| title | category | tag | |
|---|---|---|---|
Java 20 新特性概览 |
Java |
|
JDK 20 于 2023 年 3 月 21 日发布,非长期支持版本。
根据开发计划,下一个 LTS 版本就是将于 2023 年 9 月发布的 JDK 21。

JDK 20 只有 7 个新特性:
- JEP 429:Scoped Values(作用域值)(第一次孵化)
- JEP 432:Record Patterns(记录模式)(第二次预览)
- JEP 433:switch 模式匹配(第四次预览)
- JEP 434: Foreign Function & Memory API(外部函数和内存 API)(第二次预览)
- JEP 436: Virtual Threads(虚拟线程)(第二次预览)
- JEP 437:Structured Concurrency(结构化并发)(第二次孵化)
- JEP 432:向量 API(第五次孵化)
作用域值(Scoped Values)它可以在线程内和线程间共享不可变的数据,优于线程局部变量,尤其是在使用大量虚拟线程时。
final static ScopedValue<...> V = new ScopedValue<>();
// In some method
ScopedValue.where(V, <value>)
.run(() -> { ... V.get() ... call methods ... });
// In a method called directly or indirectly from the lambda expression
... V.get() ...作用域值允许在大型程序中的组件之间安全有效地共享数据,而无需求助于方法参数。
关于作用域值的详细介绍,推荐阅读作用域值常见问题解答这篇文章。
记录模式(Record Patterns) 可对 record 的值进行解构,也就是更方便地从记录类(Record Class)中提取数据。并且,还可以嵌套记录模式和类型模式结合使用,以实现强大的、声明性的和可组合的数据导航和处理形式。
记录模式不能单独使用,而是要与 instanceof 或 switch 模式匹配一同使用。
先以 instanceof 为例简单演示一下。
简单定义一个记录类:
record Shape(String type, long unit){}没有记录模式之前:
Shape circle = new Shape("Circle", 10);
if (circle instanceof Shape shape) {
System.out.println("Area of " + shape.type() + " is : " + Math.PI * Math.pow(shape.unit(), 2));
}有了记录模式之后:
Shape circle = new Shape("Circle", 10);
if (circle instanceof Shape(String type, long unit)) {
System.out.println("Area of " + type + " is : " + Math.PI * Math.pow(unit, 2));
}再看看记录模式与 switch 的配合使用。
定义一些类:
interface Shape {}
record Circle(double radius) implements Shape { }
record Square(double side) implements Shape { }
record Rectangle(double length, double width) implements Shape { }没有记录模式之前:
Shape shape = new Circle(10);
switch (shape) {
case Circle c:
System.out.println("The shape is Circle with area: " + Math.PI * c.radius() * c.radius());
break;
case Square s:
System.out.println("The shape is Square with area: " + s.side() * s.side());
break;
case Rectangle r:
System.out.println("The shape is Rectangle with area: + " + r.length() * r.width());
break;
default:
System.out.println("Unknown Shape");
break;
}有了记录模式之后:
Shape shape = new Circle(10);
switch(shape) {
case Circle(double radius):
System.out.println("The shape is Circle with area: " + Math.PI * radius * radius);
break;
case Square(double side):
System.out.println("The shape is Square with area: " + side * side);
break;
case Rectangle(double length, double width):
System.out.println("The shape is Rectangle with area: + " + length * width);
break;
default:
System.out.println("Unknown Shape");
break;
}记录模式可以避免不必要的转换,使得代码更建简洁易读。而且,用了记录模式后不必再担心 null 或者 NullPointerException,代码更安全可靠。
记录模式在 Java 19 进行了第一次预览, 由 JEP 405 提出。JDK 20 中是第二次预览,由 JEP 432 提出。这次的改进包括:
- 添加对通用记录模式类型参数推断的支持,
- 添加对记录模式的支持以出现在增强语句的标题中
for - 删除对命名记录模式的支持。
注意:不要把记录模式和 JDK16 正式引入的记录类搞混了。
正如 instanceof 一样, switch 也紧跟着增加了类型匹配自动转换功能。
instanceof 代码示例:
// Old code
if (o instanceof String) {
String s = (String)o;
... use s ...
