这一部分的内容主要来自于 github 的高星项目:golang-standards/project-layout 通过这个我们可以大概的了解到在 Go 中一些约定俗成的目录含义,虽然这些不是强制性的,但是如果有去看官方的源码或者是一些知名的项目可以发现大多都是这么命名的,所以我们最好和社区保持一致,大家保持同样的语言。
我们一般采用 /cmd/[appname]/main.go 的形式进行组织
- 首先 cmd 目录下一般是项目的主干目录
- 这个目录下的文件不应该有太多的代码,不应该包含业务逻辑
- main.go 当中主要做的事情就是负责程序的生命周期,服务所需资源的依赖注入等,其中依赖注入一般而言我们会使用一个依赖注入框架,这个主要看复杂程度,后续会有一篇文章单独介绍这个
internal 目录下的包,不允许被其他项目中进行导入,这是在 Go 1.4 当中引入的 feature,会在编译时执行
- 所以我们一般会把项目文件夹放置到 internal 当中,例如
/internal/app - 如果是可以被其他项目导入的包我们一般会放到 pkg 目录下
- 如果是我们项目内部进行共享的包,而不期望外部共享,我们可以放到
/internal/pkg当中 - 注意 internal 目录的限制并不局限于顶级目录,在任何目录当中都是生效的
举个 🌰 下面的是我们当前的目录结构,其中的代码很简单,在 t.go 当中导出了一个变量 I 然后在 a/cmd/a/main.go 和 b/cmd/b/main.go 当中分别导入输出这个变量的值
❯ tree
.
├── a
│ ├── cmd
│ │ └── a
│ │ └── main.go
│ └── internal
│ └── pkg
│ └── t
│ └── t.go
└── b
└── cmd
└── b
└── main.go
我们可以发现, a 目录下可以直接输出 I 的值
❯ go run ./a/cmd/a/main.go
1但是在 b 目录下,编译器会直接报错说导入了 a 的私有包
❯ go run ./b/cmd/b/main.go
package command-line-arguments
b/cmd/b/main.go:3:8: use of internal package github.com/mohuishou/go-training/Week04/blog/02_project_layout/01_internal_example/a/internal/pkg/t not allowed
一般而言,我们在 pkg 目录下放置可以被外部程序安全导入的包,对于不应该被外部程序依赖的包我们应该放置到 internal 目录下, internal 目录会有编译器进行强制验证
- pkg 目录下的包一般会按照功能进行区分,例如
/pkg/cache、/pkg/conf等 - 如果你的目录结构比较简单,内容也比较少,其实也可以不使用
pkg目录,直接把上面的这些包放在最上层即可 - 一般而言我们应用程序 app 在最外层会包含很多文件,例如
.gitlab-ci.ymlmakefile.gitignore等等,这种时候顶层目录会很多并且会有点杂乱,建议还是放到/pkg目录比较好
kit 库其实也就是一些基础库
- 每一个公司正常来说应该有且仅有一个基础库项目
- kit 库一般会包含一些常用的公共的方法,例如缓存,配置等等,比较典型的例子就是 go-kit
- kit 库必须具有的特点:
- 统一
- 标准库方式布局
- 高度抽象
- 支持插件
- 尽量减少依赖
- 持续维护
减少依赖和持续维护是我后面补充的,这一点其实很遗憾,我们部门刚进来的时候方向是对的也建立了一套基础库,然后大家都使用这同一套库,但是很遗憾,我们这一套库一是没人维护,二是没有一套机制来进行迭代,到现在很多团队和项目已经各搞各的了。 这样其实会导致做很多重复工作以及后续的一些改动很难推进,前车之鉴,如果有类似的情况一定要在小火苗出来的时候先摁住,从大的角度来讲统一有时候比好用重要,不好用应该参与贡献而不是另起炉灶。
API 定义的目录,如果我们采用的是 grpc 那这里面一般放的就是 proto 文件,除此之外也有可能是 openapi/swagger 定义文件,以及他们生成的文件。
下面给出一个我现在使用的 api 目录的定义,其实和毛老师课上讲的类似
.
