function component above. This is really neither JavaScript nor HTML, and honestly, it’s not even React.js. However, it’s so popular that it became the default in React applications. It’s called [*JSX*](https://facebook.github.io/jsx/) and it’s a JavaScript extension. JSX is also a *compromise*! Go ahead and try and return any other HTML element inside the function above and see how they are all supported (for example, return a text input element).
+- 组件名称首字母大写,`Button`。必须要这样做是因为我们将处理 HTML 元素和 React 元素的混合。小写名称是为 HTML 元素保留的。事实上,将 React 组件命名为 “button” 然后你就会发现 ReactDOM 会忽略这个函数,仅仅是将其作为一个普通的空 HTML 按钮来渲染。
+- 每个组件都接收一个属性列表,就像 HTML 元素一样。在 React 中,这个列表被称为**属性**。虽然你可以将一个函数随意命名。
+- 在上面 Button 函数组件的返回输出中,我们奇怪地写了段看上去像 HTML 的代码。这实际上既不是 JavaScript 也不是 HTML,老实说,这甚至不是 React.js。然而它非常流行,以至于成为 React 应用程序中的默认值。这就是所谓的 [**JSX**](https://facebook.github.io/jsx/),这是一个JavaScript 的扩展。JSX 也是一个**折中方案**!继续尝试并在上面的函数中返回其他 HTML 元素,看看它们是如何被支持的(例如,返回一个文本输入元素)。
-#### 2 — What the flux is JSX?
+#### 2 JSX 输出的是什么?
-Example 1 above can be written in pure React.js without JSX as follows:
+上面的例 1 可以用没有 JSX 的纯 React.js 编写,如下:
-```
+```js
function Button (props) {
return React.createElement(
"button",
@@ -66,24 +65,24 @@ function Button (props) {
);
}
-// To use Button, you would do something like
+// 要使用 Button,你可以这么做
ReactDOM.render(
React.createElement(Button, { label: "Save" }),
mountNode
);
```
-Example 2 — React component without JSX
+例 2:不使用 JSX 编写 React 组件
-The `createElement` function is the main function in the React top-level API. It’s 1 of a total of 7 things in that level that you need to learn. That’s how small the React API is.
+在 React 顶级 API 中,`createElement` 函数是主函数。这是你需要学习的 7 个 API 中的 1 个。React 的 API 就是这么小。
-Much like the DOM itself having a `document.createElement` function to create an element specified by a tag name, React’s `createElement` function is a higher-level function that can do what `document.createElement` does, but it can also be used to create an element to represent a React component. We did the latter when we used the `Button` component in Example 2 above.
+就像 DOM 自身有一个 document.createElement 函数来创建一个由标签名指定的元素一样,React 的 `createElement` 函数是一个高级函数,有和 `document.createElement` 同样的功能,但它也可以用于创建一个表示 React 组件的元素。当我们使用上面例 2 中的按钮组件时,我们使用的是后者。
-Unlike `document.createElement`, React’s `createElement` accepts a dynamic number of arguments after the second one to represent the *children* of the created element. So `createElement` actually creates a *tree.*
+不像 `document.createElement`,React 的 `createElement` 在接收第二个参数后,接收一个动态参数,它表示所创建元素的子元素。所以 `createElement` 实际上创建了一个**树**。
-Here’s an example of that:
+这里就是这样的一个例子:
-```
+```js
const InputForm = React.createElement(
"form",
{ target: "_blank", action: "https://google.com/search" },
@@ -92,7 +91,7 @@ const InputForm = React.createElement(
React.createElement(Button, { label: "Search" })
);
-// InputForm uses the Button component, so we need that too:
+// InputForm 使用 Button 组件,所以我们需要这样做:
function Button (props) {
return React.createElement(
"button",
@@ -101,24 +100,23 @@ function Button (props) {
);
}
-// Then we can use InputForm directly with .render
+// 然后我们可以通过 .render 方法直接使用 InputForm
ReactDOM.render(InputForm, mountNode);
```
+例 3:React 创建元素的 API
-Example 3 — React’s createElement API
-
-Note a few things about the example above:
+上面例子中的一些事情值得注意:
-- `InputForm` is not a React component; it’s just a React *element*. This is why we used it directly in the `ReactDOM.render` call and not with ``.
-- The `React.createElement` function accepted multiple arguments after the first two. Its list of arguments starting from the 3rd one comprises the list of children for the created element.
-- We were able to nest `React.createElement` calls because it’s all JavaScript.
-- The second argument to `React.createElement` can be null or an empty object when no attributes/props are needed for the element.
-- We can mix HTML element with React components. You can think of HTML elements as built-in React components.
-- React’s API tries to be as close to the DOM API as possible, that’s why we use `className` instead of `class` for the input element. Secretly, we all wish if the React’s API becomes part of the DOM API itself, because, you know, it’s much much better.
+- `InputForm` 不是一个 React 组件;它仅仅是一个 React **元素**。这就是为什么我们可以在 `ReactDOM.render` 中直接使用它并且可以在调用时不使用 `` 的原因。
+- React.createElement 函数在前两个参数后接收了多个参数。从第3个参数开始的参数列表构成了创建元素的子项列表。
+- 我们可以嵌套 `React.createElement` 调用,因为它是 JavaScript。
+- 当这个元素不需要属性时,React.createElement 的第二个参数可以为空或者是一个空对象。
+- 我们可以在 React 组件中混合 HTML 元素。你可以将 HTML 元素作为内置的 React 组件。
+- React 的 API 试图和 DOM API 一样,这就是为什么我们在 input 元素中使用 `className` 代替 `class` 的原因。我们都希望如果 React 的 API 成为 DOM API 本身的一部分,因为,你知道,它要好得多。
-The code above is what the browser understands when you include the React library. The browser does not deal with any JSX business. However, we humans like to see and work with HTML instead of these `createElement` calls (imagine building a website with just `document.createElement`, which you can!). This is why the JSX compromise exists. Instead of writing the form above with `React.createElement` calls, we can write it with a syntax very similar to HTML:
+上述的代码是当你引入 React 库的时候浏览器是怎样理解的。浏览器不会处理任何 JSX 业务。然而,我们更喜欢看到和使用 HTML,而不是那些 `createElement` 调用(想象一下只使用 `document.createElement` 构建一个网站!)。这就是 JSX 存在的原因。取代上述调用 `React.createElement` 的方式,我们可以使用一个非常简单类似于 HTML 的语法:
-```
+```js
const InputForm =
;
-// InputForm "still" uses the Button component, so we need that too.
-// Either JSX or normal form would do
+// InputForm “仍然”使用 Button 组件,所以我们也需要这样。
+// JXS 或者普通的表单都会这样做
function Button (props) {
- // Returns a DOM element here. For example:
+ // 这里返回一个 DOM 元素。例如:
return ;
}
-// Then we can use InputForm directly with .render
+// 然后我们可以直接通过 .render 使用 InputForm
ReactDOM.render(InputForm, mountNode);
```
-Example 4 — Why JSX is popular with React (compare with Example 3)
+例 4:为什么在 React 中 JSX 受欢迎(和例 3 相比)
-Note a few things about the above:
+注意上面的几件事:
-- It’s not HTML. For example, we’re still doing `className` instead of `class`.
-- We’re still considering what looks like HTML above as JavaScript. See how I added a semi-column at the end.
+- 这不是 HTML 代码。比如,我们仍然可以使用 `className` 代替 `class`。
+- 我们仍在考虑怎样让上述的 JavaScript 看起来像是 HTML。看一下我在最后是怎样添加的。
-What we wrote above (Example 4) is JSX. However, what we took to the browser is the compiled version of it (Example 3). To make that happen, we need to use a pre-processor to convert the JSX version into the `React.createElement` version.
+我们在上面(例 4)中写的就是 JSX。然而,我们要将编译后的版本(例 3)给浏览器。要做到这一点,我们需要使用一个预处理器将 JSX 版本转换为 `React.createElement` 版本。
-That is JSX. It’s a compromise that allows us to write our React components in a syntax similar to HTML, which is a pretty good deal.
+这就是 JSX。这是一种折中的方案,允许我们用类似 HTML 的语法来编写我们的 React 组件,这是一个很好的方法。
-> The word “Flux” in the header above was chosen to rhyme, but it’s also the name of a very popular [application architecture](https://facebook.github.io/flux/) popularized by Facebook. The most famous implementation of which is Redux. Flux fits the React reactive pattern perfectly.
+> “Flux” 在头部作为韵脚来使用,但它也是一个非常受欢迎的 [应用架构](https://facebook.github.io/flux/),由 Facebook 推广。最出名的是 Redux,Flux 和 React 非常合适。
-JSX, by the way, can be used on its own; it’s not a React-only thing.
+JSX,可以单独使用,不仅仅适用于 React。
-#### 3 — You can use JavaScript expressions anywhere in JSX
+#### 3 你可以在 JavaScript 的任何地方使用 JSX
-Inside a JSX section, you can use any JavaScript expression within a pair of curly braces.
+在 JSX 中,你可以在一对花括号内使用任何 JavaScript 表达式。
-```
+```js
const RandomValue = () =>
{ Math.floor(Math.random() * 100) }
;
-// To use it:
+// 使用:
ReactDOM.render(, mountNode);
```
-Example 5 — Using JavaScript expressions in JSX
+例 5:在 JSX 中使用 JavaScript 表达式
-Any JavaScript expression can go inside those curly braces. This is equivalent to the `${}` interpolation syntax in JavaScript [template literals](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals).
+任何 JavaScript 表达式可以直接放在花括号中。这相当于在 JavaScript 中插入 `${}` [模板](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals)。
-This is the only constraint inside JSX: only expressions. So, for example, you can’t use a regular `if` statement, but a ternary expression is ok.
+这是 JSX 内唯一的约束:只有表达式。例如,你不能使用 `if` 语句,但三元表达式是可以的。
-JavaScript variables are also expressions, so when the component receives a list of props (the `RandomValue` component didn’t, `props` are optional), you can use these props inside curly braces. We did this in the `Button` component above (Example 1).
+JavaScript 变量也是表达式,所以当组件接受属性列表时(不包括 `RandomValue` 组件,`props` 是可选择的),你可以在花括号里使用这些属性。我们在上述(例 1)的 `Button` 组件是这样使用的。
-JavaScript objects are also expressions. Sometimes we use a JavaScript object inside a curly braces, which makes it look like double curly braces, but it’s really just an object inside curly braces. One use case of that is to pass a CSS style object to the special style attribute in React:
+JavaScript 对象也是表达式。有些时候我们在花括号中使用 JavaScript 对象,这看起来像是使用了两个花括号,但是在花括号中确实只有一个对象。其中一个用例就是将 CSS 样式对象传递给响应中的特殊样式属性:
-```
+```js
const ErrorDisplay = ({message}) =>
{message}
;
-// Use it:
+// 使用
ReactDOM.render(
{errorMessage && }
;
-// The MaybeError component uses the ErrorDisplay component:
+// MaybeError 组件使用 ErrorDisplay 组件
const ErrorDisplay = ({message}) =>
{message}
;
-
-// Now we can use the MaybeError component:
+// 现在我们使用 MaybeError 组件:
ReactDOM.render(
0.5 ? 'Not good' : ''}
@@ -219,50 +215,51 @@ ReactDOM.render(
);
```
-Example 7 — A React element is an expression that can be used within {}
+例 7:一个 React 元素是一个可以通过 {} 使用的表达式
-The `MaybeError` component above would only display the `ErrorDisplay` component if there is an `errorMessage` string passed to it and an empty `div` otherwise. React considers `{true}`, `{false}`, `{undefined}`, and `{null}` to be valid element children, which do not render anything.
+上述 `MaybeError` 组件只会在有 `errorMessage` 传入或者另外有一个空的 `div` 才会显示 `ErrorDisplay` 组件。React 认为 `{true}`、 `{false}`
+`{undefined}` 和 `{null}` 是有效元素,不呈现任何内容。
-You can also use all of JavaScript functional methods on collections (`map`, `reduce`, `filter`, `concat`, …etc) inside JSX. Again, because they return expressions:
+我们也可以在 JSX 中使用所有的 JavaScript 的集合方法(`map`、`reduce` 、`filter`、 `concat` 等)。因为他们返回的也是表达式:
-```
+```js
const Doubler = ({value=[1, 2, 3]}) =>
{value.map(e => e * 2)}
;
-// Use it
+// 使用下面内容
ReactDOM.render(, mountNode);
```
-Example 8 — Using an array map inside {}
+例 8:在 {} 中使用数组
-Note how I gave the `value` prop a default value above, because it’s all just Javascript. Note also that I just outputted an array expression inside the div. React is ok with that. It’ll just place every doubled value in a text node.
+请注意我是如何给出上述 `value` 属性的默认值的,因为这全部都只是 JavaScript。注意我只是在 div 中输出一个数组表达式。React 是完全可以的。它只会在文本节点中放置每一个加倍的值。
-#### 4 — You can write React components with JavaScript classes
+#### 4 你可以使用 JavaScript 类写 React 组件
-Simple function components are great for simple needs, but sometimes we need more. React supports creating components through the [JavaScript class syntax](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes) as well. Here’s the `Button` component (in Example 1) written with the class syntax:
+简单的函数组件非常适合简单的需求,但是有的时候我们需要的更多。React 也支持通过使用 [JavaScript 类](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes)来创建组件。这里 `Button` 组件(在例 1 中)就是使用类的语法编写的。
-```
+```js
class Button extends React.Component {
render() {
return ;
}
}
-// Use it (same syntax)
+// 使用(相同的语法)
ReactDOM.render(, mountNode);
```
-Example 9 — Creating components using JavaScript classes
+例 9:使用 JavaScript 类创建组件
-The class syntax is simple: define a class that extends `React.Component` (another top-level React API thing that you need to learn). The class defines a single instance function, `render()`, and that render function returns the virtual DOM object. Every time we use the `Button` class-based component above (for example, by doing ``), React will instantiate an object from this class-based component and use that object in the DOM tree.
