在spark中,对所有数据的操作不外乎是创建RDD、转化已有的RDD以及调用RDD操作进行求值。在这一切的背后,Spark会自动将RDD中的数据分发到集群中,并将操作并行化。
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上。RDD可以包含Python,Java,Scala中任意类型的对象,甚至可以包含用户自定义的对象。
用户可以使用两种方法创建RDD:读取一个外部数据集,或在驱动器程序中分发驱动器程序中的对象集合,比如list或者set。
RDD的转化操作都是惰性求值的,这意味着我们对RDD调用转化操作,操作不会立即执行。相反,Spark会在内部记录下所要求执行的操作的相关信息。我们不应该把RDD看做存放着特定数据的数据集,而最好把每个RDD当做我们通过转化操作构建出来的、记录如何计算数据的指令列表。数据读取到RDD中的操作也是惰性的,数据只会在必要时读取。转化操作和读取操作都有可能多次执行。

从 Spark 2.0 开始,Dataset 开始具有两种不同类型的 API 特征:有明确类型的 API 和无类型的 API。从概念上来说,你可以把 DataFrame 当作一些通用对象 Dataset[Row] 的集合的一个别名,而一行就是一个通用的无类型的 JVM 对象。与之形成对比,Dataset 就是一些有明确类型定义的 JVM 对象的集合,通过你在 Scala 中定义的 Case Class 或者 Java 中的 Class 来指定。

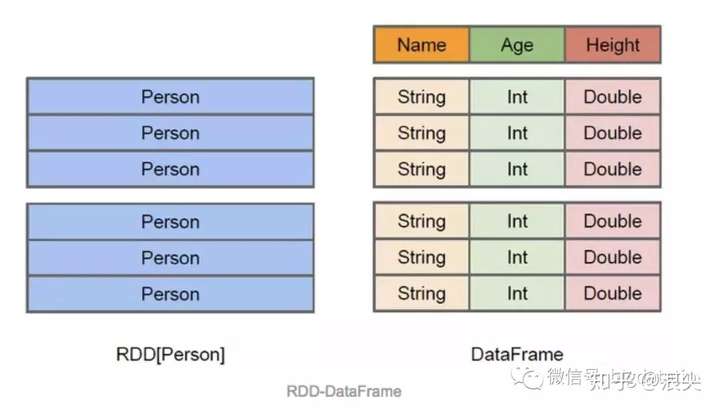
 可以用下面一张图详细对比Dataset/dataframe和rdd的区别:
可以用下面一张图详细对比Dataset/dataframe和rdd的区别:
Spark入门(四)--Spark的map、flatMap、mapToPair: https://juejin.im/post/5c77e383f265da2d8f474e29#heading-9
官方例子: https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples
- map(func):对每行数据使用func,然后返回一个新的RDD,数据处理-每行。
- filter(func):对每行数据使用func,然后返回func后为true的数据,用于过滤。
- flatMap(func):和map差不多,但是flatMap生成的是多个结果,用于行转列。
- groupByKey(numTasks):返回(K,Seq[V]),也就是Hadoop中reduce函数接受的 key-valuelist
- reduceByKey(func,[numTasks]):就是用一个给定的reduce func再作用在groupByKey产 生的(K,Seq[V]),比如求和,求平均数
- sortByKey([ascending],[numTasks]):按照key来进行排序,是升序还是降序,ascending
可以参考:https://zhuanlan.zhihu.com/p/45729547
- 不使用hive元数据:
-
SparkSession spark = SparkSession.builder().getOrCreate()
-
- 使用hive元数据
- SparkSession spark = SparkSession.builder().enableHiveSupport().getOrCreate()
- 查询远程的hive:
- 项目中resource目录加入文件hive-site.xml,指明hive的thrift连接
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://cdh01:9083</value>
</property>
</configuration>
- 直接在代码中进行普通的spark sql查询即可

val df = spark.read.json(“file:///opt/meitu/bigdata/src/main/data/people.json”)
df.show()
import spark.implicits._
df.printSchema()
df.select("name").show()
df.select($"name", $"age" + 1).show()
df.filter($"age" > 21).show()
df.groupBy("age").count().show()
spark.stop()
分桶排序保存hive表
df.write.bucketBy(42,“name”).sortBy(“age”).saveAsTable(“people_bucketed”)
分区以parquet输出到指定目录
df.write.partitionBy("favorite_color").format("parquet").save("namesPartByColor.parquet")
分区分桶保存到hive表
df.write .partitionBy("favorite_color").bucketBy(42,"name").saveAsTable("users_partitioned_bucketed")
cube
sales.cube("city", "year”).agg(sum("amount")as "amount”) .show()
rull up
sales.rollup("city", "year”).agg(sum("amount")as "amount”).show()
pivot 只能跟在groupby之后
sales.groupBy("year").pivot("city",Seq("Warsaw","Boston","Toronto")).agg(sum("amount")as "amount”).show()
参考:https://blog.csdn.net/dream_an/article/details/54915894
- 引入依赖
<!-- Spark dependency -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!--不加上会出现org/glassfish/jersey/server/spi/Container not found-->
<dependency>
<groupId>org.glassfish.jersey.core</groupId>
<artifactId>jersey-server</artifactId>
<version>2.0-m03</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.0</version>
</dependency>
- 直接在idea上运行相应的main方法。并在spark上下文设置master为local即可。
SparkConf conf = new SparkConf().setMaster("local").setAppName("com.wugui.SparkFlatMapJava");
1.启动spark
 可以观察到起来了一个master和worker进程。
可以观察到起来了一个master和worker进程。

2.代码中定义的上下文要指定master为spark server的地址。
SparkSession spark = SparkSession
.builder()
.master("spark://10.0.0.50:7077")3.使用mvn clean package打包好的作业,并提交到本地安装好的spark环境上跑
~/opt/spark-2.4.0-bin-hadoop2.7 » bin/spark-submit --class "com.wugui.sparkstarter.com.wugui.SparkHiveNewVersion" /Users/huzekang/study/spark-starter/target/spark-starter-1.0-SNAPSHOT.jar
4.打开spark server界面,可以看到已经完成的spark作业。

1.代码中定义的上下文不要指定master
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL Starter !!")
.enableHiveSupport()
.config("spark.some.config.option", "some-value")
.getOrCreate();2.shell中声明YARN_CONF_DIR和HADOOP_CONF_DIR
export YARN_CONF_DIR=/Users/huzekang/opt/hadoop-cdh/hadoop-2.6.0-cdh5.14.2/etc/hadoop
export HADOOP_CONF_DIR=/Users/huzekang/opt/hadoop-cdh/hadoop-2.6.0-cdh5.14.2/etc/hadoop
3.使用mvn clean package打包好的作业,并提交到本地安装好的yarn环境上跑。
~/opt/spark-2.4.0-bin-hadoop2.7 » bin/spark-submit --master yarn --deploy-mode cluster --class "com.wugui.sparkstarter.com.wugui.SparkHiveNewVersion" /Users/huzekang/study/spark-starter/target/spark-starter-1.0-SNAPSHOT.jar
4.打开yarn观察到作业已经完成了。
