This project is an educational exercise for hands on big data gathering and processing (ETL) using common big data tools: Kafka, Spark, Airflow (both on prem & in AWS WMAA), AWS Kinesis and DataBricks.
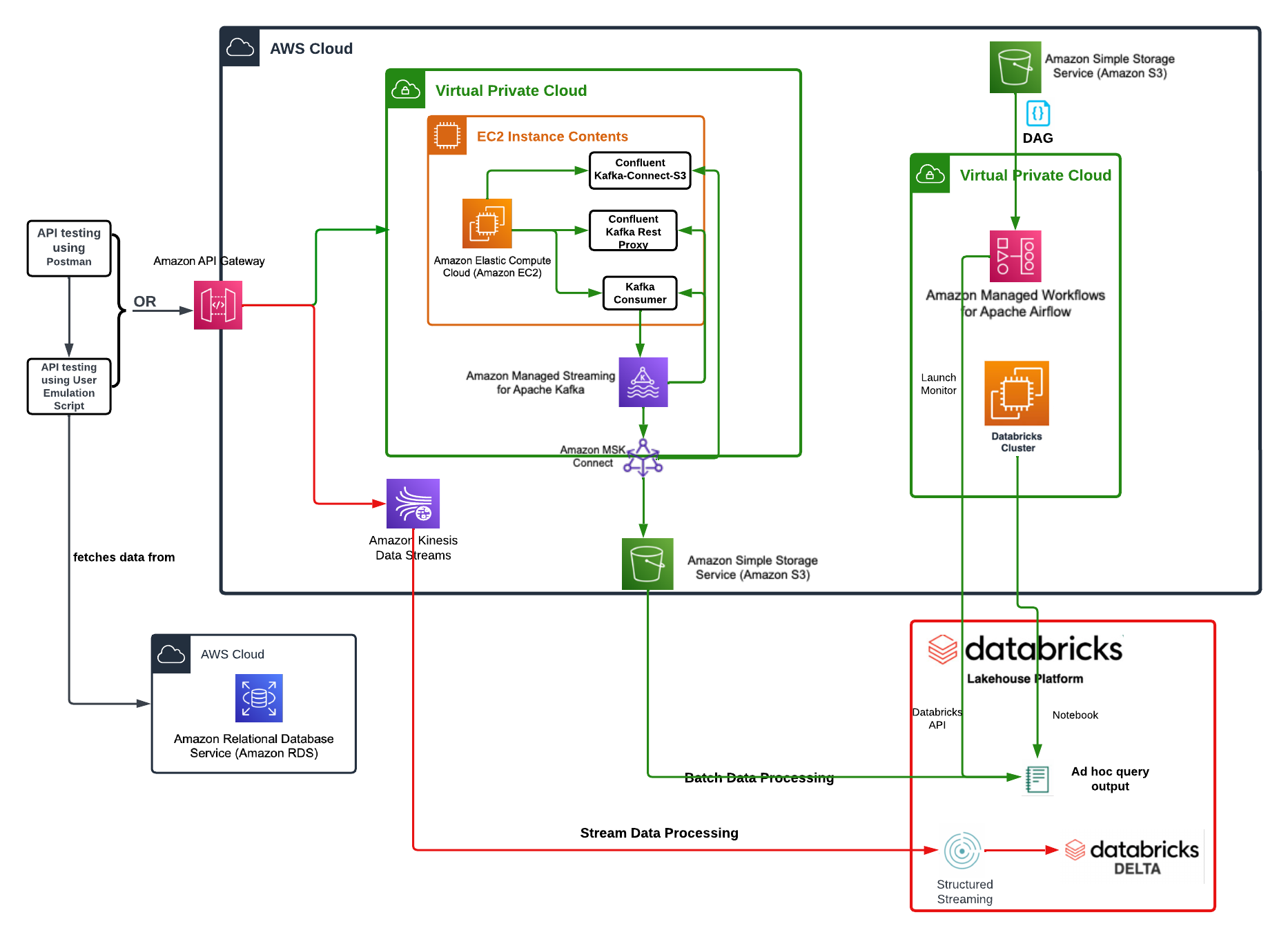
The Pinterest Data Pipeline is takes example Pinterest user generated data through an ETL process. This is handled in two ways. First through the processes of handling "legacy" data from an external database to an S3 data store for cleansing ad-hock reporting. Secondly, data is handled with data streams.
