

1. Introduction
2. Link
3. Architecture
4. Features
5. Skills
6. Trouble Shooting
HTTP, WebSocket 프로토콜에서의 로직 구현 및 MSA 기반 인프라 구축, 트래픽 제어를 목표로 하는 스터디 프로젝트입니다.
도전적인 기능들을 구현하고 테스트를 근거로 성능 개선을 이뤄내는 채팅 애플리케이션 서비스 프레임을 구현하였습니다.
비용 문제 및 인프라 개선으로 인해 현재 서버 인스턴스 연결이 끊어져있기 때문에 기왕이면 시연 영상을 참고 바랍니다


- WebSocket STOMP를 기반으로 ws 프로토콜에서의 실시간 사용자간 메세지 송수신 기능을 구현했습니다
- 웹소켓 서버 스케일링에 대응하고 메세지 신뢰성 보장을 위한 고성능 메세지 큐인 Kafka를 구축하였습니다

- 별개의 추가 WebSocket 인스턴스로 동작하되, 메세징 인스턴스와 이벤트 기반으로 상호 작용하여 실시간으로 참여자를 관리합니다
- 참여자의 접속 현황은 MongoDB를 통해 채팅방 기준으로 접속자의 접속 여부, 퇴장 시간을 관리합니다
- 가볍게 처리하고 별개의 기록을 남길 필요가 없기에 Redis Pub Sub 메세지브로커로 구현했습니다