+类的语法是非常简单的:定义一个扩展的 `React.Component` 类(另一个你需要学习的 React 的顶级 API)。该类定义了一个单一的实例函数 —— `render()`,并使函数返回虚拟 DOM 对象。每一次我们使用基于类的 `Button` 组件(例如,通过 ``),React 将从这个基于类的组件中实例化对象,并在 DOM 树中使用该对象。
-This is the reason why we used `this.props.label` inside the JSX in the rendered output above, because every component gets a special *instance* property called `props` that holds all values passed to that component when it was instantiated.
+这就是为什么上面的例子中我们可以在 JSX 中使用 `this.props.label` 渲染输出的原因,因为每一个组件都有一个特殊的称为 `props` 的 **实例** 属性,这让所有的值传递给该组件时被实例化。
-Since we have an instance associated with a single use of the component, we can customize that instance as we wish. We can, for example, customize it after it gets constructed by using the regular JavaScript `constructor` function:
+由于我们有一个与组件的单个使用相关联的实例,所以我们可以按照自己的意愿定制该实例。例如,我们可以通过使用常规 JavaScript 构造函数来构造它:
-```
+```js
class Button extends React.Component {
constructor(props) {
super(props);
@@ -273,15 +270,15 @@ class Button extends React.Component {
}
}
-// Use it
+// 使用
ReactDOM.render(, mountNode);
```
-Example 10 — Customizing a component instance
+例 10:自定义组件实例
-We can also define class prototype functions and use them anywhere we wish, including inside the returned JSX output:
+我们也可以定义类的原型并且在任何我们希望的地方使用,包括在返回的 JSX 输出的内部:
-```
+```js
class Button extends React.Component {
clickCounter = 0;
@@ -298,36 +295,35 @@ class Button extends React.Component {
}
}
-// Use it
+// 使用
ReactDOM.render(, mountNode);
```
-Example 11 — Using class properties (test by clicking the Save button)
+例 11:使用类的属性(通过单击保存按钮进行测试)
-Note a few things about Example 11 above:
+注意上述例 11 中的几件事情
-- The `handleClick` function is written using the new proposed [class-field syntax](https://github.com/tc39/proposal-class-fields) in JavaScript. This is still at stage-2, but it’s the best option (for many reasons) to access the component mounted instance (thanks to arrow functions). However, you need to use a compiler like Babel configured to understand stage-2 (or just the class-field syntax) to get the code above to work. The jsComplete REPL has that pre-configured.
-- We’ve also defined the `clickCounter` instance variables using the same class-field syntax. This allows us to skip using a class constructor call all together.
-- When we specified the `handleClick` function as the value of the special `onClick` React attribute, we did not call it. We just passed in the *reference* to the `handleClick` function. Calling the function instead on that level is one of the most common mistakes when working with React.
+- `handleClick` 函数使用 JavaScript 新提出的 [class-field syntax](https://github.com/tc39/proposal-class-fields) 语法。这仍然是 stage-2,但是这是访问组件安装实例(感谢箭头函数)最好的选择(因为很多原因)。然而,你需要使用类似 Babel 的编译器解码为 stage-2(或者仅仅是类字段语法)来让上述代码工作。 jsComplete REPL 有预编译功能。
-```
-// Wrong:
+```js
+// 错误:
onClick={this.handleClick()}
-// Right:
+// 正确:
onClick={this.handleClick}
```
-#### 5 — Events in React: Two Important Differences
+#### 5 React 中的事件:两个重要的区别
-When handling events inside React elements, there are two very important differences from the way we do so with the DOM API:
+当处理 React 元素中的事件时,我们与 DOM API 的处理方式有两个非常重要的区别:
-- All React elements attributes (events included) are named using *camelCase*, rather than *lowercase*. It’s `onClick`, not `onclick`.
-- We pass an actual JavaScript function reference as the event handler, rather than a string. It’s `onClick={**handleClick**}`, not `onClick="**handleClick"**`.
+- 所有 React 元素属性(包括事件)都使用 **camelCase** 命名,而不是 **camelCase**。例如是 `onClick` 而不是 `onClick`。
+- 我们将实际的 JavaScript 函数引用传递给事件处理程序,而不是字符串。例如是 `onClick={handleClick}` 而不是 `onClick="handleClick"`。
-React wraps the DOM event object with an object of its own to optimize the performance of events handling, but inside an event handler, we can still access all methods available on the DOM event object. React passes that wrapped event object to every handle call. For example, to prevent a form from the default submission action, you can do:
+React 用自己的对象包装 DOM 对象事件以优化事件处理的性能,但是在事件处理程序内部,我们仍然可以访问 DOM 对象上所有可以访问的方法。React 将经过包装的事件对象传递给每个调用函数。例如,为了防止表单提交默认提交操作,你可以这样做:
-```
+
+```js
class Form extends React.Component {
handleSubmit = (event) => {
event.preventDefault();
@@ -343,34 +339,35 @@ class Form extends React.Component {
}
}
-// Use it
+// 使用
ReactDOM.render(, mountNode);
```
-Example 12 — Working with wrapped events
+例 12:使用包装过的对象
-#### 6 — Every React component has a story — Part 1
+#### 6 每一个 React 组件都有一个故事:第 1 部分
-The following applies to the class component only (those that extend `React.Component`). Function components have a slightly different story.
+以下仅适用于类组件(扩展 `React.Component`)。函数组件有一个稍微不同的故事。
-1. First, we define a template for React to create elements from the component.
-2. Then, we instruct React to use it somewhere. For example, inside a `render` call of another component, or directly with `ReactDOM.render`.
-3. Then, React instantiates an element and gives it a set of *props* that we can access with `this.props`. Those props are exactly what we passed in step 2 above.
-4. Since it’s all JavaScript, the `constructor` method will be called (if defined). This is the first of what we call: *component lifecycle methods.*
-5. React then computes the output of the render method (the virtual DOM node).
-6. Since this is the first time React is rendering the element, React will communicate with the browser (on our behalf, using the DOM API) to display the element there. This process is commonly know as *mounting*.
-7. React then invokes another lifecycle method, called `componentDidMount`. We can use this method to, for example, do something on the DOM that we now know exists in the browser. Prior to this lifecycle method, the DOM we work with was all virtual.
-8. Some components stories end here. Other components get unmounted from the browser DOM for various reasons. Right before the latter happens, React invokes another lifecycle method, `componentWillUnmount`.
-9. The *state* of any mounted element might change. The parent of that element might re-render. In either case, the mounted element might receive a different set of props. React magic happens here and we actually start *needing* React at this point! Prior to this point, we did not need React at all, honestly.
-10. The story of this component continues, but before it does, we need to understand this *state* thing that I speak off.
+1. 首先,我们定义了一个模板来创建组件中的元素。
+2. 然后,我们在某处使用 React。例如,在 `render` 内部调用其他的组件,或者直接使用 `ReactDOM.render`。
+3. 然后,React 实例化一个对象然后给它设置 **props** 然后我们可以通过 `this.props` 访问。这些属性都是我们在第 2 步传入的。
+4. 因为这些全部都是 JavaScript,`constructor` 方法将会被调用(如果定义的话)。这是我们称之为的第一个:**组件生命周期方法**。
+5. 接下来 React 计算渲染之后的输出方法(虚拟 DOM 节点)。
+6. 因为这是 React 第一次渲染元素,React 将会与浏览器连通(代表我们使用 DOM API)来显示元素。这整个过程称为 **mounting**。
+7. 接下来 React 调用另一个生命周期函数,称为 `componentDidMount`。我们可以这样使用这个方法,例如:在 DOM 上做一些我们现在知道的在浏览器中存在的东西。在此生命周期方法之前,我们使用的 DOM 都是虚拟的。
+8. 一些组件的故事到此结束,其他组件得到卸载浏览器 DOM 中的各种原因。在后一种情况发生时,会调用另一个生命周期的方法,`componentWillUnmount`。
+9. 任何 mounted 的元素的**状态**都可能会改变。该元素的父级可能会重新渲染。无论哪种情况,mounted 的元素都可能接收到不同的属性集。React 的魔力就是这儿,我们实际上需要的正是 React 的这一点!在这一点之前,说实话,我们并不需要 React。
+10. 组价的故事还在继续,但是在此之前,我们需要理解我所说的这种**状态**。
-#### 7 — React components can have a private state
+#### 7 React 组件可以具有私有状态
-The following is also only applicable to class components. Did I mention that some people call presentational-only components *dumb*?
+以下只适用于类组件。我有没有提到有人叫表象而已的部件 **dumb**?
-The state class field is a special one in any React class component. React monitors every component state for changes, but for React do to so efficiently, we have to change the state field through another React API thing that we need to learn, `this.setState`:
+状态类是任何 React 类组件中的一个特殊字段。React 检测每一个组件状态的变化,但是为了 React 更加有效,我们必须通过 React 的另一个 API 改变状态字段,这就是我们要学习的另一个 API —— `this.setState`:
-```
+
+```js
class CounterButton extends React.Component {
state = {
clickCounter: 0,
@@ -400,83 +397,82 @@ class CounterButton extends React.Component {
}
}
-// Use it
+// 使用
ReactDOM.render(, mountNode);
```
-Example 13 — the setState API
+例 13:setState 的 API
-This is probably the most important example to understand because it’ll basically complete your fundamental knowledge of the React way. After this example, there are a few other small things that you need to learn, but it’s mostly you and your JavaScript skills from that point.
+这可能是最重要的一个例子因为这将是你完全理解 React 基础知识的方式。这个例子之后,还有一些小事情需要学习,但从那时起主要是你和你的 JavaScript 技能。
-Let’s walk through Example 13, starting with class fields. It has 2 of them, the special `state` field, which is initialized with an object that holds a `clickCounter` that starts with `0`, and a `currentTimestamp` that starts with `new Date()`.
+让我们来看一下例 13,从类开始,总共有两个,一个是一个初始化的有初始值为 `0` 的 `clickCounter` 对象和一个从 `new Date()` 开始的 `currentTimestamp`。
-The other class field is a `handleClick` function, which we passed to the `onClick` event for the button element inside the render method. The `handleClick` method modifies this component instance state using `setState`. Take notice of that.
+另一个类是 `handleClick` 函数,在渲染方法中我们给按钮元素传入 `onClick` 事件。通过使用 `setState` 的 `handleClick` 方法修改了组件的实例状态。要注意到这一点。
-The other place we’re modifying the state is inside an interval timer that we started inside the `componentDidMount` lifecycle method. It ticks every second and executes another call to `this.setState`.
+另一个我们修改状态的地方是在一个内部的定时器,开始在内部的 `componentDidMount` 生命周期方法。它每秒钟调用一次并且执行另一个函数调用 `this.setState`。
-In the render method, we used the two properties we have on the state with a normal read syntax (there is no special API for that).
+在渲染方法中,我们使用具有正常读语法的状态上的两个属性(没有专门的 API)。
-Now, notice that we updated the state using 2 different ways:
+现在,注意我们更新状态使用两种不同的方式:
-1. By passing a function that returned an object. We did that inside the `handleClick` function.
-2. By passing a regular object. We did that inside the interval callback.
+1. 通过传入一个函数然后返回一个对象。我们在 `handleClick` 函数内部这样做。
+2. 通过传入一个正则对象,我们在在区间回调中这样做。
-Both ways are acceptable, but the first one is preferred when you read and write to the state at the same time (which we do). Inside the interval callback, we’re only writing to the state and not reading it. When in doubt, always use the first function-as-argument syntax. It’s safer with race conditions because `setState` is actually an asynchronous method.
+这两种方式都是可以接受的,但是当你同时读写状态时,第一种方法是首选的(我们这样做)。在区间回调中,我们只向状态写入而不读它。当有问题时,总是使用第一个函数作为参数语法。伴随着竞争条件这更安全,因为 `setstate` 实际上是一个异步方法。
-How do we update the state? we returned an object with the new value of what we want to update. Notice how in both calls to `setState`, we’re just passing one property from the state field and not both. This is completely ok because `setState` actually *merges* what you pass it (the returned value of the function argument) with the existing state. So, not specifying a property while calling `setState` means that we wish to not change that property (but not delete it).
+我们应该怎样更新状态呢?我们返回一个有我们想要更新的的值的对象。注意,在调用 `setState` 时,我们全部都从状态中传入一个属性或者全都不。这完全是可以的因为 `setState` 实际上 **合并** 了你通过它(返回值的函数参数)与现有的状态,所以,没有指定一个属性在调用 `setState` 时意味着我们不希望改变属性(但不删除它)。
[](https://twitter.com/samerbuna/status/870383561983090689)
-#### 8 — React will react
+#### 8 React 将要反应
-React gets its name from the fact that it *reacts* to state changes (although not reactively, but on a schedule). There was a joke that React should have been named *Schedule*!
+React 的名字是从状态改变的**反应**中得来的(虽然没有反应,但也是在一个时间表中)。这里有一个笑话,React 应该被命名为**Schedule**!
-However, what we witness with the naked eye when the state of any component gets updated is that React reacts to that update and automatically reflects the update in the browser DOM (if needed).
+然而,当任何组件的状态被更新时,我们用肉眼观察到的是对该更新的反应,并自动反映了浏览器 DOM 中的更新(如果需要的话)。
-Think of the render function’s input as both
+将渲染函数的输入视为两种:
+- 通过父元素传入的属性
+- 以及可以随时更新的内部私有状态
-- the props that get passed by the parent,
-- and the internal private state that can be updated any time.
+当渲染函数的输入改变时,输出可能也会改变。
-When the input of the render function changes, it’s output might change.
+React 保存了渲染的历史记录,当它看到一个渲染与前一个不同时,它将计算它们之间的差异,并将其有效地转换为在 DOM 中执行的实际 DOM 操作。
-React keeps a record of the history of renders and when it sees that one render is different than the previous one, it’ll compute the difference between them and efficiently translate it into actual DOM operations that get executed in the DOM.
+#### 9 React 是你的代码
-#### 9 — React is your agent
+您可以将 React 看作是我们用来与浏览器通信的代理。以上面的当前时间戳显示为例。取代每一秒我们都需要手动去浏览器调用 DOM API 操作来查找和更新 `p#timestamp` 元素,我们仅仅改变组件的状态属性,React 做的工作代表我们与浏览器的通信。我相信这就是为什么 React 这么受欢迎的真正原因;我们只是不喜欢和浏览器先生谈话(以及它所说的 DOM 语言的很多方言),并且 React 自愿传递给我们,免费的!