└── api
└── product_name // 产品名称
└── app_name // 应用名称
└── v1 // 版本号
└── v1.proto
为什么加个(s) 是课上讲的还有参考材料中很多都叫 configs 但是我们习惯使用 config 但是含义上都是一样的 这里面一般放置配置文件文件和默认模板
额外的外部测试应用程序和测试数据。一般会放测试一些辅助方法和测试数据
微服务中的 app 服务类型分为 4 类:interface、service、job、admin。
- interface: 对外的 BFF 服务,接受来自用户的请求,比如暴露了 HTTP/gRPC 接口。
- service: 对内的微服务,仅接受来自内部其他服务或者网关的请求,比如暴露了 gRPC 接口只对内服务。
- admin:区别于 service,更多是面向运营测的服务,通常数据权限更高,隔离带来更好的代码级别安全。
- job: 流式任务处理的服务,上游一般依赖 message broker。
- task: 定时任务,类似 cronjob,部署到 task 托管平台中。

这上面是毛老师课上讲解的类型,和我们常用的做法类似,但是有点区别,同样假设我们有一个应用叫 myapp
- myapp-api: 这个是对外暴露的 api 的服务,可以是 http, 也可以是 grpc
- myapp-cron: 这个是定时任务
- myapp-job: 这个用于处理来自 message 的流式任务
- myapp-migration: 数据库迁移任务,用于初始化数据库
- scripts/xxx: 一次性执行的脚本,有时候会有一些脚本任务
大多大同小异,主要是 BFF 层我们一般是一个独立的应用,不会放在同一个仓库里面,
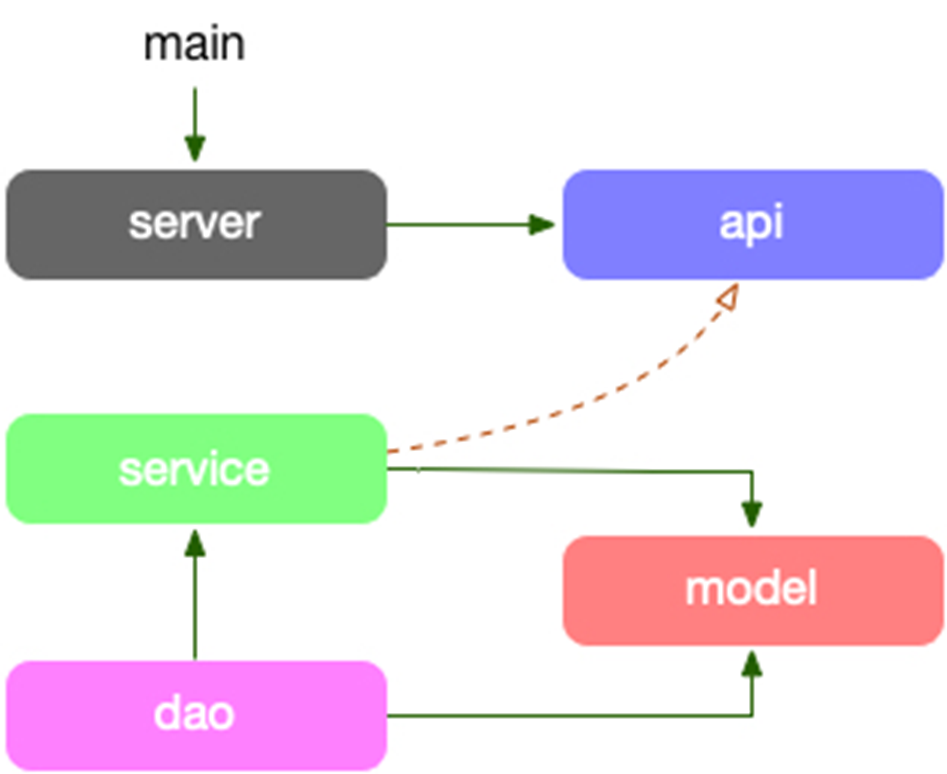
项目的依赖路径为: model -> dao -> service -> api,model struct 串联各个层,直到 api 需要做 DTO 对象转换。
- model: 放对应“存储层”的结构体,是对存储的一一隐射。
- dao: 数据读写层,数据库和缓存全部在这层统一处理,包括 cache miss 处理。
- service: 组合各种数据访问来构建业务逻辑。
- server: 依赖 proto 定义的服务作为入参,提供快捷的启动服务全局方法。
- api: 定义了 API proto 文件,和生成的 stub 代码,它生成的 interface,其实现者在 service 中。