- 접속을 끊었지만 서버 내에서 구독을 유지하고 있는 채팅 내에서 이뤄진 메세지를 저장하여 재접속할 때 출력해줍니다
- 접속자 관리를 담당하는 MongoDB에서 GraphQL을 통해 받아온 퇴장 시간을 바탕으로 PostgreSQL에서 조회합니다
- Netty 엔진을 기반으로 구축된 API Gateway에게 라우팅 및 필터링 책임만을 분배하고 인증 책임을 별도의 인스턴스에 위임
- 이를 통해 향후 인증 방식이 바뀌어도 API Gateway의 로직을 수정할 필요가 없어짐으로써 수평적 확장성을 도모
- 비동기 요청 처리에 필요한 요구 사항을 충족시키기 위해서. 인스턴스 간의 통신 수단을 Kafka로 구축한 시점
- 자연스럽게 Kafka를 통한 인증 인스턴스와 API Gateway 간의 인증 정보 송수신을 생각
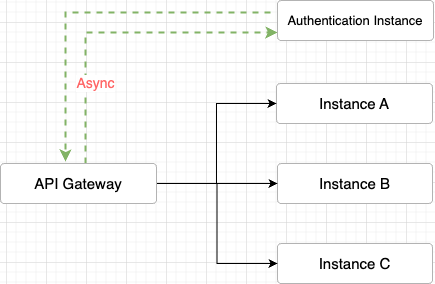
- 인증 인스턴스에서 받아온 인증 정보를 요청의 헤더에 커스텀해서 보내줌
- 각 인스턴스의 필터 단계에서 인증 객체를 생성해서 인증함으로써 최종 인증 로직 종료
// ...
SecurityContext context = SecurityContextHolder.createEmptyContext();
context.setAuthentication(createAuthentication(username));
SecurityContextHolder.setContext(context);
}
// Authentication 객체 생성 (UPAT 생성)
private Authentication createAuthentication(String username) {
UserDetails userDetails = userDetailsService.loadUserByUsername(username);
return new UsernamePasswordAuthenticationToken(userDetails, null, userDetails.getAuthorities());
}// Auth Filter in API Gateway
// 인증 요청 Kafka 전송
return kafkaProducerTemplate.send(topic, id.toString(), tokenDTO)
