Home
CTAT-Mutations Pipeline is a variant calling pipeline focussed on detecting variants from RNA sequencing (RNA-seq) data. It integrates GATK Best Practices along with downstream steps to annotate and filter variants, and to additionally prioritize variants that may be relevant to cancer biology such as likely somatic mutations. Our variant annotation includes leveraging the RADAR and RediPortal databases for identifying likely RNA-editing events, dbSNP and gnomAD for annotating common variants, and COSMIC to highlight known cancer mutations. Finally, CRAVAT is leveraged to annotate and prioritize variants according to likely biological impact and relevance to cancer.
The CTAT Mutations pipeline is one of the components of the Trinity Cancer Transcriptome Analysis Toolkit (CTAT), complementing other functionality that leverages RNA-Seq data for characterizing cancer transcriptomes, including identification of fusion transcripts, copy number variations from tumor single cell transcriptomes, among other capabilities.
Our CTAT-Mutation pipeline aims to make variant discovery from rna-seq data as easy as possible, requiring only the RNA-seq reads as input, and generating summary reports and visualizations to help guide you to the most meaningful findings.
The following flowchart is a simplified visualization of the steps performed by the CTAT-Mutation Pipeline.
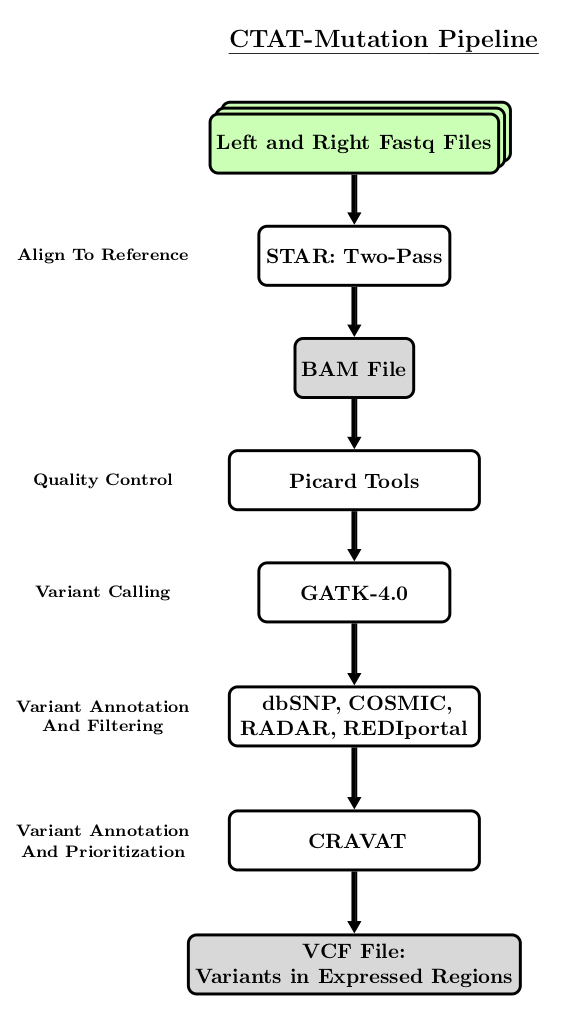
The CTAT-Mutations pipeline requires the CTAT-Mutations software and companion genomic data resources. See our instructions for installing CTAT-Mutations for details.
Once the CTAT-Mutation Pipeline has successfully been installed along with the obligatory CTAT Genome Library, CTAT-Mutation Pipeline can be ran using the following command, only requiring the input reads.
python /path/to/ctat_mutations \
--left : Path to the location of the left (ie. /1) paired end RNA-Seq Fastq file.
--right : Path to the location of the right (ie, /2) paired end RNA-Seq Fastq file.
--sample_id : The sample id
--outputdir : Name to be given to the directory in which CTAT-Mutation outputs will
be placed.
As inputs, CTAT-Mutation requires RNA-Seq reads in the form of a right and left paired-end FASTQ files, along with an output directory name where the pipeline products will be stored.
A small sample data set comes with ctat_mutations and is available for testing purposes. The pipeline can be ran on the sample data set by running the following command:
python /path/to/ctat_mutations \
--left reads_1.fastq.gz \
--right reads_2.fastq.gz \
--outputdir varcalling.outdir \
--sample_id test
See our more detailed walk through tutorial leveraging these data.
