This repository contains the code for developing, pretraining, and finetuning a GPT-like LLM and is the official code repository for the book Build a Large Language Model (From Scratch).

In Build a Large Language Model (From Scratch), you'll learn and understand how large language models (LLMs) work from the inside out by coding them from the ground up, step by step. In this book, I'll guide you through creating your own LLM, explaining each stage with clear text, diagrams, and examples.
The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT. In addition, this book includes code for loading the weights of larger pretrained models for finetuning.
- Link to the official source code repository
- Link to the book at Manning
- Link to the book page on Amazon
- ISBN 9781633437166

To download a copy of this repository, click on the Download ZIP button or execute the following command in your terminal:
git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git(If you downloaded the code bundle from the Manning website, please consider visiting the official code repository on GitHub at https://github.com/rasbt/LLMs-from-scratch for the latest updates.)
Please note that this README.md file is a Markdown (.md) file. If you have downloaded this code bundle from the Manning website and are viewing it on your local computer, I recommend using a Markdown editor or previewer for proper viewing. If you haven't installed a Markdown editor yet, MarkText is a good free option.
You can alternatively view this and other files on GitHub at https://github.com/rasbt/LLMs-from-scratch in your browser, which renders Markdown automatically.
Tip
If you're seeking guidance on installing Python and Python packages and setting up your code environment, I suggest reading the README.md file located in the setup directory.
![]()
![]()
![]()
| Chapter Title | Main Code (for quick access) | All Code + Supplementary |
|---|---|---|
| Setup recommendations | - | - |
| Ch 1: Understanding Large Language Models | No code | - |
| Ch 2: Working with Text Data | - ch02.ipynb - dataloader.ipynb (summary) - exercise-solutions.ipynb |
./ch02 |
| Ch 3: Coding Attention Mechanisms | - ch03.ipynb - multihead-attention.ipynb (summary) - exercise-solutions.ipynb |
./ch03 |
| Ch 4: Implementing a GPT Model from Scratch | - ch04.ipynb - gpt.py (summary) - exercise-solutions.ipynb |
./ch04 |
| Ch 5: Pretraining on Unlabeled Data | - ch05.ipynb - gpt_train.py (summary) - gpt_generate.py (summary) - exercise-solutions.ipynb |
./ch05 |
| Ch 6: Finetuning for Text Classification | - ch06.ipynb - gpt_class_finetune.py - exercise-solutions.ipynb |
./ch06 |
| Ch 7: Finetuning to Follow Instructions | - ch07.ipynb - gpt_instruction_finetuning.py (summary) - ollama_evaluate.py (summary) - exercise-solutions.ipynb |
./ch07 |
| Appendix A: Introduction to PyTorch | - code-part1.ipynb - code-part2.ipynb - DDP-script.py - exercise-solutions.ipynb |
./appendix-A |
| Appendix B: References and Further Reading | No code | - |
| Appendix C: Exercise Solutions | No code | - |
| Appendix D: Adding Bells and Whistles to the Training Loop | - appendix-D.ipynb | ./appendix-D |
| Appendix E: Parameter-efficient Finetuning with LoRA | - appendix-E.ipynb | ./appendix-E |
The mental model below summarizes the contents covered in this book.