.then(Mono.defer(() -> {
// 인증 응답 대기
return kafkaReceiver
.receive()
.filter(record -> record.key().equals(id.toString()))
.next()
.map(ConsumerRecord::value)
.flatMap(userInfoDTO -> {
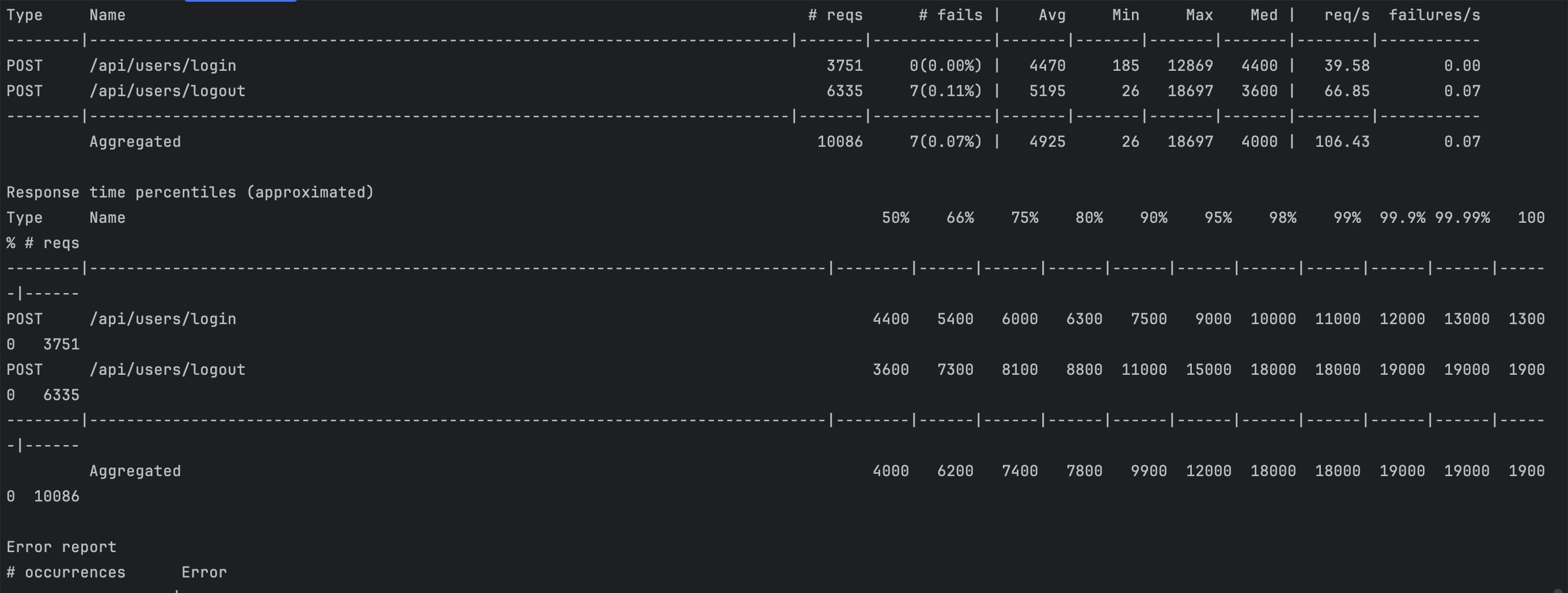
// ...- 카프카 기반 요청을 보내는 로직에서 인증 응답을 대기하는, 요청 - 응답 모델을 활용해서 인증 처리 로직 구축
- 테스트 결과, 인증을 전제로 하는 로그아웃을 비롯한 API 호출의 99% 이상 실패 기록
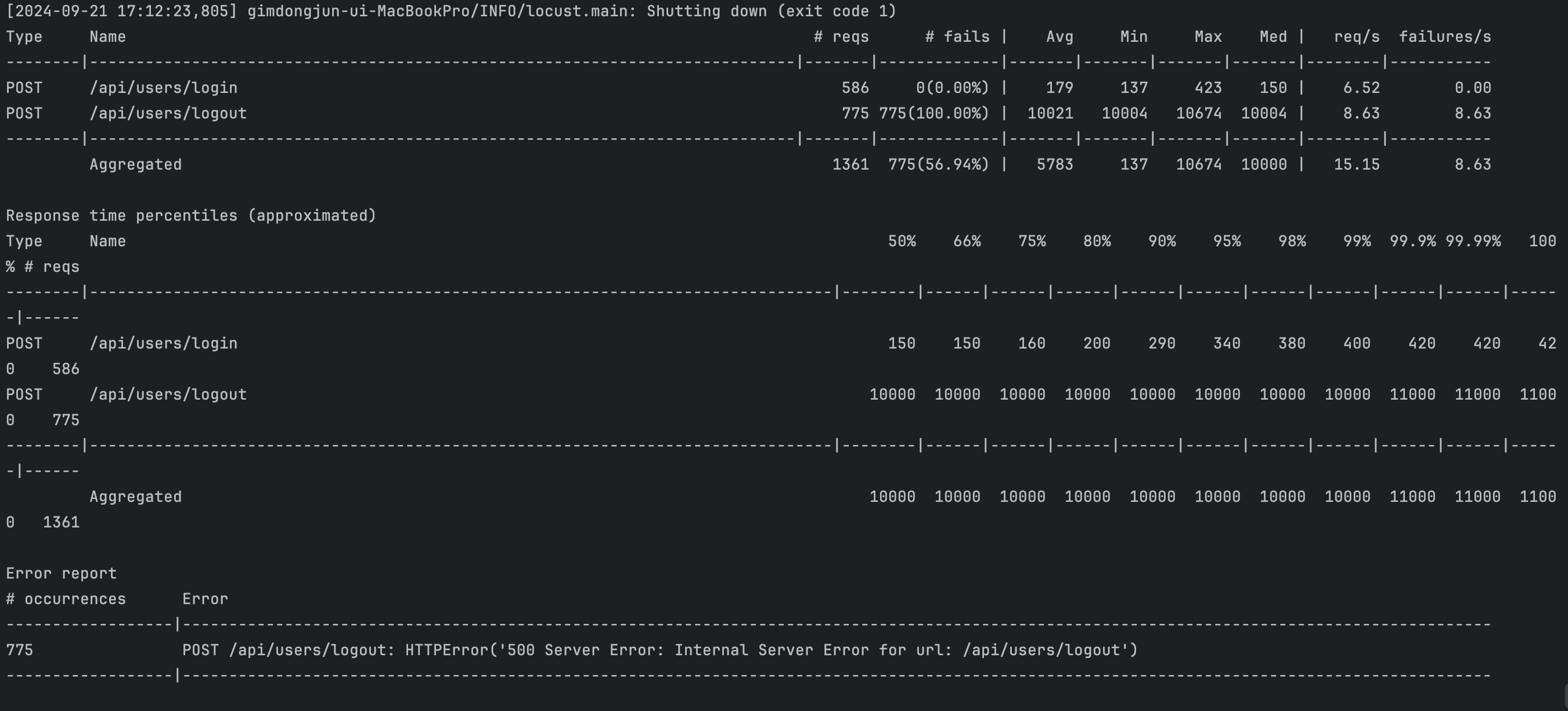
Kafka 요청 - 응답 모델에서의 테스트
- 서버 내부의 에러(500)라는 것은 응답 수신 대기 과정에서의 타임아웃 가능성
- 논블로킹 방식의 요청 - 응답은 Kafka의 비동기성 및 이벤트 스트리밍 취지를 위배
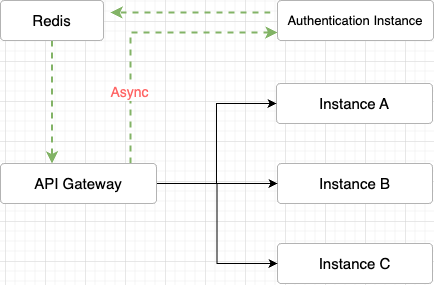
- Netty 기반의 비동기 로직으로 이뤄진 API Gateway에서 인증 결과를 직접 조회시키는 방향으로 개선
- 인증 인스턴스의 처리 결과를 Redis에 바로 저장해서 캐시 데이터로 활용, API Gateway에서 직접 Redis 조회
// Auth Filter in API Gateway
// 인증 요청 Kafka 전송
return kafkaProducerTemplate.send(topic, tokenDTO)
.flatMap(result -> {
// Kafka에 메시지 전송 후 Redis에서 결과를 비동기적으로 조회
return checkRedisForUserInfo(id)
.flatMap(userInfoDTO -> {
// ...- 카프카 응답 수신 로직을 걷어내고, 레디스 조회 메소드를 통해 결과를 반환받는 방향으로 리팩토링
- 고려할 점으로 API Gateway의 Redis 조회가 인증 작업보다 빠른 것에 대한 대비책, 엑세스 토큰의 파싱 속도보다 API Gateway의 조회 속도가 더 빠를 경우

