I'm finalizing everything to accommodate the latest major changes
| Approach | Sign-in required from the start | Risk when sign-in (*) | Risk when not sign-in | Difficulty | Speed |
|---|---|---|---|---|---|
| 1️⃣ Graph API + Full-permission Token | ✅ | Access Token leaked + Rate Limits | Not working | Easy | Fast |
| 2️⃣ SSR - Server-side Rendering | Checkpoint but less loading more failure | Hard | Medium | ||
| 3️⃣ CSR - Client-side Rendering | When access private content | Safest | Slow | ||
| 4️⃣ DevTools Console | Can be banned if overused | Medium |
When run at not sign-in state, Facebook usually redirects to the login page or prevent you from loading more comments/replies.
(*) For safety when testing with sign-in state, I recommend create a fake account (you can use a Temporary Email Address to create one) and use it for the extraction, because:
-
No matter which approach you use, any fast or irregular activity continuously in sign-in state for a long time can be likely to get blocked at any time.
-
Authenticating via services with lack of encryption such as proxies using HTTP protocol can have potential security risks, especially if sensitive data is being transmitted:
- Therefore, if you are experimenting with your own account, it's advisable to use HTTPS proxies or other more secure methods like
VPNs. - I won't implement these types of risky authentication into the sign-in process for approaches in this repo, but you can do it yourself if you want.
- Therefore, if you are experimenting with your own account, it's advisable to use HTTPS proxies or other more secure methods like
All information provided in this repo and related articles are for educational purposes only. So use at your own risk, I will not guarantee & not be responsible for any situations including:
- Whether your Facebook account may get Checkpoint due to repeatedly or rapid actions.
- Problems that may occur or for any abuse of the information or the code provided.
- Problems about your privacy while using IP hiding techniques or any malicious scripts.
👉 Check out my implementation for this approach with Python.
You will query Facebook Graph API using your own Token with full permission for fetching data. This is the MOST EFFECTIVE approach.
The knowledge and the way to get Access Token below are translated from these 2 Vietnamese blogs:
A Facebook Access Token is a randomly generated code that contains data linked to a Facebook account. It contains the permissions to perform an action on the library (API) provided by Facebook. Each Facebook account will have different Access Tokens, and there can be ≥ 1 Tokens on the same account.
Depending on the limitations of each Token's permissions, which are generated for use with corresponding features, either many or few, they can be used for various purposes, but the main goal is to automate all manual operations. Some common applications include:
- Increasing likes, subscriptions on Facebook.
- Automatically posting on Facebook.
- Automatically commenting and sharing posts.
- Automatically interacting in groups and Pages.
- ...
There are 2 types of Facebook Tokens: App-based Token and Personal Account-based Token. The Facebook Token by App is the safest one, as it will have a limited lifetime and only has some basic permissions to interact with Pages and Groups. Our main focus will on the Facebook Personal Account-based Token.
This is a full permissions Token represented by a string of characters starting with EAA.... The purpose of this Token is to act on behalf of your Facebook account to perform actions you can do on Facebook, such as sending messages, liking pages, and posting in groups through API.
Compared to an App-based Token, this type of Token has a longer lifespan and more permissions. Simply put, whatever an App-based Token can do, a Personal Account-based Token can do as well, but not vice versa.
An example of using this Facebook Token is when you want to simultaneously post to many Groups and Pages. To do this, you cannot simply log into each Group or Page to post, which is very time-consuming. Instead, you just need to fill in a list of Group and Page IDs, and then call an API to post to all in this list. Or, as you can often see on the Internet, there are tools to increase fake likes and comments also using this technique.
Note that using Facebook Token can save you time, but you should not reveal this Token to others as they can misuse it for malicious purposes:
- Do not download extensions to get Tokens or login with your phone number and password on websites that support Token retrieval, as your information will be compromised.
- And if you suspect your Token has been compromised, immediately change your Facebook password and delete the extensions installed in the browser.
- If you wanna be more careful, you can turn on two-factor authentication (2FA).
👉 To ensure safety when using the Facebook Token for personal purposes and saving time as mentioned above, you should obtain the Token directly from Facebook following the steps below.
Before, obtaining Facebook Tokens was very simple, but now many Facebook services are developing and getting Facebook Tokens has become more difficult. Facebook also limits Full permission Tokens to prevent Spam and excessive abuse regarding user behavior.
