The World Wide Web or the "Web" is the universe of network-accessible information. All this information present in a raw format on the Web. What if you want a way to ingest raw information on the web for any given topic and provide insights and visualiations for the same. This code pattern does, just that taking an example of performing analytics on Startups.
Being in the age of start-ups. There is a rapid increase in a number of companies providing skilled services. We can scrape information about such companies and evaluate their success stories based on the number of articles or live use cases appeared in news portals.
Suppose, we want to understand the current startups in a particular technology, say Machine Learning, this code pattern will evaluate its impact in the industry, on the basis of:
- How many times it has appeared on News?
- Whether it has a Wikipedia page or not?
- Whether they have Tech blogs or not?
- Whether they are active on Social Media (Twitter, Medium, etc..)?
This unstructured data once scraped (extract information from web) is processed through Watson NLU and converted to structured data. This is fed to SPSS, which can be used to understand the data and perform Analytics to determine if all the factors (as mentioned above) appear in a company, thereby computing a popularity score. Once, all the Analytics is performed this Code Pattern also provides a user friendly and interactive Dashboard visualisation of the data, giving insights of the data and complete ease to simplify the decision making process.
NOTE: Company names have been anonymised and replaced with names of Plants so as to not put down any one company, but rather provide a methodology to perform analytics on data from the web.
When the reader has completed this Code Pattern, they will understand how to:
- Create and Run a Python Notebook on Watson Studio.
- Scrape data using BeautifulSoup.
- Use Watson Natural Language Understanding to extract metadata from Python Notebook.
- Generate a CSV and Convert to a Table in Db2 Warehouse.
- Load and analyze data in SPSS Modeler.
- Load and Visualize data in the Embedded Dashboard.

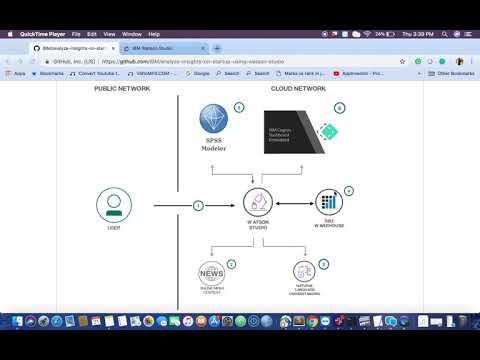
- The user creates and runs a Python Notebook on Watson Studio.
- The Notebook scrapes latest news on Startups.
- The Scraped Information is sent to Watson Natural Language Understanding to extract Keywords, Entities, Sentiments and its respective confidence scores.
- The Results of NLU are compiled into a csv file which is further converted to a table in Db2 Warehouse.
- The table created is ingested in SPSS to do some analytics and return a score against each company. The updated table is then saved back to Db2 Warehouse.
- Finally, the table generated in Db2 Warehouse is fed to the Dashboard, giving insightful visualisation.
- Scrape data from the web using Python and AI
- Predictive analytics using SPSS with database warehouse connection
- A filled out companies_list.json, see below for more information.
This JSON file contains a list of companies you want to analyze. The format is shown below, follow the template and each company in the list will be analyzed.
{
"companies": [
{
"Company_Name_1": [
"Company_Description_1",
"Company_URL_1"
]
},
{
"Company_Name_2": [
"Company_Description_2",
"Company_URL_2"
]
}
]
}Note: Pls do not enter more than 10 companies in the json file.
- Setup the Notebook on your Watson Studio Project
- Setup the SPSS Modeler on your Watson Studio Project
- Setup the Embedded Dashboard on your Watson Studio Project
- Once, you have created your Waston Studio Project, click on
Add Notebook>From URLand copy this URL:
https://github.com/IBM/analyze-insights-on-startup-using-watson-studio/blob/master/code/Scrape_Startup_Insights.ipynb-
Ensure you have created and copied the Watson Natural Language Understanding service as instructed in the Scrape data from the web using Python and AI, and paste the service credentials in your notebook in the cell below
2.1 Add your service credentials from IBM Cloud for the Watson services.
-
Ensure you have created and connected your Db2 Warehouse instance to the current Watson Studio Project as instructed in the Predictive analytics using SPSS with database warehouse connection, and insert the credentials in the section
2.2 Add your service credentials for Db2. Ensure the credentials is saved ascredentials_1.
-
In your
credentials_1variable note down theusernamefield, like DASHXXXX. This will be later used in various instances in this pattern. -
In the notebook go to the last section
Store and Add table in Db2 Warehouse, and replaceDASHXXXXwith the your schema name.