API Gateway의 조회와 엑세스 토큰 파싱의 비정합성
- 레디스 조회에서 수신 대기 메소드를 추가로 작성해서 활용
- 0.05초 간격으로 재시도 로직을 수행해서 인증 정보를 받아올 수 있도록 처리
- 최대 타임아웃으로 10초를 설정하여 인증 로직 혹은 Redis에 문제가 발생해 캐시가 조회되지 않으면 예외 처리
// redis 캐시 조회 메소드
private Mono<UserInfoDTO> checkRedisForUserInfo(String id) {
return Mono.defer(() -> {
UserInfoDTO userInfo = userInfoTemplate.opsForValue().get(REDIS_ACCESS_KEY + id);
if (userInfo != null) {
log.info("Redis에서 사용자 정보 조회 성공 - UserInfo: {}", userInfo); // 성공 시 로그 추가
if (!id.equals(userInfo.getId())) {
userInfoTemplate.delete(REDIS_ACCESS_KEY + id);
userInfoTemplate.opsForValue().set(REDIS_ACCESS_KEY + userInfo.getId(), userInfo, 120 * 30, TimeUnit.SECONDS);
}
return Mono.just(userInfo);
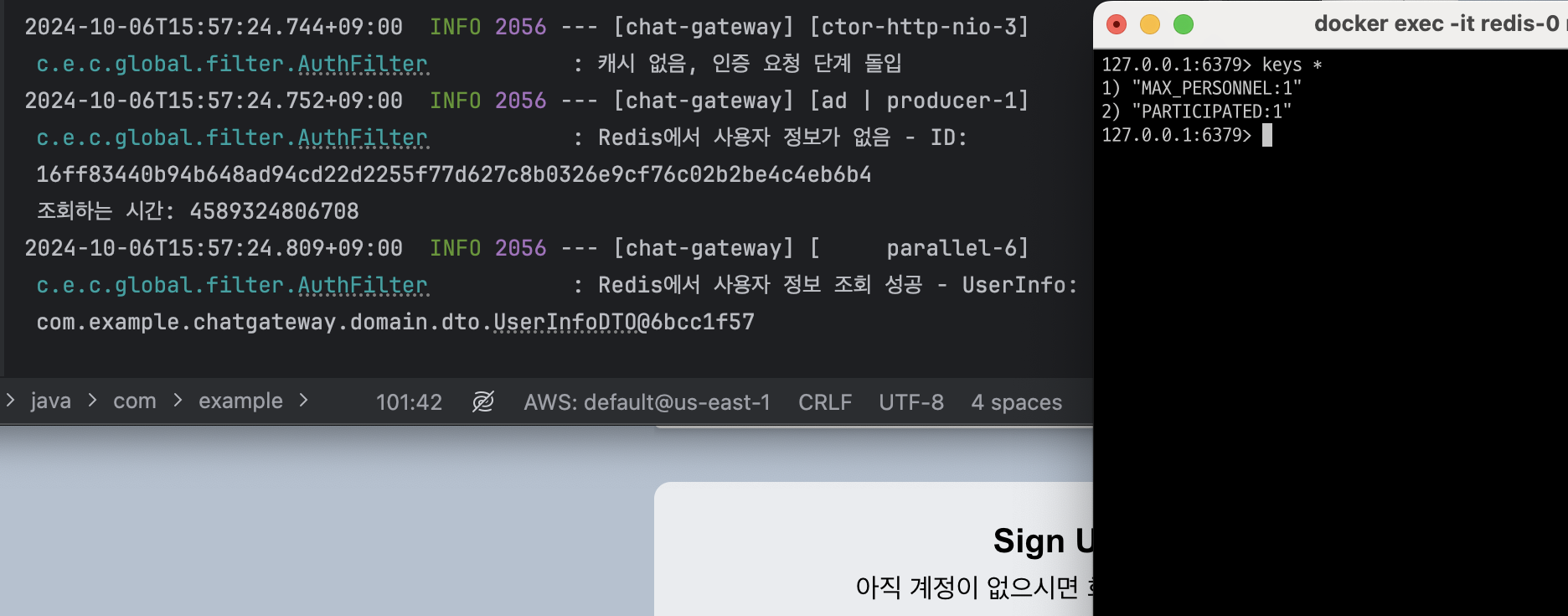
} else {
log.info("Redis에서 사용자 정보가 없음 - ID: {}\n 조회하는 시간: {}", id, System.nanoTime()); // 데이터가 없는 경우 로그 추가
return Mono.empty();
}
})
.repeatWhenEmpty(flux -> flux
.delayElements(Duration.ofMillis(50)) // 0.05초 간격으로 재시도
.take(200)) // 재시도
.timeout(Duration.ofSeconds(10)) // 타임아웃 설정
.onErrorResume(e ->
Mono.error(new ResponseStatusException(
HttpStatus.INTERNAL_SERVER_ERROR, "레디스 유저 임시정보 조회 에러", e)));
}- Redis에 캐시가 있을 때는 굳이 인증 인스턴스를 거치지 않고 바로 요청을 라우팅 처리
- 캐시가 없으면 인증 인스턴스로 Kafka를 통해 송신해서 인증 정보를 캐시 조회로 받아오는 방식으로 최종 리팩토링
- 문제 해결
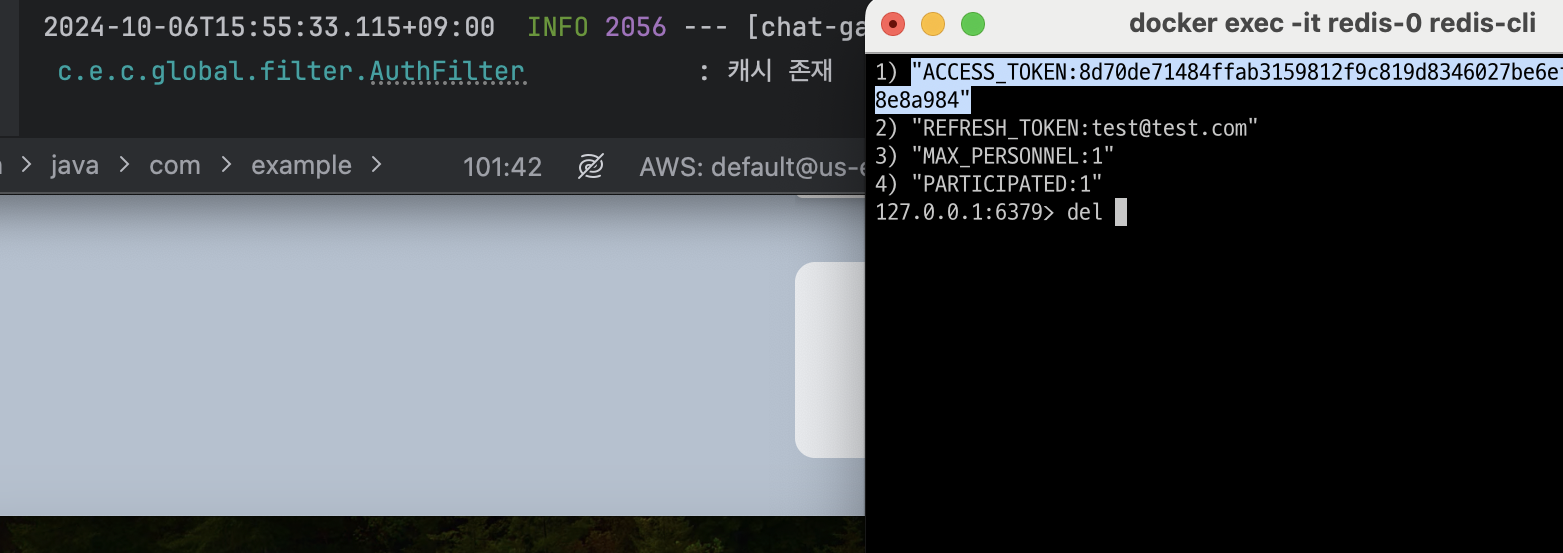
Redis에 캐시가 존재할 경우
Redis에 캐시가 존재하지 않을 경우
Kafka 전파 - Redis 캐시 조회 모델에서의 테스트
- 2차 리팩토링 전의 채팅방 구독 관리는 접속 관리와 더불어 NoSQL(Redis, MongoDB) 에서 책임
- polyglot persistence 패턴 구현을 위해 구독 관리를 RDBMS(PostgreSQL) 에 넘기는 리팩토링 시행
- 현재 구독자 수 필드를 채팅방 엔티티에 추가하고, 구독 이벤트 로직 내에서 필드의 업데이트 처리
// chat instance
@Getter
@Setter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(name = "openchats")
@EntityListeners(AuditingEntityListener.class)
public class ChatRoom {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
// ...
@Column(name = "personnel")
private Integer personnel;// message instance
@Slf4j(topic = "ChatMessageService")
@Service
@RequiredArgsConstructor
public class ChatMessageService {
// ...
public void enter(ChatMessageDTO.Enter enter, @AuthenticationPrincipal UserDetailsImpl userDetails) {
String username = userDetails.getUsername();
String role = userDetails.getRole();
// ...
// GraphQL을 통해 chat instance에 있는 채팅방 엔티티 인스턴스 필드 업데이트
graphqlService.incrementPersonnel(enter.getChatId(), username, role);- 메세지 인스턴스에서 GraphQL로 API 호출을 수행하면서 채팅 인스턴스에서의 현재 인원 업데이트 과정을 구현
- 플로우는 아래와 같음