}
// New code
if (o instanceof String s) {
... use s ...
}switch 代码示例:
// Old code
static String formatter(Object o) {
String formatted = "unknown";
if (o instanceof Integer i) {
formatted = String.format("int %d", i);
} else if (o instanceof Long l) {
formatted = String.format("long %d", l);
} else if (o instanceof Double d) {
formatted = String.format("double %f", d);
} else if (o instanceof String s) {
formatted = String.format("String %s", s);
}
return formatted;
}
// New code
static String formatterPatternSwitch(Object o) {
return switch (o) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> o.toString();
};
}switch 模式匹配分别在 Java17、Java18、Java19 中进行了预览,Java20 是第四次预览了。每一次的预览基本都会有一些小改进,这里就不细提了。
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 JEP 412 提出。Java 18 中进行了第二次孵化,由JEP 419 提出。Java 19 中是第一次预览,由 JEP 424 提出。
JDK 20 中是第二次预览,由 JEP 434 提出,这次的改进包括:
MemorySegment和MemoryAddress抽象的统一- 增强的
MemoryLayout层次结构 MemorySession拆分为Arena和SegmentScope,以促进跨维护边界的段共享。
在 Java 19 新特性概览 中,我有详细介绍到外部函数和内存 API,这里就不再做额外的介绍了。
虚拟线程(Virtual Thread)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),由 JVM 调度。许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。
在引入虚拟线程之前,java.lang.Thread 包已经支持所谓的平台线程,也就是没有虚拟线程之前,我们一直使用的线程。JVM 调度程序通过平台线程(载体线程)来管理虚拟线程,一个平台线程可以在不同的时间执行不同的虚拟线程(多个虚拟线程挂载在一个平台线程上),当虚拟线程被阻塞或等待时,平台线程可以切换到执行另一个虚拟线程。
虚拟线程、平台线程和系统内核线程的关系图如下所示(图源:How to Use Java 19 Virtual Threads):
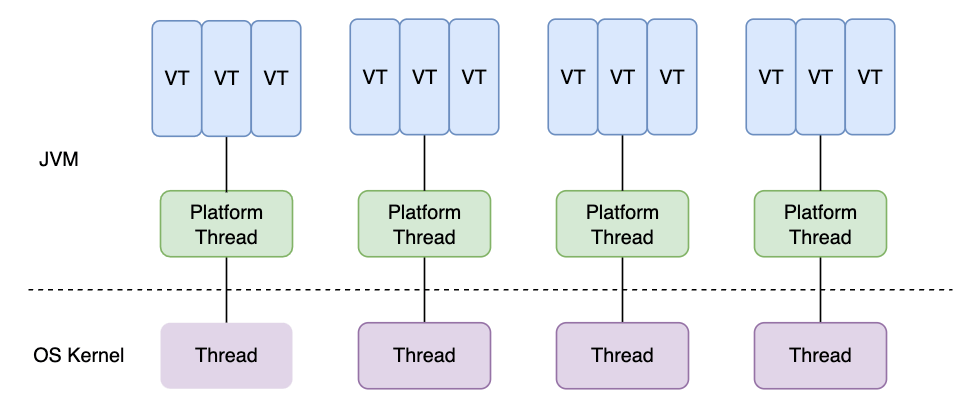
关于平台线程和系统内核线程的对应关系多提一点:在 Windows 和 Linux 等主流操作系统中,Java 线程采用的是一对一的线程模型,也就是一个平台线程对应一个系统内核线程。Solaris 系统是一个特例,HotSpot VM 在 Solaris 上支持多对多和一对一。具体可以参考 R 大的回答: JVM 中的线程模型是用户级的么?。
相比较于平台线程来说,虚拟线程是廉价且轻量级的,使用完后立即被销毁,因此它们不需要被重用或池化,每个任务可以有自己专属的虚拟线程来运行。虚拟线程暂停和恢复来实现线程之间的切换,避免了上下文切换的额外耗费,兼顾了多线程的优点,简化了高并发程序的复杂,可以有效减少编写、维护和观察高吞吐量并发应用程序的工作量。
虚拟线程在其他多线程语言中已经被证实是十分有用的,比如 Go 中的 Goroutine、Erlang 中的进程。
知乎有一个关于 Java 19 虚拟线程的讨论,感兴趣的可以去看看:https://www.zhihu.com/question/536743167 。
Java 虚拟线程的详细解读和原理可以看下面这两篇文章:
