
OPL - Thème 2: Crash Analysis
15/11/2016
Benjamin Coenen - Nicolas Delperdange
Introduction
Contexte et Problème
Travail technique
Evaluation
Limitation
Conclusion
Référence
Annexe
Dans le cadre d'un challenge pour le cours d'OPL de l'Université de Lille 1, nous devons réunir des stacktraces (capturées dans des issues Github) dans un même bucket.
Un Bucket est donc un ensemble de stacktraces qui sont liées au même problème.
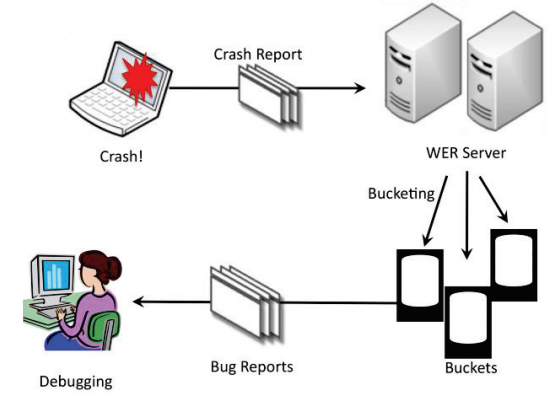
Le but étant donc pour le débuggeur de ne pas devoir traiter plusieurs fois le même problème.
Avant toute chose il faut définir quelques points essentiels d'une stacktrace :
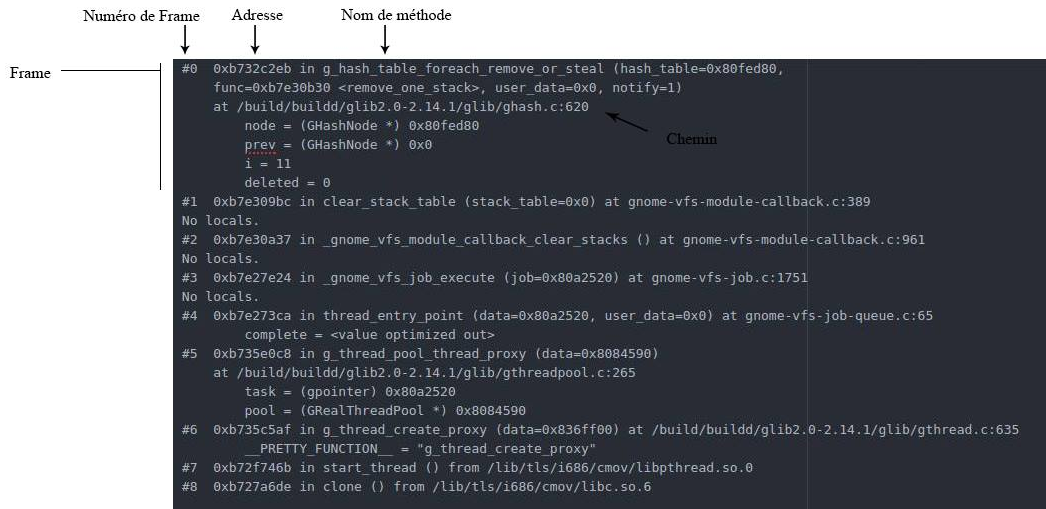
- Une stacktrace est composée d'un ensemble de frames
- Une frame correspond à un appel de méthode ou procédure et est composée de :
- Un numéro de frame
- Une adresse
- Un nom de méthode
- Un chemin
- Et différents paramètres
Comme tout bon étudiant en informatique et plus particulièrement en génie logiciel, nous avons d'abord parcouru la toile à la recherche de solutions existantes. Afin d'un côté s'en inspirer et pourquoi pas les intégrer dans notre projet.
Après quelques heures de recherches, de discussions et d'essais, nous avons réuni 3 projets : 2 outils de gestion de bugs et un papier de Microsoft.
