Search and RAG are just tools, verification is the key. The more the truth is debated, the clearer it becomes.
基础性的框架搭建与最小闭环已经实现了,接下来中需要对每个模块进行一定的优化,重要性排行如下:
- 评分模块(Agent或者机器学习方法实现,初步通过微调大模型实现)
- 策略模块(Agent或者机器学习方法实现)
- 细粒度的问答,比如针对特定角度,同时要有细粒度的论证支撑。
- 集成Langchain Agent
- 集成MetaGPT的单Agent
- 集成RAG Debater
- 集成Search Debater
- 集成人类输入Debater
- 思考一下汇总Node
- 优化提示词
- 思考一下在Neo4j中的推理
- requirements.txt:项目的第三方依赖。
- Research: 项目功能实现前技术测试。
- Test: 项目功能实现后测试,也可看做使用样例。
- Debater:即Agent智能体,可以集成市面上的多智能体或者RAG工具等,作用是生成Node中的内容。
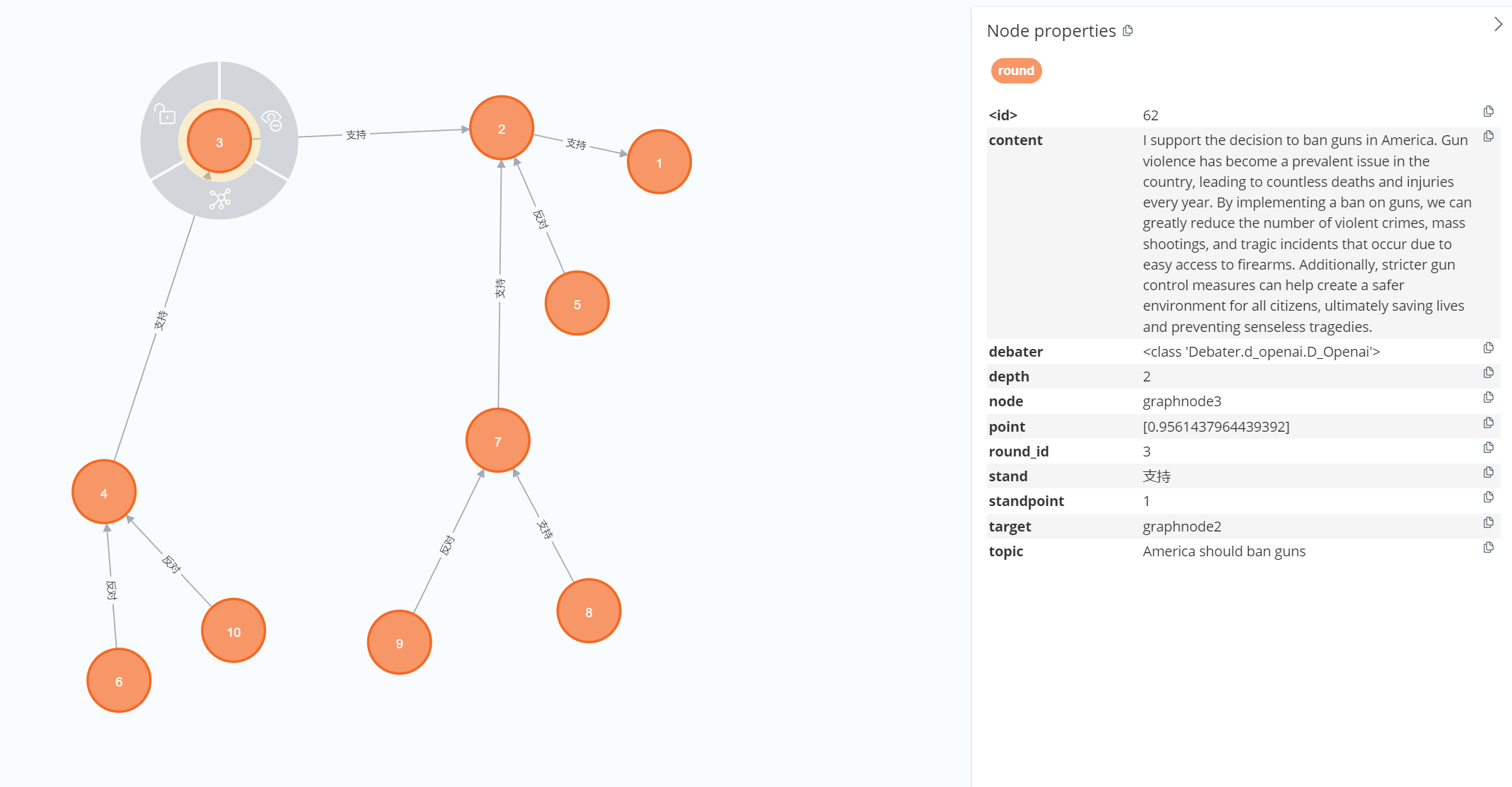
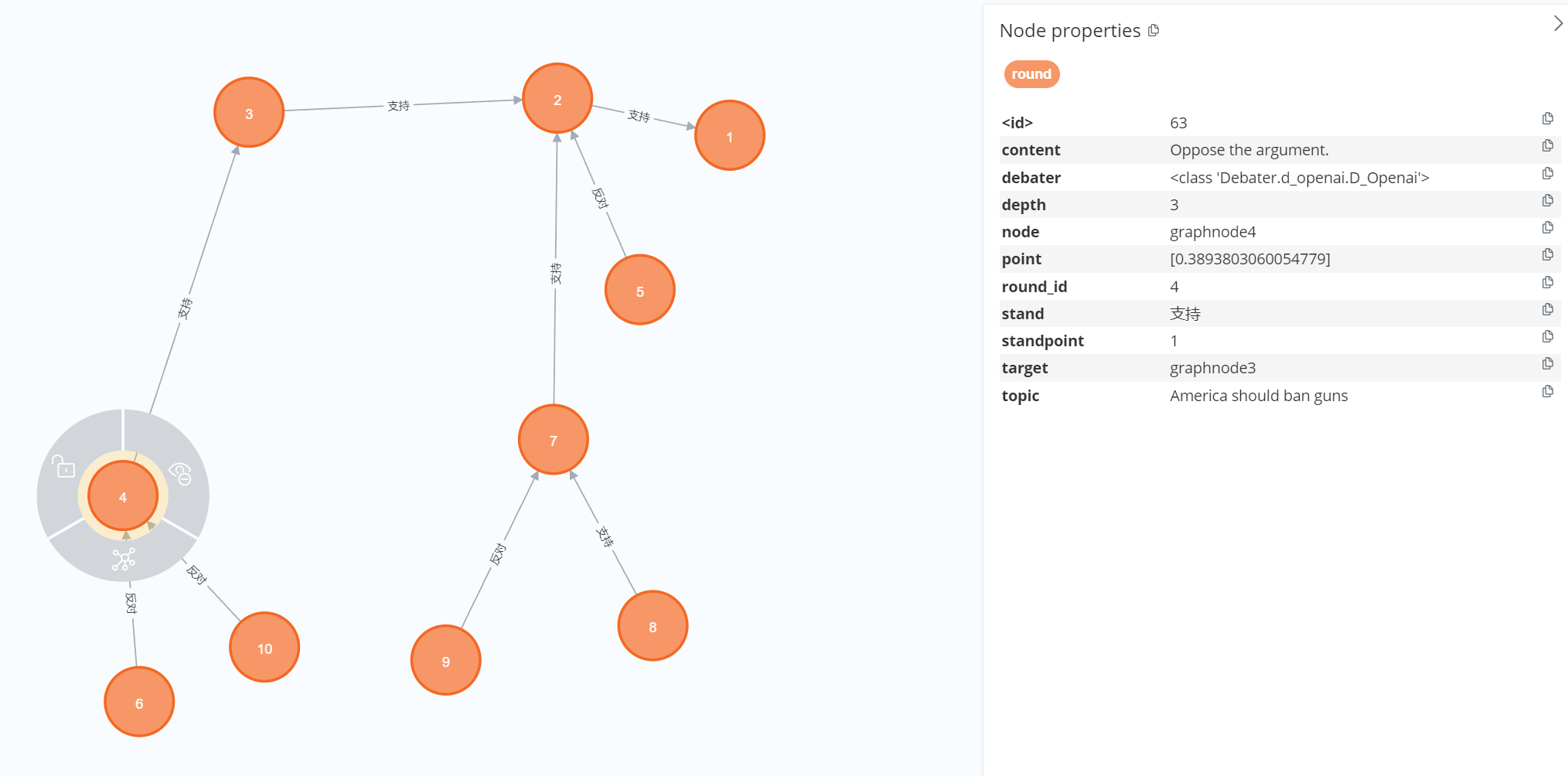