현재 인원 업데이트 플로우

PostgreSQL 테이블로 현재 인원 관리
- NoSQL에서 RDBMS로 리팩토링을 하고 메세지 인스턴스에서 채팅 인스턴스로 구독 관리 책임을 분산시켜서 JUnit 기반으로 동시성 테스트 코드를 작성
// 인메모리 데이터베이스 h2 기반 동시성 제어 테스트
// 메모리 기반이기 떄문에 테스트 종료시, 자동 휘발됨(데이터베이스까지!)
@Slf4j
@SpringBootTest
@ActiveProfiles("test")
public class ConcurrencyTest {
@Autowired
private ChatRoomRepository chatRoomRepository;
@Autowired
private ChatGraphqlServiceImpl chatGraphqlService;
// ...
@BeforeEach
@DisplayName("임의의 채팅방 객체 생성")
void setUp() {
ChatRoomDTO dto = new ChatRoomDTO(TITLE, MAX_PERSONNEL);
ChatRoom chatRoom = new ChatRoom(dto, "openUser");
chatRoomRepository.save(chatRoom);
}
// ...
@Test
@DisplayName("트래픽이 몰리는 상황에서 정합성이 지켜지는지 테스트")
void testWithNoLock() throws InterruptedException {
// given & when...
// 스레드 풀 및 동시 시작 장치
ExecutorService executorService = Executors.newFixedThreadPool(CLIENT);
CountDownLatch countDownLatch = new CountDownLatch(CLIENT);
// 성공 결과를 담을 자료구조
List<GraphqlDTO> result = new ArrayList<>();
for (int i = 0; i < CLIENT; i++) {
executorService.submit(() -> {
try {
GraphqlDTO success =
chatGraphqlService
.incrementPersonnel(chatRoom.getId().toString());
result.add(success);
log.info("입장 성공!: {}", success);
} catch (Exception e) {
log.error("입장 실패! : {}", e.getMessage());
} finally {
countDownLatch.countDown(); // 카운트 감소
}
});
}
countDownLatch.await(); // 스레드 종료 대기
executorService.shutdown(); // 서비스 종료
// then
assertThat(result.size())
.describedAs("예상 인원 수: %d, 실제 인원 수: %d", MAX_PERSONNEL, result.size())
.isGreaterThan(MAX_PERSONNEL);
}- 테스트 수행 환경은 채팅방의 제한 인원 대비 트래픽이 몰리는 상황으로 설정
- 수행 결과 제한 인원보다 더 많은 스레드에서 입장 승인 처리 확인, 즉 동시성 이슈 발생

JUnit 테스트 코드로 동시성 이슈 발생 확인
- 처음 구독자 관리를 Redis로 했을 때는 싱글 스레드로 동작하는 Redis 특성상, 동시성 이슈가 발생하지 않았음
- PostgreSQL, 즉 RDBMS에서 트래픽이 몰릴 경우 복수의 트랜잭션이 경합 발생, 커밋되지 않은 값을 기반으로 업데이트 로직 수행
# A 트랜잭션이 조회 SQL문을 수행해서 제한인원의 여유를 확인
SELECT personnel FROM openchat WHERE room_id = X;
# A 트랜잭션이 업데이트 과정을 수행하기 바로 직전 B 트랜잭션이 조회 SQL문을 수행해서 제한인원의 여유를 확인
SELECT personnel FROM openchat WHERE room_id = X;
# A, B 트랜잭션 둘 다 업데이트 처리, 동시성 이슈 발생
UPDATE openchat SET personnel = personnel + 1 WHERE room_id = X;- Redis에서 동시성 이슈가 발생하지 않았던 이유는, Redis는 싱글 스레드 기반 동작 및 원자적 연산을 지원

Redis의 원자적 연산 중 하나인 INCR
- 그렇지만 Redis로 회귀하는 것은 데이터베이스의 사용 목적 및 역할별 분류라는 MSA의 취지를 지키지 못하는 것
- 리팩토링을 수행한 RDBMS 내에서 락을 걸어 동시성 제어를 수행하기로 결정
- 락을 구현할 수 있는 방법으로, 데이터베이스 레벨의 락과 외부 툴을 활용한 락 구현 방법이 있음
- PostgreSQL 레벨의 락과 Redis를 활용한 락에 대해 고민
| 특징 | 데이터베이스 레벨 락 | 외부 툴 락 (예: Redis) |
|---|---|---|
| 속도 | 상대적으로 느릴 수 있음 (디스크 I/O 필요) | 매우 빠름 (메모리 기반) |
| 원자성 | 트랜잭션을 통해 보장됨 | 명령어 단위로 원자적 처리 |
| 확장성 | 수직적 확장 필요 | 수평적 확장이 가능 |
| 복잡성 | 데이터베이스 내에서 간단하게 관리 가능 | 별도의 로직 필요 (락 획득 및 해제) |
| 재사용성 | 특정 데이터베이스에 종속됨 | 다양한 시스템에서 재사용 가능 |
| 지속성 | 데이터베이스 트랜잭션과 함께 지속됨 | 데이터의 지속성은 설정에 따라 달라짐 |
| 경합 조건 | 다양한 격리 수준에서 동작 | 원자적 명령으로 경합 조건 감소 |
| 락 경량성 | 보통 무겁고, 성능 저하 우려 있음 | 경량 락으로 빠른 경합 처리 가능 |
| 다중 노드 지원 | 복잡한 설정 필요 | 기본적으로 다중 노드 지원 |
| 유지 관리 | 데이터베이스 내에서 관리 | 별도의 툴과 인프라 관리 필요 |
- 채팅 애플리케이션처럼 실시간 처리 속도를 우선순위로 봐야 하고 수평적 확장이 중요함
- 인스턴스의 스케일링이 있을 때, 락의 공유를 통한 경합 처리를 수행해야 함
- 위의 사유로, Redis를 활용한 분산 락 구현을 통한 동시성 제어 결정
- Redisson 클라이언트 or Lettuce 클라이언트에 대한 고민
| 특징 | Redisson | Lettuce |
|---|---|---|
| 사용 편의성 | 고수준 API 제공, 쉽게 구현 가능 | 사용자가 원하는 대로 커스터마이징 필요 |
| 기능 | 분산 락, 큐, 캐시 등 다양한 데이터 구조 지원 | 비동기 및 반응형 API, 모듈형 설계 |
| 자동 해제 | 락 타임아웃 자동 관리 | 명시적 해제를 위한 코드 필요 |
| 비동기 처리 | 비동기 지원 없음 | 비동기 및 반응형 프로그래밍 지원 |
| 성능 | 성능이 우수하지만 비동기 처리에 비해 약간 느림 | 높은 성능과 낮은 지연 시간 제공 |
| 유연성 | 다양한 기능을 한 곳에서 지원 | 다양한 프로그래밍 패러다임 지원 |
| 추천 사용 경우 | 소규모 팀, 빠른 개발, 다양한 기능 필요시 | 고성능, 대규모 채팅 애플리케이션에 적합 |
- 락의 자동 해제에 있어 기능 구현이 상대적으로 간편한 Redisson을 1차적으로 채택 후, 성능 한계가 다가올 때 Lettuce로 전환 결정
- 락 기능을 제공하는 별도의 컴포넌트에, 현재 인원 증가 업데이트 메소드를 보유한 서비스를 의존성 주입
@Slf4j
@Component
@RequiredArgsConstructor
public class DistributedLockFacade {
private final RedissonClient redissonClient;
private final ChatGraphqlService chatGraphqlService;
public GraphqlDTO incrementPersonnel(String id) {
RLock lock = redissonClient.getLock(id);
try {
boolean available = lock.tryLock(10, 1, TimeUnit.SECONDS);
if (!available) {
log.error("락 획득 실패");
return null;
}
log.info("락 획득 성공");
return chatGraphqlService.incrementPersonnel(id);
} catch (InterruptedException e) {
log.error("락 획득 예외 발생: {}", e.getMessage());
throw new RuntimeException(e);
} finally {
log.info("락 잠금 해제");
lock.unlock();
}
}
}- 해당 코드로 GraphQL 호출 컨트롤러에 주입 후, 다시 JUnit 기반으로 테스트 수행 결과 동시성 제어 확인
- 문제 해결

