Google News is a comprehensive platform for accessing and discovering news articles from around the world. Use it as your go-to source for staying informed about current events and trending topics, or as a tool to delve deeper into specific news categories that interest you.
A web scraper for Google News is a tool designed to automatically extract news articles and related information from the Google News website. Additionally, this tool visualizes a heatmap depicting the trends of the Mexican states. The gathered data can be downloaded in a JSON file, which includes headlines, publication dates, links, sources and the states identified. Web scraper news can serve various purposes, such as conducting research on news trends, analyzing media coverage, or aggregating news content for customized news feeds.
This repository houses a robust web scraper developed in Python, which utilizes libraries such as BeautifulSoup, fake_useragent, asyncio, aiohttp and flask. It enables you to scrape news data from Google News based on specified search parameters and retrieve the results in JSON format. Below are the details on how to set up and utilize this web scraper effectively.
We will be using the following dependencies for our code, which will be installed later:
- aiohttp
- asyncio
- bs4
- Flask[async]
- pandas
- fake_useragent
- requests_html
- jsonify
-
app.py: This file contains the Flask application with endpoints for executing the web scrape news, visualizing the data, download results and run the interface on the browser.
-
Dockerfile: Dockerfile for building a Docker image to run the Flask application in a containerized environment.
-
compose.yml: Docker Compose file for defining and running multi-container Docker applications. It specifies the Flask application service.
-
requirements.txt: File listing the Python dependencies required for this application.
-
sample4.html: Interface on which the user interacts in order to use all the tools of the program (scrape, visualize and download).
-
GoogleScraper.py: Python file for scrape the Google news.
-
organizing_urls.py: Python file which organize the news on a json file.
Before running the application, make sure you have Docker installed on your system. Follow these steps to install Docker:
-
Download Docker:
- Visit the Docker website to download Docker for your operating system.
- Follow the installation instructions provided for your specific platform.
-
Verify Installation:
- Once Docker is installed, open a terminal or command prompt and run the following command to verify the installation:
docker --version - If Docker is installed correctly, you should see the version information displayed in the terminal.
- Once Docker is installed, open a terminal or command prompt and run the following command to verify the installation:
-
Run Docker Desktop:
- Launch Docker Desktop from your applications menu or start menu.
- Docker Desktop will start the Docker service, allowing you to build and run Docker containers on your system.
Now that Docker is installed, you can proceed with setting up and running the application using the instructions provided below.
To download the API and initialize it, open the terminal in yout chosen Directory and run the next commands in it:
- Clone the Repository:
git clone https://github.com/Oscaretz/Scraper_and_mapping/
This line clone the API from the repository to your machine
- Navigate to the Directory:
cd Scraper_and_mapping
Open the file you just created
- Run the Docker Container:
docker-compose up --build
Build and run the container using docker compose
- Run the app:
Copy the 1st direction (It usually is 127.0.0.1:5000) and paste it in your browser.
Once you've opened the browser with the given direction, follow these steps to set it up and start scraping:
-
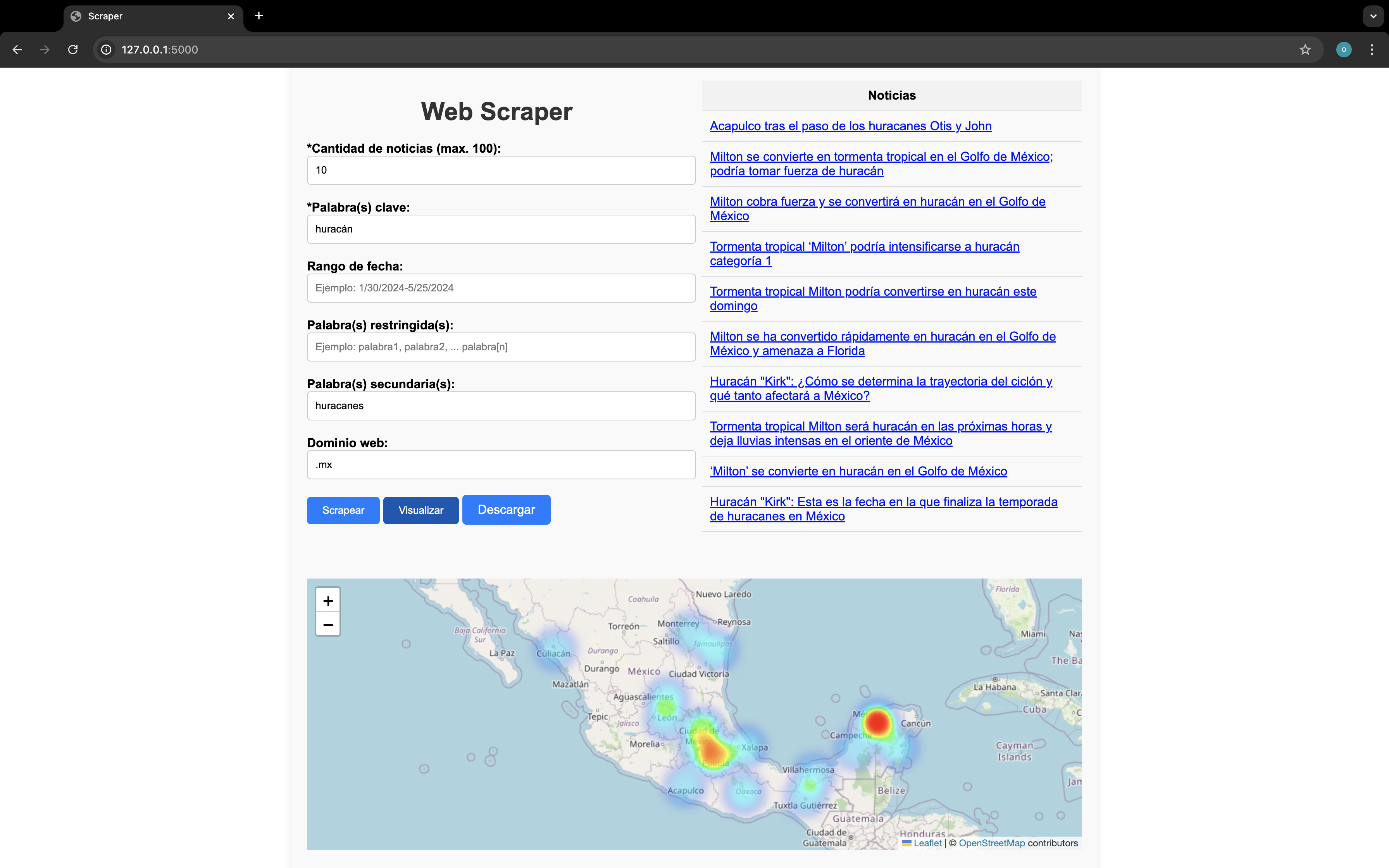
Scrape news: Insert all the parameters you want and click the botom 'Scrape'. After that, the table of the righ side will be filled with 10 news as reference. Here is the guide to write the parameters:
-
Cantidad de noticas (max. 100): Insert the amount of news to collect, mutiples of 10.
-
Palabra(s) clave: Insert the main keywords to search, separated by comas. Could be one or more.
-
Rango de fecha: Optional; Insert the range date to scrape beging with the first date and end with the last date: m1/d1/y1-m2/d2/y2
-
Palabra(s) restringida(s): Optional; Insert the restricted words, separated by comas. Could be one or more.
-
Palabra(s) secundaria(s): Optional; Insert the secundary keywords, separated by comas. Could be one or more.
-
Dominio web: Optional; Insert the domain (ej. www.samplenews.com) or type of domain (.gov .edu .org .mx .col .eu etc...)

-
-
Visualize the heat map: Visualize the heat map with the data gathered by clicking the botom 'Visualize'.

-
Download results: Click the bottom 'Download' to download a JSON file with the news collected within the given information (Title, source, date, link and State)

{
"title_example": {
"Source": "source_example",
"Link": "www.link-example.com",
"Date": "date_example",
"States": ["state_example", ...
},
...
}- This web scraper is a simple example with some customization based on the tools that Google Advanced Search provide
- The excessive use of the scrape could cause a temporary ban from Google, in case this happen, just wait a time before doing more queries.
Feel free to modify and expand upon this web scraper according to your requirements. If you encounter any issues or have suggestions for improvements, please don't hesitate to open an issue or pull request. Happy scraping!