- Using an EC2 instance via SSH, SSHFS and SCP.
- Local configuration of Kafka topics via command line.
- Basic MSK configuration in the AWS console.
- Kinesis stream connectivity with API Gateway
- Airflow to schedule jobs both on prem and in AWS (WMAA)
- Use of Databricks to:
- Connect to AWS S3 bucket
- Load a series of files into a Spark dataframe
- Connect to an AWS Kinesis data stream
- Using PySpark to clean the data/streams and provide basic query results for static data
- Store data transformed in DataBricks data lake
Since this project is connected directly to Github via the DataBricks Repo feature, DataBricks removes all notebook output before committing to Github, the reporting output can be seen in [this snapshot of the notebook] (documentation_resources/AiCore%20Pinterest%20project.ipynb) taken locally from DataBricks
While a good portion of the system could be handled with SQL, the focus was to maximise the use of Python on top of Spark to demonstrate the concepts learned. Only Python and some Bash scripts are used for development of this project.
The project has the following folder structure with the naming rule is any script with a 0 as the first character in the file name is for initial configutaton and only to be run once. More details will be explained in the "Set-up & usage instructions" section of this file. Note: The 0 prefixed set-up file naming convention excludes files starting with 0x115306525 which are naming requirements for this project AWS access.
- DataBricks
- PinterestTransformations.py Data cleaning/transformation functions used in the Jypiter notebooks
- AiCore Pinterest project.ipynb First set of milestones simulating the legacy data handling and report requests
- AiCore Read Kinesis.ipynb Cloud data stream handing using DataBricks and AWS technologies
- MWAA_S3_bucket
- 0x115306525_dag.py DAG file for Airflow in AWS (MWAA) to execute "AiCore Pinterest project.ipynb"
- documentation_resources Notebooks with the reporting output & documentation support files
- Kineses
- 0create_kinesis_streams.py Code to be run once to create the Kinesis data streams in AWS
- test_stream_api.py Simple tests to check the APIs are in place
- user_posting_emulation_streaming.py Simulates user interaction with results going to Kinesis streams
- legacy_simulation See the "Set-up & usage instructions" for more information on these files
- run_this_to_send_messages_after_ec2_kafka_started.sh
- run_on_ec2
- 0setup_topics_and_connectors.sh
- 1run_this_on_kafka_ec2.sh
The on premise software for processing of legacy data plus initial exploratory testing was done on Ubuntu Linux using Conda to manage dependencies.
The main components are:
- Java JRE 8
- Apache AirFlow
- Apache Spark
- Apache Kafka via Confluent
With the software security credentials and other minor configurations set as per the AiCore Data Engineering notebook instructions, the topics for on premise legacy data topics can be created by the following script in the legacy_simulaiton/run_on_ec2 folder:
0setup_topics_and_connector.sh
Shell scripts are provided to prevent errors and to aid in returning to this process in the future. To load the data in the legacy database into an S3 bucket using Kafka, execute the following on the EC2 instance within the VPC:
1run_this_on_kafka_ec2.sh
This will execute the following commands:
cd ~/confluent-7.2.0/bin/
./kafka-rest-start /home/ec2-user/confluent-7.2.0/etc/kafka-rest/kafka-rest.properties
The next script can be run on the same computer, though it is recommended to run it on another box:
2run_this_to_send_messages.sh
This will execute the following:
python3 user_posting_emulation.py
Data will randomly be sent to the data streams for processing.
This was the final project in the AI Core Data Engineering path which was certainly more of what we would have called "tech ops" in my previous organisation. Big data tools were entirely new to me. Now with some basic hands on experience, I know some of the capabilities and feel confident with our notebooks that I could have these tools up and running.
Some research would still be required before making a professional recommendation on the use of these technologies largely in terms of execution performance. Say that, even without further studies I can say that much of what has been taught and used here would allow a fairly rapid prototype for data handling. I'm grateful for the experience and look forward to applying these skills and learning more.