💥 VLT_SCAR/VLT_TT is accepted by NeurIPS2022.
💥 CNNInMo/TransInMo is accepted by IJCAI2022.
💥 CSTrack is accepted by IEEE TIP.
💥 OMC is accepted by AAAI2022. The training and testing code has been released in this codebase.
💥 AutoMatch is accepted by ICCV2021. The training and testing code has been released in this codebase.
💥 CSTrack ranks 5/4000 at Tianchi Global AI Competition.
💥 Ocean is accepted by ECCV2020. [OceanPlus] is accepted by IEEE TIP.
💥 SiamDW is accepted by CVPR2019 and selected as oral presentation.
- [NeurIPS2022] VLT_SCAR/VLT_TT
- [IJCAI2022] CNNInMo/TransInMo
- [ICCV2021] AutoMatch
- [ECCV2020] Ocean and Ocean+
- [CVPR2019 Oral] SiamDW
- SOT (or master): for our SOT trackers
- MOT: for our MOT trackers
- v0: old codebase supporting
OceanPlusandTensorRT testing.
Please clone the branch to your needs.
experiments:training and testing settingsdemo:figures for readmedataset:testing datasetdata:training datasetlib:core scripts for all trackerssnapshot:pre-trained modelspretrain:models trained on ImageNet (for training)tracking:training and testing interface
$SOTS
|—— experimnets
|—— lib
|—— snapshot
|—— xxx.model
|—— dataset
|—— VOT2019.json
|—— VOT2019
|—— ants1...
|—— VOT2020
|—— ants1...
|—— ...
| Model |
OTB2015 |
GOT10K |
LaSOT |
TNL2K |
TrackingNet |
NFS30 |
TOTB | VOT2019 | TC128 | UAV123 | LaSOT_Ext | OTB-99-LANG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SiamDW | 0.670 | 0.429 | 0.386 | 0.348 | 61.1 | 0.521 | 0.500 | 0.241 | 0.583 | 0.536 | - | - |
| Ocean | 0.676 | 0.615 | 0.517 | 0.421 | 69.2 | 0.553 | 0.638 | 0.323 | 0.585 | 0.621 | - | - |
| AutoMatch | 0.714 | 0.652 | 0.583 | 0.472 | 76.0 | 0.606 | 0.668 | 0.322 | 0.634 | 0.644 | - | - |
| CNNInMo | 0.703 | - | 0.539 | 0.422 | 72.1 | 0.560 | - | - | - | 0.629 | - | - |
| TransInMo | 0.711 | - | 0.657 | 0.520 | 81.7 | 0.668 | - | - | - | 0.690 | - | - |
| VLT_SCAR | - | 0.610 | 0.639 | 0.498 | - | - | - | - | - | - | 0.447 | 0.739 |
| VLT_TT | - | 0.694 | 0.673 | 0.531 | - | - | - | - | - | - | 0.484 | 0.764 |
[Paper] [Raw Results] [Training and Testing Tutorial]
VLT explores a different path to achieve SOTA tracking without complex Transformer, i.e., multimodal Vision-Language tracking. The essence is a unified-adaptive Vision-Language representation, learned by the proposed ModaMixer and asymmetrical networks. The experiments show our approach surprisingly boosts a pure CNN-based Siamese tracker to achieve competitive or even better performances compared to recent SOTAs, which also benefits Transformer-based trackers. We hope that this work inspires more possibilities for future tracking beyond Transformer.

[Paper] [Raw Results] [Training and Testing Tutorial]
CNNInMo/TransInMo introduces a novel mechanism that conducts branch-wise interactions inside the visual tracking backbone network (InBN) via the proposed general interaction modeler (GIM). We show that both CNN and Transformer backbones can benefit from InBN, with which more robust feature representation can be learned. Our method achieves compelling tracking performance by applying the backbones to Siamese tracking.

[Paper] [Training and Testing Tutorial]
OMC introduces a double-check mechanism to make the "fake background" be tracked again. Specifically, we design a re-check network as the auxiliary to initial detections. If the target does not exist in the first-check predictions (i.e., the results of object detector), as a potential misclassified target, it has a chance to be restored by the re-check network, which searches targets through mining temporal cues. Note that, the re-check network innovatively expands the role of ID embedding from data association to motion forecasting by effectively propagating previous tracklets to the current frame with a small overhead. Even with multiple tracklets, our re-check network can still propagate with one forward pass by a simple matrix multiplication. Building on a strong baseline CSTrack, we construct a new one-shot tracker and achieve favorable gains.