虚拟线程在 Java 19 中进行了第一次预览,由JEP 425提出。JDK 20 中是第二次预览,做了一些细微变化,这里就不细提了。
最后,我们来看一下四种创建虚拟线程的方法:
// 1、通过 Thread.ofVirtual() 创建
Runnable fn = () -> {
// your code here
};
Thread thread = Thread.ofVirtual(fn)
.start();
// 2、通过 Thread.startVirtualThread() 、创建
Thread thread = Thread.startVirtualThread(() -> {
// your code here
});
// 3、通过 Executors.newVirtualThreadPerTaskExecutor() 创建
var executorService = Executors.newVirtualThreadPerTaskExecutor();
executorService.submit(() -> {
// your code here
});
//
class CustomThread implements Runnable {
@Override
public void run() {
System.out.println("CustomThread run");
}
}
//4、通过 ThreadFactory 创建
CustomThread customThread = new CustomThread();
// 获取线程工厂类
ThreadFactory factory = Thread.ofVirtual().factory();
// 创建虚拟线程
Thread thread = factory.newThread(customThread);
// 启动线程
thread.start(); 通过上述列举的 4 种创建虚拟线程的方式可以看出,官方为了降低虚拟线程的门槛,尽力复用原有的 Thread 线程类,这样可以平滑的过渡到虚拟线程的使用。
Java 19 引入了结构化并发,一种多线程编程方法,目的是为了通过结构化并发 API 来简化多线程编程,并不是为了取代java.util.concurrent,目前处于孵化器阶段。
结构化并发将不同线程中运行的多个任务视为单个工作单元,从而简化错误处理、提高可靠性并增强可观察性。也就是说,结构化并发保留了单线程代码的可读性、可维护性和可观察性。
结构化并发的基本 API 是StructuredTaskScope。StructuredTaskScope 支持将任务拆分为多个并发子任务,在它们自己的线程中执行,并且子任务必须在主任务继续之前完成。
StructuredTaskScope 的基本用法如下:
try (var scope = new StructuredTaskScope<Object>()) {
// 使用fork方法派生线程来执行子任务
Future<Integer> future1 = scope.fork(task1);
Future<String> future2 = scope.fork(task2);
// 等待线程完成
scope.join();
// 结果的处理可能包括处理或重新抛出异常
... process results/exceptions ...
} // close结构化并发非常适合虚拟线程,虚拟线程是 JDK 实现的轻量级线程。许多虚拟线程共享同一个操作系统线程,从而允许非常多的虚拟线程。
JDK 20 中对结构化并发唯一变化是更新为支持在任务范围内创建的线程StructuredTaskScope继承范围值 这简化了跨线程共享不可变数据,详见JEP 429。
向量计算由对向量的一系列操作组成。向量 API 用来表达向量计算,该计算可以在运行时可靠地编译为支持的 CPU 架构上的最佳向量指令,从而实现优于等效标量计算的性能。
向量 API 的目标是为用户提供简洁易用且与平台无关的表达范围广泛的向量计算。
向量(Vector) API 最初由 JEP 338 提出,并作为孵化 API集成到 Java 16 中。第二轮孵化由 JEP 414 提出并集成到 Java 17 中,第三轮孵化由 JEP 417 提出并集成到 Java 18 中,第四轮由 JEP 426 提出并集成到了 Java 19 中。
Java20 的这次孵化基本没有改变向量 API ,只是进行了一些错误修复和性能增强,详见 JEP 438。