| Author: | The Blosc development team |
|---|---|
| Contact: | blosc@blosc.org |
| Github: | https://github.com/Blosc/python-blosc2 |
| Actions: | |
| PyPi: | 
|
| NumFOCUS: | |
| Code of Conduct: |
C-Blosc2 is the latest major version of C-Blosc, and it is backward compatible with both the C-Blosc1 API and its in-memory format. Python-Blosc2 is a Python package that wraps C-Blosc2, the most recent version of the Blosc compressor.
Starting with version 3.0.0, Python-Blosc2 includes a powerful computing engine capable of operating on compressed data stored in-memory, on-disk, or across the network. This engine also supports advanced features such as reductions, filters, user-defined functions, and broadcasting (the latter is still in beta).
You can read some of our tutorials on how to perform advanced computations at the following links:
- https://github.com/Blosc/python-blosc2/blob/main/doc/getting_started/tutorials/03.lazyarray-expressions.ipynb
- https://github.com/Blosc/python-blosc2/blob/main/doc/getting_started/tutorials/03.lazyarray-udf.ipynb
Additionally, Python-Blosc2 aims to fully leverage the functionality of C-Blosc2, supporting super-chunks (SChunk), multi-dimensional arrays (NDArray), metadata, serialization, and other features introduced in C-Blosc2.
Note: Blosc2 is designed to be backward compatible with Blosc(1) data. This means it can read data generated by Blosc, but the reverse is not true (i.e. there is no forward compatibility).
One of the most useful abstractions in Python-Blosc2 is the NDArray object. It enables highly efficient reading and writing of n-dimensional datasets through a two-level n-dimensional partitioning system. This allows for more fine-grained slicing and manipulation of arbitrarily large and compressed data:

To pique your interest, here is how the NDArray object performs when retrieving slices orthogonal to the different axis of a 4-dimensional dataset:

We have written a blog post on this topic: https://www.blosc.org/posts/blosc2-ndim-intro
We also have a ~2 min explanatory video on why slicing in a pineapple-style (aka double partition) is useful:

The NDArray objects are easy to work with in Python-Blosc2. Here it is a simple example:
import numpy as np
import blosc2
N = 10_000
na = np.linspace(0, 1, N * N, dtype=np.float32).reshape(N, N)
nb = np.linspace(1, 2, N * N).reshape(N, N)
nc = np.linspace(-10, 10, N * N).reshape(N, N)
# Convert to blosc2
a = blosc2.asarray(na)
b = blosc2.asarray(nb)
c = blosc2.asarray(nc)
# Expression
expr = ((a ** 3 + blosc2.sin(c * 2)) < b) & (c > 0)
# Evaluate and get a NDArray as result
out = expr.compute()
print(out.info)As you can see, the NDArray instances are very similar to NumPy arrays, but behind the scenes, they store compressed data that can be processed efficiently using the new computing engine included in Python-Blosc2.
To pique your interest, here is the performance (measured on a MacBook Air M2 with 24 GB of RAM) you can achieve when the operands fit comfortably in memory:

In this case, the performance is somewhat below that of top-tier libraries like Numexpr or Numba, but it is still quite good. Using CPUs with more cores than the M2 could further reduce the performance gap. One important point to note is that the memory consumption when using the LazyArray.compute() method is very low because the output is an NDArray object, which is compressed and stored in memory by default. On the other hand, the LazyArray.__getitem__() method returns an actual NumPy array, so it is not recommended for large datasets, as it can consume a significant amount of memory (though it may still be convenient for small outputs).
It is also important to note that the NDArray object can utilize memory-mapped files, and the benchmark above actually uses a memory-mapped file for operand storage. Memory-mapped files are particularly useful when the operands do not fit in-memory, while still maintaining good performance.
And here is the performance when the operands do not fit well in memory:
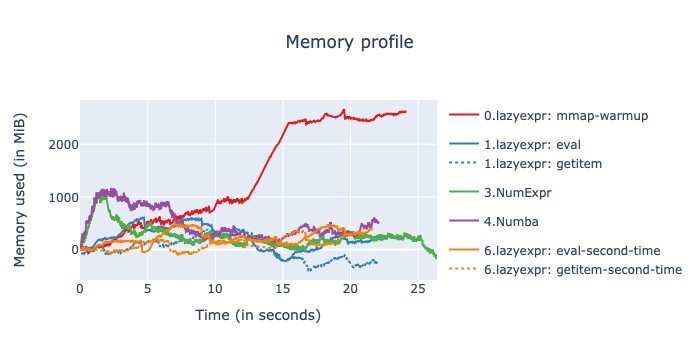
In this latter case, the memory consumption figures may seem a bit extreme, but this is because the displayed values represent actual memory consumption, not virtual memory. During evaluation, the OS may need to swap some memory to disk. In this scenario, the performance compared to top-tier libraries like Numexpr or Numba is quite competitive.
You can find the benchmark for the examples above at: https://github.com/Blosc/python-blosc2/blob/main/bench/ndarray/lazyarray-expr.ipynb
Blosc2 now provides Python wheels for the major OS (Win, Mac and Linux) and platforms.
You can install the binary packages from PyPi using pip:
pip install blosc2We are in the process of releasing 3.0.0, along with wheels for various beta versions. For example, to install the first beta version, you can use:
pip install blosc2==3.0.0b1The documentation is available here:
https://blosc.org/python-blosc2/python-blosc2.html
Additionally, you can find some examples at:
https://github.com/Blosc/python-blosc2/tree/main/examples
python-blosc2 includes the C-Blosc2 source code and can be built in place:
git clone https://github.com/Blosc/python-blosc2/
cd python-blosc2
pip install . # add -e for editable modeThat's it! You can now proceed to the testing section.
After compiling, you can quickly verify that the package is functioning correctly by running the tests:
pip install .[test]
pytest (add -v for verbose mode)If you are curious, you may want to run a small benchmark that compares a plain NumPy array copy against compression using different compressors in your Blosc build:
python bench/pack_compress.pyThis software is licensed under a 3-Clause BSD license. A copy of the python-blosc2 license can be found in LICENSE.txt.
Discussion about this module are welcome on the Blosc mailing list:
https://groups.google.es/group/blosc
Please follow @Blosc2 to stay updated on the latest developments. We recently moved from Twitter to Mastodon.
You can cite our work on the various libraries under the Blosc umbrella as follows:
@ONLINE{blosc,
author = {{Blosc Development Team}},
title = "{A fast, compressed and persistent data store library}",
year = {2009-2024},
note = {https://blosc.org}
}Make compression better!