It's possible to obtain a Token, but it might be limited by basic permissions that we do not use. This is not a big issue compared to sometimes having accounts locked (identity verification) on Facebook.
Currently, this is the most used method, but it may require you to authenticate with 2FA (via app or SMS Code). With these following steps, you can get an almost full permission Token:
-
Press
Ctrl + U, thenCtrl + Fto find the code that containsEAAG. Copy the highlighted text, that's the Token you want to obtain.
-
You can go to this facebook link to check the permissions of the above Token.

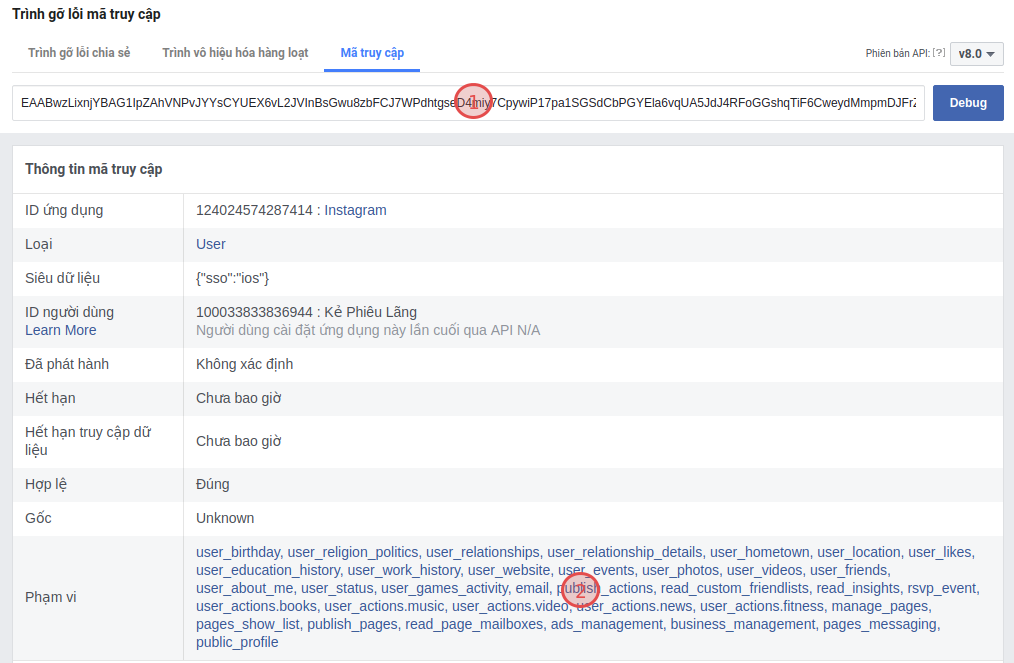
Note: I only share how to get Access Token from Facebook itself. Revealing Tokens can seriously affect your Facebook account. Please don't get Tokens from unknown sources!
👉 Check out my implementation using 2 scraping tools for this approach: Scrapy (Implementing) and Puppeteer (Implementing).
This is a popular technique for rendering a normally client-side only single-page application (SPA) on the Server and then sending a fully rendered page to the client. The client's JavaScript bundle can then take over and the SPA can operate as normal:
%%{init: {'theme': 'default', 'themeVariables': { 'primaryColor': '#333', 'lineColor': '#666', 'textColor': '#333', }}}%%
sequenceDiagram
participant U as 🌐 User's Browser
participant S as 🔧 Server
participant SS as 📜 Server-side Scripts
participant D as 📚 Database
participant B as 🖥️ Browser Engine
participant H as 💧 Hydration (SPA)
rect rgb(235, 248, 255)
U->>S: 1. Request 🌐 (URL/Link)
Note right of S: Server processes the request
S->>SS: 2. Processing 🔄 (PHP, Node.js, Python, Ruby, Java)
SS->>D: Execute Business Logic & Query DB
D-->>SS: Return Data
SS-->>S: 3. Rendering 📄 (Generate HTML)
S-->>U: 4. Response 📤 (HTML Page)
end
rect rgb(255, 243, 235)
U->>B: 5. Display 🖥️
Note right of B: Browser parses HTML, CSS, JS
B-->>U: Page Displayed to User
end
alt 6. Hydration (if SPA)
rect rgb(235, 255, 235)
U->>H: Hydration 💧
Note right of H: Attach event listeners\nMake page interactive
H-->>U: Page now reactive
end
end
- The user's browser requests a page.