-You can think of React as the agent we hired to communicate with the browser. Take the current timestamp display above as an example. Instead of us manually going to the browser and invoking DOM API operations to find and update the `p#timestamp` element every second, we just changed a property on the state of the component and React did its job of communicating with the browser on our behalf. I believe this is the true reason why React is popular; we just hate talking to Mr. browser (and the so many dialects of the DOM language that it speaks) and React volunteered to do all the talking for us, for free!
+#### 10 每一个 React 组件都有一个故事:第 2 部分
-#### 10 — Every React component has a story — Part 2
+现在我们知道了一个组件的状态,当该状态发生变化的时候,我们来了解一下关于这个过程的最后几个概念。
-Now that we know about the state of a component and how when that state changes some magic happens, let’s learn the last few concepts about that process.
-1. A component might need to re-render when its state get updated or when its parent decides to change the props that it passed to the component
-2. If the latter happens, React invokes another lifecycle method, `componentWillReceiveProps`.
-3. If either the state object or the passed-in props are changed, React has an important decision to do. Should the component be updated in the DOM? This is why it invokes another important lifecycle method here, `shouldComponentUpdate`. This method is an actual question, so if you need to customize or optimize the render process on your own, you have to answer that question by returning either true or false.
-4. If there is no custom `shouldComponentUpdate` specified, React defaults to a very smart thing that’s actually good enough in most situations.
-5. First, React invokes another lifecycle method at this point, `componentWillUpdate`. React will then compute the new rendered output and diff it with the last rendered output.
-6. If the rendered output is exactly the same, React does nothing (no need to talk to Mr. Browser).
-7. If there is a difference, React takes that difference to the browser, as we’ve seen before.
-8. In any case, since an update process happened anyway (even if the output was exactly the same), React invokes the final lifecycle method, `componentDidUpdate`.
+1. 当组件的状态被更新时,或者它的父进程决定更改它传递给组件的属性时,组件可能需要重新渲染。
+2. 如果后者发生,React 会调用另一个生命周期方法:`componentWillReceiveProps`。
+3. 如果状态对象或传递的属性改变了,React 有一个重要的决定要做:组件是否应该在 DOM 中更新?这就是为什么它调用另一个重要的生命周期方法 `shouldComponentUpdate` 的原因 。此方法是一个实际问题,因此,如果需要自行定制或优化渲染过程,则必须通过返回 true 或 false 来回答这个问题。
+4. 如果没有自定义 `shouldComponentUpdate`,React 的默认事件在大多数情况下都能处理的很好。
+5. 首先,这个时候会调用另一生命周期的方法:`componentWillUpdate`。然后,React 将计算新渲染过的输出,并将其与最后渲染的输出进行对比。
+6. 如果渲染过的输出和之前的相同,React 不进行处理(不需要和浏览器先生对话)。
+7. 如果有不同的地方,React 将不同传达给浏览器,像我们之前看到的那样。
+8. 在任何情况下,一旦一个更新程序发生了,无论以何种方式(即使有相同的输出),React 会调用最后的生命周期方法:`componentDidUpdate`。
-Lifecycle methods are actually escape hatches. If you’re not doing anything special, you can create full applications without them. They’re very handy for analyzing what is going on in the application and for further optimizing the performance of React updates.
+生命周期方法是逃生舱口。如果你没有做什么特别的事情,你可以在没有它们的情况下创建完整的应用程序。它们非常方便地分析应用程序中正在发生的事情,并进一步优化 React 更新的性能。
---
-That’s it. Believe it or not, with what you learned above (or parts of it, really), you can start creating some interesting React applications. If you’re hungry for more, check out my [**Getting Started with React.js course at Pluralsight**](https://www.pluralsight.com/courses/react-js-getting-started?aid=701j0000001heIoAAI&promo=&oid=&utm_source=google&utm_medium=ppc&utm_campaign=US_Dynamic&utm_content=&utm_term=&gclid=CNOAj_2-j9UCFUpNfgod4V0Fdg).
+信不信由你,通过上面所学的知识(或部分知识),你可以开始创建一些有趣的 React 应用程序。如果你渴望更多,看看我的 [**Pluralsight 的 React.js 入门课程**](https://www.pluralsight.com/courses/react-js-getting-started?aid=701j0000001heIoAAI&promo=&oid=&utm_source=google&utm_medium=ppc&utm_campaign=US_Dynamic&utm_content=&utm_term=&gclid=CNOAj_2-j9UCFUpNfgod4V0Fdg)。
-*Thanks for reading. If you found this article helpful, please click the💚 below. Follow me below for more articles on React.js and JavaScript.*
+**感谢阅读。如果您觉得这篇文章有帮助,请点击下面的 💚。请关注我的更多关于 React.js 和 JavaScript 的文章**。
---
-I create online courses for [Pluralsight](https://app.pluralsight.com/profile/author/samer-buna) and [Lynda](https://www.lynda.com/Samer-Buna/7060467-1.html). My most recent courses are [Advanced React.js](https://www.pluralsight.com/courses/reactjs-advanced), [Advanced Node.js](https://www.pluralsight.com/courses/nodejs-advanced), and [Learning Full-stack JavaScript](https://www.lynda.com/Express-js-tutorials/Learning-Full-Stack-JavaScript-Development-MongoDB-Node-React/533304-2.html). I also do online and onsite training for groups covering beginner to advanced levels in JavaScript, Node.js, React.js, and GraphQL. [Drop me a line](mailto:samer@jscomplete.com) if you’re looking for a trainer. If you have any questions about this article or any other article I wrote, find me on [this slack account](https://slack.jscomplete.com/) (you can invite yourself) and ask in the #questions room.
+我 [Pluralsight](https://app.pluralsight.com/profile/author/samer-buna) 和 [Lynda](https://www.lynda.com/Samer-Buna/7060467-1.html) 创建了在线课程。我最新的文章在[Advanced React.js](https://www.pluralsight.com/courses/reactjs-advanced)、 [Advanced Node.js](https://www.pluralsight.com/courses/nodejs-advanced) 和 [Learning Full-stack JavaScript](https://www.lynda.com/Express-js-tutorials/Learning-Full-Stack-JavaScript-Development-MongoDB-Node-React/533304-2.html)中。我也做小组的在线和现场培训,覆盖初级到高级的 JavaScript、 Node.js、 React.js、GraphQL。如果你需要一个导师,[请来找我](mailto:samer@jscomplete.com) 。如果你对此篇文章或者我写的其他任何文章有疑问,[通过这个联系我](https://slack.jscomplete.com/),并且在 #questions 中提问。
---
-Thanks to the many readers who reviewed and improved this article, Łukasz Szewczak, Tim Broyles, Kyle Holden, Robert Axelse, Bruce Lane, Irvin Waldman, and Amie Wilt.
-
-The most special of thanks go to “amazing” [Amie](https://www.linkedin.com/in/amiewilt/) who turned out to be an actual [Unicorn](https://medium.com/@katherinemartinez/the-unicorn-hybrid-designer-developer-5e89607d5fe0). Thanks for all your help Amie. I truly appreciate it.
+感谢很多检验和改进这篇文章的读者,Łukasz Szewczak、Tim Broyles、 Kyle Holden、 Robert Axelse、 Bruce Lane、Irvin Waldman 和 Amie Wilt.
+特别要感谢“惊人的” [Amie](https://www.linkedin.com/in/amiewilt/),经验是一个实际的 [Unicorn](https://medium.com/@katherinemartinez/the-unicorn-hybrid-designer-developer-5e89607d5fe0)。谢谢你所有的帮助,Anime,真的非常感谢你。
---
diff --git a/TODO/rest-apis-are-rest-in-peace-apis-long-live-graphql.md b/TODO/rest-apis-are-rest-in-peace-apis-long-live-graphql.md
index d7b812d2ddf..ea13f0a49fa 100644
--- a/TODO/rest-apis-are-rest-in-peace-apis-long-live-graphql.md
+++ b/TODO/rest-apis-are-rest-in-peace-apis-long-live-graphql.md
@@ -3,127 +3,126 @@
> * 原文作者:[Samer Buna](https://medium.freecodecamp.org/@samerbuna)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/rest-apis-are-rest-in-peace-apis-long-live-graphql.md](https://github.com/xitu/gold-miner/blob/master/TODO/rest-apis-are-rest-in-peace-apis-long-live-graphql.md)
-> * 译者:
-> * 校对者:
+> * 译者:[sigoden](https://github.com/sigoden)
+> * 校对者:[jasonxia23](https://github.com/jasonxia23)、[shawnchenxmu](https://github.com/shawnchenxmu)
-# REST APIs are REST-in-Peace APIs. Long Live GraphQL
+# REST API 已死,GraphQL 长存
-After years of dealing with REST APIs, when I first learned about GraphQL and the problems it’s attempting to solve, I could not resist tweeting the exact title of this article.
+在使用多年的 REST API 后,当我第一次接触到 GraphQL 并了解到它试图解决的问题时,我无法抗拒给本文取了这样一个标题。
](https://twitter.com/samerbuna/status/644548922979954688)
-Of course, back then, it was just an attempt by me at being funny, but today I believe that the funny prediction is actually happening.
+当然,过去,这可能只是本人有趣的尝试,但是现在,我相信这有趣的预测正在慢慢发生。
-Please don’t interpret this wrong. I am not going to accuse GraphQL of “killing” REST or anything like that. REST will probably never die, just like XML never did. I simply think GraphQL will do to REST what JSON did to XML.
+请不要理解错了,我并没有说 GraphQL 会干掉 REST 或其它类似的话语,REST 大概永远不会真正消亡,就像 XML 并不会真正消亡一样。我只是认为 GraphQL 与 REST 的关系将会变得像 JSON 与 XML 一样。
-This article is not actually 100% in favor of GraphQL. There is a very important section about the cost of GraphQL’s flexibility. With great flexibility comes great cost.
+本文并不是百分百支持 GraphQL。需要注意 GraphQL 灵活性所带来的开销。好的灵活性常常伴随着大的开销。
-I am a big fan of “Always [Start with WHY](https://startwithwhy.com/)”, so let’s do that.
+我信仰"一切[从提问开始](https://startwithwhy.com/)",让我们开始吧。
-### In Summary: Why GraphQL?
+### 总而言之:为什么需要 GraphQL?
-The 3 most important problems that GraphQL solves beautifully are:
+GraphQL 漂亮地解决了如下三个重要问题:
-- **The need to do multiple round trips to fetch data required by a view**: With GraphQL, you can always fetch all the initial data required by a view with a *single* round-trip to the server. To do the same with a REST API, we need to introduce unstructured parameters and conditions that are hard to manage and scale.
-- **Clients dependency on servers**: With GraphQL, the client speaks a request language which: 1) eliminates the need for the server to hardcode the shape or size of the data, and 2) decouples clients from servers. This means we can maintain and improve clients separately from servers.
-- **The bad front-end developer experience**: With GraphQL, developers express the data requirements of their user interfaces using a declarative language. They express *what* they need, not *how* to make it available. There is a tight relationship between what data is needed by the UI and the way a developer can express a description of that data in GraphQL .
+- **填充一个视图需要的数据进行多次往返拉取**: 使用 GraphQL,我们总能够通过**一次**往返就能从服务器获取到用来填充视图的所有初始化数据。如果使用 REST API,要到达相同的效果,我们需要引入非结构化的参数和条件,使管理和维护变得困难。
+- **客户端对服务端产生依赖**: 使用 GraphQL,客户端就有了自己的语言:1) 无需服务端对数据的结构和规格进行硬编码 2) 客户端与服务端解耦。这意味着我们能让客户端与服务器分离并单独对它进行维护和升级。
+- **糟糕的前端开发体验**: 使用 GraphQL,前端开发人员使用声明式语言表达其对填充用户界面所需要的数据的需求。他们表达他们需要什么,而不是如何使其可用。这样就在 UI 需要的数据和开发人员在 GraphQL 中表述的数据之间构建一种紧密的联系。
-This article will explain in detail how GraphQL solves all these problems.
+本文将就 GraphQL 如何解决这些问题进行详细阐述。
-Before we begin, for those of you not yet acquainted with GraphQL, let’s start with simple definitions.
+在我们正式开始之前,考虑到你目前可能还不熟悉 GraphQL ,我们先从简单定义开始。
-### What is GraphQL?
+### GraphQL 是什么?
-GraphQL is a *language*. If we teach GraphQL to a software application, that application will be able to *declaratively* communicate any data requirements to a backend data service that also speaks GraphQL.
+GraphQL 是一门**语言**。 如果我们传授 GraphQL 语言给一款应用,这款应用就能够向支持 GraphQL 的后端数据服务**声明式**传达数据需求。
-> Just like a child can quickly learn a new language — while a grown-up will have a harder time picking it up — starting a new application from scratch using GraphQL will be a lot easier than introducing GraphQL to a mature application.
+> 就像小孩子很快就能学会一种新语言,而成年人却很难学会一样,使用 GraphQL 从头开始编写应用比将 GraphQL 添加到一款成熟的应用要容易很多。
-To teach a data service to speak GraphQL, we need to implement a *runtime* layer and expose it to the clients who want to communicate with the service. Think of this layer on the server side as simply a translator of the GraphQL language, or a GraphQL-speaking agent who represents the data service. GraphQL is not a storage engine, so it can’t be a solution on its own. This is why we can’t have a server that speaks just GraphQL and we need to implement a translating runtime instead.
+为了让数据服务支持 GraphQL,我们需要实现一个**运行时**层并将它暴露给想要与服务通信的客户端。可以将这个添加到服务端的层简单地看作是一位 GraphQL 语言翻译员,或代表数据服务并会说 GraphQL 语言的代理。GraphQL 并不是一个存储引擎,所以它不能作为一个独立的解决方案。这就是我们不能有一个纯粹的 GraphQL 服务,而需要实现一个翻译运行时的原因。
-This layer, which can be written in any language, defines a generic graph-based schema to publish the *capabilities* of the data service it represents. Client applications who speak GraphQL can query that schema within its capabilities. This approach decouples clients from servers and allows both of them to evolve and scale independently.