- Node:即问答轮次,分为初始的轮次和后续的轮次,后续的轮次需要传入连接轮次并用边属性表示支持与反对。
- Observer:负责记录和更新全局信息,包括全局的消息信息,节点的关系(矩阵),节点的分数(字典),节点的影响力(字典)。
- Judge:负责下一个轮次选择什么辩手,下个轮次针对哪个Node,是选择支持还是反对,并且给每一轮生成的答案进行评分。
- Graph:负责上传Observer中的node数据到图数据库neo4j中,并实现后续的分析。

CCAC 2024 第四届智慧论辩评测(AI-Debater 2024): 基于LLM实现一个自主论辩智能体,与基准智能体针对给定的辩题进行辩论赛。基准智能体持正方,参赛智能体持反方。
DoT框架由于具有自由集成Agent,编排论辩流程和记录论辩信息的功能,所以可以很好地实现论辩测评的需求。(设计上预留了环节评分的模块,目前采用的方法是微调了一个评分大模型来评分,理论上也可以接入其他的评分组件比如Debatrix)
案例详见:CCAC智慧论辩评测
案例效果详见:智慧论辩之个人破产制度
目前通过调用Project Debater实现论证分数获取(目前Project Debater已经被废止,未来计划接入其他的分数评价方法)
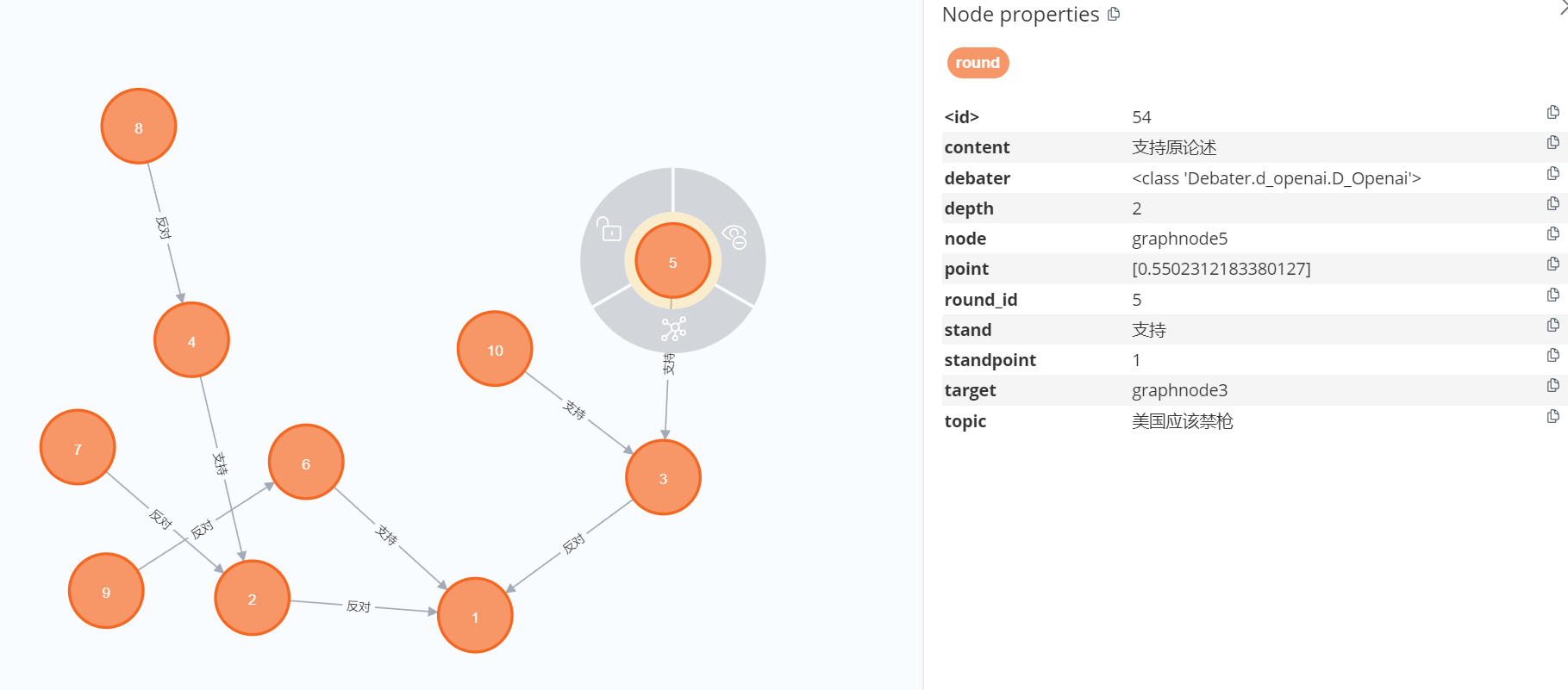