Boosting can be applied to augment prediction accuracy. By default, --boosting_method is set to none to apply hard filters instead of boosting. Additional machine learning approaches are incorporated for reducing false positive calls, including gradient boosting, stochastic gradient boosting, adaptive boosting, and random forests. Hard-filtering and boosting methods are mutually exclusive. You can first run with the default hard filtering, and then run again with boosting enabled, and the second run will reuse preexisting outputs from the earlier execution where possible, speeding up the process. See Output section below for more details.
As of version 4.0.0, the CTAT-Mutations pipeline is capable of leveraging long IsoSeq reads from PacBio. Given a fastq file with long reads, run ctat_mutations like so:
ctat_mutations --left long_reads.fastq.gz --is_long_reads
Before running with your ctat genome lib, be sure to rerun this command from the v4.0.0+ software release: "python ctat-mutations/mutation_lib_prep/ctat-mutation-lib-integration.py --genome_lib_dir /path/to/your/ctat_genome_lib_build_dir" which will prep the genome for minimap2 alignment used in the long read analyses.
Boosting is disabled with long reads, as no training of parameters was done with long reads yet.
While we've observed detection of driver mutations using long IsoSeq reads, no benchmarking of overall accuracy has been performed as of yet.
The output from the CTAT-Mutations pipeline includes variant vcf files, summary tab-delimited reports, and interactive visualizations.
The primary outputs include variants.HC_init.wAnnot.vcf.gz, containing HaplotypeCaller variant calls fully annotated. If boosting or hard-cutoffs are applied for filtering, additional corresponding vcfs are provided containing the unfiltered variant calls. A cancer.vcf and corresponding simpler summary cancer.tab file, are provided that contain a set of prioritized cancer-relevant variants detected in the sample. The cancer.vcf (VCF version 4.0) records the genetic variations, their locations, and additional annotation information. The cancer.tab is a tab-delimited file that contains the same variant information in a user-friendly format. There are additional outputs that are generated by the different stages of the CTAT-Mutations pipeline, as others are likely to be of interest as well for exploring RNA-editing or common variants. Documentation is provided for all such output files and formats.