- service 的方法签名因为实现了 API 的 接口定义,DTO 直接在业务逻辑层直接使用了,更有 dao 直接使用,最简化代码。
- DO(Domain Object): 领域对象,就是从现实世界中抽象出来的有形或无形的业务实体。缺乏 DTO -> DO 的对象转换。
- 没有 DTO 对象,model 中的对象贯穿全局,所有层都有
- model 层的数据不是每个接口都需要的,这个时候会有一些问题
- 在上一篇文章中其实也反复提到了 “如果两段看似重复的代码,如果有不同的变更速率和原因,那么这两段代码就不算是真正的重复”
- server 层的代码可以通过基础库干掉,提供统一服务暴露方式
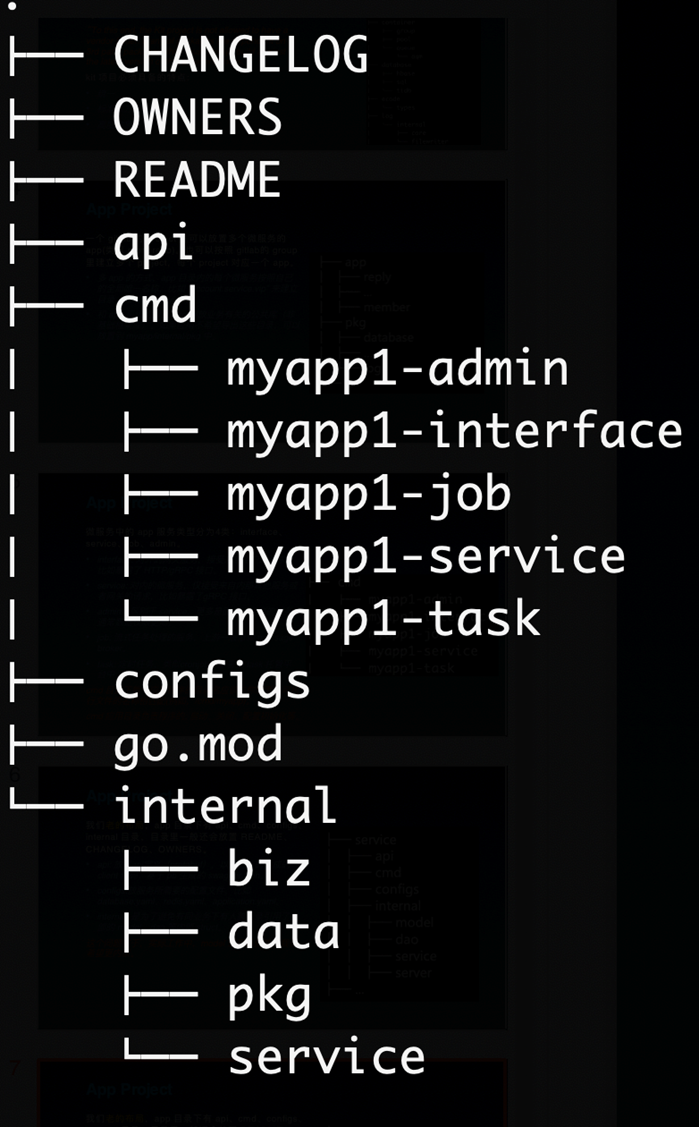
- app 目录下有 api、cmd、configs、internal 目录,目录里一般还会放置 README、CHANGELOG、OWNERS。
- internal:是为了避免有同业务下有人跨目录引用了内部的 biz、data、service 等内部 struct。
- 如果存在一个仓库多个应用,那么可以在 internal 里面进行分层,例如
/internal/app,/internal/job - biz: 业务逻辑的组装层,类似 DDD 的 domain 层,data 类似 DDD 的 repo,repo 接口在这里定义,使用依赖倒置的原则。
- data: 业务数据访问,包含 cache、db 等封装,实现了 biz 的 repo 接口。我们可能会把 data 与 dao 混淆在一起,data 偏重业务的含义,它所要做的是将领域对象重新拿出来,我们去掉了 DDD 的 infra 层。
- service: 实现了 api 定义的服务层,类似 DDD 的 application 层,处理 DTO 到 biz 领域实体的转换(DTO -> DO),同时协同各类 biz 交互,但是不应处理复杂逻辑。
- 如果存在一个仓库多个应用,那么可以在 internal 里面进行分层,例如
- PO(Persistent Object): 持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一一对应的映射关系,如果持久层是关系型数据库,那么数据表中的每个字段(或若干个)就对应 PO 的一个(或若干个)属性。
示例可以参考 kratos v2 的 example
.