Redisson 기반 분산 락 구현으로 동시성 제어
- 채팅 애플리케이션의 보편적인 기능 중 하나인 읽지 않은 메세지 확인 기능 구현을 구상
- 이를 위해 채팅과 관련된 로직으로 구독과 접속을 분리해서 생각
- 구독 메타데이터는 전술한 RDBMS로 관리하고 접속 세부 데이터는 실시간 업데이트가 유리한 NoSQL로 관리
- 구현 시점에서는 접속과 메세지를 같이 관리하는 방향으로 구상

접속 & 메세지 관리 플로우
- 접속과 메세지의 강한 결합으로 인해 NoSQL에서의 관리가 매우 복잡해짐
- 실시간 접속 관리를 Redis에서 맡은 상황에서 MongoDB 역시 접속 관리를 같이 도맡으면서 읽지 않은 메세지 보관 중복 처리
- NoSQL 내에서도, 심지어 NoSQL과 RDBMS의 책임 분리가 희석되면서 상호 서비스 의존성이 강하게 잡힘



NoSQL & RDBMS 책임 분리 희석 문제 발생
- 뿐만 아니라, 사용자별로 접속 관리가 이뤄지고 접속과 메세지를 결합한 아키텍처를 구상함으로 인해 사용자별로 읽지 않은 메세지 처리가 이뤄짐
- 자연스럽게 트래픽이 몰리게 되면 중복된 데이터를 관리하면서 리소스 낭비가 심해지고 로직의 중복 수행이 많아질 것으로 예상

사용자별 읽지 않은 메세지 중복 처리
- 당시의 문제는 Polyglot Persistence 패턴을 준수하지 않았던 것
- MSA에 있어 각 서비스가 독립적이라는 개념은, 데이터베이스 레벨까지 포함되어야 함

이커머스 플랫폼을 예시로 한 Polyglot Persistence
- 기능 구현 당시, 인스턴스 간 상황 공유 수단을 NoSQL에 최대한 위임시키면서 데이터 정합성을 처리하려고 함
- 해당 문제를 파악 후, 데이터베이스 레벨의 격리를 구축하며 인스턴스 간 상호 데이터 송수신을 위한 GraphQL 도입 결정
- 상대적으로 REST API 호출에 비해 유연성과 효율성을 챙길 수 있음
| 특성 | REST API | GraphQL |
|---|---|---|
| 데이터 페칭 | 여러 엔드포인트로 다수 요청 필요 | 단일 요청으로 필요한 데이터만 정확히 페칭 |
| 응답 크기 | 고정된 응답 구조로 불필요한 데이터 포함 가능 | 필요한 필드만 선택하여 응답 크기 최소화 |
| 네트워크 트래픽 | 여러 요청으로 트래픽 증가 가능 | 요청/응답 수 줄어들어 트래픽 감소 가능 |
| N+1 문제 | 여러 번의 추가 요청으로 발생할 수 있음 | 단일 요청으로 N+1 문제 해결 가능 (DataLoader 사용 시) |
| 오버페칭/언더페칭 | 불필요한 데이터 수신 or 필요한 데이터 부족 | 클라이언트가 정확히 필요한 데이터만 요청 |
| 서버 부하 | 여러 엔드포인트로 인한 서버 부하 가능 | 한 번의 복잡한 요청으로 서버 부하 가능성 있음 |