You will also find an html page output named "igvjs_viewer.html" (based on igv-reports ), which allows for dynamic navigation of the identified cancer variants and the read evidence supporting their identification. This file can be simply opened in your web browser. An example view is shown below.
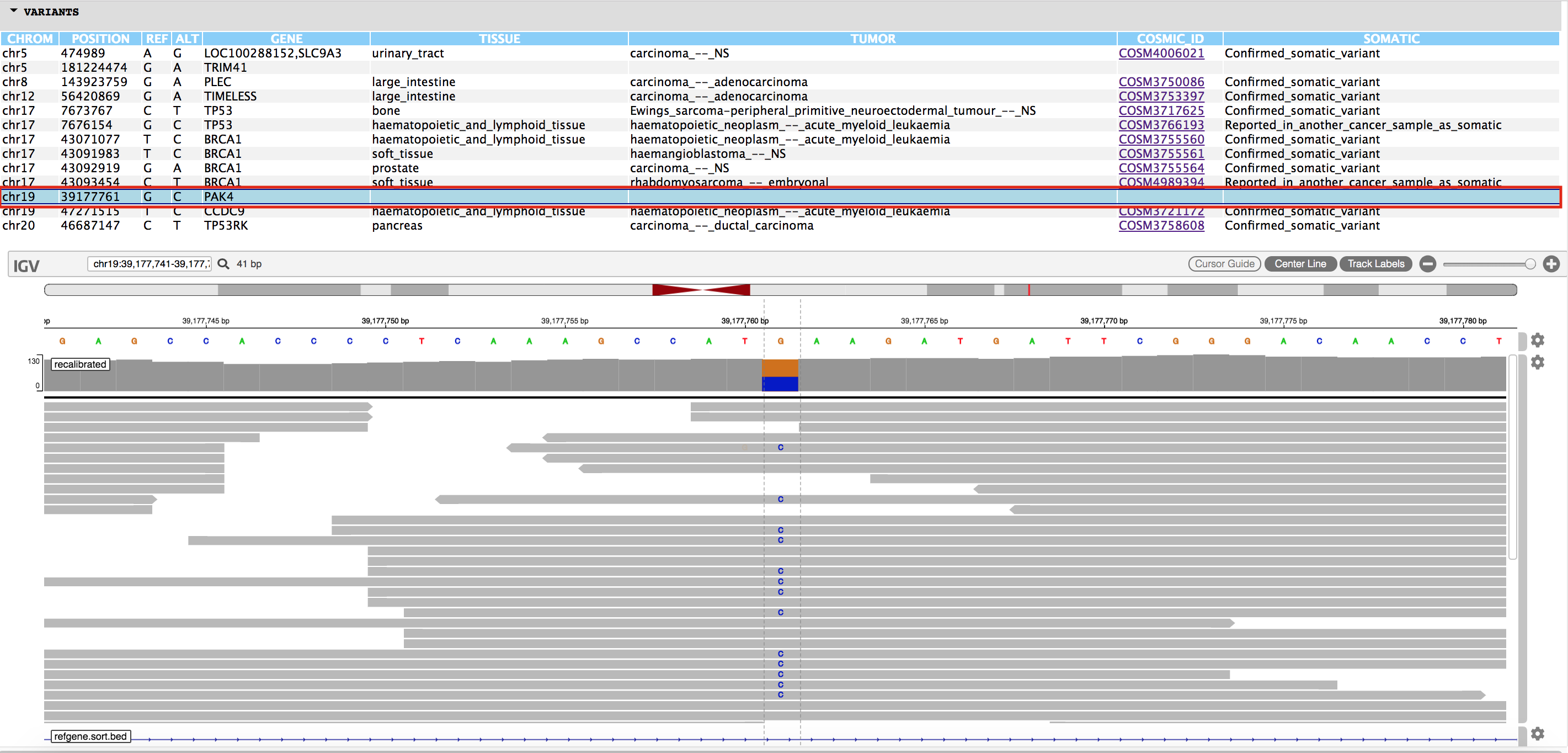
More info for exploring the variant visualization framework is available here.
The igv-reports based html report derives from a collaboration with James Robinson.
CTAT-Mutations is available for running on Terra and easy to use - select the Hg19 or Hg38 based workflow from the web interface, specify your RNA-seq fastq inputs, and click 'go'.
Contact us on our google group https://groups.google.com/forum/#!forum/trinity_ctat_users
We aim to be responsive with user support. You will be responded to within hours time, generally (not days or weeks).
Users of CTAT-Mutations should reference this GitHub Repo (https://github.com/NCIP/ctat-mutations) and also consider referencing the relevant resources leveraged incluing:
-
GATK: DePristo M, Banks E, Poplin R, Garimella K, Maguire J, Hartl C, Philippakis A, del Angel G, Rivas MA, Hanna M, McKenna A, Fennell T, Kernytsky A, Sivachenko A, Cibulskis K, Gabriel S, Altshuler D, Daly M. (2011). A framework for variation discovery and genotyping using next-generation DNA sequencing data. Nat Genet, 43:491-498. DOI: 10.1038/ng.806.
-
STAR aligner: STAR: ultrafast universal RNA-seq aligner. Dobin A, Davis CA, Schlesinger F, Drenkow J, Zaleski C, Jha S, Batut P, Chaisson M, Gingeras TR. Bioinformatics. 2013 Jan 1;29(1):15-21. doi: 10.1093/bioinformatics/bts635. Epub 2012 Oct 25. PMID: 23104886
-
OpenCRAVAT: Pagel KA et al. Integrated Informatics Analysis of Cancer-Related Variants. JCO Clinical Cancer Informatics 2020 4, 310-317.
-
Rediportal: Picardi E, D'Erchia AM, Lo Giudice C, Pesole G. REDIportal: a comprehensive database of A-to-I RNA editing events in humans. Nucleic Acids Res. 2017 Jan 4;45(D1):D750-D757. doi: 10.1093/nar/gkw767. Epub 2016 Sep 1. PMID: 27587585; PMCID: PMC5210607.
- Liu F, Zhang Y, Zhang L, Li Z, Fang Q, Gao R, Zhang Z. Systematic comparative analysis of single-nucleotide variant detection methods from single-cell RNA sequencing data. Genome Biol. 2019 Nov 19;20(1):242. doi: 10.1186/s13059-019-1863-4. PMID: 31744515; PMCID: PMC6862814.
CTAT-Mutations is supported as part of the Trinity CTAT Project, funded by the National Cancer Institute Informatics Technology for Cancer Research