├── api
├── cmd
│ └── app
├── config
├── internal
│ ├── domain
│ ├── repo
│ ├── service
│ └── usecase
└── pkginternal: 是为了避免有同业务下有人跨目录引用了内部的对象
-
domain: 类似之前的 model 层,这里面包含了 DO 对象,usecase interface, repo interface 的定义
-
repo: 定于数据访问,包含 cache, db 的封装
-
usecase: 这里是业务逻辑的组装层,类似上面的 biz 层,但是区别是我们这里不包含 DO 对象和 repo 对象的定义
-
service: 实现 api 的服务层,主要实现 DTO 和 DO 对象的转化,参数的校验等等
我们这里的定义和上面 v2 最大的区别是多了一个 domain 层,这里面有一个原因是我们对于单元测试的要求比较高,如果按照上面 v2 的代码进行组织,service 层直接依赖 usecase 的实现,service 的代码不太好进行单元测试。如果依赖 interface 会导致循环依赖,所以采用类似 go-clean-arch 的组织,单独抽象一层 domain 层
一般而言,在 Go 项目当中不应该出现 src 目录,Go 和 Java 不同,在 Go 中每一个目录都是一个包,每一个包都是一等公民,我们不需要将项目代码放到 src 当中,不要用写其他语言的方式来写 Go
不要在项目中出现 utils 和 common 这种包,如果出现这种包,因为我们并不能从包中知道你这个包的作用,长久之后这个包就会变成一个大杂烩,所有东西都往这里面扔。
有的同学这个时候会问说,那我们的工具函数应该放到哪里?怎么放?
举个例子,我们当前使用 gin 作为路由框架,但是 gin 的 handler 注册其实不是很方便,所以我们做了一层封装,这个时候这个工具方法我们一般放在 /pkg/ginx 目录下,表示这个是对 gin 增强的包,不直接使用 gin 作为包名的原因是因为我们在项目中也会引用 gin 相同的命名一个是会导致误解,另一个是在同时导入的时候也会需要去进行重命名会比较麻烦
关于项目目录结构这种真的算是见仁见智,不同的理论有不同的方法,但是我觉得有两件事比较重要,就服务应用而言需要灵活应用,就基础库而言一定要统一,做的好不好和要不要做是两件事情,如果因为当前做的不够好而不做,那么越到后面就越做不了。