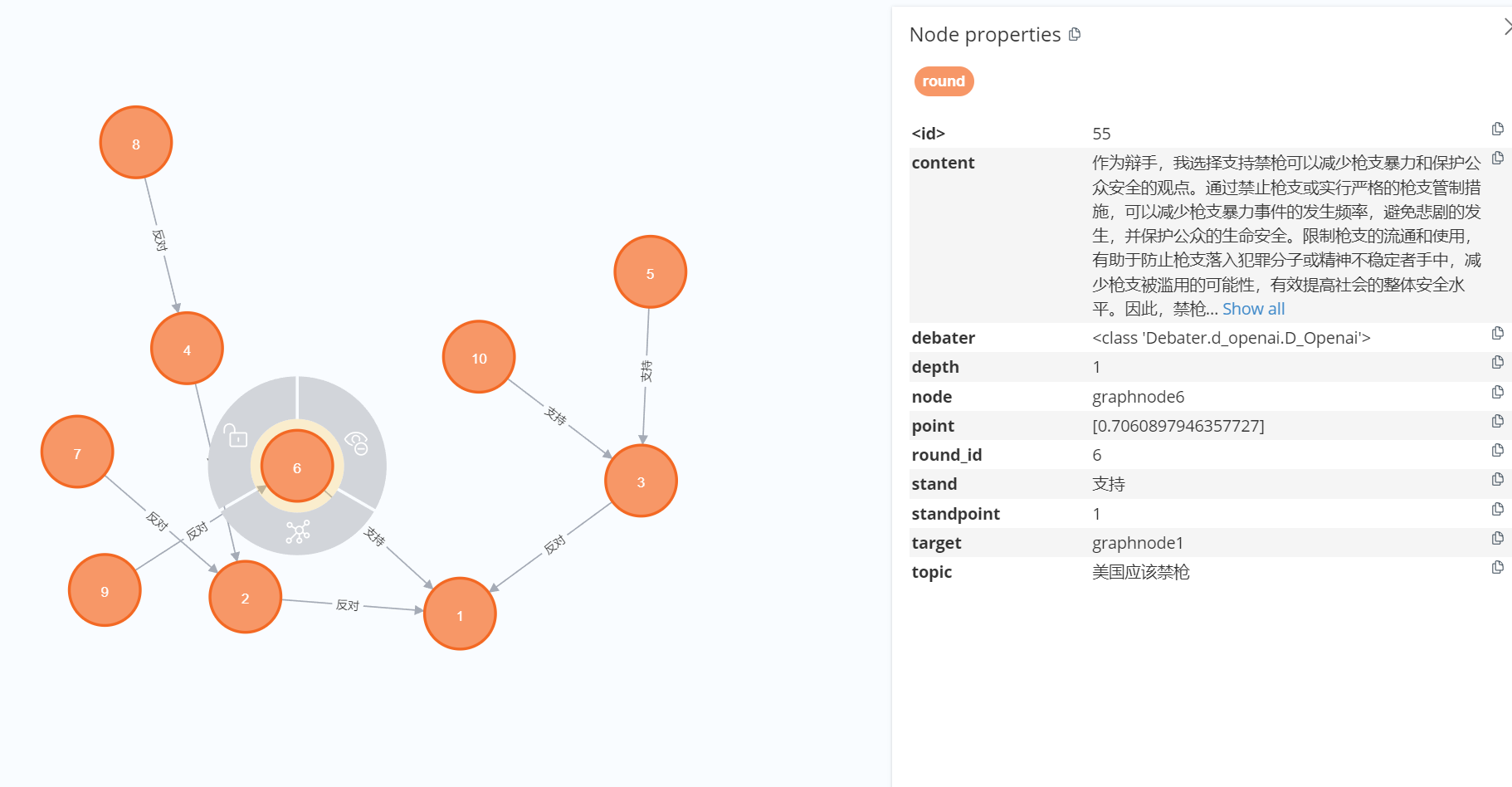
英文的区分度还是非常不错的,但是由于GPT 美式政治正确的存在,一些议题(比如禁枪)经常会有不敢答的情况出现。
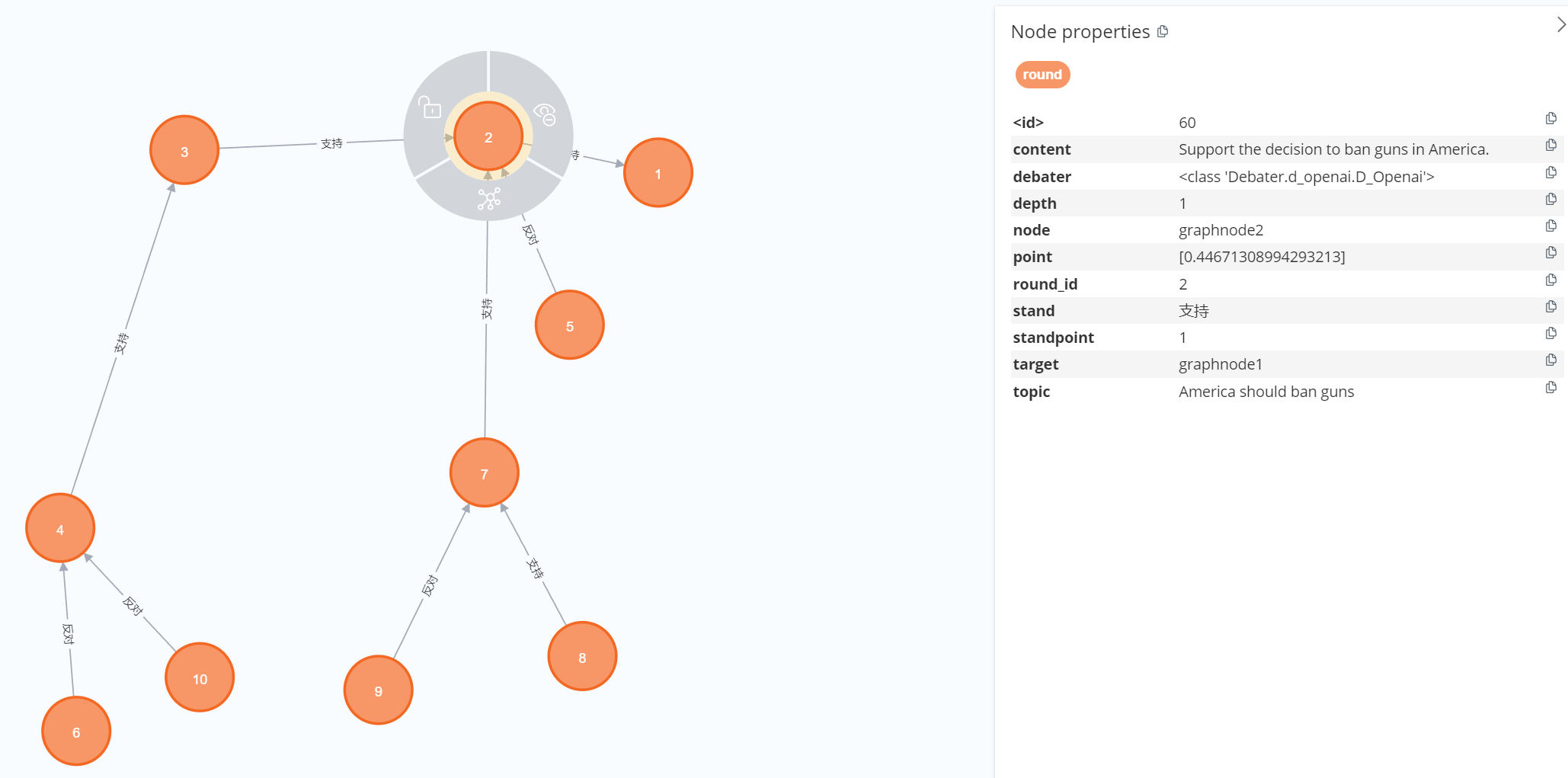
为优化中文论证评分效果,微调了开源大模型LLAMA2-7B,OpenAI-3.5-turbo以及讯飞星火3.0模型,微调数据集与方法与评测在Argument_Quality_Dataset库中。
综合测试下来讯飞3.0的中文效果非常不错,远超Project Debater的水平,在英文方面也能基本持平。不过讯飞3.0存在8%左右的敏感性问题。

