Create an Extract Transform Load pipeline using python and automate with airflow.
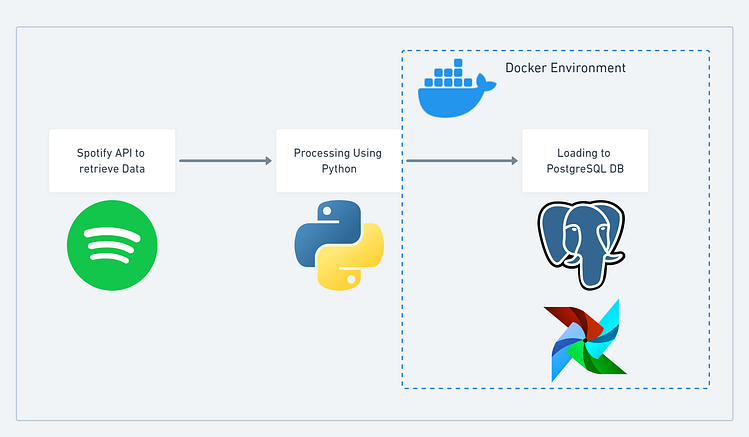
Creating a simple ETL(Extract, Transform, Load) pipeline using Python and automate the process through Apache airflow.
Use Spotify’s API to read the data and perform some basic transformations and Data Quality checks finally will load the retrieved data to PostgreSQL DB and then automate the entire process through airflow.
- Python
- API’s
- Docker
- Airflow
- PostgreSQL
This is a project building a pipeline and automating through airflow. First, we will focus on entirely building the pipeline and then extend the project by combining it with Airflow.
Using token to Extract the Data from Spotify and creating a function return_dataframe(). The Below python code explains how we extract API data and convert it to a Dataframe.
Exporting the Extract file to get the data.
def Data_Quality(load_df): Used to check for the empty data frame, enforce unique constraints, checking for null values. Since these data might ruin our database it's important we enforce these Data Quality checks.
def Transform_df(load_df): This is to enforce primary constraints.
Using sqlalchemy and SQLite to load data into a database and save the file in project directory.
E:SPOTIFY_ETL\SPOTIFY_ETL
│ Extract.py
│ Load.py
│ my_played_tracks.sqlite
│ spotify_etl.py
│ Transform.py
└───
Now we will automate this process using Airflow.
After the ETL is completed using Docker to setup airflow
In this Python File, write a logic to extract data from API → Do Quality Checks →Transform Data.
- yesterday = today — datetime.timedelta(days=1) → Defines the number of days the data is needed. 1 signifies daily.
- def spotify_etl() → Core function which returns the Data Frame to the DAG python file.
- from airflow.operators.python_operator import PythonOperator → we are using the python operator to perform python functions such as inserting DataFrame to the table.
- from airflow.providers.postgres.operators.postgres import PostgresOperator → we are using the Postgres operator to create tables in our Postgres database.
- from airflow. hooks.base_hook import BaseHook → A hook is an abstraction of a specific API that allows Airflow to interact with an external system. Hooks are built into many operators, but they can also be used directly in DAG code. We are using a hook here to connect Postgres Database from our python function
- from spotify_etl import spotify_etl → Importing spotify_etl function from spotify_etl.py.
Note: We may need to change the token in our ETL python file since it expires after some time. There are some limitations to this project they can be overcome by using a refresh token to automatically renew the token and we can set up the airflow in cloud services to run 24/7 and pick data once a day making it a Daily.