API 设计将分为四个部分:
- 首先会讲一下 API 的项目目录结构,在项目中 api 该如何组织,以及 api 依赖该如何处理
- 第二个部分会讲一下 API 该如何设计,包括错误码的设计
- 第三个部分会讲一下如何构造一个 protobuf 的代码生成器,自动生成 gin 相关代码,这个是因为我们目前主要是 http 的服务,grpc 相关基础设施建设不完全,所以依赖现有的基础设施得到更好的体验。并且做到在 service 层的代码支持 grpc 和 http 多种方式,使后续架构变化更加灵活。
- 第四个部分会给出一个 demo,辅助大家更好的理解
b 站内部主要使用 grpc 作为内部通信的方式,因为他使用 protobuf 文件定义可以支持对语言代码生成,同时还避免了手写文档导致的文档错误过时等情况,具体的原因其实在第一课的笔记当中就有提到,如果感兴趣可以查看 微服务(二) 服务发现&多租户#gRPC
我们目前使用类似 http restful 的方式进行对外对内提供服务,但是我们之前的 API 管理其实是比较混乱的,分为以下几种情况:
- 暴露给 web 的 api:有使用 swagger 的,有在文档平台上写文档的,还有没有写文档的
- 暴露给其他服务调用的 api: 有注册到内部的接口网关的,但是内部的接口网关上有的有参数,有的没有,没有返回值定义
所以就存在很多问题:
- 想要接口不知道从哪儿找,只能到处问人
- 有时候从内部网关平台上找到接口但是不知道怎么调用,没有写任何参数,有的写了还有可能是错的
- 有的压根没有接口文档,对接的同学也没有时间写,然后让你直接看代码
- 有的对接同学扔给你一个接口文档,然后试了半天发现,有问题,沟通排查之后发现文档很久没有更新了 o(╥﹏╥)o
所以课程上毛老师提到的利用 protobuf 来定义接口的方式非常令人心动,因为 protobuf 当中包含了接口的函数签名,入参和返回值同时还支持注释,就是一份天然的文档,同时也不用担心出现代码更新了但是文档没有更新的情况,因为它既是文档也是代码,服务端也需要使用,所以代码更新之后文档也一定会更新。自然而然的就少了很多沟通的成本。
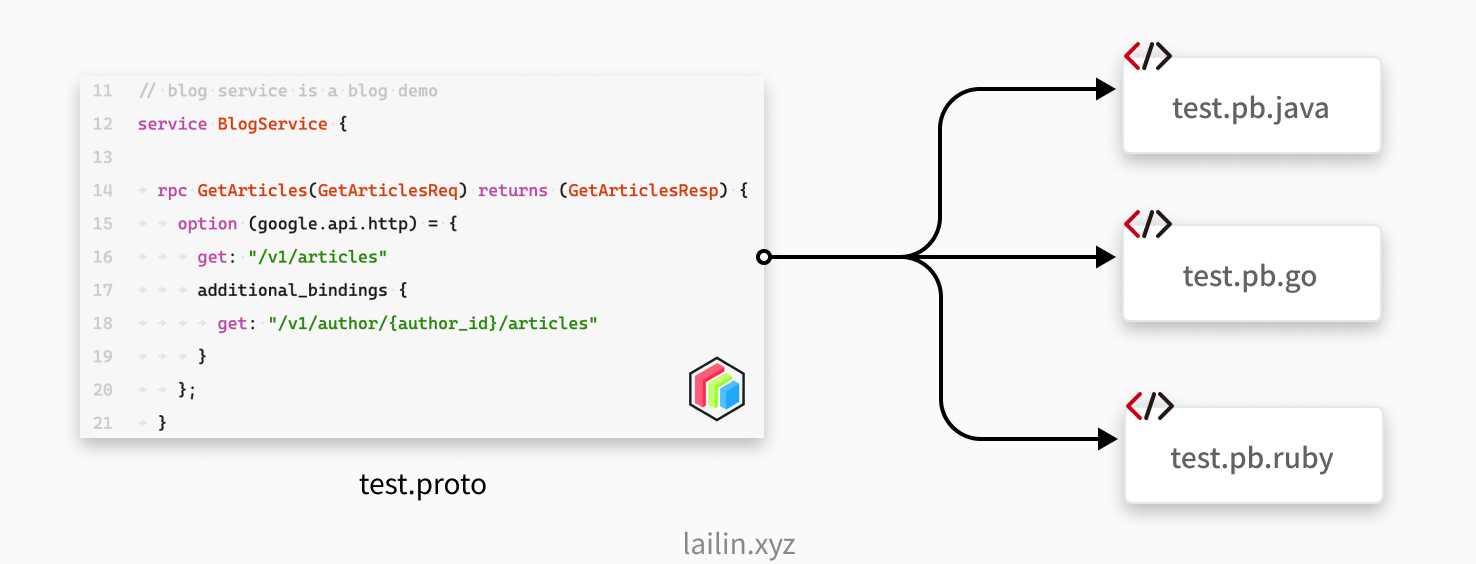