Adding your companies_list.json data
-
Download the file companies_list.json and modify it to look up companies you want to analyze.
-
On the top right corner click on the
10/01tab, click onbrowse, and choose the newly modifiescompanies_list.jsonfile. -
In section 3 of the notebook, the cell under
Insert Pandas Dataframe of the company_list.json file. Ensure the dataframe is saved asdf_data_1.
- Click the play button in Watson Studio to run the notebook.
NOTE: Since Data is being scraped from the web certain cells in the notebook will take some time to execute.
-
Download the Analyze_Startup_Data.str stream file from the repo.
-
Open your Watson Studio from IBM Cloud Dashboard and Navigate to the created project.
-
Click on the
Add to Projectbutton and selectModeller Flow.
-
Click on the
From Filetab and upload the downloaded stream file.
-
Once, the modeler is opened. Double Click on the
Data Assetnode and click on theChange Data Assetbutton.
-
Move to
Connectiontab and select theDb2 Warehouseand select the correctSchema(usually starting withDASHXXXX) and the created tableDATA_FOR_SPSS.
-
Similarly for the final node,
Data_Export, follow the same steps as above and select theDATA_FOR_COGNOStable.
-
Before saving the changes for the node, make sure the value for
If the datset already existsis set toReplace the data set, as shown in the image above. -
Run the Modeler Flow, by clicking the play button. The data would now be saved back to your Db2 Warehouse instance.





Note: At this stage you may receive an error of DB2Exception CLI0109E String data right truncation SQLSTATE 22001. This may due to unusually long URLs. However, you can treat it as a Warning and go ahead with the next steps.
-
Download the Starup_Analytics_Dashboard.json config file and open it in any editor.
-
Search for the term
DASH_SCHEMA_NAMEand replace any occurrences of it with your Db2 Warehouse schema name.
-
If you have changed the table name from
DATA_FROM_COGNOSsearch for the termDATA_FOR_COGNOSand replace any occurrences of it with your Db2 Warehouse table name.
-
-
Go to your Watson Studio project and click on
Add to Projectbutton to add the Embedded Dashboard Analytics service.
-
Select
From fileoption to upload the modifiedStarup_Analytics_Dashboard.jsonfile, select the dashboard service and then click on save.




If you don't have the Cognos Dashboard Embedded Service instance perform the following steps:
-
Click on
Associate a Cognos Dashboard Embedded Service Instance.
-
Choose the
LiteorPay-as-you-goplan as per your requirement and click onCreate.
-
Click on
Reloadand thenCreatebutton. -
Next, Click on
Connections>Db2 Warehouse>Your_Schema>DATA_FOR_COGNOS. This will load the Interactive Dashboard.


NOTE: While opening the Dashboard you may receive a warning about missing data, if this happens click on the
Re-linkbutton.

This Code Pattern provides a solution:
- That extracts live unstructured data about startups
- The impact startups create in the industry with the help of Watson Natural Language Understanding and converted to a structured data.
- The data is then fed into IBM SPSS Predictive Analytics to get meaningful insights and ratings.
- Finally, providing insights and visualisation from the provided input using Watson Embedded Dashboard.
The end-to-end Startup Analytics Dashboard provides users complete insights on startups and showcases the predicted information in the form of charts/widgets using IBM Watson Embedded Dashboard Service which hosted on Watson Studio. This enables a user to build their own sophisticated visualizations to communicate the insights from their discovered analytics data, furthermore the created dashboard can be shared among various users.
After completing the setup, you will see the dashboard with four interactive widgets as follows:

- Company score based on relevance: A view showing the most popular companies at a larger size than the smaller ones.
- Total number of articles appeared in the web of a company: A view showing the factors affecting the popularity of a startup on the web (amongst news articles, tech blogs, social media and so on).
- News Concept Relevance: Gives a broad overview of main topics of the articles across the companies, by the percentage of its relevance.
- News Sentiment Analysis by Company: Gives an overall analysis of the tone in which the article was written, to understand the impact (whether positive or negative or neutral) a given company has in the industry.
See TROUBLESHOOTING.md.
This code pattern is licensed under the Apache License, Version 2. Separate third-party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 and the Apache License, Version 2.