+这个层可以用任何语言编写,它定义了一个通用的基于图的模板来发布它所代表的数据服务的**功能**。支持 GraphQL 的客户端可以在功能允许的范围内使用这种模版进行查询。这一策略可以将客户端与服务端分离,允许两者独立开发和扩展。
-A GraphQL request can be either a **query** (read operation) or a **mutation** (write operation). For both cases, the request is a simple string that a GraphQL service can interpret, execute, and resolve with data in a specified format. The popular response format that is usually used for mobile and web applications is *JSON*.
+一个 GraphQL 请求既可以是**查询**(读操作),也可以是**修改**(写操作)。不管是何种情形,请求均只是一个带有特定格式的简单字符串,GraphQL 服务器可以对其进行解析、执行、处理。在移动和 Web 应用中最常见的响应格式是 *JSON* 。
-### What is GraphQL? (The Explain-it-like-I’m-5 version)
-
-GraphQL is all about data communication. You have a client and a server and both of them need to talk with each other. The client needs to tell the server what data it needs, and the server needs to fulfill this client’s data requirement with actual data. GraphQL steps into the middle of this communication.
+### 什么是 GraphQL ?(把我当五岁小孩后再向我解释版)
+GraphQL 一切为了数据通信。你有一个需要需要彼此通信的客户端和服务器,客户端需要告诉服务器它需要什么数据,服务器需要根据客户端的需求返回具体的数据,GraphQL 作为这种通信的中间人。
-Screenshot captured from my Pluralsight course — Building Scalable APIs with GraphQL
-Why can’t the client just communicate directly with the server, you ask? It sure can.
+屏幕截图中是我的 Pluralsight 课程 —— 使用 GraphQL 构建可扩展 API
+你问,客户端难道不能直接与服务器通信吗?答案是能。
-There are a few reasons to consider a GraphQL layer between clients and servers. One of those reasons, and perhaps the most popular one, is *efficiency*. The client usually needs to ask the server about *multiple* resources, and the server usually understands how to reply with a single resource. So the client ends up doing multiple round-trips to the server to gather all the data it needs.
+这儿有几个原因导致我们需要在客户端和服务器间添加一个 GraphQL 层。原因之一,可能也是最主要的原因,这样做更**高效**。客户端通常需要从服务器获取**多个**资源,而服务器通常只能理解如何对单个资源进行回复。这就造成客户端最后需要多次往返服务器才能集齐需要的数据。
-With GraphQL, we can basically shift this multi-request complexity to the server-side and have the GraphQL layer deal with it. The client asks the GraphQL layer a single question and gets a single response that has exactly what the client needs.
+通过 GraphQL,我们基本上可以将这种复杂的多次请求转移到服务端,让 GraphQL 层来处理。客户端向 GraphQL 层发起单个请求,并得到一个完全符合客户端需求的响应。
-There are a lot more benefits to using a GraphQL layer. For example, one other big benefit is communicating with multiple services. When you have multiple clients requesting data from multiple services, a GraphQL layer in the middle can simplify and standardize this communication. Although this is not really a point against REST APIs — as it is easy to accomplish the same there — a GraphQL runtime offers a structured and standardized way of doing it.
+使用 GraphQL 层还有很多其它好处。例如,另一个大的好处是与多个服务进行通信。当您有多个客户端向多个服务请求数据时,中间的 GraphQL 可以让通信简化、标准化。尽管与 REST API 比起来这不算是卖点 —— 因为 REST API 也可以很容易地完成同样的工作 —— 但 GraphQL 运行时提供了一种结构化和标准化的方法。
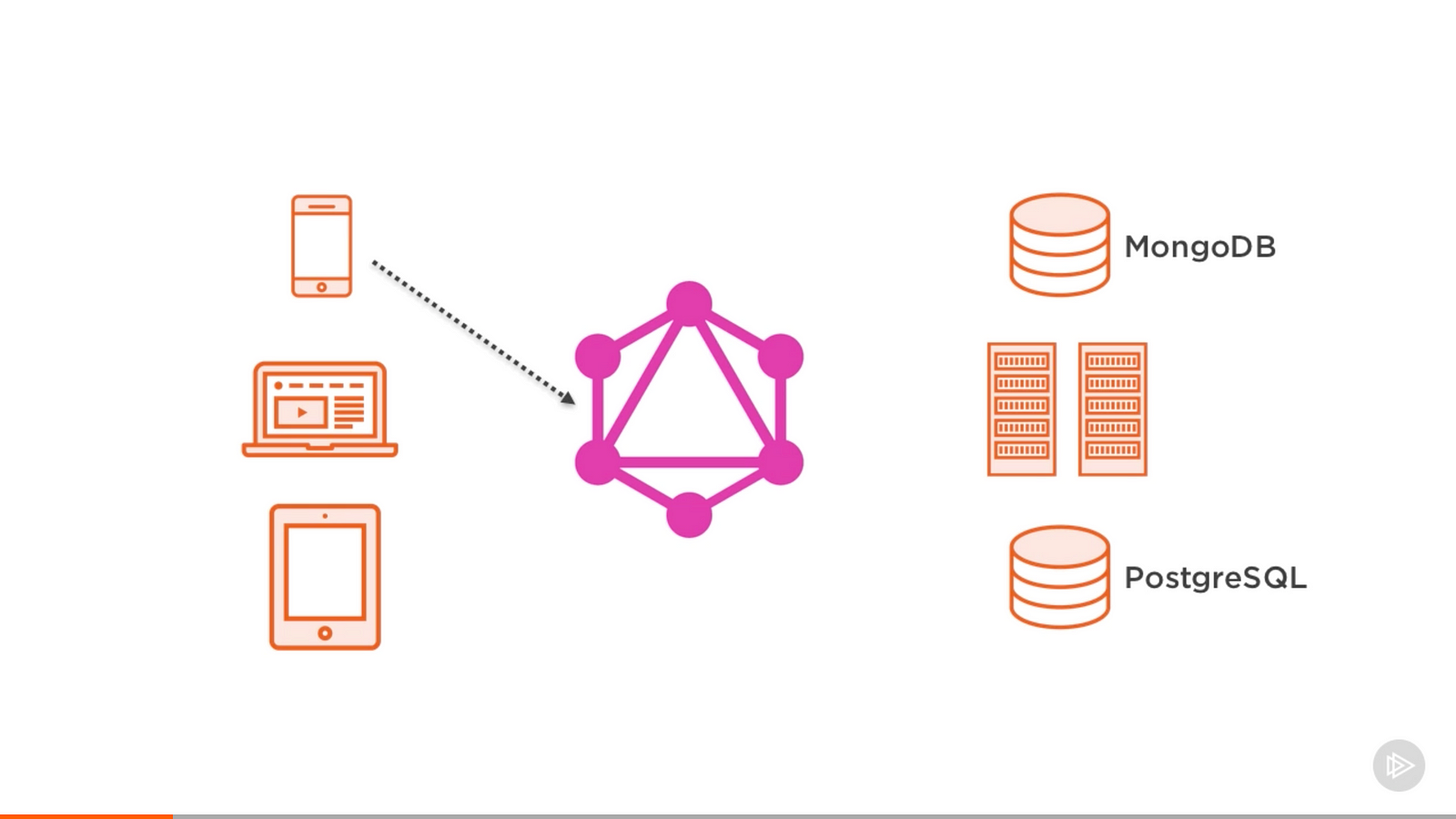
-Screenshot captured from my Pluralsight course — Building Scalable APIs with GraphQL
-Instead of a client going to the two different data services directly (in the slide above), we can have that client communicate with the GraphQL layer. Then the GraphQL layer will do the communication with the two different data services. This is how GraphQL first isolates the clients from needing to communicate in multiple languages and also translates a single request into multiple requests to multiple services using different languages.
-
-> Imagine that you have three people who speak three different languages and have different types of knowledge. Then imagine that you have a question that can only be answered by combining the knowledge of all three people together. If you have a translator who speaks all three languages, the task of putting together an answer to your question becomes easy. This is exactly what a GraphQL runtime does.
+屏幕截图中是我的 Pluralsight 课程 —— 使用 GraphQL 构建可扩展 API
+不是让客户端直接请求两个不同的数据服务(如幻灯片所示),而是让客户端先与 GraphQL 层通信。GraphQL 层再分别与两个不同的数据服务通信。通过这种方式,GraphQL 解决了客户端必须与多个不同语言的后端进行通信的问题,并将单个请求转换为使用不同语言的多个服务的多个请求。
-Computers aren’t smart enough to answer just any questions (at least not yet), so they have to follow an algorithm somewhere. This is why we need to define a schema on the GraphQL runtime and that schema gets used by the clients.
+> 想象一下,你认识三个人,他们说不同的语言,掌握着不同领域的知识。然后再想象一下,你遇到一个只有结合三个人的知识才能回答的问题。如果你有一个会说这三种语言的翻译人员,那么任务就变成将你的问题的答案放在一起,这就很容易了。这就是 GraphQL 运行时要做的。
-The schema is basically a capabilities document that has a list of all the questions which the client can ask the GraphQL layer. There is some flexibility in how to use the schema because we’re talking about a graph of nodes here. The schema mostly represents the limits of what can be answered by the GraphQL layer.
+计算机还没有聪明到能回答任何问题(至少目前是这样),所以它们必须遵守某种算法。这就是为什么我们需要在 GraphQL 运行时中定义一个模板让客户端来使用的原因。
-Still not clear? Let’s call GraphQL what it really and simply is: *A replacement for REST APIs.* So let me answer the question that you’re most likely asking now.
+这个模板基本上是一个功能文档,它列出了客户端能向 GraphQL 层查询的全部问题。因为模板采用了图形节点所以在使用上具有一定的灵活性。模板也表明了 GraphQL 层能解答哪些问题,不能解答哪些问题。
-### What’s wrong with REST APIs?
+还是不理解?让我用最确切最简短的话语来描述 GraphQL :**一种 REST API 的替代**。接下来让我回答一下你很可能会问的问题。
-The biggest problem with REST APIs is the nature of multiple endpoints. These require clients to do multiple round-trips to get their data.
+### REST API 有什么错?
-REST APIs are usually a collection of endpoints, where each endpoint represents a resource. So when a client needs data from multiple resources, it needs to perform multiple round-trips to a REST API to put together the data it needs.
+REST API 最大的问题是其天然倾向多端点。这造成客户端需要多次往返获取数据。
-In a REST API, there is no client request language. Clients do not have control over what data the server will return. There is no language through which they can do so. More accurately, the language available for clients is very limited.
+REST API 通常由多个端点组成,每个端点代表一种资源。因此,当客户端需要多个资源时,它需要向 REST API 发起多个请求,才能获取到所需要的数据。
-For example, the *READ* REST API endpoints are either:
+在 REST API 中,是没有描述客户端请求的语言的。客户端无法控制服务器返回哪些数据。没有让客户端对返回数据进行控制的语言。更确切的说,客户端能使用的语言是很有限的。
-- GET `/ResouceName` - to get a list of all the records from that resource, or
-- GET `/ResourceName/ResourceID` - to get the single record identified by that ID.
+例如,有如下进行**读取**操作的 REST API:
-A client can’t, for example, specify which *fields* to select for a record in that resource. That information is in the REST API service itself and the REST API service will always return all of the fields regardless of which ones the client actually needs. GraphQL’s term for this problem is *over-fetching* of information that’s not needed. It’s a waste of network and memory resources for both the client and server.
+- GET `/ResouceName` - 从该资源获取包含所有记录的列表
+- GET `/ResourceName/ResourceID` - 通过 ID 获取某条特定记录
-One other big problem with REST APIs is versioning. If you need to support multiple versions, that usually means new endpoints. This leads to more problems while using and maintaining those endpoints and it might be the cause of code duplication on the server.
+例如,客户端是不能够指定从该资源的记录中选择哪些**字段**的。信息仅存在于提供 REST API 的服务中,该服务将始终返回所有字段,而不管客户端需要什么。借用 GraphQL 术语描述这个问题:**超额获取**(over-fetching) 没用的信息。这浪费了服务器和客户端的网络内存资源
+*
+REST API 的另一个大问题就是版本控制了。如果你需要支持多版本,那你就需要为此创建多个新的端点。这会导致这些端点很难使用和维护,此外,还造成服务端出现很多冗余代码。
-The REST APIs problems mentioned above are the ones specific to what GraphQL is trying to solve. They are certainly not all of the problems of REST APIs, and I don’t want to get into what a REST API is and is not. I am mostly talking about the popular resource-based-HTTP-endpoint APIs. Every one of those APIs eventually turns into a mix that has regular REST endpoints + custom ad-hoc endpoints crafted for performance reasons. This is where GraphQL offers a much better alternative.
+上面列出的一些 REST API 带来的问题都是 GraphQL 试图解决的。这并不是 REST API 带来的全部问题,我也不打算说明 REST API 是什么不是什么。我只是在谈论一种最流行的基于资源的 HTTP 终点 API。这些 API 最终都会变成一种具有常规 REST 特性的端点和出于性能原因定制的特殊端点的组合。
-### How does GraphQL do its magic?
+### GraphQL 如何实现其魔力?
-There are a lot of concepts and design decisions behind GraphQL, but probably the most important ones are:
+在 GraphQL 背后有很多的概念和设计策略,这儿列举了一些最重要的:
-- A GraphQL schema is a strongly typed schema. To create a GraphQL schema, we define *fields* that have *types*. Those types can be primitive or custom and everything else in the schema requires a type. This rich type system allows for rich features like having an introspective API and being able to build powerful tools for both clients and servers.
-- GraphQL speaks to the data as a Graph, and data is naturally a graph. If you need to represent any data, the right structure is a graph. The GraphQL runtime allows us to represent our data with a graph API that matches the natural graph shape of that data.
-- GraphQL has a declarative nature for expressing data requirements. GraphQL provides clients with a declarative language for them to express their data needs. This declarative nature creates a mental model around using the GraphQL language that’s close to the way we think about data requirements in English and it makes working with a GraphQL API a lot easier than the alternatives.