Sentry et Rollbar [2-3] sont tous les 2 des gestionnaires de crashs (accessibles en mode Saas) et intègrent un système de triage de stacktrace. Sentry est open-source et est disponible sur Github et Rollbar possède une bonne documentation en ligne mais n'est malheureusement pas open-source.
Ces 2 programmes étant très proche de la réalité, nous avons donc parcouru leur documentation à la recherche de bonnes pratiques concernant le groupage d'exception.
Rollbar applique une méthode de tri qui consiste à comparer des empreintes de stacktrace. Pour cela il procède comme suit :
- Combiner tous les noms de fichiers et noms de méthodes des stacktraces
- Enlever à cela les dates, sha et entiers de plus de 2 caractères
- Ajouter le nom de classe d'exception
- Produire une empreinte SHA1 de cette concaténation
Il leur suffit ensuite de comparer les empreintes des stacktraces, si celle-ci sont égales, les stackstraces appartiennent au même bucket.
Sentry lui invoque le fait qu'il ne peut stocker tous les stacktraces qui lui sont fournis et donc essaye de ne stocker qu'une seul stacktrace par bucket et donc essaye de stocker la stacktrace la plus représentative du bucket.
Ce projet [5] n'est pas un logiciel mais un papier expliquant la méthode de Microsoft pour assembler des rapports de crash par rapport à la similarité des stacktraces jointes. Ce papier nous a permis d'affiner notre algorithme de tri en y rajoutant des concepts fort intéressants !
Cette étape de pré-processing consiste à enlever les frames qui possèdent des appels récursifs pour ne garder qu'un appel.
Sinon cela causerait un mauvais calcul par la suite dû à la duplication des méthodes.
Pendant cette étape, ils enlevent aussi les fonctions immunes, c'est-à-dire, des fonctions qui ne 'peuvent' provoquer de bugs car celles-ci ont été testés de maintes fois.
Le premier concept est la distance et l'offset d'une frame.
La distance est la position de la frame courante par rapport à la première frame (top frame).
L'offset est la différence de niveau entre 2 frames dans des stacktraces différentes.
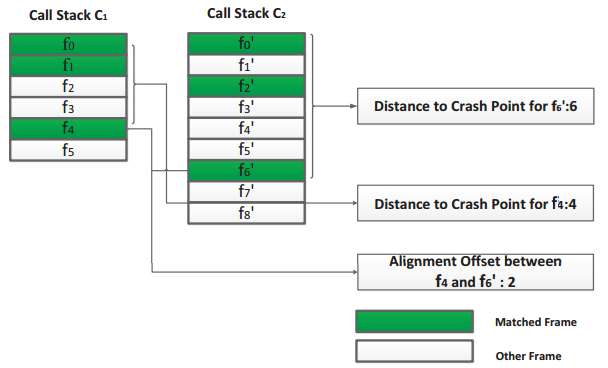
Ce concept introduit par Rebucket est une formule permettant de calculer la similarité entre 2 stacktraces et est basée sur les métriques précédentes :
- Plus de points doivent être accordés aux frames dont la position est proche du top, puisque la frame qui est à l'origine du bug est souvent proche du top.
- Et l'offset entre 2 fonctions semblables provenant du même bug est censé proche de 0.
Et grâce à ces 2 principes et le nombre de frames semblables entre 2 stacktraces, ils calculent un coefficient de similarité découlant d'une formule mathématique et de paramètres fixés (ou calculés grâce à des buckets validés).
Ils assemblent ensuite les stacktraces dans des buckets sur un principe de distance basée sur cette similarité.
Tout le but de ce travail consiste donc à créer le 'meilleur' algorithme pour rassembler les bonnes stacktraces dans les bons buckets.
Evidemment il est impossible d'obtenir un score de 100%, car même l'être humain ne peut être sûr en regardant 2 stacktraces que celles-ci découlent du même problème avec certitude car trop de facteurs non-prévisible entrent en jeu.
Et il est aussi possible qu'une stacktrace possèdent trop peu d'informations pour pouvoir être triée.
Nous avons utilisé une architecture basée sur NodeJs par soucis de facilité d'écriture et d'utilisation.