아키텍처 변환 & Polyglot Persistence 실현
- 메세지의 중복 처리를 막기 위해, 메세지 처리의 중앙화를 위한 엔티티 작성
- 메세지 인스턴스에서 PostgreSQL을 기반으로 관리 후, 필요한 인스턴스에서 GraphQL을 통한 조회
// message instance
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(name = "chat_message")
public class ChatMessage {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
@Column(name = "chat_id")
private String chatId;
@Column(name = "type")
private ChatMessageType type;
@Column(name = "usernmae")
private String username;
@Column(name = "message")
private String message;
@Column(name = "created")
private LocalDateTime createdAt;
public ChatMessage(ChatMessageDTO dto) {
this.chatId = dto.getChatId();
this.type = dto.getType();
this.username = dto.getUsername();
this.message = dto.getMessage();
this.createdAt = dto.getCreatedAt();
}
}

채팅 메세지 RDBMS로 중앙 관리
type ChatUserSubscription {
id: ID!
chatId: String!
email: String!
}
type GraphqlChatMessageDTO {
chatId: String!
type: ChatMessageType!
username: String!
message: String!
createdAt: String!
}
enum ChatMessageType {
ENTER
LEAVE
MESSAGE
}
type Query {
subscriptionsByEmail(email: String!): [ChatUserSubscription!]!
getChatMessages(chatId: String!, exitTime: String!): [GraphqlChatMessageDTO]
}- 읽지 않은 메세지의 조회 처리에 있어 사용자별로 조회 기준이 다를뿐, 내용은 동일하기 때문에 퇴장 시간을 기준으로 조회
- 참여자 인스턴스에서 각 채팅방 별로 참여자의 접속 여부, 퇴장 시간을 map 자료구조로 MongoDB를 통해 관리

MongoDB를 통해 채팅방별 참여자 접속 및 퇴장 시간 관리
- 퇴장 시간을 GraphQL을 통해 받아와 메세지 인스턴스에서 퇴장 시간부터 현재 시간까지의 메세지들을 일괄 조회
- 접속하지 않은 시간 사이에 이뤄진 메세지 송수신이 곧 읽지 않은 메세지
- 조회 속도의 향상을 위한 네이티브 쿼리 활용
@Repository
public interface ChatMessageRepository extends JpaRepository<ChatMessage, Long> {
// 네이티브 쿼리 적용
@Query(value = "SELECT * FROM chat_message WHERE chat_id = :chatId AND created >= :startTime AND created <= :endTime", nativeQuery = true)
List<ChatMessage> findMessagesByChatIdAndTimeRange(String chatId, LocalDateTime startTime, LocalDateTime endTime);
}- ws 프로토콜이 이뤄지는 메세지 인스턴스에서 읽지 않은 메세지를 GraphQL로 얻어와 채팅방 인스턴스에서 REST API를 통해 내보냄
- 프로토콜 간 간섭 방지 목적을 위한 추가적인 조치
- 문제 해결

RDBMS & GraphQL 기반 읽지 않은 메세지 처리
- 채팅 참여자 관리는 참여자 인스턴스에서 별개로 관리하지만, 업데이트 로직은 다른 인스턴스의 이벤트와 연계되어 발생
- 이벤트의 실시간 트리깅은 참여자 인스턴스로 Redis Pub Sub을 통해 레코드로 전파됨
public record ChatUserReadDTO(String chatId, String email, Boolean read, Boolean leave) {
}

메세지 & 참여자 표시 플로우
- 참여자 인스턴스 역시 웹소켓을 활용하기 때문에 웹소켓의 구독 과정이 필요함
- 웹소켓의 구독 이후에, Redis Pub Sub으로 전달받은 레코드를 바탕으로 참여자 리스트를 업데이트함

Redis Pub Sub으로 전달이 먼저 이뤄지고 웹소켓 구독이 이뤄지는 순서 역전 문제

이벤트 처리 순서의 보장이 이뤄지지 않음으로 인한 참여자 데이터 손실
- 위의 순서가 기본 전제로 이뤄진 후, 참여자 리스트를 클라이언트로 내보내줘야 하는 것이 참여자 표시 기능의 순서
- 전술한 이벤트 처리 순서가 보장되지 않으면서 참여자 리스트 손실 발생
- 웹소켓 구독 이벤트와 Redis Pub Sub을 통한 데이터 수신 이벤트는 비동기적으로 처리됨
- MSA 내의 여러 인스턴스 간에 발생하는 이벤트를 순차적으로 처리하는 과정이 포함되어야 함
- Kafka, RabbitMQ, AWS SQS 등을 통해 구현할 수 있음