+- GraphQL 模板是强类型的。要创建一套 GraphQL 模板,我们需要定义了一些带有**类型**的**字段**。这些类型可以是原始数据类型也可以是自定义的,在模板中一切均需要类型。丰富的类型系统带来了丰富的特性,如 API 自证,这让我们能够为客户端和服务端创建强大的工具。
+- GraphQL 以图的形式组织数据,数据自然形成图。如果你需要一个结构描述数据,图是一种不错的选择。GraphQL 运行时让我们能够使用与该数据的自然图结构匹配的图 API 来表示我们的数据。
+-GraphQL 具有表达数据需求声明性质。GraphQL 让客户端能够以一种声明性的语言描述其对数据的需求。这种声明性带来了一种围绕着 GraphQL 语言使用的心智模型,该模型与我们用自然语言思考数据需求的方式接近,让我们使用 GraphQL 时比使用其它方式更容易。
-The last concept is why I personally believe GraphQL is a game changer.
+最后一个概念是我为什么认为 GraphQL 是游戏规则改变者的原因。
-Those are all high-level concepts. Let’s get into some more details.
+这些全是抽象概念。让我们深入到细节中。
-To solve the multiple round-trip problem, GraphQL makes the responding server just a single endpoint. Basically, GraphQL takes the custom endpoint idea to an extreme and just makes the whole server a single custom endpoint that can reply to all data questions.
+为了解决多次往返请求的问题,GraphQL 让响应服务器变成一个端点。本质上,GraphQL 把自定义端点这一思想发挥到了极致,它让这个端点能够回复所有数据问题。
-The other big concept that goes with this single endpoint concept is the rich client request language that is needed to work with that custom single endpoint. Without a client request language, a single endpoint is useless. It needs a language to process a custom request and respond with data for that custom request.
+伴随着单个端点这一概念的另一个重要概念是需要一种强大的客户端请求描述语言与自定义的单个端点进行通信。缺少客户端请求描述语言,单个端点是没有意义的。它需要一种语言解析自定义请求以及根据自定义请求返回数据。
-Having a client request language means that the clients will be in control. They can ask for exactly what they need and the server will reply with exactly what that they’re asking for. This solves the over-fetching problem.
+拥有一门客户端请求描述语言意味这客户端能够对请求进行控制。客户端能够精确表达它们需要什么,服务端也能精准回复客户端需要的。这就解决了超额获取的问题。
-When it comes to versioning, GraphQL has an interesting take on that. Versioning can be avoided all together. Basically, we can just add new *fields* without removing the old ones, because we have a graph and we can flexibly grow the graph by adding more nodes. So we can leave paths on the graph for old APIs and introduce new ones without labeling them as new versions. The API just grows.
+当涉及到版本时,GraphQL 提供了一种有趣的解决方式。版本能够被完全避免。基本上,我们只需要在保留老的字段的基础上添加新**字段**即可,因为我们用的是图,我们能很灵活的在图上添加更多节点。因此,我们可以在图上留下旧的 API,并引入新的 API,而不会将其标记为新版本。API 只是多了更多节点。
-This is especially important for mobile clients because we can’t control the version of the API they’re using. Once installed, a mobile app might continue to use that same old version of the API for years. On the web, it’s easy to control the version of the API because we just push new code. For mobile apps, that’s a lot harder to do.
+这点对于移动端尤为重用,因为我们无法充值这些移动端使用的版本。一经安装,移动端应用可能数年都使用老版本 API 。对于 Web,我们可以通过发布新代码简单的控制 API 版本,对于移动端应用,这点很难做到。
-*Not totally convinced yet?* How about we do a one-to-one comparison between GraphQL and REST with an actual example?
+**还没有完全相信?** 结合实例一对一对比 GraphQL 和 REST 怎么样?
-### RESTful APIs vs GraphQL APIs — Example
+### REST 风格 API vs GraphQL API —— 案例
-Let’s imagine that we are the developers responsible for building a shiny new user interface to represent the Star Wars films and characters.
+我们假设我们是开发者,负责构建闪亮全新的用户界面,用来展示星球大战影片和角色。
-The first UI we’ve been tasked to build is simple: a view to show information about a single Star Wars person. For example, Darth Vader, and all the films this person appeared in. This view should display the person’s name, birth year, planet name, and the titles of all the films in which they appeared.
+我们要构建的第一份 UI 很简单:一个显示单个星球大战角色的信息视图。例如,达斯·维德以及电影中出场的其他角色。这个视图需要显示角色的姓名、出生年份、母星名、以及出场的所有影片中出现的头衔。
-As simple as that sounds, we’re actually dealing with 3 different resources here: Person, Planet, and Film. The relationship between these resources is simple and anyone can guess the shape of the data here. A person object belongs to one planet object and it will have one or more films objects.
+听起来很简单,我们实际上已经需要处理三种不同的资源:人物、星球和电影。资源之间的关系很简单,任何人都很容易就猜出这里的数据组成。
-The JSON data for this UI could be something like:
+此 UI 的 JSON 数据可能类似于:
{
"data": {
@@ -143,7 +142,7 @@ The JSON data for this UI could be something like:
}
}
-Assuming a data service gave us this exact structure for the data, here’s one possible way to represent its view with React.js:
+假设数据服务按照上面的结构返回数据给我们。我们有一种可行的方式即使用 React.js 来展现视图:
// The Container Component:
@@ -154,58 +153,58 @@ Assuming a data service gave us this exact structure for the data, here’s one
Planet: {person.planet.name}
Films: {person.films.map(film => film.title)}
-This is a simple example, and while our experience with Star Wars might have helped us here a bit, the relationship between the UI and the data is very clear. The UI used all the “keys” from the JSON data object we imagined.
+这是一个简单例子,此外我们关于星球大战的经验也能帮我们一点忙,我们可以很清楚的明白 UI 和数据之间的关系。与我们想象一致,UI 是使用了 JSON 数据对象中的全部的键。
-Let’s now see how we can ask for this data using a RESTful API.
+让我们来看看如何通过 REST 风格 API 获取这些数据。
-We need a single person’s information, and assuming that we know the ID of that person, a RESTful API is expected to expose that information as:
+我们需要单个角色的信息,假设我们知道这个角色的 ID,REST 风格的 API 倾向于这样输出这些信息:
GET - /people/{id}
-This request will give us the name, birthYear, and other information about the person. A good RESTful API will also give us the ID of this person’s planet and an array of IDs for all the films this person appeared in.
+这个请求将会返回角色的姓名、出生年份以及一些其它信息给我们。一个规范的 REST 风格 API 将会返回给我们角色星球的 ID 以及该角色出现过的所有影片的 ID 组成的数组。
-The JSON response for this request could be something like:
+这个请求以 JSON 格式返回的响应类似于:
{
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planetId": 1
"filmIds": [1, 2, 3, 6],
- *** other information we do not need ***
+ *** 其它信息我们不需要 ***
}
-Then to read the planet’s name, we ask:
+然后为了获取星球名称,我们发起请求:
GET - /planets/1
-And to read the films titles, we ask:
+接着为了获取影片中的头衔,我们发起请求:
GET - /films/1
GET - /films/2
GET - /films/3
GET - /films/6
-Once we have all 6 responses from the server, we can combine them to satisfy the data needed by our view.
+当从服务器接受到所有的六个数据后,我们才能将其组合并生成满足视图需要的数据。
-Besides the fact that we had to do 6 round-trips to satisfy a simple data need for a simple UI, our approach here was imperative. We gave instructions for *how* to fetch the data and *how* to process it to make it ready for the view.
+除了有需要六次往返才能获取到满足一个简单 UI 需求的数据这一事实外,这种方式并无不可。我们阐明了如何获取数据,以及如何处理数据使其满足视图需要。
-You can try this yourself if you want to see what I mean. The Star Wars data has a RESTful API currently hosted at [http://swapi.co/](http://swapi.co/). Go ahead and try to construct our data person object there. The keys might be a bit different, but the API endpoints will be the same. You will need to do exactly 6 API calls. Furthermore, you will have to over-fetch information that the view does not need.
+如果你想确认我说的你可以自己动手尝试。有一个部署在 [http://swapi.co/](http://swapi.co/) 上的 REST API 服务提供了星球大战的数据,点进去,在里面尝试构造角色数据。数据的键名可能不同,但 API 端点是一致的。你同样需要进行六次 API 调用。同样,你不得不超额获取视图不需要的信息。
-Of course, this is just one implementation of a RESTful API for this data. There could be better implementations that will make this view easier to implement. For example, if the API server implemented nested resources and understood the relationship between a person and a film, we could read the films data with:
+当然,这只是 REST API 的一个实现方式,可能有更好的实现让生成视图更简单。例如,如果 API 服务支持资源嵌套并能理解角色和影片之间的关系,我们能够通过这种方式获取影片数据:
GET - /people/{id}/films
-However, a pure RESTful API server would most likely not implement that, and we would need to ask our backend engineers to create this custom endpoint for us. That’s the reality of scaling a RESTful API — we just add custom endpoints to efficiently satisfy the growing clients needs. Managing custom endpoints like these is hard.
+然而,一个纯粹的 REST API 服务很难实现这点。我们需要让后端工程师为我们创建自定义端点。这造成 REST API 规模不断增长这一事实 —— 为了满足不断增长的客户端的需要,我们不断添加自定义端点。管理这些自定义端点很难。
-Let’s now look at the GraphQL approach. GraphQL on the server embraces the custom endpoints idea and takes it to its extreme. The server will be just a single endpoint and the channel does not matter. If we’re doing this over HTTP, the HTTP method certainly wouldn’t matter either. Let’s assume we have a single GraphQL endpoint exposed over HTTP at `/graphql`.
+让我们来看一看 GraphQL 策略。GraphQL 在服务端拥抱自定义端点思想并把它发展到极致。服务将只是一个端点,通道变得没有意义。如果我们使用 HTTP 实现,HTTP 方法将失去意义。假设我们有一个单一的 GraphQL 端点,它的 HTTP 地址是 `/graphql`
-Since we want to ask for the data we need in a single round-trip, we’ll need a way to express our complete data needs for the server. We do this with a GraphQL query:
+因为我们希望一次往返获取需要的数据,所以我们需要明明白白告诉服务器我们需要哪些数据。我们通过 GraphQL 进行查询:
GET or POST - /graphql?query={...}
-A GraphQL query is just a string, but it will have to include all the pieces of the data that we need. This is where the declarative power comes in.
+GraphQL 查询只是字符串,但它将包含我们需要的全部数据。这就是声明的强大之处。
-In English, here’s how we declare our data requirement: *we need a person’s name, birth year, planet’s name, and the titles of all their films*. In GraphQL, this translates to:
+英语中,我们这样阐述数据需求:**我们需要角色名、出生年份、星球名和在所有出现过的影片中的头衔**。通过 GraphQL,我们进行如下转换:
{
person(ID: ...) {
@@ -220,25 +219,26 @@ In English, here’s how we declare our data requirement: *we need a person’s
}
}
-Read the English-expressed requirements one more time and compare it to the GraphQL query. It’s as close as it can get. Now, compare this GraphQL query with the original JSON data that we started with. The GraphQL query is the exact structure of the JSON data, except without all the “values” parts. If we think of this in terms of a question-answer relation, the question is the answer statement without the answer part.
+再细读一次英语表述的需求并与 GraphQL 查询进行对比。它们不能再更接近了。现在,将 GraphQL 查询与我们最开始用到的原始 JSON 数据进行对比。GraphQL 查询完全与 JSON 数据结构相对应,不过排除所有是值的部分。如果我们仿照问题与答案关系来考虑这中情况,那问题就是没有具体答案的答案原语。
-If the answer statement is:
+如果答案是:
-> *The closest planet to the Sun is Mercury.*
+> **离太阳最近的星球是水星。**
-A good representation of the question is the same statement without the answer part:
+一种好的提问方式是保留原话只去掉提问部分:
-> *(What is) the closest planet to the Sun?*
+> **哪个星球里太阳最近?**
-The same relationship applies to a GraphQL query. Take a JSON response, remove all the “answer” parts (which are the values), and you end up with a GraphQL query very suitable to represent a question about that JSON response.
+这种关系同样适用于 GraphQL 查询。拿着 JSON 格式的响应数据,移除所有是答案的部分(作为值的对象),最后你得到了一个非常适合代表关于 JSON 响应问题的 GraphQL 查询。
-Now, compare the GraphQL query with the declarative React UI we defined for the data. Everything in the GraphQL query is used in the UI, and everything used in the UI appears in the GraphQL query.
+现在,将 GraphQL 查询和与我们展示数据的声明性 React UI 对比。所有出现在 GraphQL 查询中的数据都出现在了 UI 中。所有出现在 UI 中的数据都出现在了 GraphQL 查询中。
-This is the great mental model of GraphQL. The UI knows the exact data it needs and extracting that requirement is fairly easy. Coming up with a GraphQL query is simply the task of extracting what’s used as variables directly from the UI.
+这就是 GraphQL 强大的心智模型。UI 知晓它所需要的确切数据,提取需要的数据也很容易。编写 GraphQL 查询变成一个从 UI 中提取作为变量这一简单的工作。
-If we invert this model, it would still hold the power. If we have a GraphQL query, we know exactly how to use its response in the UI because the query will be the same “structure” as the response. We don’t need to inspect the response to know how to use it and we don’t need any documentation about the API. It’s all built-in.
-Star Wars data has a GraphQL API hosted at [https://github.com/graphql/swapi-graphql](https://github.com/graphql/swapi-graphql). Go ahead and try to construct our data person object there. There are a few minor differences that we’ll explain later, but here’s the official query you can use against this API to read our data requirement for the view (with Darth Vader as an example):
+将模型进行反转,它仍然很强大。如果我们知道了 GraphQL 查询,我们同样知道如何在 UI 中使用相应数据。我们不需要分析响应数据就能使用它,也不需要的这些 API 的文档。这一切都是内建的。
+
+获取星球大战数据的 GraphQL 托管在 [https://github.com/graphql/swapi-graphql](https://github.com/graphql/swapi-graphql)。点击进去并尝试构造角色数据。只有一点点不同,我们之后会谈论,以下是可以从这个 API 中获取视图所需要数据的正式查询(使用达斯·维德举例)
{
person(personID: 4) {
@@ -255,48 +255,47 @@ Star Wars data has a GraphQL API hosted at [https://github.com/graphql/swapi-gra
}
}
-This request gives us a response structure very close to what our view used, and remember, we’re getting all of this data in a single round-trip.