如上图所示于此同时我们还可以利用 protobuf 文件生成对应语言的客户端代码,就不用每个项目都去维护一套 sdk 了,同时我们使用接口生成代码,在 go 当中可以使用 gomock 非常方便的对代码进行 mock。
使用 protobuf 定义接口可以解决我们找到 api 文档之后,文档不准确,缺失的问题,但是我们应该如何找到我们的 api 呢?我们生成出的 api 文件调用方应该如何引用呢?难道我们给每个调用方都去开一个项目的权限么?那明显是不太行的,接下来我们就看看我们 api 该如何管理和组织。
毛老师他们仿照 googleapis/googleapis,istio/api 等知名项目在 b 站内部搞了一个 bapis 的仓库用于同一存放 api 定义文档,然后通过 ci/cd 生成对应的客户端代码放到各个语言的子仓库当中
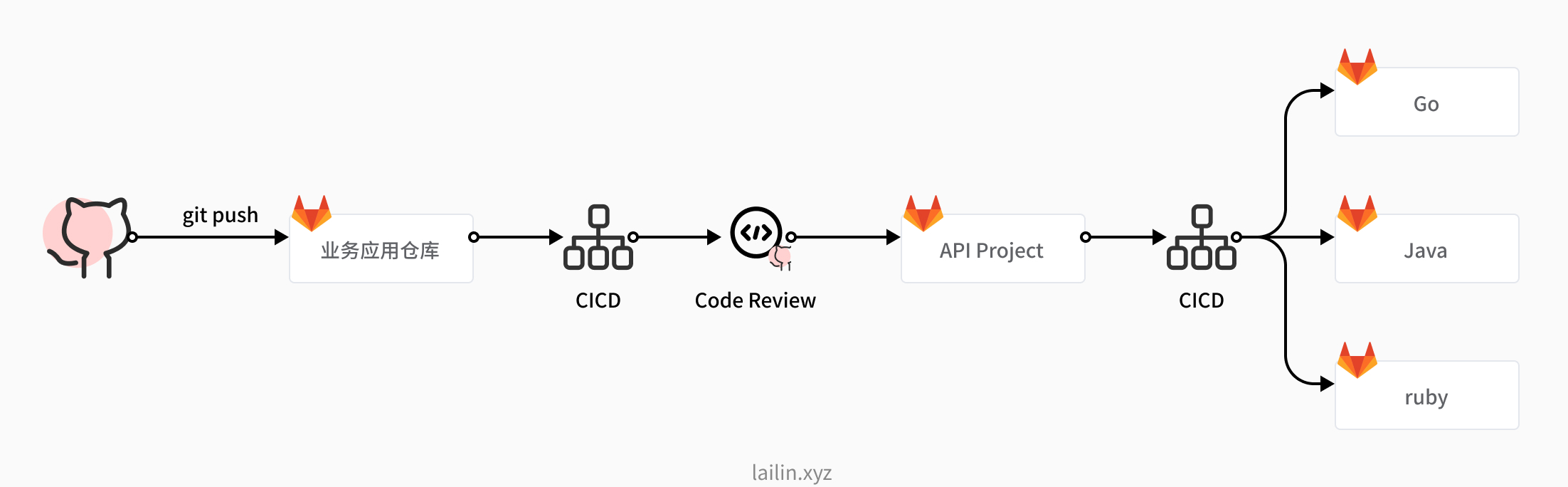
工作流程如上图所示
- 开发同学修改了 proto 文件定义之后 push 到对应的业务应用仓库当中
- 然后触发 cicd 流程将 proto 文件复制到 api project 当中
- 首先会对 proto 文件进行静态代码分析,查看是否符合规范
- 然后 clone api project 创建一个新的分支
- 然后 push 代码,创建一个 merge request 请求
- 然后我们对应负责的同学收到 code review 的通知之后进行 code review,没有问题就会合并到 api project 的主分支当中了
- 然后就会触发 cicd 生成对应语言的客户端代码,push 到对应的各个子仓库当中了
我们的 api 项目是如何定义的呢?看下图

- 首先是在业务项目当中,我们顶层会有一个 api 目录
- 在 api 目录当中我们会按照 product name/app name/版本号/app.proto 的方式进行组织
- 具体怎么组织可能每个公司都不太一样,但是总的来说就是应用的 唯一名称+版本号 来进行一个区分
- 在 api project 当中和业务应用类似,也有一个 api 目录,通过上图的两个框就可以发现这是一模一样的
- 除此之外 api project 还有用于注解的 annotations 文件夹