- The Server receives and processes request. This involves running necessary Server-side scripts, which can be written in languages like PHP, Node.js, Python, ...
- These Server-side scripts dynamically generate the
HTMLcontent of the page. This may include executing business logic or querying a database. - The Server responds by sending the fully-rendered HTML page back to user's browser. This response also includes
CSSand theJS, which will be process once theHTMLis loaded. - The user's browser receives the
HTMLresponse and renders the page. The browser's rendering engine parses theHTML,CSS, and executeJSto display the page. - (Optional) If the application is a
SPAusing a framework like React, Vue, or Angular, an additional process called Hydration may occur to attach event listeners to the existing Server-rendered HTML:- This is where the client-side
JStakes over andbindsevent handlers to the Server-rendered HTML, effectively turning a static page into a dynamic one. - This allows the application to handle user interactions, manage
state, and potentially update theDOMwithout the need to render a new page from scratch or return to the Server for every action.
- This is where the client-side
| Pros | Cons |
|---|---|
| - Improved initial load time as users see a fully-rendered page sooner, which is important for experience, particularly on slow connections | - More Server resources are used to generate the fully-rendered HTML. |
| - Improved SEO as search engine crawlers can see the fully-rendered page. | - Complex to implement as compared to CSR, especially for dynamic sites where content changes frequently. |
II. Mbasic Facebook - A Facebook SSR version
This Facebook version is made for mobile browsers on slow internet connection by using SSR to focus on delivering content in raw HTML format. You can access it without a modern smartphones. With modern devices, it will improves the page loading time & the contents will be mainly rendered using raw HTML rather than relying heavily on JS:
JavaScript.toggle.-.Mbasic.vs.Standard.Facebook.mp4
- You can leverage the power of many web scraping frameworks like scrapy not just automation tools like puppeteer or selenium and it will become even more powerful when used with IP hiding techniques.
- You can get each part of the contents through different URLs, not only through the page scrolling ➔ You can do something like using proxy for each request or AutoThrottle (a built-in scrapy extension), ...
Updating...
👉 Check out my implementation using 2 scraping tools for this approach: Selenium (Deprecated) and Puppeteer (Implementing).
Updating...
This is the most simple way, which is to directly write & run JS code in the DevTools Console of your browser, so it's quite convenient, not required to setup anything.
-
You can take a look at this extremely useful project which includes many automation scripts (not just about data extraction) with no Access Token needed for Facebook users by directly manipulating the DOM.
-
Here's my example script to collect comments on a Facebook page when not sign-in:
// Go to the page you want to collect, wait until it finishes loading.
// Open the DevTools Console on the Browser and run the following code
let csvContents = [['UserId', 'Name', 'Comment']];
let cmtsSelector = '.userContentWrapper .commentable_item';
// 1. Click see more comments
// If you want more, just wait until the loading finishes and run this again
moreCmts = document.querySelectorAll(cmtsSelector + ' ._4sxc._42ft');
moreCmts.forEach(btnMore => btnMore.click());
// 2. Collect all comments
comments = document.querySelectorAll(cmtsSelector + ' ._72vr');
comments.forEach(cmt => {
let info = cmt.querySelector('._6qw4');
let userId = info.getAttribute('href')?.substring(1);
let content = cmt.querySelector('._3l3x>span')?.innerText;
csvContents.push([userId, info.innerText, content]);
});
csvContents.map(cmt => cmt.join('\t')).join('\n');Example result for the script above
| UserId | Name | Comment |
|---|---|---|
| freedomabcxyz | Freedom | Sau khi dùng |
| baodendepzai123 | Bảo Huy Nguyễn | nhưng mà thua |
| tukieu.2001 | Tú Kiều | đang xem hài ai rãnh xem quãng cáo |
| ABCDE2k4 | Maa Vănn Kenn | Lê Minh Nhất |
| buikhanhtoanpro | Bùi Khánh Toàn | Haha |
Updating...
Updating...