+这个请求返回的我们的响应数据结构十分接近视图用到的,记住,这些数据是我们通过一次往返获得的。
-### The Cost of GraphQL’s Flexibility
+### GraphQL 灵活性带来的开销
-Perfect solutions are fairy tales. With the flexibility GraphQL introduces, a door opens on some clear problems and concerns.
+完美的解决方案是不存在的。GraphQL 带来了灵活性,也带来了一些明确的问题和考量。
-One important threat that GraphQL makes easier is resource exhaustion attacks (AKA Denial of Service attacks). A GraphQL server can be attacked with overly complex queries that will consume all the resources of the server. It’s very simple to query for deep nested relationships (user -> friends -> friends …), or use field aliases to ask for the same field many times. Resource exhaustion attacks are not specific to GraphQL, but when working with GraphQL we have to be extra careful about them.
+GraphQL更容易的造成一个安全隐患是资源耗尽型攻击(拒绝服务攻击)。GraphQL 服务器可能会受到伴随着极其复杂的查询的攻击,造成服务器资源耗尽。很容易就能构造一个深度嵌套关系链(用户 -> 好友 -> 好友的好友。) 或者多次通过字段别名请求同一字段的查询。资源耗尽型攻击并没有限定 GraphQL,但是在使用 GraphQL 时,我们要特别小心。
-There are some mitigations we can do here. We can do cost analysis on the query in advance and enforce some kind of limits on the amount of data one can consume. We can also implement a time-out to kill requests that take too long to resolve. Also, since GraphQL is just a resolving layer, we can handle the rate limits enforcement at a lower level under GraphQL.
+这儿有一些缓解措施我们可以用上。我们可以进行一些高级查询的开销分析,对单个用户请求的数据量做某种限制。我们也可以实现一种机制对需要很长时间处理的请求进行超时处理。此外,考虑到 GraphQL 就只是一个处理层,我们能在 GraphQL 之下的更底层进行速率限制。
-If the GraphQL API endpoint we’re trying to protect is not public and is meant for internal consumption of our own clients (web or mobile), we can use a whitelist approach and pre-approve queries that the server can execute. Clients can just ask the servers to execute pre-approved queries using a query unique identifier. Facebook seems to be using this approach.
+如果我们尝试保护的 GraphQL API 端点并不是公开的,仅供我们私有的客户端(web、移动)内部访问,我们能够使用白名单策略并预先审核服务器能够处理的查询。客户端仅能通过唯一查询标识码向服务器发起审核过的查询。Facebook 似乎就采用了这种策略。
-Authentication and authorization are other concerns that we need to think about when working with GraphQL. Do we handle them before, after, or during a GraphQL resolve process?
+当使用 GraphQL 时,我们还需要考虑到认证和授权。我们是在 GraphQL 解析请求之前,之后还是之间处理它们呢?
-To answer this question, think of GraphQL as a DSL (domain specific language) on top of your own backend data fetching logic. It’s just one layer that we could put between the clients and our actual data service (or multiple services).
+为了回答这个问题,需要将 GraphQL 想象成你一种位于你的后端数据请求逻辑顶层的 DSL(领域限定语言)。它只是一个能够被我们放在客户端与实际数据服务(多个)之间的处理层。
-Think of authentication and authorization as another layer. GraphQL will not help with the actual implementation of the authentication or authorization logic. It’s not meant for that. But if we want to put these layers behind GraphQL, we can use GraphQL to communicate the access tokens between the clients and the enforcing logic. This is very similar to the way we do authentication and authorization with RESTful APIs.
+将认证和授权当成另一个处理层。GraphQL 与认证和授权逻辑的具体实现关系不大。它的意义不在这儿。但是如果我们把这些层放在 GraphQL 之后,我们就可以在 GraphQL 层使用访问令牌连通客户端与执行逻辑。这和我们在 REST 风格 API 处理认证和授权类似。
-One other task that GraphQL makes a bit more challenging is client data caching. RESTful APIs are easier to cache because of their dictionary nature. This location gives that data. We can use the location itself as the cache key.
+另一件因为 GraphQL 而变得更具挑战性的任务是客户端数据缓存。REST 风格的 API 因其类似目录更容易进行缓存处理。REST API 通过访问路径获取数据,我们能够使用访问路径作缓存键。
-With GraphQL, we can adopt a similar basic approach and use the query text as a key to cache its response. But this approach is limited, not very efficient, and can cause problems with data consistency. The results of multiple GraphQL queries can easily overlap, and this basic caching approach would not account for the overlap.
+对于 GraphQL,我们能够采用类似的策略使用查询字段作为响应数据的缓存键。但是这种方式有限制,效率低下,还容易造成数据一致性方面的问题。原因是多个 GraphQL 查询的结果很容易重叠,而这种缓存策略并没有考虑到这种重叠。
-There is a brilliant solution to this problem though. A Graph Query means a *Graph Cache*. If we normalize a GraphQL query response into a flat collection of records, giving each record a global unique ID, we can cache those records instead of caching the full responses.
+这个问题有一个很好的解决方案。一个图的查询意味这一个**图的缓存**。如果我们将一个 GraphQL 查询的响应数据正则化为一个平铺的记录集合,为每个记录设置一个全局唯一 ID,我们就能够只缓存这些记录而不用缓存整个响应了。
-This is not a simple process though. There will be records referencing other records and we will be managing a cyclic graph there. Populating and reading the cache will need query traversal. We need to code a layer to handle the cache logic. But this method will overall be a lot more efficient than response-based caching. [Relay.js](https://facebook.github.io/relay/) is one framework that adopts this caching strategy and auto-manages it internally.
+这种处理并不容易。这样导致一些记录指向另一些记录,导致我们可能得管理一个环形图,导致在写入和读取缓存时我们需要进行遍历,导致我们需要编写一个层来处理缓存逻辑。但是,这种方法总体上比基于响应的缓存更高效。[Relay.js](https://facebook.github.io/relay/) 就是一个采用这种缓存策略并在内部进行自动管理的框架。
-Possibly the most important problem that we should be concerned about with GraphQL is the problem that’s commonly referred to as N+1 SQL queries. GraphQL query fields are designed to be stand-alone functions and resolving those fields with data from a database might result in a new database request per resolved field.
+对于 GraphQL 我们最需要关心的问题可能是被普遍称作 N+1 SQL 查询的问题了。GraphQL 的字段查询被设计成独立的函数,从数据库获取这些字段可能造成每个字段都需要一个数据库查询。
-For a simple RESTful API endpoint logic, it’s easy to analyze, detect, and solve N+1 issues by enhancing the constructed SQL queries. For GraphQL dynamically resolved fields, it’s not that simple. Luckily Facebook is pioneering one possible solution to this problem: [DataLoader](https://github.com/facebook/dataloader).
+简单 REST 风格 API 端点的逻辑,易分析,易检测,可以优化 SQL 查询语句来解决 N+1 问题。而 GraphQL 需要动态处理字段,这点不容易做到。幸运的是 Facebook 正在研发一个处理类似问题的可能的解决方案:DataLoader。
-As the name implies, DataLoader is a utility one can use to read data from databases and make it available to GraphQL resolver functions. We can use DataLoader instead of reading the data directly from databases with SQL queries, and DataLoader will act as our agent to reduce the actual SQL queries we send to the database.
+如名字暗示,DataLoader 是一款能让我们从数据库读取数据并让数据能被 GraphQL 处理函数使用的工具。我们使用 DataLoader,而不是直接通过 SQL 查询从数据库获取数据,将 DataLoader 作为代理以减少我们实际需要发送给数据库的 SQL 查询。
-DataLoader uses a combination of batching and caching to accomplish that. If the same client request resulted in a need to ask the database about multiple things, DataLoader can be used to consolidate these questions and batch-load their answers from the database. DataLoader will also cache the answers and make them available for subsequent questions about the same resources.
+DataLoader 使用批处理和缓存的组合来实现。如果同一个客户端请求会造成多次请求数据库,DataLoader 会整合这些问题并从数据库批量拉取请求数据。DataLoader 会同时缓存这些数据,当有后续请求需要同样资源时可以直接从缓存获取到。
---
-Thanks for reading. If you found this article helpful, please click the💚 below. Follow me for more articles on Node.js and JavaScript.
-
-I create **online courses** for [Pluralsight](https://app.pluralsight.com/profile/author/samer-buna) and [Lynda](https://www.lynda.com/Samer-Buna/7060467-1.html). My most recent courses are [Advanced React.js](https://www.pluralsight.com/courses/reactjs-advanced), [Advanced Node.js](https://www.pluralsight.com/courses/nodejs-advanced), and [Learning Full-stack JavaScript](https://www.lynda.com/Express-js-tutorials/Learning-Full-Stack-JavaScript-Development-MongoDB-Node-React/533304-2.html).
+谢谢你阅读本文。如果你觉得本文有用,点击下面的连接。关注我以获取更多的关于 Node.js 和 JavaScript 的文章。
-I also do **online and onsite training** for groups covering beginner to advanced levels in JavaScript, Node.js, React.js, and GraphQL. [Drop me a line](mailto:samer@jscomplete.com) if you’re looking for a trainer. If you have any questions about this article or any other article I wrote, find me on [this **slack** account](https://slack.jscomplete.com/) (you can invite yourself) and ask in the #questions room.
+我在 [Pluralsight](https://app.pluralsight.com/profile/author/samer-buna) and [Lynda](https://www.lynda.com/Samer-Buna/7060467-1.html) 上创建了**在线课程**。我最近的课程包含 Advanced React.js](https://www.pluralsight.com/courses/reactjs-advanced), [Advanced Node.js](https://www.pluralsight.com/courses/nodejs-advanced), and [Learning Full-stack JavaScript](https://www.lynda.com/Express-js-tutorials/Learning-Full-Stack-JavaScript-Development-MongoDB-Node-React/533304-2.html)。
+我还在做让 JavaScript、Node.js、React.js 和 GraphQL 初学者进阶到更高级别的线上线下培训。如果您正在寻找教练,[请与我联系](mailto:samer@jscomplete.com)。如果你您对本文以及我写的其它文章有疑问,可以在 『这个**slack**账户』() 找到我并在 #questions 频道提问。
---
diff --git a/TODO/understanding-service-workers.md b/TODO/understanding-service-workers.md
index bb16447edb0..1c8fc6ff4b7 100644
--- a/TODO/understanding-service-workers.md
+++ b/TODO/understanding-service-workers.md
@@ -3,56 +3,57 @@
> * 原文作者:[Adnan Chowdhury](http://blog.88mph.io/author/adnan/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/understanding-service-workers.md](https://github.com/xitu/gold-miner/blob/master/TODO/understanding-service-workers.md)
- > * 译者:
- > * 校对者:
+ > * 译者:[zyziyun](https://github.com/zyziyun)
+ > * 校对者:[undead25](https://github.com/undead25)、[calpa](https://github.com/calpa)
- # Understanding Service Workers
- What are Service Workers? What can they do, and how can make your web app perform better? This article sets out to answer those questions, plus how to implement them using the Ember.js framework.
+# 理解 Service Workers
-## Table of Contents
+ 什么是 Service Workers?他们能够做什么,怎样使你的 web app 表现得更好?本文旨在回答这些问题,以及如何使用 Ember.js 框架来实现他们。
-- [Background](#background)
-- [Registration](#registration)
-- [Install Event](#installevent)
-- [Fetch Event](#fetchevent)
-- [Caching Strategies](#cachingstrategies)
-- [Activate Event](#activateevent)
-- [Sync Event](#syncevent)
-- [When is the Sync Event fired?](#whenisthesynceventfired)
-- [Push Notifications](#pushnotifications)
-- [Notifications](#notifications)
-- [Push messaging](#pushmessaging)
-- [Implementing Using Ember.js](#implementingusingemberjs)
-- [Understanding ember-service-worker Conventions](#understandingemberserviceworkerconventions)
-- [Build your Ember App w/ Service Workers](#buildyouremberappwserviceworkers)
-- [Conclusion](#conclusion)
+## 目录
-## Background
+- [背景](#背景)
+- [注册](#注册)
+- [安装事件](#安装事件)
+- [Fetch 事件](#Fetch事件)
+- [缓存策略](#缓存策略)
+- [激活事件](#激活事件)
+- [同步事件](#同步事件)
+- [什么时候同步事件被触发?](#什么时候同步事件被触发?)
+- [通知推送](#通知推送)
+- [通知](#通知)
+- [消息推送](#消息推送)
+- [使用 Ember.js 实现](#使用Ember.js实现)
+- [了解 ember-service-worker 的约定](#了解ember-service-worker的约定)
+- [构建基于 Ember 和 Service-Workers 的App](#构建基于Ember和Service-Workers的App)
+- [结论](#结论)
-In a time when the web was young, there was scarcely any thought given to how a web page should behave when a user was offline. You were just *always* online.
+## 背景
+
+在互联网早期时代,几乎没人会考虑用户处于离线状态时该如何呈现一个 web 页面,只会考虑在线状态。

-Connected! The gang's all here! Don't ever leave.
+连接上了!这帮家伙在这里!永远别想离开。
-But with the advent of mobile internet, and with the rest of the world catching up, spotty internet connections have become increasingly commonplace across users of the modern web.
+但是,随着移动互联网的到来以及网络在世界其他地区的普及,参差不齐的网络质量在用户使用的现代网络中已经越来越普遍。
-Consequently, it has become valuable for websites to take ownership of how they behave offline so that users are not limited by network availability.
+因此,网站在离线状态时候的表现,以便用户不受网络可用性的限制,已变得非常有价值。
-[AppCache](https://developer.mozilla.org/en-US/docs/Web/HTML/Using_the_application_cache) was initially introduced as part of the HTML5 spec as a solution for offline web applications. It consisted of a combination of HTML and JS that centered around a *cache manifest*, a configuration file written in a declarative language.