이벤트 큐의 대략적인 흐름
- 해당 문제는 서버 레벨에서 발생하는 이벤트 순서 보장 문제
- 그렇기 때문에 직접 코드로 이벤트 큐 구현 결정
- 이벤트 요소의 고유 식별값을 부여한 후, Redis Pub Sub으로부터의 수신 이벤트와 웹소켓 구독 이벤트의 상호간 추적 필요
- 웹소켓의 구독 완료 여부를 Redis Pub Sub 측에서 파악해야 함과 동시에 구독이 되지 않으면 이벤트 큐로 데이터를 전달해야 함
- 웹소켓 구독은 서버 레벨에서 이뤄지고, 데이터 수신은 곧 클라이언트로의 데이터 송신이므로 클라이언트 레벨에서 이뤄짐
- 각각의 고유 식별값은 세션 ID와 채팅방 ID로 지정
@Slf4j(topic = "WEBSOCKET_EVENT_LISTENING")
@Controller
@RequiredArgsConstructor
public class WebSocketEventListener {
private final EventQueueService eventQueueService;
@EventListener
public void handleWebSocketSubscribeEvent(SessionSubscribeEvent event) throws HttpResponseException {
StompHeaderAccessor accessor = StompHeaderAccessor.wrap(event.getMessage());
String destination = accessor.getDestination();
String sessionId = accessor.getSessionId();
if (destination == null || !destination.startsWith("/sub/participant/")) {
throw new HttpResponseException(
HttpStatus.SC_SERVICE_UNAVAILABLE,
"Server Error, 구독 경로 확인 필요"
);
}
log.info("구독 시점의 세션 아이디: {}", sessionId);
String id = destination.replaceFirst("/sub/participant/", "");
log.info("구독할 때의 경로 아이디 갖고오기: {}", id);
// ...- 구독이 이뤄질 때 발생하는
SessionSubscribeEvent를StompHeaderAccessor로 감싸서 구독 경로를 추출 - 이벤트 객체에서 세션 ID, 구독 경로에서 채팅방 ID를 추출 후, map 자료구조로 둘을 매핑시킴
@Slf4j(topic = "QUEUE_SERVICE")
@Component
@RequiredArgsConstructor
public class EventQueueService {
private final Map<String, String> sessionIdChannelMap = new ConcurrentHashMap<>();
private final Map<String, Boolean> subscriptionFlags = new ConcurrentHashMap<>();
private final Map<String, Queue<List<UserReadDTO>>> messageQueue = new ConcurrentHashMap<>();
private final SimpMessageSendingOperations messagingTemplate;
// 세션 아이디 - 채널 저장
public void setSessionIdChannelMap(String sessionId, String chatId) {
sessionIdChannelMap.put(sessionId, chatId);
}
// ...- 이벤트 큐의 필드로
ConcurrentHashMap구조를 채택, 객체 공유 현상 방지 - 이를 통해 채팅방 ID를 통해서 현재 세션이 구독 상태인지, 종료 상태인지를 Redis Pub Sub 관련 코드에서도 추적 가능
@Slf4j
@RequiredArgsConstructor
@Service
public class RedisMessageListenerService implements MessageListener {
private final EventQueueService eventQueueService;
private final SimpMessageSendingOperations messagingTemplate;
// ...
@Override
public void onMessage(Message message, byte[] pattern) {
String channel = new String(message.getChannel());
String id = channel.replaceFirst("chat_", "");
String body = new String(message.getBody());
log.info("채널 확인: {} // 파싱: {}", channel, id);
try {
// ...
if (eventQueueService.isSubscriptionComplete(id)) {
// 구독 완료 -> 바로 전송
log.info("{}번 구독 확인, 송신", id);
messagingTemplate.convertAndSend("/sub/participant/" + id, data);
} else {
// 구독 미완료 -> 대기열에 저장
log.info("{}번 구독 미완료, 데이터 대기열에 저장: {}", id, data);
eventQueueService.enqueueMessage(id, data);
}@Slf4j(topic = "QUEUE_SERVICE")
@Component
@RequiredArgsConstructor
public class EventQueueService {
private final Map<String, String> sessionIdChannelMap = new ConcurrentHashMap<>();
private final Map<String, Boolean> subscriptionFlags = new ConcurrentHashMap<>();
private final Map<String, Queue<List<UserReadDTO>>> messageQueue = new ConcurrentHashMap<>();
private final SimpMessageSendingOperations messagingTemplate;
// 세션 아이디 - 채널 저장
public void setSessionIdChannelMap(String sessionId, String chatId) {
sessionIdChannelMap.put(sessionId, chatId);
}
// 세션 아이디 - 채널 및 채널의 플래그, 큐 삭제
public void removeAllFields(String sessionId) {
String chatId = sessionIdChannelMap.get(sessionId);
if (chatId == null) {
throw new IllegalArgumentException("채팅 아이디가 세션 맵에 저장 안 됨");
}
subscriptionFlags.remove(chatId);
messageQueue.remove(chatId);
sessionIdChannelMap.remove(sessionId);
}
// 구독 완료 처리
public void onSubscriptionComplete(String clientId) {
subscriptionFlags.put(clientId, true);
flushQueueForClient(clientId);
}
// 구독 완료 여부 확인
public boolean isSubscriptionComplete(String clientId) {
return subscriptionFlags.getOrDefault(clientId, false);
}
// 대기열에 메시지 저장
public void enqueueMessage(String clientId, List<UserReadDTO> message) {
messageQueue.computeIfAbsent(clientId, k -> new ConcurrentLinkedQueue<>()).add(message);
}
// 대기열 처리
private void flushQueueForClient(String clientId) {
log.info("{}번 큐 플러시 과정 돌입", clientId);
Queue<List<UserReadDTO>> queue = messageQueue.get(clientId);
if (queue != null) {
while (!queue.isEmpty()) {
log.info("{}번 큐 데이터 산입 확인: {}", clientId, queue.size());
List<UserReadDTO> message = queue.poll();
// 대기열에 쌓인 메시지를 클라이언트로 전송하는 로직
sendMessageToClient(clientId, message);
log.info("*** 데이터 송신 완료 ***");
}
}
}
private void sendMessageToClient(String clientId, List<UserReadDTO> message) {
// WebSocket 클라이언트로 메시지를 전송하는 로직
log.info("대기열 이후 최종 메세지 송신: {}번", clientId);
messagingTemplate.convertAndSend("/sub/participant/" + clientId, message);
}
}- 구독이 이미 완료됐으면 바로 클라이언트에 데이터를 송신하고, 구독이 완료되지 않으면 이벤트 큐에 데이터를 저장해둠
- 최종적으로 채팅방 ID를 통해 세션의 구독 여부를 추적 후, 구독이 완료되면 클라이언트로 데이터 전파하는 순서를 유지시킴
- 구독이 종료되면
SessionDisconnectEvent를 통해 세션 ID를 추출해서 이벤트 큐에 저장된 세션 ID 및 매핑된 채팅방 ID 삭제 처리 - 문제 해결

이벤트 리스너 기반 앱 레벨의 이벤트 큐 구축