Nous avons aussi fortement découpé notre code en multiples méthodes afin de le rendre très modulaire, le projet étant découpé principalement en 3 fichiers :
index.js, qui s'occupe du calcul du score et du regroupement en bucketparse.js, qui s'occupe de tout le traitement des fichiers et chaînes de caractères (lecture, récupération, nettoyage, ...)filer.js, qui gère tout ce qui manipule les fichiers (lecture et écriture de répertoire et fichier)
Concernant les librairies utilisées :
- Bluebird : librairie permettant d'utiliser des 'promises' (système asynchrone) [6]
- Crypto : librairie de cryptographie pour calculer le SHA1 des stacktraces [7]
- Mathjs : librairie mathématique avec fonctions avancées [8]
- fs : librairie de lecture de fichier intégrée à Nodejs [9]
Notre algorithme se décompose en 3 étapes :
- Pré-processing
- Calcul de la similitude
- Groupage en bucket
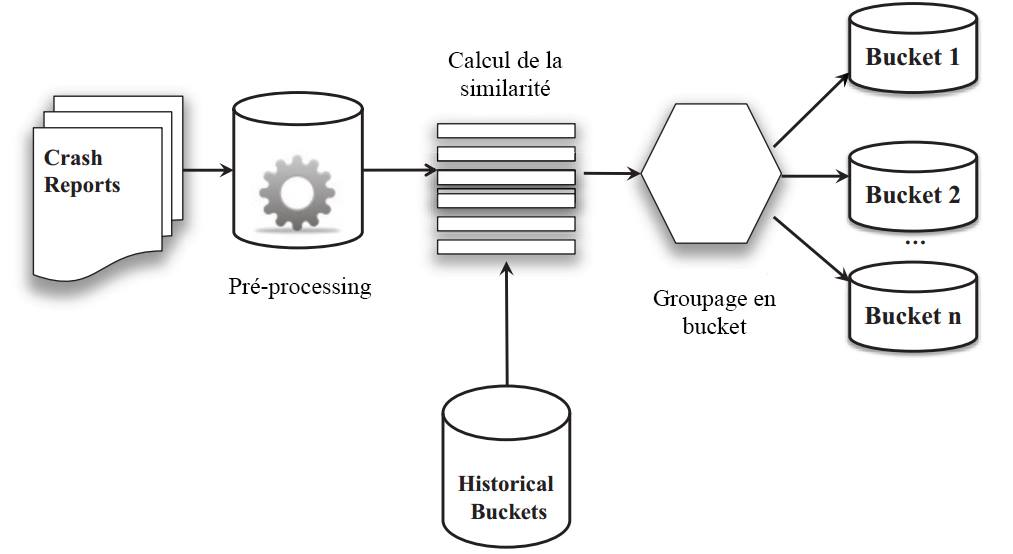
La première étape est donc une étape de pré-processing, elle consiste à lire toutes les stacktraces et buckets existants et à en extraire les données utiles.
Pour cela nous utilisons la librairie FS afin de lire les différents fichiers auxquels nous appliquons de multiples regex afin d'enlever les informations inutiles et en tirer les informations suivantes pour chaque frame :
- Le nom de la méthode
- Le chemin de la méthode
- Le numéro de frame
- L'adresse mémoire
Avant de faire cela, nous enlevons les méthodes récursives car celles-ci peuvent introduire des erreurs de calculs de similarité par la suite et aussi les fonctions immunes qui sont réputées pour ne pas provoquer de bugs (comme la méthode clone() par exemple) et qui dont ne doivent pas entrer dans le calcul de similarité.
Concernant les informations retirées, nous enlevons :
- Les paramètres (différents paramètres pouvant amener au même bug)
- Les numéros de lignes (pouvant trop facilement varier)
- Les numéros de version de librairies
Nous obtenons donc au final de cette étape un tableau contenant les différentes frames de chaque stacktraces afin de pouvoir les comparer aisément.
Pour calculer la similitude, nous nous basons fortement sur le Position Dependent Model de Microsoft qui utilise le paradigme de la programmation dynamique.