- 有一些第三方的引用,例如 googleapis 当中的一些 proto 文件
随着应用的不断开发,业务的不断发展我们的 api 肯定会不断的进行修改,在修改 api 的时候考虑 api 的兼容性就会很重要了,如果我们做了一些破坏性的变更就有可能会导致依赖我们的服务或者是客户端报错,这样就会带来事故。
- 新增接口
- 新增参数字段
- 新增返回字段
- 在不改变其他响应字段的行为的前提下,非资源(例如,ListBooksResponse)的响应消息可以扩展而不必破坏客户端的兼容性。即使会引入冗余,先前在响应中填充的任何字段应继续使用相同的语义填充。
一般而言新增都是相对安全的,但是我们要注意的是新增字段不能改变我们原本的逻辑,如果改变了 api 的逻辑,那就不一定安全了
- 删除或重命名服务,字段,方法或枚举值
- 在做这种修改的时候需要修改我们 api 的版本号,常见有两种方式
- 如果只有很少的 api 变动可以创建一个 XXXV2 的方法
- 如果变动的 api 比较多,可以直接新启一个 v2 的包
- 修改字段的类型
- 严禁修改字段的类型,修改字段的类型可能会导致客户端崩溃
- 修改现有请求的可见行为
- 给资源消息添加 读取/写入 字段
| 产品名 | product |
|---|---|
| 应用名 | app |
| 版本号 | v1 |
| 包名 | product.app.v1 |
| 目录结构 | api/product/app/v1/xx.proto |
- 命名规则:方法 + 资源
- 标准方法:参考 Google API 设计指南
| 标准方法 | HTTP 映射 |
|---|---|
| List | GET |
| Get | GET |
| Update | PUT 或者 PATCH |
| Create | POST |
| Delete | DELETE |
除了标准的也有一些非标准的,例如同步数据可能会用 Sync 等,不过大部分的 api 应该都是标准的
// api/product/app/v1/blog.proto
syntax = "proto3";
package product.app.v1;
import "google/api/annotations.proto";
// blog service is a blog demo
service BlogService {