+[AppCache](https://developer.mozilla.org/en-US/docs/Web/HTML/Using_the_application_cache) 最初是作为 HTML5 规范的一部分引入,用以解决离线 web 应用程序的问题。它包含以 **Cache Manifest** 配置文件为中心的HTML和JS的组合,配置文件以声明式语言来编写。
-AppCache was eventually found to be [unwieldy and full of gotchas](https://alistapart.com/article/application-cache-is-a-douchebag). It has since been deprecated and effectively replaced by Service Workers.
+AppCache 最终被发现是 [不实用的和充满陷阱的](https://alistapart.com/article/application-cache-is-a-douchebag)。因此它已被废弃,被 Service Workers 有效的取代。
-[Service workers](https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API) provide a more future-proof solution to the offline problem, by replacing AppCache's declarative style of implementation with a more imperative, procedural one.
+[Service workers](https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API) 提供了一个更具前瞻性的离线应用解决方案,通过更加程序化的语言书写规则替代 AppCache 的声明式书写方式。
-Service Workers are a way to execute code in a persistent, background process contained in the web browser. The code is event-driven, meaning the events that fire in the scope of a Service Worker are what drives its behavior.
+Service Workers 在浏览器后台进程中持续的执行其代码。它是事件驱动的,这意味着在 Service Worker 的作用域范围内触发的事件会驱动其行为。
-The rest of this article is a brief explanation for each of those events. But to begin utilizing Service Workers, you will first need to implement code in your front-facing web app that registers the Service Worker.
+这篇文章剩下的部分将对 Service Worker 的每个事件阶段做个简要的说明,但是在开始使用 Service Workers 之前,你首先需要在你的 web app 中执行代码来注册 Service Worker 。
-## Registration
+## 注册
-The code below illustrates how to **register** your Service Worker in the client's browser. This is accomplished by having the following `register` call executed somewhere on your front-facing web app:
+下面的代码说明了怎样在你的客户端浏览器中注册你的 Service Worker,这是通过在你的 web app 前端代码的某一处执行 `register` 方法调用来实现的:
```
if (navigator.serviceWorker) {
@@ -66,28 +67,27 @@ if (navigator.serviceWorker) {
}
```
-This will tell the browser where to find your Service Worker implementation. The browser will look for the file (`/sw.js`) and save it as a Service Worker under the domain that is being accessed. This file will contain all of the event handlers that will define your Service Worker.
+这将告诉浏览器在哪里找到你的 Service Worker 的实现,浏览器将查找对应的(`/sw.js`)文件,并将它保存在你正在访问的域名下,这个文件将包含所有你自己定义的 Service Worker 事件处理程序。

-A registered Service Worker in Chrome DevTools
+在 Chrome 开发者工具中查看已注册的 Service Worker
-It will also set the **scope** of your ServiceWorker. The filename `/sw.js` implies that the scope of the SW is the root path of your URL (or `http://localhost:3000/`). This means any requests that are made under the root path of your URL will be made visible to the SW via fired events. A filename such as `/js/sw.js` would capture requests only under `http://localhost:3000/js`.
+它也将设置你的 Service Worker 的**作用域**,这个 `/sw.js` 文件意味着 Service Worker 的作用范围是在你 URL(这里是指`http://localhost:3000/`) 的根路径下。这意味着在你的根路径下的任何请求,都将通过触发事件的方式告诉 Service Worker。一个文件路径为`/js/sw.js`的文件就仅仅可以捕获`http://localhost:3000/js`该链接下的请求。
-Alternatively, you could explicitly set the scope of your SW by passing a second argument to the `register` method:
-`navigator.serviceWorker.register('/sw.js', { scope: '/js' })`.
+另外,你也可以通过将第二个参数传入给 `register` 方法来明确地设置 Service Worker 的作用域范围:`navigator.serviceWorker.register('/sw.js', { scope: '/js' })`。
-## Event Handlers
+## 事件处理程序
-Now that your Service Worker is registered, it's time to implement the event handlers that are triggered during the lifetime of your Service Worker.
+现在你的 Service Worker 已经被注册好了,是时候在你的 Service Worker 生命周期中触发实现对应的事件处理程序了。
-#### Install Event
+#### 安装事件
-The install event is fired when your Service Worker registers for the first time, and any time after that when your Service Worker file (`/sw.js`) is updated (the browser will automatically detect changes).
+当你的 Service Worker 首次注册的时,或者你的 Service Worker 文件(`/sw.js`)在之后的任何时间被更新时(浏览器会自动检测这些更改),install 事件都将被触发。
-The install event is useful for logic you want to execute during the initialization of your Service Worker, i.e. a one-off operation that sets things up for the life of your Service Worker. A common use case is to load the cache during the install step.
+对于那些你想在你的 Service Worker 初始化时执行的逻辑,install 事件是非常有用的,它可以执行一些一次性的操作,贯穿在整个 Service Worker 应用程序的生命周期中。一个常见的例子是在 install 阶段加载缓存。
-Here is an example of an install event handler that will add data to the cache.
+下面是一个在 install 事件处理程序阶段向缓存添加数据的例子。
```
const CACHE_NAME = 'cache-v1';
@@ -106,21 +106,21 @@ self.addEventListener('install', event => {
});
```
-`urlsToCache` contains a list of URLs we want to add to the cache.
+`urlsToCache` 包含了一组我们想要添加到缓存的 URL。
-`caches` is a global [CacheStorage](https://developer.mozilla.org/en-US/docs/Web/API/CacheStorage) object that allows you to manage your caches in the browser. We call `open` to retrieve the specific [Cache](https://developer.mozilla.org/en-US/docs/Web/API/Cache) object we want to work with.
+`caches` 是一个全局的 [CacheStorage](https://developer.mozilla.org/en-US/docs/Web/API/CacheStorage) 对象,允许你在浏览器中管理你的缓存。我们将调用 `open` 方法来检索具体我们想要使用的 [Cache](https://developer.mozilla.org/en-US/docs/Web/API/Cache) 对象。
-`cache.addAll` will take a list of URLs, make a request to each, and then store the response in its cache. It uses the request body as a key for each cache value. Read more at the [addAll](https://developer.mozilla.org/en-US/docs/Web/API/Cache/addAll) docs.
+`cache.addAll` 将收到一组 URL,并向每个 URL 发起一个请求,然后将响应存储在其缓存中。它使用请求体作为每个缓存值的键名。了解更多请参阅 [addAll](https://developer.mozilla.org/en-US/docs/Web/API/Cache/addAll)。

-Cached data in Chrome DevTools
+在 Chrome 开发者工具中查看缓存数据
-#### Fetch event
+#### Fetch事件
-The **fetch** event is fired every time the web page makes a request. When it fires, your Service Worker has the ability to 'intercept' the request and decide what to return - whether that be cached data, or the response to an actual network request.
+**Fetch** 事件是在每次网页发出请求的时候触发的,触发该事件的时候 Service Worker 能够 '拦截' 请求,并决定返回内容 ———— 是返回缓存的数据,还是返回真实请求响应的数据。
-The following example illustrates a *cache-first* strategy: any cached data that matches the request will be sent off first, without a network request. Only if there is no existing cached data will a network request be made.
+下面的例子说明了**缓存优先**的策略:与请求匹配的任何缓存数据都将优先被返回,而不需要发送网络请求。只有当没有现有的缓存数据时才会发出网络请求。
```
self.addEventListener('fetch', event => {
@@ -139,21 +139,21 @@ self.addEventListener('fetch', event => {
});
```
-`request` contains the request body that is included in the [FetchEvent](https://developer.mozilla.org/en-US/docs/Web/API/FetchEvent) object. It is used to lookup a matching response in the cache.
+`request` 属性包含在 [FetchEvent](https://developer.mozilla.org/en-US/docs/Web/API/FetchEvent) 对象里,它用于查找匹配请求的缓存。
-`cache.match` will try to find a cached response that matches the specified request. If it finds nothing, the promise will resolve with `undefined`. We check for this, and make a `fetch` call in this case, which makes a network request and returns a promise.
+`cache.match` 将尝试找到一个与指定请求匹配的缓存响应。如果没有找到对应的缓存,则 promise 会 resolve 一个 `undefined` 值。在这个例子里,我们通过判断这个值来决定是返回这个值,还是调用 fetch 发起一个网络请求并返回一个 promise。
-`event.respondWith` is a method specifically on a FetchEvent object that we use to send a response back to the browser for the request. It accepts a Promise that resolves to a response (or network error).
+`event.respondWith` 是一个 FetchEvent 对象中的特殊方法,用于将请求的响应发送回浏览器。它接收一个对响应(或网络错误)resolve 后的 Promise 对象作为参数。
-###### Caching Strategies
+###### 缓存策略
-The fetch event is particularly important because it's where you can define your *caching strategy*. That is, how you determine when to use cached data, and when to use network-sourced data.
+Fetch 事件特别重要,因为它能够定义你的缓存策略。也就是说,你可以决定何时使用缓存数据,何时使用网络请求来的数据。
-The beauty in Service Workers is that it is a low-level API for intercepting requests and lets you decide what response to provide for them. This allows us the freedom to implement our own strategy for providing cached or network-sourced content. There are several basic caching strategies that you could employ when trying to implement the best one for your web app.
+Service Worker 的好用之处在于它是一个用于拦截请求的低层 API,并允许你决定为其提供哪些响应。这允许我们自由的提供我们自己的缓存策略或者网络来源的内容。当你尝试实现一个最好的 Web App 的时候,有几种基本的缓存策略可以使用。
-Mozilla has a [handy resource](https://serviceworke.rs/caching-strategies.html) that documents several different caching strategies. There is also [The Offline Cookbook](https://developers.google.com/web/fundamentals/instant-and-offline/offline-cookbook) written by Jake Archibald that outlines some of the same caching strategies, and more.
+Mozilla 基金会有一个 [handy resource](https://serviceworke.rs/caching-strategies.html) 的文档,其中有写几种不同的缓存策略。还有 Jake Archibald 编写的 [The Offline Cookbook](https://developers.google.com/web/fundamentals/instant-and-offline/offline-cookbook) 书中有概述几种相似的缓存策略等等。
-In an above example, we demonstrated a basic **cache-first** strategy. The following is an example which I've found applicable in my own projects: a **cache and update** strategy. This method will let the cache respond first, but subsequently make a network request in the background. The response from this background request is used to update the value in the cache so that an updated response is provided the next time it is accessed.
+在上文的一个例子中,我们演示了一个基本的**缓存优先**的策略。以下是我发现的一个适用于我自己项目的示例:**缓存和更新**策略。这个方法首先让缓存响应,随后在后台发起对应的网络请求。来自后台请求的响应用于更新缓存中的数据,以便在下次访问时提供更新后的响应。
```
self.addEventListener('fetch', event => {
@@ -169,27 +169,27 @@ self.addEventListener('fetch', event => {
});
```
-`event.respondWith` is used to provide a response to the request. Here we are opening the cache and finding a matching response. If it doesn't exist, we reach out to the network.
+`event.respondWith` 用于提供对请求的响应。这里我们打开缓存找到匹配的响应,如果它不存在,我们会走网络请求。
-Subsequently, we call `event.waitUntil` to allow the async Promise to resolve before the Service Worker context is terminated. Here we make a network request, and then cache the response. Once this asynchronous operation is finished, `waitUntil` will resolve and the operation will terminate.
+随后,我们将调用 `event.waitUntil` 方法以允许在 Service Worker 上下文终止之前 resolve 一个异步Promise。这里会走一个网络请求,然后缓存其响应。一旦这个异步操作完成,`waitUntil` 将会 resolve,操作将会终止。
-#### Activate Event
+#### 激活事件
-The activate event is a slightly less documented event, but is important for when you are updating your Service Worker file and need to execute any clean up or maintenance from the previous version of your Service worker.
+激活事件是一个较少记录的事件,但当你需要更新 Service Worker 文件,执行清理或者维护之前版本的 Service Worker 的时候,它是非常重要的。
-When you update your Service Worker file (`/sw.js`), the browser will detect changes and display this in Chrome DevTools:
+当你更新你的 Service Worker 文件(`/sw.js`)的时候,浏览器会检测到这些改变,它们在 Chrome 开发者工具中的展示如下图所示:

-Your new Service Worker is 'waiting to activate'.
+你的新 Service Worker 正在“等待激活”。
-When the actual web page is closed, and re-opened again, the browser will replace the old Service Worker with the new one, and fire the **activate** event, after the **install** event. If you needed to clean up the caches or perform maintenance regarding the old version of your Service Worker, the activate event allows you the perfect time to do this.
+当实际网页关闭并重新打开的时候,浏览器将使用新的 Service Worker 替换旧的 Service Worker,然后在 **install** 事件触发之后,触发 **activate** 事件,如果你需要清理缓存或者对旧版本的 Service Worker 进行维护,激活事件可以让你完美的做到这一点。
-#### Sync event
+#### 同步事件
-The sync event allows the deferring of network tasks until the user has connectivity. The feature it implements is commonly referred to as **background sync**. This is useful for ensuring that any network-dependent tasks that a user kicks off during offline mode will eventually reach their intended destination when the network is available again.
+Sync 事件允许延迟网络任务,直到用户连接上网络,它实现的功能通常被称为**后台同步**。这对于在离线模式下,确保用户启动的任何有网络依赖的任务,最终都将在网络再次可用时达到其预期目的,是非常有用的。
-Here is an example of what a background sync implementation would look like. You'll need code in your front-facing JS that registers a sync event, accompanied by a sync event handler in your Service Worker:
+下面是一个后台同步实现的例子。你需要在前端 JavaScript 中注册一个 sync 事件,并在 Service Worker 中附带 sync 事件处理程序。
```
// app.js
@@ -203,11 +203,11 @@ navigator.serviceWorker.ready
});
```
-Here we are assigning a click event to a button that will call `sync.register` on the [ServiceWorkerRegistration](https://developer.mozilla.org/en-US/docs/Web/API/ServiceWorkerRegistration) object.
+在这里,我们分配一个 click 事件给 button 元素,它将调用 [ServiceWorkerRegistration](https://developer.mozilla.org/en-US/docs/Web/API/ServiceWorkerRegistration) 对象上的 `sync.register` 方法。
-Basically, any operation that you want to ensure reaches the network either immediately or eventually when the network comes online, needs to be registered as a sync event.