Le principe est de calculer une matrice de similitude entre chaque stacktrace, c'est donc évidemment l'étape la plus longue et la plus lourde en calcul.
Pour calculer cette matrice, il faut attribuer des points par rapport à la comparaison entre frames et y ajouter un coût basé sur les principes de distance et offset.
Concernant la comparaison nous appliquons des points par rapport aux éléments suivants :
Define coeffs : coeffPath, coeffMethod, coeffAdresse, coeffSame;
if (stacktraceToBePlaced is anonymous OR stacktracePlaced is anonymous)
if(stacktraceToBePlaced.path === stacktracePlaced.path)
return coeffPath;
if(stacktraceToBePlaced.adresse === stacktracePlaced.adresse)
return coeffPath;
return MIN_INTEGER;
else
if(stacktraceToBePlaced === stacktracePlaced)
return coeffSame;
if(stacktraceToBePlaced.adresse === stacktracePlaced.adresse)
return coeffAdresse;
if(stacktraceToBePlaced.method === stacktracePlaced.method)
return coeffMethod;
if(stacktraceToBePlaced.path === stacktracePlaced.path)
return coeffPath;
return MIN_INTEGER;Ces coefficients, ainsi que les coefficients de distance, peuvent être fixés au préalable (leur valeur par défaut étant défini par des expériences sur les 2 datasets fournis) ou peuvent être définis automatiquement à travers un processus qui va analyser les buckets confirmés. Mais cette étape est forte lente et parfois ne trouvent pas de meilleurs coefficients que ceux par défaut.
Nous avons aussi amélioré ce calcul en y ajoutant un coût de similitude à chaque étape du calcul de la matrice ce qui a amélioré les résultats.
Voici les fonctions de calculs de Rebucket que nous avons légèrement modifiées.
Respectivement le calcul de la matrice, le calcul du coût et le calcul de la similarité entre 2 stacktraces.
C et O étant les deux coefficients de coût (distance et offset).
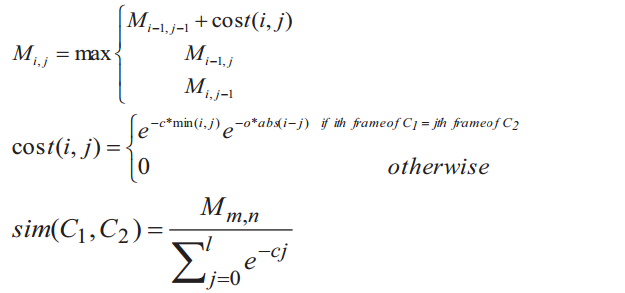
Le placement d'une stacktrace dans un bucket est assez aisé et se base sur les similitudes calculées à l'étape précédent.
Deux options sont possibles pour cette étape :
- Soit grouper la stacktrace avec la stacktrace d'un bucket qui a obtenu le plus haut score de similarité
- Soit calculer une moyenne de similitude entre chaque stacktrace d'un bucket et la stacktrace que l'on veut placer
Ces 2 types de groupage obtiennent de meilleurs résultats par rapport au type de dataset fourni. Il est donc envisageable de lancer 2 fois l'algorithme.