rpc GetArticles(GetArticlesReq) returns (GetArticlesResp) {
option (google.api.http) = {
get: "/v1/articles"
additional_bindings {
get: "/v1/author/{author_id}/articles"
}
};
}
}注意,一般而言我们应该为每个接口都创建一个自定义的 message,为了后面扩展,如果我们用 Empty 的话后续就没有办法新增字段了
先说我们当前的问题,我们一直用的 http 然后我们返回是使用的下面这种格式,然后 http code 统一返回 200
{
"code": 1,
"msg": "xxx",
"data": {}
}这种做法就存在一个比较大的问题,做监控的时候不太好做,很多现成的东西没有办法直接使用,因为我们都返回的成功。
参照 google 的错误定义,将 http code 和 grpc 错误码进行映射,返回对应的错误信息
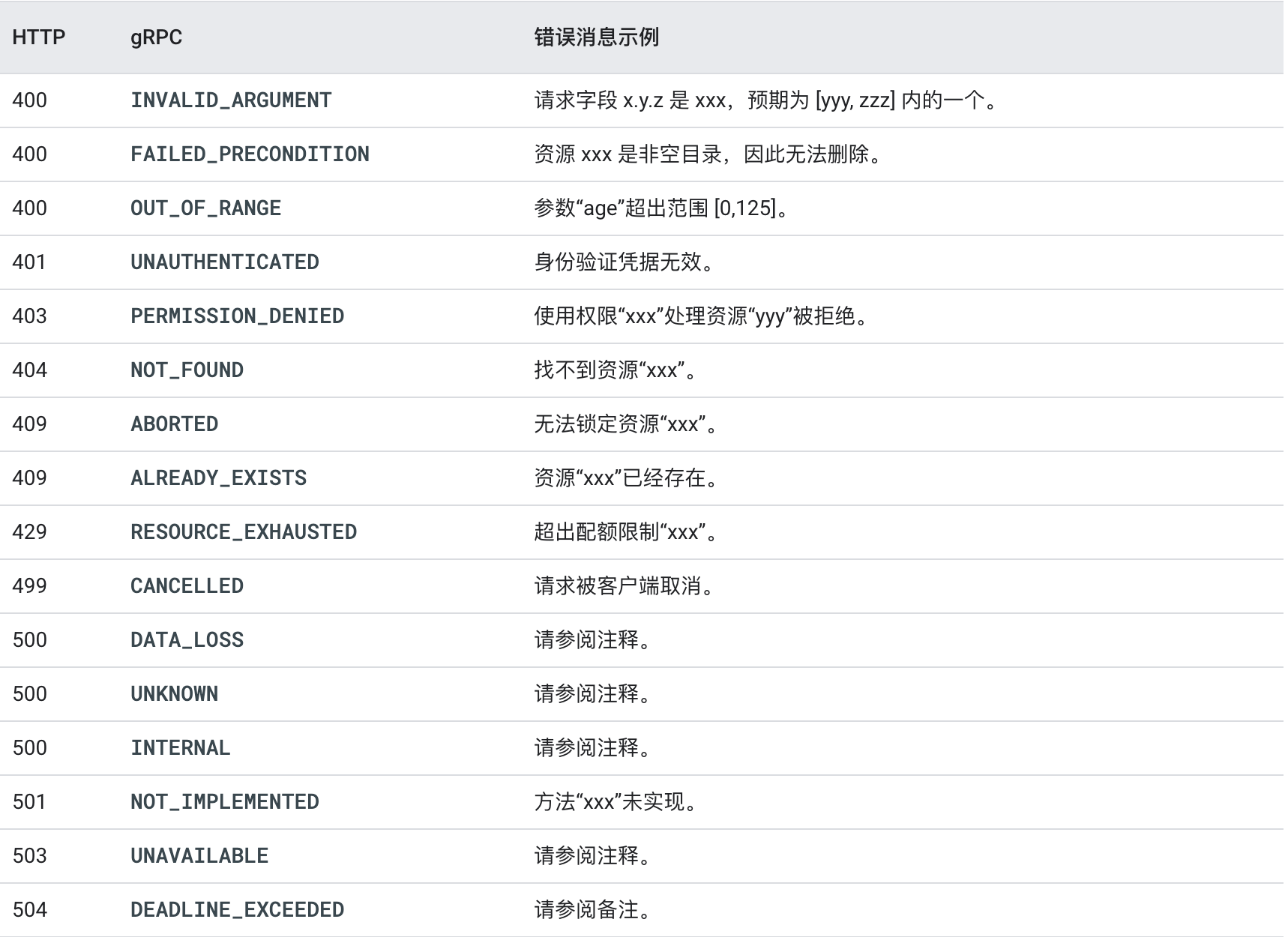
但是这样还是不行,因为这样很多业务错误信息无法区分,毛老师他们的 kratos v2 的做法是做了两层,使用下面的方式进行定义
message Status {
// 错误码,跟 grpc-status 一致,并且在HTTP中可映射成 http-status
int32 code = 1;
// 错误原因,定义为业务判定错误码
string reason = 2;
// 错误信息,为用户可读的信息,可作为用户提示内容
string message = 3;
// 错误详细信息,可以附加自定义的信息列表
repeated google.protobuf.Any details = 4;
}和我们当前的方式差不太多,但是我们是在原来的基础上返回了 http code,剩下的字段还是和原来保持一致
这一点我们之前做的还行,错误传播这一部分很容易出的问题就是,当前服务直接把上游服务的错误给返回了,这样会导致一些问题:
- 如果我调用了多个上游服务都报错了,我应该返回哪一个错误
- 直接返回导致必须要有一个全局错误码,不然的话就会冲突,但是全局错误码是很难定义的
正确的做法应该是把上游错误信息吞掉,返回当前服务自己定义的错误信息就可以了。