👉 Highly recommend: https://github.com/niespodd/browser-fingerprinting
| Technique | Speed | Cost | Scale | Anonymity | Other Risks | Additional Notes |
|---|---|---|---|---|---|---|
| VPN Service ⭐⭐ ⭐⭐ |
Fast, offers a balance of anonymity and speed | Usually paid | - Good for small-scale operations. - May not be suitable for high-volume scraping due to potential IP blacklisting. |
- Provides good anonymity and can bypass geo-restriction. - Potential for IP blacklisting/blocks if the VPN's IP range is known to the target site. |
- Service reliability varies. - Possible activity logs. |
Choose a reputable provider to avoid security risks. |
| TOR Network ⭐⭐ |
Very slow due to onion routing | Free | - Fine for small-scale, impractical for time-sensitive/ high-volume scraping due to very slow speed. - Consider only for research purposes, not scalable data collection. |
- Offers excellent privacy. - Tor exit nodes can be blocked or malicious, like potential for eavesdropping. |
- | Slowest choice |
| Public Wi-Fi ⭐ |
Vary | Free | Fine for small-scale. | Potential for being banned by target sites if scraping is detected. | Potential unsecured networks | Long distance way solution. |
| Mobile Network ⭐⭐ |
Relatively fast but slower speeds on some networks | Paid, potential for additional costs. | Using mobile IPs can be effective for small-scale scraping, impractical for large-scale. | Mobile IPs can change but not an anonymous option since it's tied to your personal account. | - | Using own data |
| Private/ Dedicated Proxies ⭐⭐⭐ ⭐⭐ (Best) |
Fast | Paid | - Best for large-scale operations and professional scraping projects. | Offer better performance and reliability with lower risk of blacklisting. | Vary in quality | - Rotating Proxies are popular choices for scraping as they can offer better speed and a variety of IPs. - You can use this proxy checker tool to assess your proxy quality |
| Shared Proxies ⭐⭐⭐ (Free) ⭐⭐ ⭐⭐ (Paid) |
Slow to Moderate | Usually Free or cost-effective for low-volume scraping. | Good for basic, small-scale, or non-critical scraping tasks. | Can be overloaded or blacklisted or, encountering already banned IPs. | Potential unreliable/ insecure proxies, especially Free ones. |
IMPORTANT: Nothing above is absolutely safe and secure. Caution is never superfluous. You will need to research more about them if you want to enhance the security of your data and privacy.
As you can conclude from the table above, Rotating Private/Dedicated Proxies is the most effective IP hiding technique for undetectable and large-scale scraping. Below are 2 popular ways to effectively integrate this technique into your scraping process:
| Technique | Speed | Cost | Scale | Anonymity | Additional Notes |
|---|---|---|---|---|---|
| Residential Rotating Proxies ⭐⭐⭐ ⭐⭐ (Best) |
Fast | Paid | Ideal for high-end, large-scale scraping tasks. | - Mimics real user IPs and auto-rotate IPs when using proxy gateways, making detection harder. - Provides high anonymity and low risk of blacklisting/blocks due to legitimate residential IPs. |
Consider proxy quality, location targeting, and rotation speed. |
| Datacenter Rotating Proxies ⭐⭐ ⭐⭐ |
Faster than Residential Proxies | More affordable than Residential Proxies | Good for cost-effective, large-scale scraping. | Less anonymous than Residential Proxies. - Higher risk of being blocked. - Easily detectable due to their datacenter IP ranges. |
Consider reputation of the provider and frequency of IP rotation. |
Recently, I experimented my web scraping npm package with NodeMaven, a Residential proxy provider with a focus on IP quality as well as stability, and I think it worked quite well. Below is the proxy quality result that I tested using the proxy checker tool I mentioned above:

And this is the performance measure of my actual run that I tested with my scraping package:
- Successful scrape runs: 96% (over 100 attempts). This result is a quite good.
- NodeMaven already reduced the likelihood of encountering banned or blacklisted IPs through the
IP Quality Filteringfeature. - Another reason is that it can access to over
5M residential IPsacross 150+ countries, a broad range of geo-targeting options. - I also used their
IP Rotationfeature to rotate IPs within a single gateway endpoint, which simplified my scraping setup and provided consistent anonymity.
- NodeMaven already reduced the likelihood of encountering banned or blacklisted IPs through the
- Average scrape time: around 1-2 mins/10 pages for complex dynamic loading website (highly dependent on website complexity). While the proxy speeds were generally consistent, there were occasional fluctuations, which is expected in any proxy service.
- Sticky Sessions: 24h+ session durations allowed me to maintain connections and complete scrapes efficiently.
- IP block rate / Redirect / Blank page in the first run: <4%.
Overall, throughout many runs, the proxies proved to be reliable with minimal downtime or issues. For those interested in trying NodeMaven, you can apply the code QD2 for an additional 2GB of traffic free with your trial or package purchase.
Updating...