Pour lancer le programme, il suffit d'avoir node et de lancer la commande :
$ node index.jsSi vous voulez ajouter un autre dataset, il suffit de lancer le programme de cette façon :
$ node index.js ./cheminVersMesBuckets ./cheminVersMesStacktracesAPlacerPour évaluer notre projet d'un point de vue performance, nous possédons 2 métriques :
- Le temps d'exécution
- Les points accordés par l'oracle sur 2 datasets
Voici un graphique réprésentant l'avancement de notre projet par étape :
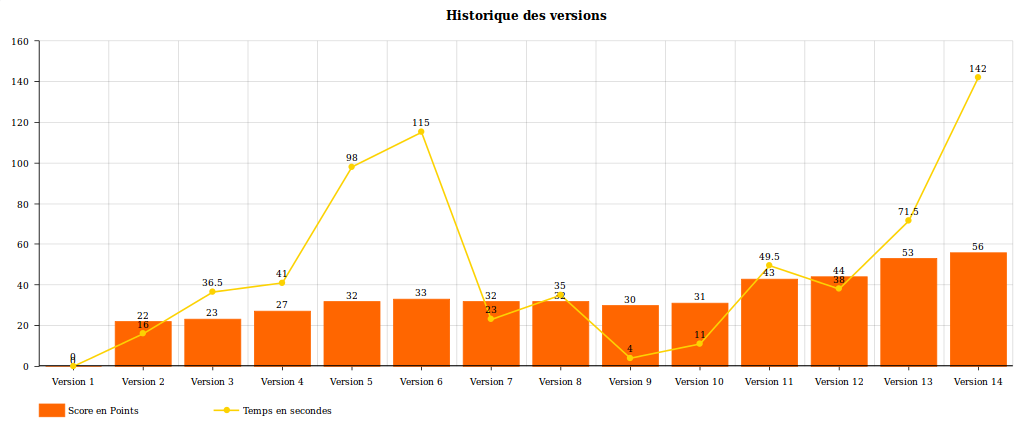
Version numéro (technique - temps) : score pour la dataset 1
- Version 1 (librairie fuzzy pour comparer - 3heures) : 0
- Version 2 (comparaison de chaine simple - 15886.117ms): 22
- Version 3 (+ comparaison d'addresse - 36440.523ms): 23
- Version 4 (+ ajout de score pour les méthodes '??' et le chemin - 51045.092ms): 27
- Version 5 (+ ajout du cout distance - 98183.193ms) : 32
- Version 6 (+ ajout du cout offset - 115283.663ms) : 33
- Version 7 (+ enlever les fonctions récursives - 23141.745ms) : 32
- Version 8 (+ ajout SHA1 pour comparaison identique - 34978.063ms) : 32
- Version 9 (+ enlever les fonctions immunes - 3781.552ms) : 30
- Version 10 (fix détecter par les tests - 10804.055ms) : 31
- Version 11 (Remplacement de par le PDM similarity - 49422.940ms) : 43
- Version 12 (Coefficient par défaut + suppression des version de lib - 38022.126ms) : 44
- Version 13 (+ Ajout d'un cout de comparaison a chaque étape - 71630.500ms) : 53
- Version 14 (+ Ajout de comparaison de méthodes anonymes et adresse - 65304.689ms) : 55
Nous sommes donc assez content de notre avancée par rapport à l'oracle mais aussi au temps d'exécution globale de notre programme, malgré que celui-ci ne soit pas écrit dans le meilleur langage pour faire de l'algorithmique.
Sur certains versions (comme par exemple la 7 et 9), nous avons perdus des points mais avons quand même préféré les garder car celles-ci étaient logique dans leur intégration mais ne pouvaient se révéler utiles que plus tard par l'ajout d'autres mécanismes.
Nous avons aussi, lors de la version 10, ajouté des tests unitaires sur le parseur et avons rémarqué différents problèmes liés a celui-ci.
Nos tests se limitent au parseur car le calcul de points étant assez difficile à tester et changeant constamment par rapport aux nombreux ajouts et modifications apportés.
Cependant notre couverture sur la partie parseur est très bonne et nous est fournie grâce à la librairie Istanbul [10] et le framework de test Mocha [11].

Ces tests nous ont donc permis d'être assuré que le parseur faisait bien son boulot et nous avons pu nous concentrer sur l'algorithme de calcul de similarité. De plus les tests sont exécutés automatiquement à chaque push sur github grace à Travis CI [12].
En résumé, sur les machines fournis par l'école et avec le premier dataset d'exemple, notre algorithme prend environ +-2min et atteints un score de 56 stacktraces placées sur 108 (sachant que certaines sont impossibles à placer, possédant trop peu d'informations). Celui-ci obtient un score de 75 sur 121 pour le 2ieme dataset avec un temps d'1min et 10 secondes en moyenne.