+基本上,要确保任何操作都可以立即或最终在网络可用时到达网络,都需要被注册为 sync 事件。
-This could be something like POSTing a comment, or fetching user data, which will be defined in the Service Worker's event handler:
+在 Service Worker 的事件处理程序中,可能的操作像是发送一个评论,或者获取用户数据等等。
```
// sw.js
@@ -218,33 +218,33 @@ self.addEventListener('sync', event => {
});
```
-Here we are listening for a sync event, and checking for the `tag` on the [SyncEvent](https://developer.mozilla.org/en-US/docs/Web/API/SyncEvent) object to see if it matches the `'submit'` tag we specified for the click event.
+这里我们监听一个 sync 事件,并检查 [SyncEvent](https://developer.mozilla.org/en-US/docs/Web/API/SyncEvent) 对象上的 `tag` 属性属性是否匹配我们指定给 click 事件的`'submit'`标签。
-If multiple sync's under the `'submit'` tag are registered, the sync event handler will only execute once.
+如果对应 `'submit'` 标签下的多个 sync 事件信息被注册,sync 事件处理程序将只执行一次。
-So for this example, if the user were offline, and clicked the button seven times, when the network returned, all sync registrations would consolidate and the sync event would fire just once.
+因此,在这个例子中,如果用户离线,并点击了七次按钮,那么当网络恢复时,所有同步的注册事件将被合并且只触发一次。
-In the case you would want separate syncs for each click event, you would register syncs under unique tags.
+在这种情况下,如果你想拆分同步事件给每一次点击,你可以注册多个具有唯一标记的同步事件。
-###### When is the Sync Event fired?
+###### 什么时候同步事件被触发?
-If the user is online, then the sync event will fire immediately and accomplish whatever task you've defined without delay.
+如果用户在线,则同步事件将会立即触发,并完成你定义的任何任务,而不会延时。
-If the user is offline, the sync event will fire as soon as network connectivity is regained.
+如果用户离线,则一旦重新获得网络连接,同步事件就会触发。
-If you're like me, and want to try this out in Chrome, be sure to actually disconnect your internet by disabling your Wi-Fi or otherwise network adapter. Toggling the Network checkbox in Chrome DevTools will not trigger sync events.
+如果你像我一样,想在 Chrome 中尝试一下,一定要通过禁用 Wi-Fi 或者其他网络适配器来断开互联网连接。而在 Chrome 开发者工具中切换网络复选框不会触发 sync 事件。
-For more information, you can read [this explainer document](https://github.com/WICG/BackgroundSync/blob/master/explainer.md), as well as this [introduction to background syncs](https://developers.google.com/web/updates/2015/12/background-sync). The sync event is largely unimplemented across browsers (only in Chrome at the time of this writing), and is bound to undergo changes, so stay tuned.
+想了解更多的信息,你可以阅读文档 [this explainer document](https://github.com/WICG/BackgroundSync/blob/master/explainer.md) ,还有这篇文档 [introduction to background syncs](https://developers.google.com/web/updates/2015/12/background-sync) 。sync 事件现在在大部分浏览器当中并没有实现(撰写本文时,只能在 Chrome 中使用),但势必在将来会发生变化,敬请期待。
-#### Push Notifications
+#### 通知推送
-Push notifications are a feature that are enabled by Service Workers by exposing the `push` event to Service Workers, as well as the [Push API](https://developer.mozilla.org/en-US/docs/Web/API/Push_API) implemented by the browser.
+通知推送是 Service Workers 通过曝露其 `push` 以及浏览器实现的 [Push API](https://developer.mozilla.org/en-US/docs/Web/API/Push_API) 来启用的功能。
-When speaking about Web Push Notifications, there are actually two technologies at work: Notifications & Push Messaging.
+当我们讨论网络推送通知的时候,实际上会涉及两种对应的技术:通知和推送信息。
-###### Notifications
+###### 通知
-Notifications are pretty straightforward feature to implement with Service Workers:
+通知是可以通过 Service Workers 实现的非常简单的功能:
```
// app.js
@@ -275,27 +275,27 @@ self.addEventListener('notificationclose', event => {
});
```
-You first need to ask permission from the user to enable notifications for your web page. From then on, you are able to toggle on notifications, and handle certain events, such as when a notification is closed by the user.
+你首先需要向用户发出许可才能启用网页的通知。从那时起,你可以切换通知,并处理某些事件,例如用户关闭一个通知的时候。
-###### Push Messaging
+###### 消息推送
-Push messaging involves utilizing the Push API provided by the browser, coupled with backend implementation. An entirely separate article could be written on the implementation of Push API, but the basic gist is:
+推送消息涉及利用浏览器提供的 Push API 以及后端实现。这个要点可以单独抽出一篇文章详细讲解,但是其基本要点如下图所示:

-It is an involved and slightly complicated process, and is outside the scope of this article. But if you'd like to learn more, this [introduction to push notifications](https://developers.google.com/web/ilt/pwa/introduction-to-push-notifications) is an informative read.
+这是一个稍微复杂的过程,超出了本文的范围。但如果你想了解更多,可以参考 [introduction to push notifications](https://developers.google.com/web/ilt/pwa/introduction-to-push-notifications) 这篇文章 。
-## Implementing Using Ember.js
+## 使用Ember.js实现
-Implementing Service Workers for your Ember app is incredibly easy. By virtue of [ember-cli](https://ember-cli.com/) and the [Ember Add-ons](https://www.emberaddons.com) community, you can equip your web app with Service Workers in plug-and-play fashion.
+用 Ember.js 实现 Service Workers 的 APP 是非常容易的,凭借其脚手架工具 [ember-cli](https://ember-cli.com/) 和其插件体系 [Ember Add-ons](https://www.emberaddons.com) 社区的支持,你可以以一种即插即拔的方式在你的 Web App 中增加 Service Worker。
-This is made possible in part by the [ember-service-worker](https://github.com/DockYard/ember-service-worker) add-on, provided by the folks at DockYard (docs [here](http://ember-service-worker.com/documentation/getting-started/)).
+这是由 DockYard 的人员提供的一系列插件 [ember-service-worker](https://github.com/DockYard/ember-service-worker) 及其对应文档 [here](http://ember-service-worker.com/documentation/getting-started/)。
-**ember-service-worker** sets up a modular architecture that can be used to plug in other ember-service-worker-* add-ons, such as [ember-service-worker-index](https://github.com/DockYard/ember-service-worker-index) or [ember-service-worker-asset-cache](https://github.com/DockYard/ember-service-worker-asset-cache). These add-ons implement different parts of behavior and caching strategies to make up your Service Worker.
+**ember-service-worker** 建立了一个模块化的结构,可以被用于插入其他 ember-service-worker-* 的插件,例如 [ember-service-worker-index](https://github.com/DockYard/ember-service-worker-index) 或者 [ember-service-worker-asset-cache](https://github.com/DockYard/ember-service-worker-asset-cache)。这些插件使用不同的表现实现对应行为,以及不同的缓存策略组成你的 Service Worker 服务。
-#### Understanding `ember-service-worker` conventions
+#### 了解`ember-service-worker`的约定
-All of the **ember-service-worker-*** add-ons follow a convention, in that their core logic is stored in one of two folders in the root directory of the add-on, `/service-worker` and `/service-worker-registration`:
+所有的 **ember-service-worker-** 插件都遵循相同的模块结构,它们的核心逻辑存储在其根目录的`/service-worker` and `/service-worker-registration` 这两个文件夹中。
node_modules/ember-service-worker
├── ...
@@ -306,11 +306,11 @@ All of the **ember-service-worker-*** add-ons follow a convention, in that their
└── index.js
-`/service-worker` is where the main implementation of your Service Worker is located (what you would store in `sw.js` as shown earlier).
+`/service-worker` 该目录是实现 Service Worker 的主要存储位置(如文章前面所说的那个 `sw.js` 就是存储在这个目录下)。
-`/service-worker-registration` holds the logic you need to run in your front-facing code, where Service Worker registration would take place.
+`/service-worker-registration` 该目录下有你需要在前端代码中运行的逻辑,像 Service Worker 的注册流程。
-Let's take a look at the `/service-worker` implementation for **ember-service-worker-index** (code [here](https://github.com/DockYard/ember-service-worker-index/blob/master/service-worker/index.js)) to divulge what it actually does:
+让我们看看 **ember-service-worker-index** 该插件的 `/service-worker` 目录下的代码实现 (code [here](https://github.com/DockYard/ember-service-worker-index/blob/master/service-worker/index.js)) ,符合上面所说的内容。
```
import {
@@ -356,25 +356,25 @@ self.addEventListener('fetch', (event) => {
});
```
-Without getting bogged down in the details, we can see that this code is basically implementing three of the event handlers we've talked about: `install`, `activate` and `fetch`.
+不去看具体的细节,我们可以看到,这个代码基本实现了我们之前讨论过的三个事件处理程序:`install`, `activate` and `fetch`。
-In the `install` event handler, we are fetching `INDEX_HTML_URL`, and then calling `cache.put` to store the response.
+在 `install` 事件处理程序中,我们调用 `INDEX_HTML_URL`对应的接口,获取数据,然后调用 `cache.put` 存储响应数据。
-`activate` does some rudimentary clean up.
+`activate` 阶段做了一些基本的清理缓存的操作。
-In the `fetch` handler, we are checking to see if `request` meets several conditions (is it a `GET` request; is it asking for HTML; is it local; etc.) and if it satisfies those conditions, we respond with what is stored in the cache.
+在 `fetch` 事件处理程序中,我们检查 `request` 是否满足几个条件(是否是 `GET` 请求,是否请求 HTML,是否是本地资源等等),只有满足一系列的条件,我们才把对应的数据缓存返回。
-Notice we're calling `cache.match` and using `INDEX_HTML_URL` to look up the value, and not `request.url`. This means we'd always look up the same cache key, no matter what the actual URL is.
+注意我们调用 `cache.match`方法 和 `INDEX_HTML_URL` 地址,来查找值,而不使用 `request.url`请求的 url。这意味着无论实际调用的 URL 请求是什么,我们始终会根据相同的缓存密钥做对应的查找操作。
-This is because an Ember app will always render using `index.html`. Any URL requests that are under the root URL of the app will end up with a cached version of `index.html`, where the Ember app would normally take over. That is the purpose of **ember-service-worker-index** - to cache `index.html`.
+这是因为 Ember 的应用程序将始终使用 `index.html` 进行页面渲染。在应用程序的根路径下的任何 URL 请求都将以 `index.html` 的缓存版本结尾,Ember 应用程序通常会接管。这就是 **ember-service-worker-index** 来缓存`index.html`的目的。
-Similarly, [**ember-service-worker-asset-cache**](https://github.com/DockYard/ember-service-worker-asset-cache) will cache all the assets found in the `/assets` folder by implementing its own `install` and `fetch` event handlers.
+同样的,[**ember-service-worker-asset-cache**](https://github.com/DockYard/ember-service-worker-asset-cache) 该插件将缓存所有在 `/assets` 目录下可以找到的所有资源,文件,触发调用其 `install`和 `fetch` 事件处理函数。
-There are [several add-ons](https://www.emberaddons.com/?query=service-worker) that employ **ember-service-worker** architecture and allow you to customize and fine tune your Service Worker's behavior and caching strategies.
+有几个插件 [several add-ons](https://www.emberaddons.com/?query=service-worker) 也使用 **ember-service-worker** 该插件的结构,允许你自定义和微调对应的 Service Worker 的表现和缓存策略。
-#### Build your Ember App w/ Service Workers
+#### 构建基于Ember和Service-Workers的App
-First, you'll need [ember-cli](https://ember-cli.com/) installed. Then execute the following commands:
+首先,你需要下载 [ember-cli](https://ember-cli.com/),然后在命令行中执行下面的语句操作:
```
$ ember new new-app
@@ -385,26 +385,26 @@ $ ember install ember-service-worker-asset-cache
```
-Your app is now serviced by Service Workers and by default will have `index.html` and `/assets/**/*` cached.
+你的应用程序现在由 Service Workers 提供缓存服务,默认情况下,会将 `index.html`文件和 `/assets/**/*` 该目录下的内容缓存。
-You can fine tune what files under the `/assets` folder will get cached via `config/environment.js`.
+你可以通过修改 `config/environment.js` 这个配置文件调整 `/assets` 文件夹下哪些文件将被缓存。
-If you find that none of the existing ember-service-worker add-ons solve your problem, you can create your own following the [docs at the ember-service-worker website](http://ember-service-worker.com/documentation/authoring-plugins/).
+如果你发现现有的 ember-service-worker 插件没有解决你的问题,你可以参照这个文档 [docs at the ember-service-worker website](http://ember-service-worker.com/documentation/authoring-plugins/) 创建你自己的插件。
-## Conclusion
+## 结论
-I hope you have gained a firmer understanding of Service Workers, and their underlying architecture, and also how web apps can utilize them to create a better experience for users.
+我希望你能够对 Service Workers 和其底层架构有一个更深入理解,以及怎样利用他们创建用户体验更好的Web App。
-`ember-service-worker` add-ons allow you implement them easily in your Ember.js web app. If you find that you need to implement your own logic for a Service Worker, it should be easy to create your own add-on that implements the event handlers you need to implement the behavior you want. This is something I'd like to tackle in the near future, so stay tuned!
+`ember-service-worker` 插件让你能在你的 Ember.js 应用程序中很容易地实现他们。如果你发现需要实现一个自己的 Service Worker 的逻辑,你可以很容易的创建自己的插件,来实现你需要的行为所对应的事件处理程序,这是我想在不久的将来解决的问题,敬请关注!
-#### From our Sponsors
+#### 来自我们的赞助商

-*If you are interested in working with Ember.js full-time, [Quartzy](https://www.quartzy.com/) is hiring frontend devs! We help scientists around the world by helping them save money and be more efficient in the lab. Apply [here](http://grnh.se/coe8yp1).*
+**如果你对基于 Ember.js 的全职工作感兴趣,[Quartzy](https://www.quartzy.com/) 正在招聘前端工程师!我们帮助世界各地的科学家节省资金,使得他们更有效率的在实验室研究。[点击这里](http://grnh.se/coe8yp1)申请吧。**
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
-
\ No newline at end of file
+