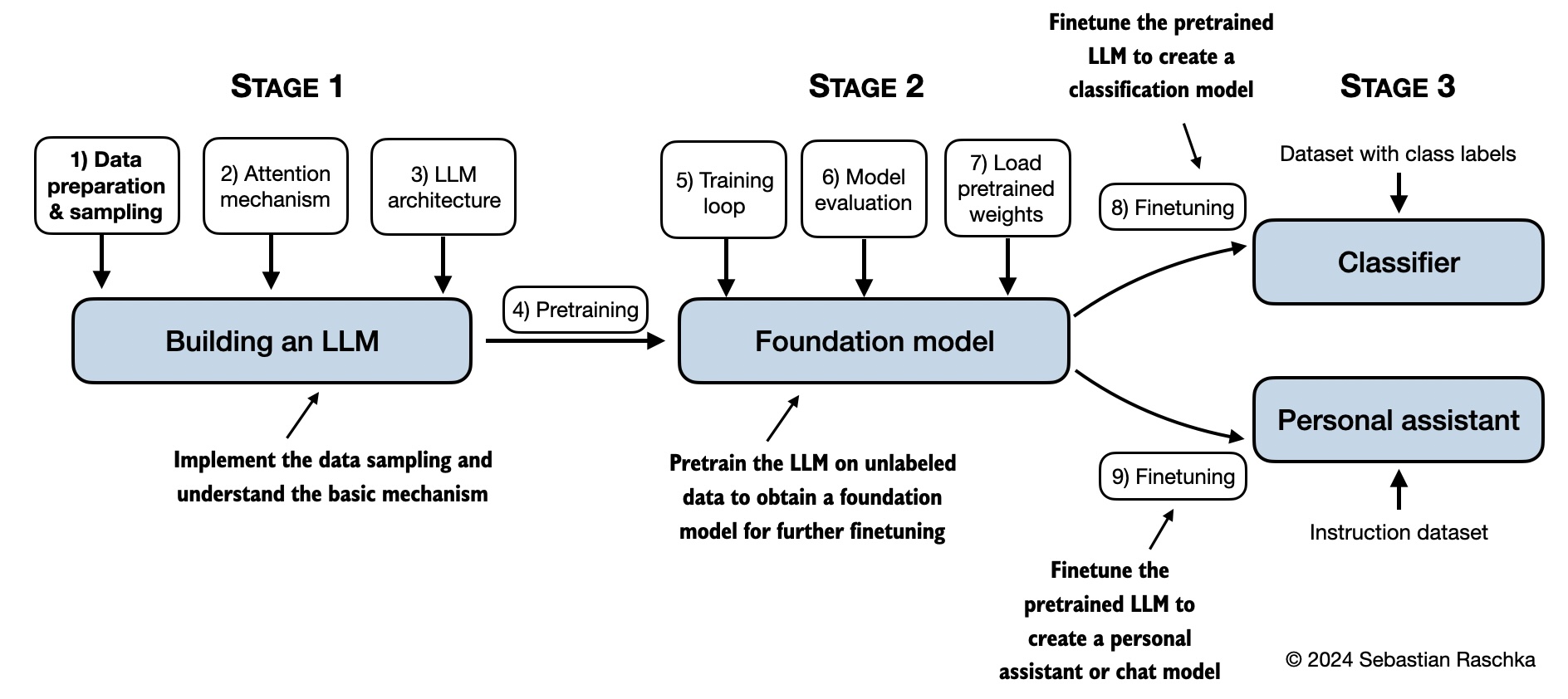
The code in the main chapters of this book is designed to run on conventional laptops within a reasonable timeframe and does not require specialized hardware. This approach ensures that a wide audience can engage with the material. Additionally, the code automatically utilizes GPUs if they are available. (Please see the setup doc for additional recommendations.)
Several folders contain optional materials as a bonus for interested readers:
- Setup
- Chapter 2:
- Chapter 3:
- Chapter 4:
- Chapter 5:
- Chapter 6:
- Chapter 7:
- Dataset Utilities for Finding Near Duplicates and Creating Passive Voice Entries
- Evaluating Instruction Responses Using the OpenAI API and Ollama
- Generating a Dataset for Instruction Finetuning
- Generating a Preference Dataset with Llama 3.1 70B and Ollama
- Direct Preference Optimization (DPO) for LLM Alignment
I welcome all sorts of feedback, best shared via the Discussions forum. Likewise, if you have any questions or just want to bounce ideas off others, please don't hesitate to post these in the forum as well.
If you notice any problems or issues, please do not hesitate to file an Issue.
However, since this repository contains the code corresponding to a print book, I currently cannot accept contributions that would extend the contents of the main chapter code, as it would introduce deviations from the physical book. Keeping it consistent helps ensure a smooth experience for everyone.
If you find this book or code useful for your research, please consider citing it.
Chicago-style citation:
Raschka, Sebastian. Build A Large Language Model (From Scratch). Manning, 2024. ISBN: 978-1633437166.
BibTeX entry:
@book{build-llms-from-scratch-book,
author = {Sebastian Raschka},
title = {Build A Large Language Model (From Scratch)},
publisher = {Manning},
year = {2024},
isbn = {978-1633437166},
url = {https://www.manning.com/books/build-a-large-language-model-from-scratch},
github = {https://github.com/rasbt/LLMs-from-scratch}
}