Comme dit précédemment, nous avons axé notre projet sur un grand découpage de celui-ci, car nous savions que de nombreuses parties de notre algorithme allaient être modifiées très fréquemment. Cela nous a permis de tester les fonctionnalités une à une pour voir si celles-ci étaient bénéfiques tant d'un point de vue de score que de performance.
De ce fait, notre code est aussi très facile d'accès et pourrait être adapté pour d'autres types de stacktraces, il ne faudrait alors que modifier les fonctions à l'intérieur du fichier parse.js.
Concernant les limitations du projet, nous avons mis en oeuvre l'algorithme du papier de Microsoft, il reste donc assez générique quelques soient le type de stacktraces à analyser. La vraie limitation est située dans le parseur qui lui est assez spécifique aux types de stacktrace que l'on nous a fourni dans les datasets.
Nous possédons aussi une branche contenant l'algorithme permettant de calculer les coéfficiant C et O de façon optimale. Cependant cet algorithme est très gourmand en temps et nous sommes donc limité dans l'utilisation de celui-ci.
Pour conclure, nous pensons être arrivé à un algorithme efficace grâce à une bonne méthodologie. Celle-ci consistant en de nombreuses heures de recherches (4 à 5 heures dans ce cas-ci) afin de trouver des projets ou documents traitant de ce sujet. Ensuite de les lire rapidement, les trier pour pouvoir en extraire les principales données et enfin les appliquer à notre projet.
Nous sommes assez fier d'avoir pu mettre en oeuvre l'algorithme de Microsoft et d'avoir presque atteint un projet open source utilisable pour la communauté (grâce aux tests, la couverture de tests et l'intégration continue). D'autant que d'après nos recherches il n'y a actuellement aucune version de cet algorithme disponible sur github pour l'instant. #jeSuisOPL
- [1] Crashwalk : https://github.com/bnagy/crashwalk
- [2] AFL : http://lcamtuf.coredump.cx/afl/ & https://en.wikipedia.org/wiki/American_fuzzy_lop_(fuzzer)
- [3] Sentry : https://sentry.io/welcome/ & https://github.com/getsentry/sentry
- [4] Rollbar : https://rollbar.com/
- [5] Rebucket : https://www.microsoft.com/en-us/research/publication/rebucket-a-method-for-clustering-duplicate-crash-reports-based-on-call-stack-similarity/
- [6] Bluebird : https://github.com/petkaantonov/bluebird
- [7] Crypto : https://github.com/Gozala/crypto
- [8] Mathjs : http://mathjs.org/
- [9] FS : https://nodejs.org/api/fs.html
- [10] Istanbul : https://github.com/gotwarlost/istanbul
- [11] Mocha : https://mochajs.org/
- [12] Travis CI : https://travis-ci.org
N'ayant pu retirer quelque chose de concret de ce projet, nous avons préféré déplacer celui-ci en Annexe car il nous a néanmoins aider à arriver à notre résultat final.
Ce projet [1] a pour vocation de trier les crashs disque de Linux et de les trier dans différentes buckets. Celui-ci est écrit en Go et une partie en Python.
Il nous a fait découvrir le projet "american fuzzy lop (fuzzer) (AFL)" [2] qui est un algorithme permettant d'augmenter la couverture des tests. AFL demande à l'utilisateur de fournir un exemple de commande qui teste l'application et un petit exemple de fichier d'entrée.
Après cette phase initiale, AFL commence le processus actuel de 'fuzzing' en appliquant différentes modifications au fichier d'entrée. Quand le programme crash, cella suggère un potentiel nouveau bug ou même une faille de sécurité. Il enregistre donc le fichier d'entrée utilisé pour inspection future.
Voici un exemple de modification d'image par AFL :
![]()
Malgré l'intéret pour ce projet et AFL, nous n'avons pas pu en retirer quelque chose d'intéressant pour notre problème actuel car l'algorithme de tri était trop spécifique aux crashs disque.
- Ajouter la stacktrace traitée au tableau des buckets
- Possibilité d'add/remove des fonctionnalités