[Paper] [Raw Results] [Training and Testing Tutorial] [Demo]
AutoMatch replaces the essence of Siamese tracking, i.e. the cross-correlation and its variants, to a learnable matching network. The underlying motivation is that heuristic matching network design relies heavily on expert experience. Moreover, we experimentally find that one sole matching operator is difficult to guarantee stable tracking in all challenging environments. In this work, we introduce six novel matching operators from the perspective of feature fusion instead of explicit similarity learning, namely Concatenation, Pointwise-Addition, Pairwise-Relation, FiLM, Simple-Transformer and Transductive-Guidance, to explore more feasibility on matching operator selection. The analyses reveal these operators' selective adaptability on different environment degradation types, which inspires us to combine them to explore complementary features. We propose binary channel manipulation (BCM) to search for the optimal combination of these operators.
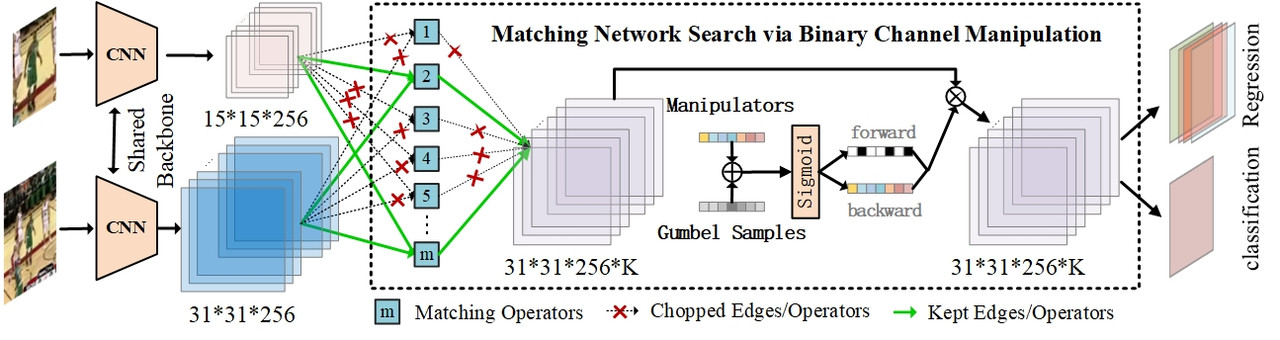
[Paper] [Raw Results] [Training and Testing Tutorial] [Demo]
Ocean proposes a general anchor-free based tracking framework. It includes a pixel-based anchor-free regression network to solve the weak rectification problem of RPN, and an object-aware classification network to learn robust target-related representation. Moreover, we introduce an effective multi-scale feature combination module to replace heavy result fusion mechanism in recent Siamese trackers. This work also serves as the baseline model of OceanPlus. An additional TensorRT toy demo is provided in this repo.

[Paper] [Raw Results] [Training and Testing Tutorial] [Demo]
SiamDW is one of the pioneering work using deep backbone networks for Siamese tracking framework. Based on sufficient analysis on network depth, output size, receptive field and padding mode, we propose guidelines to build backbone networks for Siamese tracker. Several deeper and wider networks are built following the guidelines with the proposed CIR module.

[Paper] [Raw Results] [Training and Testing Tutorial] [Demo]
Official implementation of the OceanPlus tracker. It proposes an attention retrieval network (ARN) to perform soft spatial constraints on backbone features. Concretely, we first build a look-up-table (LUT) with the ground-truth mask in the starting frame, and then retrieve the LUT to obtain a target-aware attention map for suppressing the negative influence of background clutter. Furthermore, we introduce a multi-resolution multi-stage segmentation network (MMS) to ulteriorly weaken responses of background clutter by reusing the predicted mask to filter backbone features.

[Paper] [Training and Testing Tutorial] [Demo]
CSTrack proposes a strong ReID based one-shot MOT framework. It includes a novel cross-correlation network that can effectively impel the separate branches to learn task-dependent representations, and a scale-aware attention network that learns discriminative embeddings to improve the ReID capability. This work also provides an analysis of the weak data association ability in one-shot MOT methods. Our improvements make the data association ability of our one-shot model is comparable to two-stage methods while running more faster.

If you are interested in our work or have any questions, please contact me at 201921060415@std.uestc.edu.cn.
Other trackers, coming soon ...
https://github.com/StrangerZhang/pysot-toolkit
...